


服务治理及源码分析
服务治理
一、服务的演变之路
1、单体服务
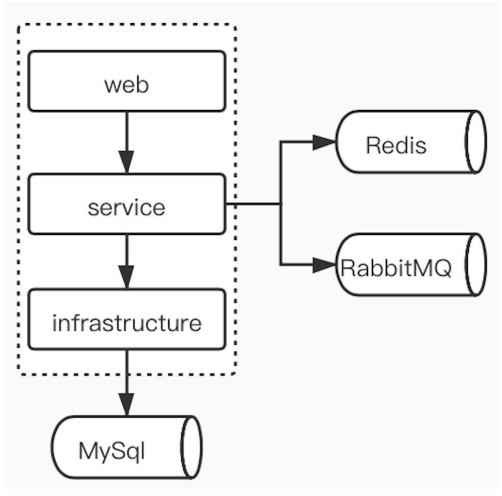
优点:① 架构简单 ② 部署简单,对运维人员比较友好;
缺点:① 代码量日益庞大 ② 上线部署特别特别慢;③ 有的模块是IO密集型的,有的模块是cpu密集型的,对硬件的要求不一样,cpu密集型提升cpu核数;如果是IO密集型的,可以将机器硬盘变为固态硬盘,但如果都在一个service里面,没办法区分哪个是CPU密集型的哪个是IO密集型的,只能全升,那付出的代价就大了;
④ 技术升级,只能整个都换
2、微服务
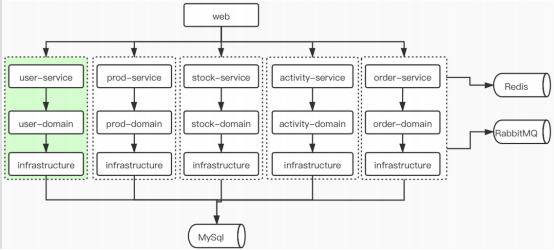
通过业务垂直划分,DDD模型。微服务就是小,职责单一;
优点:① 服务非常小,职责单一,如果来1个新人,只开相应的微服务代码权限; ②服务之间互不影响,某个服务的上线、出问题对其它服务没有影响;③ 针对不同的服务是IO密集型的还是CPU密集型的,可以进行不同的升级方式。
缺点:①运维成本高;②单体服务实在一个jvm里面运行,微服务是进程之间的通信,会有网络消耗的成本,根据http调用;③如果横向扩展,会出现数据不一致的问题;④服务非常多,如果出异常,定位问题比单体服务复杂的多。
二、SpringCloud简介
1、springCloud微服务的生态圈
2、SpringCloud的模块
|
微服务技术栈 |
实现技术 |
|
服务开发 |
SpringBoot SpringMVC |
|
服务配置 |
Config |
|
服务注册和发现 |
Eureka |
|
服务调用 |
Ribbon,Feign |
|
服务路由 |
zuul |
|
服务熔断 |
Hystrix |
|
服务全链路监控 |
Sleuth +zipkin |
|
服务部署 |
Docker、K8s |
3、技术栈的应用
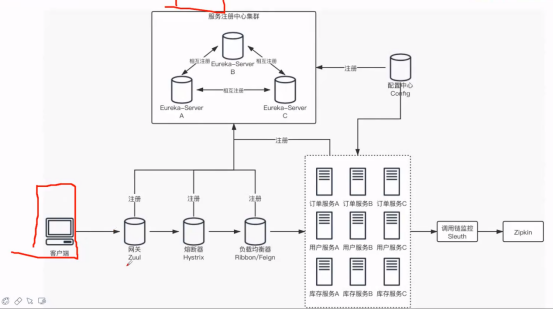
1)zull 网关,权限校验
2)Eureka 注册中心,所有的服务都注册到Eureka
三、服务治理
1、服务治理的概念
1)服务治理可以说是微服务架构中最为核心和基础的模块,它主要用来实现各个微服务实例的自动注册和服务发现。
2)在传统的系统部署中,服务运行在一个固定的已知的ip和端口上,如果一个服务需要调用另一个服务,那么可以通过地址直接调用。但是,在虚拟化或者容器化的环境中,服务实例的启动和销毁是很频繁的,那么服务地址也是在动态变化的,因此就产生了服务治理的概念。
3)如果需要将请求发送到动态变化的服务实例上,至少需要两个步骤:服务注册和发现。
2、服务发现的两种方式
1)客户端服务发现
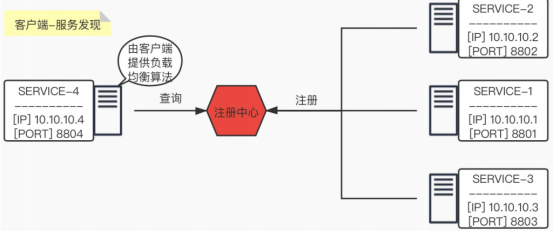
优点:客户端知道所有可用服务的实际网络地址,所以可以方便的实现负载均衡功能。(比如轮询、随机、一致性hash)
缺点:耦合性强。针对不同的语言,每个客户端都得实现一套服务发现功能。
2)服务端服务发现

优点:服务端发现逻辑对客户是不透明的,客户端只需要向load balancer发送请求就可以了。
缺点:必须关注负载均衡的高可用性。
1、服务治理技术对比
|
Feature |
Consul |
zookeeper |
etcd |
euerka |
|
服务健康检查 |
服务状态,内存,硬盘等 |
(弱)长连接keepalive |
连接心跳 |
可配,支持 |
|
多数据中心 |
支持 |
-- |
-- |
-- |
|
Kv存储服务 |
支持 |
支持 |
支持 |
-- |
|
一致性 |
Raft |
zab |
raft |
-- |
|
cap |
cp |
cp |
cp |
ap |
|
使用接口(多语言能力) |
支持http和dns |
客户端 |
http/grpc |
http(sidecar) |
|
自身监控 |
Metrics |
---- |
Metrics |
Metrics |
Sevice mesh :sidecar,每个服务都有一个前置处理
四、CAP
CAP理论指的是一个分布式系统最多只能同时满足一致性(consistency)、可用性(availability)和分区容错性(Partion tolerance)这三项中的两项。分布式一定有 P
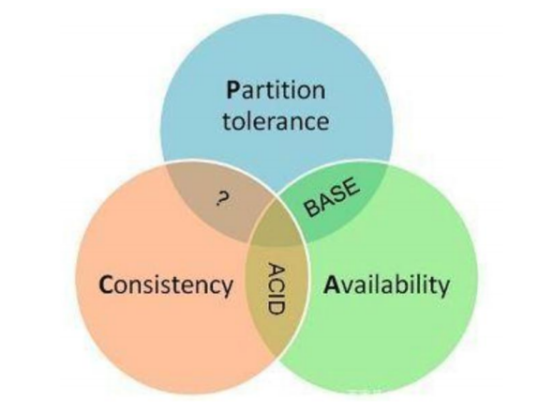
1一致性和可用性,如果user 集群部署四台服务,其中一台服务挂掉,那如果user服务继续可以用,就能保证可用性,但是如果挂掉这台服务有数据没有同步过去,那就不能保证数据的强一致性,反之不能保证数据的可用性。
1、分区容错性,在分布式系统中,有多个节点,如果某些节点之间断了连接,就分为几个区域,数据在这几个区域散落,如果数据都是冗余保存,满足分区容错性,但是就不会满足强一致性。
2、BASE 数据的最终一致性
3、ACID 原子性、一致性、隔离性、持久性
一、Eureka实战
1、涉及 client和server;client包括producer和 consumer
Sever注册中心,集群部署;
2、Sever配置:第一步使用@EnableEurekaServer
第二部配置文件:
增加相应配置application.properties
server.port=1111
# 表示不向注册中心注册自己
eureka.instance.hostname=localhost
# 不需要去检索服务
eureka.client.register-with-eureka=false
eureka.client.fetch-registry=false
3、为什么加上@EnableEurekaServer就可以了?
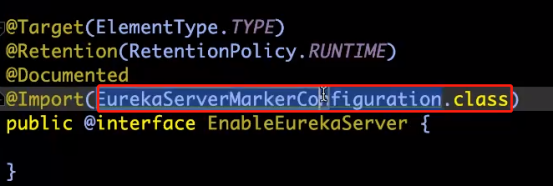
EurekaServerMarkerConfiguration.class,加入一个eurekaServerMarkerBean,初始化Marker
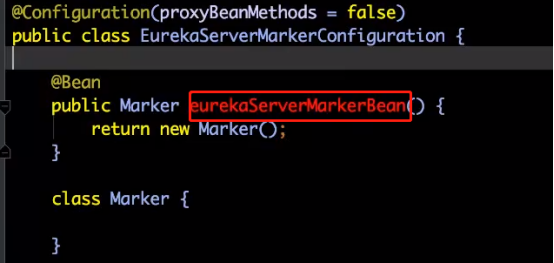
在spring.factory


必须有Marker才能初始化EurekaServerAutoConfiguration 类,才能实现自动化配置。
5、client 端(producer和consumer)
1)@EnableDiscoveryClient 加不加都可以启动客户端;
因为autoRegister()默认是true
在spring.factory下面有客户端的自动配置类。
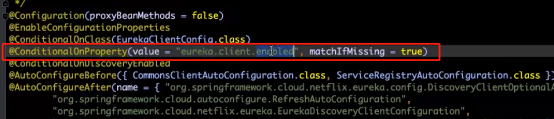
如果丢失,默认是true,所以写不写都可以
2)相关配置
① 通过@EnableDiscoveryClient注解,来激活DiscoveryClient实现
② 增加相应配置application.properties
# 服务名
spring.application.name=eureku-service-1
# 指定服务注册中心的地址
eureka.client.service- url.defaultZone=http://localhost:1111/eureka/
6、通过consumer 访问 producer
7、集群配置
Server之间相互注册,搭建集群。
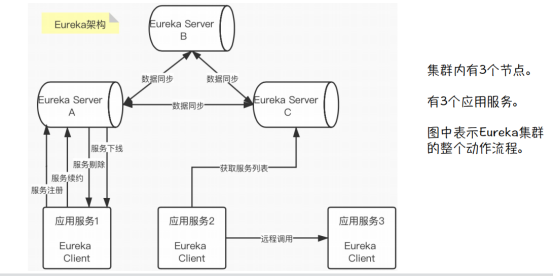
六、Eureka 核心功能

1、服务注册功能
Client 注册到Euraka,注册功能
2、服务续约功能

3、服务同步功能
如果Euraka Server集群部署,就会涉及到数据的同步。启动定时任务,每隔600s执行一次。
4、服务获取功能
Client 启动以后,会给Euraka Server发送一个requst请求,获取服务列表,缓存到本地。缓存30s,服务端也缓存30s;缓存的多写,本地内存、读写缓存、只读;存是先存到本地内存,在写入读写缓存,最后到只读;获取正好相反
5、服务调用功能
Client端,请求server端,可以获得服务列表;Euraka 有个叫regin和zool,一个regin里面有多个zool,在调用时优选选择同一个zool下面的机器。
6、服务下线功能
Client关闭或者重启时涉及到一个服务的下线功能。
7、服务剔除功能
由于网络原因导致Client端和Euraka server端不能通信了,Euraka 会创建一个定时任务,默认每隔60s从当前的服务列表,把超时90s的服务剔除掉。
8、服务自我保护功能
如果没有网络了30分钟,按照剔除的逻辑,服务会全部剔除掉,有1个自我保护功能,当15分钟之内,出现了低于85%的连续续约情况,会触发自我保护功能,不再剔除。
一、常用的Http rest接口
1、查看所有的服务注册列表
http://localhost:1001/euraka/apps
2、查看某一个服务的注册列表
http://localhost:1001/euraka/apps/service-name
3、服务下线
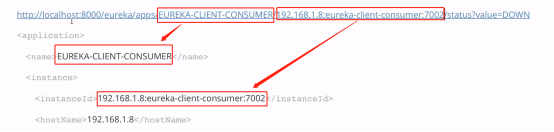
4、服务恢复
就是上面的链接 value = UP
5、服务剔除
Delete http://localhost:1001/euraka/apps/SERVICE-NAME/INSTANCE-NAME
八、源码分析
1、在看源码时@import非常关键

问:如何调用EurakaServerInitializerConfiguration的start方法?
答:由于它实现了smartLifecycle接口,并且isAutoStartup()方法返回的是true,那么会在容器启动过程中调用finishRefresh()方法来调用start()方法。
源码分析如下:
AbstractApplicationContext 的refresh()方法,有一个finishRefresh()方法
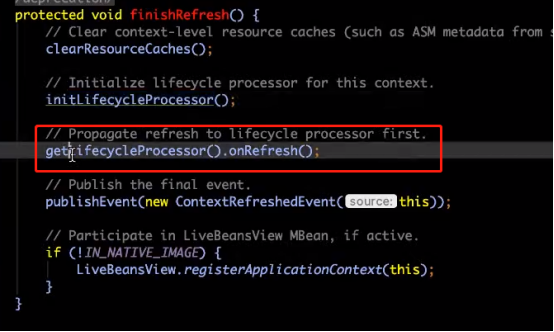
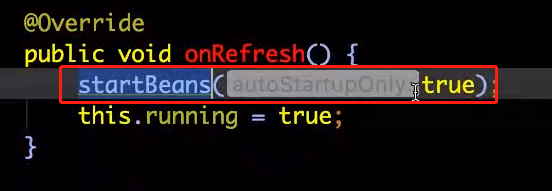
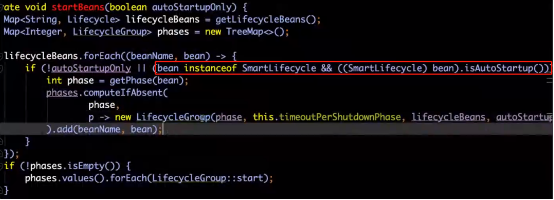
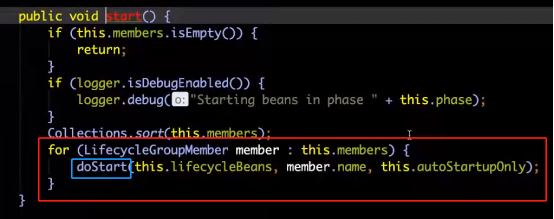
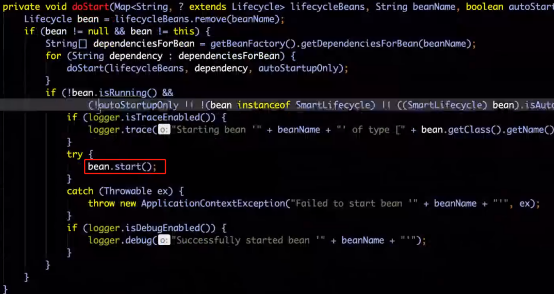
2、Start方法

3、初始化上下文,涉及服务注册和服务剔除

1)服务剔除逻辑
每隔60s执行一次剔除

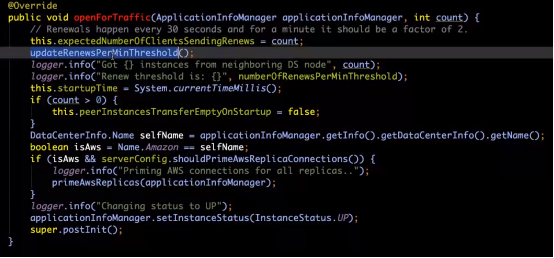

EvictionTask() 里面有一个run()方法。
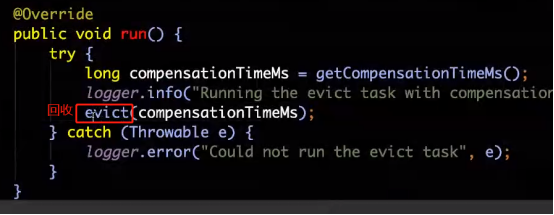
2)同步


