Faster R-CNN(RPN)
最先进的目标检测网络依赖于区域生成算法来假设目标位置。先前的SPPnet和Fast R-CNN都已经减少了检测网络的运行时间,但也暴露出区域建议计算是个瓶颈。这篇文章,引出一个区域生成网络(RPN)和检测网络共享全图的卷积特征,因此使得区域建议几乎没有任何开销。RPN是一个在每一个位置同时预测目标边界和目标分数的全卷积网络。通过端到端的训练RPN来生成高质量的区域建议来提供给Fast R-CNN作检测使用。通过简单的交替优化,RPN和Fast R-CNN可以共享特征训练。
区域建议网络
RPN输入一个任意尺寸的图像,并且输出一组矩形目标建议,每一个都带有一个目标分数。对这个过程使用全卷积网络进行建模。因为最终的目标是和Fast R-CNN目标检测网络共享计算,所有假设两个网络都共享一组普通的卷积层。实验中,调研了ZF(5层共享卷积)和VGG模型(13层共享卷积)。
为了生成区域建议,在最后的共享卷积层的卷积特征图输出上滑动一个小网络。这个网络被完全连接(注意,不是全连接)到输入卷积特征图的$n×n$空间窗口上。每个滑动窗口映射成一个低维的向量(256-d for ZF and 512-d for VGG)(这里的意思是,使用256或512个卷积核生成与被卷积特征图同样大的特征图,只不过深度为256或者512)。这个向量被送到两个同胞全连接层——边框回归层(reg)和边框分类层(cls)。这里使用$n=3$,注意到输入图像的有效接受域是很大的(对于ZF和VGG来说分别是171和228)。在单个位置上解释迷你版的网络(图1左)。注意因为迷你网络以一种滑窗的方式操作,所以跨越所有空间位置。这个结构自然而然地通过一个$n×n$的卷积层实现,其后还跟着两个同胞般的1x1卷积层(分别用于回归和分类)。$n×n$卷积层的输出使用ReLU。
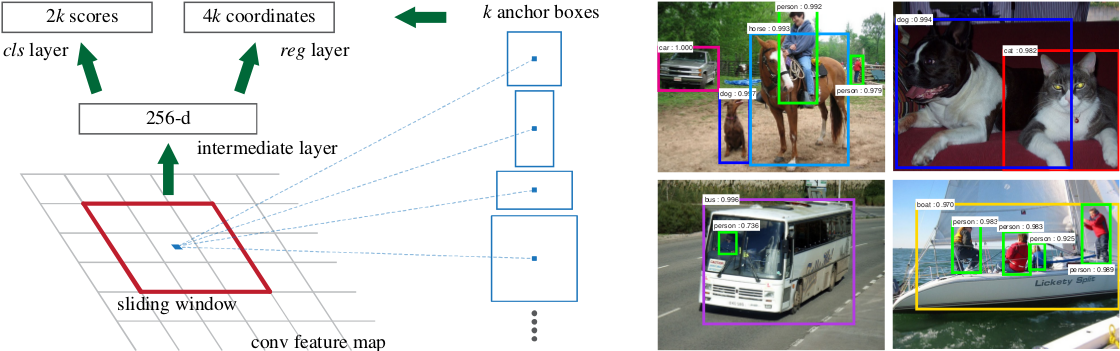
图1:左:区域建议网络(RPN)。右:在PASCAL VOC 2007测试上用RPN建议的样本检测。该方法可以在大范围的尺度和纵横比上检测目标。
Translation-Invariant Anchors
在每一个滑窗位置,同时预测$k$个区域建议,因此$reg$层有$4k$个输出编码$k$个边框坐标。$cls$层输出$2k$个分数来估计每个建议的目标/非目标的概率。$k$个建议相对于$k$个称为锚点的参考框参数化。每个锚点在滑窗的中心,并且与尺度和纵横比相关。这里使用3个尺度和3个纵横比,在每个滑动位置上生成$k=9$个锚点。对于一个尺寸为$W×H$的卷积特征图(约2400),总共有$W×H×k$个锚点。这个方法的一个重要属性是,就锚点和与锚点相关的计算建议框函数而言,具有平移不变性。
相比而言,MultiBox method使用k-means来生成800个锚点,那不具有平移不变性。如果在一张图像中平移一个目标,则建议框也应该平移,并且同样能在每个位置上预测建议框。此外,因为MultiBox锚点不具有平移不变性,所有它要求一个(4+1)×800维的输出层,而这篇论文的方法是一个(4+2)×9维的输出层。这里的建议层有一个数量级的参数减少(使用GoogLeNet 的MultiBox有27百万,而使用VGG-16的RPN有2.4百万),因此在想PASCAL VOC这样的小数据集上有更少拟合的风险。
A Loss Function for Learning Region Proposals
对于训练RPN来说,为每一个锚点分配一个二元类标签(是目标或不是)。为两种锚点分配一个正标签:(i)与真值框有最高IoU的锚点,(ii)与任何真值框有超过0.7的IoU。注意一个真值框可以将正标签分配给多个锚点。如果锚点与所有真值框的IoU比例小于0.3,则赋给它一个负标签。既不是正或也不是负的锚点没有给训练目标做任何贡献。
根据这些定义,参照Fast R-CNN中的多任务损失最小化目标函数。一张图像的损失函数定义为:
$L(\{p_{i}\},\{t_{i}\})=\frac{1}{N_{cls}}\sum_{i}L_{cls}(p_{i},p_{i}^*)+λ\frac{1}{N_{reg}}\sum_{i}p_{i}^*L_{reg}(t_{i},t_{i}^*)$. (1)
这里的$i$在一个批量中一个锚点的索引,$p_{i}$是锚点$i$是一个目标的概率。如果锚点是正的,标签$p_{i}^{*}$是1,如果是负的则为0。$t_{i}$是代表边框坐标4个参数的向量,$t_{i}^{*}$是与正锚点相关的真值。$p_{i}^{*}$用于只计算正锚点框损失,不计算负的。
RPN代码示例
def rpn_graph(feature_map, anchors_per_location, anchor_stride): """Builds the computation graph of Region Proposal Network. feature_map: backbone features [batch, height, width, depth] anchors_per_location: number of anchors per pixel in the feature map anchor_stride: Controls the density of anchors. Typically 1 (anchors for every pixel in the feature map), or 2 (every other pixel). Returns: rpn_logits: [batch, H, W, 2] Anchor classifier logits (before softmax) rpn_probs: [batch, H, W, 2] Anchor classifier probabilities. rpn_bbox: [batch, H, W, (dy, dx, log(dh), log(dw))] Deltas to be applied to anchors. """ # TODO: check if stride of 2 causes alignment issues if the feature map # is not even. # Shared convolutional base of the RPN shared = KL.Conv2D(512, (3, 3), padding='same', activation='relu', strides=anchor_stride, name='rpn_conv_shared')(feature_map) # Anchor Score. [batch, height, width, anchors per location * 2]. x = KL.Conv2D(2 * anchors_per_location, (1, 1), padding='valid', activation='linear', name='rpn_class_raw')(shared) # Reshape to [batch, anchors, 2] rpn_class_logits = KL.Lambda( lambda t: tf.reshape(t, [tf.shape(t)[0], -1, 2]))(x) # Softmax on last dimension of BG/FG. rpn_probs = KL.Activation( "softmax", name="rpn_class_xxx")(rpn_class_logits) # Bounding box refinement. [batch, H, W, anchors per location, depth] # where depth is [x, y, log(w), log(h)] x = KL.Conv2D(anchors_per_location * 4, (1, 1), padding="valid", activation='linear', name='rpn_bbox_pred')(shared) # Reshape to [batch, anchors, 4] rpn_bbox = KL.Lambda(lambda t: tf.reshape(t, [tf.shape(t)[0], -1, 4]))(x) return [rpn_class_logits, rpn_probs, rpn_bbox]

 浙公网安备 33010602011771号
浙公网安备 33010602011771号