jenkins03-Pipeline
1、pipeline简介
- 通常Jenkins pipeline被简称为pipeline。只有安装了pipeline插件,Jenkins才支持pipeline。pipeline代码被写在一个被命名为Jenkinsfile的文本文件中,在同一个代码项目下可以按需创建多个不同名称的Jenkinsfile。
1、pipeline是什么
- Jenkins 1.x只能通过Web界面手动操作来“描述”部署流水线。Jenkins 2.x支持“pipeline as code”了,即可以通过“代码”来描述部署流水线。
- 使用“代码”而不是UI的意义在于:
- 更好地版本化:将pipeline提交到版本库中进行版本控制。
- 更好地协作:pipeline的每次修改对所有人都是可见的。除此之外,还可以对pipeline进行代码审查。
- 更好的重用性:手动操作没法重用,但是代码可以重用。
2、pipeline语法的选择
- Jenkins Pipeline有两种语法:
- 脚本式(Scripted)语法
- 写脚本式pipeline时,很像是(其实就是)在写Groovy代码。可以为用户提供巨大的灵活性和可扩展性,但语法复杂(Groovy语言的学习成本对于(不使用Groovy的)开发团队来说通常是不必要的)。
- 声明式(Declar-ative)语法
- 提供了更简单、更结构化(more opinionated)的语法。
- Jenkins社区推荐使用声明式语法。
- 脚本式(Scripted)语法
- node为根节点的是脚本式语法,pipeline为根节点的是声明式语法。
- pipeline插件从2.5版本开始,同时支持两种格式的语法。
示例1:脚本式语法
node {
def mvnHome
stage('Preparation') {
// 从GitHub存储库获取一些代码
git 'https://github.com/jglick/simple-maven-project-with-tests.git'
// 获取Maven工具(注意:Maven工具必须配置在全局工具配置中)
mvnHome = tool 'maven-3.9.4'
}
stage('Build') {
// 运行maven进行构建
withEnv(["MVN_HOME=$mvnHome"]) {
if (isUnix()) {
sh '"$MVN_HOME/bin/mvn" -Dmaven.test.failure.ignore clean package'
} else {
bat(/"%MVN_HOME%\bin\mvn" -Dmaven.test.failure.ignore clean package/)
}
}
}
stage('Deploy') {
try{
// 执行部署
}catch(err){
currenBuild.result = "FAILURE"
mail subject: "project build failed",
body: "project build error is here: ${env.BUILD_URL}",
from: "xxx@hh.com",
replyTo: "yyy@hh.com",
to: "zzz@hh.com"
throw err
}
}
}
示例2:声明式语法
pipeline {
agent any
stages {
stage('Build') {
steps {
echo 'Building...'
}
}
stage('Test') {
steps {
echo 'Testing...'
}
}
stage('Deploy') {
steps {
echo 'Deploying...'
}
}
}
post {
failure {
mail to: "xxx@hh.com", subject: "The pipeline failed :("
}
}
}
2、pipeline的存放位置
- pipeline可以放在两个位置:
- 直接放在Jenkins Web界面上
- 使用Jenkinsfile,并将其放在相应的代码库(如GitLab的项目)中。
2.1、直接放在Jenkins Web界面上
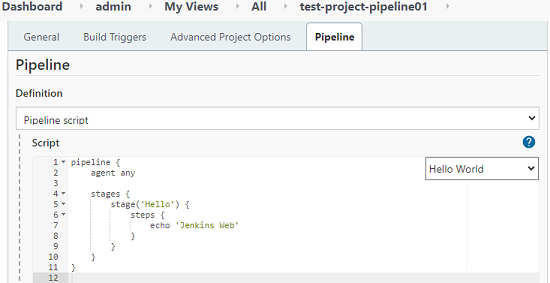
- 直接在Jenkins Web界面上填入pipeline。
- 在实验时可以这么做,但是不推荐,因为这样无法做到pipeline的版本化。
2.2、使用Jenkinsfile
- Jenkinsfile就是一个文本文件,也就是部署流水线概念在Jenkins中的表现形式。像Dockerfile之于Docker。所有部署流水线的逻辑都写在Jenkinsfile中。
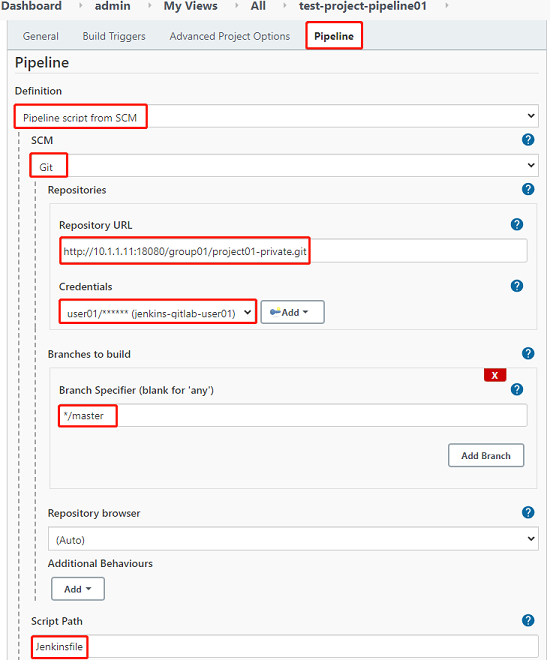
1、在jenkins web界面上指定Jenkinsfile
- 注意,我这里提前设置了链接GitLab的凭据。
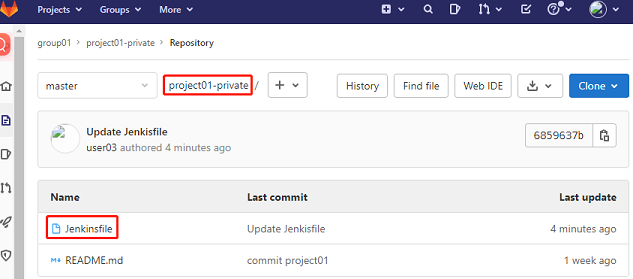
2、将Jenkinsfile放到代码库中
1、Jenkisfile文件
]# cat project01-private/Jenkinsfile
pipeline {
agent any
stages {
stage('Hello') {
steps {
echo 'Jenkinsfile'
}
}
}
}
2、jenkinsfile在代码库中的位置
]# ls -l project01-private/ -rw-r--r-- 1 root root 151 Sep 5 00:59 Jenkinsfile -rw-r--r-- 1 root root 10 Sep 5 00:59 README.md
3、pipeline语法
3.1、必要的Groovy知识
- 虽然学习Jenkins pipeline可以不需要任何Groovy知识,但是学习以下Groovy知识,对于写pipeline会如虎添翼。
- (1)Groovy同时支持静态类型和动态类型。但在定义变量时,习惯使用def关键字,比如def x="abc"、def y=1。
- (2)不像Java,Groovy语句最后的分号不是必需的。
- (3)Groovy中的方法调用可以省略括号, 比如System.out.println "Hello world"。
- (4)支持命名参数
//定义方法
def createName(String givenName, String familyName){
return givenName + " " + familyName
}
//调用方法
createName familyName = "Lee", givenName = "Bruce"
- (5)支持默认参数值
//定义方法
def sayHello(String name = "humans"){
print "hello ${name}"
}
//调用方法
sayHello() //此时括号不能省略
- (6)支持单引号、双引号。双引号支持插值,单引号不支持。
def name = "world"
print "hello ${name}" //结果:hello world
print 'hello ${name}' //结果:hello ${name}
- (7)支持三引号。三引号分为三单引号和三双引号。它们都支持换行,区别在于只有三双引号支持插值。
def name = 'world'
def aString = '''line one
line two
${name}
'''
def bString = """line one
line two
${name}
"""
- (8)闭包的定义方法
//定义闭包
def codeBlock = {print "hello closure"}
//闭包可以当成函数调用
codeBlock() //结果:hello closure
-
- 还可以将闭包看作一个参数传递给另一个方法。
//定义一个pipeline函数,它会接受一个闭包作为参数
def pipeline(closure){
closure()
}
//调用pipeline函数
pipeline(codeBlock)
//如果把闭包定义的语句去掉
pipeline({print "hello closure"})
//由于小括号是非必须的,所以...。(是不是和Jenkins pipeline很像)
pipeline {
print "hello closure"
}
3.2、声明式pipeline的结构
- 声明式pipeline语法说明文档:https://www.jenkins.io/doc/book/pipeline/syntax/
- Jenkins pipeline其实就是基于Groovy语言实现的一种DSL(领域特定语言),用于描述整条流水线是如何进行的。流水线的内容包括执行编译、打包、测试、输出测试报告等步骤。
- pipeline基本结构决定的是pipeline整体流程,但是真正“做事”的还是pipeline中的每一个步骤。步骤是pipeline中已经不能再拆分的最小操作。
- Jenkins pipeline内置了很多步骤。
- 步骤是可插拔的,就像Jenkins的插件一样。并且只需要对现有的插件进行一些修改,就可以在pipeline中被当成一个步骤使用。
- 只要安装了适配Jenkins pipeline的插件,就可以使用其提供的pipeline步骤。
1、声明式pipeline的结构
- 在声明式pipeline中有效的基本语句和表达式遵循与Groovy相同的语法规则,但有以下例外:
- pipeline的顶层必须是一个块(block),例如pipeline{}。
- 没有分号作为语句分隔符,且每行只有一个语句。
- 块只能由节(Sections)、指令(Directives)、步骤容器(Steps)或赋值语句(assignment statements)组成。
- 属性引用语句被视为无参数方法调用。例如,input被视为input()。
- 可以使用声明式指令生成器生成sections和directives。
2、声明式pipeline最简结构
- 列出的每一个节(sections)都是必需的,缺少一个,Jenkins都会报错。
pipeline { //(必须)代表整条流水线,包含整条流水线的逻辑。
agent any //(必须)指定流水线的执行位置(Jenkins agent)。流水线中的每个阶段都必须在某个地方(物理机、虚拟机或Docker容器)执行。
stages { //(必须)流水线中多个阶段(stage)的容器。一个stages部分至少包含一个stage。
stage('Hello') { //(必须)流水线中的阶段,每个阶段都必须有名称。一个stage中有且只能有一个steps。
steps { //(必须)多个具体步骤(step)的容器。一个steps中至少包含一个步骤。
echo 'Hello World' //(必须)具体的步骤
}
}
}
}
3、声明式pipeline复杂结构
1
4、声明式pipeline中的Sections(节)
- Sections通常包含一个或多个指令或步骤。
- 声明式pipeline中的Sections(节)有:agent、post、stages、steps。
4.1、agent(代理)
- agent:指定整个Pipeline或特定阶段的执行位置(Jenkins agent)。流水线中的每个阶段都必须在某个地方(物理机、虚拟机或Docker容器)执行。
- agent可以定义在pipeline或stage部分,在pipeline部分是必须的,在stage部分是可选的。
- agent的参数有:
- any:在任何可用的代理上执行整个Pipeline或特定阶段。例如,agent any
- none:当在Pipeline块的顶层使用时,不会为整个Pipeline运行分配全局代理,并且必须为每个阶段都定义自己的代理。例如,agent none
- label:根据所提供的标签在Jenkins环境中查找可用的代理,并在其上执行整个Pipeline或特定阶段。例如:agent { label 'my-defined-label' },{ label 'my-label1 && my-label2' },agent { label 'my-label1 || my-label2' }
- node:agent { node { label 'labelName' } }的行为与agent { label 'labelName' }相同,但node允许额外的选项(如customWorkspace)。
- docker:使用给定的容器执行整个Pipeline或特定阶段,该容器将动态地配置在预配置为接受基于docker的Pipeline的节点上,或者匹配可选定义的label参数的节点上。docker可以使用args参数,直接传递给docker运行调用的参数(alwaysPull将强制docker拉取,即使映像名称已经存在)。docker还可以使用registryUrl和registryCredentialsId参数指定docker镜像仓库及其凭据。
-
agent { docker 'maven:3.9.3-eclipse-temurin-17' } //或 agent { docker { image 'maven:3.9.3-eclipse-temurin-17' label 'my-defined-label' args '-v /tmp:/tmp' registryUrl 'https://myregistry.com/' registryCredentialsId 'myPredefinedCredentialsInJenkins' } }
-
-
dockerfile:使用源存储库中的Dockerfile构建的容器并在其上执行整个Pipeline或特定阶段。使用这个选项,必须从多分支Pipeline或SCM Pipeline中加载Jenkinsfile。
-
通常Dockerfile文件在源存储库根目录下: agent { dockerfile true }。
-
如果Dockerfile文件在其他目录中,可以使用dir选项:agent { dockerfile { dir 'someSubDir' } }。
-
如果Dockerfile文件的名称是其他名称,可以使用filename选项指定文件名。
-
可以通过additionalBuildArgs选项向docker build命令传递额外的参数,比如agent { dockerfile { additionalBuildArgs '--build-arg foo=bar' } }
-
//相当于"docker build -f Dockerfile.build --build-arg version=1.0.2 ./build/ agent { dockerfile { filename 'Dockerfile.build' dir 'build' label 'my-defined-label' additionalBuildArgs '--build-arg version=1.0.2' args '-v /tmp:/tmp' registryUrl 'https://myregistry.com/' registryCredentialsId 'myPredefinedCredentialsInJenkins' } }
-
- 在Kubernetes集群上创建一个pod,并在这个pod中执行整个Pipeline或特定阶段。使用这个选项,必须从多分支Pipeline或SCM Pipeline中加载Jenkinsfile。Pod模板在kubernetes{}块中定义。
-
 View Code
View Code//创建一个包含Kaniko容器的pod agent { kubernetes { defaultContainer 'kaniko' yaml ''' kind: Pod spec: containers: - name: kaniko image: gcr.io/kaniko-project/executor:debug imagePullPolicy: Always command: - sleep args: - 99d volumeMounts: - name: aws-secret mountPath: /root/.aws/ - name: docker-registry-config mountPath: /kaniko/.docker volumes: - name: aws-secret secret: secretName: aws-secret - name: docker-registry-config configMap: name: docker-registry-config ''' } }
-
- agent的常见选项:
- label:一个字符串。该选项对node、docker和dockerfile参数有效,对于node是必需的。
- customWorkspace:一个字符串。自定义工作区,可以是相对路径(在这种情况下,自定义工作区将位于节点的工作区根目录下),也可以是绝对路径。该选项对node、docker和dockerfile参数有效。
-
agent { node { label 'my-defined-label' customWorkspace '/some/other/path' } }
-
- reuseNode:一个布尔值,默认为false。如果为true,则在Pipeline顶层指定的节点上运行容器,在相同的工作空间中,而不是完全在新节点上运行容器。该选项对docker和dockerfile参数有效,只有在代理上用于单个阶段时才有效。
- args:一个字符串。传递给docker运行的运行时参数。该选项对docker和dockerfile参数有效。

- 当agent配合timeout使用时:
- 定义在pipeline部分,超时计数器在分配代理后启动。
- 定义在stage部分,超时计数器在分配代理之前启动。(即该超时包括代理分配时间,如果代理分配延迟,Pipeline可能会失败。)
agent any
options {
timeout(time: 1, unit: 'SECONDS')
}
4.2、post(附加步骤)
- post:定义了一个或多个附加步骤,这些步骤将在整个Pipeline或特定阶段运行完成时运行(取决于post的位置)。
- post可以定义在pipeline或stage部分,post是可选的(所以并不在pipeline最简结构中)。
- post没有参数。
- 根据pipeline或阶段的完成状态,post部分可以分成多种条件块:
- always:不论当前完成状态是什么,都执行。
- changed:只要当前完成状态与上一次完成状态不同,就执行。
- fixed:当前完成状态为成功,且上一次完成状态为失败或不稳定(unstable),才执行。
- regression:当前完成状态为失败、不稳定或中止(aborted),且上一次完成状态为成功,才执行。
- aborted:当前执行结果是中止状态(一般为人为中止)时执行。
- failure:当前完成状态为失败时执行。
- success:当前完成状态为成功时执行。
- unstable:当前完成状态为不稳定时执行。
- cleanup:清理条件块。不论当前完成状态是什么,在其他所有条件块执行完成后都执行。
- post部分可以同时包含多种条件块。
pipeline {
agent any
stages {
stage('Hello') {
steps {
echo 'Hello World'
}
post { //阶段之后的post
alwasy {
echo "stage post alwasy"
}
}
}
}
post { //整个pipeline之后的post
changed {
echo "pipeline post changed"
}
alwasy {
echo "pipeline post alwasy"
}
success {
echo "pipeline post success"
}
}
}
4.3、stages(阶段容器)
- stages:包含一个或多个stage(阶段:指令的序列。stage至少包含一个指令),stages部分描述了pipeline中的大部分“工作”。
- stages可以定义在pipeline部分,stages是必须的。
- stages没有参数。
4.4、steps(步骤容器)
- steps:定义了在给定stage中执行的一个或多个步骤。
- steps可以定义在stage部分,steps是必须的。
- steps没有参数。
5、声明式pipeline中的Directives(指令)
- 基本结构满足不了现实多变的需求。因此,Jenkins pipeline通过各种指令(directive)来丰富自己。
- 指令可以被理解为对Jenkins pipeline基本结构的补充。
- Jenkins pipeline支持的指令有:
- environment:用于设置环境变量。可以定义在pipeline或stage部分。
- tools:会自动下载并安装指定的工具,并将其加入到PATH变量中。可以定义在pipeline或stage部分。
- input:会暂停pipeline,提示输入内容。可以定义在stage部分。
- options:用于配置Jenkins pipeline本身的选项,比如options{retry(3)}指当pipeline失败时再重试2次。可以定义在pipeline或stage部分。
- parameters:与input不同,parameters是执行pipeline前传入的一些参数。
- triggers:用于定义执行pipeline的触发器。
- when:当满足when定义的条件时,阶段才执行。
- parallel:并行执行多个step。在pipeline插件1.2版本后,parallel开始支持对多个阶段进行并行执行。
- 在使用指令时,需要注意的是每个指令都有自己的“作用域”。如果指令使用的位置不正确,Jenkins将会报错。
5.1、environment(环境变量)
- environment(环境指令)指定了一系列键值对,这些键值对将被定义为所有步骤或特定阶段的步骤的环境变量,这取决于环境指令的位置。
- environment指令支持一个特殊的辅助方法credentials(),它可以在Jenkins环境中通过标识符访问预定义的凭据。
- environment可以定义在pipeline或stage部分,environment是可选的(所以并不在pipeline最简结构中)。
- environment没有参数。
- 支持的凭证类型:
- Secret Text:指定的环境变量将被设置为Secret Text内容。
- Secret File:指定的环境变量将被设置为临时创建的File文件的路径。
- Username and password:指定的环境变量将被设置为username:password,另外这两个环境变量将被自动赋值给MYVARNAME_USR和MYVARNAME_PSW。
- SSH with Private Key:指定的环境变量将被设置为临时创建的SSH密钥文件的路径,另外这两个环境变量将被自动赋值给MYVARNAME_USR和MYVARNAME_PSW(包含密码短语)。
pipeline {
agent any
// 在顶级块中使用的环境指令将应用于所有步骤(steps)。
environment {
CC = 'clang'
}
stages {
stage('Example secret-text') {
// 在阶段(stage)中定义的环境指令,只会应用于该阶段中的步骤。
environment {
AN_ACCESS_KEY = credentials('my-predefined-secret-text')
}
steps {
sh 'printenv'
}
}
stage('Example Username/Password') {
environment {
SERVICE_CREDS = credentials('my-predefined-username-password')
}
steps {
sh 'echo "Service user is $SERVICE_CREDS_USR"'
sh 'echo "Service password is $SERVICE_CREDS_PSW"'
sh 'curl -u $SERVICE_CREDS https://myservice.example.com'
}
}
stage('Example SSH Username with private key') {
environment {
SSH_CREDS = credentials('my-predefined-ssh-creds')
}
steps {
sh 'echo "SSH private key is located at $SSH_CREDS"'
sh 'echo "SSH user is $SSH_CREDS_USR"'
sh 'echo "SSH passphrase is $SSH_CREDS_PSW"'
}
}
}
}
5.2、options(pipeline选项)
- options指令:可以在Pipeline内部配置特定于Pipeline的选项(即使用options指令配置Jenkins pipeline自身)。Pipeline提供了许多这样的选项,比如buildDiscarder,但是它们也可以由插件提供,比如timestamps(时间戳)。
- options可以定义在pipeline或stage(有一定限制)部分,options是可选的(所以并不在pipeline最简结构中)。
- options没有参数。
- 注意,在stage部分定义的options指令,会在进入代理或检查任何when条件之前将调用。
5.2.1、常用options指令
1、buildDiscarder
- 保存最近历史构建记录的数量。当pipeline执行完成后,会在硬盘上保存制品和构建执行日志,如果长时间不清理会占用大量空间,设置此选项后会自动清理。
- 可以定义在pipeline部分。
- 例如,options { buildDiscarder(logRotator(numToKeepStr: '1')) }
2、checkoutToSubdirectory
- Jenkins从版本控制库拉取源码时,默认检出到工作空间的根目录中,此选项可以指定检出到工作空间的子目录中。
- 可以定义在pipeline部分。
- 例如,options { checkoutToSubdirectory('foo') }
3、disableConcurrentBuilds
- 同一个pipeline,Jenkins默认是可以同时执行多次的。此选项是为了禁止同一个pipeline同时被执行。
- 可以定义在pipeline部分。
//当已经有一个正在执行的构建时,新的构建会排队
options {
disableConcurrentBuilds()
}
//中止正在运行的构建并开始新的构建。
options {
disableConcurrentBuilds(abortPrevious: true)
}
4、newContainerPerStage
- 当agent为docker或dockerfile时,指定在同一个Jenkins节点上,每个stage都分别运行在一个新的容器中,而不是所有stage都运行在同一个容器中。
- 可以定义在pipeline部分。
- 例如,options { newContainerPerStage() }
5、retry
- 当发生失败时进行重试,可以指定整个pipeline的重试次数。需要注意的是,这个次数是指总次数,包括第1次失败。
- 可以定义在pipeline或stage部分。
- 例如,options { retry(3) }
6、timeout
- 如果pipeline执行时间过长,超出了设置的timeout时间,Jenkins将中止pipeline。单位有:SECONDS(秒)、MINUTES(分)、HOURS(小时)
- 可以定义在pipeline或stage部分。
- 例如,options { timeout(time: 1, unit: 'HOURS') }
5.2.2、其他options指令
1、disableResume
- 如果控制器重新启动,不允许管道恢复。
- 可以定义在pipeline部分。
- 例如,options { disableResume() }
2、overrideIndexTriggers
- 允许重写分支索引触发器的默认处理。
- 可以定义在pipeline部分。
// 如果在多分支或组织标签处禁用分支索引触发器,可以仅为此作业启用分支索引触发器。
options { overrideIndexTriggers(true) }
// 否则,仅为该作业禁用分支索引触发器。
options { overrideIndexTriggers(false) }
3、preserveStashes
- 保留完成构建的存储,用于阶段重新启动。
- 可以定义在pipeline部分。
// 保存最近完成的构建的存储
options { preserveStashes() }
// 保存最近完成的五个构建的存储
options { preserveStashes(buildCount: 5) }
4、quietPeriod
- 为Pipeline设置安静周期(以秒为单位),覆盖全局默认值。
- 可以定义在pipeline部分。
- 例如,options { quietPeriod(30) }
5、skipDefaultCheckout
- 默认情况下,在代理指令(agent directive)中跳过从源代码控制签出代码。
- 可以定义在pipeline或stage部分。
- 示例,options { skipDefaultCheckout() }
6、skipStagesAfterUnstable
- 一旦构建状态变为不稳定(UNSTABLE),就跳过各个阶段。
- 可以定义在pipeline部分。
- 示例,options { skipStagesAfterUnstable() }
7、timestamps
- 在Pipeline运行生成的所有控制台输出前加上该行发出的时间。
- 可以定义在pipeline或stage部分。
- 示例,options { timestamps() }
8、parallelsAlwaysFailFast
- 将管道中所有后续并行阶段的failfast设置为true。
- 可以定义在pipeline部分。
- 示例,options { parallelsAlwaysFailFast() }
9、disableRestartFromStage
- 完全禁用在经典Jenkins UI和蓝海中可见的“重新启动”选项。
- 可以定义在pipeline部分,不能定义在stage部分。
- 例如,options { disableRestartFromStage() }
5.3、parameters(参数)
- parameters指令:提供了一个参数列表,用户在触发Pipeline时应该提供这些参数。这些用户指定参数的值可以通过params对象提供给管道步骤。
- 根据参数类型,每个参数都有一个Name和Value。当构建开始时,这些信息被导出为环境变量,从而允许构建配置的后续部分访问这些值。例如,在POSIX shell(如bash和ksh)中使用${PARAMETER_NAME}语法,在PowerShell中使用${Env:PARAMETER_NAME}语法,或在Windows cmd.exe中使用%PARAMETER_NAME%语法。
- parameters可以定义在pipeline部分,parameters是可选的(所以并不在pipeline最简结构中)。且parameters只能出现一次。
- parameters没有参数。
1、string
- 字符串类型的参数。例如,parameters { string(name: 'DEPLOY_ENV', defaultValue: 'staging', description: '') }
2、text
- 文本类型的参数,可以包含多行。例如,parameters { text(name: 'DEPLOY_TEXT', defaultValue: 'One\nTwo\nThree\n', description: '')
3、booleanParam
- 布尔类型的参数。例如,parameters { booleanParam(name: 'DEBUG_BUILD', defaultValue: true, description: '') }
4、choice(选择)
- 一个枚举的参数列表,第一个值是默认值。例如,parameters { choice(name: 'CHOICES', choices: ['one', 'two', 'three'], description: '') }
5、password
- 密码参数。例如,parameters { password(name: 'PASSWORD', defaultValue: 'SECRET', description: 'A secret password') }
pipeline {
agent any
parameters {
string(name: 'PERSON', defaultValue: 'Mr Jenkins', description: 'Who should I say hello to?')
text(name: 'BIOGRAPHY', defaultValue: '', description: 'Enter some information about the person')
booleanParam(name: 'TOGGLE', defaultValue: true, description: 'Toggle this value')
choice(name: 'CHOICE', choices: ['One', 'Two', 'Three'], description: 'Pick something')
password(name: 'PASSWORD', defaultValue: 'SECRET', description: 'Enter a password')
}
stages {
stage('Example') {
steps {
echo "Hello ${params.PERSON}"
echo "Biography: ${params.BIOGRAPHY}"
echo "Toggle: ${params.TOGGLE}"
echo "Choice: ${params.CHOICE}"
echo "Password: ${params.PASSWORD}"
}
}
}
}
5.4、triggers(触发器)
- triggers指令:定义了自动触发管道的方式。对于与GitHub或BitBucket等源集成的管道,可能不需要触发器,因为基于webhook的集成可能已经存在。
- 目前可用的触发器有:
- cron:定时执行pipeline
- pollSCM:定时轮询代码仓库,如果有变化就执行pipeline
- upstream:由上游任务触发
- triggers可以定义在pipeline部分,triggers是可选的(所以并不在pipeline最简结构中)。且triggers只能出现一次。
- triggers没有参数。
// 定时触发器
triggers { cron('H */4 * * 1-5') }.
// 定时轮询代码仓库的触发器
triggers { pollSCM('H */4 * * 1-5') }
// 由上游任务触发的触发器(接受以逗号分隔的作业字符串和阈值)
triggers { upstream(upstreamProjects: 'job1,job2', threshold: hudson.model.Result.SUCCESS) }
示例:
pipeline {
agent any
triggers {
cron('H */4 * * 1-5')
}
stages {
stage('Example') {
steps {
echo 'Hello World'
}
}
}
}
5.5、stage(阶段)
- 每个stages中至少有一个stage,每个stage中应该包含一个steps节、一个可选代理(agent)节或其他特定于stage的指令。
- stage可以定义在stages部分,stage是必须的。
- stage有一个必选参数,即该阶段的名称。
- 实际上,管道完成的所有实际工作都将被封装在一个或多个阶段(stage)指令中。
pipeline {
agent any
stages {
stage('Example') {
steps {
echo 'Hello World'
}
}
}
}
5.6、tools(工具)
- 定义要自动安装并放在PATH上的工具。如果指定代理none,则忽略此选项。
- tools可以定义在pipeline或stage部分,tools是可选的(所以并不在pipeline最简结构中)。
- tools没有参数。
- 目前支持的工具有:
- maven
- jdk
- gradle
pipeline {
agent any
tools {
maven 'apache-maven-3.0.1'
}
stages {
stage('Example') {
steps {
sh 'mvn --version'
}
}
}
}
5.7、input(输入语句)
- 执行input步骤会暂停pipeline,直到用户输入参数。
- input的参数:
- message(必须的):提示信息。
- id:输入的可选标识符。默认值是基于阶段(stage)名称的。
- ok:自定义确定按钮的文本。
- submitter:可以进行操作的用户ID或用户组名,使用“,”分隔,在“,”左右不允许有空格。这在做input步骤的权限控制方面很实用。默认允许任何用户。
- submitterParameter:保存input步骤的实际操作者的用户名的变量名。
- parameters:手动输入的参数列表。
pipeline {
agent any
stages {
stage('Example') {
input {
message "Should we continue?"
ok "Yes, we should."
submitter "alice,bob"
parameters {
string(name: 'PERSON', defaultValue: 'Mr Jenkins', description: 'Who should I say hello to?')
}
}
steps {
echo "Hello, ${PERSON}, nice to meet you."
}
}
}
}
5.8、when(条件判断)
- when指令允许管道根据给定的条件决定是否执行阶段。when指令必须包含至少一个条件。
- 如果when指令包含多个条件,则所有子条件必须返回true才能执行阶段。这与将子条件嵌套在allOf条件中的情况相同。
- 如果使用anyOf条件,请注意,一旦发现第一个条件为“true”,就会跳过剩余的测试。
- 可以使用嵌套条件来构建更复杂的条件结构:not、allOf或anyOf。嵌套条件可以嵌套到任意深度。
- when可以定义在stage部分,when是可选的(所以并不在pipeline最简结构中)。
- when没有参数。
示例:
pipeline { agent any stages { stage('Example 1') { steps { echo 'Hello World 111' } } stage('Example 2') { when { branch 'production' } steps { echo 'Hello World 222' } } stage('Example 3') { when { branch 'production' environment name: 'DEPLOY_TO', value: 'production' } steps { echo 'Hello World 333' } } stage('Example 4') { when { allOf { branch 'production' environment name: 'DEPLOY_TO', value: 'production' } } steps { echo 'Hello World 444' } } stage('Example 5') { when { branch 'production' anyOf { environment name: 'DEPLOY_TO', value: 'production' environment name: 'DEPLOY_TO', value: 'staging' } } steps { echo 'Hello World 555' } } stage('Example 666') { when { expression { BRANCH_NAME ==~ /(production|staging)/ } anyOf { environment name: 'DEPLOY_TO', value: 'production' environment name: 'DEPLOY_TO', value: 'staging' } } steps { echo 'Hello World 666' } } stage('Example 7') { agent { label "some-label" } when { beforeAgent true branch 'production' } steps { echo 'Hello World 777' } } stage('Example 8') { when { beforeInput true branch 'production' } input { message "Deploy to production?" id "simple-input" } steps { echo 'Hello World 888' } } stage('Example 9') { when { beforeOptions true branch 'testing' } options { lock label: 'testing-deploy-envs', quantity: 1, variable: 'deployEnv' } steps { echo "Deploying to ${deployEnv}" } } } }
5.8.1、内置条件
1、branch
- 执行正在构建的分支与给定的分支模式(ANT风格的通配符)匹配时,则执行该阶段。例如,when { branch 'master' }。注意,这只适用于多分支管道。
- 可以使用参数comparator指定匹配模式:
- EQUALS:简单的字符串比较
- GLOB(默认值):ANT风格的通配符
- REGEXP:正则表达式
when { branch pattern: "release-\\d+", comparator: "REGEXP"}
2、buildingTag
- 当正在构建是构建标记时才执行该阶段。例如,when { buildingTag() }
3、changelog
- 如果构建的SCM变更日志包含给定的正则表达式模式,则执行该阶段。例如,when { changelog '.*^\\[DEPENDENCY\\] .+$' }
4、changeset
- 如果构建的SCM变更集包含一个或多个与给定模式匹配的文件,则执行该阶段。示例,when { changeset "**/*.js" }
- 可以使用参数comparator指定匹配模式:
- EQUALS:简单的字符串比较
- GLOB(默认值):ANT风格的通配符,不区分大小写(可以使用caseSensitive参数关闭)。
- REGEXP:正则表达式
when { changeset pattern: ".TEST\\.java", comparator: "REGEXP" }
when { changeset pattern: "*/*TEST.java", caseSensitive: true }
5、changeRequest
- 如果当前构建是针对“变更请求”(也称为GitHub和Bitbucket上的Pull request, GitLab上的Merge request, Gerrit中的change,等等),则执行该阶段。当不传递任何参数时,阶段在每个更改请求上运行。例如, when { changeRequest() }。
- 通过向变更请求添加带有参数的过滤器属性,可以使阶段仅在匹配的变更请求上运行。可能的属性有id、target、branch、fork、url、title、author、authorDisplayName和authorremail。每一个都对应一个CHANGE_*环境变量。例如,when { changeRequest target: 'master' }
- 可以使用参数comparator指定匹配模式:
- EQUALS(默认值):简单的字符串比较
- GLOB:ANT风格的通配符
- REGEXP:正则表达式
when { changeRequest authorEmail: "[\\w_-.]+@example.com", comparator: 'REGEXP' }
6、environment
- 当指定的环境变量设置为给定值时,则执行该阶段。例如,when { environment name: 'DEPLOY_TO', value: 'production' }。
7、equals
- 当期望值等于实际值时,则执行的阶段。例如,when { equals expected: 2, actual: currentBuild.number }
8、expression
- 当指定的Groovy表达式求值为true时,则执行该阶段。例如,when { expression { return params.DEBUG_BUILD } }
- 注意,当从表达式返回字符串时,必须将它们转换为布尔值或返回null以求值为false。简单地返回“0”或“false”仍然会计算为“true”。
9、tag
- 如果TAG_NAME变量与给定的模式匹配,则执行阶段。例如,when { tag "release-*" }提供一个空模式时,如果TAG_NAME变量存在,就会执行该阶段(与buildingTag()相同)。
- 可以使用参数comparator指定匹配模式:
- EQUALS:简单的字符串比较
- GLOB(默认值):ANT风格的通配符
- REGEXP:正则表达式
when { tag pattern: "release-\\d+", comparator: "REGEXP"}
10、not
- 嵌套条件为false时,则执行该阶段。必须包含一个条件。例如,when { not { branch 'master' } }
11、allOf
- 所有嵌套条件为真时,则执行该阶段。必须包含至少一个条件。例如,when { allOf { branch 'master'; environment name: 'DEPLOY_TO', value: 'production' } }
12、anyOf
- 当至少有一个嵌套条件为真时,则执行该阶段。必须包含至少一个条件。例如,when { anyOf { branch 'master'; branch 'staging' } }
13、triggeredBy
- 由给定的参数触发当前构建时,则执行该阶段。
when { triggeredBy 'SCMTrigger' }
when { triggeredBy 'TimerTrigger' }
when { triggeredBy 'BuildUpstreamCause' }
when { triggeredBy cause: "UserIdCause", detail: "vlinde" }
5.8.2、when与其他指令
1、when与agent
- 如果在某个阶段定义了when条件,默认情况下会先在进入该阶段的代理,再计算when条件。
- 可以在when块中指定beforeAgent选项来更改。如果beforeAgent设置为true,则先计算when条件,并且只有当when的条件值为true时才会进入代理。
2、when与input
- 如果定义了某个阶段的when条件,默认情况下先执行input指令,再计算when条件。
- 可以在when块中指定beforeInput选项来更改。如果beforeInput设置为true,则先计算when条件,并且只有当when条件值为true时才会执行输入。
- beforeInput true优先于beforeAgent true。
3、when与options
- 如果定义了某个阶段的when条件,默认情况下会先执行options指令,再计算when条件。
- 可以在when块中指定beforeOptions选项来更改。如果beforeOptions设置为true,则先计算when条件,并且只有当when条件值为true时才会执行options指令。
- beforeOptions true优先于beforeInput true和beforeAgent true。
6、声明式pipeline中的Steps(步骤)
6.1、pipeline内置基础步骤
- pipeline步骤:https://www.jenkins.io/doc/pipeline/steps
6.1.1、基础步骤(Basic Steps)
- echo:将信息输出到控制台。
- 支持的参数有:
- message(String):要输出的信息
- 支持的参数有:
- deleteDir:删除当前目录
- deleteDir是一个无参步骤。通常它与dir步骤一起使用,用于删除指定目录下的内容。
- fileExists:判断文件或目录是否存在,返回true或false。
- 支持的参数有:
- file(String):文件路径
- 支持绝对路径和相对路径。当使用相对路径时,它是相对于当前工作目录的。
- Unix和Windows路径分割符都可以使用:/
- file(String):文件路径
- 支持的参数有:
//脚本语法 stage ('Check for existence of index.html') { agent any # Could be a top-level directive or a stage level directive steps { script { if (fileExists('src/main/resources/index.html')) { echo "File src/main/resources/index.html found!" } } } } //分隔符 node('Linux') { if (fileExists('/usr/local/bin/jenkins.sh')) { sh '/usr/local/bin/jenkins.sh' } } node('Windows') { if (fileExists('C:/jenkins.exe')) { bat 'C:/jenkins.exe' } }
- isUnix:判断是否为类UNIX系统
- 如果当前pipeline运行在一个类UNIX系统上,则返回true。
- pwd:返回当前目录
- pwd步骤与Linux的pwd命令一样,返回当前目录。
- 支持的参数有:
- tmp(boolean, 可选):默认值是false。如果参数值为true,则返回与当前目录关联的临时目录。
- writeFile:将内容写入指定文件中
- 支持的参数有:
- file(String):文件路径,可以是绝对路径,也可以是相对路径。
- text(String):要写入的文件内容。
- encoding(String, 可选):目标文件的编码。默认使用操作系统默认的编码。如果是Base64的数据,则可以使用Base64编码。
- 支持的参数有:
- readFile:读取文件内容
- 支持的参数有:
- file(String):文件路径,可以是绝对路径,也可以是相对路径。
- encoding(String, 可选):读取文件时使用的编码。
- 支持的参数有:
- stash:保存临时文件
- stash步骤可以保存一组文件以供在同一Pipeline中的其他步骤或阶段使用(任何节点/工作空间)。如果整个pipeline的所有阶段在同一台机器上执行,stash步骤是多余的。所以,stash通常是要跨Jenkins node使用的。
- 默认情况下,在Pipeline运行结束时丢弃存储的文件。其他插件可能会更改此行为以延长存储时间。例如,声明式管道包含一个preserveStashes()选项,允许保留运行时的存储,并在重新启动运行时使用。
- 一个Pipeline运行的缓存在其他Pipeline或其他作业中不可用。
- stash步骤会将文件存储在tar文件中,对于大文件的stash操作将会消耗Jenkins master的计算资源。Jenkins官方文档推荐,当文件大小为5∼100MB时,应该考虑使用其他替代方案。
- 支持的参数有:
- name(String):保存文件的集合的唯一标识。
- allowEmpty(boolean, 可选):允许stash内容为空。
- excludes(String, 可选):将哪些文件排除(ant风格)。如果排除多个文件,则使用逗号分隔。如果为空代表不排除任何文件。
- includes(String, 可选):包含哪些文件(ant风格)。如果要添加多个表达式,可以使用逗号分隔。如果为空代表当前文件夹下的所有文件。
- useDefaultExcludes(boolean, 可选):默认为true。如果为true,则代表使用Ant风格路径默认排除文件列表。
- unstash:取出之前stash的文件
- 支持的参数有:
- name(String):先前保存的存储库的名称。
- 支持的参数有:
//stash步骤在master节点上执行,而unstash步骤在node1节点上执 pipeline { agent none stages { stage('stash') { agent {label "master"} steps { writeFile(file: "a.txt", text: "${env.BUILD_NUMBER}") stash(name: "abc", includes: "a.txt") } } stage('unstash') { agent {label "node1"} steps { unstash("abc") script { def content = readFile("a.txt") echo "${content}" } } } } }
- error:主动报错,中止当前pipeline
- error步骤的执行类似于抛出一个异常。
- 支持的参数有:
- message(String)
- 通常省略参数:error("there's an error")。
- tool:使用预定义的工具
- 如果在Global Tool Configuration(全局工具配置)中配置了工具,可以通过tool步骤得到工具路径。
- 支持的参数有:
- name(Strin):工具名称。
- type(String, 可选):工具类型,指该工具安装类的全路径类名
- 每个插件的type值都不一样,而且绝大多数插件的文档根本不写type值。除了到该插件的源码中查找,还有一种方法可以快速找到type值,就是前往Jenkins pipeline代码片段生成器中生成该tool步骤的代码即可。
- timeout:代码块超时时间
- 为timeout步骤块内运行的代码设置超时时间限制。如果超时,将抛出一个org.jenkinsci.plugins.workflow.steps.FlowInterruptedException异常,导致中止构建(除非它被捕获并以某种方式处理)。。
- 支持如下参数:
- time(int):超时时间。
- unit(可选):时间单位,支持的值有NANOSECONDS、MICROSECONDS、MILLISECONDS、SECONDS、MINUTES(默认)、HOURS、DAYS。
- activity(boolean, 可选):如果值为true,则只有当日志没有活动后,才真正算作超时。
- waitUntil:等待条件满足
- 不断重复waitUntil块内的代码,直到条件为true。但waitUntil不负责处理块内代码的异常,遇到异常时直接向外抛出。waitUntil步骤最好与timeout步骤共同使用,避免死循环。
- 支持如下参数:
- initialRecurrencePeriod(long, 可选):设置重试之间的初始等待时间(以毫秒为单位)。默认为250ms。每次失败将减少尝试之间的延迟,最多可达15秒。
- quiet(Boolean, 可选):如果为true,则该步骤不会在每次检查条件时记录一条消息。默认为false。
timeout(time: 30, unit: 'SECONDS') { waitUntil { script { def r = sh(script: 'curl http://exmaple', returnStatus: true) return(r == 0) } } }
- retry:重复执行块
- 如果在其代码块执行期间发生任何异常,则重试该块(最多N次)。如果在最后一次尝试时发生异常,那么它将导致终止构建(除非它被捕获并以某种方式处理)。构建的用户中止不会被捕获。同时,在执行retry的过程
- 中,用户是无法中止pipeline的。
- 支持如下参数:
- count(int):可以重试的最多次数。
- conditions(可选):应该重试该块的条件。如果没有匹配,块将失败。如果没有指定的条件,除了用户中止的情况外,该块将总是被重试。
- sleep:让pipeline休眠一段时间
- 支持的参数有:
- time(int):休眠时间。
- unit(可选):时间单位,支持的值有NANOSECONDS、MICROSECONDS、MILLISECONDS、SECONDS(默认)、MINUTES、HOURS、DAYS
- 支持的参数有:
6.2.2、节点与进程(Nodes and Processes)
- dir:切换目录
- pipeline默认工作在工作空间目录下,dir步骤可以切换到其他目录。
- dir块中的任何步骤都将使用该目录作为当前目录,而且任何相对路径都会使用它作为基础路径。
- 支持的参数有:
- path(String):目录路径
dir("/var/logs") {
deleteDir
}
- sh:执行shell命令
- 支持的参数有:
- script(String):要执行的shell脚本,可以是多行。通常在类UNIX系统上。
- 可以指定解释器(如#!/usr/bin/perl),默认使用-xe标志运行系统默认的shell(您可以指定set +e和/或set +x来禁用它们)。
- encoding(String, 可选):脚本执行后输出日志的编码,默认是脚本运行所在系统的编码。
- returnStatus(boolean, 可选):脚本默认返回的是状态码,如果是一个非零的状态码,将导致该步骤失败,并引发pipeline执行失败。如果returnStatus为true,则不论状态码是什么,pipeline的执行都不会受影响。
- returnStdout(boolean, 可选):如果为true,则任务的标准输出将作为步骤的返回值,而不是打印到构建日志中(如果有错误,则依然会打印到日志中)。
- label(String, 可选):要在pipeline步骤视图中显示的标签和步骤的详细信息,而不是步骤类型。
- script(String):要执行的shell脚本,可以是多行。通常在类UNIX系统上。
- returnStatus与returnStdout参数一般不会同时使用,因为返回值只能有一个。如果同时使用,则只有returnStatus参数生效。
- 支持的参数有:
- bat、powershell
- bat步骤执行的是Windows的批处理命令。powershell步骤执行的是PowerShell脚本,支持3+版本。
- 这两个步骤支持的参数与sh步骤的一样。
6.2、在声明式pipeline中使用脚本
- 不能直接在steps块中写if-else,或者定义一个变量,否则Jenkins都会报错。也就是不能直接在steps块中写Groovy代码。
- 为了解决这个问题,Jenkins pipeline专门提供了一个script步骤,可以在script步骤中像写代码一样写pipeline逻辑。(在script块中的其实就是Groovy代码)
- 大多数时候,是不需要使用script步骤的。如果在script步骤中写了大量的逻辑,则说明应该把这些逻辑拆分到不同的阶段,或者放到共享库中。
pipeline {
agent any
stages {
stage('Hello') {
steps {
script { //在script步骤中写Groovy代码
def browsers = ["chrome", "firefox"]
for (int i = 0; i < browsers.size(); ++i) {
echo "Testing the ${browsers[i]} browser."
}
}
}
}
}
}
1
4、环境变量
- 环境变量可以分为Jenkins内置变量和自定义变量。
4.1、Jenkins内置变量
- 在pipeline执行时,可以通过一个名为env的全局变量,将Jenkins内置环境变量暴露出来。
- 使用内置环境变量的三种方法:
- 默认env的属性可以直接在pipeline中引用。所以,三种方法都是合法的。但是不推荐方法三,因为出现变量冲突时,非常难查问题。
pipeline {
agent any
stages {
stage('Example') {
steps {
echo "Running ${env.BUILD_NUMBER} on ${env.JENKINS_URL}"
echo "Running $env.BUILD_NUMBER on $env.JENKINS_URL"
echo "Running $BUILD_NUMBER on $JENKINS_URL"
}
}
}
}
- env变量都有哪些可用属性呢?通可以过访问<Jenkins master的地址>/pipeline-syntax/globals来获取完整列表。在列表中,当一个变量被声明为“For a multibranch project”时,代表只有多分支项目才会有此变量。
- 几个常用的内置变量(即全局变量env的属性):
- BUILD_NUMBER:当前构建的构建号,一个累加的数字。在打包时,它可作为制品名称的一部分,比如server-2.jar。
- BRANCH_NAME:对于多分支项目,这将被设置为正在构建的分支的名称。当需要根据不同的分支做不同的事情时就会用到,比如通过代码将release分支发布到生产环境中、master分支发布到测试环境中。
- BUILD_URL:当前构建的页面URL。如果构建失败,则需要将失败的构建链接放在邮件通知中,这个链接就可以是BUILD_URL。
- GIT_BRANCH:通过git拉取的源码构建的项目才会有该变量。
- 在使用env变量时,需要注意不同类型的项目,env变量所包含的属性及其值是不一样的。比如普通pipeline任务中的GIT_BRANCH变量的值为origin/master,而在多分支pipeline任务中GIT_BRANCH变量的值为master。
- 小技巧:在调试pipeline时,可以在pipeline的开始阶段将env变量的属性值都打印出来:sh 'printenv'。
4.2、自定义全局环境变量
- 自定义的全局环境变量可以让Jenkins的所有pipeline项目使用。
- Jenkins --> Manage Jenkins --> Configure System --> Global properties --> 勾选“Environment variables” --> 单击“Add”按钮
- 通过单击“Add”按钮,可以添加多个全局环境变量。
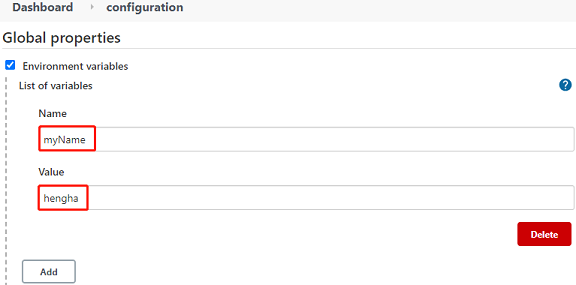
- 自定义全局环境变量会被加入env属性列表中,因此使用自定义全局环境变量与使用Jenkins内置变量的方法一样:${env.myName}。
4.3、自定义pipeline环境变量
- 当pipeline变得复杂时,可能就要定义自己的环境变量。声明式pipeline提供可以通过environment指令自定义自己的变量。
- environment指令可以定义在pipeline中,变量的作用域是整个pipeline;也可以定义在stage中,此时变量的作用域仅是该阶段。
- 但是这些变量都不可以跨pipeline,比如pipeline A访问不到pipeline B的变量。在pipeline之间共享变量可以通过参数化pipeline来实现。
pipeline {
agent any
environment { //作用范围是整个pipeline
myName = "hangha_pipeline"
}
stages {
stage('Example') {
environment { //作用范围仅是这个stage
myAge = "12"
}
steps {
echo "my name is ${myName}, my age is ${myAge}"
sh 'printenv'
}
}
}
}
- 在实际工作中,还会遇到一个环境变量引用另一个环境变量的情况。在environment中可以这样定义:
environment {
myName = "hangha"
myAge = "12"
myNameAge = "${myName}-${myAge}"
}
- 如果在environment中定义的变量与env中的变量重名,那么env中的变量值将会被覆盖掉。
- 小技巧:为避免变量名冲突,可以根据实际情况,在变量名前加上前缀,比如__server_name,__就是前缀。
5、tools(构建工具)
- 构建是指将源码转换成一个可以使用的二进制程序的过程。这个过程可以包括但不限于这几个环节:下载依赖、编译、打包。
- 构建过程的输出,比如一个jar包,我们称为制品(有些书籍也称之为产出物)。而管理制品的仓库,称为制品库。
- 当Jenkins执行到tools时,tools指令可以自动下载并安装所指定的构建工具,并将其加入PATH变量中。这样,就可以在sh步骤里直接使用工具了。但在agent none的情况下不会生效。
- tools指令默认支持3种工具:JDK、Maven、Gradle。
5.1、使用tools段
- Jenkins pipeline的tools指令默认就支持Maven。所以,使用Maven只需要两步。
- (1)进入Jenkins --> Manage Jenkins --> Global Tool Configuration --> Maven页,配置maven工具。
- 请注意Name的值为mvn-3.9.4,接下来会在pipeline中用到这个值。
- (2)在pipeline中指定Maven版本,并使用mvn命令。
- (1)进入Jenkins --> Manage Jenkins --> Global Tool Configuration --> Maven页,配置maven工具。
pipeline {
agent any
tools {
maven "maven-3.9.4"
}
stages {
stage('Example') {
steps {
sh 'mvn -v'
sh 'printenv'
}
}
}
}
5.2、利用环境变量支持更多的构建工具
- 一般搭建开发环境的做法是:首先在机器上安装好构建工具,然后将这个构建工具所在目录加入PATH环境变量中。
- 如果想让Jenkins支持更多的构建工具,也是同样的做法:在Jenkins agent上安装构建工具,然后将该构建工具的可执行命令的目录添加到Jenkins pipeline的PATH环境变量中。示例如下:
//方法一
pipeline {
agent any
environment {
PATH = "/usr/local/maven/bin/:${PATH}" //将maven的bin目录添加到PATH中
}
stages {
stage('Example') {
steps {
sh 'mvn -v' //
sh 'printenv'
}
}
}
}
//方法二
pipeline {
agent any
environment {
MAVEN_HOME = "/usr/local/maven/bin" //将mavem的bin目录的路径定义成一个变量
}
stages {
stage('Example') {
steps {
sh '${MAVEN_HOME}/mvn -v' //直接引用maven的bin目录
sh 'printenv'
}
}
}
}
5.3、利用tools作用域实现多版本编译
- 在实际工作中,有时需要对同一份源码使用多个版本的编译器进行编译。tools指令除了支持pipeline作用域,还支持stage作用域。所以,可以在同一个pipeline中实现多版本编译。
pipeline {
agent any
stages {
stage('Example-3.9.4') {
tools {
maven "maven-3.9.4"
}
steps {
sh 'mvn -v'
sh 'printenv'
}
}
stage('Example-3.9.5') {
tools {
maven "maven-3.9.5"
}
steps {
sh 'mvn -v'
sh 'printenv'
}
}
}
}
1
# #

 浙公网安备 33010602011771号
浙公网安备 33010602011771号