Dubbo分布式扩展
一:Dubbo集群容错
1、Failover Cluster
失败自动切换,当出现失败,重试其它服务器通常用于读操作,但重试会带来更长延迟。可通过retries = “2”来实现重试次数(不含第一次)。
<dubbo:reference retries="2"/>

1、Failfast Cluster
快速失败,只发布一次调用,失败立即报错。通常用于非幂等性的写操作,比录。
<dubbo:service cluster="failfast" />
2、Failsafe Cluster
失败安全,出现异常时,直接忽略。通常⽤于写⼊审计⽇志等操作。
<dubbo:service cluster="failsafe"/>
3、Failback Cluster
失败自动恢复,后台记录失败请求,定时重发。通常用于消息通知操作。<dubbo:service cluster="failback"/>
4、Forking Cluster
并行调用多个服务器,只要一个成功即返回。通常用于实时性要求较高的读写操作,但需要浪费更多的服务资源。可通过forks = “2”来设置最大并行数。
<dubbo:service cluster="forking" forks="2">
5、Broadcast Cluster
广播调用所有提供者,逐个调用,任意一台报错则报错。通常用于通知所有提供者更新缓存或日志等本地资源信息。
<dubbo:service cluster="broadcast" forks="2">
二、dubbo负载均衡
1、Random LoadBalance
随机,按权重设置随机概率。
2、RoundRobin LoadBalance
轮询,按公约后的权重设置轮询比率。
3、LeastActive LoadBalance
最少活跃调用数,相同活跃数的随机,活跃数指调用前后计数差。
4、ConsistentHash LoadBalance
一致性Hash,相同参数请求总是发到同一提供者
三、Dubbo 最佳实践
1、分包
建议将服务接口、服务模型、服务异常等均放在AIP包中。
2、粒度
服务接口尽可能大粒度,每个服务方法应代表一个功能。
3、版本
每个接口都应对应版本号,为后续不兼容
4、兼容性
服务接口增加方法,或服务模型增加字段,可向后兼容,删除方法和字段没办法向后兼容,需要升级版本号
5、枚举值
不建议使用枚举
6、序列化
服务参数及返回值建议使用POJO对象
7、调用
四、Dubbo 推荐用法
1、在provider端尽量多配置consumer 端属性,一下方法可以配在provider:
1) Timeout:方法调用的超时时间
2) Retries:失败重试次数
Loadbalance:负载均衡算法,缺省是随机 random 。还可以配置轮询 roundrobin 、最不活跃优先 4 leastactive 和⼀致性哈希 consistenthash 等
3) Actives 消费者端的最大并发调用限制
2、在provider端配置合理的provider端属性
1)threads:服务线程池的大小
2)Executes:一个服务提供者并行执行请求上限
3、配置管理信息
<dubbo:reference owner=”ding.lid,william.liangf” />
4、配置dubbo缓存文件
<dubbo:registry file=”${user.home}/output/dubbo.cache” />
该⽂件会缓存注册中⼼列表和服务提供者列表。配置缓存⽂件后,应⽤重启过程中,若注册中⼼不可用,应用会从缓存文件读取服务提供者列表,进一步保证应用的可靠性。
5、监控配置
1)使⽤固定端⼝暴露服务,⽽不要使⽤随机端⼝
这样在注册中⼼推送有延迟的情况下,消费者通过缓存列表也能调⽤到原地址,保证调⽤成
功。
五、Dubbo常见面试题
1、为什么要用dubbo
随着服务化的进一步发展,服务越来越多,服务之间的调用和依赖关系越来越复杂,诞生了面向服务的架构体系(SOA),也因此衍生出了一系列的相应技术,如服务提供、服务调用、连接处理、通讯协议、序列化方式、服务发现等行为进行封装的服务架构。就这样为分布式的服务治理框架就出现了,Dubbo也就产生了。
2、RPC与HTTP区别
传输效率
RPC:使⽤⾃定义的TCP协议,可以让请求报⽂体积更⼩,或者使⽤HTTP2协议,也可以很好的减少报 ⽂的体积,提⾼传输效率
HTTP:如果是基于HTTP1.1的协议,请求中会包含很多⽆⽤的内容
性能消耗
RPC:可以基于thrift实现⾼效的⼆进制传输
HTTP:⼤部分是通过json来实现的,字节⼤⼩和序列化耗时都⽐thrift要更消耗性能
负载均衡
RPC:基本都⾃带了负载均衡策略HTTP:需要配置Nginx,HAProxy来实现
服务治理
RPC:能做到⾃动通知,不影响上游
HTTP:需要事先通知,修改Nginx/HAProxy配置
总结
RPC主要⽤于公司内部的服务调⽤,性能消耗低,传输效率⾼,服务治理⽅便。HTTP主要⽤于对外的异构环境,浏览器接⼝调⽤,APP
APP接⼝调⽤,第三⽅接⼝调⽤等。
3、默认使用的是什么通信框架,还有别的选择吗
默认推荐使用netty框架,还有mina
4、服务调用时阻塞的吗?
默认是阻塞的,可以异步调用,没有返回值的可以这么做。Dubbo是基于NIO的非阻塞实现并行调用,客户端不需要启动多线程即可完成并行调用,客户端不需要启动多线程即可完成并行调用多个远程服务,相对多线程开销较小,异步调用会返回一个future对象。
5、一般用什么注册中心
推荐使⽤ Zookeeper 作为注册中⼼,还有 Redis、Multicast、Simple 注册中⼼,但不推荐。
6、默认使用什么序列化框架,你知道的有哪些
推荐使用Hessian序列化,还有Dubbo、FastJson、java自带序列化
7、服务提供者能实现失效剔除是什么原理?
服务失效剔除基于Zookeeper的临时节点原理。 服务的提供者有一个宕机了,每台服务器都有1个注册监听,利用watch机制,会删除宕机的临时节点。把最新的链接列表发给consumer
8、服务上线怎么不影响旧版本?
采用多版本控制
9、同一服务多个注册的情况下可以直连某一个服务吗?
可以连接,可以点对点连接,修改配置即可;
10、Dubbo的默认集群容错方案?
Failover Cluster
失败⾃动切换,当出现失败,重试其它服务器。(缺省)
通常⽤于读操作,但重试会带来更⻓延迟。
可通过retries="2"来设置重试次数(不含第⼀次)。
11、负载均衡的策略有哪些?
见上面。
12、Dubbo的整体架构设计有哪些
接⼝服务层(Service):该层与业务逻辑相关,根据 provider 和 consumer 的业务设计对应的接⼝和实现
配置层(Config):对外配置接⼝,以 ServiceConfig 和 ReferenceConfig 为中⼼
服务代理层(Proxy):服务接⼝透明代理,⽣成服务的客户端 Stub 和 服务端的 Skeleton,以ServiceProxy 为中⼼,扩展接⼝为 ProxyFactory
服务注册层(Registry):封装服务地址的注册和发现,以服务 URL 为中⼼,扩展接⼝为RegistryFactory、Registry、RegistryService
路由层(Cluster):封装多个提供者的路由和负载均衡,并桥接注册中⼼,以Invoker 为中⼼,扩展接⼝为 Cluster、Directory、Router 和 LoadBlancce
监控层(Monitor):RPC 调⽤次数和调⽤时间监控,以 Statistics 为中⼼,扩展接⼝为MonitorFactory、Monitor 和 MonitorService
远程调⽤层(Protocal):封装 RPC 调⽤,以 Invocation 和 Result 为中⼼,扩展接⼝为Protocal、Invoker 和 Exporter
信息交换层(Exchange):封装请求响应模式,同步转异步。以 Request 和Response 为中⼼,扩展接⼝为 Exchanger、ExchangeChannel、ExchangeClient 和 ExchangeServer
⽹络传输层(Transport):抽象 mina 和 netty 为统⼀接⼝,以 Message 为中⼼,扩展接⼝为Channel、Transporter、Client、Server
数据序列化层(Serialize):可复⽤的⼀些⼯具,扩展接⼝为 Serialization、ObjectInput、ObjectOutput 和ThreadPool
13、Dubbo SPi 和jDK SPI区别
jDK SPI 会一次性加载所有的扩展实现,如果只希望加载某个实现就不现实了。
Dubbo SPi:
1)对dubbo的扩展,不需要改动dubbo的源码
2)延迟加载,可以一次加载自己想要的扩展实现
3)增加了对扩展点IOC和AOP的支持,一个扩展点可以直接setter注入其它扩展点。
4)Dubbo的扩展机制很好的支持第三方IOC容器,默认支持spring Bean。
六、MVCC原理详解
1、当前读和快照读
快照读是基于MVCC实现的,就是单纯的 SELECT 语句,不包括下面这两类语句:
select....for update
select ....lock in share mode
如果包括以上两个语句就是当前读。
MVCC实现原理
隐式字段

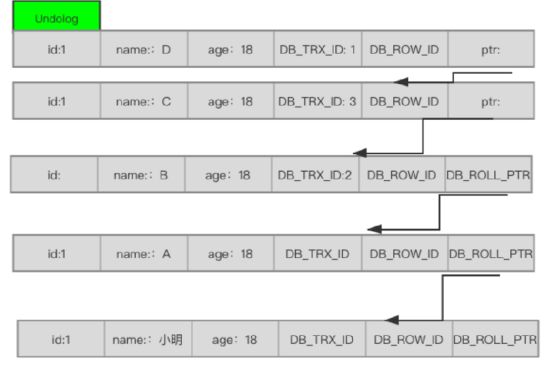
Undo日志
在更新之前先把数据copy一份,放到undolog里面,指针指向上一个版本数据。这样形成一个版本链。
Redolog日志
记录当前事务操作的数据,目的是为了防止机器宕机时,数据没有持久化磁盘,再次重启时会从Redolog里面读取。防止数据丢失的。
Read View(读视图)
把当前存在的事务,还没有提交的事务记录下来形成一个数组。数组里面包括当前事务还有其它没有提交的事务。例如下面返回1和3。还包括当前事务的最大ID
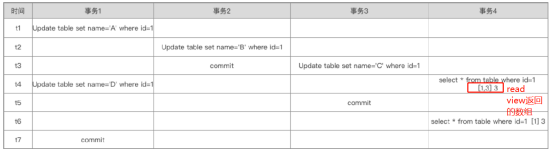
如果事务用的读已提交,拿事务的id与Read View视图的数组进行比较,① 如果小于最小值,那是可见的。
② 如果当前事务ID大于最大值那是不可见的
③ 是否存在未提交的数组里,如果存在不可见
可重复读与读已提交最大的区别在于,重复读的视图不会重新生成,还是沿用第一次查询的视图。
整体流程
二、分布式事务
1、为什么会有分布式事务问题
一个系统垂直划分后,会有跨网络的调用,会出现分布式事务问题
2、分布式理论基础
CAP理论:
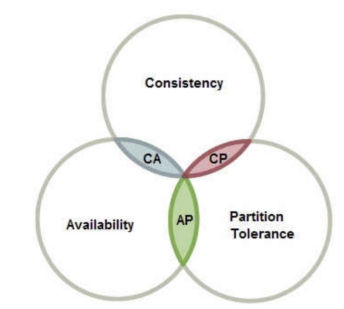
C:一致性(大部分互联网公司会牺牲强一致性)
A:可用性
P:分区容错性
思考Zookeeper 满足CAP中的那些原则:CP,用ZAB协议保证强一致性,用了两阶段提交,但是会有一段时间不可用。
BASE理论 保证最终一致性
1、分布式事务常见的方案
1)2CP 两阶段提交(XA协议,基于数据库的管理机制)
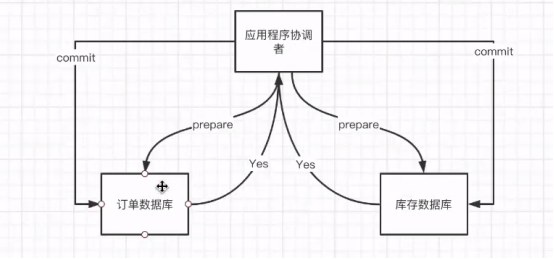
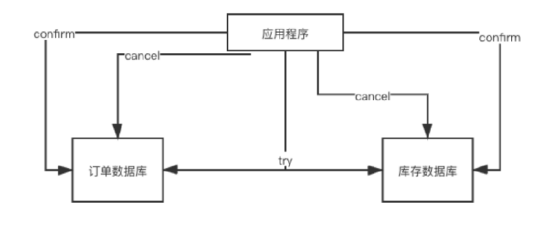
2)TCC(事务补偿) try confirm cancel
Try 检查一下资源够不够
confirm 确认
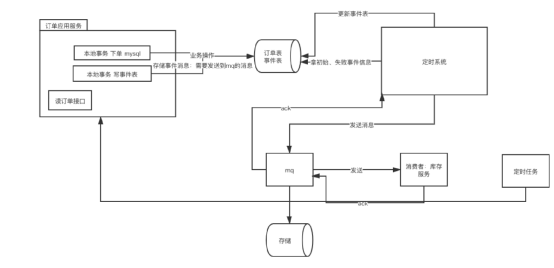
3)本地消息事件+消息队列 (比较常用)
失败后继续轮询。