Generative Adversarial Nets(生成对抗网络)
生成对抗网络通过一个对抗步骤来估计生成模型,它同时训练两个模型:一个是获取数据分布的生成模型$G$,一个是估计样本来自训练数据而不是$G$的概率的判别模型$D$。$G$的训练步骤就是最大化$D$犯错的概率。这个框架对应于一个二元极小极大博弈。在任意函数$G$和$D$的空间中,存在唯一解,$G$恢复数据分布,$D$总是等于1/2。在$G$和$D$通过多层感知机定义的情况下,整个系统通过反向传播训练。在训练或者生成样本过程中,不需要任何马尔科夫链或者展开近似推理网络。通过对生成样本定性和定量分析,实验证明了框架的潜力。
3 对抗网络
当模型都是多层感知机时,对抗模型框架最直接应用。为了在数据$x$上学习生成器的分布$p_{g}$,在输入噪声变量$p_{z}(z)$上定义了一个先验,然后将数据空间的映射表示为$G(z;\Theta_{g})$,其中$G$是一个由多层感知机表示的可微函数,参数为$\Theta_{g}$。也定义了第二个多层感知器$D(x;\Theta_{d})$,其输出一个标量。$D(x)$表示$x$来自数据而不是$p_{g}$的概率。训练$D$以最大化为训练样本和来自$G$的样本分配准正确的标签的概率。同时训练$G$来最小化$log(1-D(G(z)))$。换句话说,$D$和$G$使用值函数$V(G,D)$来进行下面的二元极小极大博弈:
\begin{equation} \min \limits_{G} \max \limits_{D} V(D,G)=\mathbb{E}_{x \sim p_{data}(x)}[logD(x)]+\mathbb{E}_{z \sim p_{z}(z)}[log(1-D(G(z)))] \end{equation}
下节将提出对抗网络的理论分析,基本展示了训练准则允许人们恢复数据生成分布,因为$G$和$D$被赋予了足够的能力,也就是没有参数限制。有关方法不太正式,但是更具教学意义的解释,请参见图1。在实践中,必须使用一种迭代的数字化的方法实现游戏。在训练的内循环上优化$D$到完成在计算上是禁止的,并且有限的数据集将导致过拟合。相反,交替优化$D$k步和优化$G$1步。这将导致$D$保持在最优解附近,只要$G$足够缓慢地变化。该步骤在算法1中正式呈现。
在实践中,公式1不能为$G$提供足够的梯度来学好。在学习早期,$G$很糟糕,$D$可以以高可信度拒绝样本,因为它们和训练数据有明显的不同。在这种情况下,$log(1-D(G(z)))$是饱和的。可以最大化$logD(G(z))$来训练$G$,而不是最小化$log(1-D(G(z)))$。这个目标函数将导致$G$和$D$动力学的相同固定点,但是在学习早期提供更健壮的梯度。
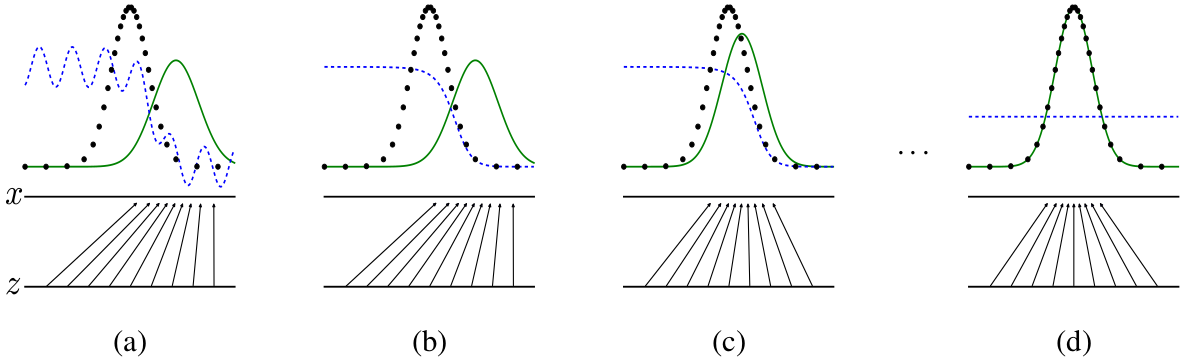
图1:同时更新判别分布(D,蓝虚线)来训练生成对抗网络,以便于能鉴别样本是来自数据分布$p_{x}$(黑点线)还是生成的分布$p_{g}(G)$(绿实线)。向上的箭头展示了映射$x=G(z)$如何在转化样本上强加非均匀分布$p_{g}$。$G$在高密度区域收缩,在低密度区域扩展。(a)视为一个对抗趋于收敛:$p_{g}$相似于$p_{data}$,并且$D$是一个部分准确的分类器。(b)在算法的内环,训练$D$以从数据中区分样本,收敛到$D^*(x)=\frac{p_{data}(x)}{p_{data}(x)+p_{g}(x)}$。(c)在更新$G$之后,$D$的梯度会引导$G(z)$更倾向于将输入分类为数据。(d)训练几步之后,如果$G$和$D$有足够的容量,它们都达到一个不能再改善的点,因为$p_{g}=p_{data}$。判别器不能区分两个分布,即$D(x)=\frac{1}{2}$。

4 理论结果
生成器$G$隐含地将概率分布$p_{g}$定义为当$z \sim p_{z}$时获得的样本$G(z)$的分布。因此,如果给定足够的容量和训练时间,想要算法1收敛成$p_{data}$的好估计器。这部分的结果是在非参数设置中得到,例如,通过研究概率密度函数空间的收敛来表示具有无限容量的模型。
4.1节将展示这个二元极小极大博弈有个最优解$p_{g}=p_{data}$。然后在4.2节展示算法1优化公式1,从而获得所需结果。
4.1 $p_{g}=p_{data}$的全局优化
首先考虑给定任意生成器$G$的最佳判别器$D$。
命题 1。对于固定的$G$,最佳判别器$D$是
\begin{equation} D^{*}_{G}(x)=\frac{p_{data}(x)}{p_{data}(x)+p_{g}(x)} \end{equation}
证明。判别器$D$的训练准则是,给定任意生成器$G$,最大化$V(G,D)$
\begin{equation}\begin{aligned} V(G,D) &= \int_{x}p_{data}(x)log(D(x))dx+\int_{z}p_{z}(z)log(1-D(g(z)))dz \\ &= \int_{x}p_{data}(x)log(D(x))+p_{g}(x)log(1-D(x))dx \end{aligned}\end{equation}
对于任意$(a,b) \in \mathbb{R^2} \setminus \{0,0\}$,函数$y \to alog(y)+blog(1-y)$在$[0,1]$的$\frac{a}{a+b}$处得到最大值。判别器不需要在$Supp(p_{data})∪Supp(p_{g})$之外定义,证明结束。
注意$D$的训练目标可以解释为最大化条件概率$P(Y=y|x)$的似然,其中$Y$表明$x$来自$p_{data}$($y=1$),还是来自$p_{g}$($y=0$)。公式1的极小极大博弈现在可以重新表述为:
\begin{equation}\begin{aligned} C(G) &= \max \limits_{D} V(G,D) \\ &= \mathbb{E}_{x \sim p_{data}}[logD^*_{G}(x)] + \mathbb{E}_{z \sim p_{z}}[log(1-D^*_{G}(G(z)))] \\ &= \mathbb{E}_{x \sim p_{data}}[logD^*_{G}(x)] + \mathbb{E}_{x \sim p_{g}}[log(1-D^*_{G}(x))] \\ &= \mathbb{E}_{x \sim p_{data}}[log \frac{p_{data}(x)}{p_{data}(x)+p_{g}(x)}] + \mathbb{E}_{x \sim p_{g}}[log \frac{p_{g}(x)}{p_{data}(x)+p_{g}(x)}] \end{aligned}\end{equation}
定理1。当且仅当$p_{g}=p_{data}$时,实现实际训练准则$C(G)$的全局最小。在这个点,$C(G)$的值为$-log4$。
证明。对于$p_{g}=p_{data}$,$D^*_{G}(x)=\frac{1}{2}$。因此,通过在$G^*_{G}(x)=\frac{1}{2}$观察公式4,发现$C(G)=log \frac{1}{2}+log \frac{1}{2}=-log4$...
4.2 算法1的收敛
命题2。如果$G$和$D$有足够容量,并且在算法的每一步,允许判别器到达给定$G$的最优,以及更新$p_{g}$以便改善以下准则:
\begin{equation} \mathbb{E}_{x \sim p_{data}}[logD^*_{G}(x)] + \mathbb{E}_{x \sim p_{g}}[log(1-D^*_{G}(x))] \end{equation}
然后$p_{G}$收敛到$p_{data}$
在实践中,对抗网络通过函数$G(x;\Theta_{g})$表示一组有限的$p_{g}$分布,并且优化$\Theta_{g}$而不是$p_{g}$本身,因此证明不可用。然而,多层感知机在实践中杰出的性能表明,尽管缺少理论保证它们仍然是一个合理的模型。
5 实验
在一个广泛的数据集上训练对抗网络,包括MNIST,the Toronto Face Database(TFD)和CIFAR-10。生成器混合使用rectifier linear activations和sigmoid激活函数,而判别器使用maxout激活。在训练判别器的时候使用了Dropout。虽然理论框架允许在生成器的中间层使用dropout和其它噪声,但是噪声仅仅作为生成器最低层的输入。

表1:基于Parzen窗口的log似然估计。在MNIST上报告的数字是测试上样本的平均对数似然,和在示例中计算的平均值的标准差。
通过拟合一个高斯Prazen窗口到由$G$生成样本和报告在这个分布下的似然概率,来估计测试集的概率。通过验证集上的交叉验证获得$\sigma$参数。结果如表1所示。这个估计似然的方法有点高方差,并且在高维空间性能不好,但是就我们所知它仍然是最好的方法。可以采样但不能直接估计似然的生成模型的进步直接激发了如何评估此类模型的进一步研究。图2和3展示了训练之后生成器画出的样本。尽管没有宣称这些样本比其它现有模型生成的更好,但是相信这些样本至少与文献中最好的生成模型相当,并且对抗模型更具有潜力。

图2:模型中样本的可视化。最右边的列显示了最近的相邻样本的训练示例,以证明没有记住训练集。样本是随机生成,没有挑选。不想大多数其它深度生成模型的可视化,这些图像展示了模型分布真是样本 ,非条件意味着给定的隐藏单元样本。此外,这些样本是不相关的,因为采样过程不要求马尔科夫链。a)MNIST b)CIFAR-10(全连接模型) d)CIFAR-10(卷积判别器和解卷积生成器) 
图3:通过在完整模型的$z$空间的坐标之间线性插值获得的数字
6 优点和缺点
这个框架和先前的模型相比有优点也有缺点。缺点主要在于$p_{g}(x)$没有明确表示,并且在$G$训练期间$D$必须很好地同步(尤其,没有更新$D$的时候,$G$一定不能训练的太多,防止“the Helvetica scenario”即$G$将太多的z值折叠到x来有足够的多样性来模拟$p_{data}$),正如一个玻尔兹曼机的负链必须在学习步骤之间保持最新。优点是不需要马尔科夫链,仅仅使用反向传播获得梯度,在学习期间也不需要推理,并且将多种函数合并到模型。表2总结了生成对抗网络和其它生成模型的比较。
上述优点主要是计算。对抗模型也从生成网络获得一些统计优势,不是直接使用数据示例更新, 而是流经判别器的梯度。这意味着输入的组件不是直接复制到生成器的参数。另一个对抗网路的优点是它们可以表示非常清晰甚至退化的分布,而基于马尔科夫链的方法要求分布有点模糊以便链能够在模式之间混合。
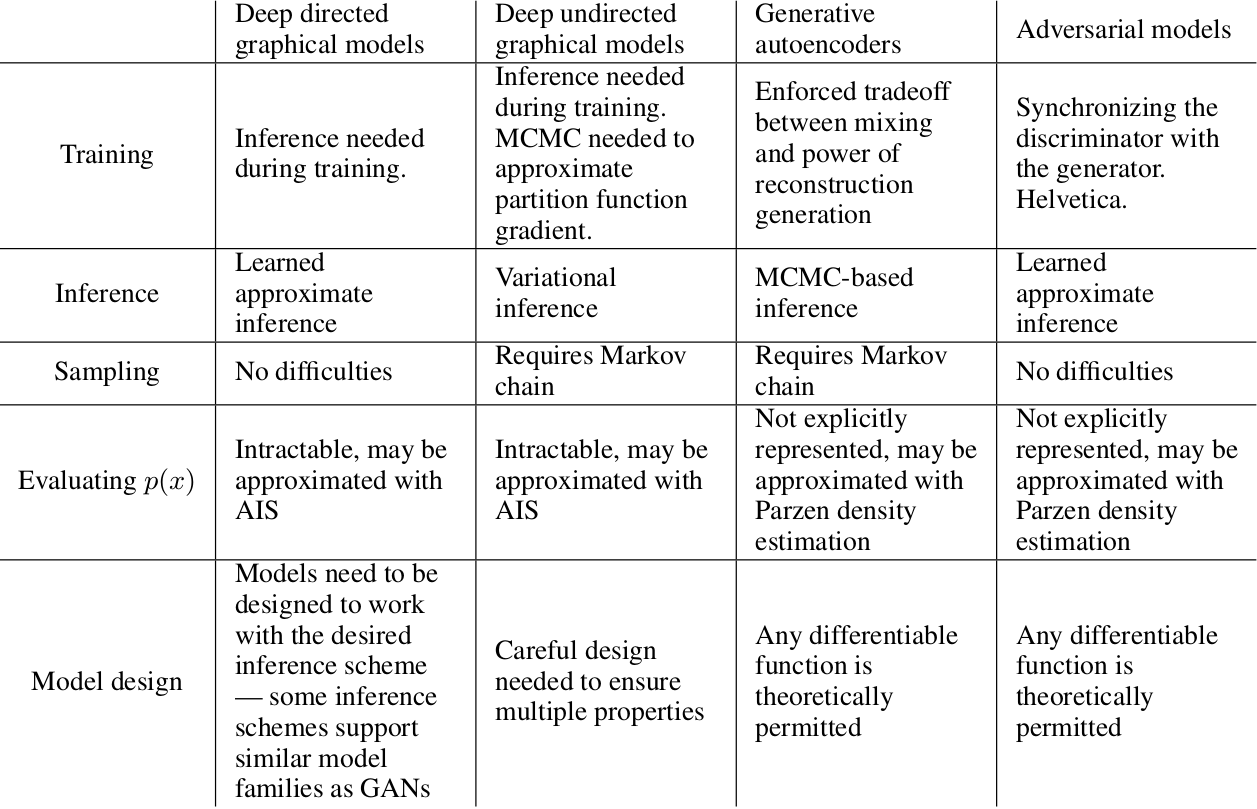
表2:生成建模中的挑战:总结了涉及模型每个主要操作的深度生成建模的不同方法遇到的困难。
7 总结和未来的工作
这个框架允许许多直接的扩展:
1. 通过将$c$添加到$C$和$D$的输入获得一个条件生成模型$p(x|c)$
2. 可以通过训练一个辅助网络来预测给定$x$的$z$,来进行可学习的近似推断。这类似于由wake-sleep算法训练的推理网络,但具有以下优点:在生成器网络完成训练之后,针对固定的生成器可以训练一个推理网络。
3. 通过训练一组共享参数的条件模型,可以近似地共享所有条件$p(x_{s}|x_{slashed{D}})$,其中$S$是$x$索引的子集。从本质上说,可以使用对抗网络来实现确定性MP-DBM的随机扩展。
4. 半监督学习:当有限的标签可用时,判别器的特征或者推理网络可以改善分类器的性能。
5. 效率改善:通过设计更好的方法来协调$G$和$D$或者在训练期间更好地分配样本$z$可以加速训练。
二元博弈的特点是什么?
两个具有互斥性的优化目标或任务,在博弈的过程中,保持一方不变优化另一方,如此交替,动态优化自身共同进步。两个目标分别给对方提供一把“尺”作为衡量,博弈过程中,“尺”会越来越严格,以此形成反馈,最终实现两者最优。
互斥性体现在哪?
两个目标相反,必定是若一方强,则另一方弱。不可能在优化过程中始终保持一强一弱,这样强的一方就无法得到反馈,从而优化自己,所以是交替强弱。若一方强一方弱,则是一方始终在追赶另一方。
极限/最优的判断?
生成对抗网络的极限在于,生成器生成了和真图一样的假图,使得判别器对于无论来自自然图像还是生成图像的输出都为1/2。?

 浙公网安备 33010602011771号
浙公网安备 33010602011771号