04.卷积神经网络_第一周卷积神经网络
1.1 计算机视觉
上面这张图是64x64像素的图像,它的数据量是12288,下图是1000x1000像素的图像,它的数据量是3百万。如果用全连接网络去处理这张图片,输入是一个维度为3百万的向量,如果隐藏层有1000个神经元,则第一层的权重是一个(1000,3百万)的矩阵,有30亿个参数。这是一个非常大的数字,在参数量如此巨大的情况下,难以获得足够的数据来防止过拟合。并且一个拥有这么多参数的神经网络需要的内存量是让人难以接受的。为了处理大尺寸图像,可以使用卷积运算。
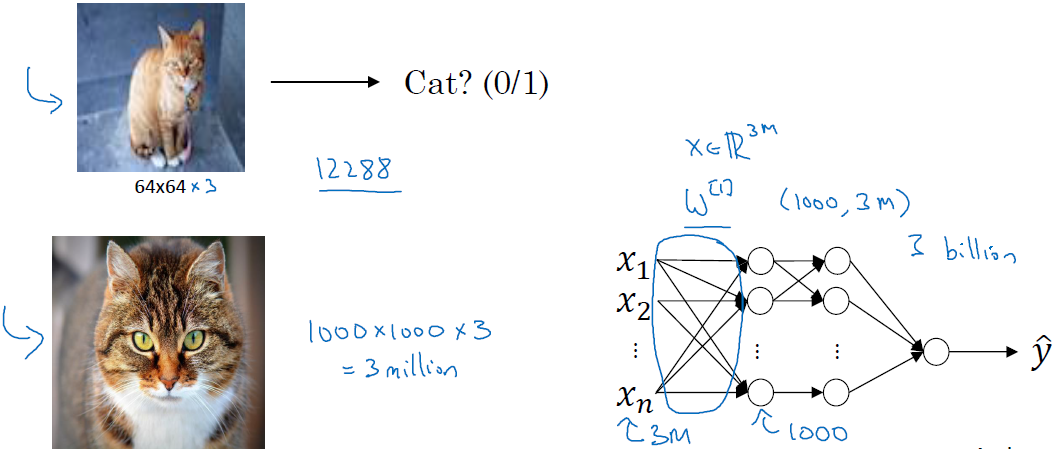
1.2 边缘检测
一个神经网络的前几层能检测到物体的边缘,后面几层可以检测到物体的部分,最后几层可以检测物体的整体。一张图像的边缘如何检测?通过垂直检测器可以检测到垂直边缘,水平检测器可以检测到水平边缘。
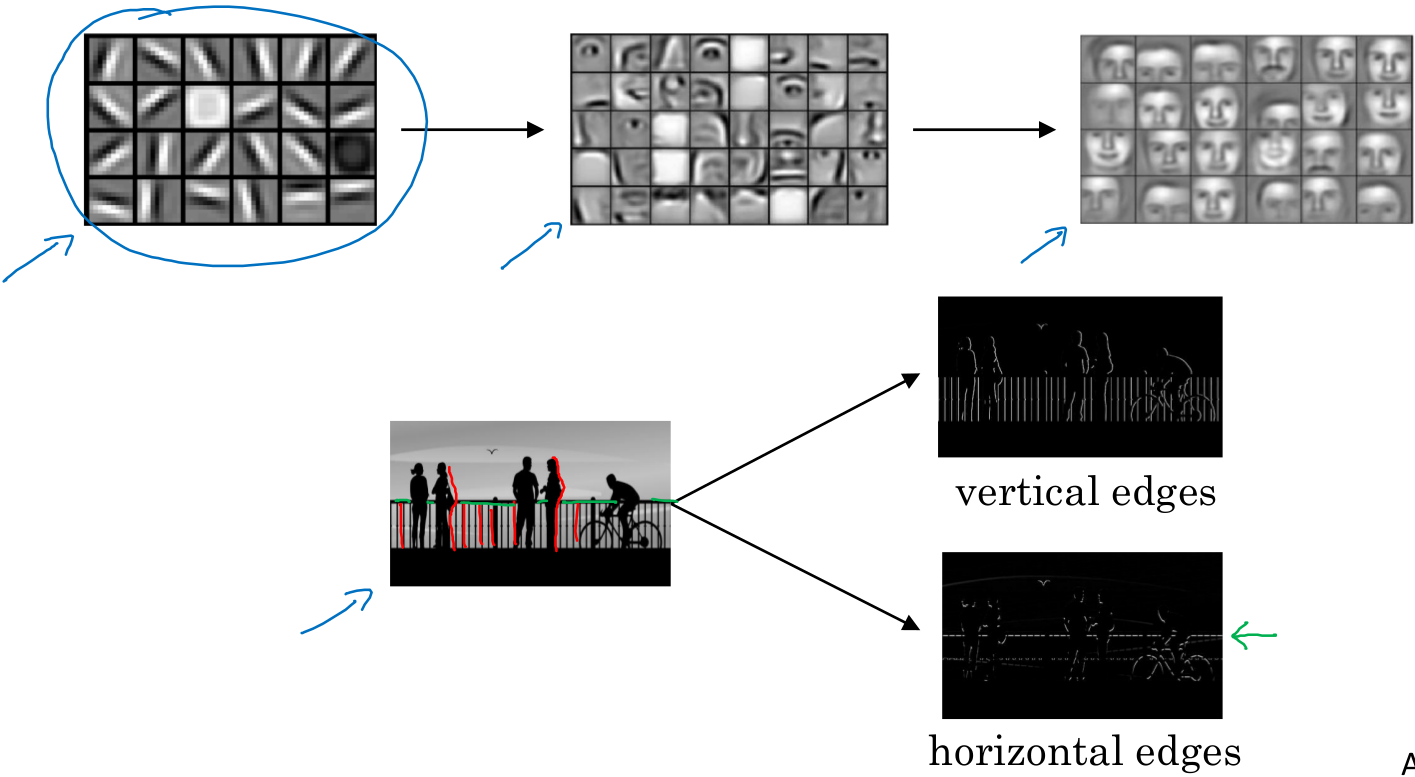
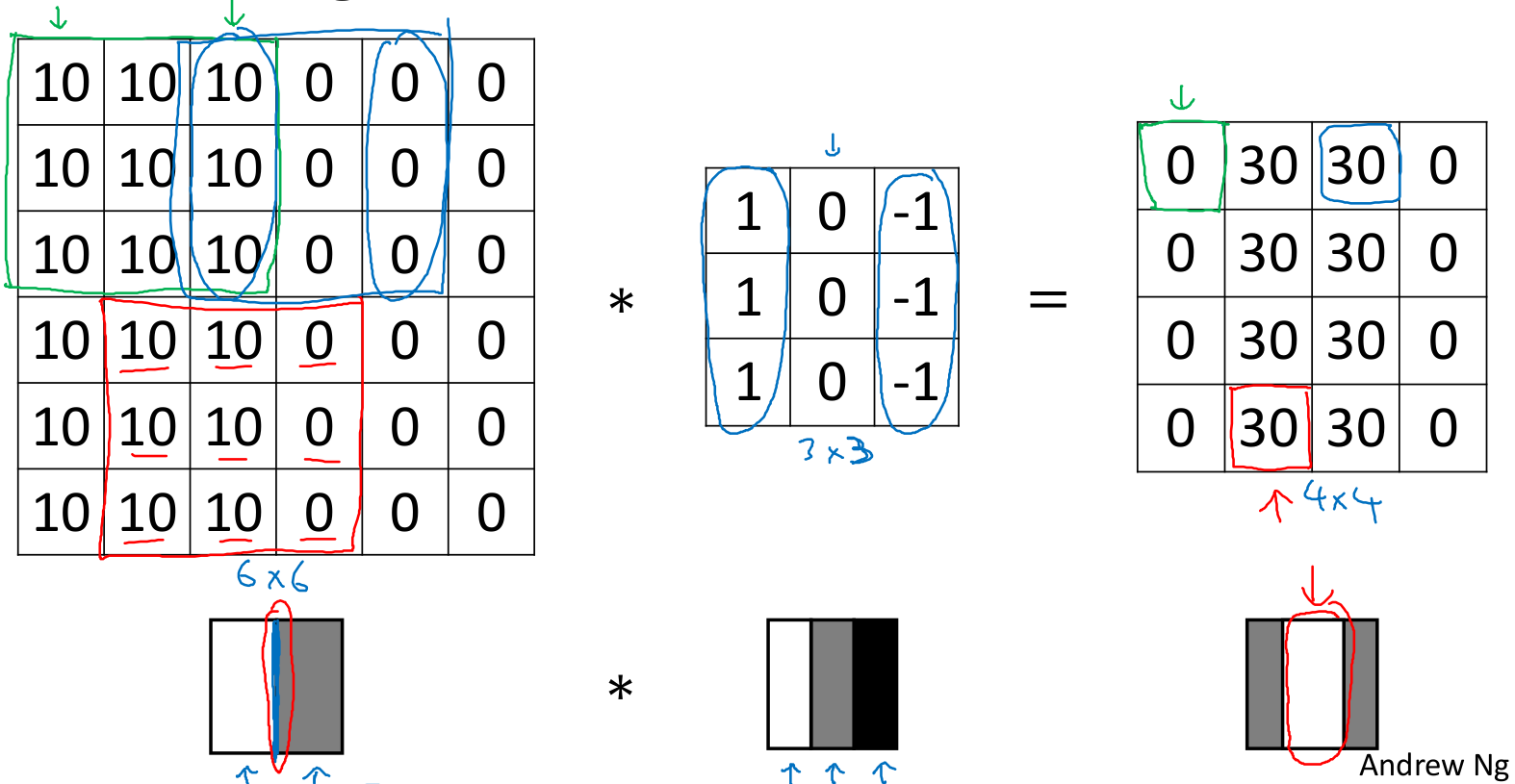
为了检测图像中的垂直边缘,可以通过一个3x3的矩阵,这里称为滤波器(filter),也有些论文称为核(kernel)。使用滤波器对图像进行卷积可以得到边缘。原始图像中有个明显的边缘,在检测结果的中间有个较粗的边缘,因为原始图像较小,如果是1000x1000的图像,则可以检测到很好的边缘信息。卷积运算提供了一种简单的方法来检测边缘。
1.3 更多边缘检测内容
还是上节的例子,图像左边亮右边暗,如果将图像进行颜色翻转,滤波器不变,就会得到不一样的结果。这样一个特定的滤波器可以检测到图像亮度从亮到暗和从暗到亮的变化。
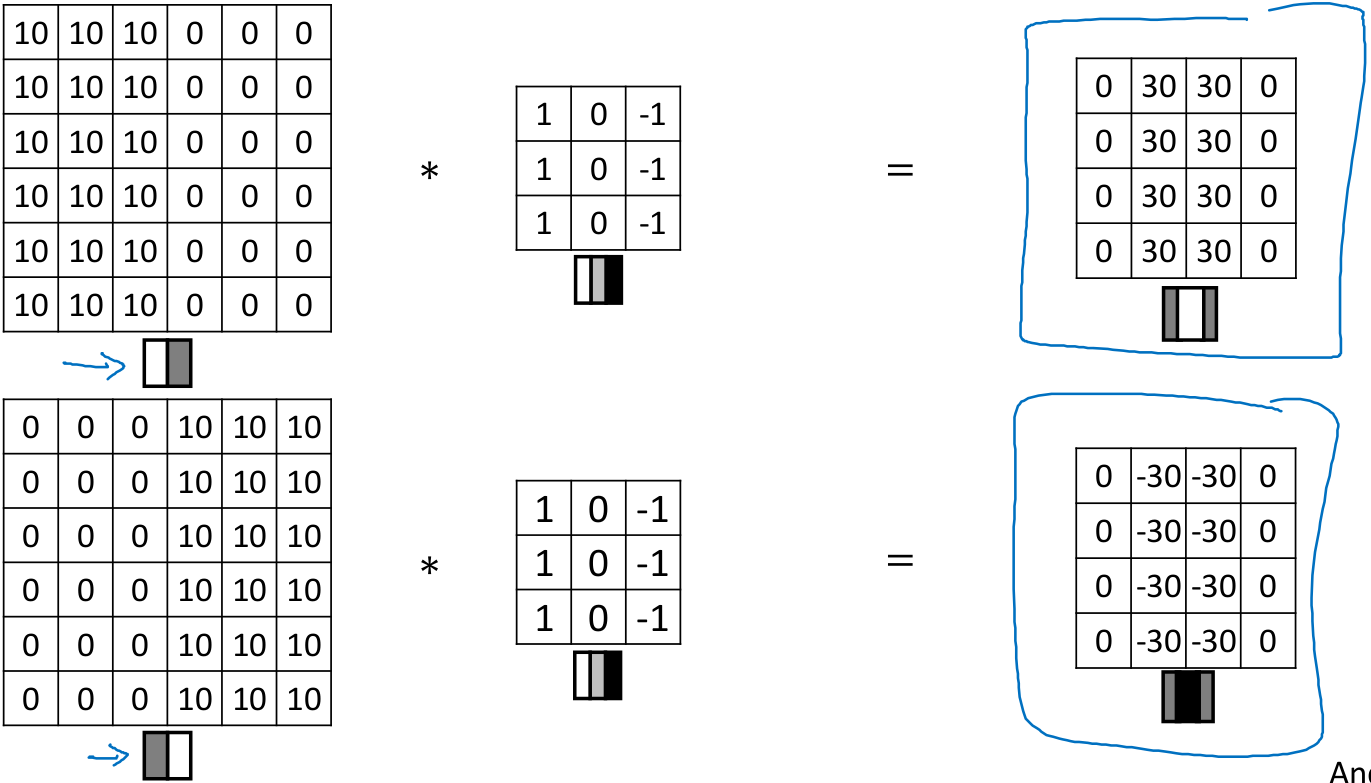
再看看水平边缘检测,检测结果中30和-30分别表明检测到了由亮到暗和由暗到亮的边缘。因为这里的图像较小(6x6),所以其中的过渡带10和-10就很明显,如果是1000x1000的大图,这样的过渡带相对图像尺寸就微不足道了。
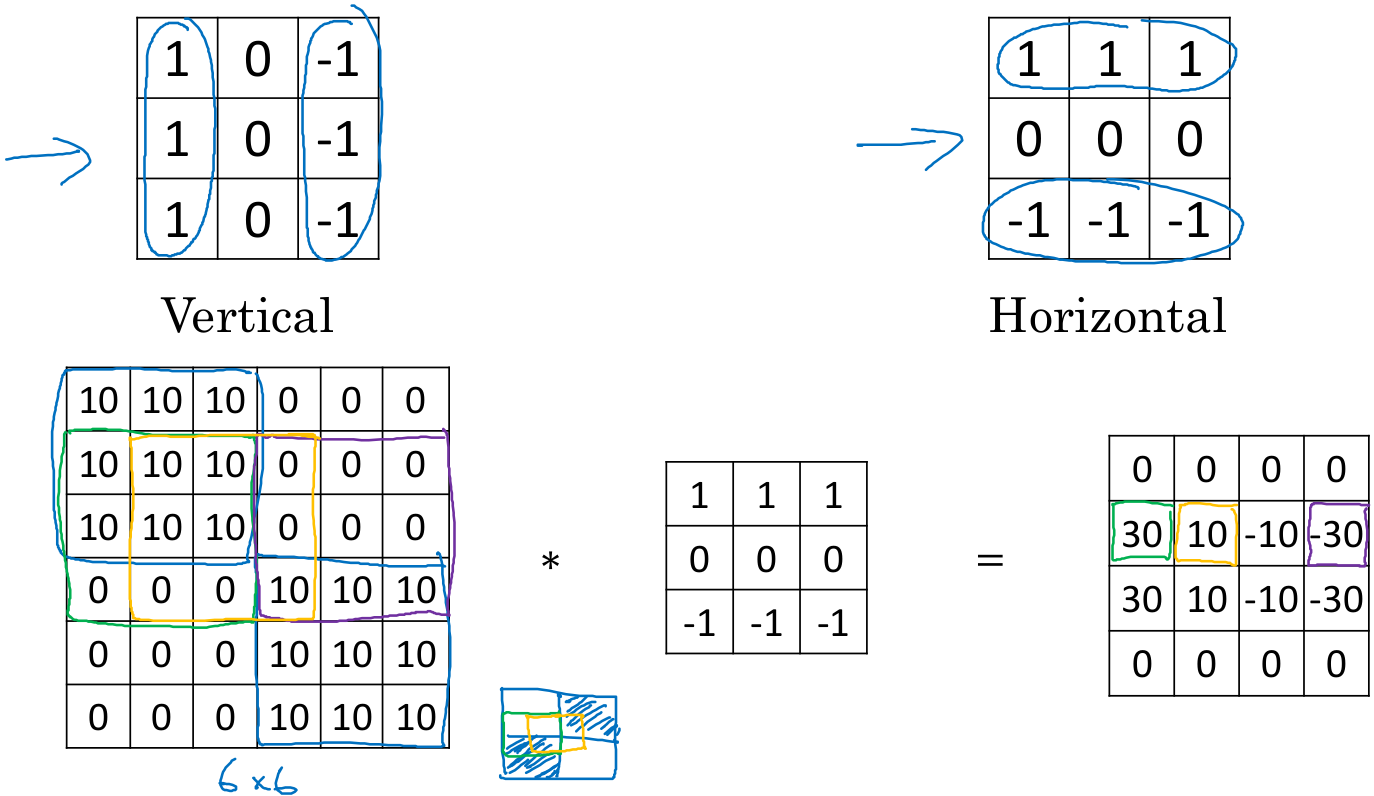
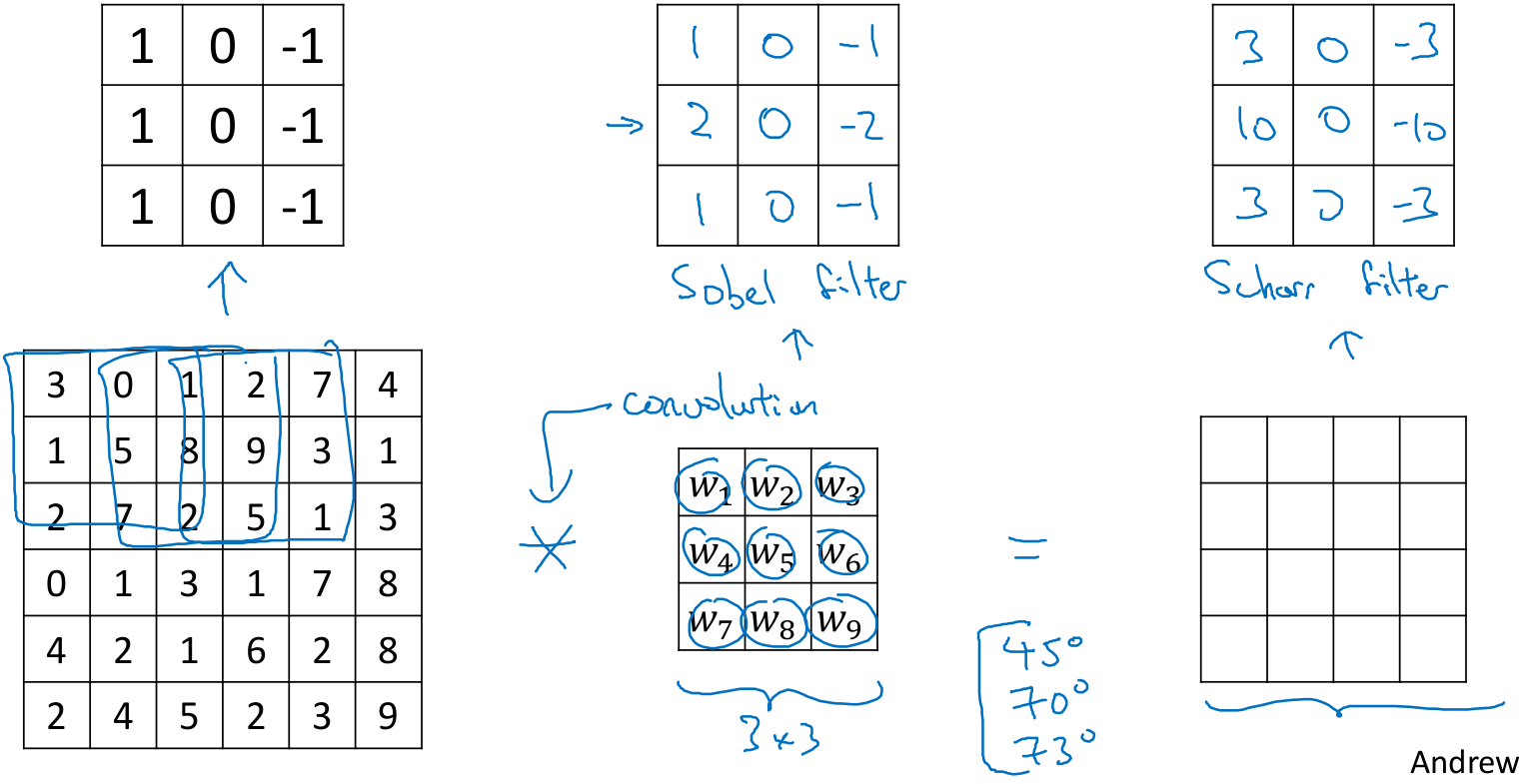
上面使用滤波器只是一种数字组合,在计算机视觉发展中曾公开讨论过哪种数字组合最好,如sobel滤波器、scharr滤波器。这里将滤波器中的数字设为参数,通过反向传播的算法去学习这些参数,不仅可以学习到垂直边缘滤波器、水平边缘滤波器,还可以检测许多特殊的角度(45°,70°,73°等),甚至没有名字的滤波器。
1.4 Padding
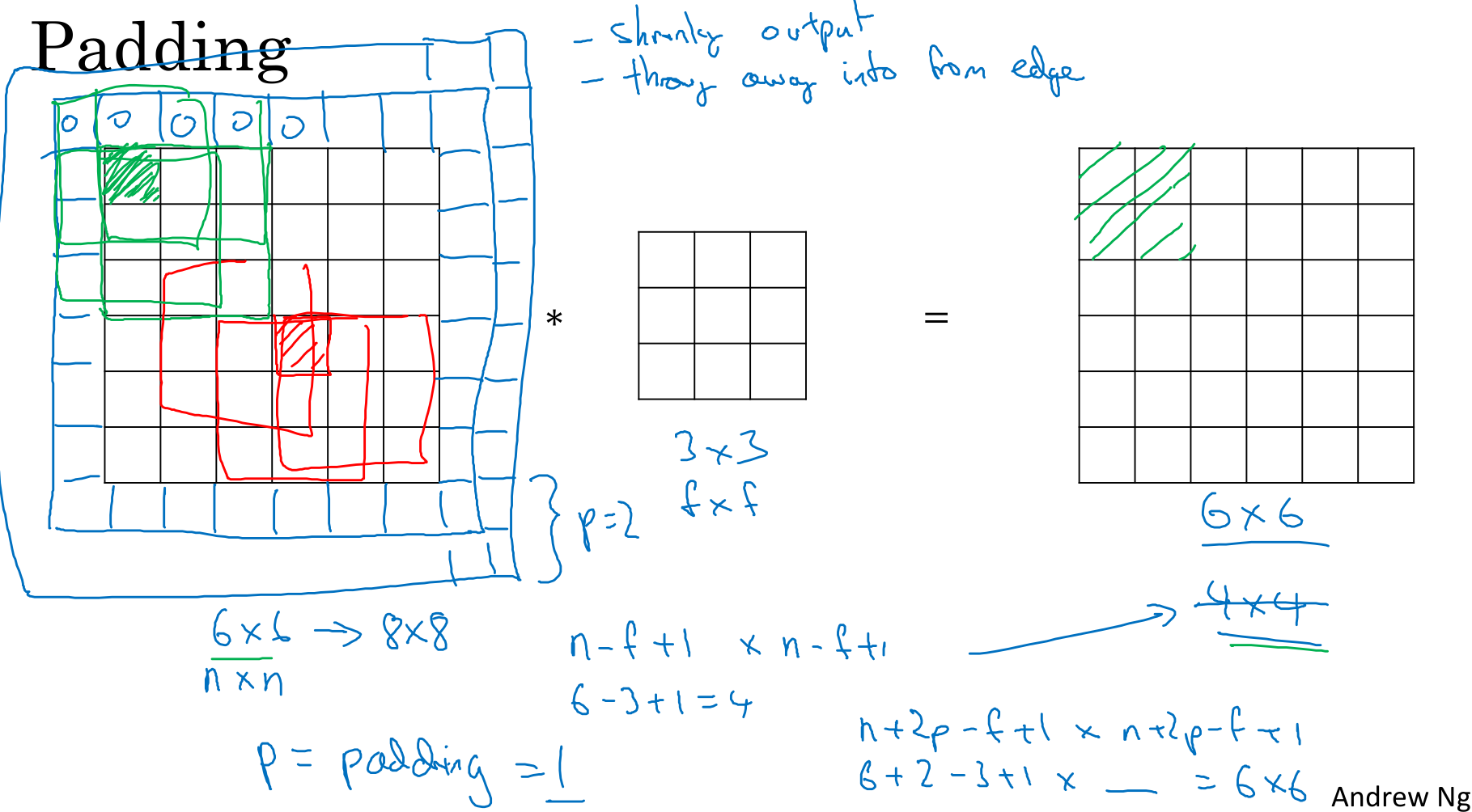
前文所述,用fxf的滤波器对nxn的图像进行卷积,就会产生一个(n-f+1)x(n-f+1)的结果,所以上面得到一个4x4的结果。这样有两个缺点,一是每次卷积后图像就会缩小,经过几层后可能会变成1x1,ResNet有100多层,这样肯定不行。二是角落处的点只会被滤波器“触碰”到一次,而中间的点就会被“触碰”多次,这会导致角落或者边缘的点在输出中采样较少,因而导致失去边缘信息。为了解决这个问题,可以在卷积前填充图像,习惯用0填充。设填充为p,输出为(n+2p-f+1)x(n+2p-f+1)。至于选择多少像素填充,这里有两种卷积方式,valid和same。valid意味着不填充,same意思是填充后输出大小和输入一样。对于same来说,就是n+2p-f+1=n,因此p=(f-1)/2。习惯上,计算机视觉中滤波器都是奇数,比如3x3,5x5,7x7,很少看到偶数,因为偶数会造成不对称填充,其次是,奇数滤波器有一个中心,有时候需要指出滤波器的位置。不过,这些都不是使用奇数滤波器的充分原因,但是大部分论文中都使用奇数滤波器。
1.5 卷积步长
卷积中的步幅设置是一个基本操作,如下图所示,结果向下取整。

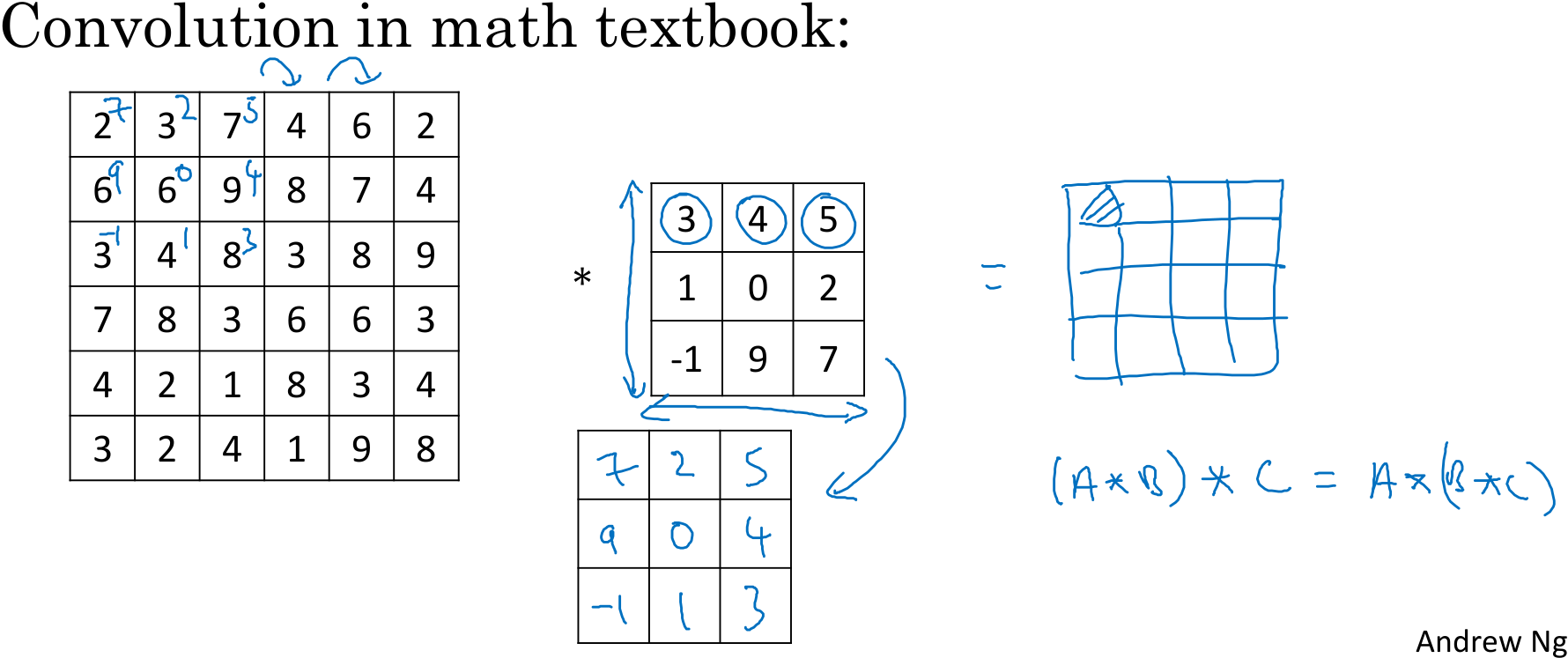
在数学领域,这里的卷积叫做互相关(cross-correlation),把这里的卷积在元素乘积和求和前对滤波器进行翻转才叫做卷积。而在深度学习领域,重新定义了卷积。
1.6 卷积为何有效
如果不仅想检测灰度图像,也想检测彩色图像,这里使用3x3x3的立体滤波器对RGB图像进行检测,其中滤波器最后的3对应RGB的3,如下所示输出4x4的结果。如果想使用多个滤波器来检测不同的特征,就会输出多个叠加的结果,如下图结果中的2所示。
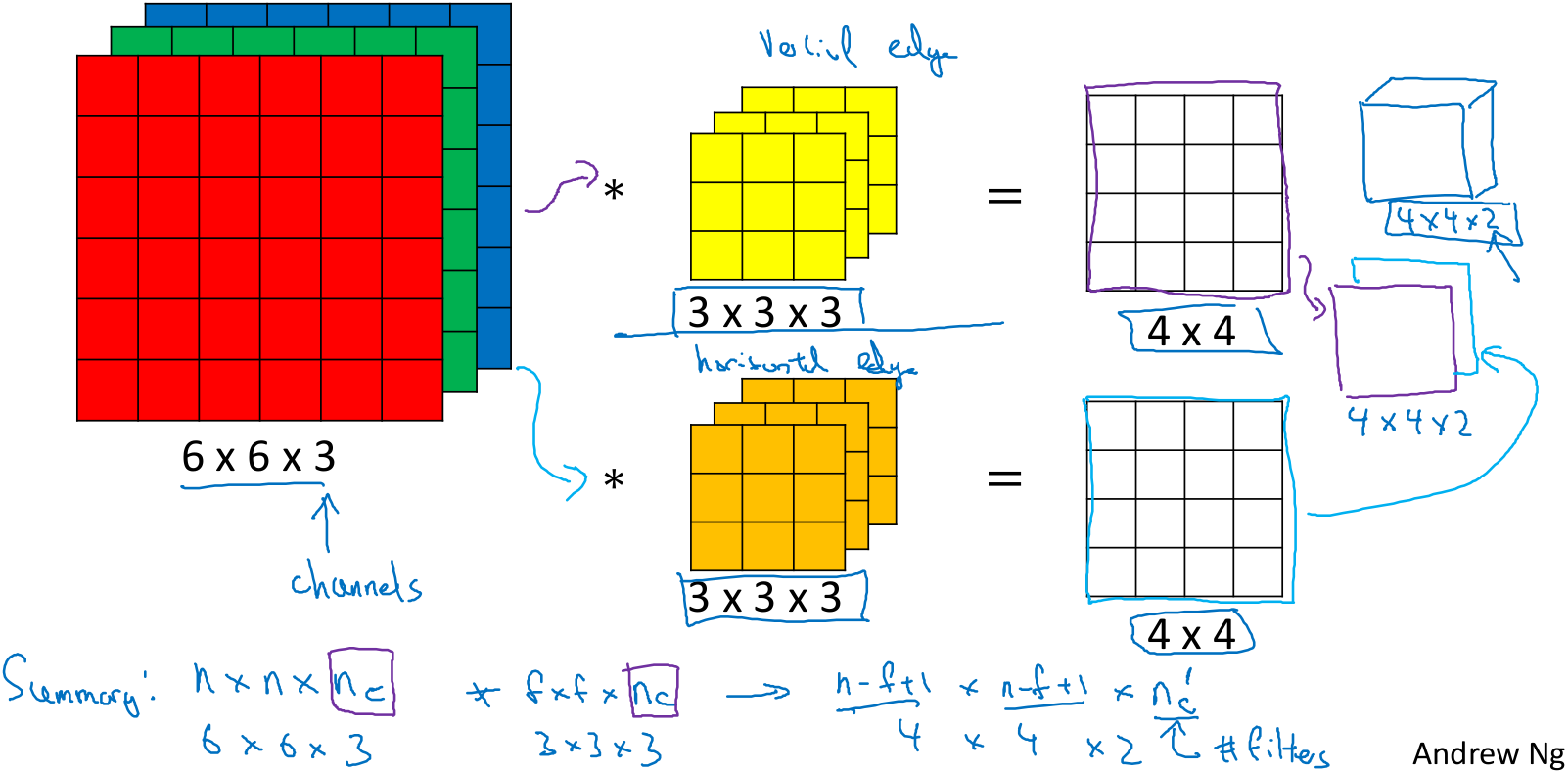
1.7 单层卷积神经网络
一个卷积层可以通过上节所述并在其结果上,针对每个特征图加上一个偏置b,然后在使用ReLU激活函数得到卷积层的输出。卷积层有个特点,假如上述的卷积层有10个滤波器,则参数为(3x3x3+1)x10=280个,但是不论图像有多大,参数始终是280个,用这10个滤波器提取特征,如垂直边缘、水平边缘和其它特征,即使这些图片很大,参数却很少。这是卷积网络的一个特性,可以避免过拟合。

1.8 简单卷积网络示例
一个典型的卷积网络是由卷积层、池化层、全连接层组成,当然完全由卷积层组成也可以。原始输入的图像较大,经过一层又一层之后会变小,但是通道数在增加。最后的特征图拉成一个向量送入全连接,随后再使用softmax进行分类。

1.9 池化层
卷积网络除了使用卷积层,也使用池化层来缩减模型的大小、提高计算速度,同时提高所提取特征的鲁棒性。池化有最大池化和平均池化两种,如下图所示,就是将原图分成很多块区域,然后将对应区域求最大值或平均得到输出。对于最大池化来说,可以把这个4x4的输入看作是某些特征的集合,数字大意味着可能提取了某些特定特征。最大化运算的实际作用就是如果在过滤器中提取到某个特征,那么保留其最大值(如左上角),如果没有提取到某个特征,其中最大值也还是很小(如右上角),这就是最大池化的直观理解。人们用最大池化的主要原因是,此法在很多实验中效果都很好。尽管刚刚的直观理解经常被引用,但是不知道大家是否真的了解了它的真正原因,这可能都是推测。它有一组超参数并不需要学习,一定确定了f和s,它就是一个固定运算,梯度下降无需改变任何值。
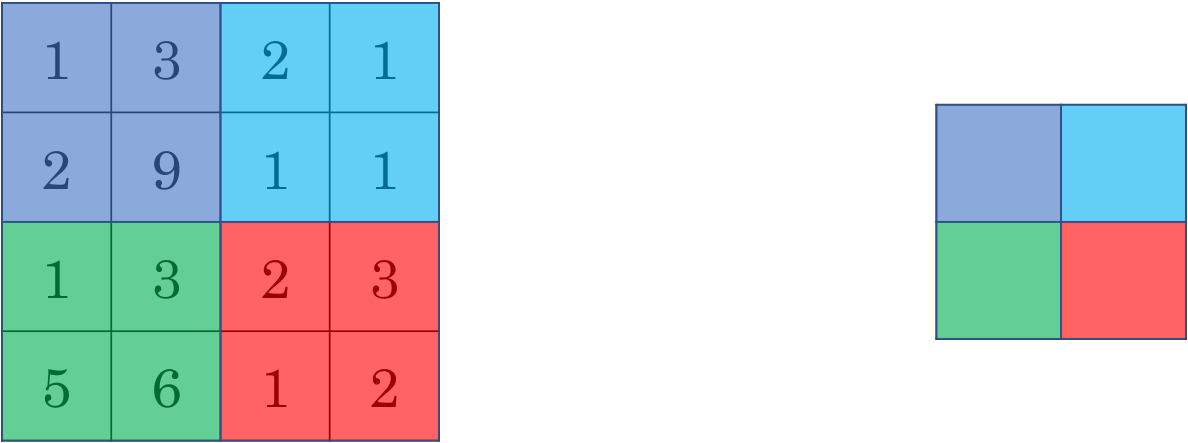
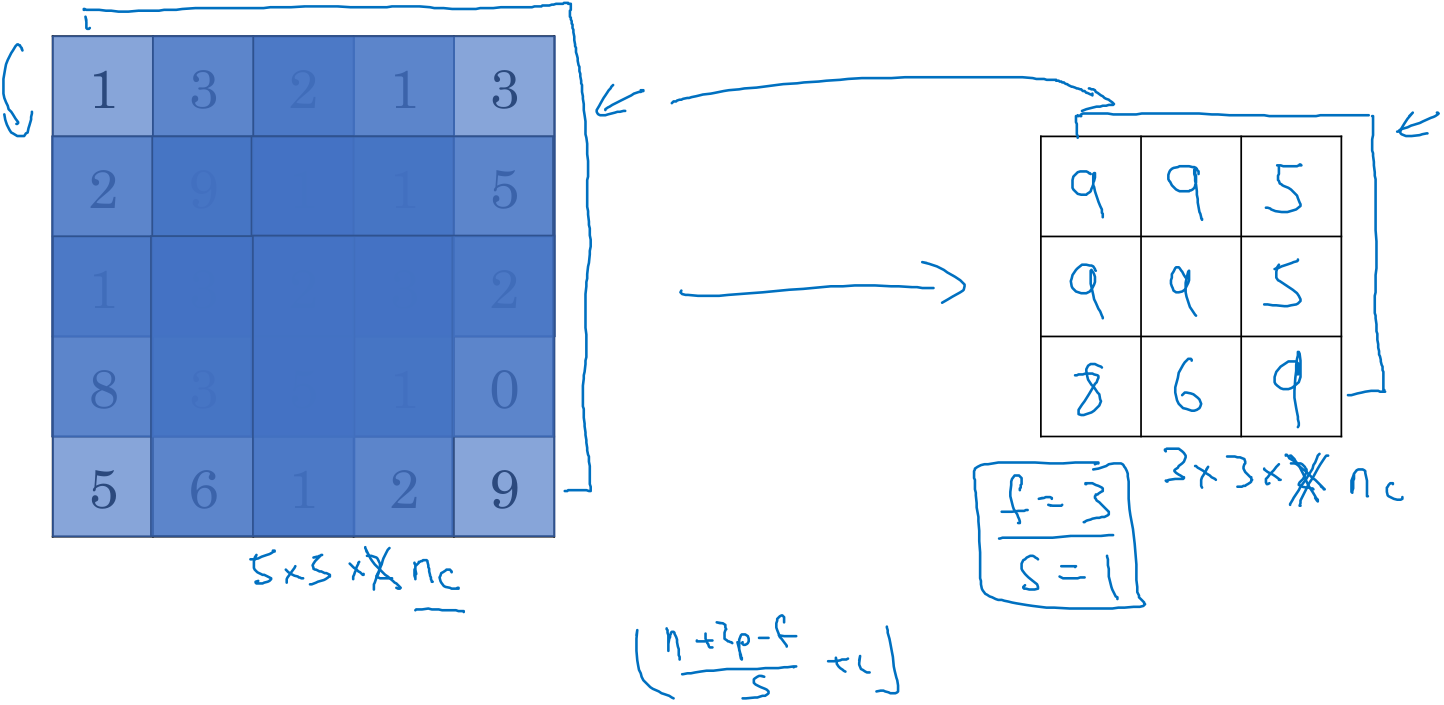
下面是一个池化的具体操作,之前讲的计算卷积层输出大小的公式同样适用于池化。输入的通道数等于输出的通道数,每个通道执行单独的最大池化计算。
还有另外一种类型的池化-平均池化,它不太常用,顾名思义,它计算的是滤波器中的平均值不是最大值。目前来说最大池化比平均池化更常用,但也有例外,就是深度很深的神经网络,可以用平均池化来分解规模为7x7x1000的网络,在整个空间求平均值,得到1x1x1000的输出。
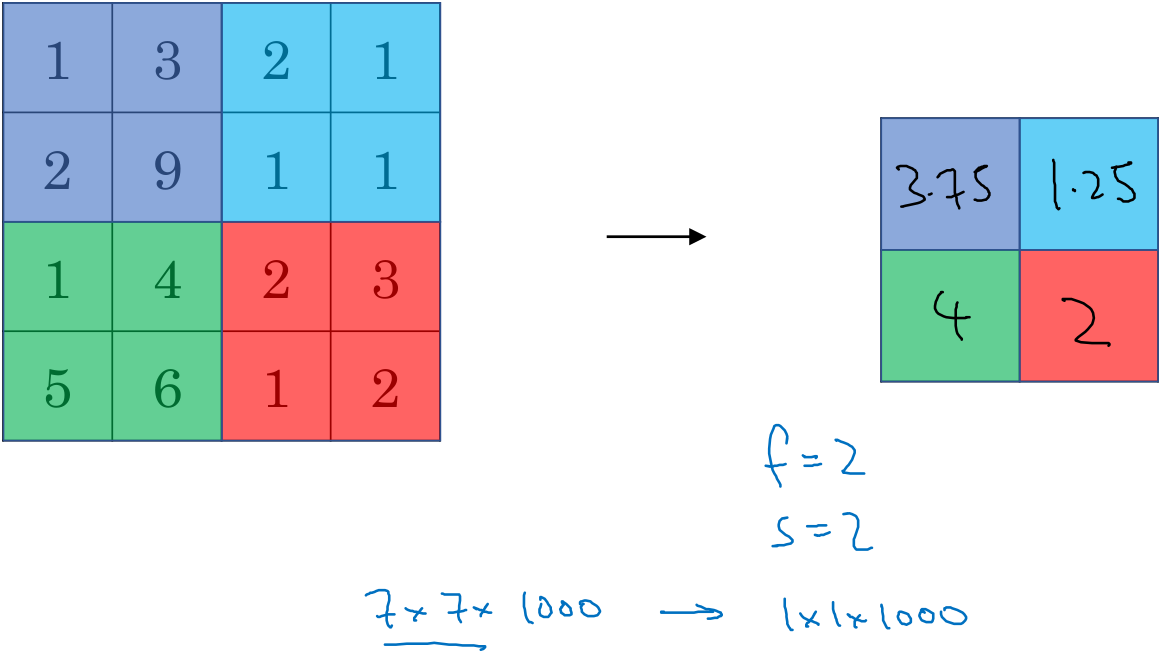
池化的超参数包括滤波器大小f和步幅s,常用的参数值是f=2,s=2,应用频率非常高,其效果相当于高度和宽度缩减一半,也有f=3,s=2的情况。其它超参数就是用最大池化还是平均池化了,也可以根据自己意愿增加表示padding的超参数,当然很少使用这种情况,也有例外。池化在反向传播过程中没有需要训练的参数,只是神经网络某一层的静态属性。
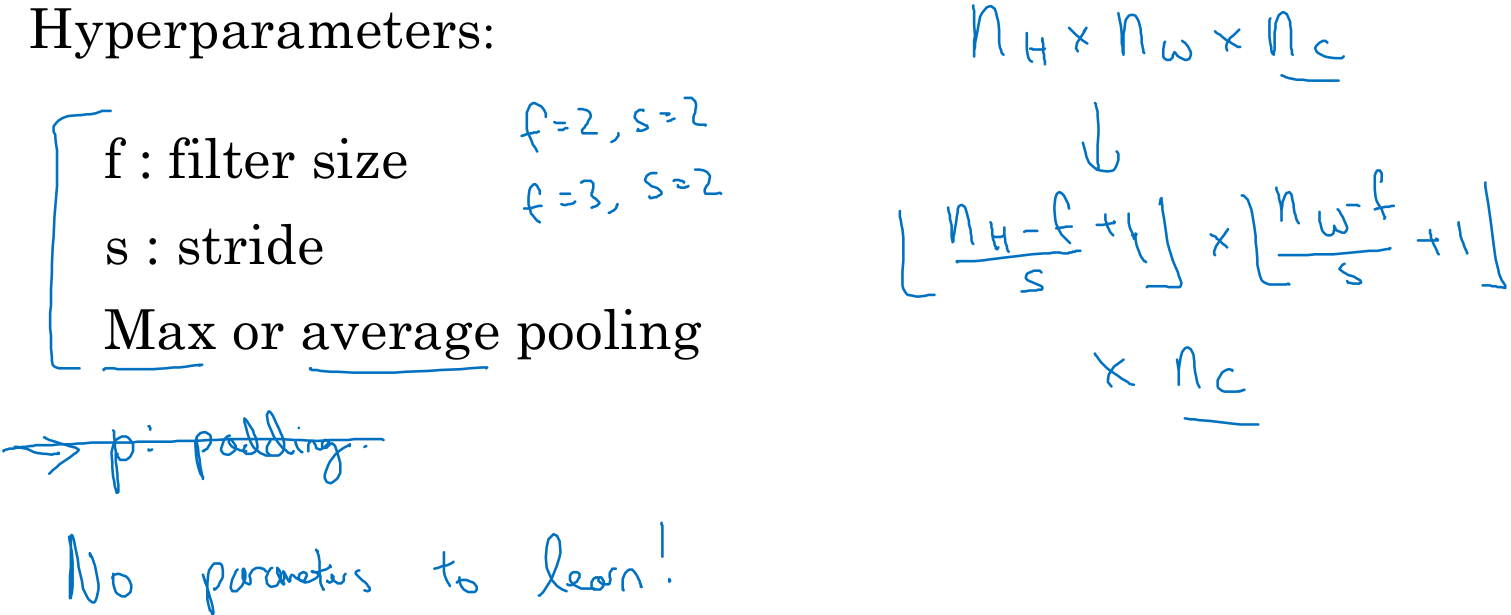
1.10 卷积神经网络示例
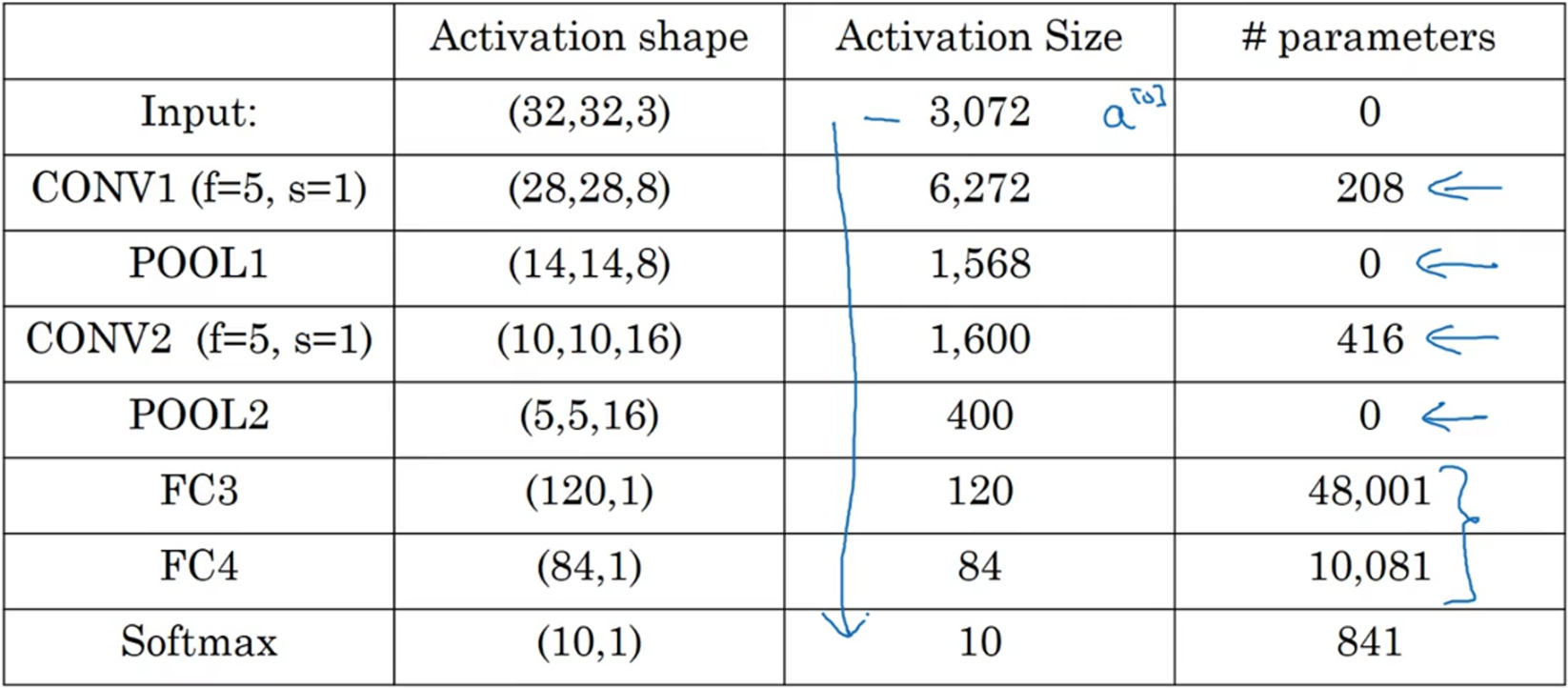
一个典型的卷积网络由卷积层、池化层、全连接层组成。池化层没有参数,卷积层的参数相对较少,许多参数存在于神经网络的全连接层。随着网络的加深,激活值尺寸在减少,如果下降太快,也会影响网络性能。
1.11 为什么使用卷积?
和只用全连接层相比,卷积层的两个主要优势在于参数共享和稀疏连接。例如一个32×32×3(3072)的图像到28×28×6的特征图,全连接层需要3072×4704=14M个参数,要训练的参数很多。而卷积需要的每个过滤器只有5×5+1=26个参数,一共6个过滤器。

卷积网络映射这么少参数有两个原因:一是参数共享,特征检测器如垂直边缘检测如果适用于图片某个区域,那么它也可能适用于其它区域,也就是说,如果使用一个3×3的过滤器检测垂直边缘,图片的任何区域都可以使用这个过滤器。第二种方法是稀疏连接,即输出特征图中的一个值,只取决于前一个特征图中一部分区域,并非是整个特征图。神经网络可以通过这两种机制减少参数,以便于使用更小的训练集来训练它,从而防止过拟合。卷积神经网路还具有平移不变性,即使图像有些平移,依旧可以输出准确的结果。网路可以通过自我学习获得健壮的参数。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号