
Hadoop综合大作业
1.用Hive对爬虫大作业产生的文本文件(或者英文词频统计下载的英文长篇小说)进行词频统计。
在网上下载英文小说,下载到本地home/hadoop/wc
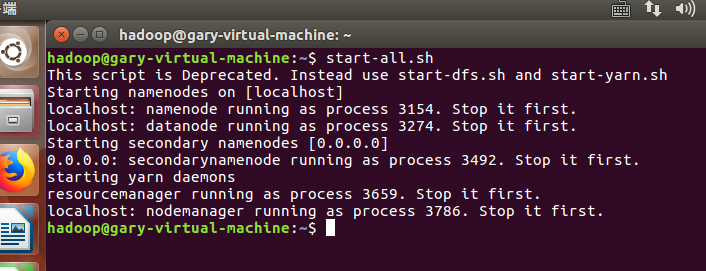
首先要启动dfs:
在user/hadoop/上创建文件夹xiaoshuo:
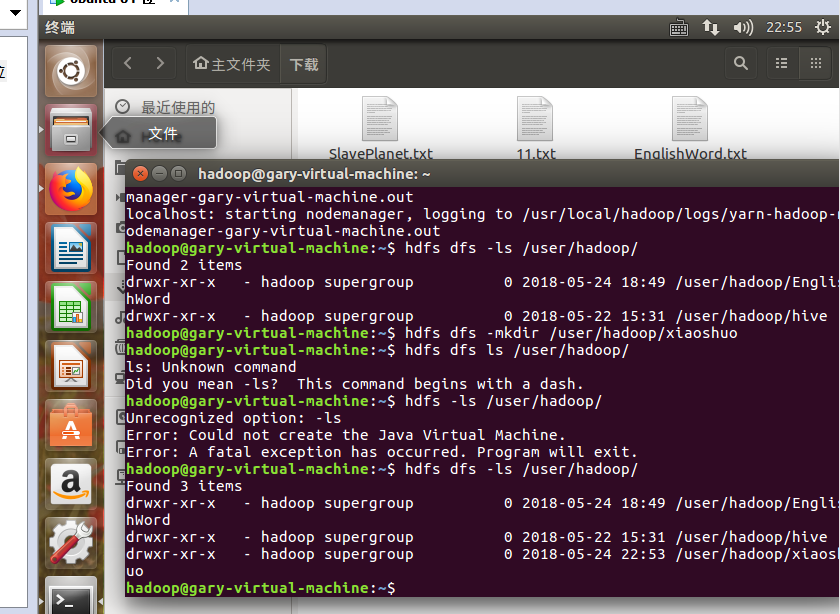
上传下载文档到user/hadoop/xiaoshuo文件中:

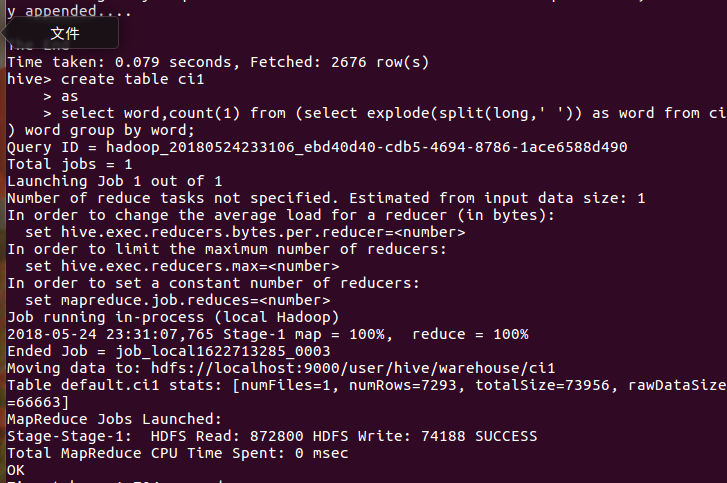
在hive数据库创建表 ci:
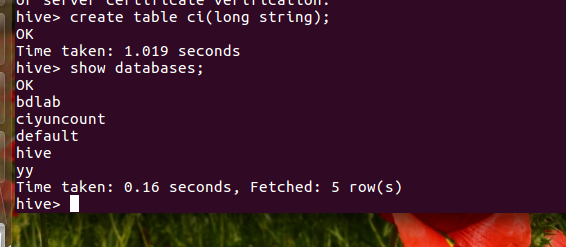
导入文本world.txt并查看

用HQL进行词频统计并保持到表 ci:
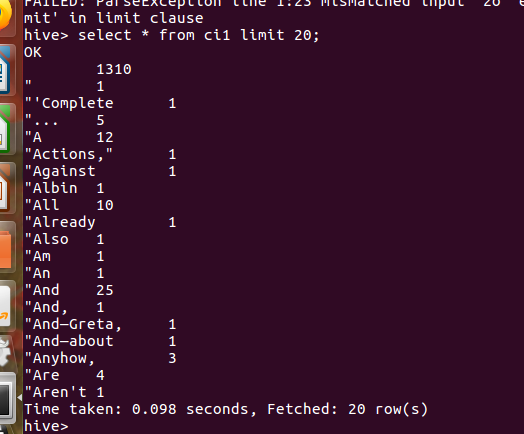
2.用Hive对爬虫大作业产生的csv文件进行数据分析,写一篇博客描述你的分析过程和分析结果。
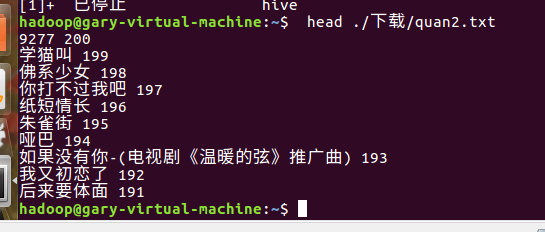
将爬虫作业产生的文件转为txt格式的文件,发生至网盘,然后再虚拟机下载操作。
下载下来的txt文件显示前十条:
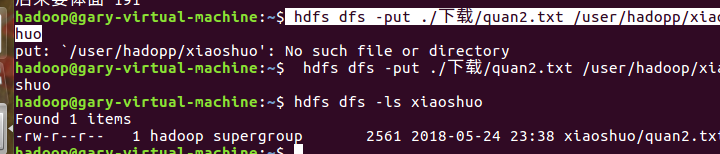
把文件上传至hdfs,并查看:
创建数据库cyfx和表cyfx:
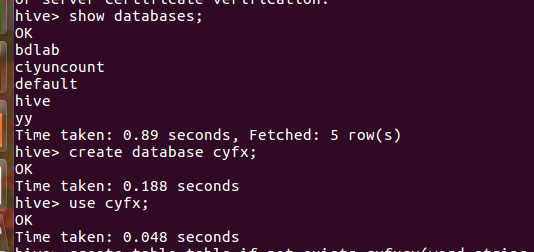

导入数据:

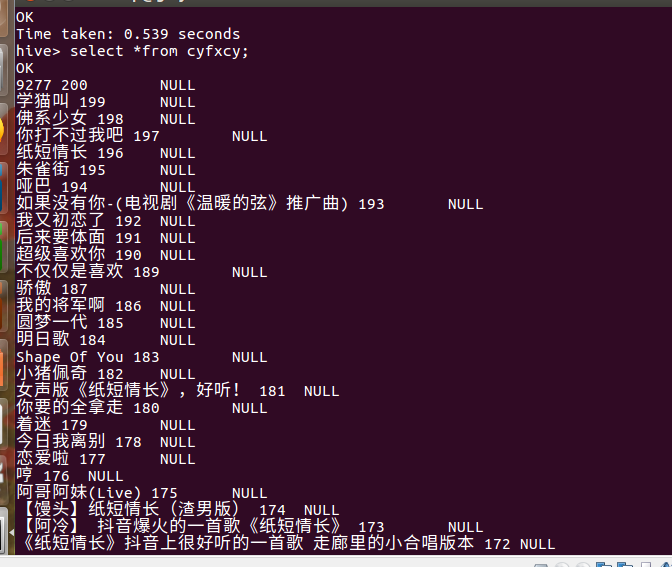
查看数据:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号