


hive的分桶
一.总结
分桶是相对分区进行更细粒度的划分。分桶将整个数据内容安装某列属性值得hash值进行区分,如要安装name属性分为3个桶,就是对name属性值的hash值对3取摸,按照取模结果对数据分桶。如取模结果为0的数据记录存放到一个文件,取模为1的数据存放到一个文件,取模为2的数据存放到一个文件。几个桶就是几个文件.
二.用途
在分区数量过于庞大,就会有海量的目录建立,以至于可能导致文件系统崩溃时,我们就需要使用分桶来解决问题了。
三.建立分桶表
set hive.enforce.bucketing=true;(建议开启)
CREATE TABLE `report_buckets_test`(
`id` string,
`mobile` string,
`idcard` string,
`name` string,
`result` string,
`contact` string,
`ip` string,
`gps` string,
`create_date` string,
`checktime` string,
`checkname` string,
`depname` string,
`depcode` string,
`county_code` string,
`area_addr` string)clustered by (mobile) INTO 3 BUCKETS;
往表里插入数据
set hive.enforce.bucketing=true;(建议开启)
INSERT into report_buckets_test
select * FROM report;
这样数据就会被插入到表report_buckets_test
因为分表作用的是文件,并不会引起目录的变化吗,这里是建立3个桶来装,取模之后只放到三个桶里面去了
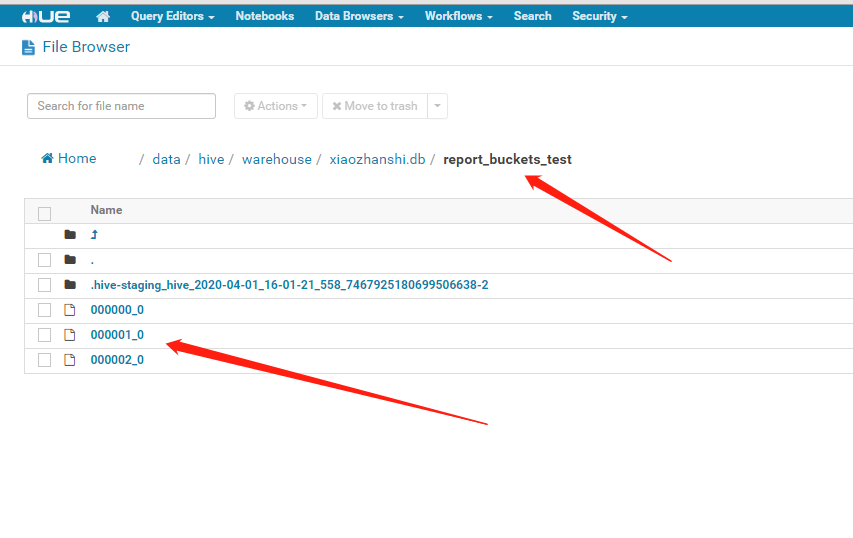
四.基于桶抽样
SELECT * FROM report_buckets_test TABLESAMPLE(BUCKET 1 OUT OF 3 ON mobile);
桶的个数从1开始计数。因此,前面的查询从4个桶的第一个中获取所有的用户。 对于一个大规模的、均匀分布的数据集,这会返回表中约四分之一的数据行。我们 也可以用其他比例对若干个桶进行取样(因为取样并不是一个精确的操作,因此这个 比例不一定要是桶数的整数倍)。

