
Redis
一、redis简介
Redis是开源的,数据结构存于内存中,被用来作为数据库、缓存和消息代理!它支持多种数据结构,例如:字符串、Hash、list、set、zset(带范围查询的排序集合)。Redis具有内置的复制、LUA脚本、LRU逐出,事务和不同级别的磁盘持久性,并通过Redis Sentinel 和 redis Cluster 自动分区提供高可用。
二、redis安装
https://redis.io/download
三、基础篇
1、Redis支持的数据类型

Redis对象源码:
Key redis_String 没有用c的string,用的是自己的。
Value Redis对象,五种类型。

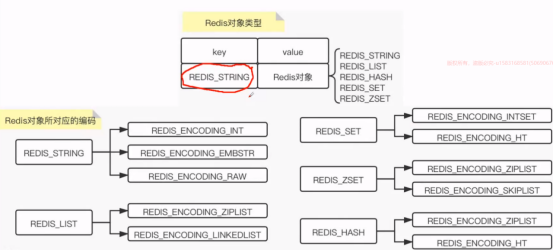
编码与数据结构实现
REDIS_ENCODING_INT long类型整数
REDIS_ENCODING_EMBSTR embstr 编码的简单动态字符串
REDIS_ENCODING_RAW 简单动态字符串
REDIS_ENCODING_HW 字典
REDIS_ENCODING_LINKEDLIST 双向链表 头尾指向null
REDIS_ENCODING_ZIPLIST 压缩列表
REDIS_ENCODING_INTLIST 整数集合
REDIS_ENCODING_SKIPLIST 跳表和字典
2、Redis String 类型
1)基本操作
set key value
get key
del key
expire key second(锁的过期时间)
setnx key value 如果key不存在,才新增key和value
tll key 查看key还要多久过期
setex key value 如果key存在,则将值更新为value
strlen key 计算指定key的值的长度
mset key1 value2 key2 value3
mget key1 key2
2)String
5种类型里面最简单的类型,但是是最常用的类型。扩展是非常高的
Set key value(字符串) value json
字符串底层存储是字符串数组。
String使用了以下3种encoding
Int 设置为long类型的整数,那么encoding是int


Embstr
当我们保存的值小于40时,使用的embstr
专门用于保存短字符串的编码方式。
优点:快。Raw 调用两次的内存分配来分别创建redisObject 和sdshdr;Embstr通过一次内存分配函数来分配一块儿连续的空间,包含着 redisObject 和sdshdr,所以执行速度快
Embstr没有提供修改 函数,如果 需要修改,就要转换为raw,再进行修改
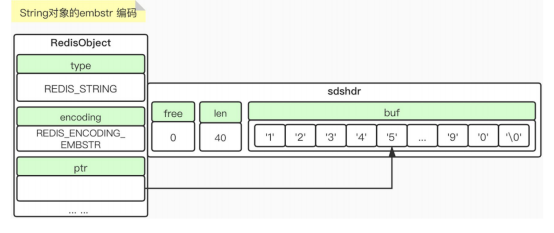

Raw
当我们保存的值大于等于40的时候,则使用raw

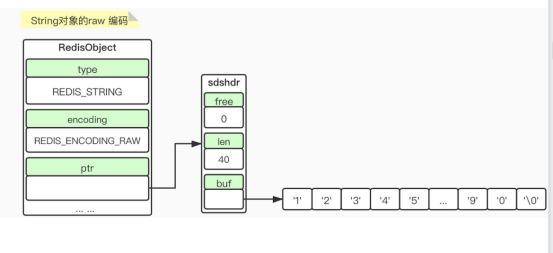
3)SDS
它是什么?简单的动态的字符串,redis自己开发的字符串类型。

Redis为什么要开发字符串类型?
1>计算C字符串的长度,就需要一个一个元素去遍历,直到遇见字符结束符号 ,复杂度O(n);SDS只要读取len就可以,复杂度O(1)
2> C字符串缓冲区溢出

利用strcat(s1,”aaaa”;),在添加元素之前,如果没有进行足够的内存分配,添加,相当于把S2冲掉了。这就是一个缓存区溢出;
SDS是动态的进行空间扩展,是不存在内存溢出。
1>C字符串来说,内存的重新分配是很耗性能的。
SDS能不能解决这个问题?能,2种方式:
①空间的预分配;
如果SDS进行修改后,SDS的长度<1M,那么这个时候,分配的len=free;
如果SDS进行修改后,SDS的长度>=1M,只会按1M分配。
② 惰性释放。
Len = 40 ,如果需要增加10,len =50 在free 里面也预分配10;如果减少10,惰性释放,len = 40 ,free = 20;如果再次增加数据,free里面有数据就不用了再次申请内存了。
2> C字符串,以\0结尾的,并且字符串里不能包含空字符串的,所以使用范围较小,SDS是没有的,它的长度是通过len判断的,这个它可以保存任意的,如图片、音频、二进制数据等。
3、Redis List 类型
常用的就是消息队列,有序的,可重复的,插入和删除比较快,查找比较慢。
lpush key value1 value2 value3 左侧插入
rpush key value1 value2 右侧插入
lpop key 左侧弹出
rpop 右侧弹出
llen key 查看key的长度
lindex key index 查看列表中某个index对应的value
setnx key value 如果key不存在,才新增key和value
lrange key startIndex endIndex 查看指定元素,下标从0开始,-1为倒数第一个
itrm key startIndex endIndex
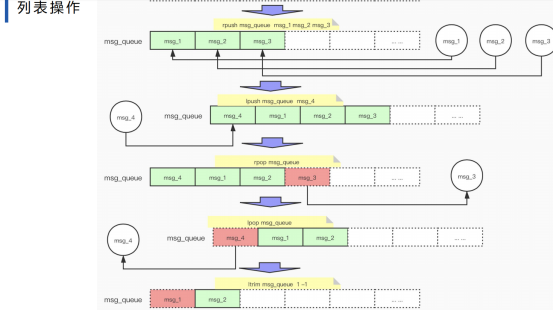
1) Encodong
① ziplist
压缩列表,
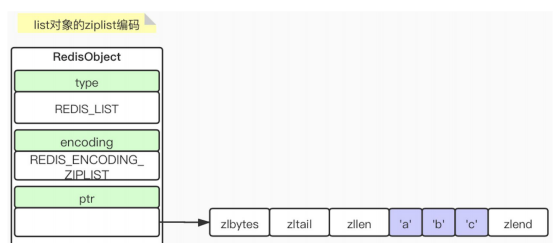
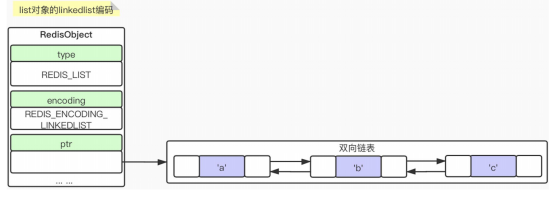
② Linkedlist
4、set
添加的时候保证去重,比如针对用户对文章点赞,可以用set类型进行去重。
sadd key value value1
smembers key 查看集合所有的元素
sismember key value 查看value是否在集合中
scart key 查看集合的长度
spop key 取出集合中一个元素
del key 删除集合
1)encoding intset
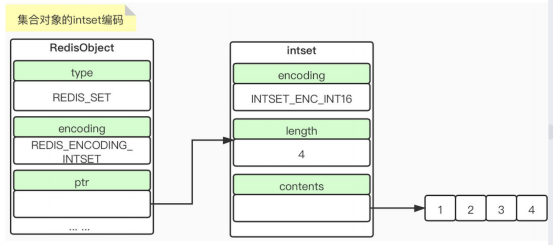
Keys 查看所有的key FlUSHALL 清楚所有的key
Object encoding key 查看编码格式
2) encoding HT
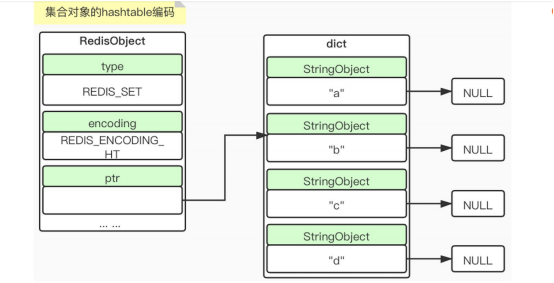
当intset编码时,是针对整形集合作为实现的,HT编码,底层是字典, key String 对象,HT对应的值为null,什么情况下用int编码,什么情况下用HT编码?
Intset必须满足下面两点
1>集合对象保存的所有元素都是整数值
保存的元素<=512
5、Zset
字典+跳表
zadd key value1 score1 value2 score2 添加元素到有序集合中
zscore key value 查看key的score值,输出score>=负无穷,
score<=正无穷的所有元素
zrange key 0 -1 正序输出
zranggebyscore key -inf +inf 正序输出
zrevrange key 0 -1 倒序输出
zcard key 查看key 元素的个数
zrangebyscore key indexStart endStart key中score>=indexStart 且 score<=endStart的元素,正序排列
zrem key value 删除key中的元素value
1)ziplist
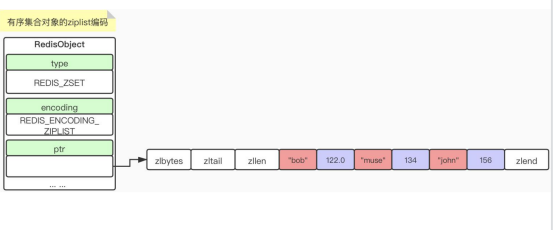
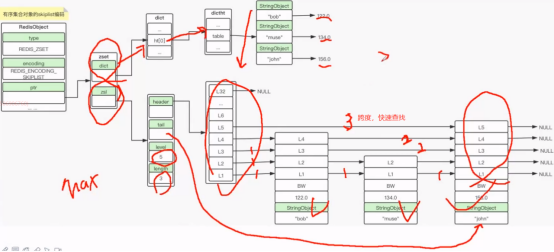
2) Skiplist
使用跳表,方便快速查找,包括 字典和跳表
6、Hash
hset key name value 添加
hget key name 获取
hmset key name1 value1 name2 value2 批量添加
hmget key name1 name2 批量获取
hgetall key 查询key中所有元素
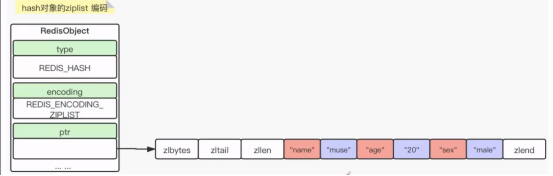
1) Ziplist
2) hashtable
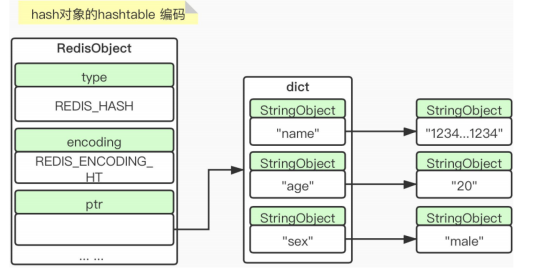
同时满足以下两种情况,那么就是ziplist,否则就是hashtable
1>hash里面的键值对中,key和 value的长度全都小于46个字节 ;
2>Hash里面的键值对中,个数小于512个。
四、应用
1、分布式锁
Set成功了就抢到锁了,不成功没有抢到。
实现要点:
1)加锁和解锁的key一致(账户)
2)不用永久加锁,过期时间。
3)一定保证加锁与设置过期时间的原子性
4)要支持过期续租。重入threadLocal?
分布式锁续约,最好是把过期时间设置长一点儿。续约是增加了复杂程度,value进行一个校验,如线程ID,避免其它线程解掉被人的锁。
加锁 setnx +过期时间
解锁 del key
问题,雷区:
1> 锁过期。增加加锁时间
2> 重叠解锁,锁过期引发的问题。A解了B的锁,B解了C的锁。。。。。。,解锁的 雪崩,用对应的机器好或者serviceid等唯一标识,插入到value,防止解别人的锁。
3> 单点的问题
A线程抢到锁后,把信息存入到主节点,还没有同步到主节点,主节点挂掉,但是从节点没有保存主节点加锁的信息,造成锁也被其它线程抢到。Redlock 解决这个问题
2、消息队列
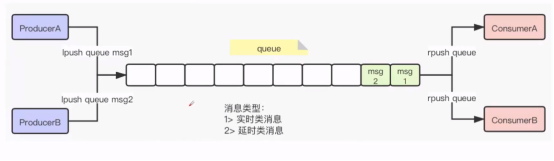
1) 实时类消息和 延时类消息。
延时消息如何去做?延时队列可以通过 Redis 的 zset(有序列表) 来实现。我们将消息序列化成一个字符串作为 zset 的value,这个消息的到期处理时间作为score,可以进行时间排序,抓到时间段的消息。
2) 消息获取方式,push pop,pop的话可以采用blpop 和brpop,利用block阻塞的方式获取,如果有就获取,没有就阻塞。如果redis监测到blpop 和brpop一直空闲,会断开与consumer的链接,这是blpop 和brpop会抛出异常,一定要捕获异常,再次建立连接。
3、位图
五、Redis持久化
redis数据库,但是存于内存中,内存中存储的问题,如果服务器挂掉,数据就没有了。持久化恢复数据,通过RDB和AOF。
1、RDB
支持手工和服务器定时执行,它产生的是二进制文件,它保存的是数据。
RDB相关参数

通过 seconds 和changes验证是否可执行操作,Dirty 与changes进行对比,大于就可以执行;lastsave上次保存的时间,now()时间 - lastsave 执行多少秒 与 seconds进行对比,大于就可执行。

Save BGAAVE 开启子进程进行保存。RDB的加载频率会比AOF高,如果开启了AOF就执行AOF,否则就执行RDB。如果选择BGSAVE,有1个条件检测器,server cron 100ms执行一次。
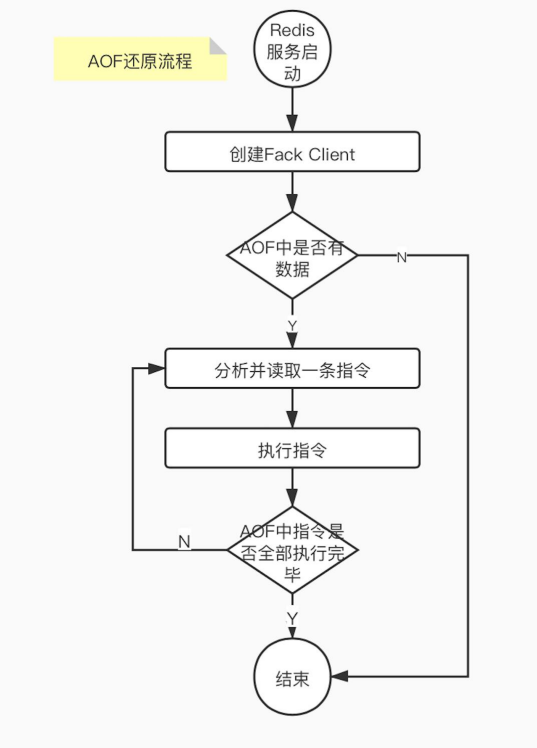
2、AOF append only file
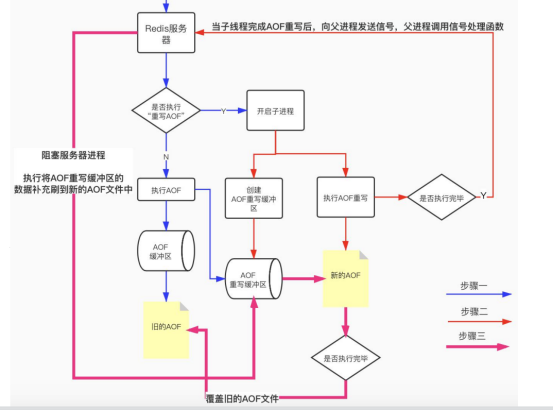
记录redis命令来记录数据库的变更。客户端---->Redis服务器-->执行命令--->保存被执行的命令--->AOF文件中。
Ps -ef | grep redis 查看redis 杀死进程
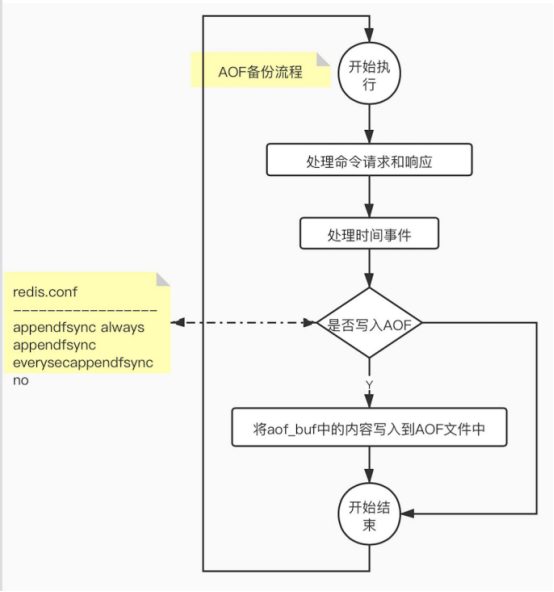
Aof_buf:打开aof开关,每次执行完1条写命令,都会把写命令以请求协议格式保存到aof_buf缓存区中。
appendfsync always 将aof_buf里的内容写入,并同步到AOF文件中,真正的把指令存入了磁盘。优点:数据不丢失,缺点:效率低。
appendfsync everysec 将aof_buf里的内容写入到AOF中,上次同步时间距现在超过1s进行同步。
appendfsync no 将aof_buf里的内容写入到AOF中,不对AOF进行同步操作,同步由操作系统决定。
时间事件,是处理 server cron 100ms执行一次。
写入,写入内存缓存区,然后同步到磁盘。
AOF重写的缺陷?
1)AOF越来越大。造成空间的大量浪费,数据加载也非常慢。
2)多条执行命令的保存,很大几率是浪费的。
为了解决缺项,AOF重写;
6条语句,我们可以通过1条就可以实现数据的还原。
AOF重写必须满足下面两个条件
1)auto-aof -rewrite-percentage 100 //比上次重写后的体量增加了100%
2)auto-aof -rewrite-min-size 64mb //在AOF文件体积超过64MB
重写的时候会有大量的写入操作,如果调用主线程会造成主线程的阻塞,没办法执行其它的操作。所以一定不能做成阻塞的,所以redis fork了一个子进程去执行AOF重写,主线程才不会被阻塞。但是主线程一直不停,一直在写,造成数据不一致。
针对数据不一致的情况,redis服务器设置了1个AOF重写缓冲区,子进程建立的时候开始用的。
缓冲区:
1> AOf缓冲区
2> AOF 重写缓冲区;
等AOF重写完成,通知主线程阻塞,主线程重写缓冲区的数据,这样AOF重写的数据就是1个完整的。
六、集群搭建
port 不能重复
requirepass myredus 是否需要密码
如果主节点设置密码,所有的从节点都要设置masterauth myredus
slave of 主节点的ip+端口,从节点只读
如果 master挂掉,数据就没办法写入,如果加入哨兵,监控master挂掉,重新选1个master。
七、Redis七大经典问题以及解决方案
1、缓存雪崩
定义:指缓存同一时间大面积失效,所以后面的请求都会落到数据库上,造成数据库短时间内承受大量请求而崩溃。
解决方案:① redis高可用,主从+哨兵
② 本地encache缓存+hystrix限流和降级,避免mysql崩溃
③ 缓存的过期时间设置随机,避免在同一时间大量数据过期现象发生
④ 逻辑上永不过期,给每一个数据增加缓存标记,缓存标记失效则更新缓存数据
⑤ 可以使用多级缓存,失效通过二级更新一级。
2、缓存穿透
缓存穿透是指缓存和数据库都没有的数据,导致所有的请求都落到数据上,造成数据库短时间内承受大量的请求而崩溃。
解决方案:① 接口层增加校验,如id<0的直接过滤
②从缓存取不到数据,在数据库也没有找到,针对这样的数据可以以key -value的形式存入缓存,可以设置有效期为30s,这样可以防止用同一id暴力攻击。
③ 采用布隆过滤器,将所有可能存在的数据hash到一个足够大的bitmap中,一个一定不存在的数据会被这个bitmap拦截掉,从而避免了对底层存储系统得查询压力。
3、缓存击穿
某一时刻,由于并发用户特别多,同时读缓存没读到数据,又同时去数据库读取数据,引起数据库压力瞬间增大。和缓存雪崩的不同点儿是,缓存击穿指并发查询同一条数据,缓存雪崩是不同数据都过期了,很多数据都查询不到从而查询数据库
解决方案:① 设置热点数据永不过期,异步线程处理;
② 缓存预热,系统上线后,将热点儿数据直接加到缓存;写一个缓存刷新页面,手动操作热点儿数据的上线。
③ 加互斥锁
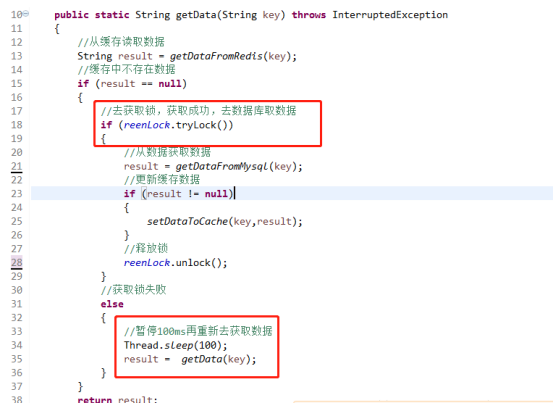
缓存中没有数据,第1个进入的线程,获取锁并从数据库去取数据,没释放锁之前,其他并行进入的线程会等待100ms,再重新去缓存取数据。这样就防止都去数据库重复取数据,重复往缓存中更新数据情况出现;
4、数据不一致
在缓存机器的带宽被打满,或者机房网络出现波动时,缓存更新失败,新数据没有写入缓存,就会导致缓存和DB数据不一致。
缓存rehash时,某个缓存机器反复异常,多次上下线,更新请求多次rehash。这样一份数据存在多个节点,且每次rehash只更新某个节点,导致一些缓存节点产生脏数据。
① cache更新失败后,可以进行重试,则将重试失败的key写入mq,待缓存恢复后,将这些key从缓存中删除。这些key再次被查询时,重新从DB加载,从而保证数据一致性。
② 缓存时间适当调短,让缓存数据及早过期后,然后从DB重新加载,确保数据的最终一致性。
③ 不采用rehash漂移策略,而采用缓存分层策略,尽量避免脏数据产生。
5、数据并发竞争
数据并发竞争在大流量系统也比较常见。比如车票系统,如果某个车次缓存信息过期,但是仍然有大量用户在查询该车次信息。又比如微博系统中,如果某条微博正好被缓存淘汰,但是这条微博仍有大量的转发、评论和点赞。上述情况都会造成并发竞争读取的问题。
解决方案:① 写回操作加互斥锁,查询失败,默认值快速返回。
② 对缓存数据保持多个备份,减少并发竞争的概率
6、热点key问题
明星结婚、离婚、出轨这种特殊突发事件,比如奥运、春节这些重大活动或节日,还比如秒杀、双12、618等线上促销活动,都很容易出现Hot key的情况。
如何提前发现Hot key?
① 对于重大节日、线上促销活动这些提前已知的事情可以提前评估出可能的热key来
② 而对于突发事件,无法评估,可以通过spark,对应流任务进行实时分析,及时发现新发布的热点key。而对于之前已发生的事情,逐步发酵成为key的,则可以通过Hadoop对批处理任务离线计算,找出最近历史数据中的高频热key。
解决方案:
① 这n个key分散存在多个缓存节点,然后client端请求时,随机访问其中某个后缀的hotkey,这样就可以把热key的请求打散,避免一个缓存节点过载。
② 缓存集群可以单节点进行主从复制和垂直扩容
③ 利用应用内的前置缓存,但是需要注意需要设置上限
④ 延迟不敏感,定时刷新,实时感知用主动刷新
⑤ 和缓存穿透一样,限制逃逸流量,单请求进行数据回源并刷新前置
⑥ 无论如何设计,最后都要写一个兜底逻辑,千万级流量说来就来
7、Bigkey问题
微博的 feed 内容缓存也很容易出现,一般用户微博在 140 字以内,但很多用户也会发表 1千 字甚至更长的微博内容,这些长微博也就成了大 key
解决方案:① 首选redis底层数据结构里,根据value的不同,会进行数据结构的重新选择
② 可以扩展新的数据结构,进行序列化构建,然后通过 restore 一次性写入
③ 将大key拆为多个key,设置较长的过期时间

