1、设计数据库
- MongoDB数据库是非关系数据库并且是无模式的。这意味着,不同于关系数据库(例如MySQL),MongoDB数据库并未绑定到任何预定义的列或数据类型。这种实现方式最大的优势在于,处理数据非常灵活,因为该文档不需要遵守任何预定义的结构。
- 可以在一个集合中包含数百个甚至数千个结构不同的文档,而不会破坏MongoDB数据库的任何规则。
- 在MongoDB中文档的数据设计,体现出了MongoDB的灵活性,尤其是与关系数据库相比时。“文档(document)”是一个包含了真正数据的元素。
- 在下面示例中将会展示出同一集合Media中的两个完全不同类型的文档(注意,集合大致等同于SQL中的表):
{
"Type": "CD",
"Artist": "Nirvana",
"Title": "Nevermind",
"Genre": "Grunge",
"Releasedate": "1991.09.24",
"Tracklist": [
{
"Track": "1",
"Title": "Smells Like Teen Spirit",
"Length": "5:02"
},
{
"Track": "2",
"Title": "In Bloom",
"Length": "4:15"
}
]
}
{
"Type": "Book",
"Title": "Definitive Guide to MongoDB: A complete guide to dealing with Big Data usingMongoDB 3rd ed.",
"ISBN": "987-1-4842-1183-0",
"Publisher": "Apress",
"Author": [
"Hows, David",
"Plugge, Eelco",
"Membrey, Peter",
"Hawkins, Tim"
]
}
- 可以看出,这两个文档的大多数字段相互之间都有联系。它们都拥有字段Title和Type;但除了相似性,这两个文档是完全不同的,但它们被添加到了同一个集合Media中。
- MongoDB被称为无模式数据库,并不意味着MongoDB的数据结构是完全没有模式的。例如,在MongoDB中也需要定义集和索引。但是,不需要为新增的文档预定义任何结构,这与MySQL是不同的。
- 简单地说,MongoDB是一个极其动态的数据库。之前的示例无法正常存储在关系数据库中,除非在表中添加了所有可能的字段,但这样做会浪费空间和性能,更会引起极度混乱。
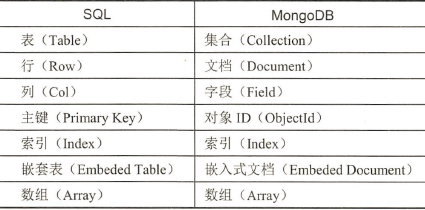
1.1、集合
- 集合是MongoDB中的一个常用术语。可以将集合看成存储文档(即数据)的容器,如图3-1所示。(如图3-2是关系数据库的典型模型)
- MongoDB中有两种集合:
- 默认的创建的集合,其大小是可以自动扩展的,即添加的数据越多,集合就变得越大。
- 固定大小(capped)的集合,只可以包含特定数量的数据,最老的文档将被新增的文档替代。
- MongoDB中的所有集合都有唯一的名称。集合的名称定义规则:
- 以字母或下划线(_)开头,名字中可以包含数字和字母。
- 不能使用\$符号($符号是MongoDB的保留关键字),不能使用空白字符串(" "),不能使用null字符,也不能以system."字符串开头。
- 最大长度为128字符,但建议使用简短的集合名称(大约不超过9个字符)。
- 单个数据库的名称空间数量的限制:
- MMAPv1存储引擎(默认的存储引擎)最多可以创建24000个名称空间。
- WiredTiger存储引擎没有这个限制。
- 每个集合至少包含两个名称空间:一个用于集合自身,另一个用于集合中创建的第一个索引。也就是说,如果为集合添加更多索引,那么该集合将使用更多名称空间。这意味着,如果使用MMAPv1存储引擎,且每个集合都只含有一个索引,那么每个数据库最多可以拥有12000个集合。
1.2、文档
- 文档由键/值对组成。例如,"Type":"Book"由键Type和值Book组成。
- 键的类型为字符串。
- 值可以是任何类型的数据,例如可以是数组甚至是二进制数据。
- MongoDB的数据类型,即可以用在文档中的数据类型:
- String:包含一串文本(或任何其他种类的字符)。该数据类型常用于存储文本值(例如,"Country":"Japan")。
- Integer(32位和64位):整型,常用于存储数值(例如,"Rank":1)。注意在整数的前后没有引号。
- Boolean:其值要么为真,要么为假。
- Double:用于存储浮点数。
- Min/Max keys:分别用于与BSON中的最低和最高值进行比较。
- Arrays:用于存储数组(例如,["Membrey,Peter","Plugge,Eelco","Hows,David"])。
- Timestamp:用于存储时间截。可以方便记录文档修改或添加的时间。
- Object:用于存储嵌入文档。
- Null:用于存储Null值。
- Symbol:用法与字符串一致。但通常该数据类型将被语言保留用于特定的符号类型,
- Date:用于存储UNIX时间格式的当前日期或时间(POSIX时间)。
- ObjectID:用于存储文档的ID。
- Binarydata:用于存储二进制数据。
- Regularexpression:用于正则表达式。所有选项都通过按字母顺序提供的特殊字符表示。
- JavaScriptCode:用于JavaScript代码。
1.3、在文档中内嵌或引用信息
- 可选择在文档中内嵌信息,或者引用另一个文档中的信息。
- 内嵌信息:在文档自身中添加某种类型的数据(例如包含了更多数据的数组)。
- 引用信息:在一个文档中引用另一个文档的内容。例如,使用关系数据库时会采用引用信息的方式。假设希望使用关系数据库记录CD、DVD和图书的信息,在该数据库中,可能需要一张表用于存储CD信息,另一张表用于存储CD的曲目列表。因此,可能就需要查询多个表来获取某个CD中包含的曲目列表。
- 在MongoDB(和其他非关系数据库)中使用内嵌信息的方式,因为此方式更加简单。毕竞,文档本身能够实现这样的操作。采用这种方式将保持数据库简洁,保证所有相关的信息都存储在单个文档中,甚至因为数据在磁盘中存储位置相近,处理速度会更快。
- 现在通过一个真实的场景,在关系和非关系数据库中存储CD数据,演示内嵌信息和引用信息这两种方式的区别。
//在关系数据库中,数据结构(引用信息)如下
|_media
|_cds
|_id, artist, title, genre, releasedate
|_cd_tracklists
|_cd_id, songtitle, length
//在非关系数据库中,数据结构(内嵌信息)如下
|_media
|_items
|_<document>
- 在非关系数据库中,文档结构将如下所示:
- 曲目列表信息内嵌在文档中。这种方式不仅高效,而且结构清晰。所有要存储的CD信息都将被添加到该单个文档中。
- 在关系数据库版本中,至少需要两个表。
- 在非关系数据库中,只要求一个集合和一个文档。
{
"Type": "CD",
"Artist": "Nirvana",
"Title": "Nevermind",
"Genre": "Grunge",
"Releasedate": "1991.09.24",
"Tracklist": [
{
"Track": "1",
"Title": "Smells Like Teen Spirit",
"Length": "5:02"
},
{
"Track": "2",
"Title": "In Bloom",
"Length": "4:15"
}
]
}
- 提示:
- 使用MongoDB的经验法则是:尽可能地使用内嵌数据。这种方式要高效得多,并且总是可行的。
- 此时,你可能会好奇拥有多用户的应用是如何工作的。通常来说,关系数据库版本将要求使用一个表存储所有用户,另外两个表用于存储CD信息。对于非关系数据库,可分别为用户和CD信息各使用一个集合。对于此类问题,MongoDB允许通过两种方式创建引用:手动方式和自动方式。
1.4、创建_id字段
- MongoDB数据库中的所有对象都有一个唯一标识符,用于区分不同的对象,该标识符被称作_id键。
- _id键是集合中所有文档的必需元素,_id键是添加到所有新创建文档中的第1个属性,因此MongoDB会将在创建集合时自动将_id添加到所有文档中。
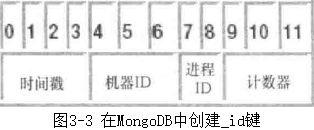
- 如果不手动指定_id值,MongoDB会自动将_id值设置为12字节长度的二进制数据(BSON类型)。
- 这样设计,使它具有唯一值的概率非常高。这个12字节的值包含4字节的时间截(从1970年1月1日以来的秒数)、3字节的机器ID、2字节的进程ID和3字节的计数器。计数器和时间截字段都以大端格式存储。这是因为MongoDB希望保证这些值能够按升序存储,而大端格式最符合此需求
- 注意:术语“大端”和“小端”指的是在内存中存储一个字的每个字节/位的方式。大端通常意味着最大的数字存储在开头。类似地,小端意味着最小的值存储在开头。
- 图3-3显示了_id键值的组成和每个部分的来源。
- 如何创建_id键?
- 访问MongoDB时使用的所有额外支持的驱动(例如PHP驱动或Python驱动),都支持这种特殊的BSON数据类型,并在创建新数据时使用它。
- 可以在MongoDB shell中调用Objectld()以创建_id键值。
- 可以使用ObjectId(string)指定自己的_id键值,string是十六进制字符串。
2、构建索引
- 索引是一种数据结构,用于收集集合中文档特定字段的值的信息。MongoDB的查询优化器使用该数据结构对集合中的文档进行快速排序。
- 索引使在文档中查询数据的速度非常快(不需要遍历整个数据库)。基本上,可以将索引看成已经执行并存储了结果的预定义查询。在MongoDB中通用的经验是:对于需要在关系数据库中创建索引的场景,在MongoDB中也应该创建索引。
- 为什么需要删除索引、重建索引,甚至删除集合内的所有索引?
- 最简单的答案是清除一些违规数据。例如,有时数据库的大小会毫无原因地剧烈增长。
- 索引也可能会使用过多的空间。
- 每个集合最多可以拥有40个索引。通常来说,这远超个人的需要,不过某天你有可能不经意间就达到这个限制。
- 注意:添加索引将提高查询速度,但也会降低插入或删除的速度。最好在读操作多于写操作的集合中添加索引。但当写操作多于读操作时,索引可能降低性能。
- List Indexes()命令可以查看目前已经存储的索引。
- getlndexes命令可以查看某个集合中创建的索引:
db.collection.getIndexes()
3、使用地理空间索引(没有看完)
- 如果你是一个MongoDB新手,之前也未曾使用过地理空间索引数据,本节内容的难度会比较大。不过不必担心,现在完全可以忽略本节内容,在之后随时可以再回来学习。
- MongoDB从版本1.4开始就已经实现了对地理空间索引的支持,可用于处理基于位置的查询。例如,可以使用该特性查找距用户当前位置最近的已知目标。
1、创建地理空间信息
- 地理空间信息的文档必须有一个子对象或数组(第一个元素指定了对象类型,紧接着是该元素的经度和纬度)。注意,参数type用于指定文档的GeoJSON对象类型,可以是Point、MultiPoint、LineString、MultiLineString、MultiPolygon、Polygon或GeometryCollection。
- Point类型指定某个条目所在的准确位置,因此需要两个值:经度和结度。
> db.restaurants.insert ({name: "Kimono", loc: {type: "Point", coordinates: [52.370451, 5.217497]}})
WriteResult({ "nInserted" : 1 })
- LineString类型指定某个沿着特定路线扩展的条目(例如街道),因此需要起点和终点。
> db.streets.insert({name: "Westblaak", loc: {type: "LineString", coordinates: [[52.36881, 4.890286], [52.368762, 4.890021]]}})
WriteResult({ "nInserted" : 1 })
- Polygon类型可用于指定(非默认的)图形(购物区域)。使用该类型时,需要保证起点和终点是一致的,从而可以闭合这个环。另外,该点的坐标将通过在数组中内嵌数组的方式提供。
> db.stores.insert({name: "SuperMall", loc: {type: "Polygon", coordinates: [[52.146917, 5.374337], [52.146966, 5.375471], [52.146722, 5.375085], [52.146744, 5.37437], [52.146917, 5.374337]]}})
WriteResult({ "nInserted" : 1 })
- Multi版本(MultiPoint、MultiLineString等)是选中数据类型的数组。
> db.restaurants.insert({name: "Shabu", loc: {type: "MultiPoint", coordinates: [[52.1487441, 5.3873406], [52.3569665, 4.890517]]}})
WriteResult({ "nInserted" : 1 })
- 一旦在文档中添加地理空间信息,就可以创建此类型的索引(当然也可以提前创建索引),为ensureIndex()函数提供2dsphere参数。
2、查询地理空间信息
- 下面的示例将展示如何(以及为什么)在实际应用中使用地理空间索引。
4、可插拔的存储引擎
- MongoDB的存储引擎是数据库的一部分,负责把数据存储在磁盘上。
- 在3.0版本之前,只能使用MongoDB原生的MMAPv1存储引擎。在3.2之前的任何版本中,MMAPv1仍然是默认的存储引擎。
- 在3.0之后,可以选择使用WiredTiger存储引擎,甚至使用存储引擎API开发自己的存储引擎。
- 默认情况下,MongoDB v3.0及其以后版本有两个支持的存储引擎:MMAPv1和WiredTiger。
- 与MMAPvl相比,WiredTiger存储引擎提供了更细的并发控制,同时具备原生的压缩功能。这样可以更好地利用硬件,降低存储成本,性能也好。
- 注意:每个存储引擎都有自己的优缺点,一个存储引擎可能最适合大量读取操作的任务,另一个存储引擎可能更便于执行大量写入任务。多个存储引擎可以共存于单个副本集中。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号