模拟递归生成器
与递归生成器实现同样的功能,不过这里使用非生成器的方法来模拟。
def flatten(nested): result = [] try: for sublist in nested: for element in flatten(sublist): print('element:', element) result.append(element) print('rrrrrrrrrresult:', result) except TypeError: print(nested) result.append(nested) return result a = flatten([[[1], 2], 3, 4, [5, [6, 7]], 8]) print(a) 输出: 1 element: 1 rrrrrrrrrresult: [1] element: 1 rrrrrrrrrresult: [1] 2 element: 2 rrrrrrrrrresult: [1, 2] element: 1 rrrrrrrrrresult: [1] element: 2 rrrrrrrrrresult: [1, 2] 3 element: 3 rrrrrrrrrresult: [1, 2, 3] 4 element: 4 rrrrrrrrrresult: [1, 2, 3, 4] 5 element: 5 rrrrrrrrrresult: [5] 6 element: 6 rrrrrrrrrresult: [6] 7 element: 7 rrrrrrrrrresult: [6, 7] element: 6 rrrrrrrrrresult: [5, 6] element: 7 rrrrrrrrrresult: [5, 6, 7] element: 5 rrrrrrrrrresult: [1, 2, 3, 4, 5] element: 6 rrrrrrrrrresult: [1, 2, 3, 4, 5, 6] element: 7 rrrrrrrrrresult: [1, 2, 3, 4, 5, 6, 7] 8 element: 8 rrrrrrrrrresult: [1, 2, 3, 4, 5, 6, 7, 8] [1, 2, 3, 4, 5, 6, 7, 8]
通过输出可以看出,虽然最终的结果一样,但是中间的element输出却不一样。原因在于,yield每次返回时,当前的代码就会被挂起,如果用return替代yield代码就完全返回。所以实现同样的功能,生成器每次遍历到一个值就逐层向上传递,而模拟递归函数得先保存result中,把result逐层向上传递。此外,因为模拟代码不能挂起代码,所以必须得把底层代码处理完,才能逐层返回,而生成器可以每次都挖到最底层。如此看来如果递归嵌套比较深,生成器的效率会比较低,因为每次都要从上到下。
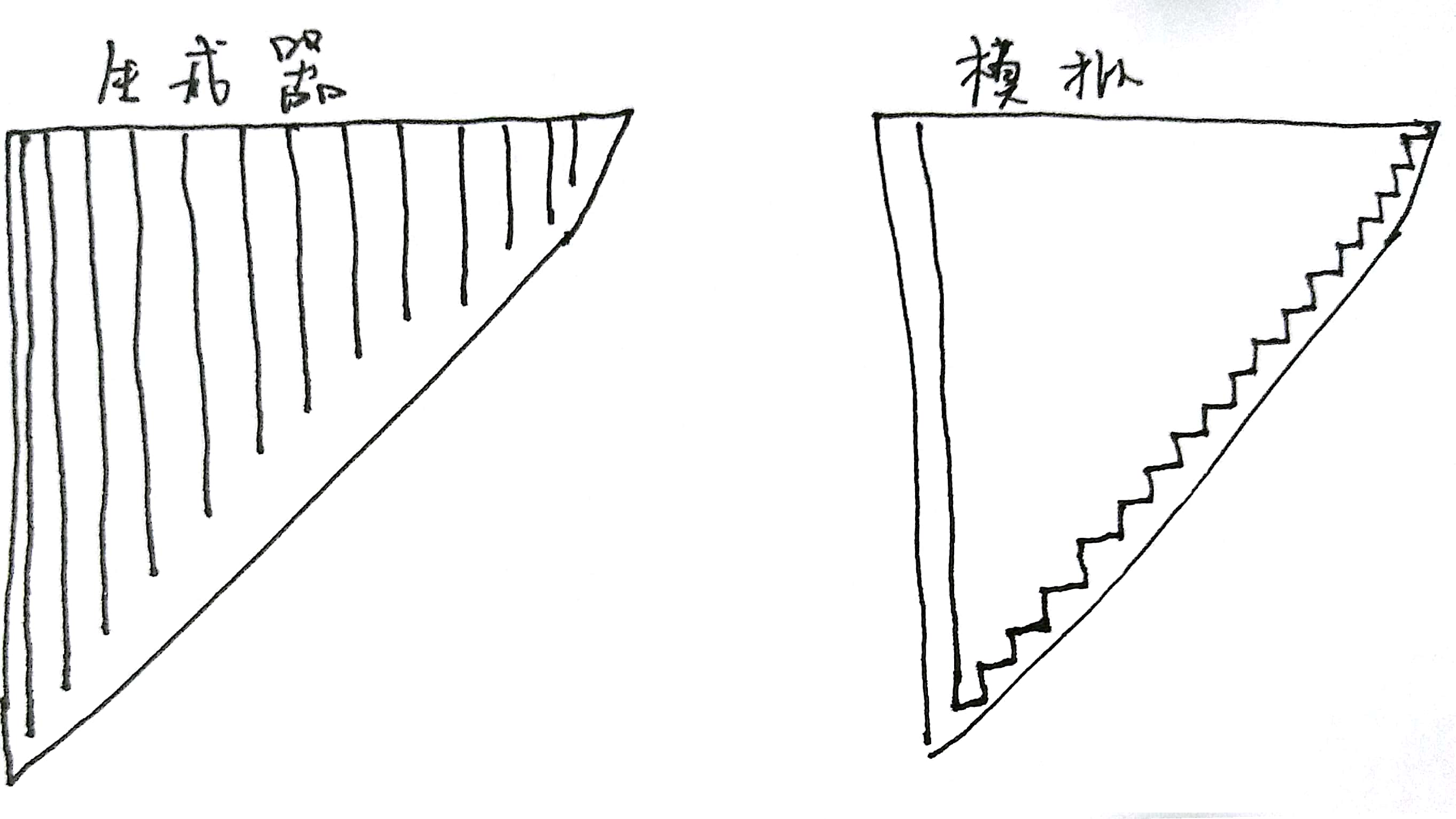
上图是两者执行的示意图,生成器每次生成一个值都是从上往下搜,然后通过yield原路返回,而模拟递归是全部遍历最终返回。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号