Git04-git基础原理
1、基本概念
1.1、版本库
- Git版本库(repository)是一个简单的数据库,其中包含所有用来维护与管理项目的修订版本和历史的信息。在Git中,跟大多数版本控制系统一样,一个版本库维护项目整个生命周期的完整副本。然而,不同于其他大多数VCS,Git版本库不仅仅提供版本库中所有文件的完整副本,还提供版本库本身的副本。
- Git在每个版本库里维护一组配置值,如版本库的用户名和email地址。不像文件数据和其他版本库的元数据,在把一个版本库克隆(clone)或者复制到另一个版本库的时候配置设置是不跟着转移的。相反,Git对每个网站、每个用户和每个版本库的配置和设置信息都进行管理与检查。
- 在版本库中,Git维护两个主要的数据结构:对象库(objectstore)和索引(index)。所有版本库数据存放在工作目录根目录下一个名为.git的隐藏子目录中。
- 对象库在复制操作的时候能进行有效复制,这也是用来支持完全分布式VCS的一种技术。
- 索引是暂时的信息,对版本库来说是私有的,并且可以在需要的时候按需求进行创建和修改。
1.2、Git对象类型
- 对象库是Git版本库实现的核心。它包含原始数据文件和所有日志消息、作者信息、日期,以及其他用来重建项目任意版本或分支的信息。
- Git放在对象库里的对象有4种类型:块(blob)、目录树(tree)、提交(commit)和标签(tag)。
- 块(blob)
- 文件的每一个版本表示为一个块(blob)。blob是“二进制大对象”(binary large object)的缩写,是计算机领域的常用术语,用来指代某些可以包含任意数据的变量或文件,同时其内部结构会被程序忽略。一个blob被视为一个黑盒。一个blob保存一个文件的数据,但不包含任何关于这个文件的元数据,甚至连文件名也没有。
- 目录树(tree)
- 一个目录树(tree)对象代表一层目录信息。它记录blob标识符、路径名和在一个目录里所有文件的一些元数据。它也可以递归引用其他目录树或子树对象,从而建立一个包含文件和子目录的完整层次结构。
- 提交(commit)
- 一个提交(commit)对象保存版本库中每一次变化的元数据,包括作者、提交者、提交日期和日志消息。每一个提交对象指向一个目录树对象,这个目录树对象在一张完整的快照中捕获提交时版本库的状态。最初的提交或者根提交(rootcommit)是没有父提交的。大多数提交都有一个父提交,后面会介绍一个提交如何引用多个父提交。
- 标签(tag)
- 一个标签对象分配一个任意的且人类可读的名字给一个特定对象,通常是一个提交对象。虽然9da581d910c9c4ac93557ca4859e767f5caf5169指的是一个确切且定义好的提交,但是一个可读的标签名(如Ver-1.0-Alpha)可能会更有意义!
- 这4种原子对象是构成Git高层数据结构的基础。
- 随着时间的推移,所有信息在对象库中会变化和增长,项目的编辑、添加和删除都会被跟踪和建模。为了有效地利用磁盘空间和网络带宽,Git把对象压缩并存储在打包文件(pack file)里,这些打包文件也在对象库里。
1.3、索引
- 索引是一个临时的、动态的二进制文件,它描述整个版本库的目录结构。更具体地说,索引捕获项目在某个时刻的整体结构(即一个版本)。项目的状态可以用一个提交和一个目录树表示,它可以来自项目历史中的任意时刻,或者它可以是你正在开发的未来状态。
- Git的关键特性之一就是它允许你用有条理的、定义好的步骤来改变索引的内容。索引使得开发的推进与提交的变更之间能够分离开来。
- 索引的工作原理:
- 开发人员可以通过执行Git命令在索引中暂存(stage)变更。变更通常是添加、删除或者编辑某个文件或某些文件。索引会记录和保存这些变更,保障它们的安全直到你准备好提交了。
- 还可以删除或替换索引中的变更。因此,索引支持一个由你主导的从复杂的版本库状态到一个可推测的更好状态的逐步过渡。
- 索引还在合并(merge),允许管理、检查和同时操作同一个文件的多个版本中起到的重要作用。
1.4、基于内容可寻址的对象名称
- Git对象库被组织成一个内容寻址的存储系统。具体而言,对象库中的每个对象都有一个唯一的名称,这个名称是基于对象的内容应用SHA1得到的SHA1散列值。
- 因为一个对象的完整内容决定了这个散列值,并且认为这个散列值能有效并唯一地对应特定的内容,所以SHA1散列值用来做对象数据库中对象的名字和索引是完全充分的。
- 文件的任何微小变化都会导致SHA1散列值的改变,使得文件的新版本被单独编入索引。
- SHA1的值是一个160位的数,通常表示为一个40位的十六进制数,比如,9da581d910c9c4ac93557ca4859e767f5caf5169。有时候,在显示期间,SHA1值被简化成一个较小的、唯一的前缀。Git用户所说的SHA1、散列码和对象ID都是指同一个东西。
- 全局唯一标识符
- SHA散列计算的一个重要特性是不管内容在哪里,它对同样的内容始终产生同样的ID。
- 换言之,是在不同目录里,甚至是在不同机器中的相同文件内容产生的SHA1哈希ID是完全相同的。因此,文件的SHA1散列ID是一种有效的全局唯一标识符。
- 这里有一个强大的推论,在互联网上,文件或者任意大小的blob都可以通过仅比较它们的SHA1标识符来判断是否相同。
1.5、Git追踪内容
- Git不仅仅是一个VCS,Git同时还是一个内容追踪系统(content tracking system)。尽管区别很微小,但是这指导了Git的很多设计,并且也许这就是处理内部数据操作相对容易的关键原因。这也可能是新手最难把握的概念之一。
- Git的内容追踪主要表现为两种方式,这两种方式与大多数其他"修订版本控制系统都不一样。
- 首先,Git的对象库基于其对象内容的散列计算的值,而不是基于用户原始文件布局的文件名或目录名设置。因此,当Git放置一个文件到对象库中的时候,它基于文件内容的散列值而不是文件名。事实上,Git并不追踪那些与文件次相关的文件名或者目录名。再次强调,Git追踪的是内容而不是文件。
- 如果两个文件的内容完全一样,无论是否在相同的目录,Git在对象库里只保存一份blob形式的内容副本。Git仅根据文件内容来计算每一个文件的散列码,如果文件有相同的SHA1值,它们的内容就是相同的,然后将这个blob对象放到对象库里,并以SHA1值作为索引。项目中的这两个文件,不管它们在用户的目录结构中处于什么位置,都使用那个相同的对象指代其内容。
- 如果这些文件中的一个发生了变化,Git会为它计算一个新的SHA1值,识别出它现在是一个不同的blob对象,然后把这个新的blob加到对象库里。原来的blob在对象库里保持不变,为没有变化的文件所使用。
- 其次,当文件从一个版本变到下一个版本的时候,Git的内部数据库有效地存储每个文件的每个版本,而不是它们的差异。因为Git使用一个文件的全部内容的散列值作为文件名,所以它必须对每个文件的完整副本进行操作。Git不能将工作或者对象库条目建立在文件内容的一部分或者文件的两个版本之间的差异上。
- 文件拥有修订版本和从一个版本到另一个版本的步进,用户的典型看法是这种文件简直是个工艺品。Git用不同散列值的blob之间的区别来计算这个历史,而不是直接存储一个文件名和一系列差异。这似乎有些奇怪,但这个特性让Git在执行某些任务的时候非常轻松。
1.6、路径名与内容
- 跟很多其他VCS一样,Git需要维护一个明确的文件列表来组成版本库的内容。然而,这个需求并不需要Git的列表基于文件名。实际上,Git把文件名视为一段区别于文件内容的数据。这样,Git就把索引从传统数据库的数据中分离出来了。
- 下表会很有帮助,它粗略地比较了Git和其他类似的系统。

- 文件名和目录名来自底层的文件系统,但是Git并不关心这些名字。Git仅仅记录每个路径名,并且确保能通过它的内容精确地重建文件和目录,这些是由散列值来索引的。
- Git的物理数据布局并不模仿用户的文件目录结构。相反,它有一个完全不同的结构却可以重建用户的原始布局。在考虑其自身的内部操作和存储方面,Git的内部结构是一种更高效的数据结构。
- 当Git需要创建一个工作目录时,它对文件系统说:“嘿!我这有这样大的一个blob数据应该放在路径名为path/to/directory/file的地方。你能理解吗?”文件系统回复说:“可以啊,我认出那个字符串是一组子目录名,并且我知道把你的blob数据放在哪里!”
1.7、打包文件
- 直接存储每个文件每个版本的完整内容是否太低效了?即使它是压缩的,把相同文件的不同版本的全部内容都存储是否太低效了?如果你只添加一行到文件里,Git是不是要存储两个版本的全部内容?
- 幸运的是,答案是“不是,不完全是!”
- 相反,Git使用了一种叫做打包文件(pack file)的更有效的存储机制。要创建一个打包文件,Git首先定位内容非常相似的全部文件,然后存储它们之一的全部内容,之后计算相似文件之间的差异并且只存储差异。例如,如果你只是更改或者添加文件中的一行,Git可能会只存储新版本的全部内容,然后将更改的那一行作为差异,并存储在包里。
- 存储一个文件的整个版本,并存储用来构造其他版本的相似文件的差异,并不是一个方法。这个机制已经被其他VCS(如RCS)用了好几十年了,它们本质上是相同的。
- 然而,Git文件打包是非常巧妙。因为Git是由内容驱动的,所以它并不真正关心它计算出来的两个文件之间的差异是否属于同一个文件的两个版本。这就是说,Git可以在版本库里的任何地方取出两个文件并计算差异,只要它认为它们足够相似来产生良好的数据压缩。因此,Git有一套相当复杂的算法来定位和匹配版本库中潜在的全局候选差异。此外,Git可以构造一系列差异文件,从一个文件的一个版本到第二个,第三个,等等。
- Git还维护打包文件表示中每个完整文件(包括完整内容的文件和通过差异重建出来的文件)的原始blob的SHA1值。这给定位包内对象的索引机制提供了基础。
- 打包文件跟对象库中其他对象存储在一起。它们也用于网络中版本库的高效数据传输。
2、对象库图示
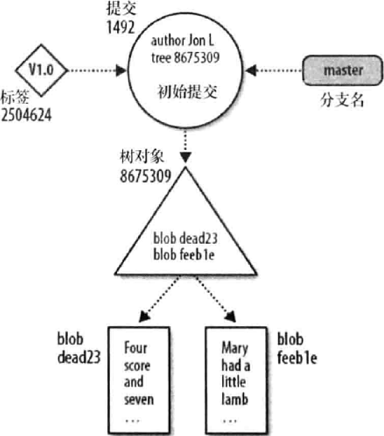
- 该图展示了对象之间是如何协作的。该图显示了一个裸版本库在添加了两个文件,并提交之后的状态。两个文件都在顶级目录中。同时它们的master分支和一个叫V1.0的标签都指向ID为1492的提交对象。
- 矩形表示blob对象。blob对象是数据结构的“底端”,它什么也不引用,而且只被树对象引用。
- 三角形表示树对象。树对象指向若干blob对象,也可能指向其他树对象。许多不同的提交对象可能指向任意的树对象。
- 圆圈表示提交对象。一个提交对象指向一个特定的树对象,并且这个树对象是由提交对象引入版本库的。
- 菱形表示标签。每个标签仅可以指向一个提交对象。
- 圆角矩形代表分支。分支不是Git中的基本对象,但是它在命名提交对象的时候起到了至关重要的作用。
- 对象库就如图所示。保留原来的两个文件不变,再添加一个包含一个文件的新子目录。
- 为新提交对象添加了一个树对象(ID是1010220)来表示目录和文件结构的状态。
- 因为在顶级目录中添加了新子目录,改变了顶级树对象的内容,所以Git引进了一个新的树对象(ID是cafed00d)。
- blob对象dead23和feeble在从第一次到第二次提交的时没有发生变化。Git看到到ID没有变化,所以可以被新的树对象cafed00d直接引用和共享。
- 请注意提交对象之间箭头的方向,父提交存在的时间更早,因此,在Git的实现里,每个提交对象指向它的一个或多个父提交。很多人对此感到困惑,因为版本库的状态通常画成反方向:数据流从父提交流向子提交。

3、Git在工作时的概念
3.1、隐藏目录.git
- 首先,使用git init来初始化一个空的版本库,然后使用tree看看都创建了什么文件。
- git init命令会创建一个空的Git版本库。即在指定目录中创建了一个隐藏目录“.git”,Git会把所有修改的信息都放在.git目录里。
- .git目录中包含objects、refs/heads、refs/tags和template等子目录。
1、创建一个裸版本库
//(1)创建一个目录 ]# mkdir hello ]# cd hello/ //(2)创建一个新的版本库 ]# git init Initialized empty Git repository in /root/hello/.git/
2、查看版本库的目录结构
- 可以看到,.git目录包含很多内容。这些文件是基于模板创建的,可以根据需要进行调整。目录结构在不同的Git版本中,可能会有一些不同。例如,旧版本的Git对.git/hooks文件不使用.sample后缀。
- 在一般情况下,不需要查看或者操作.git目录下的文件。这些“隐藏”的文件是Git底层(plumbing)或者配置的一部分。Git有一些底层命令可以处理这些隐藏的文件,但很少用到它们。
- 可以看到,最初,git/objects目录(用来存放所有Git对象的目录)是空的,除了几个占位符之外。
]# tree -a ../hello/
../hello/
└── .git
├── branches
├── config
├── description
├── HEAD
├── hooks
│ ├── applypatch-msg.sample
│ ├── commit-msg.sample
│ ├── fsmonitor-watchman.sample
│ ├── post-update.sample
│ ├── pre-applypatch.sample
│ ├── pre-commit.sample
│ ├── pre-merge-commit.sample
│ ├── prepare-commit-msg.sample
│ ├── pre-push.sample
│ ├── pre-rebase.sample
│ ├── pre-receive.sample
│ ├── push-to-checkout.sample
│ └── update.sample
├── info
│ └── exclude
├── objects
│ ├── info
│ └── pack
└── refs
├── heads
└── tags
3.2、创建一个对象(blob、散列和对象)
1、创建一个对象
//(1)创建一个文件 ]# echo "hello world" > hello.txt //(2)创建blob对象 ]# git add hello.txt
2、对比版本库的目录结构的前后差异
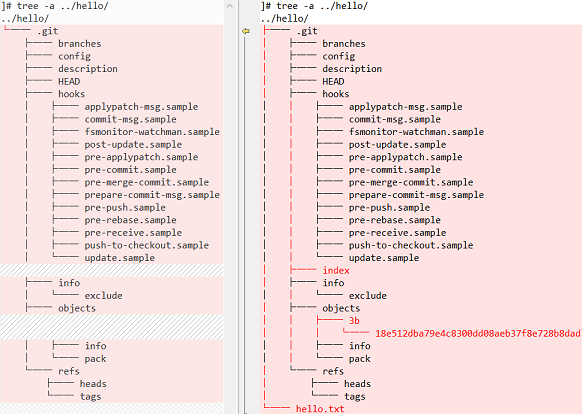
- 将hello.txt文件(blob)创建成一个创建对象时,Git并不关心hello.txt的文件名,只关心文件的内容:“hello world”这11个字符和换行符(跟之前创建的blob一样)。
- Git计算hello.txt文件的SHA1散列值,把散列值的十六进制的值作为文件名放进对象库中。
- hello.txt文件的SHA1散列值是3b18e512dba79e4c8300dd08aeb37f8e728b8dad。160位的SHA1散列值对应20个字节,需要40个字节的十六进制来表示。
- Git在前两个数字后面插入一个“/”以提高文件系统效率(如果把太多的文件放在同一个目录中,一些文件系统会变慢。使SHA1的第一个字节成为一个目录是一个很简单的办法,理论上可以均匀分布所有对象)。因此,hello.txt另存为.git/objects/3b/18e512dba79e4c8300dd08aeb37f8e728b8dad。
- Git不会修改文件的内容,可以使用散列值把文件内容从对象库里提取出来。
]# git cat-file -p 3b18e512dba79e4c8300dd08aeb37f8e728b8dad hello world
- 可以通过对象的唯一前缀来查找对象的散列值。
]# git rev-parse 3b18 3b18e512dba79e4c8300dd08aeb37f8e728b8dad
- 散列函数是一个真正的数学函数:对于一个给定的输入,它总会生产相同的输出。
- 如果两个对象具有相同的SHA1散列值,就可以说他们是相同的。
- 反过来也是如此:如果在你的对象库里没找到具有特定散列值的对象,那么你就可以肯定你没有那个对象的副本。总之,你可以判断你的对象库是否有一个特定的的对象,即使你对它(可能非常大)的内容一无所知。
3.3、创建树(文件和树)
- 已经将hello.txt文件(blob)中的内容“hello world”存放到对象库里了,那么其文件名又发生了什么事呢?如果不能通过文件名找到文件,那么Git就太没用了。
- Git通过目录树(tree)对象来跟踪文件的路径名。
- 当执行git add命令时,Git会给每个文件的内容创建一个blob对象,但它并不会立刻创建树对象,而是更新索引。索引位于.git/index中,它跟踪文件的路径名和相应的blob。每次执行命令(比如,gitadd、gitrm或者gitmv)时,Git会用新的路径名和blob信息来更新索引。
- 任何时候,都可以从当前索引创建一个树对象,只要执行底层命令git write-tree来捕获索引当前信息的快照就可以了。
1、查看索引文件中的内容
//可以看到,此时索引中只包含一个文件hello.txt。 ]# git ls-files -s 100644 3b18e512dba79e4c8300dd08aeb37f8e728b8dad 0 hello.txt
2、创建树对象
]# git write-tree 68aba62e560c0ebc3396e8ae9335232cd93a3f60
3、对比版本库的目录结构的前后差异
- 可以看到,现在有两个对象:3b18e5的“hello world”对象和一个新的68aba6树对象。
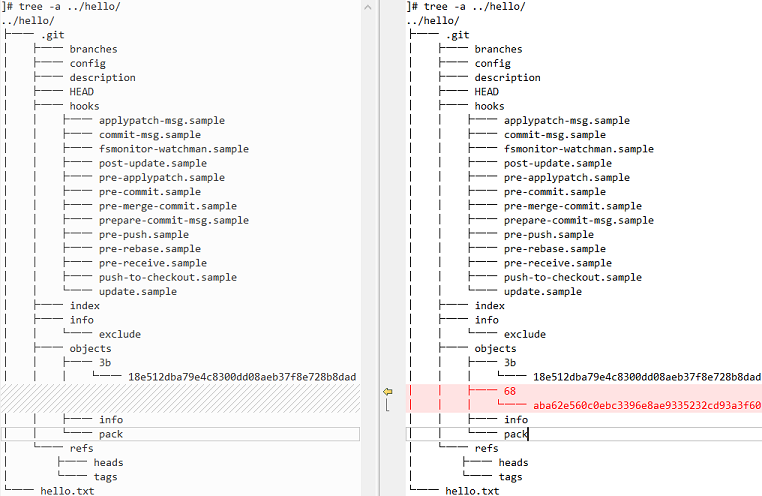
4、查看树对象
- 树对象包含什么信息呢?因为它是一个对象,就像blob一样,所以可以用git cat-file命令来查看它。
]# git cat-file -p 68aba62e560c0ebc3396e8ae9335232cd93a3f60 100644 blob 3b18e512dba79e4c8300dd08aeb37f8e728b8dad hello.txt
- 树对象的内容很容易解释:
- 100644:是对象文件属性的八进制表示(类似UNIX的chmod命令的设置)。
- blob:该对象的类型。
- 3b18e5:是"hello world"的blob的对象名。
- hello.txt:是与该blob关联的文件的名字。
3.4、树的层次结构
- 只有单个文件的信息很好管理,就像上一节所讲的一样。但是项目包含复杂且深层嵌套的目录结构,并且会随着时间的推移而重构和移动。
1、创建新树
- 通过创建一个新的子目录,且该子目录包含一个与hello.txt完全相同的副本。
//(1)子目录 ]# mkdir subdir ]# cp hello.txt subdir/ //(2)创建blob对象 ]# git add subdir/hello.txt //(3)创建树 ]# git write-tree 492413269336d21fac079d4a4672e55d5d2147ac
2、对比版本库的目录结构的前后差异
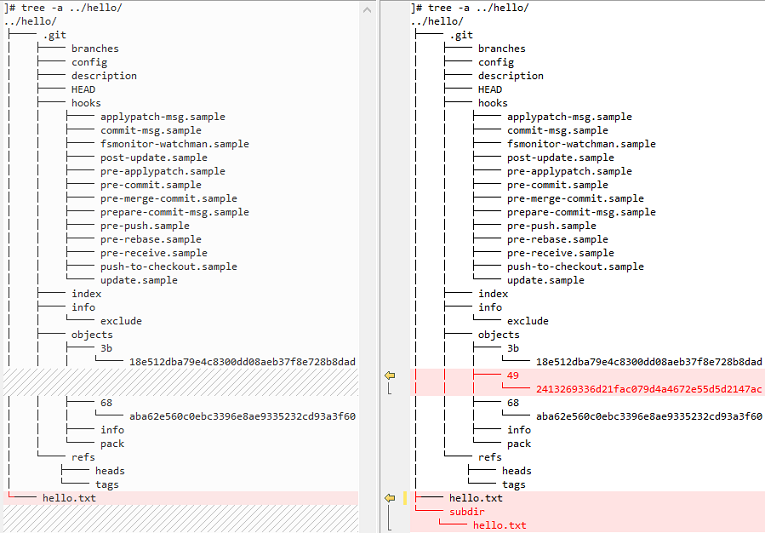
3、查看新的树对象中的信息
- 新的顶级树包含两个条目:原始的hello.txt以及新的子目录,子目录是树而不是blob。
]# git cat-file -p 492413269336d21fac079d4a4672e55d5d2147ac 100644 blob 3b18e512dba79e4c8300dd08aeb37f8e728b8dad hello.txt 040000 tree 68aba62e560c0ebc3396e8ae9335232cd93a3f60 subdir
- 注意到不寻常之处了吗?仔细看subdir的对象名,是原本的顶级树的对象名68aba62e560c0ebc3396e8ae9335232cd93a3f60!
- subdir的新树只包含一个文件hello.txt,该文件跟旧的“hello world”内容相同。所以subdir树跟原本的顶级树是完全一样的!因此它就有了跟之前一样的SHA1对象名了。
3.5、提交
- hello.txt已经通过git add命令添加到了存储库了,树对象也通过底层命令git write-tree生成了,现在就可以使用底层命令git commit-tree创建提交对象了。
1、提交
//在一个树上创建提交 ]# git commit-tree -m "Commit a file that says hello" 492413269336d21fac079d4a4672e55d5d2147ac c29f6ad7192b93e4d53dfbda9f77e801b54fcc1d
2、对比版本库的目录结构的前后差异
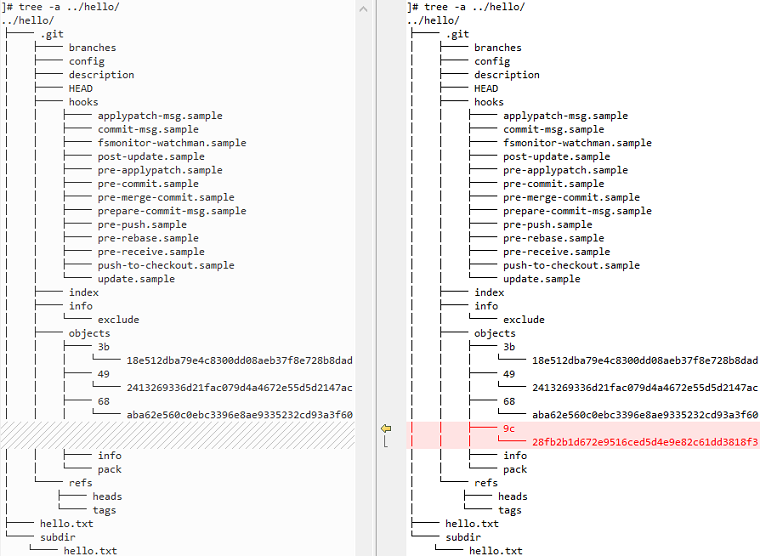
3、查看提交对象中的信息
- 如果在计算机上按上述步骤进行操作,你可能会发现你生成的提交对象的名字和书上的不一样。因为一个提交包含你的名字和创建提交的时间,尽管这些区别很微小,但依然会使其名称发生变化。这就是提交对象与它们的树对象分开的原因:不同的提交经常指向同一棵树。当这种情况发生时,Git能足够聪明地只传输新的提交对象,这是非常小的,而不是很可能很大的树和blob对象。
- 实际操作时,可以(并且应该)跳过底层的git write-tree和git commit-tree步骤,并只使用git commit命令。
]# git cat-file -p 9c28fb2b1d672e9516ced5d4e9e82c61dd3818f3 tree 492413269336d21fac079d4a4672e55d5d2147ac author heng ha <hengha@123.com> 1678978087 +0800 committer heng ha <hengha@123.com> 1678978087 +0800 Commit a file that says hello
- 一个基本的提交对象是相当简单的,这是成为一个真正的RCS需要的最后组成部分。
- 提交对象中的信息包含:
- 标识关联的树对象的名称。
- 创作新版本的人(作者)的名字和创作的时间。
- 把新版本放到版本库的人(提交者)的名字和提交的时间。
- 对本次修订原因的说明(提交消息)。
- 尽管提交对象跟树对象用的结构是完全不同的,但是它也存储在隐藏目录.git中。当你创建一个新提交时,可以为指定它一个或多个父提交。通过继承链来回溯,可以查看项目历史。
3.6、标签
- Git只有一种标签对象,但是有两种基本的标签类型,通常称为轻量级的(lightweight)和带附注的(annotated)。
- 轻量级标签只是一个提交对象的引用,通常被版本库视为是私有的。这些标签并不在版本库里创建永久对象。
- 带标注的标签则更加充实,并且会创建一个对象。它包含一条描述信息(-m),并且可以根据RFC4880来使用GnuPG密钥进行数字签名。
- Git在创建一个提交的时,对轻量级的标签和带标注的标签是同等对待。不过,默认情况下,很多Git命令只对带标注的标签起作用,因为它们被认为是“永久”的对象。
1、创建标签
- 通过git tag命令来创建一个带有提交信息、带附注且未签名的标签。
//在一个提交上创建标签 ]# git tag -m "Tag version 1.0" V1.0 9c28fb2b1d672e9516ced5d4e9e82c61dd3818f3
2、对比版本库的目录结构的前后差异
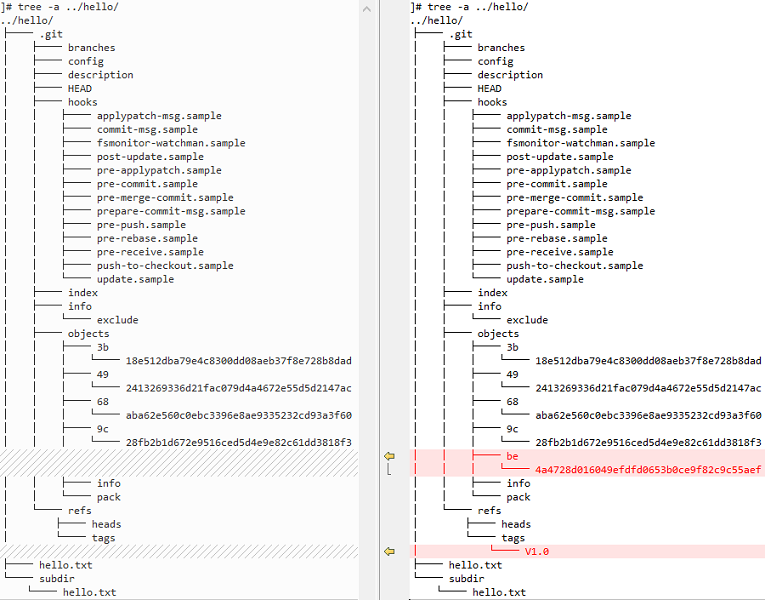
3、查看标签对象中的信息
//(1)获取标签的对象 ]# git rev-parse V1.0 be4a4728d016049efdfd0653b0ce9f82c9c55aef //(2)查看标签对象中的信息 ]# git cat-file -p be4a4728d016049efdfd0653b0ce9f82c9c55aef object 9c28fb2b1d672e9516ced5d4e9e82c61dd3818f3 type commit tag V1.0 tagger heng ha <hengha@123.com> 1678978473 +0800 Tag version 1.0
4、查看标签的其他细节
//查看标签的其他细节 ]# git show --pretty=fuller V1.0 //查看提交的其他细节 ]# git show --pretty=fuller 9c28fb2b1d672e9516ced5d4e9e82c61dd3818f3
- 除了日志消息和作者信息之外,标签指向提交对象9c28fb2b1d672e9516ced5d4e9e82c61dd3818f3。通常情况下,Git通过某些分支来给特定的提交命名标签。请注意,这种行为跟其他VCS有明显的不同。
- Git通常给指向树对象的提交对象打标签,这个树对象包含版本库中文件和目录的整个层次结构。
- 回想一下“对象库图示中的第二个图”,V1.0标签指向提交1492——依次指向跨越多个文件的树(8675309)。因此,这个标签同时适用于该树的所有文件。
- 这跟CVS不同,例如,对每个单独的文件应用标签,然后依赖所有打过标签的文件来重建一个完整的标记修订。并且CVS允许你移动单独文件的标签,而Git则需要在标签移动到的地方做一个新的提交,囊括该文件的状态变化。
# #

 浙公网安备 33010602011771号
浙公网安备 33010602011771号