JVM基础
一、JVM内存模型
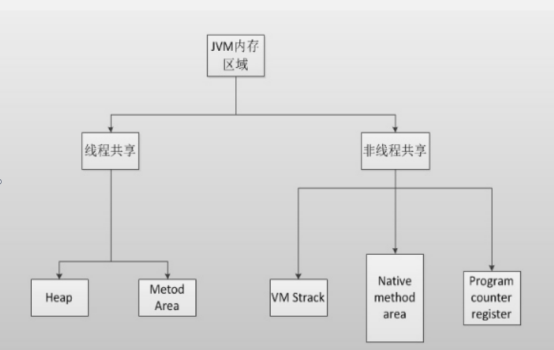
1)程序技术器
程序计数器是一块儿较小的内存区域,作用可以看做是当前线程执行的字节码的位置指示器。分支、循环、跳转、异常处理和线程恢复等基础功能都需要这个计算器来完成。
2)jvm栈
一部分是方法本身、方法内部的变量。
虚拟机栈也叫栈内存,是线程创建时创建,它的生命期是跟随线程的生命期,线程结束栈内存也就释放
3)Heap堆
放对象,是垃圾回收的主要场所
4)Method Area 方法区
是存储方法区的,除此之外,常量、静态变量、JIT(即时编译器)编译后的代码也都在方法区。
常量池,源信息和原数据。
方法区是jvm的一个概念,永久代是是方法区的具体实现。
5)Native method area 本地方法栈
为native方法服务的。
Jdk1.8后,用源空间?取代永久代。源空间放到本地内存,基本见不到方法区溢出。
小结:
1、分清什么是实例什么是对象。Class a = new class(); 此时a叫实例而不是对象。实例放在栈中,对象在堆中,操作实例实际上是通过实例的指针间接操作对象。多个实例可以指向同一个对象。
2、栈中的数据和堆中的数据销毁并不是同时销毁的。方法一旦结束,栈中的局部变量立即销毁。因为可能有其它变量也指向了这个对象,直到栈中没有变量指向堆中的对象时,它才销毁。
3、类的成员变量在不同对象中各不相同,都有自己的存储空间,而类的方法却是该类的所有对象共享的,只有一套,对象使用方法的时候方法才被压入栈,方法不使用则不占用内存。
4、生命周期:堆内存属于java应用程序所使用,生命周期与jvm一致,栈内存属于线程所私有的,它的生命周期与线程相同。
5、应用:不论任何时创建一个对象,他总是存储在堆内存空间,并且栈内存空间包含对它的引用。栈内存空间只包含方法、原始数据类型、局部变量以及堆空间中对象的引用变量。
6、在堆中的对象可以全局访问,栈内存空间属于线程私有
7、JVM栈内存结构较为简单,遵循LIFO的原则,堆空间管理较为复杂,细分为:新生代、老年代。。。
8、二者抛出异常的方式:如果线程请求的栈的深度大于虚拟机所允许的深度,将抛出StackOverflowError异常,堆内存抛出OutOfMemoryError异常。
二、内存分配
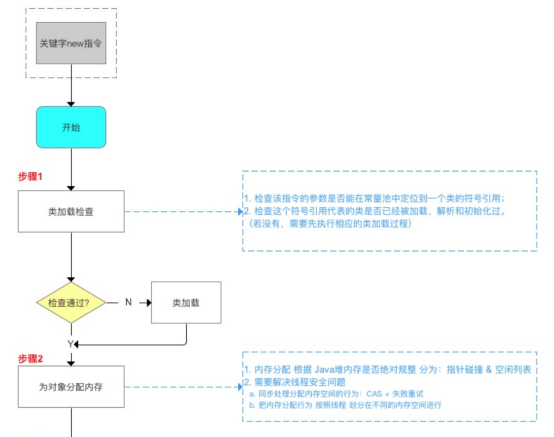
为对象分配 ,如果是复制算法采用指针碰撞,如果是标记清除发采用空闲列表



逃逸分析:分析java对象的动态作用域,当一个对象定以后,如果被其它方法和线程引用,称之为方法逃逸和线程逃逸,如果一个对象并没有逃逸出方法的话,那可能被优化成栈上分配,这样无需在堆上分配内存,也无需进行垃圾回收了。
三、对象头
1、HotSpot虚拟机中,对象在内存中存储的布局可以分为三块区域:对象头、实例数据和对齐补充。
New 一个字符串小王,占几个字节,1考虑编码;2、考虑对象头和对齐补充,对齐补充是补充为8的倍数
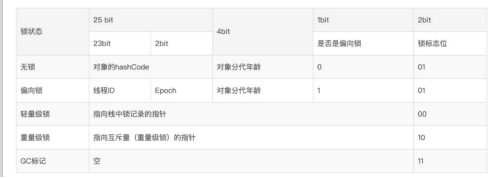
对象头包括两部分信息:第一部分用于存储对象自身的运行时的数据,如哈希码、GC分代年龄、锁状态标志、线程持有的锁、偏向线程ID、偏向时间戳等等
2、锁
偏向锁,代码没有加锁,是无锁的状态,如果加锁,先升级为偏向锁,偏向锁,就是保存一个ThreadId,如果ThreadId是空的,第一次获取锁的时候,将自身的线程id写入到锁的ThreadId,这样下次获取锁的时候,直接检查ThreadId是否和自身线程id一致,如果一致,则认为当前线程已经获取锁,因此不需要再次获取锁,略过了轻量级锁和重量级锁的加锁阶段。提高了效率。
偏向锁获取失败,升级为轻量级锁 CAS 轻量级锁获取失败,就升级为重量级锁,重量级锁是一个互斥的指针。
锁只能升级,不能降级
3、在Hotspot JVM中,32位机器下,Integer对象的大小是int的几倍?
Integer 只有一个int类型的成员变量value,所以数据部分的大小是4个字节,markword 4字节,指针4字节,然后后面补充4字节,所以占16字节。
四、jvm整体结构

1、类加载

1)加载
把class文件加载到内存中
2)连接
分为三步:
验证:验证被加载后的类是否有正确的结构,类数据是否符合虚拟机的要求,确保不会危害虚拟机的安全。
准备:为类的静态变量在方法区分配内存,并赋默认值0,静态常量在准备阶段就进行赋值。
解析:将类的二进制数据中的符号引用换为直接引用。
3)类的初始化
类的初始化是类加载的最后一步,除了加载阶段,用户可以通过自定义的类加载器参与,其它阶段都完全由虚拟机主导和控制。到了执行阶段才真正执行java代码。
初始化真正的赋值。
只有以下四种情况需要初始化:
① 使用new a创建的实例
② 通过java.long.reflect包的方法对类进行反射调用的时候,如果类没有初始化,要进行初始化
③ 当初始化一个类时,如果发现其父类没有进行初始化,则首选触发父类初始化。
④ 当虚拟机启动时,用户需要指定一个主类(包含main()方法的类),虚拟机会首选初始化这个类。
例子:只输出hello word ,不会输出上面一句话,是因为 静态常量在准备阶段已经赋值,不再进行初始化。

2、双亲委派
1)虚拟机有三种类型的加载器,引导类加载器、扩展类加载器、系统类加载器(应用类加载器);以及父类加载器为AppClassLoader的自定义加载器。虽然存在父子关系,但是区别于继承,它属于组合。子类加载器保存着父加载器的引用,当一个类加载器需要加载一个目标时,会委托父加载器去加载,然后父加载器在自己的加载路径中搜索目标类,父加载器在自己的目标范围内找不到时,才会交给子加载器加载目标类。


2)实现原理
LoadClass()是classLoder类自己实现的,该方法中的逻辑就是双亲委派实现的,顶层的类加载器是ClassLoader类,它是一个抽象类,除了启动类加载器外,都继承ClassLoader。
3)破坏双亲委派
①应用上下文类加载器
② loadclass
问题,it.jar重写怎么加载成功?这是加载不成功的,过不老安全校验
如果有两个a.class,这两个a.class加载到内存中一定是相等的吗?这不一定。
在JVM中表示两个class对象是否为同一个类对象存在两个必要条件
① 类的完整类名必须一致,包括包名
② 加载这个类的ClassLoder(指 ClassLoader实例对象)必须相同。
4)双亲委派的好出
① 主要是为了安全,避免用户自己编写的类动态替换java的一些核心类,比如string
② 避免了类的重复加载,因为jvm中区分不同类,不仅仅是根据类名,相同的class文件被不同的类加载器加载,就是两个不同的类
5)自定义类加载器
① 如果不想打破双亲委派模型,那就重写findClass方法即可
② 如果想打破双亲委派模型,那么就重写整个loadClass方法
6)双亲委派的破坏者---线程上下文类加载器(了解)
为什么破坏双亲委派: 引导类加载器,加载的是一些核心jar包,例如jdbc.Jar,加载不到,通过线程上下文类加载器加载jdbc.jar ,引导类加载器会看有没有加载好的jar
简而言之就是ContextClassLoader 默认存放了AppClassLoader的引用,由于她在运行时被放在了线程中,不管当前程序处在何处(BootstrapClassLoder 和ExtClassLoader等),在任何需要的时候都可以使用Thread.currentThread().getContextClassLoader()取出应用程序加载器来完成需要的操作。

3、Tomcat类加载器
1)Tomcat类加载器有没有破坏双亲委派
破坏了双亲委派
①部署在同一个Web容器上的两个web应用程序所使用的java类库实现相互隔离;
②部署在同一个Web容器上的两个Web应用程序所使用的的java类库可以相互共享。
③Web容器需要尽可能地保障自身的安全不受部署的web应用程序的影响。
通过contexclassLoder 在bootstrapclassloder加载一个webAppClassLoder,当你的Tomcat启动时,先判断webAppClassLoder有没有加载过,如果没有加载过,返回到bootstrapclassloder加载,如果bootstrapclassloder加载不到就在当前类加载,如果再加载不到调用common share加载器加载。
Web应用类加载器默认的加载顺序
总结:(1)先从缓存中加载
(2)如果没有,则从jvm的bootstrap类加载器加载;
(3)如果没有,则从当前类加载器加载(按着 WEB-INF/classes、WEB-INF/lib的顺序)
(4)如果没有,则从父类加载器加载,以加载顺序是 AppclassLoader、Common、Shared


