Redis数据类型的底层结构
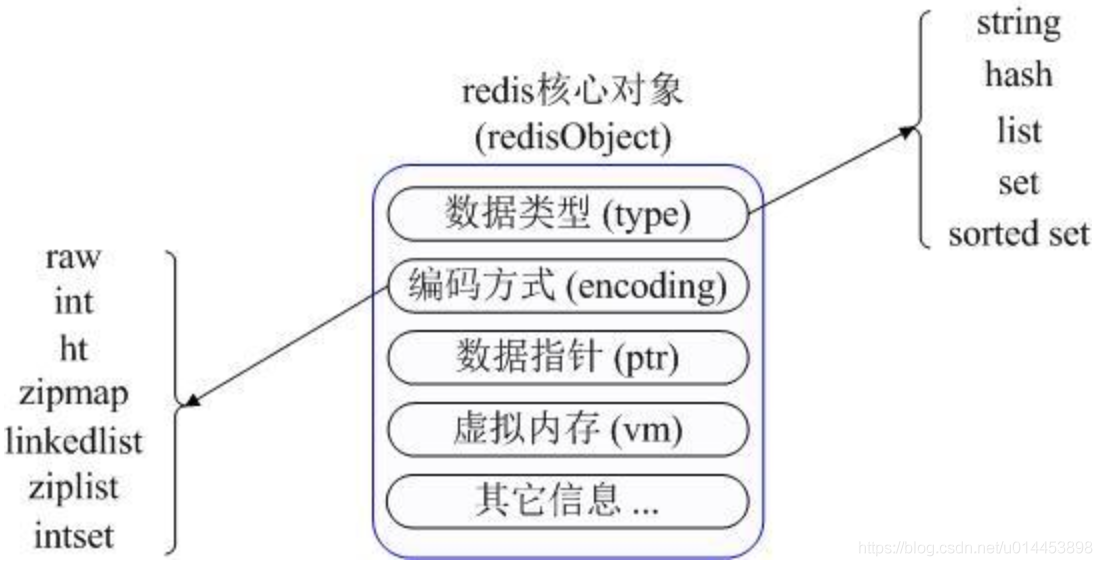
RedisObject底层结构实现
1、String
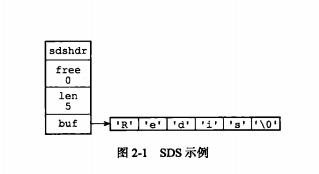
底层实现:SDS
Redis构建的简单动态字符串(Simple Dynamic String),简称SDS,
AOF的缓冲层也用的是SDS
优点:
传统字符串(C字符串) SDS
1. 获取字符串长度的复杂度为O(N) 获取字符串长度的复杂度为O(1)
2. API 是不安全的,可能会造成缓冲区溢出 API 是安全的,不会造成缓冲区溢出
3. 修改字符串长度N次必然需要执行N次内存重分配 修改字符串长度N次最多执行N次内存重分配
4. 只能保存文本数据 可以保存二进制数据和文本文数据
5. 可以使用所有<String.h>库中的函数 可以使用一部分<string.h>库中的函数
1、C字符串通过遍历的方式来获取字符串的长度,O(n);
SDS数据结构中存储了字符串长度,空余长度,数据空间,直接可获取字符串长度,O(1)
struct sdshdr {
int len;// buf 中已占用空间的长度
int free;// buf 中剩余可用空间的长度
char buf[];// 数据空间
};
2、C字符串在进行字符串修改的时候,若修改后的字符串的长度大于原有的长度,此时又为及时修改空间长度,就会产生内存得溢出;而且每次进行字符串修改都要重新分配空间。
SDS进行修改时会有如下三步:
检查空间是否足够
若不足够则会,进行空间的开辟,开辟为新字符串的长度,将len改为新空间的大小
重新计算free空间大小,即将free改为新len的长度。
3、C字符串每次进行扩充和收缩时都要进行内存空间的分配,若修改后的长度大于原来的长度,此时未进行内存空间的分配,就会导致内存空间的泄露;
SDS则不会在内次修改时会进行一次内存空间的判断,若上次扩展的空间足够这次字符的使用则不用进行空间扩展,这样分配空间的次数也会变少,效率也会变高。同时SDS提供了惰性空间释放的API可以防止一些无用空间的浪费。
4、c字符串只有一个空字符作为结束符,因此无法存储图片,音频,视频,压缩文件这样的二进制数据;
SDS对空字符串没有要求,通过len属性来判断字符串的结束。
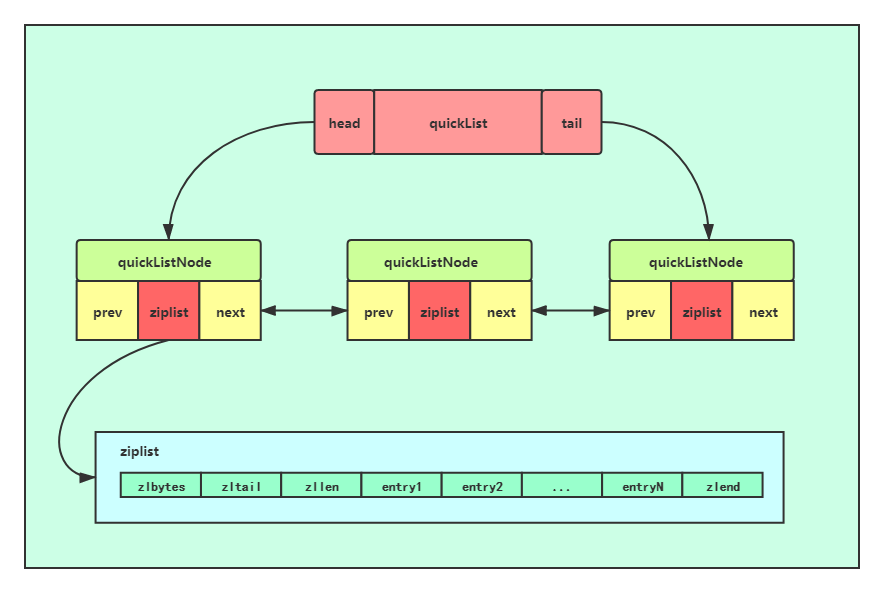
2、list(列表)
quicklist:而在Redis3.2版本开始对列表数据结构进行了改造,使用 quicklist 代替了 ziplist 和 linkedlist
底层实现:ziplist,linkedlist
ziplist(压缩列表):列表长度少于 512,并且所有元素的长度都少于64个字节时
linkedlist(双链表): 上述反之,使用双链表
quicklist
数组

压缩表

linkedlist(双向链表)
ziplist节省内存原理:
普通数组的各个元素的长度都是一样的,按元素的最大值来确定,这样有时候会造成空间的浪费,
ziplist在各个元素中存放元素的长度,这样会更好的使用空间。
linkedlist:双向链表
3、hash
底层实现:ziplist、hashtable
ziplist(压缩列表):当哈希对象保存的键值对数量少于512,且所有键值对的长度都少于64字节时
hashtable:上述反之使用hashtable
ziplist
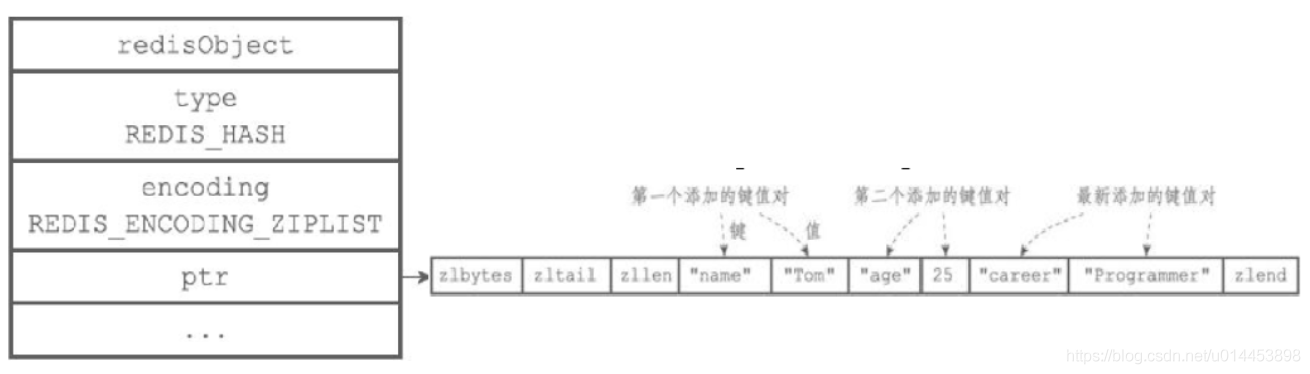
hashtable
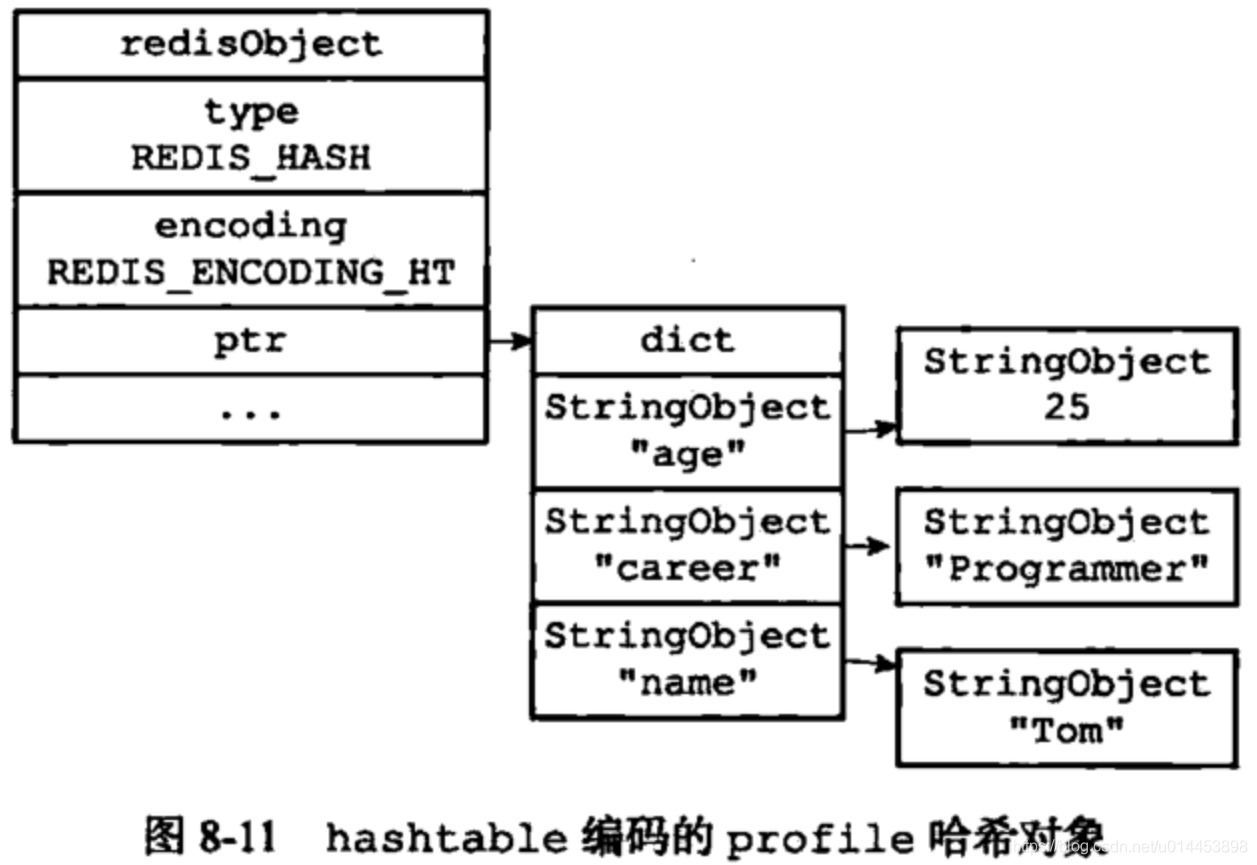
4、set(集合)
底层实现:intset、hashtable
intset:当 集合的长度少于 512 时,并且所有元素都是整数,使用 intset存储
hashtable: hashtable编码的底层实现是字典,字典的每个键是字符串对象,只不过值都是空(NULL)
inset

hashtable
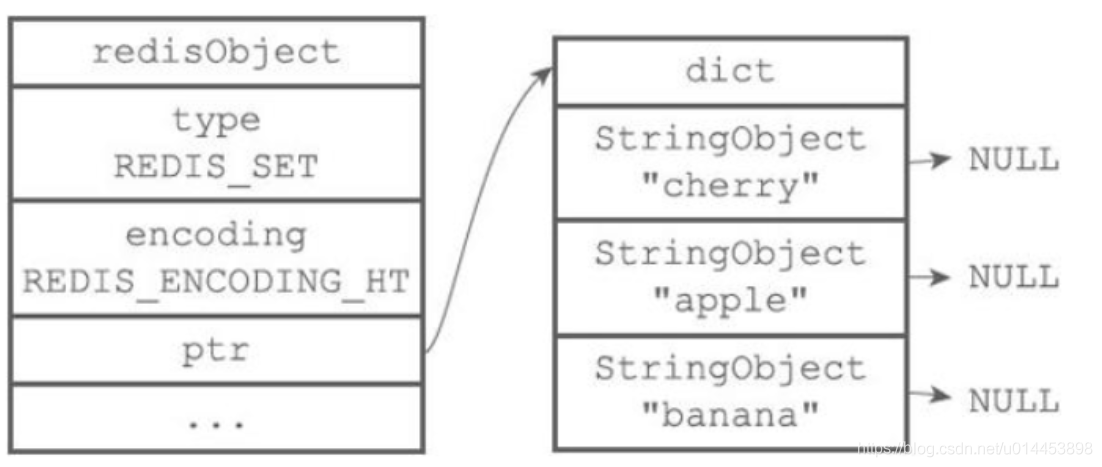
5、SortSet(有序列表)
底层实现:skiplist、ziplist
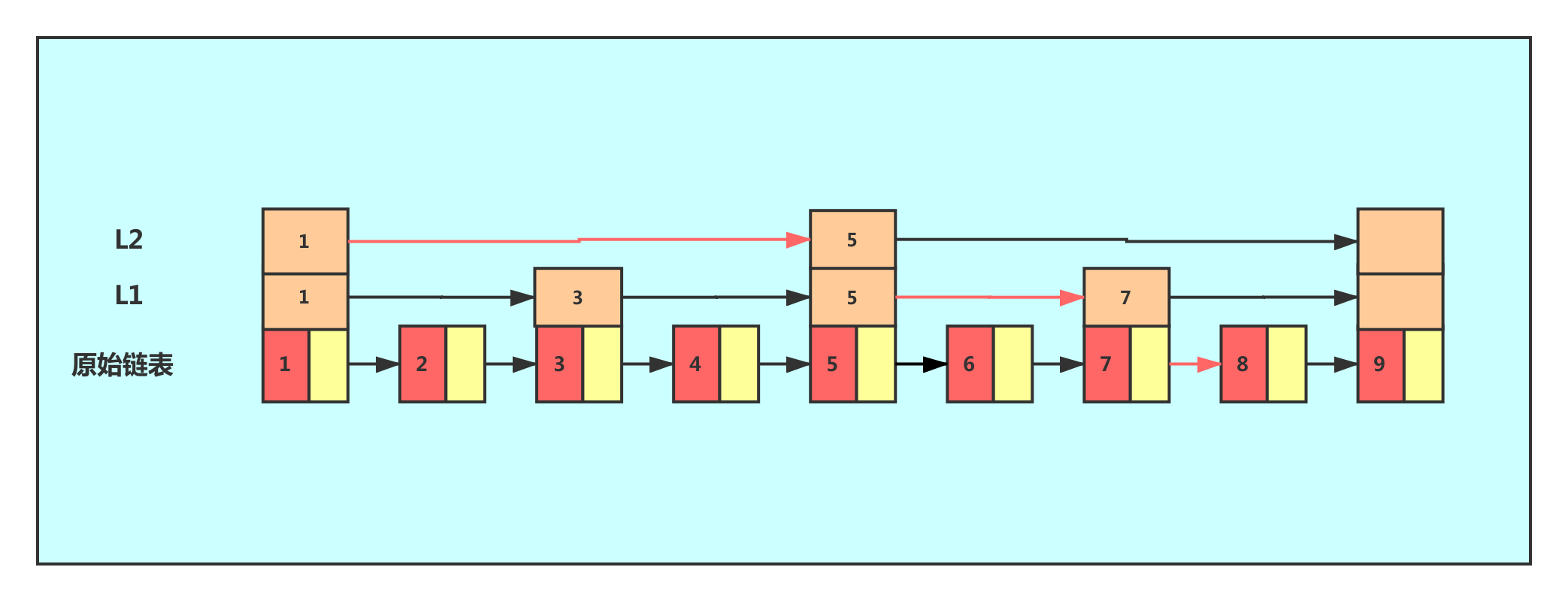
定义:增加了向前指针的链表叫作跳表。
即:可进行二分查找的有序链表,增加了多级索引,提高了对链表数据操作的速度。
哪些数据格式底层:SortSet
ziplist
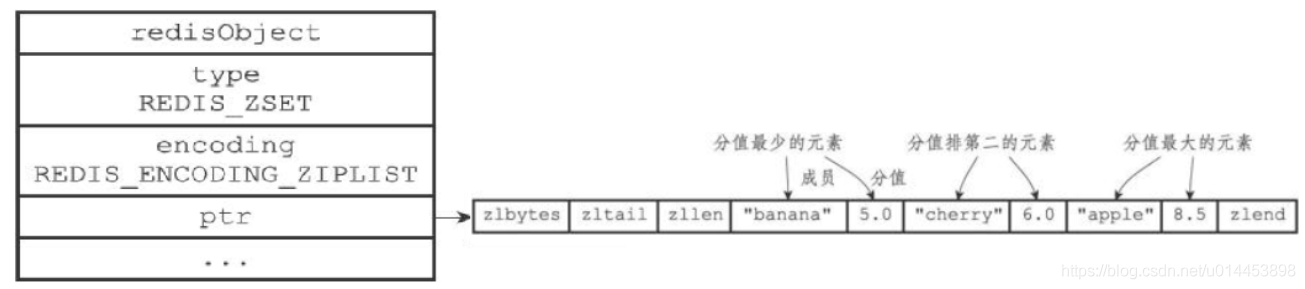
普通单链表
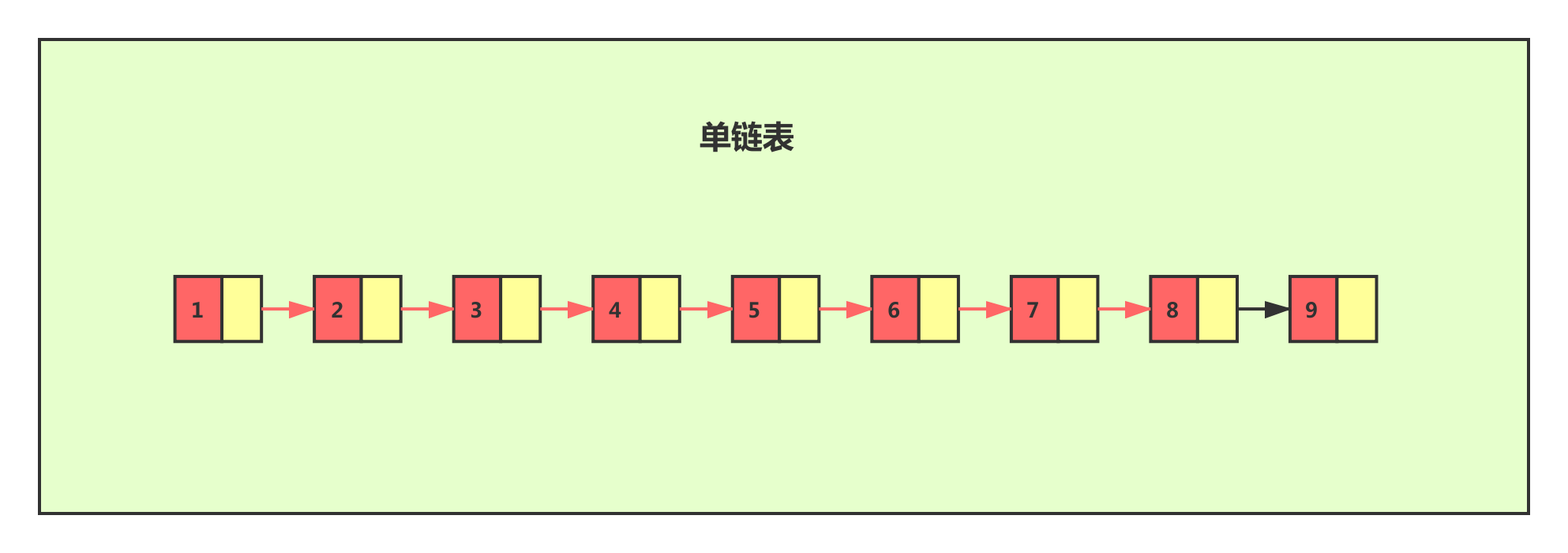
跳跃表

 浙公网安备 33010602011771号
浙公网安备 33010602011771号