监控-Prometheus08-监控Docker容器
1、Docker容器架构与监控
- 可以使用Google开源的容器度量收集工具cAdvisor对容器进行监控。
1.1、Docker容器架构
- Docker使用了传统的Client-Server架构模式,总体架构如图10-1所示。
- 用户通过DockerClient与Docker daemon建立通信,并将请求发送给后者。而Docker的后端是松耦合结构,不同模块各司其职、有机组合,完成用户的请求。
- Docker通过driver模块来实现对Docker容器执行环境的创建和管理。
- 当需要创建Docker容器时,可通过镜像管理(imagemanagement)部分的distribution和registry模块从Docker registry中下载镜像,并通过镜像管理的image、reference和layer存储镜像的元数据,通过镜像存储驱动graphdriver将镜像文件存储于具体的文件系统中。
- 当需要为Docker容器创建网络环境时,通过网络模块network调用libnetwork创建并配置Docker容器的网络环境。
- 当需要为容器创建数据卷volume时,则通过volume模块调用某个具体的volumedriver来创建一个数据卷并负责后续的挂载操作。
- 当需要限制Docker容器运行资源或执行用户指令操作时,则通过execdriver来完成。
- libcontainer是对cgroups和namespace的二次封装,execdriver是通过libcontainer来实现对容器的具体管理,包括利用UTS、IPC、PID、Network、Mount、User等namespace实现容器之间的资源隔离和利用cgroups实现对容器的资源限制。
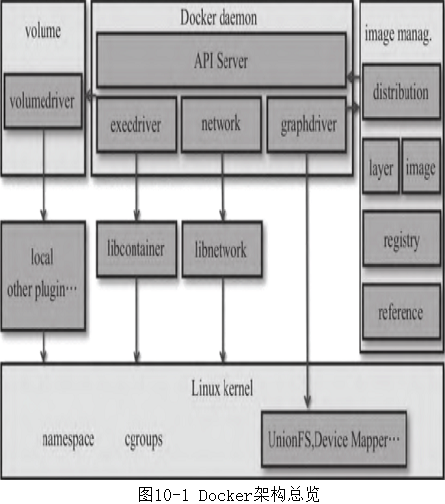
- 当运行容器的命令执行完毕后,一个实际的容器就处于运行状态,该容器拥有独立的文件系统、相对安全且相互隔离的运行环境。Docker1.9版本之后,volume和network是生命周期都是独立于容器的,与容器层级相同的组件,Docker用户可以单独增删改查volume或network,然后在创建容器的时候根据需要配置给容器。
1.2、Docker容器监控方式
- Docker原生监控常用的方式有:docker ps/top/logs、docker stats、Docker Remote API、Docker伪文件系统。
1、docker stats
- 该命令默认以流式方式输出,如果想打印出最新的数据并立即退出,可以使用no-stream=true参数。可以指定一个已停止的容器,但是停止的容器不返回任何数据。
- 监控容器性能度量指标有多种方法,简单的如通过Docker的CPU、内存、网络及磁盘的使用情况进行监测,示例如下:
]# docker stats CONTAINER ID NAME CPU % MEM USAGE / LIMIT MEM % NET I/O BLOCK I/O PIDS db9ee91008fc cadvisor 1.95% 100.3MiB / 1.777GiB 5.51% 3.06MB / 718MB 229kB / 0B 13
2、伪文件系统
- docker stats的数据来自/sys/fs/cgroup下的文件:
- mem usage那一列的值,来自于/sys/fs/cgroup/memory/docker/[containerId]/memory.usage_in_bytes。
- 如果没限制内存,Limit=machine_mem,否则来自于/sys/fs/cgroup/memory/docker/[id]/memory.limit_in_bytes。
- 内存使用率=memory.usage_in_bytes/memory.limit_in_bytes。
- 一般情况下,cgroup文件夹下的内容包括CPU、内存、磁盘、网络等信息,下面列出常用的指标说明。
- devices:设备权限控制。
- cpuset:分配指定的CPU和内存节点。
- cpu:控制CPU占用率。
- cpuacct:统计CPU使用情况。
- memory:限制内存的使用上限。
- freezer:冻结(暂停)cgroup中的进程。
- net_cls:配合tc(traffic controller)限制网络带宽。
- net_prio:设置进程的网络流量优先级。
- huge_tlb:限制HugeTLB的使用。
- perf_event:允许Perf工具基于cgroup分组做性能监测。
- 在memory中常用的指标说明如下:
- memory.usage_in_bytes:已使用的内存量(包含cache和buffer),相当于used_mem。
- memory.limit_in_bytes:限制的内存总量(字节),相当于Linux的total_mem。
- memory.failcnt:申请内存失败次数计数。
- memory.memsw.usage_in_bytes:已使用的内存和swap容量(字节)。
- memory.memsw.limit_in_bytes:限制的内存和swap容量(字节)。
- memory.memsw.failcnt:申请内存和swap失效次数计数。
- memory.stat:内存相关状态。
- 随着Docker容器云的广泛应用,大量的业务软件运行在容器中,这使得对Docker容器的监控越来越重要。对容器集群系统进行监控,一般采用物理机监控+容器本身监控的方式(如图10-2所示),具体监控指标总结如下:
- 容器本身资源使用情况:CPU、内存、网络、磁盘。
- 物理机的资源使用情况:CPU、内存、网络、磁盘。
- 物理机上容器镜像情况:名字、大小、版本。
- 目前较为流行的容器监控工具有DockerStats、cAdvisor、Scout、Data Dog以及Sensu。应用场景不同,各监控工具的优缺点体现得也有所不同。
- DockerStats是Docker本身提供的,用于监控容器资源使用情况,直接输入命令行即可查看,还可提供远程API接口,易于操作,但没有图形界面。
- cAdvisor可提供数据的可视化界面,并且可监控容器所在宿主机中的资源使用情况,只监控单一主机。
- Scout可聚合多主机容器的监控,并且提供告警,但无法显示容器的详细信息,更多的是偏向于主机资源的监控,为收费项目。
- Data Dog监控功能较为强大,可以获得运行和停止的容器计数以及镜像数量等,可整合集群主机数据和容器数据,但使用成本较高。
- Sensu监控部署较为复杂。
2、cAdvisor
- 在容器集群的环境中,通过Docker stats命令对一台台机器收集容器的度量指标显然是不现实的。在Kubenetes(有时简称k8s)设计之初就考虑到了这一点,因此它将Google开源的容器度量收集工具cAdvisor集成到了Kubelet中。在集群中,Kubelet会驻留在集群的每一个节点上,因此cAdvisor也将随之运行在所有节点上。
- cAdvisor为容器用户提供了对其运行容器的资源使用和性能特征的理解。它是一个运行守护程序,用于收集、聚合、处理和导出有关正在运行的容器的信息,同时它消耗的资源也比较少。cAdvisor不仅可以搜集一台机器上所有运行的容器的信息,还提供基础查询界面和http接口,方便其他组件(如Prometheus)进行数据抓取,或者cAdvisor+Influxdb+Grafna搭配使用。可以导出资源使用情况和完整历史资源使用的直方图,通过快速预览压力表(pressuregauge)可了解集群是否需要额外的资源。
- cAdvisor可以对节点机器上的资源及容器进行实时监控和性能数据采集,包括CPU使用情况、内存使用情况、网络吞吐量及文件系统使用情况。
- cAdvisor也有一定的局限性,即只能监控一个Docker主机。对于多节点的场景,就需要在所有的主机上都各安装一个cAdvisor。另外,在图表中的数据仅仅显示时长为2分钟,并没有查看长期数据趋势的方法。它也没有生成告警的机制,如果资源使用率较高则可能存在风险。
2.1、cAdvisor架构
- 只需在宿主机上部署cAdvisor容器,用户就可通过Web界面或REST服务访问当前节点和容器的详尽性能数据(CPU、内存、网络、磁盘、文件系统等)。
- cAdvisor支持一下指标:
- 容器基础指标。
- 容器内进程查看。
- 容器状态实践。
- 监控数据push到第三方存储介质。
- 通过Prometheus采集自定义指标。
- 通过容器标签采集应用自定义指标。
- Collector可扩展开发其他标准类型,如数据库、Kafka、Redis等,当前只支持http方式采集应用自定义指标。
- Storage可扩展开发其他介质。
- cAdvisor软件架构如图10-3所示。
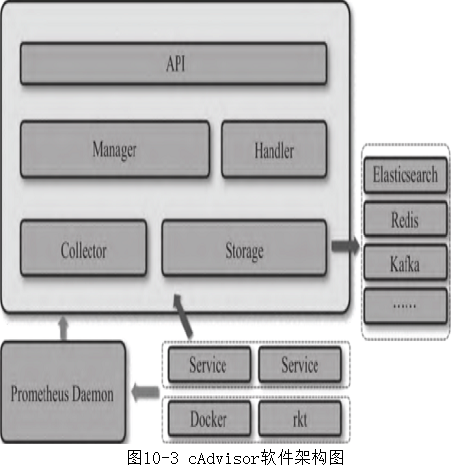
- cAdvisor主要包括API层、Handler、Manager、Collector,具体说明如下:
- API层:提供节点信息、容器运行状态信息、自定义指标信息、容器spec信息、事件信息、容器进程列表、文件系统信息的查询API。
- Handler:提供rkt、Docker的容器spec以及Storage栈信息。内置有rkt、Docker的适配器被Manager调用。
- Manager:总控,实例化Storage,为周期任务,通过Handler获取容器列表,自动发现容器的增/删等。
- Collector:内置两种采集器,即Prometheus和自定义指标采集器。
2.2、部署cAdvisor
//下载镜像 docker pull google/cadvisor:latest //运行容器 docker run \ --volume=/:/rootfs:ro \ --volume=/var/run:/var/run:rw \ --volume=/sys:/sys:ro \ --volume=/var/lib/docker/:/var/lib/docker:ro \ --publish=8080:8080 \ --detach=true \ --name=cadvisor \ google/cadvisor:latest
- cAdvisor提供一些运行时参数供用户配置使用:
- 4个--volume挂载操作不能省略,如果不挂载,将无法连接到Docker deamon,ro表示只读。
- --detach操作是为了在创建后不进入容器内部,让其自动完成监视功能。
- 在Ret Hat/CentOS/Fedora等发行版上需要传递privileged参数,因为SELinux加强了安全策略:--privileged=true。
- --storage_duration保存在内存中的数据时间段长度,默认为2min,即保存2分钟的数据。
- --allow_dynamic_housekeeping依据容器的活跃程度,动态调整读取容器监控数据的时间间隔。
- --global_housekeeping_interval检测是否有新增容器的时间周期。
- --housekeeping_interval统计每个容器数据的时间周期,默认每秒取1次数据,取统计到的最近的60个数据。
- 启动后cAdvisor立即开始监控,可以浏览主机上的端口8080查看cAdvisor的Web接口,确认它是可操作的。可以访问/metric页面查看监控指标。
- http://10.1.1.13:8080/containers/
- http://10.1.1.13:8080/metrics
- cAdvisor支持的Prometheus的指标主要有五大类(62个),包括CPU(10个)、内存(9个)、文件(18个)、网络(12个)、其他容器状态(13个),具体指标说明可以参考:https://github.com/google/cadvisor/blob/master/docs/storage/prometheus.md。
- cAdvisor通过存储插件(cAdvisor Storage Plugins)把状态信息输出到InfluxDB数据库进行存储、读取或KAfka等,通过-storage_driver来配置,具体支持的存储项有:BigQuery、ElasticSearch、InfluxDB、Kafka、Prometheus、Redis、StatsD以及stdout标准输出等。详见官网文档:https://github.com/google/cadvisor/tree/master/docs/storage。
2.3、集成到Prometheus
- cAdvisor采集的监控数据通过http://localhost:8080/metrics展现给Prometheus。
- 修改/etc/prometheus/prometheus.yml,将cAdvisor添加到监控数据采集任务目标当中:
global: scrape_interval: 15s evaluation_interval: 15s scrape_configs: - job_name: 'cadvisor' static_configs: - targets: ['cadvisor:8080']
- PromQL表达式示例:
//当正常采集到cAdvisor的样本数据后,可以通过以下表达式计算容器的CPU使用率
sum(irate(container_cpu_usage_seconds_total{image!=""}[1m])) without(cpu)
//使用类似的方法还可以查询容器内存使用量(单位为字节)
container_memory_usage_bytes{image!=""}
//查询容器网络接收量速率(单位为字节/秒)
sum(rate(container_network_receive_bytes_total{image!=""}[1m])) without(interface)
//查询容器网络传输量速率(单位为字节/秒)
sum(rate(container_network_transmit_bytes_total{image!=""}[1m])) without(interface)
//查询容器文件系统读取速率(单位为字节/秒)
sum(rate(container_fs_reads_bytes_total{image!=""}[1m])) without(device)
//查询容器文件系统写入速率(单位为字节/秒)
sum(rate(container_fs_writes_bytes_total{image!=""}[1m])) without(device)
1
# #

 浙公网安备 33010602011771号
浙公网安备 33010602011771号