
并发编程基础
并发编程基础
一、 并发编程基础
1、synchronized 原理分析
Synchronized关键字解决的是多线程之间访问同一资源的同步性问题,synchronized关键字,可以保证被它修饰的方法或者代码块在任意时刻,只能在一个线程运行。
2、jdk1.6之前性能比较低,之后引入了大量的优化,如自旋锁、适应性自旋锁、锁消除、锁粗化、偏向锁、轻量级锁。
3、synchronized 使用
1)修饰实例方法
作用于当前对象实例加锁

2)修饰静态方法
也就是给当前类加锁,会作用于所有类对象实例。
3)修饰代码块
指定加锁对象,对给定对象加锁。
4、sychronzied关键字的底层实现原理
同步代码块情况
① sychronzied 同步语句使用的是monitorenter和monitorexist指令,monitorenter指向同步代码块的开始时间,monitorexist指向同步代码块的结束时间。
② 当执行monitorenter 指令时,线程试图获取锁,也就是获取monitor的持有权。
③ java对象存在于每个java对象的对象投中,synchronized 锁便是通过这种方式获取锁的,也是为什么Java中任意对象可以作为锁的原因。
④ 当计数器为0 可以成功获取锁,计数器加1,在执行monitorexist 后计数器减1,减到0后,表明锁被释放。如果获取对象锁失败,那么当前线程就阻塞等待,直到锁被另一个线程释放为止。
同步方法情况
修饰的方法并没有monitorenter和monitorexist指令,取而代之的确是ACC_SYNCHRONIZED标识,该标识指明了该方法是一个同步方法,JVM通过该ACC_SYNCHRONIZED访问标识来判别这个方法是否被声明同步方法,从而执行相应的同步调用。
5、synchronized JDK 1.6之后的性能优化
锁主要存在四种状态,依次是无锁状态、偏向锁状态、轻量级锁状态、重量级锁状态,他们会随着竞争的激烈而逐渐升级。注意:锁只可以升级不可以降级。
① 偏向锁
引入偏向锁和引入重量级锁的目的很像,他们都是为了没有多线程竞争的前提下,减少传统的重量级锁使用操作系统互斥量产生的性能消耗。但不同的是:轻量级锁在无竞争的情况下使用CAS操作去代替互斥量。而偏向锁在无竞争的情况下把整个同步都消除掉。
② 轻量级锁
倘若偏向锁失败,虚拟机并不会立即升级为重量级锁,他会尝试升级为轻量级锁,轻量级锁不是为了代替重量级锁,它的本意是在没有多线程竞争的前提下,减少传统的重量级锁使用操作系统互斥量产生的性能消耗,轻量级锁的加锁和解锁都用到了CAS操作。
③ 自旋锁和自适应锁
轻量级锁失败后,虚拟机为了避免线程真实地在操作系统层面挂起,还会进行一项成为自旋锁的优化手段。一般线程持有锁的时间都不会太长,所以仅仅为了这一点儿时间去挂起线程是得不偿失的。为了让一个线程等待,我们只需要让线程执行一个忙循环(自旋)。
④ 锁消除
虚拟机在编译运行期,如果监测到那些共享数据不可能存在竞争,那么就执行锁消除。
⑤ 锁粗化
解决一系列连续操作都对同一对象反复加锁和解锁,那么会带来很多不必要的性能消耗。
锁消除和锁粗化的原理就是逃逸分析。
6、synchronized 和 ReentrantLock的对比
① 两者都是可重入锁
② Synchronized 依赖于JVM,ReentrantLock依赖于API
③ ReentrantLock比Synchronized 增加了一些高级功能。主要来说有三点: 等待可中断、可实现公平锁、可实现选择性通知。
1>ReentrantLock 提供了一种能够中断等待锁的线程机制。
Lock.lockInterruptibly()
2>ReentrantLock可以指定是公平锁还是非公平锁。而Synchronized 只能是非公平锁。所谓的公平锁就是先等待的线程先获得锁。ReentrantLock默认情况是非公平的,可以通过ReentrantLock类的ReentrantLock(boolean fair)构造方法来制定是否是公平的。
3>线程对象可以注册在指定的condition中,从而可以有选择性的进行线性通知,在调度线程上更加灵活。在使用notify/notifyAll()方法进行通知时,被通知的线程是由jvm选择的,用ReentrantLock类结合condition实例可以实现选择性通知。Condition 实例的signalAll()方法只会唤醒注册在该condition实例中的所有等待线程。
一、 volatile 原理分析
1、volatile 介绍
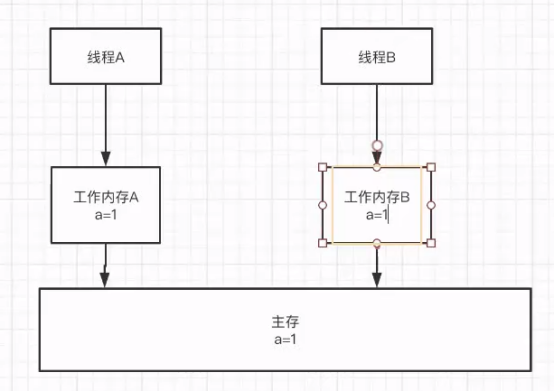
Java内存模型(JMM),各个线程会将共享变量从主内存拷贝到工作内存,然后执行引擎会基于工作内存中的数据进行操作处理。
被 volatile 修饰的变量能够保证每个线程能够获取该变量的最新值,从而避免出现数据脏读的现象。
2、Volatile实现原理
① volatile与可见性
被其修饰的变量在被修改之后可以立即同步到主内存,被其修饰的变量在每次使用之前从主内存刷新。因此,可以使用volatile来保证多线程操作时变量的可见性。
1、volatile与内存屏障
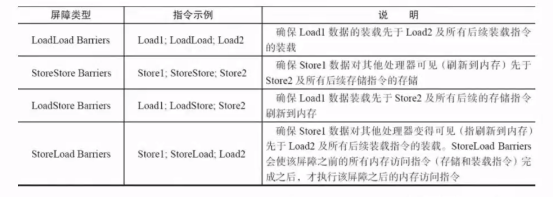
① JMM内存屏障分为4类:
StoreStore 屏障:禁止上面的普通写和下面的volatile写重新排序。
StoreLoad屏障:防止上面的volatile 写与下面的volatile 读重排序
LoadLoad屏障:禁止下面所有的普通读操作和上面的volatile读重排序
LoadStore屏障:禁止下面所有的普通写操作和上面的volatile读重排序。
为了实现volatile内存语义时,编译器在形成字节码时,会在指令序列中插入内存屏障来禁止重排序
① 在每个volatile写操作的前面插入一个storestore屏障;
② 在每一个volatile写操作的后面插入一个storeload屏障;
③ 在每个volatile读操作的后面入一个loadload屏障;
④ 在每个volatile读操作的后面入一个loadstore屏障;
注意:volatile写是在前面和后面分别插入内存屏障,而volatile读操作在后面插入两个内存屏障
一、 不可变对象
1、引入不可变对象的意义
事实上,引起线程安全问题的根本原因在于:多个线程需要同时访问同一共享资源。假如没有共享资源,那么多线程安全问题就自然解决了,java中提供的threadLocal机制就是采用这种思想。
threadLocal 用空间换时间,维护了一个threadLocalmap key 线程id value 是信息。
不可变对象就是这样一种在创建之后就不再变更的对象,这种特性使他们天生支持线程安全,让并发编程变得更简单。
2、如何创建不可变对象?
① 所有成员变量必须是private
② 最好同时用private
③ 不提供修改原对象状态的方法
最常见的方法是不提供setter方法
如果提供修改方法,需要新创建1个对象,并在新创建的对象上进行修改。
④ Getter方法不能对外泄露this引用以及成员变量引用。
3、创建不可变对象
1)Collections.unmodifiableXXX
JDK中提供了一系列方法方便我们创建不可变对象
java.util.Collections#unmodifiableCollection
java.util.Collections#unmodifiableSet
java.util.Collections#unmodifiableSortedSet
java.util.Collections#unmodifiableNavigableSet
java.util.Collections#unmodifiableList
java.util.Collections#unmodifiableMap
java.util.Collections#unmodifiableSortedMap
java.util.Collections#unmodifiableNavigableMap
底层是屏蔽所有的写方法。
2)Guava
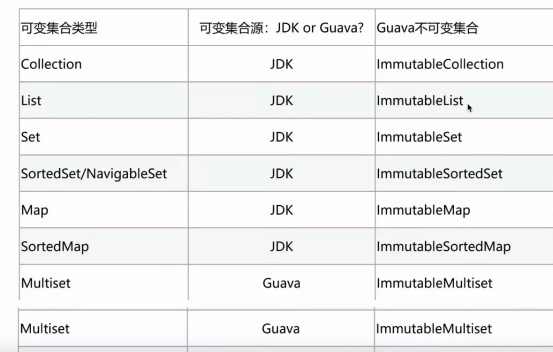
3) Final
① 修饰类(禁止继承)
② 修饰方法(禁止子类被覆盖)
③ Final修饰的变量成为常量
④ Final修饰的引用类型变量,是引用不可变,对象可变。
一、 线程不安全类
StringBuilder --> stringBuffer
simpleDateFormat -> jodaTime
ArrayList ->copyOnWriteArrayList
HashSet treeSet ->copyOnWriteArraySet-> concurrentSkipListSet
HashMap treeMap->concurrentHashMap concurrentSkipListMap
1、HashMap为什么会出现并发问题
HashMap并发问题,会出现脏数据、死锁、造成内存飙升100%
1)Jdk1.8之前,linklist是头插法,在1.8之前,如果在并发情况下,在扩容时发生并发,环形链表就形成了。出现死循环。
2)如果多线程同时使用put方法添加元素,而且假设正好存在两个put的key发生了碰撞,这两个key会添加到数组的同一个位置,这样最终就会发生其中一个线程put的数据被覆盖。
3)如果多个线程同时检测到元素个数超过数组大小*loadFactor,这样就会发生多个线程同时对Node数组进行扩容,都在重新计算元素位置以及复制数据,但是最终只有⼀个线程扩容后的数组会赋给table,也就是说其他线程的都会丢失,并且各⾃线程 put 的数据也丢失
Jdk1.8后,头插法改成了尾插法。变为数组+链表+红黑树,提高了性能
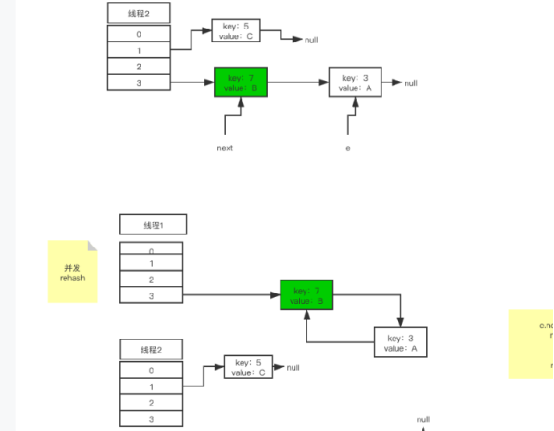
1、HashMap出现不安全类的解决方案
ConcurrentHashMap
java.util.Collections#synchronizedCollection(java.util.Collection)
java.util.Collections#synchronizedSet(java.util.Set)
java.util.Collections#synchronizedSortedSet
java.util.Collections#synchronizedNavigableSet
java.util.Collections#synchronizedList(java.util.List)
java.util.Collections#synchronizedMap
1、ConcurrentHashMap
在jdk1.7中ConcurrentHashMap 采用数组+segment(分段锁)的方式实现。
① segment(分段锁)
ConcurrentHashMap中的分段锁称为segment,它即类似于HashMap的结构,即内部拥有一个Entry数组,数组中的每一个元素又是一个链表,同时又是一个reentrantLock(segment 继承了reentrantLock)
② 内部结构
ConcurrentHashMap使用了分段锁技术,将数据分成一段一段的存储,然后每一段配上一把锁,当一个线程占用锁访问其中一段数据的时候,其他段的数据也能被其它线程访问,能够真正的实现并发访问。
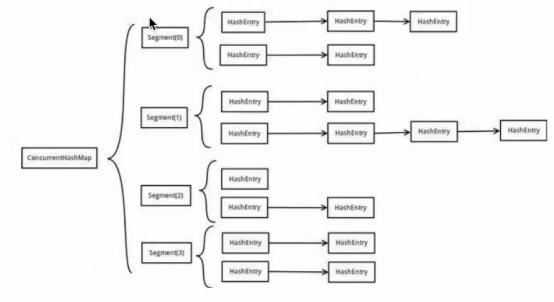
从上面的结构我们可以了解到,ConcurrentHashMap定位一个个元素的过程需要两次Hash。第一Hash定位到segment,第二次Hash定位到元素所在的链表头部。
JDK1.8 采用了数组+链表+红黑树大的实现方式来设计,内部采用CAS操作。
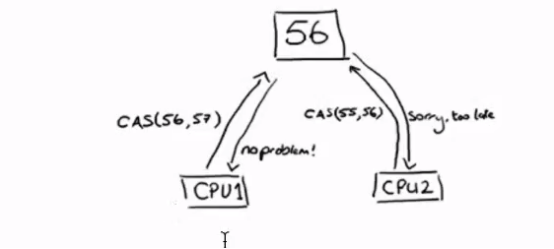
CAS操作包含三个操作数----内存位置(V)、预期原值(A)和新值(B)。如果内存地址⾥⾯的值和A的值是⼀样的,那么就将内存⾥⾯的值更新成B。CAS是通过⽆限循环来获取数据的,如果在第⼀轮循环中,a线程获取地址⾥⾯的值被b线程修改了,那么a线程需要⾃旋,到下次循环才有可能机会执⾏。
2、cow写时复制(copyOnWriteArrayList ,copyOnWriteArraySet)
写⼊时复制(CopyOnWrite)思想写⼊时复制(CopyOnWrite,简称COW)思想是计算机程序设计领域中的⼀种优化策略。 其核⼼思想是,如果有多个调⽤者(Callers)同时要求相同的资源(如内存或 者是磁盘上的数据存储),他们会共同获取相同的指针指向相同的资源,直到某个调⽤者视图修改资源 内容时,系统才会真正复制⼀份专⽤副本(private copy)给该调⽤者,⽽其他调⽤者所⻅到的最初的 资源仍然保持不变。这过程对其他的调⽤者都是透明的(transparently)。此做法主要的优点是如果调
⽤者没有修改资源,就不会有副本(private copy)被创建,因此多个调⽤者只是读取操作时可以共享同⼀份资源。
① copyOnWriteArrayList
实现原理:
copyOnWriteArrayList 允许并发的读,读操作是无锁的,性能比较高。比如写操作的话,比如向容器增加一个元素,则首先将当前容器复制一份,然后在新副本上执行写操作,结束之后再将原容器的引用指向新容器。
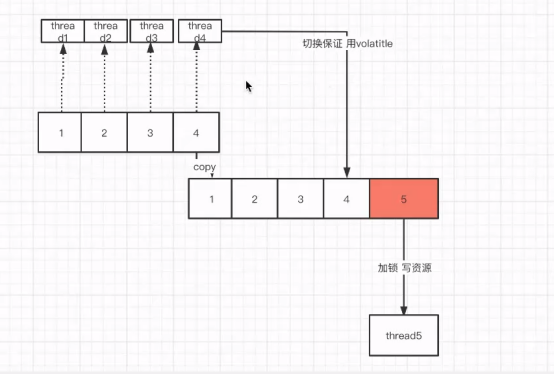
优点:① 读操作性能很高,因为无需任何同步措施,比较适合读多写少的并发场景。
②java 中的list在遍历时,若中途其他线程对容器进行修改,则会抛出concurrentModificationException异常。
而copyOnWriteArrayList 使用了读写分离的思想,遍历和修改作用在不同的list容器,不会抛出异常。
缺点:① 内存占用问题,毕竟每次执行写操作都将原容器拷贝一份,数据量大时,对内存压力比较大,甚至可以频繁引起GC
② 读写作用于不同的容器,有可能会出现读不到刚写入的数据。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号