jenkins05-参数化pipeline
- 参数化pipeline:是指可以通过传参来决定pipeline的行为。参数化让写pipeline就像写函数,而函数意味着可重用、更抽象。所以,通常使用参数化pipeline来实现一些通用的pipeline。
- 有两种方法配置参数化pipeline:
- (1)在Jenkins Web上配置(直接生效)
- (2)在pipeline中配置(需要手动执行一次,才能生效)
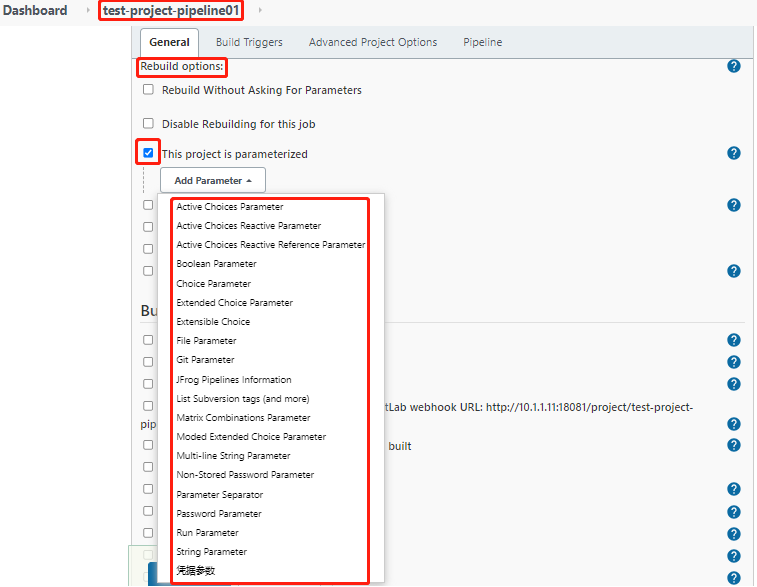
1、parameters指令
- 参数化pipeline是通过parameters指令实现的,parameters指令只能放在pipeline块下。
- 为了满足不同的应用场景,参数化pipeline中的parameters指令支持多种参数类型:
- string:字符串类型。
- text:多行文本类型,换行使用\n。
- booleanParam:布尔类型。
- choice:选择参数类型,使用\n来分隔多个选项。
- file:文件类型,用户可上传文件。但是此类型存在Bug(无法拿到上传后的文件,所以不推荐使用)
- password:密码类型。
1、在pipeline中定义参数
- 可以通过指令生成器(Declarative Directive Generator)生成相应的参数类型。
示例1:
pipeline {
agent any
parameters {
//字符串类型
string defaultValue: '', description: '项目名称', name: 'projectName', trim: false
//选择参数类型
choice choices: ['master', 'release', 'dev'], description: '分支名称', name: 'branchName'
}
stages {
stage('echo') {
steps {
echo "------------------${params.projectName}"
echo "------------------${params.branchName}"
}
}
}
}
2、使新定义的参数生效
- 在Jenkins pipeline新增参数后,至少要手动执行一次,它才会被Jenkins加载生效。生效后,在执行项目时,就可以设置参数值了,如图所示。
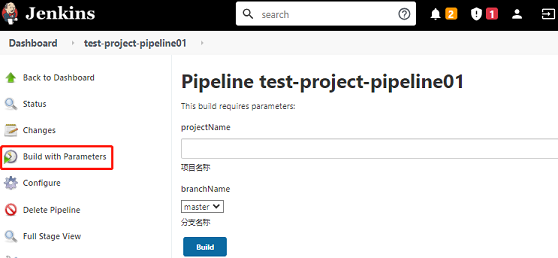
3、使用新定义的参数
- 被传入的参数会放到一个名为params的对象中,在pipeline中可直接使用。params.userFlag就是引用parameters指令中定义的userFlag参数。
2、由另一个pipeline传参并触发
- 既然存在参数化的pipeline,那么就表示可以在一个pipeline中“调用”另一个pipeline。在Jenkins pipeline中可以使用build步骤实现此功能。build步骤是pipeline插件的一个组件,所以不需要另外安装插件,可以直接使用。
- build步骤其实也是一种触发pipeline执行的方式,它与triggers指令中的upstream方式有两个区别:
- (1)build步骤是由上游pipeline使用的,而upstream方式是由下游pipeline使用的。
- (2)build步骤是可以带参数的,而upstream方式只是被动触发,并且没有带参数。
- 上游pipeline触发下游pipeline时,并没有自动带上自身的信息。所以,当下游pipeline需要使用上游pipeline的信息时,上游pipeline信息就要以参数的方式传给下游pipeline。
- 如果我们要调用test-project-pipeline01(即示例1)任务就可以在steps部分这样写。
pipeline {
agent any
stages {
stage('build-other') {
steps {
build( //调用另个pipeline任务,并传递参数
job: 'test-project-pipeline01',
parameters: [
string(name: 'projectName', value: 'project-name-02'),
string(name: 'branchName', value: 'dev')
]
)
echo 'Hello World'
}
}
}
}
- build步骤的基本的两个参数:
- job(必填):目标Jenkins任务的名称。
- parameters(可选):数组类型,传入目标pipeline的参数列表。
- propagate(布尔类型,可选):如果值为true,则只有当下游pipeline的最终构建状态为SUCCESS时,上游pipeline才算成功;如果值为false,则不论下游pipeline的最终构建状态是什么,上游pipeline都忽略。默认值为true。
- quietPeriod(布尔类型,可选):整型,触发下游pipeline后,下游pipeline等待多久执行。如果不设置此参数,则等待时长由下游pipeline确定。单位为秒。
- wait(布尔类型,可选):布尔类型,是否等待下游pipeline执行完成。默认值为true。
- 如果你使用了Folder(cloudbees-folder)插件,那么就需要注意build步骤的job参数的写法了。使用Folder插件,可以让我们像管理文件夹下的文件一样来管理Jenkins项目。我们的Jenkins项目可以创建在这些文件夹下。
- 如果目标pipeline与源pipeline在同一个目录下,则可以直接使用名称。
- 如果不在同一个目录下,则需要指定相对路径,如../sister-folder/downstream,或者指定绝对路径,如/top-level-folder/nested-folder/downstream。
3、使用Conditional BuildStep插件处理复杂的判断逻辑
- 有些场景要求我们根据传入的参数做一些逻辑判断。很自然地,我们想到了在script函数内就可以实现。
pipeline {
agent any
parameters { //定义一个pipeline参数
choice choices: ['master', 'release', 'test'], description: '分支名称', name: 'branchName'
}
stages {
stage('deploy') {
steps {
script {
if( params.branchName == "test" ) { //使用pipeline参数
echo "deploy to test。"
} else {
echo "deploy to dev。"
}
}
}
}
}
}
- 这样写起来很不优雅, Conditional BuildStep(conditional-buildstep)插件,可以让我们像使用when指令一样进行条件判断。
pipeline {
agent any
parameters {
choice choices: ['master', 'release', 'test'], description: '分支名称', name: 'branchName'
}
stages {
stage('deploy test') {
when {
expression { return params.branchName == "test"}
}
steps {
echo "deploy to test。"
}
}
stage('deploy dev') {
when {
expression { return params.branchName != "test"}
}
steps {
echo "deploy to dev。"
}
}
}
}
- 现实中,我们会面对更复杂的判断条件。而expression表达式本质上就是一个Groovy代码块,大大提高了表达式的灵活性。以下是比较常用的例子。
//逻辑与
when {
expression { return A && B}
}
//逻辑或
when {
expression { return A || B}
}
//从文件中取值
when {
expression { return readFile("pom.xml").contains("mycomponent") }
}
//正则表达式
when {
expression { return token ==~/(?i)(Y|YES|T|TRUE)/}
}
4、使用input步骤
- 执行input步骤会暂停pipeline,直到用户输入参数。这是一种特殊的参数化pipeline的方法。
- 可以利用input步骤实现以下两种场景:
- (1)实现简易的审批流程。例如,pipeline暂停在部署前的阶段,由负责人点击确认后,才能部署。
- (2)实现手动测试阶段。在pipeline中增加一个手动测试阶段,该阶段中只有一个input步骤,当手动测试通过后,测试人员才可以通过这个input步骤。
1、input步骤的简单用法
pipeline {
agent any
stages {
stage('Hello') {
steps {
input(message: "发布或暂停")
echo 'Hello World'
}
}
}
}
- (1)如果input步骤只有message参数,则这样写更简洁:input "发布或停止"。
- (2)当pipeline执行到deploy阶段后,就会暂停。
- (3)将鼠标指针移到虚线方块上后,就会出现有提示信息的浮层,如图所示。
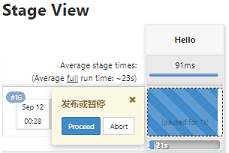
- (4)如果单击“Proceed”按钮,将会进入下一个步骤;如果单击“Abort”按钮,则pipeline中止。
- 不论是通过还是中止,job日志都会记录是谁进行的手动操作。这对审计非常友好。
2、input步骤的复杂用法
- input步骤的参数:
- message:input步骤的提示消息。
- submitter(可选):字符串类型,可以进行操作的用户ID或用户组名,使用“,”分隔,在“,”左右不允许有空格。这在做input步骤的权限控制方面很实用。
- submitterParameter(可选):字符串类型,保存input步骤的实际操作者的用户名的变量名。
- ok(可选):自定义确定按钮的文本。
- parameters(可选):手动输入的参数列表。
- input步骤的返回值类型取决于要返回的值的个数。
- 如果只有一个值,返回值类型就是这个值的类型。
- 如果有多个值,则返回值类型是Map类型。
- Map的key就是每个参数的name属性,比如ENV、myparam都是key。
- 在pipeline外定义了一个变量approvalMap。这是因为定义在阶段内的变量的作用域只在这个阶段中,而input步骤的返回值需要跨阶段使用,所以需要将其定义在pipeline外。这样变量approvalMap的作用域就是整个pipeline了。
//定义一个变量,用于存储input步骤的返回值
def approvalMap
pipeline {
agent any
stages {
stage('pre deploy') {
steps {
script {
approvalMap = input(
message: "准备发布到哪个环境?",
parameters: [
choice(choices: ['dev', 'test'], description: '发布到什么环境', name: 'ENV'),
string(defaultValue: '', description: '', name: 'myparam', trim: false)
],
submitter: "admin, admin2, releaseGroup",
submitterParameter: "APPROVER"
)
}
}
}
stage('deploy') {
steps {
echo "操作者是${approvalMap["APPROVER"]}"
echo "部署的环境是${approvalMap["ENV"]}"
echo "自定义参数是${approvalMap["myparam"]}"
}
}
}
}
3、input与timeout
- input步骤可以与timeout步骤实现超时自动中止pipeline,防止无限等待。
//一小时后不处理就自动中止
pipeline {
agent any
stages {
stage('Hello') {
steps {
timeout(time: 1, unit: "HOURS") {
input(message: "发布或暂停")
}
echo 'Hello World'
}
}
}
}
1
# #

 浙公网安备 33010602011771号
浙公网安备 33010602011771号