特征金字塔-Feature Pyramid Networks for Object Detection
特征金字塔是用于检测不同尺度的对象的识别系统中的基本组件。但是最近的深度学习对象检测器已经避免了金字塔表示,部分原因是它们是计算密集型和内存密集型的。在本文中,我们利用深层卷积网络固有的多尺度金字塔层次结构来构造具有边际额外损失的特征金字塔。开发了一种具有横向连接的自上而下的架构,用于在所有尺度上构建高级语义特征图。这种称为特征金子塔网络(FPN)的体系结构在几个应用中作为普通特征提取器显示出显著的改进。在基本的Faster R-CNN系统中使用FPN,我们的方法在COCO检测基准上没有任何花里胡哨的技巧实现了最先进的单模型结果,超过所有现有的单模型条目,包括来自COCO2016挑战赛获胜者。此外,我们的方法可以在GPU上以5FPS运行,因此是多尺度物体检测的实际且准确的解决方法。代码将公开发布。
多尺度上识别目标是计算机视觉的一个基本挑战。在图像金字塔上构建特征金字塔(简称特征化图像金字塔)形成了一个基本解决方案【1】(图1(a))。因为一个目标的尺度改变通过在金字塔中移动层级来抵消,所以从某种意义上说这些金字塔是尺度不变的。直观上讲,这些性质通过在位置和金字塔层级上扫描模型使得模型检测跨尺度的目标。
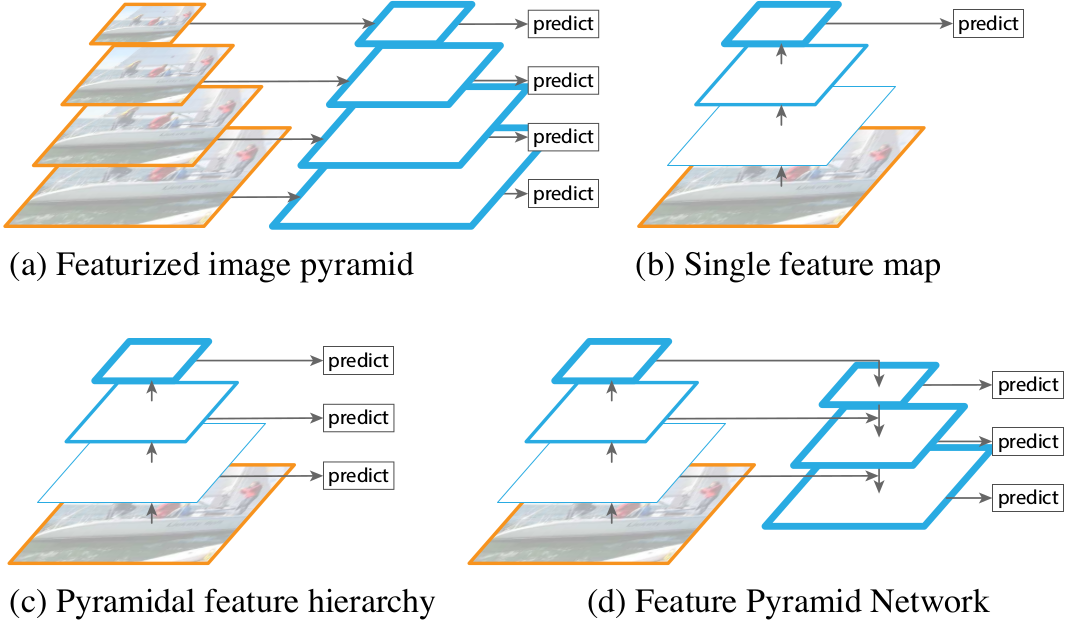
图1:(a)用一个图像金字塔来构建一个特征金字塔。在每个图像尺度上独立地计算特征,很慢。(b)最近的检测系统选择使用于更快速的检测的单尺度特征。(c)通过卷积层重复利用金字塔式的特征层次结构。(d)这里提出的特征金字塔网络(RPN),和(b)(c)一样快,但是更准确。这张图中,特征图通过蓝框表示,越粗的轮廓表示语义越强。
特征化图像金字塔手工设计特征的时代大量使用【5,25】。它们那么重要以至于像DPM【7】这样的目标检测器要求密集尺度采样来实现好的结果(例如,每个阶段10个尺度)。对于识别任务,设计特征已经被卷积特征取代【19,20】。除了能表示更高级的语义特征,卷积网络对于尺度变化更鲁棒,因此促进在单尺度输入上计算的识别【15,11,29】(图1(b))。但是即使有这种鲁棒性,金字塔仍然需要获得更多准确的结果。所有最近在ImageNet【33】和COCO【21】检测挑战上的前几名都在特征化的图像金字塔上使用多尺度测试(例如,【16,35】)。一个图像金字塔的特征化的每个层级的主要优点是它能产生多尺度特征表示,其中所有层级都有很强的语义,并且有很高的分辨率层级。
然而,特征化一个图像金字塔的每一个层级都有明显的限制。大大增加的推理时间(例如,【11】)使得这个方法对于真实的应用是不实际的。此外,在一个图像金字塔上训练端到端的深度网络就内存而言是不可行的,并且如果想用可以在测试时间用【15,11,16,35】,这导致了训练/测试时间不一致。出于这些原因,Fast 和 Faster R-CNN【11,29】在默认设置下选择不使用特征化图像金字塔。
然而,图像金字塔不是计算多尺度特征金字塔的唯一方法。深度卷积网络计算逐层的特征层次结构,并且具有子采样层的特征层次结构有一个固有的多尺度金字塔形状。这个内网层次结构产生了不同空间分辨率的特征图,但是在不同深度有很大的语义差异。高分辨图有低级的特征,该特征影响目标识别表示能力。
单点检测器(SSD)【22】是使用卷积金字塔特征层次第一次尝试中的一个,就好像它是一个特征化的图像金字塔(图1(c))。概念上看,SSD风格的金字塔重用不同层多尺度特征图,因此没有代价。但是为了避免使用低级特征,SSD放弃重用已经计算的层,相反从网络的高层开始构建金字塔(例如,VGG的con4_3【36】)并且然后添加一些新层。因此它失去了重用特征层次结构高分辨率图的机会。这些对于检测小目标是重要的。
这篇论文的目标是利用卷积网络特征层次结构的金字塔形状,并同时创建一个在所有尺度上有强语义的特征金字塔。为了实现这个目标,依赖于一个结构,该结构通过从上而下的路径和横向连接,来将低分辨率但语义强的特征和高分辨率但语义弱的特征结合起来(图1(d))。结果是在所有层级上都有丰富语义且在单输入图像尺度上快速构建的特征金字塔。换句话说,就是使用内网特征金字塔取代特征化图像金字塔,且没有牺牲表示能力,速度和内存。
相似的采样从上而下和跳跃连接的结构在最近的研究中是流行的【28,17,8,26】。它们的目标是在一个精细的特征图上产生一个高级特征图(图2上)。相反的是,这片论文的方法是利用该结构作为一个特征金字塔在每个层级上独立预测(图2下)。
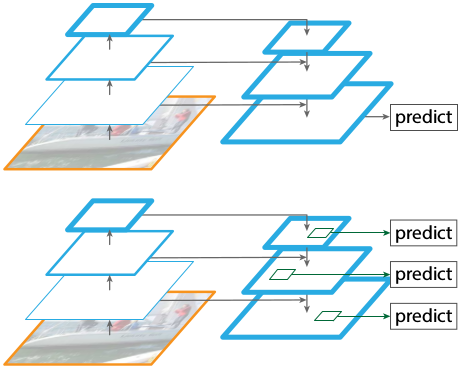
图2:上:一个使用跳跃连接的从上而下的结构,在最精细的层级上预测。下:与上面有相似的结构,但是充分利用作为特征金字塔,在所有层级上独立预测。
在用于检测和分割【11,29,27】的不同系统上评估FPN。没有任何花里胡哨的东西,在COCO检测基准上使用Faster R-CNN和FPN取得了最好的结果。这个方法也可以很容易扩展到掩码建议中并改善实例分割的性能。
此外,这里的特征金字塔结构可以在所有尺度上进行端到到的训练,并且在训练和测试时间是一致的。
特征金子塔网络
我们的目标是利用ConvNet的金字塔特征层次结构,该结构具有从低级到高级的语义,并构建一个具有高级语义的特征金字塔。由此产生的$Feature\,Pyramid\,Network$是通用的,在本文中,我们关注滑动窗口建议器(Region$\,$Proposal$\,$Network,简称RPN)【29】和基于区域的探测器(Fast R-CNN)【11】。我们还将FPN泛化到第6节中的实例分割建议。
我们的方法采用任意大小的单尺度图像作为输入,并以全卷积的方式输出多个级别的按比例大小的特征图。这个过程独立于backbone卷积架构(例如,【19,36,16】),并且本文中我们用ResNets【16】来呈现结果。我们金字塔的结构涉及从下而上的路径,从上而下的路径,和横向连接,如下所述。
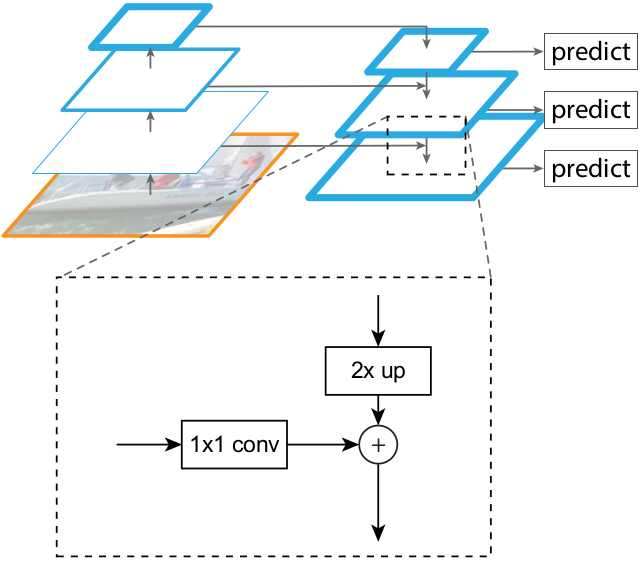
图3:一个解释横向连接和从上而下连接路径通过加来融合的构建块。
Bottom-up pathway. 从下而上的路径是backbone ConvNet的前向计算,它计算一个特征层次结构,其包含缩放步长为2的多尺度的特征图。通常有许多层产生同样尺寸的输出图,并且我们说这些层处于同样的网络$stage$。对于我们的特征金字塔,我们为每一个阶段定义一个金字塔等级。我们选择每个阶段最后一层的输出作为我们的参考特征图集,我们将丰富它们创建我们的金字塔。这种选择很自然,因为每个阶段的最深的层应该有最健壮的特征。
具体地说,对于ResNets【16】,我们使用每个阶段的最后残差块的特征激活输出。对于conv2,conv3,conv4和conv5的输出,我们这些最后残差块的输出表示为$\{C_{2}, C_{3}, C_{4}, C_{5}\}$,并且注意它们相对于输入图像具有$\{4, 8, 16, 32\}$像素的步长。由于内存占用大,我们不会将conv1包含在金字塔中。
Top-down pathway and lateral connections. 自上而下的路径从更高的金字塔等级上采样空间粗略但是语义健壮的特征图,来幻化更高的分辨率特征。然后通过横向连接从下而上的路径来增强这些特征。每个横向连接融合来自从下而上的路径和从上而下的路径同样空间尺寸的特征图。自下而上的特征图具有较低级别的语义,但是它的激活更准确地本地化了,因为它被子采样数减少。
图3展示了构建自上而下特征图的建造块。使用粗糙分辨率的特征图,我们将空间分辨率上采样2倍(为了简单使用最近邻上采样)。然后通过逐元素相加将上采样的特征图与相关从下而上的特征图(它经历1x1的卷积层来减少通道维度)融合。迭代此过程,直到生成最精细的分辨率特征图。为了开始迭代,我们简单地把$C_{5}$上附加1x1卷积层来产生最粗糙的分辨率特征图。最终,我们在每一个融合图上添加一个3x3的卷积来生成最终的特征图,这减少了上采样的混叠效应。这最终的特征图集被称为$\{P_{2},P_{3},P_{4},P_{5}\}$,分别对应同样空间尺寸的$\{C_{2},C_{3},C_{4},C_{5}\}$。
因为所有的金字塔等级使用共享的分类器/回归器,如在传统的特征化图金字塔一样,所以我们在所有的特征图中固定特征维度(通道的数量,表示为d1)。本文中设置$d=256$,因此所有额外的卷积层有256-channel的输出。在这些额外的层中没有非线性,我们根据经验发现它们有轻微的影响。
简单是我们设计的核心,并且我们发现我们的模型对于许多设计选择是鲁棒的。我们尝试了更多复杂的块(例如,用多层残差块作为连接),并且观察到了略微更好地结果。设计更好的连接块不是本文你的重点,因此我们选择上面描述的简单设计。
应用
我们的方法是在深层ConvNets中构建特征金字塔的通用解决方案。下面我们在用于边界框建议生成的RPN【29】和用于目标检测的Fast R-CNN【11】中采用我们的方法。为了证明我们方法的简单性和有效性,当改变它们以适应我们的特征金字塔时,我们对于【29,11】的原始系统做极小的修改。
用于RPN的特征金字塔网络
RPN【29】是一个滑窗的且类无关的目标检测器。在原始RPN设计中,一个小的子网络在密集的3x3滑窗上评估,并且在单尺度卷积特征图的顶部执行目标/非目标二元分类和边界框回归。这通过一个3x3卷积层,其后跟随两个兄弟般的用于分类和回归的1x1卷积实现,我们将其称为网络的head。目标/非目标标准和边界框回归目标是关于一组称为$anchors$的参考框定义的【29】。锚点具有多个预定义的尺度和纵横比,以便覆盖不同类型的目标。
我们通过用FPN替换单尺度特征图来调整RPN。我们将同样设计的头部(3x3的卷积和两个兄弟般的1x1的卷积)附加到特征金字塔的每个等级上。因为头部在所有金字塔等级的所有位置上密集滑动,所以在一个特定的等级上有多尺度的锚点是不必要的。相反,我们为每一个等级分配单尺度的锚点。在形式上,我们将锚点定义为分别在$\{P_{2}, P_{3}, P_{4}, P_{5}, P_{6}\}$上具有$\{32^{2}, 64^{2}, 128^{2}, 256^{2}, 512^{2}\}$像素的区域。如【29】一样,我们在每个等级上有多个纵横比例$\{1:2, 1:1, 2:1\}$的锚点。因此金字塔上总共有15个锚点。
我们根据真值边界框的交并比(IoU)把训练标签分配给锚点,正如【29】所述。在形式上,如果锚点对于一个给定的真值框有最高的IoU或者与任何真值框有超过0.7的IoU,则为锚点分配正标签,如果锚点对于所有的真值框有低于0.3的IoU,则为锚点分配负标签。注意,真值框的尺度没有明确地被用于分配它们给金字塔的等级。相反,真值框与锚点相关联,锚点已被分配给金字塔等级。因此,除了【29】的规则外,我们没有引入额外的规则。
我们注意到头部的所有参数在所有特征金字塔等级之间共享;我们也评估了没有共享参数的替代方案,并观察到了相似的准确率。共享参数的好性能表示我们金字塔的所有等级共享相似的语义级别。这个优点类似于用特征化图像金字塔的优点,其中一个普通的头部分类器可以应用于以任何图像尺度计算的特征。
通过上述调整,RPN可以很自然地用FPN训练和测试,和【29】是同样的方式。我们详细说明了实验中实现细节。
用于Fast RCNN的特征金字塔网络
Fast R-CNN【11】是一个基于区域的目标检测器,其中感兴趣区域(RoI)用于提取特征。Fast R-CNN最常在单尺度特征图上执行。为了使用FPN用它,我们需要将不同尺度的RoI分配给金字塔等级。
我们将特征金字塔视为从图像金字塔中生成。因此,当它们在图像金字塔上运行时,我们可以调整基于区域的检测器【15,11】的分配策略。在形式上,我们将宽度为$w$和高度为$h$的RoI分配给特征金字塔的$P_{k}$级:
$k=[k_{0}+log_{2}(\sqrt{wh}/224)]$(1)
这里的224是典型的ImageNet预训练尺寸,并且$k_{0}$是一个具有$wxh=224^{2}$的RoI应该映射到的目标等级。相似于基于ResNet的用$C_{4}$作为单尺度特征图的Faster R-CNN系统,我们设置$k_{0}$为4。直观地,等式(1)意味着如果RoI的尺度变得更小(例如,224的1/2),应该把它映射到更精细的分辨率等级(例如,$k=3$)。
我们将预测器头部(在Fast R-CNN中头部是具体类的分类器和边界框分类器)附加到所有等级的所有RoI上。同样,头部都共享参数,无论它们的级别如何。在【16】中,ResNet的conv5层(9层深的子网络)被用为conv4特征顶部的头部,但是我们的方法已经利用conv5来构建特征金字塔。因此不像【16】,我们简单地采用RoI池化来提取7x7特征,并且在最终的分类和边界框回归层之前附加了两个隐藏的1024-d全连接(fc)层(每个后面更随一个ReLU)。这些层被随机初始化,因为ResNet中没有预训练的$fc$层。注意,和标准的conv5头相比,我们的$2-fc$ MLP头部重量更轻并且更快。
基于这些调整,我们可以在特征金字塔的顶部训练和测试Fast R-CNN。
FPN代码示例
def resnet_graph(input_image, architecture, stage5=False, train_bn=True): """Build a ResNet graph. architecture: Can be resnet50 or resnet101 stage5: Boolean. If False, stage5 of the network is not created train_bn: Boolean. Train or freeze Batch Norm layers """ assert architecture in ["resnet50", "resnet101"] # Stage 1 x = KL.ZeroPadding2D((3, 3))(input_image) x = KL.Conv2D(64, (7, 7), strides=(2, 2), name='conv1', use_bias=True)(x) x = BatchNorm(name='bn_conv1')(x, training=train_bn) x = KL.Activation('relu')(x) C1 = x = KL.MaxPooling2D((3, 3), strides=(2, 2), padding="same")(x) # Stage 2 x = conv_block(x, 3, [64, 64, 256], stage=2, block='a', strides=(1, 1), train_bn=train_bn) x = identity_block(x, 3, [64, 64, 256], stage=2, block='b', train_bn=train_bn) C2 = x = identity_block(x, 3, [64, 64, 256], stage=2, block='c', train_bn=train_bn) # Stage 3 x = conv_block(x, 3, [128, 128, 512], stage=3, block='a', train_bn=train_bn) x = identity_block(x, 3, [128, 128, 512], stage=3, block='b', train_bn=train_bn) x = identity_block(x, 3, [128, 128, 512], stage=3, block='c', train_bn=train_bn) C3 = x = identity_block(x, 3, [128, 128, 512], stage=3, block='d', train_bn=train_bn) # Stage 4 x = conv_block(x, 3, [256, 256, 1024], stage=4, block='a', train_bn=train_bn) block_count = {"resnet50": 5, "resnet101": 22}[architecture] for i in range(block_count): x = identity_block(x, 3, [256, 256, 1024], stage=4, block=chr(98 + i), train_bn=train_bn) C4 = x # Stage 5 if stage5: x = conv_block(x, 3, [512, 512, 2048], stage=5, block='a', train_bn=train_bn) x = identity_block(x, 3, [512, 512, 2048], stage=5, block='b', train_bn=train_bn) C5 = x = identity_block(x, 3, [512, 512, 2048], stage=5, block='c', train_bn=train_bn) else: C5 = None return [C1, C2, C3, C4, C5]
P5 = KL.Conv2D(config.TOP_DOWN_PYRAMID_SIZE, (1, 1), name='fpn_c5p5')(C5) P4 = KL.Add(name="fpn_p4add")([ KL.UpSampling2D(size=(2, 2), name="fpn_p5upsampled")(P5), KL.Conv2D(config.TOP_DOWN_PYRAMID_SIZE, (1, 1), name='fpn_c4p4')(C4)]) P3 = KL.Add(name="fpn_p3add")([ KL.UpSampling2D(size=(2, 2), name="fpn_p4upsampled")(P4), KL.Conv2D(config.TOP_DOWN_PYRAMID_SIZE, (1, 1), name='fpn_c3p3')(C3)]) P2 = KL.Add(name="fpn_p2add")([ KL.UpSampling2D(size=(2, 2), name="fpn_p3upsampled")(P3), KL.Conv2D(config.TOP_DOWN_PYRAMID_SIZE, (1, 1), name='fpn_c2p2')(C2)]) # Attach 3x3 conv to all P layers to get the final feature maps. P2 = KL.Conv2D(config.TOP_DOWN_PYRAMID_SIZE, (3, 3), padding="SAME", name="fpn_p2")(P2) P3 = KL.Conv2D(config.TOP_DOWN_PYRAMID_SIZE, (3, 3), padding="SAME", name="fpn_p3")(P3) P4 = KL.Conv2D(config.TOP_DOWN_PYRAMID_SIZE, (3, 3), padding="SAME", name="fpn_p4")(P4) P5 = KL.Conv2D(config.TOP_DOWN_PYRAMID_SIZE, (3, 3), padding="SAME", name="fpn_p5")(P5) # P6 is used for the 5th anchor scale in RPN. Generated by # subsampling from P5 with stride of 2. P6 = KL.MaxPooling2D(pool_size=(1, 1), strides=2, name="fpn_p6")(P5) # Note that P6 is used in RPN, but not in the classifier heads. rpn_feature_maps = [P2, P3, P4, P5, P6] mrcnn_feature_maps = [P2, P3, P4, P5] # RPN Model rpn = build_rpn_model(config.RPN_ANCHOR_STRIDE, len(config.RPN_ANCHOR_RATIOS), config.TOP_DOWN_PYRAMID_SIZE) # Loop through pyramid layers layer_outputs = [] # list of lists for p in rpn_feature_maps: layer_outputs.append(rpn([p]))
# Concatenate layer outputs
# Convert from list of lists of level outputs to list of lists
# of outputs across levels.
# e.g. [[a1, b1, c1], [a2, b2, c2]] => [[a1, a2], [b1, b2], [c1, c2]] output_names = ["rpn_class_logits", "rpn_class", "rpn_bbox"] # e.g. [(rpn_class_logits1, rpn_class_logits2, rpn_class_logits3), # (rpn_probs1, rpn_probs2, rpn_probs3), # (rpn_bbox1, rpn_bbox2, rpn_bbox3)] outputs = list(zip(*layer_outputs)) # axis=1 is the dimension of every anchor outputs = [KL.Concatenate(axis=1, name=n)(list(o)) for o, n in zip(outputs, output_names)] rpn_class_logits, rpn_class, rpn_bbox = outputs

 浙公网安备 33010602011771号
浙公网安备 33010602011771号