
hadoop集群搭建——3/4——hadoop的安装和集群的启停
一、安装hadoop
rz -E #选择jar包,解压 tar -zxvf hadoop-2.7.2.tar.gz -C ../servers/
设置环境变量:
vim /etc/profile
source /etc/profile
末尾追加以下内容:
export HADOOP_HOME=/exports/servers/hadoop-2.7.2 export PATH =$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
环境变量配置完成
二、集群配置
| IP | 主机名 | 环境配置 | 集群部署 |
| 192.168.2.100 | hadoop100 | 关防火墙和selinux,host映射,时钟同步 |
HDFS:NameNode、DataNode YARN:NodeManager |
| 192.168.2.110 | hadoop110 | 关防火墙和selinux,host映射,时钟同步 |
HDFS:DataNode YARN:ResourceManager、NodeManager |
| 192.168.2.120 | hadoop120 | 关防火墙和selinux,host映射,时钟同步 |
HDFS:SecondaryNameNode、DataNode YARN:NodeManager |
etc/hadoop/hadoop-env.sh:
export JAVA_HOME=/exports/servers/jdk1.8.0_202
etc/hadoop/core-site.xml:指定HDFS中NameNode的地址和Hadoop运行时产生文件的存储目录
<!-- 指定HDFS中NameNode的地址 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop100:9000</value>
</property>
<!-- 指定Hadoop运行时产生文件的存储目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/exports/servers/hadoop-2.7.2/data/tmp</value>
</property>
etc/hadoop/hdfs-site.xml:指定HDFS副本的数量,默认为3
<!-- 指定hdfs副本的数量 -->
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<!-- 指定hdfs辅助名称节点主机配置 -->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>hadoop120:50090</value>
</property>
etc/hadoop/yarn-env.sh:
export JAVA_HOME=/exports/servers/jdk1.8.0_202
etc/hadoop/yarn-site.xml:
<!-- Reducer获取数据的方式 -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 指定YARN的ResourceManager的地址 -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop110</value>
</property>
etc/hadoop/mapred-env.sh:
export JAVA_HOME=/exports/servers/jdk1.8.0_202
etc/hadoop/mapred-site.xml:
<!-- 指定MR运行在Yarn上 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
拷贝hadoop到其他主机,更新环境变量并source
三、启动集群
1、集群单点启动
如果集群是第一次启动,需要格式化NameNode
[root@hadoop100 hadoop-2.7.2]# hadoop namenode -format
在hadoop100上启动NameNode
[root@hadoop100 hadoop-2.7.2]# hadoop-daemon.sh start namenode [root@hadoop100 hadoop-2.7.2]# jps
在hadoop100、hadoop110和hadoop120上分别启动DataNode
[root@hadoop100 hadoop-2.7.2]# hadoop-daemon.sh start datanode [root@hadoop110 hadoop-2.7.2]# hadoop-daemon.sh start datanode [root@hadoop120 hadoop-2.7.2]# hadoop-daemon.sh start datanode
退出
[root@hadoop100 hadoop-2.7.2]# sbin/hadoop-daemon.sh stop datanode [root@hadoop100 hadoop-2.7.2]# sbin/hadoop-daemon.sh stop namenode [root@hadoop110 hadoop-2.7.2]# sbin/hadoop-daemon.sh stop datanode [root@hadoop120 hadoop-2.7.2]# sbin/hadoop-daemon.sh stop datanode
2、群起集群
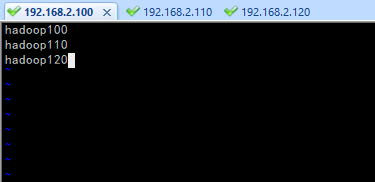
etc/hadoop/slaves:配置slaves(三台都要配)
如果集群是第一次启动,需要格式化NameNode(注意格式化之前,一定要先停止上次启动的所有namenode和datanode进程,然后再删除data和log数据)
[root@hadoop100 hadoop-2.7.2]# bin/hdfs namenode -format
[root@hadoop100 hadoop-2.7.2]# sbin/start-dfs.sh
启动yarn,必须从hadoop110上启动(ResourceManager)
[root@hadoop110 hadoop-2.7.2]# sbin/start-yarn.sh
四、启停总结
1、各个服务组件逐一启动/停止
分别启动/停止HDFS组件
hadoop-daemon.sh start / stop namenode / datanode / secondarynamenode
启动/停止YARN
yarn-daemon.sh start / stop resourcemanager / nodemanager
2、各个模块分开启动/停止(配置ssh是前提)常用
整体启动/停止HDFS
start-dfs.sh / stop-dfs.sh
整体启动/停止YARN
start-yarn.sh / stop-yarn.sh

 浙公网安备 33010602011771号
浙公网安备 33010602011771号