

基础数据结构与算法
基础数据结构与算法
一、实战
问题1:我们程序里的数据存储方式有几种?
数组(顺序存储)链表(链式存储)
|
数据结构 |
存储形式 |
|
队列、栈 |
数组、链表 |
|
树 |
链表 |
|
图 |
数组(邻接矩阵) |
|
哈希表 |
数组 |
数组:连续存储。
通过索引可以查找到对应的元素,查找快,查找的时间复杂度O(1);
存在扩容问题,扩容的时间复杂度O(n);
插入和删除,每次都必须搬移后面的数据以保持连续性,时间复杂度O(n);
链表:元素不连续,不存在扩容问题;
插入和删除,时间复杂度是O(1);
因为空间不连续,无法根据一个索引算出对应元素的地址,不能随机访问,时间复杂度是O(n)。
1、如何实现一个队列?ArrayBlockingQueue的队列是什么?
涉及到入队、出队、判空和判满;
数组复用;
1)入队
通过取模的方式让数组复用
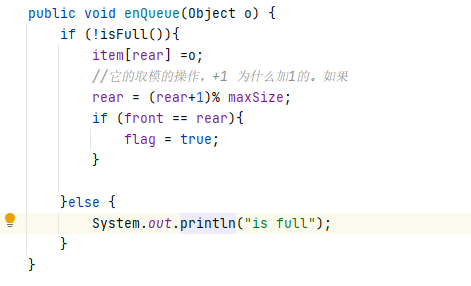
2)出队

2、说一下mysql的索引设计?
Innodb 默认是B+树,
1)数组:静态数据,插入比较麻烦
2)链表:二叉树(没有顺序)
3)二叉排序树
一颗空树,或者是具有下列性质的二叉树:
① 若左子树不为空,则左子树上所有节点的值均小于它的根节点的值;
② 若右子树不为空,则右子树上所有节点的值均大于或者等于它的根节点值;
③ 左右子树也分别为二叉排序树。
问题是:链表会无限增长,基本和链表差不多,查询复杂度变为O(N),查询效率很慢,不可能用排序二叉树实现mysql的索引。
3)平衡二叉树
任意节点的子树的高度差都小于等于1。
通过右旋、左旋、双旋转,让一个不平衡的二叉树变为平衡二叉树。
① 右旋
创建一个新节点,值等于当前根节点的值;
把新节点的右子树设置为当前节点的右子树;
把新节点的左子树设置成当前节点的左子树的右子树;
把当前节点的值换为左节点的值;
把当前节点的左子树设置成左子树的左子树
把当前节点的右子树设置为新节点

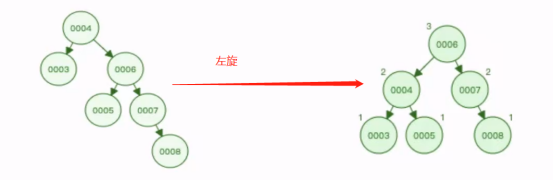
② 左旋
创建一个新节点,值等于当前根节点的值;
把新节点的左子树设置为当前节点的左子树;
把新节点的右子树设置成当前节点的右子树的左子树;
把当前节点的值换为右节点的值;
把当前节点的右子树设置成右子树的右子树
把当前节点的左子树设置为新节点
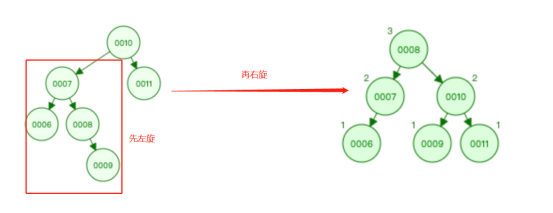
③ 双旋转
符合右旋条件
当前节点的左子树的右子树的高度大于当前节点的左子树的左子树,对当前节点的左孩子进行左旋
再对当前节点进行右旋;
4)B树
平衡二叉树的问题:
根据局部性原理,mysql拿数据一拿就拿一页的数据(32k)。
平衡二叉树一个node肯定装不了32k,这导致查询次数非常多,让IO负载非常大,在平衡二叉树的基础上提出了B树;
在一个里面存了两个数据,并且是多叉的。使数据存的尽可能多,存一页的数据,这样的话数据量变多,查询的次数变少。
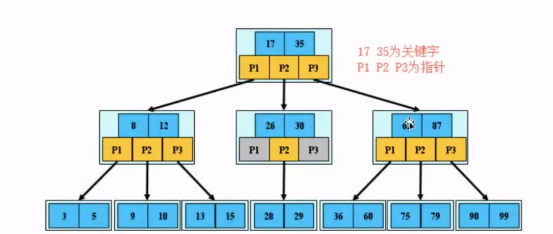
5)B+树
B树的问题:
查询效率不稳定,层数多,每一行都有数据;IO次数不一定;因此引入B+树;
B+树的数据只存在在叶子节点;并且使用链表的形式。
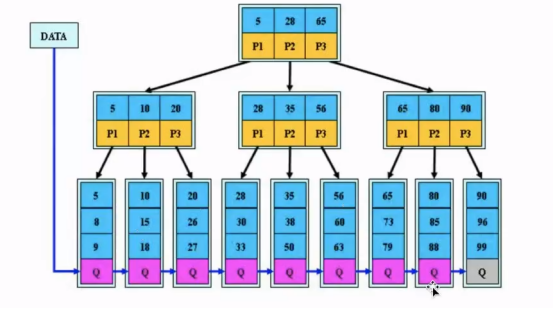
叶子节点存的就是主键索引。二级索引,如果上面存的二级索引name ,下面存主键id的地址。
B+树优点:
①单一节点存储更多元素,使得查询的IO次数减少;
② 所有查询都要查找到叶子节点,查询性能稳定。
③ 所有叶子节点形成有序链表,便于范围查询;
④ 扫表能力强,不需要一直去遍历这棵树了。
