MongoDB04-使用数据
1、数据库相关命令
- 第一次插入数据时自动创建数据库和集合。
- MongoDB在插入数据的时候自动创建数据库,并且还区分大小写。
//查看已经存在的数据库 show dbs //查看当前正在使用的数据库 db //如果数据库不存在,就创建数据库,否则就切换到指定的数据库(必须要插入数据后,才能使用show命令显示该新数据库) use DATABASE_NAME //删除当前数据库 db.dropDatabase()
- use函数后面紧跟着一个数据库名,将全局变量db设置为db_name。这意味着,接下来所有输入到shell中的命令都将在数据库db_name中执行,除非将该变量重置为另一个数据库。
示例:
//创建数据库library
> use library
switched to db library
//插入数据
> db.media.insert({"name":"hengha"})
WriteResult({ "nInserted" : 1 })
//查看已经存在的数据库
> show dbs
admin 0.000GB
config 0.000GB
library 0.000GB
local 0.000GB
//查看当前正在使用的数据库
> db
library
//删除当前数据库
> db.dropDatabase()
{ "ok" : 1 }
//查看已经存在的数据库
> show dbs
admin 0.000GB
config 0.000GB
local 0.000GB
2、集合相关命令
- 集合有两种:
- 标准集合:其大小随数据的增加而变大。插入数据时,会自动创建。
- 固定集合:其大小固定。当达到设置的大小时,最老的数据将被删除,最新的数据被添加到末端。必须使用createCollection函数显式地创建。
- 集合的名称定义规则:
- 必须以字母或下划线(_)开头,名字中可以有数字。
- 不能使用\$符号(符号是MongoDB的保留关键字),不能使用空白字符串(" "),不能使用null字符,也不能以system."字符串开头。
- 最大长度为128字符,但建议使用简短的集合名称(大约不超过9个字符)。
1、集合的基本使用
//查看当前数据库中的集合
show collections
//创建固定集合
db.createCollection(name, {capped:BOOL, autoIndexId:BOOL, size:NUM, max:NUM})
//重命名集合
db.COLLECTION_NAME.renameCollection(target)
target:集合的新名称。
//删除集合(同时会删除集合中的所有数据和索引)
db.COLLECTION_NAME.drop()
2、创建固定集合方法的详情
- 创建固定集合:
- name: 要创建的集合名称
- capped:布尔值(可选),如果为true,则创建固定集合。固定集合是指有着固定大小的集合,当达到最大值时,它会自动覆盖最早的文档。当该值为true时,必须指定size参数。
- size:数值(可选),为固定集合指定一个最大值(字节数)。如果capped为true,就需要指定该字段。
- max:数值(可选),指定固定集合中包含的文档的最大数量。(size的优先级比max要高)
- autoIndexId 布尔(可选),如为true,自动在_id字段创建索引。默认为false。MongoDB 3.2之后不再支持该参数。
- writeConcern:写入策略,默认为1,即要求确认写操作,0是不要求。
db.createCollection( <name>,
{
capped: <boolean>,
timeseries: { // Added in MongoDB 5.0
timeField: <string>, // required for time series collections
metaField: <string>,
granularity: <string>
},
expireAfterSeconds: <number>,
autoIndexId: <boolean>,
size: <number>,
max: <number>,
storageEngine: <document>,
validator: <document>,
validationLevel: <string>,
validationAction: <string>,
indexOptionDefaults: <document>,
viewOn: <string>, // Added in MongoDB 3.4
pipeline: <pipeline>, // Added in MongoDB 3.4
collation: <document>, // Added in MongoDB 3.4
writeConcern: <document>
}
)
- 常用方法介绍:
- (1)一般来说,我们创建集合用db.createCollection(name),如:db.createCollection("log"),创建一个名字为log的集合,没有任何的大小,数量限制,使用_id作为默认索引;
- (2)限制集合空间的大小:db.createCollection("log",{capped:true,size:1024}),这个必须使用capped:true,否则不生效。创建一个名字为log集合,限制它的空间大小为1M,如果超过1M的大小,则会删除最早的记录;
- (3)限制集合的最大条数:db.createCollection("log",{max:1024}),创建一个名字为log集合,最大条数为1024条,超过1024再插入数据的话会删除最早的一条记录。这个不能使用capped:true,否则会报错;
- (4)即限制最大条数有限制使用空间大小:db.createCollection("log",{capped:true,size:1024,max:1024}),限制集合最大使用空间为1M,最大条数为1024条。
示例:
//查看当前数据库中的集合
> show collections
//创建标准集合
> db.media.insert({"name":"hengha"})
WriteResult({ "nInserted" : 1 })
//创建固定集合
> db.createCollection("mycol", {capped:true, size:6142800, max:10000})
{ "ok" : 1 }
//查看当前数据库中的集合
> show collections
media
mycol
//删除集合
> db.media.drop()
true
//查看当前数据库中的集合
> show collections
mycol
3、向集合中插入文档
- 所有数据都以BSON格式存储(不仅紧凑,并且扫描速度快)。BSON是一种类似JSON的二进制形式的存储格式,是Binary JSON的简称。
- 插入文档的方法:
- 使用插入函数,直接将文档内容插入到集合中。
- 先定义文档,然后使用插入函数将文档插入到集合中。
- 键的名称定义规则:
- 第一个字符不能是\$字符。
- 键名中不能使用圆点[.]
- _id是保留关键字,用作主键ID(不建议使用)
- insert函数向集合中插入数据:
- document:要写入的文档。
- writeConcern:写入策略,默认为1,即要求确认写操作,0是不要求。
- ordered:指定是否按顺序写入,默认 true,按顺序写入。
//向集合插入一个或多个
db.COLLECTION_NAME.insert(
<document or array of documents>, //document 或 [ <document1> , <document2>, ... ]
{
writeConcern: <document>,
ordered: <boolean>
}
)
//向集合插入一个新文档(3.2版本之后新增)
db.COLLECTION_NAME.insertOne(
<document>,
{
writeConcern: <document>
}
)
//向集合插入一个多个文档(3.2版本之后新增)
db.COLLECTION_NAME.insertMany(
[ <document1> , <document2>, ... ],
{
writeConcern: <document>,
ordered: <boolean>
}
)
示例1:
- 直接将文档插入到集合中。
//切换数据库
> use library
switched to db library
//查看当前数据库中已经存在的集合
> show collections
//使用insert插入文档,将文档插入到当前数据库的media集合中
> db.media.insert({"Type":"Book", "Title":"Definitive Guide to MongoDB 3rd ed.", "ISBN":"978-1-4842-1183-0", "Publisher":"Apress", "Author":["Hows, David", "Plugge, Eelco", "Membrey, Peter", "Hawkins, Tim"]})
WriteResult({ "nInserted" : 1 })
//查看当前已经存在的集合和集合中存在的文档
> show collections
media
> db.media.find()
{ "_id" : ObjectId("6316c9e7f3740efcd7e2b174"), "Type" : "Book", "Title" : "Definitive Guide to MongoDB 3rd ed.", "ISBN" : "978-1-4842-1183-0", "Publisher" : "Apress", "Author" : [ "Hows, David", "Plugge, Eelco", "Membrey, Peter", "Hawkins, Tim" ] }
示例2:
- 先定义文档,再将文档插入到集合中。
//先定义文档(注意,变量的内容将被立即输出)
> document = ({"Type":"CD", "Artist":"Nirvana", "Title":"Nevermind", "Genre":"Grunge", "Releasedate":"1991.09.24", "Tracklist":[{"Track":"1", "Title":"Smells Like Teen Spirit", "Length":"5:02"}, {"Track":"2", "Title":"In Bloom", "Length":"4:15"}]})
{
"Type" : "CD",
"Artist" : "Nirvana",
"Title" : "Nevermind",
"Genre" : "Grunge",
"Releasedate" : "1991.09.24",
"Tracklist" : [
{
"Track" : "1",
"Title" : "Smells Like Teen Spirit",
"Length" : "5:02"
},
{
"Track" : "2",
"Title" : "In Bloom",
"Length" : "4:15"
}
]
}
//再使用insert插入数据,将文档插入到当前数据库的media集合中
> db.media.insert(document)
WriteResult({ "nInserted" : 1 })
//查看当前集合中存在的文档
> db.media.find()
{ "_id" : ObjectId("6316e6e18758acb8d618601e"), "Type" : "Book", "Title" : "Definitive Guide to MongoDB 3rd ed.", "ISBN" : "978-1-4842-1183-0", "Publisher" : "Apress", "Author" : [ "Hows, David", "Plugge, Eelco", "Membrey, Peter", "Hawkins, Tim" ] }
{ "_id" : ObjectId("6316e77a8758acb8d618601f"), "Type" : "CD", "Artist" : "Nirvana", "Title" : "Nevermind", "Genre" : "Grunge", "Releasedate" : "1991.09.24", "Tracklist" : [ { "Track" : "1", "Title" : "Smells Like Teen Spirit", "Length" : "5:02" }, { "Track" : "2", "Title" : "In Bloom", "Length" : "4:15" } ] }
4、查询集合中的文档
- 查询数据时,有大量可用的选项、操作符、表达式、过滤器等。
- find函数查询集合中的文档:
- query:可选,使用查询操作符指定查询条件
- projection:可选,使用投影操作符指定返回的键。查询时返回文档中所有键值,只需省略该参数即可(默认省略)。
//find()方法以非结构化的方式来显示所有文档 db.COLLECTION_NAME.find(query, projection) //以易读的方式显示文档(添加pretty()函数) db.COLLECTION_NAME.find(query, projection).pretty()
示例:
- _id字段总是被返回,除非使用{_id:0}排除它。
- {key_name:1}只返回必要的信息,这样会节省很多时间,因为你只看到了需要的信息。还可以节省数据查询的时间,因为它不需要返回不必要的信息。
//查询media集合中的所有文档
> db.media.find()
{ "_id" : ObjectId("631843da66d3fc0450e53649"), "Type" : "CD", "Artist" : "Nirvana", "Title" : "Nevermind", "Genre" : "Grunge", "Releasedate" : "1991.09.24", "Tracklist" : [ { "Track" : "1", "Title" : "Smells Like Teen Spirit", "Length" : "5:02" }, { "Track" : "2", "Title" : "In Bloom", "Length" : "4:15" } ] }
{ "_id" : ObjectId("631843df66d3fc0450e5364a"), "Type" : "Book", "Title" : "Definitive Guideto MongoDB 3rd ed.", "ISBN" : "978-1-4842-1183-0", "Publisher" : "Apress", "Author" : [ "Hows, David", "Plugge, Eelco", "Membrey, Peter", "Hawkins, Tim" ] }
//查询media集合中包含键值对"Type":"Book"的文档
> db.media.find({"Type":"Book"})
{ "_id" : ObjectId("631843df66d3fc0450e5364a"), "Type" : "Book", "Title" : "Definitive Guideto MongoDB 3rd ed.", "ISBN" : "978-1-4842-1183-0", "Publisher" : "Apress", "Author" : [ "Hows, David", "Plugge, Eelco", "Membrey, Peter", "Hawkins, Tim" ] }
//只返回指定的键值,忽略其他部分(在查询中插入一个额外的参数,指定希望返回的键的名称,并在其后紧跟1)
> db.media.find({"Type":"Book"}, {Type:1,ISBN:1})
{ "_id" : ObjectId("631843df66d3fc0450e5364a"), "Type" : "Book", "ISBN" : "978-1-4842-1183-0" }
//忽略指定的键值,返回其他部分(在查询中插入一个额外的参数,指定希望返回的键的名称,并在其后紧跟0)
> db.media.find({"Type":"Book"}, {Type:0,ISBN:0})
{ "_id" : ObjectId("631843df66d3fc0450e5364a"), "Title" : "Definitive Guideto MongoDB 3rd ed.", "Publisher" : "Apress", "Author" : [ "Hows, David", "Plugge, Eelco", "Membrey, Peter", "Hawkins, Tim" ] }
4.1、使用点号
- 在复杂文档结构中,可能使用了数组或字典的嵌套或相互嵌套,这时查询相关文档的时候,要使用点号[.]引用嵌套内部的键。
- 在键名之后使用点号[.],将告诉find函数查找文档中内嵌的信息。
//查询media集合中的所有文档
> db.media.find()
{ "_id" : ObjectId("631843da66d3fc0450e53649"), "Type" : "CD", "Artist" : "Nirvana", "Title" : "Nevermind", "Genre" : "Grunge", "Releasedate" : "1991.09.24", "Tracklist" : [ { "Track" : "1", "Title" : "Smells Like Teen Spirit", "Length" : "5:02" }, { "Track" : "2", "Title" : "In Bloom", "Length" : "4:15" } ] }
{ "_id" : ObjectId("631843df66d3fc0450e5364a"), "Type" : "Book", "Title" : "Definitive Guideto MongoDB 3rd ed.", "ISBN" : "978-1-4842-1183-0", "Publisher" : "Apress", "Author" : [ "Hows, David", "Plugge, Eelco", "Membrey, Peter", "Hawkins, Tim" ] }
> db.media.find({"Tracklist.Title" : "In Bloom"})
{ "_id" : ObjectId("631843da66d3fc0450e53649"), "Type" : "CD", "Artist" : "Nirvana", "Title" : "Nevermind", "Genre" : "Grunge", "Releasedate" : "1991.09.24", "Tracklist" : [ { "Track" : "1", "Title" : "Smells Like Teen Spirit", "Length" : "5:02" }, { "Track" : "2", "Title" : "In Bloom", "Length" : "4:15" } ] }
- 处理数组时会简单一些。
> db.media.find({"Author" : "Membrey, Peter"})
{ "_id" : ObjectId("631843df66d3fc0450e5364a"), "Type" : "Book", "Title" : "Definitive Guideto MongoDB 3rd ed.", "ISBN" : "978-1-4842-1183-0", "Publisher" : "Apress", "Author" : [ "Hows, David", "Plugge, Eelco", "Membrey, Peter", "Hawkins, Tim" ] }
- 子对象必须精确匹配,否则无法匹配到任何文档。
//没有匹配到文档
> db.media.find({"Tracklist" : {"Track": "1"}})
//匹配到了文档
> db.media.find({"Tracklist" : { "Track" : "1", "Title" : "Smells Like Teen Spirit", "Length" : "5:02" }})
{ "_id" : ObjectId("631843da66d3fc0450e53649"), "Type" : "CD", "Artist" : "Nirvana", "Title" : "Nevermind", "Genre" : "Grunge", "Releasedate" : "1991.09.24", "Tracklist" : [ { "Track" : "1", "Title" : "Smells Like Teen Spirit", "Length" : "5:02" }, { "Track" : "2", "Title" : "In Bloom", "Length" : "4:15" } ] }
4.2、条件操作符
4.2.1、基本条件操作符
- MongoDB与RDBMS的条件操作比较
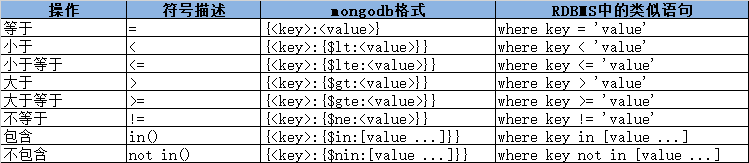
示例:
//查询media集合中的所有文档
> db.media.find()
{ "_id" : ObjectId("6318484c66d3fc0450e5364b"), "name" : "zhangsan", "age" : 11, "addr" : "shanghai" }
{ "_id" : ObjectId("6318484c66d3fc0450e5364c"), "name" : "lisi", "age" : 22, "addr" : "beijing" }
{ "_id" : ObjectId("6318484c66d3fc0450e5364d"), "name" : "wanger", "age" : 33, "addr" : [ "beijing", "shanghai" ] }
{ "_id" : ObjectId("6318484d66d3fc0450e5364e"), "name" : "mazi", "age" : 44, "face" : "pock", "addr" : [ "beijing", "shanghai", "guangzhou" ] }
//查找addr是(等于)shanghai的(注意,当addr的值是列表时的现象)
> db.media.find({"addr":"shanghai"})
{ "_id" : ObjectId("6318484c66d3fc0450e5364b"), "name" : "zhangsan", "age" : 11, "addr" : "shanghai" }
{ "_id" : ObjectId("6318484c66d3fc0450e5364d"), "name" : "wanger", "age" : 33, "addr" : [ "beijing", "shanghai" ] }
{ "_id" : ObjectId("6318484d66d3fc0450e5364e"), "name" : "mazi", "age" : 44, "face" : "pock", "addr" : [ "beijing", "shanghai", "guangzhou" ] }
//查找age小于22的
> db.media.find({"age":{$lt:22}})
{ "_id" : ObjectId("6318484c66d3fc0450e5364b"), "name" : "zhangsan", "age" : 11, "addr" : "shanghai" }
//查找age小于等于22的
> db.media.find({"age":{$lte:22}})
{ "_id" : ObjectId("6318484c66d3fc0450e5364b"), "name" : "zhangsan", "age" : 11, "addr" : "shanghai" }
{ "_id" : ObjectId("6318484c66d3fc0450e5364c"), "name" : "lisi", "age" : 22, "addr" : "beijing" }
//查找age大于33的
> db.media.find({"age":{$gt:33}})
{ "_id" : ObjectId("6318484d66d3fc0450e5364e"), "name" : "mazi", "age" : 44, "face" : "pock", "addr" : [ "beijing", "shanghai", "guangzhou" ] }
//查找age大于等于33的
> db.media.find({"age":{$gte:33}})
{ "_id" : ObjectId("6318484c66d3fc0450e5364d"), "name" : "wanger", "age" : 33, "addr" : [ "beijing", "shanghai" ] }
{ "_id" : ObjectId("6318484d66d3fc0450e5364e"), "name" : "mazi", "age" : 44, "face" : "pock", "addr" : [ "beijing", "shanghai", "guangzhou" ] }
//查找age不等于33的
> db.media.find({"age":{$ne:33}})
{ "_id" : ObjectId("6318484c66d3fc0450e5364b"), "name" : "zhangsan", "age" : 11, "addr" : "shanghai" }
{ "_id" : ObjectId("6318484c66d3fc0450e5364c"), "name" : "lisi", "age" : 22, "addr" : "beijing" }
{ "_id" : ObjectId("6318484d66d3fc0450e5364e"), "name" : "mazi", "age" : 44, "face" : "pock", "addr" : [ "beijing", "shanghai", "guangzhou" ] }
//查找addr在列表["shanghai","nanjing"]中的(注意,当addr的值是列表时的现象)
> db.media.find({"addr":{$in:["shanghai","nanjing"]}})
{ "_id" : ObjectId("6318484c66d3fc0450e5364b"), "name" : "zhangsan", "age" : 11, "addr" : "shanghai" }
{ "_id" : ObjectId("6318484c66d3fc0450e5364d"), "name" : "wanger", "age" : 33, "addr" : [ "beijing", "shanghai" ] }
{ "_id" : ObjectId("6318484d66d3fc0450e5364e"), "name" : "mazi", "age" : 44, "face" : "pock", "addr" : [ "beijing", "shanghai", "guangzhou" ] }
//查找addr不在["shanghai","nanjing"]列表中的(注意,当addr的值是列表时的现象)
> db.media.find({"addr":{$nin:["shanghai","nanjing"]}})
{ "_id" : ObjectId("6318484c66d3fc0450e5364c"), "name" : "lisi", "age" : 22, "addr" : "beijing" }
4.2.2、匹配查询列表中的所有属性
- 操作符\$all的工作方式与\$in类似。
- \$in只要求查询列表中的一个值被文档匹配即可。
- \$all要求查询列表中的所有值都要被文档匹配。(in和all后面的就是查询列表)
示例:
//查询media集合中的所有文档
> db.media.find()
{ "_id" : ObjectId("6318484c66d3fc0450e5364b"), "name" : "zhangsan", "age" : 11, "addr" : "shanghai" }
{ "_id" : ObjectId("6318484c66d3fc0450e5364c"), "name" : "lisi", "age" : 22, "addr" : "beijing" }
{ "_id" : ObjectId("6318484c66d3fc0450e5364d"), "name" : "wanger", "age" : 33, "addr" : [ "beijing", "shanghai" ] }
{ "_id" : ObjectId("6318484d66d3fc0450e5364e"), "name" : "mazi", "age" : 44, "face" : "pock", "addr" : [ "beijing", "shanghai", "guangzhou" ] }
//匹配列表中的一个值在文档addr中即可
> db.media.find({"addr":{$in:["beijing","shanghai"]}})
{ "_id" : ObjectId("6318484c66d3fc0450e5364b"), "name" : "zhangsan", "age" : 11, "addr" : "shanghai" }
{ "_id" : ObjectId("6318484c66d3fc0450e5364c"), "name" : "lisi", "age" : 22, "addr" : "beijing" }
{ "_id" : ObjectId("6318484c66d3fc0450e5364d"), "name" : "wanger", "age" : 33, "addr" : [ "beijing", "shanghai" ] }
{ "_id" : ObjectId("6318484d66d3fc0450e5364e"), "name" : "mazi", "age" : 44, "face" : "pock", "addr" : [ "beijing", "shanghai", "guangzhou" ] }
//匹配列表中的所有值都要在文档addr中
> db.media.find({"addr":{$all:["beijing","shanghai"]}})
{ "_id" : ObjectId("6318484c66d3fc0450e5364d"), "name" : "wanger", "age" : 33, "addr" : [ "beijing", "shanghai" ] }
{ "_id" : ObjectId("6318484d66d3fc0450e5364e"), "name" : "mazi", "age" : 44, "face" : "pock", "addr" : [ "beijing", "shanghai", "guangzhou" ] }
4.2.3、and、or和not
1、and
- 在单个查询中可以使用\$and操作符,它将返回满足所有条件的文档。
db.COLLECTION_NAME.find({$and: [{key1: value1}, {key2: value2}]})
2、or
- 在单个查询中可以使用\$or操作符,它将返回满足其中任何一个条件的文档。
db.COLLECTION_NAME.find({$or: [{key1: value1}, {key2: value2}]})
- 通过\$or操作符可以同时执行多个查询,将多个无关的查询的结果结合在一起。如果\$or子句中的所有查询都得到索引的支持,MongoDB将执行索引扫描。否则,就执行集合扫描。
3、not
- 对运算符取反。
db.COLLECTION_NAME.find({key: {$not: {<operator-expression>}}})
示例:
//查询media集合中的所有文档
> db.media.find()
{ "_id" : ObjectId("6318484c66d3fc0450e5364b"), "name" : "zhangsan", "age" : 11, "addr" : "shanghai" }
{ "_id" : ObjectId("6318484c66d3fc0450e5364c"), "name" : "lisi", "age" : 22, "addr" : "beijing" }
{ "_id" : ObjectId("6318484c66d3fc0450e5364d"), "name" : "wanger", "age" : 33, "addr" : [ "beijing", "shanghai" ] }
{ "_id" : ObjectId("6318484d66d3fc0450e5364e"), "name" : "mazi", "age" : 44, "face" : "pock", "addr" : [ "beijing", "shanghai", "guangzhou" ] }
//addr等于beijing,且age小于40的文档(and)
> db.media.find({"addr": "beijing", "age": {$lt:40}})
{ "_id" : ObjectId("6318484c66d3fc0450e5364c"), "name" : "lisi", "age" : 22, "addr" : "beijing" }
{ "_id" : ObjectId("6318484c66d3fc0450e5364d"), "name" : "wanger", "age" : 33, "addr" : [ "beijing", "shanghai" ] }
//name等于wanger,或age小于20的文档(or)
> db.media.find({$or: [{"name": "wanger"}, {"age": {$lt:20}}]})
{ "_id" : ObjectId("6318484c66d3fc0450e5364b"), "name" : "zhangsan", "age" : 11, "addr" : "shanghai" }
{ "_id" : ObjectId("6318484c66d3fc0450e5364d"), "name" : "wanger", "age" : 33, "addr" : [ "beijing", "shanghai" ] }
//age不小于22的文档(not)
> db.media.find({"age":{$not:{$lt:22}}})
{ "_id" : ObjectId("6318484c66d3fc0450e5364c"), "name" : "lisi", "age" : 22, "addr" : "beijing" }
{ "_id" : ObjectId("6318484c66d3fc0450e5364d"), "name" : "wanger", "age" : 33, "addr" : [ "beijing", "shanghai" ] }
{ "_id" : ObjectId("6318484d66d3fc0450e5364e"), "name" : "mazi", "age" : 44, "face" : "pock", "addr" : [ "beijing", "shanghai", "guangzhou" ] }
4.2.4、使用\$slice对列表进行切片
- 使用\$slice对文档中的列表进行切片操作。\$slice操作符有两个参数:
- 第一个参数表示要返回列表元素的个数。
- 第二个参数是可选的,如果使用了该参数,那么第一个参数偏移量,第二个参数是要返回列表元素的个数。偏移量也可以使用负值,从列表尾部开始返回元素。
示例:
//查询media集合中的所有文档
> db.media.find()
{ "_id" : ObjectId("6318484c66d3fc0450e5364b"), "name" : "zhangsan", "age" : 11, "addr" : "shanghai" }
{ "_id" : ObjectId("6318484c66d3fc0450e5364c"), "name" : "lisi", "age" : 22, "addr" : "beijing" }
{ "_id" : ObjectId("6318484c66d3fc0450e5364d"), "name" : "wanger", "age" : 33, "addr" : [ "beijing", "shanghai" ] }
{ "_id" : ObjectId("6318484d66d3fc0450e5364e"), "name" : "mazi", "age" : 44, "face" : "pock", "addr" : [ "beijing", "shanghai", "guangzhou" ] }
//返回addr的前两个值
> db.media.find({"age": {$gt: 22}}, {"addr": {$slice: 2}})
{ "_id" : ObjectId("6318484c66d3fc0450e5364d"), "name" : "wanger", "age" : 33, "addr" : [ "beijing", "shanghai" ] }
{ "_id" : ObjectId("6318484d66d3fc0450e5364e"), "name" : "mazi", "age" : 44, "face" : "pock", "addr" : [ "beijing", "shanghai" ] }
//返回addr的后两个值
> db.media.find({"age": {$gt: 22}}, {"addr": {$slice: -2}})
{ "_id" : ObjectId("6318484c66d3fc0450e5364d"), "name" : "wanger", "age" : 33, "addr" : [ "beijing", "shanghai" ] }
{ "_id" : ObjectId("6318484d66d3fc0450e5364e"), "name" : "mazi", "age" : 44, "face" : "pock", "addr" : [ "shanghai", "guangzhou" ] }
//返回从第二值开始向后的两个值
> db.media.find({"age": {$gt: 22}}, {"addr": {$slice: [1,2]}})
{ "_id" : ObjectId("6318484c66d3fc0450e5364d"), "name" : "wanger", "age" : 33, "addr" : [ "shanghai" ] }
{ "_id" : ObjectId("6318484d66d3fc0450e5364e"), "name" : "mazi", "age" : 44, "face" : "pock", "addr" : [ "shanghai", "guangzhou" ] }
//返回从倒数第二值开始向后的两个值
> db.media.find({"age": {$gt: 22}}, {"addr": {$slice: [-2,2]}})
{ "_id" : ObjectId("6318484c66d3fc0450e5364d"), "name" : "wanger", "age" : 33, "addr" : [ "beijing", "shanghai" ] }
{ "_id" : ObjectId("6318484d66d3fc0450e5364e"), "name" : "mazi", "age" : 44, "face" : "pock", "addr" : [ "shanghai", "guangzhou" ] }
4.2.5、使用\$size过滤列表大小
- \$size操作符可以过滤出包含指定大小的列表的文档。
//查询media集合中的所有文档
> db.media.find()
{ "_id" : ObjectId("6318484c66d3fc0450e5364b"), "name" : "zhangsan", "age" : 11, "addr" : "shanghai" }
{ "_id" : ObjectId("6318484c66d3fc0450e5364c"), "name" : "lisi", "age" : 22, "addr" : "beijing" }
{ "_id" : ObjectId("6318484c66d3fc0450e5364d"), "name" : "wanger", "age" : 33, "addr" : [ "beijing", "shanghai" ] }
{ "_id" : ObjectId("6318484d66d3fc0450e5364e"), "name" : "mazi", "age" : 44, "face" : "pock", "addr" : [ "beijing", "shanghai", "guangzhou" ] }
//查询addr有两个元素的文档
> db.media.find({"addr": {$size: 2}})
{ "_id" : ObjectId("6318484c66d3fc0450e5364d"), "name" : "wanger", "age" : 33, "addr" : [ "beijing", "shanghai" ] }
4.2.6、搜索奇数/偶数
- 通过使用\$mod操作符可以查询特定的数值,该操作符有两个参数[除数, 余数]。
示例:
//查询media集合中的所有文档
> db.media.find()
{ "_id" : ObjectId("6318484c66d3fc0450e5364b"), "name" : "zhangsan", "age" : 11, "addr" : "shanghai" }
{ "_id" : ObjectId("6318484c66d3fc0450e5364c"), "name" : "lisi", "age" : 22, "addr" : "beijing" }
{ "_id" : ObjectId("6318484c66d3fc0450e5364d"), "name" : "wanger", "age" : 33, "addr" : [ "beijing", "shanghai" ] }
{ "_id" : ObjectId("6318484d66d3fc0450e5364e"), "name" : "mazi", "age" : 44, "face" : "pock", "addr" : [ "beijing", "shanghai", "guangzhou" ] }
//查询age是偶数的文档
> db.media.find({"age": {$mod: [2,0]}})
{ "_id" : ObjectId("6318484c66d3fc0450e5364c"), "name" : "lisi", "age" : 22, "addr" : "beijing" }
{ "_id" : ObjectId("6318484d66d3fc0450e5364e"), "name" : "mazi", "age" : 44, "face" : "pock", "addr" : [ "beijing", "shanghai", "guangzhou" ] }
//查询age是奇数的文档
> db.media.find({"age": {$mod: [2,1]}})
{ "_id" : ObjectId("6318484c66d3fc0450e5364b"), "name" : "zhangsan", "age" : 11, "addr" : "shanghai" }
{ "_id" : ObjectId("6318484c66d3fc0450e5364d"), "name" : "wanger", "age" : 33, "addr" : [ "beijing", "shanghai" ] }
4.2.7、查询特定的字段
- \$exists操作符会查询特定字段。该操作符有一个参数:为true时,存在为真;为false时,不存在为真。
示例:
//查询media集合中的所有文档
> db.media.find()
{ "_id" : ObjectId("63185af666d3fc0450e53655"), "name" : "zhangsan", "age" : 11, "addr" : "shanghai" }
{ "_id" : ObjectId("63185af666d3fc0450e53656"), "name" : "lisi", "age" : 22, "addr" : "beijing" }
{ "_id" : ObjectId("63185af666d3fc0450e53657"), "name" : "wanger", "age" : 33, "addr" : [ "beijing", "shanghai" ] }
{ "_id" : ObjectId("63185af766d3fc0450e53658"), "name" : "mazi", "age" : 44, "face" : "pock", "addr" : [ "beijing", "shanghai", "guangzhou" ] }
//查询有face字段的文档
> db.media.find({"face": {$exists: true}})
{ "_id" : ObjectId("63185af766d3fc0450e53658"), "name" : "mazi", "age" : 44, "face" : "pock", "addr" : [ "beijing", "shanghai", "guangzhou" ] }
//查询没有face字段的文档
> db.media.find({"face": {$exists: false}})
{ "_id" : ObjectId("63185af666d3fc0450e53655"), "name" : "zhangsan", "age" : 11, "addr" : "shanghai" }
{ "_id" : ObjectId("63185af666d3fc0450e53656"), "name" : "lisi", "age" : 22, "addr" : "beijing" }
{ "_id" : ObjectId("63185af666d3fc0450e53657"), "name" : "wanger", "age" : 33, "addr" : [ "beijing", "shanghai" ] }
4.2.8、查询特定的数据类型
- \$type操作符可以基于值的数据类型进行匹配。
示例:
//查询media集合中的所有文档
> db.media.find()
{ "_id" : ObjectId("6318600f1429a7d55c777d6f"), "Type" : "CD", "Artist" : "Nirvana", "Title" : "Nevermind", "Genre" : "Grunge", "Releasedate" : "1991.09.24", "Tracklist" : [ { "Track" : "1", "Title" : "Smells Like Teen Spirit", "Length" : "5:02" }, { "Track" : "2", "Title" : "In Bloom", "Length" : "4:15" } ] }
//Tracklist的值是数组
> db.media.find({"Tracklist": {$type: 3}})
{ "_id" : ObjectId("6318600f1429a7d55c777d6f"), "Type" : "CD", "Artist" : "Nirvana", "Title" : "Nevermind", "Genre" : "Grunge", "Releasedate" : "1991.09.24", "Tracklist" : [ { "Track" : "1", "Title" : "Smells Like Teen Spirit", "Length" : "5:02" }, { "Track" : "2", "Title" : "In Bloom", "Length" : "4:15" } ] }
//Tracklist的值中包含是对象
> db.media.find({"Tracklist": {$type: 4}})
{ "_id" : ObjectId("6318600f1429a7d55c777d6f"), "Type" : "CD", "Artist" : "Nirvana", "Title" : "Nevermind", "Genre" : "Grunge", "Releasedate" : "1991.09.24", "Tracklist" : [ { "Track" : "1", "Title" : "Smells Like Teen Spirit", "Length" : "5:02" }, { "Track" : "2", "Title" : "In Bloom", "Length" : "4:15" } ] }
- 数据类型和其代码对照表。
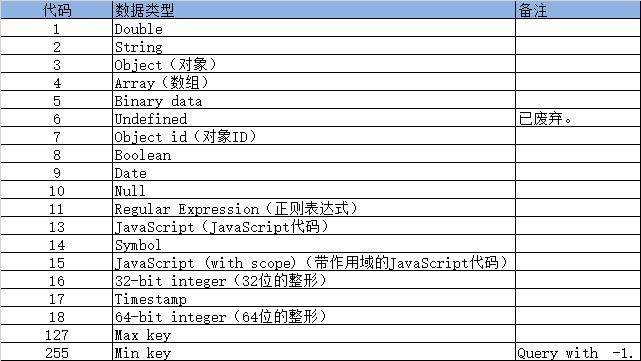
4.2.9、对列表的同一个元素进行匹配
- 对列表的同一个元素进行匹配,可以使用\$elemMatch操作符。如果集合中有多个文档,其中一些文档包含一些相同的信息,该操作符就非常有用了。
示例:
//查询media集合中的所有文档
> db.media.find().pretty()
{
"_id" : ObjectId("6318620d1429a7d55c777d70"),
"Type" : "CD",
"Artist" : "Nirvana",
"Title" : "Nevermind",
"Genre" : "Grunge",
"Releasedate" : "1991.09.24",
"Tracklist" : [
{
"Track" : "1",
"Title" : "Smells Like Teen Spirit",
"Length" : "5:02"
},
{
"Track" : "2",
"Title" : "In Bloom",
"Length" : "4:15"
}
]
}
{
"_id" : ObjectId("6318620e1429a7d55c777d71"),
"Type" : "CD",
"Artist" : "Nirvana",
"Title" : "Nevermind",
"Genre" : "Grunge",
"Releasedate" : "1991.09.24",
"Tracklist" : [
{
"Track" : "1",
"Title" : "You Know You're Right",
"Length" : "3:38"
},
{
"Track" : "5",
"Title" : "Smells Like Teen Spirit",
"Length" : "5:02"
}
]
}
//可以看出两个文档的Tracklist中都包含这两个键值对,但在第二个文档这两个键值对分属不同的对象
> db.media.find({"Tracklist.Track":"1","Tracklist.Title": "Smells Like Teen Spirit"})
{ "_id" : ObjectId("6318620d1429a7d55c777d70"), "Type" : "CD", "Artist" : "Nirvana", "Title" : "Nevermind", "Genre" : "Grunge", "Releasedate" : "1991.09.24", "Tracklist" : [ { "Track" : "1", "Title" : "Smells Like Teen Spirit", "Length" : "5:02" }, { "Track" : "2", "Title" : "In Bloom", "Length" : "4:15" } ] }
{ "_id" : ObjectId("6318620e1429a7d55c777d71"), "Type" : "CD", "Artist" : "Nirvana", "Title" : "Nevermind", "Genre" : "Grunge", "Releasedate" : "1991.09.24", "Tracklist" : [ { "Track" : "1", "Title" : "You Know You're Right", "Length" : "3:38" }, { "Track" : "5", "Title" : "Smells Like Teen Spirit", "Length" : "5:02" } ] }
//对列表的同一个元素进行匹配
> db.media.find({"Tracklist": {$elemMatch: {"Track": "1", "Title": "Smells Like Teen Spirit"}}})
{ "_id" : ObjectId("6318620d1429a7d55c777d70"), "Type" : "CD", "Artist" : "Nirvana", "Title" : "Nevermind", "Genre" : "Grunge", "Releasedate" : "1991.09.24", "Tracklist" : [ { "Track" : "1", "Title" : "Smells Like Teen Spirit", "Length" : "5:02" }, { "Track" : "2", "Title" : "In Bloom", "Length" : "4:15" } ] }
4.3、sort、limit和skip函数
- 三个函数的执行优先级是sort > skip > limit。
1、sort
- sort函数可以对查询返回的结果根据指定的键名进行排序,并使用1和-1来指定排序的方式,其中1为升序,-1是降序。
- 如果指定一个不存在的键,结果的顺序就是未定义的。
db.COLLECTION_NAME.find().sort({KEY_NAME:1})
2、limit
- limit函数可以限制返回结果的最大数目。该函数只有一个参数,希望返回结果的数目。如果参数为0,将返回所有结果。
db.COLLECTION_NAME.find().limit(NUM)
3、skip
- skip函数可以忽略掉集合中的前n个文档。
db.COLLECTION_NAME.find().skip(NUM)
4、函数结合使用
- 所有函数都可与其他函数结合使用。
示例:
//查询media集合中的所有文档
> db.media.find()
{ "_id" : ObjectId("63189c23dc0a01ca13d2fa0c"), "name" : "zhangsan", "age" : 11, "addr" : "shanghai" }
{ "_id" : ObjectId("63189c23dc0a01ca13d2fa0d"), "name" : "lisi", "age" : 22, "addr" : "beijing" }
{ "_id" : ObjectId("63189c23dc0a01ca13d2fa0e"), "name" : "wanger", "age" : 33, "addr" : [ "beijing", "shanghai" ] }
{ "_id" : ObjectId("63189c24dc0a01ca13d2fa0f"), "name" : "mazi", "age" : 44, "face" : "pock", "addr" : [ "beijing", "shanghai", "guangzhou" ] }
//基于age键的值对结果进行降序排序
> db.media.find().sort({age: -1})
{ "_id" : ObjectId("63189c24dc0a01ca13d2fa0f"), "name" : "mazi", "age" : 44, "face" : "pock", "addr" : [ "beijing", "shanghai", "guangzhou" ] }
{ "_id" : ObjectId("63189c23dc0a01ca13d2fa0e"), "name" : "wanger", "age" : 33, "addr" : [ "beijing", "shanghai" ] }
{ "_id" : ObjectId("63189c23dc0a01ca13d2fa0d"), "name" : "lisi", "age" : 22, "addr" : "beijing" }
{ "_id" : ObjectId("63189c23dc0a01ca13d2fa0c"), "name" : "zhangsan", "age" : 11, "addr" : "shanghai" }
//最多只返回media集合中的前2个文档
> db.media.find().limit(2)
{ "_id" : ObjectId("63189c23dc0a01ca13d2fa0c"), "name" : "zhangsan", "age" : 11, "addr" : "shanghai" }
{ "_id" : ObjectId("63189c23dc0a01ca13d2fa0d"), "name" : "lisi", "age" : 22, "addr" : "beijing" }
//略过media集合中的前2个文档
> db.media.find().skip(2)
{ "_id" : ObjectId("63189c23dc0a01ca13d2fa0e"), "name" : "wanger", "age" : 33, "addr" : [ "beijing", "shanghai" ] }
{ "_id" : ObjectId("63189c24dc0a01ca13d2fa0f"), "name" : "mazi", "age" : 44, "face" : "pock", "addr" : [ "beijing", "shanghai", "guangzhou" ] }
//先按降序排序,再忽略前2个,最后只输出一个文档
> db.media.find().limit(1).skip(2).sort({age: -1})
{ "_id" : ObjectId("63189c23dc0a01ca13d2fa0d"), "name" : "lisi", "age" : 22, "addr" : "beijing" }
4.4、聚集函数
- 除了count、distinct和group这3个基本的聚集函数,MongoDB还包含一个聚集框架。
- 聚集框架可以在不使用映射/归约框架的情况下,计算聚集结果。
1、使用count()函数返回文档的数目
//查询media集合中的所有文档
> db.media.find()
{ "_id" : ObjectId("63189c23dc0a01ca13d2fa0c"), "name" : "zhangsan", "age" : 11, "addr" : "shanghai" }
{ "_id" : ObjectId("63189c23dc0a01ca13d2fa0d"), "name" : "lisi", "age" : 22, "addr" : "beijing" }
{ "_id" : ObjectId("63189c23dc0a01ca13d2fa0e"), "name" : "wanger", "age" : 33, "addr" : [ "beijing", "shanghai" ] }
{ "_id" : ObjectId("63189c24dc0a01ca13d2fa0f"), "name" : "mazi", "age" : 44, "face" : "pock", "addr" : [ "beijing", "shanghai", "guangzhou" ] }
//函数count()将返回指定集合中的文档数目
> db.media.count()
4
//结合条件操作符,使用count()返回条件的文档数目
> db.media.find({"age": {$gt: 22}}).count()
2
2、使用distinct()函数获取值,并去重
- 使用distinct()函数
//查询media集合中的所有文档
> db.media.find()
{ "_id" : ObjectId("63189c23dc0a01ca13d2fa0c"), "name" : "zhangsan", "age" : 11, "addr" : "shanghai" }
{ "_id" : ObjectId("63189c23dc0a01ca13d2fa0d"), "name" : "lisi", "age" : 22, "addr" : "beijing" }
{ "_id" : ObjectId("63189c23dc0a01ca13d2fa0e"), "name" : "wanger", "age" : 33, "addr" : [ "beijing", "shanghai" ] }
{ "_id" : ObjectId("63189c24dc0a01ca13d2fa0f"), "name" : "mazi", "age" : 44, "face" : "pock", "addr" : [ "beijing", "shanghai", "guangzhou" ] }
//使用distinct()函数获取值,并去重
> db.media.distinct("addr")
[ "beijing", "guangzhou", "shanghai" ]
4.5、获取单个文档
- 如果只希望返回一个结果,可以使用findOne函数。find()函数会查询所有的文档,浪费CPU和内存。
//查询media集合中的所有文档
> db.media.find()
{ "_id" : ObjectId("63189c23dc0a01ca13d2fa0c"), "name" : "zhangsan", "age" : 11, "addr" : "shanghai" }
{ "_id" : ObjectId("63189c23dc0a01ca13d2fa0d"), "name" : "lisi", "age" : 22, "addr" : "beijing" }
{ "_id" : ObjectId("63189c23dc0a01ca13d2fa0e"), "name" : "wanger", "age" : 33, "addr" : [ "beijing", "shanghai" ] }
{ "_id" : ObjectId("63189c24dc0a01ca13d2fa0f"), "name" : "mazi", "age" : 44, "face" : "pock", "addr" : [ "beijing", "shanghai", "guangzhou" ] }
//与使用find({"age": {$gt: 22}}).limit(1)函数得到的结果一致
> db.media.findOne({"age": {$gt: 22}})
{
"_id" : ObjectId("63189c23dc0a01ca13d2fa0e"),
"name" : "wanger",
"age" : 33,
"addr" : [
"beijing",
"shanghai"
]
}
4.6、固定集合和自然顺序
- 自然顺序是数据库中集合的原生排序方法。所以,在查询集合中的文档时,如果没有显式指定排序顺序,结果将默认按照自然顺序返回,通常与文档插入的顺序一致。
- 标准集合的自然顺序没有定义,可能取决于数据增长模式、用于查询的索引和所使用的存储引擎。
- 固定集合的自然顺序一定与文档插入的顺序一致。
- 一旦固定集合达到设置的大小,最老的文档将被删除,最新的文档将被添加到末端,保证自然顺序与文档插入的顺序一致。该类型的集合可用于日志或自动归档数据。
- 与标准集合不同,固定集合必须使用createCollection函数显式地创建。必须使用参数指定集合的大小。
- 使用{\$natural:-1},将固定集合的查询结果按自然顺序的逆序排序。
db.media.find().sort({$natural:-1})
4.7、正则表达式
- MongoDB可以在集合中搜索文档时使用正则表达式。
- 如果符合前缀查询,它就尝试使用索引,以提高性能。前缀表达式以一个左锚点("\A")或插入符号(^)开头,后面根几个字符(例如: "^Matrix”)。
- 如果正则表达式不符合前缀表达式,就不能有效地使用索引。
- MongoDB使用\$regex操作符来设置匹配字符串的正则表达式,使用PCRE(Pert Compatible Regular Expression)作为正则表达式语言。
//regex操作符
{<field>: {$regex: /pattern/, $options: '<options>'}}
{<field>: {$regex: 'pattern', $options: '<options>'}}
{<field>: {$regex: /pattern/<options>}}
//正则表达式对象
{<field>: /pattern/<options>}
- \$regex操作符中的option选项可以改变正则匹配的默认行为,它包括i、m、x和s四个选项:
- i,忽略大小写。{<field>: {\$regex: /pattern/i}}
- m,多行匹配模式,会更改^和$元字符的默认行为,分别使用与行的开头和结尾匹配,而不是与输入字符串的开头和结尾匹配。{<field>: {$regex: /pattern/, $options: 'm'}}
- x,忽略非转义的空白字符,同时井号(#)被解释为注释的开头注。{<field>: {$regex: /pattern/, $options: 'x'}}
- s,单行匹配模式,会改变模式中的点号(.)元字符的默认行为,它会匹配所有字符,包括换行符(\n)。{<field>: {$regex: /pattern/, $options: 's'}}
- regex操作符与正则表达式对象的区别:
- 在\$in操作符中只能使用正则表达式对象。例如,{name: {\$in: [/^joe/i, /^jack/]}}
- 在使用隐式的\$and操作符中,只能使用\$regex。例如,{name: {\$regex: /^jo/i, $nin: ['john']}}
- 当option选项中包含x或s选项时,只能使用$\regex,例如:{name: {\$regex: /m.*line/, \$options: "si"}}
- 使用$regex操作符时,需要注意下面几个问题:
- i、m、x和s可以组合使用,例如:{name: {\$regex: /j*k/, \$options: "si"}}
- 在有索引的字段上进行正则匹配可以提高查询速度,而且当正则表达式使用的是前缀表达式时,查询速度会进一步提高,例如:{name: {\$regex: /^joe/}
示例:
//查询media集合中的所有文档
> db.media.find()
{ "_id" : ObjectId("6318979e9695f03c70025356"), "name" : "zhangoosan" }
{ "_id" : ObjectId("6318979e9695f03c70025357"), "name" : "zhangsi" }
{ "_id" : ObjectId("6318979e9695f03c70025358"), "name" : "Wangsan" }
{ "_id" : ObjectId("6318979f9695f03c70025359"), "name" : "wangoosi" }
//name包含oo的
> db.media.find({name: {$regex: /oo/}})
{ "_id" : ObjectId("6318979e9695f03c70025356"), "name" : "zhangoosan" }
{ "_id" : ObjectId("6318979f9695f03c70025359"), "name" : "wangoosi" }
//name以wang开头的
> db.media.find({name: {$regex: /^wang/}})
{ "_id" : ObjectId("6318979f9695f03c70025359"), "name" : "wangoosi" }
//name以wang开头的,不区分大小写
> db.media.find({name: {$regex: /^wang/, $options: 'i'}})
{ "_id" : ObjectId("6318979e9695f03c70025358"), "name" : "Wangsan" }
{ "_id" : ObjectId("6318979f9695f03c70025359"), "name" : "wangoosi" }
5、更新集合中的文档
- 注意,在查找(find)中使用点号[.]和在修改操作符中使用是用区别的。在修改操作符中每层的字段都是确定的。
//查询media集合中的所有文档
> db.media.find()
{ "_id" : ObjectId("6319caa1c58ecbc0e689091b"), "name" : "hengha", "age" : 21, "features" : [ "eyes", "mouth", "nose", "eyes" ], "body" : { "height" : 175, "weight" : 130 }, "CD" : [ { "Track" : "1", "Title" : "Smells Like Teen Spirit", "Length" : "5:02" }, { "Track" : "2", "Title" : "In Bloom", "Length" : "4:15" } ] }
//在find中跳过了列表索引
> db.media.find({"CD.Track": "1"})
//在修改操作符中显示使用了列表索引
> db.media.update({"name" : "hengha"}, {$set: {"CD.1.Track": "8"}})
5.1、update()的基本语法
- update函数会更新匹配到的文档:
- <query>或<filter>:匹配要更新的文档的查询。使用方法与find()相同。
- <update>:指定要更新的数据,也可以使用操作符。
- upsert:可选的。
- 为true时,如果没有文档与查询匹配,则创建一个新文档。更新与查询匹配的单个文档。
- 为false(默认)时,如果没有文档与查询匹配,不会插入新文档。
- 如果upsert和multi都为真,并且没有文档匹配查询,更新操作只插入单个文档。
- multi:可选的。
- 为true时,更新所有满足查询条件的文档。如果单个文档更新失败,则不更新其他文档。
- 为false(默认)时,只更新一个满足查询条件的文档。
- hint:可选的。指定用于支持查询的索引的文档或字符串。如果指定的索引不存在,则操作将出错。
- let:指定带有变量列表的文档。可以将变量从查询文本中分离出来来提高命令的可读性。
//只更新一个或所有满足查询条件的文档
db.COLLECTION_NAME.update(
<query>,
<update>,
{
upsert: <boolean>,
multi: <boolean>,
writeConcern: <document>,
collation: <document>,
arrayFilters: [ <filterdocument1>, ... ],
hint: <document|string>, // Added in MongoDB 4.2
let: <document> // Added in MongoDB 5.0
}
)
//只更新一个满足查询条件的文档
db.COLLECTION_NAME.updateOne(
<filter>,
<update>,
{
upsert: <boolean>,
writeConcern: <document>,
collation: <document>,
arrayFilters: [ <filterdocument1>, ... ],
hint: <document|string> // Available starting in MongoDB 4.2.1
}
)
//更新所有满足查询条件的文档
db.COLLECTION_NAME.updateMany(
<filter>,
<update>,
{
upsert: <boolean>,
writeConcern: <document>,
collation: <document>,
arrayFilters: [ <filterdocument1>, ... ],
hint: <document|string> // Available starting in MongoDB 4.2.1
}
)
5.2、替换整个文档
- 不使用修改操作符,将替换整个文档(_id除外)。
//查询media集合中的所有文档
> db.media.find()
{ "_id" : ObjectId("6318cdb9dc0a01ca13d2fa15"), "name" : "hengha1", "age" : 21, "features" : [ "eyes", "mouth", "nose" ], "body" : { "height" : 175, "weight" : 130 }, "CD" : [ { "Track" : "1", "Title" : "Smells Like Teen Spirit", "Length" : "5:02" }, { "Track" : "2", "Title" : "InBloom", "Length" : "4:15" } ] }
{ "_id" : ObjectId("6318cdb9dc0a01ca13d2fa16"), "name" : "hengha2", "age" : 21, "features" : [ "eyes", "mouth", "nose" ], "body" : { "height" : 175, "weight" : 130 }, "CD" : [ { "Track" : "1", "Title" : "Smells Like Teen Spirit", "Length" : "5:02" }, { "Track" : "2", "Title" : "InBloom", "Length" : "4:15" } ] }
{ "_id" : ObjectId("6318cdbadc0a01ca13d2fa17"), "name" : "hengha3", "age" : 23, "features" : [ "eyes", "mouth", "nose" ], "body" : { "height" : 175, "weight" : 130 }, "CD" : [ { "Track" : "1", "Title" : "Smells Like Teen Spirit", "Length" : "5:02" }, { "Track" : "2", "Title" : "InBloom", "Length" : "4:15" } ] }
//将hengha3的age修改为33,并删除CD(任何忽略的字段都将被移除)
> db.media.update({"name": "hengha3"}, {"name" : "hengha3", "age" : 33, "features" : [ "eyes", "mouth", "nose" ], "body" : { "height" : 175, "weight" : 130 }})
WriteResult({ "nMatched" : 1, "nUpserted" : 0, "nModified" : 1 })
//查看hengha3
> db.media.find({"name": "hengha3"})
{ "_id" : ObjectId("6318cdbadc0a01ca13d2fa17"), "name" : "hengha3", "age" : 33, "features" : [ "eyes", "mouth", "nose" ], "body" : { "height" : 175, "weight" : 130 } }
5.3、修改指定字段的值
- \$set操作符会修改指定字段的值。
示例:
//查询media集合中的所有文档
> db.media.find()
{ "_id" : ObjectId("6318da75acc52f243e62f12b"), "name" : "hengha", "age" : 22, "features" : [ "eyes", "mouth", "nose" ], "body" : { "height" : 175, "weight" : 130 }, "CD" : [ { "Track" : "1", "Title" : "Smells Like Teen Spirit", "Length" : "5:02" }, { "Track" : "2", "Title" : "InBloom", "Length" : "4:15" } ] }
//将hengha的age值改为81
> db.media.update({"name": "hengha"}, {$set: {"age": 81}})
WriteResult({ "nMatched" : 1, "nUpserted" : 0, "nModified" : 1 })
//将features的第二个元素改为mouth-1(修改数组中的元素)
> db.media.update({"name": "hengha"}, {$set: {"features.1": "mouth-1"}})
WriteResult({ "nMatched" : 1, "nUpserted" : 0, "nModified" : 1 })
//将body.weight的改为260(修改字典中的键值)
> db.media.update({"name": "hengha"}, {$set: {"body.weight": 260}})
WriteResult({ "nMatched" : 1, "nUpserted" : 0, "nModified" : 1 })
//将CD.1.Track的改为"4"(数组嵌套字典)
> db.media.update({"name": "hengha"}, {$set: {"CD.1.Track": "4"}})
WriteResult({ "nMatched" : 1, "nUpserted" : 0, "nModified" : 1 })
//查看hengha
> db.media.find()
{ "_id" : ObjectId("6318da75acc52f243e62f12b"), "name" : "hengha", "age" : 81, "features" : [ "eyes", "mouth-1", "nose" ], "body" : { "height" : 175, "weight" : 260 }, "CD" : [ { "Track" : "1", "Title" : "Smells Like Teen Spirit", "Length" : "5:02" }, { "Track" : "4", "Title" : "InBloom", "Length" : "4:15" } ] }
5.4、删除指定的字段
- \$unset操作符可以删除指定的字段。
//查询media集合中的所有文档
> db.media.insert({"name":"hengha", "age":21, "features":["eyes", "mouth", "nose"], "body":{"height":175, "weight":130}, "CD":[{"Track":"1", "Title":"Smells Like Teen Spirit", "Length":"5:02"}, {"Track":"2", "Title":"InBloom", "Length":"4:15"}]})
WriteResult({ "nInserted" : 1 })
//删除age
> db.media.update({"name": "hengha"}, {$unset: {"age": 1}})
WriteResult({ "nMatched" : 1, "nUpserted" : 0, "nModified" : 1 })
//查看hengha
> db.media.find()
{ "_id" : ObjectId("6318ddf9acc52f243e62f12f"), "name" : "hengha", "features" : [ "eyes", "mouth", "nose" ], "body" : { "height" : 175, "weight" : 130 }, "CD" : [ { "Track" : "1", "Title" : "Smells Like Teen Spirit", "Length" : "5:02" }, { "Track" : "2", "Title" : "InBloom", "Length" : "4:15" } ] }
5.5、将指定字段的值增大特定的增量
- \$inc操作符可以将指定字段的值增大特定的增量。
- 如果字段存在,就将该值增加给定的增量。
- 如果字段不存在,就创建该字段。
示例:
//查询media集合中的所有文档
> db.media.find()
{ "_id" : ObjectId("6318d2bbf0644c73767c194c"), "name" : "hengha", "age" : 21, "features" : [ "eyes", "mouth", "nose" ], "body" : { "height" : 175, "weight" : 130 }, "CD" : [ { "Track" : "1", "Title" : "Smells Like Teen Spirit", "Length" : "5:02" }, { "Track" : "2", "Title" : "InBloom", "Length" : "4:15" } ] }
//将hengha的age值增加10
> db.media.update({"name": "hengha"}, {$inc: {"age": 10}})
WriteResult({ "nMatched" : 1, "nUpserted" : 0, "nModified" : 1 })
//查看hengha
> db.media.find()
{ "_id" : ObjectId("6318d2bbf0644c73767c194c"), "name" : "hengha", "age" : 31, "features" : [ "eyes", "mouth", "nose" ], "body" : { "height" : 175, "weight" : 130 }, "CD" : [ { "Track" : "1", "Title" : "Smells Like Teen Spirit", "Length" : "5:02" }, { "Track" : "2", "Title" : "InBloom", "Length" : "4:15" } ] }
5.6、向列表中添加元素
1、\$push操作符
- \$push操作符可以向指定的字段(列表)中添加一个元素。(可以添加重复的元素)
- 如果该字段是数组,那么该值将被添加到数组中。
- 如果该字段不存在,那么该字段的值将被设置为数组。
- 如果该字段存在,但不是数组,将会抛出错误。
- \$push结合\$each操作符可以同时向列表中添加多个元素。
- \$each结合\$slice操作符可以限制列表(\$push操作的列表)中的元素个数。
- \$slice的值可以是负数或0:
- 为负数时,将只保留列表中的最后n个元素。
- 为0时,将清空列表。
- \$slice的值可以是负数或0:
- 注意,操作符\$slice必须是\$push操作中的第一个修改操作符(\$slice与\$each同级)。
示例:
//查询media集合中的所有文档
> db.media.find()
{ "_id" : ObjectId("6319af01c58ecbc0e6890912"), "name" : "hengha", "age" : 21, "features" : [ "eyes", "mouth", "nose" ], "body" : { "height" : 175, "weight" : 130 }, "CD" : [ { "Track" : "1", "Title" : "Smells Like Teen Spirit", "Length" : "5:02" }, { "Track" : "2", "Title" : "InBloom", "Length" : "4:15" } ] }
//向列表features中添加一个元素
> db.media.update({"name": "hengha"}, {$push: {"features": "ear"}})
WriteResult({ "nMatched" : 1, "nUpserted" : 0, "nModified" : 1 })
//向列表features中添加多个元素
> db.media.update({"name": "hengha"}, {$push: {"features": {$each: ["foot", "hand"]}}})
WriteResult({ "nMatched" : 1, "nUpserted" : 0, "nModified" : 1 })
//查看hengha
> db.media.find()
{ "_id" : ObjectId("6319af01c58ecbc0e6890912"), "name" : "hengha", "age" : 21, "features" : [ "eyes", "mouth", "nose", "ear", "foot", "hand" ], "body" : { "height" : 175, "weight" : 130 }, "CD" : [ { "Track" : "1", "Title" : "Smells Like Teen Spirit", "Length" : "5:02" }, { "Track" : "2", "Title" : "InBloom", "Length" : "4:15" } ] }
//向列表features中添加多个元素,并只保留最后3个元素
> db.media.update({"name": "hengha"}, {$push: {"features": {$each: ["head", "face"], $slice: -3}}})
WriteResult({ "nMatched" : 1, "nUpserted" : 0, "nModified" : 1 })
//查看hengha
> db.media.find()
{ "_id" : ObjectId("6319af01c58ecbc0e6890912"), "name" : "hengha", "age" : 21, "features" : [ "hand", "head", "face" ], "body" : { "height" : 175, "weight" : 130 }, "CD" : [ { "Track" : "1", "Title" : "Smells Like Teen Spirit", "Length" : "5:02" }, { "Track" : "2", "Title" : "InBloom", "Length" : "4:15" } ] }
2、\$addToSet操作符
- \$addToSet操作符可以向列表中添加元素。
- 只有元素在列表中不存在时,才能将该元素添加到列表中。
- \$addToSet结合\$each操作符可以同时向列表中添加多个元素。
示例:
//查询media集合中的所有文档
> db.media.find()
{ "_id" : ObjectId("6319adabc58ecbc0e6890911"), "name" : "hengha", "age" : 21, "features" : [ "eyes", "mouth", "nose" ], "body" : { "height" : 175, "weight" : 130 }, "CD" : [ { "Track" : "1", "Title" : "Smells Like Teen Spirit", "Length" : "5:02" }, { "Track" : "2", "Title" : "InBloom", "Length" : "4:15" } ] }
//向列表features中添加一个元素
> db.media.update({"name": "hengha"}, {$addToSet: {"features": "ear"}})
WriteResult({ "nMatched" : 1, "nUpserted" : 0, "nModified" : 1 })
//向列表features中添加多个元素
> db.media.update({"name": "hengha"}, {$addToSet: {"features": {$each: ["foot", "hand"]}}})
WriteResult({ "nMatched" : 1, "nUpserted" : 0, "nModified" : 1 })
//查看hengha
> db.media.find()
{ "_id" : ObjectId("6319adabc58ecbc0e6890911"), "name" : "hengha", "age" : 21, "features" : [ "eyes", "mouth", "nose", "ear", "foot", "hand" ], "body" : { "height" : 175, "weight" : 130 }, "CD" : [ { "Track" : "1", "Title" : "Smells Like Teen Spirit", "Length" : "5:02" }, { "Track" : "2", "Title" : "InBloom", "Length" : "4:15" } ] }
5.7、从列表中删除元素
- 从数组中删除元素的方法,包括\$pop、\$pull和\$pullAll。
1、\$pop操作符
- \$pop操作符可以从列表中删除第一个或最后一个元素。
- 参数是1时,从列表中删除最后一个元素。
- 参数是-1时,从列表中删除第一个元素。
示例:
//查询media集合中的所有文档
> db.media.find()
{ "_id" : ObjectId("6319b403c58ecbc0e6890913"), "name" : "hengha", "age" : 21, "features" : [ "eyes", "mouth", "nose" ], "body" : { "height" : 175, "weight" : 130 }, "CD" : [ { "Track" : "1", "Title" : "Smells Like Teen Spirit", "Length" : "5:02" }, { "Track" : "2", "Title" : "InBloom", "Length" : "4:15" } ] }
//从列表中删除最后一个元素
> db.media.update({"name": "hengha"}, {$pop: {"features": 1}})
WriteResult({ "nMatched" : 1, "nUpserted" : 0, "nModified" : 1 })
//查看hengha
> db.media.find()
{ "_id" : ObjectId("6319b403c58ecbc0e6890913"), "name" : "hengha", "age" : 21, "features" : [ "eyes", "mouth" ], "body" : { "height" : 175, "weight" : 130 }, "CD" : [ { "Track" : "1", "Title" : "Smells Like Teen Spirit", "Length" : "5:02" }, { "Track" : "2", "Title" : "InBloom", "Length" : "4:15" } ] }
//从列表中删除第一个元素
> db.media.update({"name": "hengha"}, {$pop: {"features": -1}})
WriteResult({ "nMatched" : 1, "nUpserted" : 0, "nModified" : 1 })
//查看hengha
> db.media.find()
{ "_id" : ObjectId("6319b403c58ecbc0e6890913"), "name" : "hengha", "age" : 21, "features" : [ "mouth" ], "body" : { "height" : 175, "weight" : 130 }, "CD" : [ { "Track" : "1", "Title" : "Smells Like Teen Spirit", "Length" : "5:02" }, { "Track" : "2", "Title" : "InBloom", "Length" : "4:15" } ] }
2、\$pull操作符
- \$pull操作符可以从列表中删除所有指定的元素。如果要删除的元素在列表中有多个重复值,那么这些重复值都会被删除。
示例:
//查询media集合中的所有文档
> db.media.find()
{ "_id" : ObjectId("6319bec7c58ecbc0e6890915"), "name" : "hengha", "age" : 21, "features" : [ "eyes", "mouth", "nose", "eyes" ], "body" : { "height" : 175, "weight" : 130 }, "CD" : [ { "Track" : "1", "Title" : "Smells Like Teen Spirit", "Length" : "5:02" }, { "Track" : "2", "Title" : "InBloom", "Length" : "4:15" } ] }
//从列表中删除所有指定的元素,可以看到两个eyes都被删除了
> db.media.update({"name": "hengha"}, {$pull: {"features": "eyes"}})
WriteResult({ "nMatched" : 1, "nUpserted" : 0, "nModified" : 1 })
//查看hengha
> db.media.find()
{ "_id" : ObjectId("6319bec7c58ecbc0e6890915"), "name" : "hengha", "age" : 21, "features" : [ "mouth", "nose" ], "body" : { "height" : 175, "weight" : 130 }, "CD" : [ { "Track" : "1", "Title" : "Smells Like Teen Spirit", "Length" : "5:02" }, { "Track" : "2", "Title" : "InBloom", "Length" : "4:15" } ] }
3、\$pullAll操作符
- \$pullAll操作符可以从列表中删除多个元素。
示例:
//查询media集合中的所有文档
> db.media.find()
{ "_id" : ObjectId("6319c185c58ecbc0e6890916"), "name" : "hengha", "age" : 21, "features" : [ "eyes", "mouth", "nose", "eyes" ], "body" : { "height" : 175, "weight" : 130 }, "CD" : [ { "Track" : "1", "Title" : "Smells Like Teen Spirit", "Length" : "5:02" }, { "Track" : "2", "Title" : "InBloom", "Length" : "4:15" } ] }
//从列表中删除所有指定的元素,可以看到nose和eyes(有两个)都被删除了
> db.media.update({"name": "hengha"}, {$pullAll: {"features": ["nose", "eyes"]}})
WriteResult({ "nMatched" : 1, "nUpserted" : 0, "nModified" : 1 })
//查看hengha
> db.media.find()
{ "_id" : ObjectId("6319c185c58ecbc0e6890916"), "name" : "hengha", "age" : 21, "features" : [ "mouth" ], "body" : { "height" : 175, "weight" : 130 }, "CD" : [ { "Track" : "1", "Title" : "Smells Like Teen Spirit", "Length" : "5:02" }, { "Track" : "2", "Title" : "InBloom", "Length" : "4:15" } ] }
5.8、使用\$操作符引用搜索到的列表
- \$操作符可用于在搜索到一个列表元素之后,对它进行数据操作。
示例:
//查询media集合中的所有文档
> db.media.find()
{ "_id" : ObjectId("6319c185c58ecbc0e6890916"), "name" : "hengha", "age" : 21, "features" : [ "eyes", "mouth", "nose", "eyes" ], "body" : { "height" : 175, "weight" : 130 }, "CD" : [ { "Track" : "1", "Title" : "Smells Like Teen Spirit", "Length" : "5:02" }, { "Track" : "2", "Title" : "In Bloom", "Length" : "4:15" } ] }
//使用$操作符引用搜索到的列表
> db.media.update({"CD.Title": "In Bloom"}, {$set: {"CD.$.Length": "8:30"}})
WriteResult({ "nMatched" : 1, "nUpserted" : 0, "nModified" : 1 })
//查看hengha
> db.media.find()
{ "_id" : ObjectId("6319c3f9c58ecbc0e6890917"), "name" : "hengha", "age" : 21, "features" : [ "eyes", "mouth", "nose", "eyes" ], "body" : { "height" : 175, "weight" : 130 }, "CD" : [ { "Track" : "1", "Title" : "Smells Like Teen Spirit", "Length" : "5:02" }, { "Track" : "2", "Title" : "In Bloom", "Length" : "8:30" } ] }
5.9、原子操作
- MongoDB支持针对单个文档的原子操作。
- 什么是原子操作,如果一组操作满足下面的条件:
- 一组操作完成之前,其他进程无法获得修改的结果。
- 如果其中一个操作失败,整组操作(整个原子操作)都将失败,并全部回滚,即数据将被恢复至运行这组操作之前的状态。
- 执行原子操作时的标准行为是锁定数据,不允许其他查询访问。不过,MongoDB并不支持锁或复杂的事务:
- 在分片环境中,分布式锁是昂贵并且缓慢的。
- MongoDB的目标是轻量并且快速,所以昂贵和缓慢的操作违反了它的原则。
- MongoDB开发者不喜欢死锁。在他们看来,系统最好是简单并且可预测的。
- MongoDB被设计用于处理实时问题。当执行一个操作需要锁定大量数据时,它将会停止一些轻量级查询的执行,这同样违背了MongoDB要求快速的目标。
- 下面几种更新操作符都是原子操作:
- \$set:修改指定字段的值。
- \$unset:删除指定的字段。
- \$inc:将指定字段的值增大特定的增量。
- \$push:向列表中添加元素。
- \$pull:从列表中删除所有指定的元素。
- \$pullAll:从列表中删除多个元素。
1、使用Update if Current方法
- 使用Update if Current(如果数据目前仍未改变就更新)方法实现原子更新的步骤:
- (1)从文档中取得对象。
- (2)在本地修改对象(使用之前提到的操作)。
- (3)发送更新请求来更新对象值,假定当前值仍然匹配之前取得的旧值。
- 在多用户环境中,许多应用都在同时处理数据,就可能出现ABA问题(多个进程同时修改一个数据)。
- 为避免ABA问题,可以使用下面的方法:
- 在更新的查询表达式中使用完整的对象,而不是只使用_id和comments.by字段。
- 使用Sset更新重要的字段。即使其他字段已经改变,也不会受该字段的影响。
- 在对象中添加一个版本变量,并在每次更新时增加它的值。
- 如有可能,请使用\$操作符,而不是Update-if-Current序列操作。
- 注意,MongoDB不支持在单个操作中以原子方式更新多个文档,相反,可使用嵌套对象来实现单个文档中的原子操作。
2、以原子方式修改并返回文档
- findAndModify()函数可以对文档进行修改并返回(原子操作)。
- findAndModify()可能会匹配到多个文档,但只会修改排序后的第一个文档。
- query:可选的。匹配要更新的文档的查询。使用方法与find()相同。
- sort:可选的。对匹配到的多个文档进行排序。
- remove:必须的。如果是true,将删除所选的文档。默认为false。
- update:必须的。对所选的文档进行更新。
- new:可选的。如果是true,将返回修改后的文档而不是原始文档。默认为false,返回原始文档。(删除操作忽略new选项)
- fields:可选的。要返回的字段的子集。例如, { <field1>: 1, <field2>: 1, ... }。
- upsert:可选的。与update字段一起使用。
- 为true时,如果没有文档与查询匹配,则创建一个新文档。否则,更新与查询匹配的一个文档。
- 为false(默认)时,如果没有文档与查询匹配,不会插入新文档。
db.COLLECTION_NAME.findAndModify({
query: <document>,
sort: <document>,
remove: <boolean>,
update: <document or aggregation pipeline>, // Changed in MongoDB 4.2
new: <boolean>,
fields: <document>,
upsert: <boolean>,
bypassDocumentValidation: <boolean>,
writeConcern: <document>,
collation: <document>,
arrayFilters: [ <filterdocument1>, ... ],
let: <document> // Added in MongoDB 5.0
});
示例:
//查询media集合中的所有文档
> db.media.find()
{ "_id" : ObjectId("6319f0e0c58ecbc0e6890929"), "name" : "hengha1", "age" : 21, "features" : [ "eyes", "mouth", "nose" ], "body" : { "height" : 175, "weight" : 130 }, "CD" : [ { "Track" : "1", "Title" : "Smells Like Teen Spirit", "Length" : "5:02" }, { "Track" : "2", "Title" : "In Bloom", "Length" : "4:15" } ] }
{ "_id" : ObjectId("6319f0e0c58ecbc0e689092a"), "name" : "hengha2", "age" : 21, "features" : [ "eyes", "mouth", "nose" ], "body" : { "height" : 175, "weight" : 130 }, "CD" : [ { "Track" : "1", "Title" : "Smells Like Teen Spirit", "Length" : "5:02" }, { "Track" : "2", "Title" : "In Bloom", "Length" : "4:15" } ] }
{ "_id" : ObjectId("6319f0e1c58ecbc0e689092b"), "name" : "hengha3", "age" : 23, "features" : [ "eyes", "mouth", "nose" ], "body" : { "height" : 175, "weight" : 130 }, "CD" : [ { "Track" : "1", "Title" : "Smells Like Teen Spirit", "Length" : "5:02" }, { "Track" : "2", "Title" : "In Bloom", "Length" : "4:15" } ] }
//修改文档,并返回修改前的文档(匹配到了两个,但只修改了一个文档)
> db.media.findAndModify({query: {"age": 21}, sort: {"name": -1}, update: {$set: {"age": 22}}})
{
"_id" : ObjectId("6319f0e0c58ecbc0e689092a"),
"name" : "hengha2",
"age" : 21,
"features" : [
"eyes",
"mouth",
"nose"
],
"body" : {
"height" : 175,
"weight" : 130
},
"CD" : [
{
"Track" : "1",
"Title" : "Smells Like Teen Spirit",
"Length" : "5:02"
},
{
"Track" : "2",
"Title" : "In Bloom",
"Length" : "4:15"
}
]
}
//查询media集合中的所有文档
> db.media.find()
{ "_id" : ObjectId("6319f0e0c58ecbc0e6890929"), "name" : "hengha1", "age" : 21, "features" : [ "eyes", "mouth", "nose" ], "body" : { "height" : 175, "weight" : 130 }, "CD" : [ { "Track" : "1", "Title" : "Smells Like Teen Spirit", "Length" : "5:02" }, { "Track" : "2", "Title" : "In Bloom", "Length" : "4:15" } ] }
{ "_id" : ObjectId("6319f0e0c58ecbc0e689092a"), "name" : "hengha2", "age" : 22, "features" : [ "eyes", "mouth", "nose" ], "body" : { "height" : 175, "weight" : 130 }, "CD" : [ { "Track" : "1", "Title" : "Smells Like Teen Spirit", "Length" : "5:02" }, { "Track" : "2", "Title" : "In Bloom", "Length" : "4:15" } ] }
{ "_id" : ObjectId("6319f0e1c58ecbc0e689092b"), "name" : "hengha3", "age" : 23, "features" : [ "eyes", "mouth", "nose" ], "body" : { "height" : 175, "weight" : 130 }, "CD" : [ { "Track" : "1", "Title" : "Smells Like Teen Spirit", "Length" : "5:02" }, { "Track" : "2", "Title" : "In Bloom", "Length" : "4:15" } ] }
//删除文档,并返回删除的文档(匹配到了三个,但只删除一个文档)
> db.media.findAndModify({query: {"name": {$regex: /^heng/}}, sort: {"name": -1}, remove: true})
{
"_id" : ObjectId("6319f0e1c58ecbc0e689092b"),
"name" : "hengha3",
"age" : 23,
"features" : [
"eyes",
"mouth",
"nose"
],
"body" : {
"height" : 175,
"weight" : 130
},
"CD" : [
{
"Track" : "1",
"Title" : "Smells Like Teen Spirit",
"Length" : "5:02"
},
{
"Track" : "2",
"Title" : "In Bloom",
"Length" : "4:15"
}
]
}
//查询media集合中的所有文档
> db.media.find()
{ "_id" : ObjectId("6319f0e0c58ecbc0e6890929"), "name" : "hengha1", "age" : 21, "features" : [ "eyes", "mouth", "nose" ], "body" : { "height" : 175, "weight" : 130 }, "CD" : [ { "Track" : "1", "Title" : "Smells Like Teen Spirit", "Length" : "5:02" }, { "Track" : "2", "Title" : "In Bloom", "Length" : "4:15" } ] }
{ "_id" : ObjectId("6319f0e0c58ecbc0e689092a"), "name" : "hengha2", "age" : 22, "features" : [ "eyes", "mouth", "nose" ], "body" : { "height" : 175, "weight" : 130 }, "CD" : [ { "Track" : "1", "Title" : "Smells Like Teen Spirit", "Length" : "5:02" }, { "Track" : "2", "Title" : "In Bloom", "Length" : "4:15" } ] }
5.10、使用save()函数更新数据
- 使用save()函数时,如果不指定id值,将会向集合中插入数据。
- save()函数的主要优势是:不需要指定upsert参数(update()函数中的参数)。
示例:
//查询media集合中的所有文档
> db.media.find()
//使用update
> db.media.update({"name": "hengha1"}, {$set: {"age": 81}}, {upsert: true})
WriteResult({
"nMatched" : 0,
"nUpserted" : 1,
"nModified" : 0,
"_id" : ObjectId("6319f86b1d1843efd0f9dcd2")
})
//使用save
> db.media.save({"name": "hengha2"}, {"age": 81})
WriteResult({ "nInserted" : 1 })
//查询media集合中的所有文档
> db.media.find()
{ "_id" : ObjectId("6319f86b1d1843efd0f9dcd2"), "name" : "hengha1", "age" : 81 }
{ "_id" : ObjectId("6319f8a5c58ecbc0e6890930"), "name" : "hengha2" }
6、删除集合中的文档
- 先find()搜索到目标文档,再使用该条件作为参数调用deleteOne和deleteMany函数删除目标文档。
- deleteOne和deleteMany函数会删除匹配到的文档:
- <filter>:匹配要更新的文档的查询。使用方法与find()相同。
- writeConcern:写入策略,默认为1,即要求确认写操作,0是不要求。
- 警告:在删除文档时,并不会同时删除对该文档的引用。一定要保证同时删除或更新这些引用,否则这些引用在执行时将返回null。
//只删除一个满足查询条件的文档
db.COLLECTION_NAME.deleteOne(
<filter>,
{
writeConcern: <document>,
collation: <document>,
hint: <document|string> // Available starting in MongoDB 4.4
}
)
//删除所有满足查询条件的文档
db.COLLECTION_NAME.deleteMany(
<filter>,
{
writeConcern: <document>,
collation: <document>
}
)
示例:
//查询media集合中的所有文档
> db.media.find()
{ "_id" : ObjectId("631b1989c3b68a93ffe375f5"), "name" : "hengha1", "age" : 21, "features" : [ "eyes", "mouth", "nose" ], "body" : { "height" : 175, "weight" : 130 }, "CD" : [ { "Track" : "1", "Title" : "Smells Like Teen Spirit", "Length" : "5:02" }, { "Track" : "2", "Title" : "In Bloom", "Length" : "4:15" } ] }
{ "_id" : ObjectId("631b1989c3b68a93ffe375f6"), "name" : "hengha2", "age" : 21, "features" : [ "eyes", "mouth", "nose" ], "body" : { "height" : 175, "weight" : 130 }, "CD" : [ { "Track" : "1", "Title" : "Smells Like Teen Spirit", "Length" : "5:02" }, { "Track" : "2", "Title" : "In Bloom", "Length" : "4:15" } ] }
{ "_id" : ObjectId("631b198ac3b68a93ffe375f7"), "name" : "hengha3", "age" : 23, "features" : [ "eyes", "mouth", "nose" ], "body" : { "height" : 175, "weight" : 130 }, "CD" : [ { "Track" : "1", "Title" : "Smells Like Teen Spirit", "Length" : "5:02" }, { "Track" : "2", "Title" : "In Bloom", "Length" : "4:15" } ] }
//先find()搜索到目标文档
> db.media.find({"age": {$lt: 23}})
{ "_id" : ObjectId("631b1989c3b68a93ffe375f5"), "name" : "hengha1", "age" : 21, "features" : [ "eyes", "mouth", "nose" ], "body" : { "height" : 175, "weight" : 130 }, "CD" : [ { "Track" : "1", "Title" : "Smells Like Teen Spirit", "Length" : "5:02" }, { "Track" : "2", "Title" : "In Bloom", "Length" : "4:15" } ] }
{ "_id" : ObjectId("631b1989c3b68a93ffe375f6"), "name" : "hengha2", "age" : 21, "features" : [ "eyes", "mouth", "nose" ], "body" : { "height" : 175, "weight" : 130 }, "CD" : [ { "Track" : "1", "Title" : "Smells Like Teen Spirit", "Length" : "5:02" }, { "Track" : "2", "Title" : "In Bloom", "Length" : "4:15" } ] }
//再删除所有目标文档
> db.media.deleteMany({"age": {$lt: 23}})
{ "acknowledged" : true, "deletedCount" : 2 }
//查询media集合中的所有文档
> db.media.find()
{ "_id" : ObjectId("631b198ac3b68a93ffe375f7"), "name" : "hengha3", "age" : 23, "features" : [ "eyes", "mouth", "nose" ], "body" : { "height" : 175, "weight" : 130 }, "CD" : [ { "Track" : "1", "Title" : "Smells Like Teen Spirit", "Length" : "5:02" }, { "Track" : "2", "Title" : "In Bloom", "Length" : "4:15" } ] }
7、引用数据
- 参考文档:https://www.mongodb.com/docs/v5.0/reference/database-references/?_ga=2.50199142.1916745264.1662563997-555618228.1661564910#database-references
- 如同SQL一样,MongoDB文档之间的引用也是通过查询来实现的。
- MongoDB有两种引用数据的方式:手动引用,或者使用DBRef标准(多种驱动都支持它们)。
- 手动引用:将一个文档的_id字段(或其他字段)包含在另一个文档中。
- DBRefs是从一个文档到另一个文档的引用,使用_id字段(或其他字段)、集合名称和数据库名称(可选)。DBRefs可以很容易地引用存储在多个集合或数据库中的文档。
1、手动引用数据
- (1)在集合people中插入一个文档。hengha的个人信息,他喜欢的CD是haha
> db.people.insert({"name":"hengha", "age":21, "features":["eyes", "mouth", "nose", "eyes"], "body":{"height":175, "weight":130}, "CD": "haha"})
WriteResult({ "nInserted" : 1 })
- (2)在集合media中插入一个文档。是CD haha的信息
> db.media.insert({"name":"haha", "content": [{"Track":"1", "Title":"Smells Like Teen Spirit", "Length":"5:02"}, {"Track":"2", "Title":"In Bloom", "Length":"4:15"}]})
WriteResult({ "nInserted" : 1 })
- (3)查询hengha喜欢的歌曲
//查出hengha的文档,并赋值给变量person(必须使用findOne)
> person=db.people.findOne({"name":"hengha"})
{
"_id" : ObjectId("631b5dc62aaac7d49ce9e137"),
"name" : "hengha",
"age" : 21,
"features" : [
"eyes",
"mouth",
"nose",
"eyes"
],
"body" : {
"height" : 175,
"weight" : 130
},
"CD" : "haha"
}
//通过person.CD获取hangha喜欢的CD名称(是"haha"),然后再通查询media集合获取CD的信息
> db.media.find({"name": person.CD})
{ "_id" : ObjectId("631b5dcd2aaac7d49ce9e138"), "name" : "haha", "content" : [ { "Track" : "1", "Title" : "Smells Like Teen Spirit", "Length" : "5:02" }, { "Track" : "2", "Title" : "In Bloom", "Length" : "4:15" } ] }
2、DBRefs
- DBRefs提供了在文档之间引用数据的规范。
- 用DBRefs替代手动引用的主要原因是,引用中文档所在的集合可能发生变化。如果引用的一直都是相同的集合,那么手动引用数据也可以。
- 使用DBRefs可以将数据库引用存储为标准的嵌入对象(JSON/BSON)。使用一种标准方式代表引用,意味着驱动和数据框架可以添加辅助方法,以标准的方法操作引用。
- 添加DBRefs引用值的语法:
- DBRefs中的字段顺序很重要,使用时的顺序必须是这样。
{ "$ref" : <COLLECTION_NAME>, "$id" : <value>, "$db" : <DATABASE_NAME> }
$ref:引用文档所在的集合名称。
$id:引用文档的_id字段的值。
$db:可选的。引用文档所在的数据库名称。
示例:
//创建并切换的数据库db1
> use db1
switched to db db1
//在数据库db1的集合media中插入一条数据
> db.media.insert({"content": [{"Track": "1", "Title": "Smells Like Teen Spirit", "Length": "5: 02"}, {"Track": "2", "Title": "In Bloom", "Length": "4: 15"}]})
WriteResult({ "nInserted": 1 })
//查询media集合中的所有文档
> db.media.find()
{ "_id": ObjectId("631b691b2aaac7d49ce9e13c"), "content": [ { "Track": "1", "Title": "Smells Like Teen Spirit", "Length": "5: 02" }, { "Track": "2", "Title": "In Bloom", "Length": "4: 15" } ] }
//创建并切换的数据库db2
> use db2
switched to db db2
//在数据库db2的集合people中插入一条数据,并引用数据库db1的集合media中的ObjectId("631b691b2aaac7d49ce9e13c")
> db.people.insert({"name": "hengha", "age": 21, "features": [ "eyes", "mouth", "nose", "eyes" ], "body": { "height": 175, "weight": 130 }, "CD":{"$ref" : "media", "$id" : ObjectId("631b691b2aaac7d49ce9e13c"), "$db": "db1"}})
WriteResult({ "nInserted": 1 })
//查询people集合中的所有文档
> db.people.find()
{ "_id": ObjectId("631b6f6ff7665b2923b33895"), "name": "hengha", "age": 21, "features": [ "eyes", "mouth", "nose", "eyes" ], "body": { "height": 175, "weight": 130 }, "CD": DBRef("media", ObjectId("631b691b2aaac7d49ce9e13c"), "db1") }
//获取指定的文档,并赋值给变量(必须使用findOne)
> use db2
switched to db db2
> var person=db.people.findOne({"name" : "hengha"})
//使用DBRef数据(数据引用)
> use db1
switched to db db1
> db[person.CD.$ref].findOne({_id: person.CD.$id})
{
"_id" : ObjectId("631b691b2aaac7d49ce9e13c"),
"content" : [
{
"Track" : "1",
"Title" : "Smells Like Teen Spirit",
"Length" : "5:02"
},
{
"Track" : "2",
"Title" : "In Bloom",
"Length" : "4:15"
}
]
}
1
# #

 浙公网安备 33010602011771号
浙公网安备 33010602011771号