Kubernetes07-深入掌握Pod
1、Pod定义详解
- Pod定义的YAML文件完整内容如下:
apiVersion: v1 #必选,版本号,例如v1
kind: Pod #必选,Pod
metadata: #必选,元数据
name: string #必选,Pod名称
namespace: string #必选,Pod所属的命名空间
labels: #自定义标签
- name: string #自定义标签名字
annotations: #自定义注释列表
- name: string
spec: #必选,Pod中容器的详细定义
containers: #必选,Pod中容器列表
- name: string #必选,容器名称
image: string #必选,容器的镜像名称
imagePullPolicy: [Always | Never | IfNotPresent] #获取镜像的策略:Alawys表示总是下载镜像,IfnotPresent表示优先使用本地镜像,否则下载镜像,Nerver表示仅使用本地镜像
command: [string] #容器的启动命令列表。如不指定,则使用镜像打包时指定的启动命令
args: [string] #容器的启动命令参数列表
workingDir: string #容器的工作目录
volumeMounts: #挂载到容器内部的存储卷配置
- name: string #引用pod定义的共享存储卷的名称,需要使用volumes[]部分定义的卷名
mountPath: string #存储卷在容器内mount的绝对路径,应少于512字符
readOnly: boolean #是否为只读模式,默认值为读写模式
ports: #需要暴露的端口号列表
- name: string #端口的名称
containerPort: int #容器需要监听的端口号
hostPort: int #容器所在主机需要监听的端口号,默认与Container相同。设置hostPort 时,同一台宿主机将无法启动该容器的第2 份副本
protocol: string #端口协议,支持TCP和UDP,默认TCP
env: #容器运行前需设置的环境变量列表
- name: string #环境变量名称
value: string #环境变量的值
resources: #资源限制和资源请求的设置
limits: #资源限制的设置
cpu: string #Cpu的限制,单位为core数,将用于docker run --cpu-shares参数
memory: string #内存限制,单位可以为Mib、Gib,将用于docker run --memory参数
requests: #资源请求的设置
cpu: string #Cpu请求,单位为core数,容器启动的初始可用数量
memory: string #内存请求,单位可以为Mib、Gib,容器启动的初始可用数量
livenessProbe: #对Pod内个容器健康检查的设置,当探测无响应几次后将自动重启该容器,检查方法有exec、httpGet和tcpSocket,对一个容器只需设置其中一种方法即可
exec: #对Pod容器内检查方式设置为exec方式
command: [string] #exec方式需要制定的命令或脚本
httpGet: #对Pod内个容器健康检查方法设置为HttpGet,需要制定Path、port
path: string #http服务器上的访问URI
port: number #容器上要访问端口号或名称
host: string #要连接的主机名,默认为Pod的IP,可以在http request head中设置host头部。
scheme: string #用于连接host的协议,默认为HTTP
HttpHeaders: #自定义HTTP请求headers,HTTP允许重复headers
- name: string
value: string
tcpSocket: #对Pod内个容器健康检查方式设置为tcpSocket方式
port: number
initialDelaySeconds: 0 #容器启动后要等待多少秒后探针才开始工作(单位是秒),默认是0秒,最小值是0
timeoutSeconds: 1 #探针执行检测请求后,等待响应的超时时间(单位是秒),默认为1s,最小值是 1
periodSeconds: 10 #执行探测的时间间隔(单位是秒),默认为10s,最小值是1
successThreshold: 1 #(失败-->就绪)探针检测失败后认为成功的最小连接成功次数,默认为1s,最小值为1s。(在Liveness和startupProbe探针中必须为1s)
failureThreshold: 3 #(就绪-->失败)探测失败的重试次数,重试一定次数后将认为失败,默认为3s,最小值为1s。(在readiness探针中,Pod会被标记为未就绪)
securityContext:
privileged:false
restartPolicy: [Always | Never | OnFailure] #Pod的重启策略。Always(默认值)表示一旦不管以何种方式终止运行,kubelet都将重启。OnFailure表示只有Pod以非0退出码退出才重启。Nerver表示Pod终止后,kubelet将退出码报告给Master,不会再重启该Pod
nodeSelector: obeject #设置NodeSelector表示将该Pod调度到包含这个label的node上,以key:value的格式指定
imagePullSecrets: #Pull镜像时使用的secret名称,以key:secretkey格式指定
- name: string
hostNetwork:false #是否使用主机网络模式,默认为false。如果设置为true,表示使用宿主机网络,不再使用Docker网桥,该Pod将无法在同一台宿主机上启动第2个副本。
volumes: #在该pod上定义共享存储卷列表
- name: string #共享存储卷名称 (volumes类型有很多种)。容器定义部分的containers[].volumeMounts[].name将引用该共享存储卷的名称。可以定义多个volume ,每个volume的name保持唯一。
emptyDir: {} #类型为emtyDir的存储卷,与Pod同生命周期的一个临时目录。为空值
hostPath: string #类型为hostPath的存储卷,表示挂载Pod所在宿主机的目录
path: string #Pod所在宿主机的目录,将被用于同期中mount的目录
secret: #类型为secret的存储卷,挂载集群与定义的secre对象到容器内部
scretname: string
items:
- key: string
path: string
configMap: #类型为configMap的存储卷,挂载预定义的configMap对象到容器内部
name: string
items:
- key: string
path: string
2、Pod的基本用法
2.1、pod中有多个容器
- Pod可以由一个或多个容器组合而成。
- 属于同一个Pod的多个容器之间相互访问时仅需要通过localhost就可以通信,使得这一组容器被“绑定”在了一个环境中。
- 当busybox和nginx两个容器应用为紧耦合的关系,并组合成一个整体对外提供服务时,应将这两个容器打包为一个Pod,如图3.1所示。
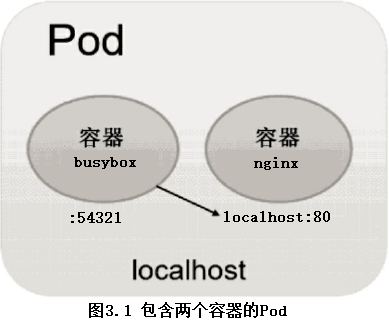
示例:
1、配置文件busybox-nginx-deployment.yaml


apiVersion: apps/v1 kind: Deployment metadata: name: busybox-nginx-deployment namespace: default spec: selector: matchLabels: app: busybox-nginx-pod replicas: 2 template: metadata: labels: app: busybox-nginx-pod spec: imagePullSecrets: - name: svharborwx volumes: - name: html hostPath: path: /apps/html containers: - name: test-busybox-container image: busybox:1.28 imagePullPolicy: IfNotPresent command: ["/bin/sleep", "10000000000"] ports: - containerPort: 54321 - name: test-nginx-container image: nginx:latest imagePullPolicy: IfNotPresent command: ["/usr/sbin/nginx", "-g", "daemon off;"] ports: - containerPort: 80 volumeMounts: - mountPath: /usr/share/nginx/html name: html
2、创建index.html文件
mkdir -p /apps/html echo "<h1>12</h1>" > /apps/html/index.html
3、运行kubectl create命令创建该Pod
kubectl create -f busybox-nginx-deployment.yaml
4、查看已经创建的Pod
]# kubectl get pods NAME READY STATUS RESTARTS AGE busybox-nginx-deployment-868b85c48b-6x4c6 2/2 Running 0 9s busybox-nginx-deployment-868b85c48b-phcqm 2/2 Running 0 9s
- 可以看到READY信息为2/2,表示Pod中的两个容器都成功运行了。
5、进入容器test-busybox-container,请求nginx的80端口
]# kubectl exec -it busybox-nginx-deployment-868b85c48b-6x4c6 -c test-busybox-container -- /bin/sh / # telnet localhost 80 GET /index.html HTTP/1.1 Host:localhost HTTP/1.1 200 OK Server: nginx/1.21.5 Date: Mon, 21 Mar 2022 13:45:10 GMT Content-Type: text/html Content-Length: 12 Last-Modified: Tue, 08 Mar 2022 10:41:59 GMT Connection: keep-alive ETag: "622732f7-c" Accept-Ranges: bytes <h1>12</h1>
2.2、taint(污点)的基本使用
- Taint让Node拒绝Pod的在其上运行,除非Pod明确声明能够容忍这污点。
2.2.1、kubectl taint的语法
- 一个污点由键、值和效果组成。作为这里的一个参数,它被表示为key=value:effect。
- 效果(effect)描述污点的作用,其值必须为NoSchedule、PreferNoSchedule或NoExecute。
- NoSchedule:表示不会将Pod调度到具有该污点的Node上。
- PreferNoSchedule:表示将尽量避免将Pod调度到具有该污点的Node上
- NoExecute:表示不会将Pod调度到具有该污点的Node上;如果Pod已经在该节点上运行,则会被驱逐。
]# kubectl taint --help Usage: kubectl taint nodes node_name key1=value1:taint_effect1 ... keyn=valuen:taint_effectn [options] Options: --all=false:选择集群中的所有节点 --dry-run='none':必须是"none"、"server"或"client"。 --overwrite=false:如果为真,允许覆盖污点,否则拒绝覆盖现有的污点 -l, --selector='':选择器(标签查询)进行筛选, 支持'=', '==', and '!='。(e.g. -l key1=value1,key2=value2)
2.2.2、定义污点
- 如果键值相同,但是最后的标识不同,也是属于不同的污点信息
kubectl taint nodes k8s-node node-type=production:NoSchedule kubectl taint nodes k8s-node node-type=production:PreferNoSchedule //在节点"k8s-node"添加污点,键为"dedicated",值为"special-user",效果为"NoSchedule"。 kubectl taint nodes k8s-node dedicated=special-user:NoSchedule //在标签有mylabel=X的节点上添加一个键为'dedicated'的污点 kubectl taint node -l myLabel=X dedicated=foo:PreferNoSchedule //向节点'k8s-node'添加一个带有键'bar'且没有值的污点 kubectl taint nodes k8s-node bar:NoSchedule
2.2.3、删除污点
kubectl taint nodes k8s-node node-type- kubectl taint nodes k8s-node node-type=production:NoSchedule- //从节点'k8s-node'中删除键为'dedicated'并效果为'NoSchedule'的污点(如果存在的话)。 kubectl taint nodes k8s-node dedicated:NoSchedule- //从节点"k8s-node"中删除键为'dedicated'的所有污点 kubectl taint nodes k8s-node dedicated-
2.2.4、查看节点污点信息
kubectl get nodes k8s-node1 -o go-template={{.spec.taints}}
kubectl describe node k8s-node
for i in $(kubectl get nodes -o name | awk -F'/' '{print $2}');do echo "$i:";kubectl describe nodes $i | grep 'Taints:';done
3、静态Pod
- 静态Pod是由kubelet进行管理的,仅存在于特定的Node上。它们不能通过API Server进行管理,无法与ReplicationController、Deployment或者DaemonSet进行关联,并且kubelet无法对它们进行健康检查。
- 静态Pod是由kubelet创建的,并且只在有kubelet的Node上运行。
- 创建静态Pod的两种方式:配置文件方式和HTTP方式。
3.1、配置文件方式
- 需要设置kubelet的启动参数“--config”,指定kubelet需要监控的静态pod文件所在的目录,kubelet会定期扫描该目录,并根据该目录下的.yaml或.json文件进行创建操作。
示例:
1、设置静态pod文件的目录
//获取启动参数“--config” ]# systemctl status kubelet.service -l ...... --config=/var/lib/kubelet/config.yaml ......
- 设置静态pod文件目录为/etc/kubelet.d/,然后重启kubelet服务。
]# vim /var/lib/kubelet/config.yaml ...... staticPodPath: /etc/kubelet.d/ ...... //重启服务,使配置生效 ]# systemctl daemon-reload ]# systemctl restart kubelet.service
2、在目录/etc/kubelet.d中放入static-nginx-pod.yaml文件
cat > /etc/kubelet.d/static-nginx-pod.yaml << EOF
apiVersion: v1
kind: Pod
metadata:
name: static-nginx-pod
labels:
app: static-nginx-pod
spec:
containers:
- name: test-nginx-container
image: nginx:latest
imagePullPolicy: Never
command: ["/usr/sbin/nginx", "-g", "daemon off;"]
ports:
- containerPort: 80
EOF
3、在本机上查看已经启动的容器。
]# docker container ls CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES eaeec2b37ed0 605c77e624dd "/usr/sbin/nginx -g …" 4 minutes ago Up 4 minutes k8s_test-nginx-container_static-nginx-pod-k8s-node1_default_88aa0ea4b2465468c53079731bc8da11_0 6faf89d1777c registry.aliyuncs.com/google_containers/pause:3.2 "/pause" 4 minutes ago Up 4 minutes k8s_POD_static-nginx-pod-k8s-node1_default_88aa0ea4b2465468c53079731bc8da11_0
4、到Master上查看Pod列表,可以看到这个static pod。
]# kubectl get pods -A NAMESPACE NAME READY STATUS RESTARTS AGE default static-nginx-pod-k8s-node1 1/1 Running 0 5m43s
5、由于静态Pod无法通过API Server直接管理,所以在Master上尝试删除这个Pod时,会使其变成Pending状态,不会被删除,然后会自动重建。
]# kubectl get pods -A NAMESPACE NAME READY STATUS RESTARTS AGE default static-nginx-pod-k8s-node1 0/1 Pending 0 2s ]# kubectl get pods -A NAMESPACE NAME READY STATUS RESTARTS AGE default static-nginx-pod-k8s-node1 1/1 Running 0 4s
6、要删除该Pod,只能到其所在Node上将其定义文件static-nginx-pod.yaml从/etc/kubelet.d/目录下删除。
]# rm -f /etc/kubernetes/manifests/static-nginx-pod.yaml --可以看到该静态pod生成的容器被删除了 ]# docker container ls
3.2、HTTP方式
- 通过设置kubelet的启动参数“--manifest-url”,kubelet将会定期从该URL地址下载Pod的定义文件,并以.yaml或.json文件的格式进行解析,然后创建Pod。其实现方式与配置文件方式是一致的。
4、Pod容器共享Volume
- 同一个Pod中的多个容器能够共享Pod级别的存储卷Volume。
- Volume可以被定义为各种类型,多个容器各自进行挂载操作,将一个Volume挂载为容器内部需要的目录,如图3.2所示。
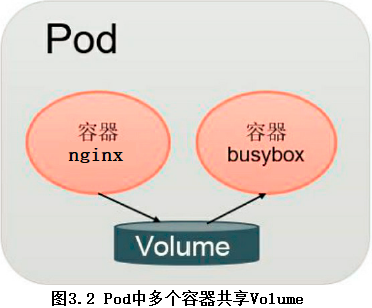
- 在下面的例子中,在Pod内包含两个容器:nginx和busybox,在Pod级别设置Volume“app-logs”,用于nginx向其中写日志文件,busybox读日志文件。配置文件pod-volume-applogs.yaml的内容如下:
- 这里设置的Volume名为app-logs,类型为emptyDir,挂载到nginx容器内的/var/log/nginx/目录,同时挂载到busybox容器内的/log/目录。
- nginx容器在启动后会向/var/log/nginx/目录写文件,busybox容器就可以读取其中的文件了。
apiVersion: apps/v1 kind: Deployment metadata: name: busybox-nginx-deployment namespace: default spec: selector: matchLabels: app: busybox-nginx-pod replicas: 2 template: metadata: labels: app: busybox-nginx-pod spec: imagePullSecrets: - name: svharborwx volumes: - name: app-logs emptyDir: {} containers: - name: test-busybox-container image: busybox:1.28 imagePullPolicy: IfNotPresent command: ["sh", "-c", "tail -f /log/error.log"] ports: - containerPort: 54321 volumeMounts: - mountPath: /log/ name: app-logs - name: test-nginx-container image: nginx:latest imagePullPolicy: IfNotPresent command: ["/usr/sbin/nginx", "-g", "daemon off;"] ports: - containerPort: 80 volumeMounts: - mountPath: /var/log/nginx/ name: app-logs
- nginx容器的启动命令为tail -f /log/error.log,我们可以通过kubectl logs命令查看busybox容器的输出内容。
]# kubectl logs busybox-nginx-deployment-784bfd588f-5wvnf -c test-busybox-container
5、Pod的配置管理
- 应用部署的一个最佳实践是将应用所需的配置信息与程序进行分离,这样可以使应用程序被更好地复用,通过不同的配置也能实现更灵活的功能。
- 将应用打包为镜像后,可以通过环境变量或者外挂文件的方式在创建容器时进行配置注入,但在大规模容器集群的环境中,对多个容器进行不同的配置将变得非常复杂。从Kubernetes 1.2开始提供了一种统一的应用配置管理方案——ConfigMap。
5.1、ConfigMap概述
- ConfigMap供容器使用的典型用法如下:
- (1)生成为容器内的环境变量。
- (2)设置容器启动命令的启动参数(需设置为环境变量)。
- (3)以Volume的形式挂载为容器内部的文件或目录。
- ConfigMap以一个或多个key:value的形式保存在Kubernetes系统中供应用使用,既可以用于表示一个变量的值(例如apploglevel=info),也可以用于表示一个完整配置文件的内容(例如server.xml=<?xml...>...)。
- 可以通过YAML配置文件或者直接使用kubectl create configmap命令行的方式来创建ConfigMap。
5.2、创建ConfigMap资源对象
5.2.1、通过YAML配置文件方式创建
1、cm-appvars.yaml描述了将几个应用所需的变量定义为ConfigMap的用法
apiVersion: v1 kind: ConfigMap metadata: name: cm-appvars data: apploglevel: info appdatadir: /var/data
2、执行kubectl create命令创建该ConfigMap:
kubectl create -f cm-appvars.yaml
3、查看创建好的ConfigMap:
]# kubectl get configmap NAME DATA AGE cm-appvars 2 25s ]# kubectl get configmap cm-appvars -o yaml ]# kubectl describe configmap cm-appvars
5.2.2、通过kubectl命令行方式创建
- 通过kubectl create configmap创建ConfigMap,可以使用参数--from-file或--from-literal指定内容,并且可以在一行命令中指定多个参数。
- (1)通过--from-file参数从文件中进行创建,可以指定key的名称(不指定以文件名为key),也可以在一个命令行中创建包含多个key的ConfigMap,语法为:
kubectl create configmap NAME --from-file=[key=]source
- (2)通过--from-file参数从目录中进行创建,该目录下的每个配置文件名都被设置为key,文件的内容被设置为value,语法为:
kubectl create configmap NAME --from-file=config-files-dir
- (3)使用--from-literal时会从文本中进行创建,直接将指定的key#=value#创建为ConfigMap的内容,语法为:
kubectl create configmap NAME --from-literal=keyl=valuel --from-literal=key2=value2
示例:
- nginx.conf文件:
user apps; worker_processes auto; error_log /apps/logs/nginx_80/error.log; pid /apps/run/nginx_80/nginx.pid; events { worker_connections 1024; } http { server_tokens off; vhost_traffic_status_zone; vhost_traffic_status_filter_by_host on; proxy_cache_path /apps/svr/nginx_80/proxy_temp levels=1:2 keys_zone=cache_one:4000m inactive=2d max_size=20g; upstream backend { server 127.0.0.1:80 weight=1; sticky; } include mime.types; default_type application/octet-stream; log_format main '$remote_addr - $remote_user [$time_local] $http_host "$request" ' '$status $body_bytes_sent "$http_referer" ' '"$http_user_agent" "$http_x_forwarded_for" $request_time '; access_log /apps/logs/nginx_80/access.log main; sendfile on; #tcp_nopush on; #keepalive_timeout 0; keepalive_timeout 65; gzip on; gzip_min_length 1k; gzip_buffers 4 16k; gzip_http_version 1.1; gzip_comp_level 5; gzip_types text/plain application/x-javascript text/css application/xml text/javascript application/x-httpd-php application/javascript application/json; gzip_disable "MSIE [1-6]\."; gzip_vary on; upstream ingress_master { server 10.234.116.58:32395; server 10.234.116.59:32395; server 10.234.116.60:32395; } server { listen 13531; server_name 127.0.0.1; location = /nginx_status { stub_status on; access_log off; allow 127.0.0.1; deny all; } location = /nginx_vts { allow 127.0.0.1; deny all; vhost_traffic_status_bypass_stats on; vhost_traffic_status_display; vhost_traffic_status_display_format json; } } server { listen 80; server_name localhost; #charset koi8-r; #access_log /apps/logs/nginx_80/host.access.log main; location / { # python web server forward # #include uwsgi_params; #uwsgi_pass 127.0.0.1:3031; proxy_cache cache_one; proxy_cache_valid 200 304 12h; proxy_cache_key $uri$is_args$args; proxy_set_header Host $host; proxy_set_header X-Forwarded-For $remote_addr; expires 2d; concat on; concat_max_files 30; # root html; root /apps/data/nginx_80; index index.html index.htm; } location ^~ /api/page/cloudvideo/vr { proxy_http_version 1.1; proxy_redirect off; proxy_set_header Host ecloud.10086.cn; proxy_set_header X-Real-IP $remote_addr; proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for; proxy_set_header X-Forwarded-Host $http_host; proxy_connect_timeout 10; proxy_send_timeout 300; proxy_read_timeout 300; proxy_buffer_size 128k; proxy_buffers 1000 128k; proxy_busy_buffers_size 256k; proxy_temp_file_write_size 256k; proxy_pass http://ingress_master; } location ^~ /api/web/cloudvideo/vr/ { proxy_http_version 1.1; proxy_redirect off; proxy_set_header Host ecloud.10086.cn; proxy_set_header X-Real-IP $remote_addr; proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for; proxy_set_header X-Forwarded-Host $http_host; proxy_connect_timeout 10; proxy_send_timeout 300; proxy_read_timeout 300; proxy_buffer_size 128k; proxy_buffers 1000 128k; proxy_busy_buffers_size 256k; proxy_temp_file_write_size 256k; proxy_pass http://ingress_master/vr/; } #error_page 404 /404.html; # redirect server error pages to the static page /50x.html # error_page 500 502 503 504 /50x.html; location = /50x.html { # root html; root /apps/data/nginx_80; } location = /status { include fastcgi_params; fastcgi_param SCRIPT_FILENAME $document_root$fastcgi_script_name; fastcgi_index index.php; fastcgi_pass 127.0.0.1:9000; } # proxy the PHP scripts to Apache listening on 127.0.0.1:80 # #location ~ \.php$ { # proxy_pass http://127.0.0.1; #} # pass the PHP scripts to FastCGI server listening on 127.0.0.1:9000 # location ~ \.php$ { root /apps/data/nginx_80; fastcgi_pass 127.0.0.1:9000; fastcgi_index index.php; fastcgi_param SCRIPT_FILENAME $document_root$fastcgi_script_name; include fastcgi_params; } # deny access to .htaccess files, if Apache's document root # concurs with nginx's one # #location ~ /\.ht { # deny all; #} } # another virtual host using mix of IP-, name-, and port-based configuration # #server { # listen 8000; # listen somename:8080; # server_name somename alias another.alias; # location / { # root html; # index index.html index.htm; # } #} # HTTPS server # #server { # listen 443 ssl; # server_name localhost; # ssl_certificate cert.pem; # ssl_certificate_key cert.key; # ssl_session_cache shared:SSL:1m; # ssl_session_timeout 5m; # ssl_ciphers HIGH:!aNULL:!MD5; # ssl_prefer_server_ciphers on; # location / { # root html; # index index.html index.htm; # } #} }
- fastcgi.conf文件
fastcgi_param SCRIPT_FILENAME $document_root$fastcgi_script_name; fastcgi_param QUERY_STRING $query_string; fastcgi_param REQUEST_METHOD $request_method; fastcgi_param CONTENT_TYPE $content_type; fastcgi_param CONTENT_LENGTH $content_length; fastcgi_param SCRIPT_NAME $fastcgi_script_name; fastcgi_param REQUEST_URI $request_uri; fastcgi_param DOCUMENT_URI $document_uri; fastcgi_param DOCUMENT_ROOT $document_root; fastcgi_param SERVER_PROTOCOL $server_protocol; fastcgi_param HTTPS $https if_not_empty; fastcgi_param GATEWAY_INTERFACE CGI/1.1; fastcgi_param SERVER_SOFTWARE nginx/$nginx_version; fastcgi_param REMOTE_ADDR $remote_addr; fastcgi_param REMOTE_PORT $remote_port; fastcgi_param SERVER_ADDR $server_addr; fastcgi_param SERVER_PORT $server_port; fastcgi_param SERVER_NAME $server_name; # PHP only, required if PHP was built with --enable-force-cgi-redirect fastcgi_param REDIRECT_STATUS 200;
- (1)在当前目录下含有配置文件nginx.conf,可以创建一个包含该文件内容的ConfigMap。
//创建configmap ]# kubectl create configmap cm-nginxconf --from-file=nginx.conf //查看configmap ]# kubectl get configmap NAME DATA AGE cm-nginxconf 1 35s ]# kubectl get configmap cm-nginxconf -o yaml ]# kubectl describe configmap cm-nginxconf
- (2)在configfiles目录下包含两个配置文件nginx.conf和fastcgi.conf,创建一个包含这两个文件内容的ConfigMap:
//查看configfiles目录 ]# ls -l configfiles/ -rw-r--r-- 1 root root 1034 3月 14 17:47 fastcgi.conf -rw-r--r-- 1 root root 5924 3月 15 16:43 nginx.conf //创建configmap ]# kubectl create configmap cm-nginx --from-file=configfiles //查看configmap ]# kubectl get configmap NAME DATA AGE cm-nginx 2 13s ]# kubectl get configmap cm-nginx -o yaml ]# kubectl describe configmap cm-nginx
- 使用--from-literal参数进行创建的示例如下:
//创建configmap ]# kubectl create configmap cm-appenv --from-literal=apploglevel=info --from-literal=appdatadir=/var/data //查看configmap ]# kubectl get configmap NAME DATA AGE cm-appenv 2 13s ]# kubectl get configmap cm-appenv -o yaml ]# kubectl describe configmap cm-appenv
5.3、在Pod中使用ConfigMap
- 容器使用ConfigMap的两种方法:
- (1)通过环境变量获取ConfigMap中的内容。
- (2)通过Volume挂载的方式将ConfigMap中的内容挂载为容器内部的文件或目录。
5.3.1、通过环境变量方式使用ConfigMap
- 环境变量的名称受POSIX命名规范([a-zA-Z_][azA-Z0-9_]*)约束,不能以数字开头。如果包含非法字符,则系统将跳过该条环境变量的创建,并记录一个Event来提示环境变量无法生成,但并不阻止Pod的启动。
1、在containers中使用env字段
- 以前面创建的“cm-appvars” ConfigMap为例:
apiVersion: v1 kind: ConfigMap metadata: name: cm-appvars data: apploglevel: info appdatadir: /var/data
- 在“cm-test-busybox-pod”的定义中,将“cm-appvars” ConfigMap中的内容以环境变量(APPLOGLEVEL和APPDATADIR)的方式设置为容器内部的环境变量,容器的启动命令将显示这两个环境变量的值("env | grepAPP"):
apiVersion: v1
kind: Pod
metadata:
name: cm-test-busybox-pod
spec:
containers:
- name: cm-test-busybox
image: busybox:1.28
imagePullPolicy: IfNotPresent
command: ["sh", "-c", "env | grep APP"]
env:
- name: APPLOGLEVEL #定义环境变量名称
valueFrom: #key “appl.glevel”对应的值
configMapKeyRef:
name: cm-appvars #环境变量的值取自cm-appvars中
key: apploglevel #key为“apploglevel”
- name: APPDATADIR #定义环境变量名称
valueFrom:
configMapKeyRef:
name: cm-appvars #环境变量的值取自cm-appvars中
key: appdatadir #key 为“appdatadir”
restartPolicy: Never
- 使用kubectl create -f命令创建该Pod,由于是测试Pod,所以该Pod在执行完启动命令后将会退出,并且不会被系统自动重启(restartPolicy=Never):
]# kubectl create -f cm-test-busybox-pod.yaml ]# kubectl get pods -A NAMESPACE NAME READY STATUS RESTARTS AGE default cm-test-busybox-pod 0/1 Completed 0 71s ]# kubectl logs cm-test-busybox-pod APPDATADIR=/var/data APPLOGLEVEL=info
2、在containers中使用envFrom字段
- Kubernetes从1.6版本开始,引入了一个新的字段envFrom,实现了在Pod环境中将ConfigMap(也可用于Secret资源对象)中所有定义的key=value自动生成为环境变量:
apiVersion: v1
kind: Pod
metadata:
name: cm-test-busybox-pod
spec:
containers:
- name: cm-test
image: busybox:1.28
imagePullPolicy: IfNotPresent
command: ["/bin/sh", "-c", "env | grep app"]
envFrom:
- configMapRef:
name: cm-appvars #根据cm-appvars中的key=value自动生成环境变量
restartPolicy: Never
5.3.2、通过volumeMount使用ConfigMap
1、引用ConfigMap时指定items
- 在“cm-test-nginx-pod”的定义中,将“cm-nginx” ConfigMap中的内容以文件的形式mount到容器内部的/configfiles目录下。
apiVersion: v1
kind: Pod
metadata:
name: cm-test-nginx-pod
spec:
containers:
- name: cm-test-nginx
image: nginx:latest
imagePullPolicy: IfNotPresent
command: ["/usr/sbin/nginx", "-g", "daemon off;"]
ports:
- containerPort: 80
volumeMounts :
- name: cm-nginx #引用volume的名称
mountPath : /configfiles #挂载到容器内的目录
volumes:
- name: cm-nginx #定义volume的名称
configMap:
name: cm-nginx #使用“cm-nginx” ConfigMap
items:
- key: fastcgi.conf #key=fastcgi.conf
path: fastcgi.conf #value将以fastcgi.conf文件名进行挂载
- key: nginx.conf #key=nginx.conf
path: nginx.conf #value将以nginx.conf文件名进行挂载
- 创建该Pod:
]# kubectl apply -f cm-test-nginx-pod.yaml ]# kubectl get pods -A NAMESPACE NAME READY STATUS RESTARTS AGE default cm-test-nginx-pod 1/1 Running 0 4s
- 登录容器,查看到在/configfiles目录下存在fastcgi.conf和nginx.conf文件,它们的内容就是“cm-nginx” ConfigMap中两个key定义的内容:
]# kubectl exec -it cm-test-nginx-pod -- /bin/sh # ls -l /configfiles lrwxrwxrwx 1 root root 19 Mar 26 13:02 fastcgi.conf -> ..data/fastcgi.conf lrwxrwxrwx 1 root root 17 Mar 26 13:02 nginx.conf -> ..data/nginx.conf
2、引用ConfigMap时不指定items
- 如果在引用ConfigMap时不指定items,则在容器内的目录下为每个key都生成一个文件,。
apiVersion: v1
kind: Pod
metadata:
name: cm-test-nginx-pod
spec:
containers:
- name: cm-test-nginx
image: nginx:latest
imagePullPolicy: IfNotPresent
command: ["/usr/sbin/nginx", "-g", "daemon off;"]
ports:
- containerPort: 80
volumeMounts :
- name: cm-nginx #引用volume的名称
mountPath : /configfiles #挂载到容器内的目录
volumes:
- name: cm-nginx #定义volume的名称
configMap:
name: cm-nginx #使用“cm-nginx” ConfigMap
5.4、使用ConfigMap的限制条件
- ConfigMap必须在Pod之前创建。
- ConfigMap受Namespace限制,只有处于相同Namespace中的Pod才可以引用它。
- ConfigMap中的配额管理还未能实现。
- kubelet只支持可以被API Server管理的Pod使用ConfigMap。kubelet在本Node上通过--manifest-url或--config自动创建的静态Pod将无法引用ConfigMap。
- 在Pod对ConfigMap进行挂载(volumeMount)操作时,在容器内部只能挂载为“目录”,无法挂载为“文件”。
- 在挂载到容器内部后,在目录下将包含ConfigMap定义的每个item,如果在该目录下原来还有其他文件,则容器内的该目录将被挂载的ConfigMap覆盖。如果应用程序需要保留原来的其他文件,则需要进行额外的处理。可以将ConfigMap挂载到容器内部的临时目录,再通过启动脚本将配置文件复制或者链接到(cp或link命令)应用所用的实际配置目录下。
6、在容器内获取Pod信息(Downward API)
- Downward API的作用:
- 在某些集群中,集群中的每个节点都需要将自身的标识(ID)及进程绑定的IP地址等信息事先写入配置文件中,进程在启动时会读取这些信息,然后将这些信息发布到某个类似服务注册中心的地方,以实现集群节点的自动发现功能。
- 此时Downward API就可以派上用场了,具体做法是先编写一个预启动脚本或Init Container,通过环境变量或文件方式获取Pod自身的名称、IP地址等信息,然后将这些信息写入主程序的配置文件中,最后启动主程序。
- Downward API将Pod信息注入容器内部的两种方式:
- (1)环境变量:用于单个变量,可以将Pod信息和Container信息注入容器内部。
- 将Pod信息注入为环境变量。
- 将容器资源信息注入为环境变量。
- (2)Volume挂载:将数组类信息生成为文件并挂载到容器内部。
- (1)环境变量:用于单个变量,可以将Pod信息和Container信息注入容器内部。
6.1、将Pod信息注入为环境变量
- 目前Downward API提供了Pod信息的以下变量(valueFrom特殊的用法):
- metadata.name:Pod的名称,当Pod通过RC生成时,其名称是RC随机产生的唯一名称。
- metadata.namespace:Pod所在的Namespace。
- status.podIP:Pod的IP地址,之所以叫作status.podIP而非metadata.IP,是因为Pod的IP属于状态数据,而非元数据。
- 通过Downward API将Pod的IP、名称和所在Namespace注入容器的环境变量中。容器应用使用env命令将全部环境变量打印到标准输出中:
apiVersion: v1
kind: Pod
metadata:
name: dapi-test-busybox-pod1
spec:
containers:
- name: dapi-test-busybox
image: busybox:1.28
imagePullPolicy: IfNotPresent
command: ["/bin/sh", "-c", "env"]
env:
- name: my_pod_name #Downward API的用法
valueFrom:
fieldRef:
fieldPath: metadata.name
- name: my_pod_namespace
valueFrom:
fieldRef:
fieldPath: metadata.namespace
- name: my_pod_ip
valueFrom:
fieldRef:
fieldPath: status.podIP
restartPolicy: Never
- 创建该Pod:
]# kubectl apply -f dapi-test-busybox-pod.yaml ]# kubectl get pods -A NAMESPACE NAME READY STATUS RESTARTS AGE default dapi-test-busybox-pod1 0/1 Completed 0 18s
- 查看dapi-test-busybox-pod1的日志:
- 从日志中可以看到Pod的IP、Name及Namespace等信息都被保存到了容器的环境变量中。
]# kubectl logs dapi-test-busybox-pod1 | grep my_pod my_pod_ip=10.10.169.132 my_pod_name=dapi-test-busybox-pod my_pod_namespace=default
6.2、将容器资源信息注入为环境变量
- 目前Downward API提供了container信息的以下变量(valueFrom特殊的用法):
- requests.cpu:容器的CPU请求值。
- limits.cpu:容器的CPU限制值。
- requests.memory:容器的内存请求值。
- limits.memory:容器的内存限制值。
- 通过Downward API将Container的资源请求和限制信息注入容器的环境变量中。容器应用使用env命令将设置的资源请求和资源限制环境变量打印到标准输出中:
- resourceFieldRef可以将容器的资源请求和资源限制等配置设置为容器内部的环境变量。
apiVersion: v1
kind: Pod
metadata:
name: dapi-test-busybox-pod2
spec:
containers:
- name: dapi-test-busybox
image: busybox:1.28
imagePullPolicy: IfNotPresent
command: ["/bin/sh", "-c", "env"]
resources:
requests:
memory: "32Mi"
cpu: "250m"
limits:
memory: "64Mi"
cpu: "1500m"
env:
- name: my_cpu_request #Downward API的用法
valueFrom:
resourceFieldRef:
containerName: dapi-test-busybox
resource: requests.cpu
- name: my_cpu_limit
valueFrom:
resourceFieldRef:
containerName: dapi-test-busybox
resource: limits.cpu
- name: my_memory_request
valueFrom:
resourceFieldRef:
containerName: dapi-test-busybox
resource: requests.memory
- name: my_memory_limits
valueFrom:
resourceFieldRef:
containerName: dapi-test-busybox
resource: limits.memory
restartPolicy: Never
- 创建该Pod:
]# kubectl apply -f dapi-test-busybox-pod2.yaml ]# kubectl get pods -A NAMESPACE NAME READY STATUS RESTARTS AGE default dapi-test-busybox-pod2 0/1 Completed 0 6s
- 查看dapi-test-busybox-pod2的日志:
- 从日志中可以看到Container的requests.cpu、limits.cpu、requests.memory、limits.memory等信息都被保存到了容器的环境变量中。
]# kubectl logs dapi-test-busybox-pod2 | grep 'my_' my_memory_limits=67108864 my_memory_request=33554432 my_cpu_request=1 my_cpu_limit=2
6.3、Volume挂载方式
- 通过Downward API将Pod的Label、Annotation列表通过Volume挂载为容器中的一个文件。
- 这里要注意“volumes”字段中downwardAPI的特殊语法。通过items的设置,系统会根据path的名称生成文件。
apiVersion: v1
kind: Pod
metadata:
name: dapi-test-busybox-pod3
labels:
zone: us-est-coast
cluster: test-cluster1
annotations:
build: two
builder: john-doe
spec:
containers:
- name: dapi-test-busybox3
image: busybox:1.28
imagePullPolicy: IfNotPresent
command: ["/bin/sh", "-c", "sleep 3600"]
volumeMounts:
- name: podinfo
mountPath: /downwardAPI
readOnly: false
volumes:
- name: podinfo #Downward API的用法
downwardAPI:
items:
- path: "labels"
fieldRef:
fieldPath: metadata.labels
- path: "annotations"
fieldRef:
fieldPath: metadata.annotations
- 创建Pod:
]# kubectl apply -f dapi-test-busybox-pod3.yaml ]# kubectl get pods -A NAMESPACE NAME READY STATUS RESTARTS AGE default dapi-test-busybox-pod3 1/1 Running 0 33s
- 进入Pod:
- 将在容器内的/downwardAPI目录中生成labels和annotations两个文件。在labels文件中将包含metadata.labels的全部Label列表,在annotations文件中将包含metadata.annotations的全部Label列表。
]# kubectl exec -it dapi-test-busybox-pod3 -- /bin/sh / # ls -l /downwardAPI/ lrwxrwxrwx 1 root root 18 Mar 26 17:37 annotations -> ..data/annotations lrwxrwxrwx 1 root root 13 Mar 26 17:37 labels -> ..data/labels
7、Pod的生命周期和重启策略
- Pod的可能处于的状态:

- Pod的重启策略(RestartPolicy)应用于Pod内的所有容器,并且仅在Pod所处的Node上由kubelet进行判断和重启操作。当某个容器异常退出或者健康检查失败时,kubelet将根据RestartPolicy的设置来进行相应的操作。
- Pod的重启策略包括Always、OnFailure和Never,默认值为Always。
- Always:当容器失效时,由kubelet自动重启该容器。
- OnFailure:当容器终止运行且退出码不为0时,由kubelet自动重启该容器。
- Never:不论容器运行状态如何,kubelet都不会重启该容器。
- kubelet重启失效容器的时间间隔以sync-frequency乘以2n来计算,例如1、2、4、8倍等,最长延时5min,并且在成功重启后的10min后重置该时间。(重启的时间间隔会不断增大)
- Pod的重启策略与控制方式息息相关,当前可用于管理Pod的控制器包括ReplicationController、Job、DaemonSet及直接通过kubelet管理(静态Pod)。每种控制器对Pod的重启策略要求如下:
- RC和DaemonSet:必须设置为Always,需要保证该容器持续运行。
- Job:OnFailure或Never,确保容器执行完成后不再重启。
- kubelet:在Pod失效时自动重启它,不论将RestartPolicy设置为什么值,也不会对Pod进行健康检查。
- 常见的状态转换场景

- yaml文件示例
apiVersion: v1
kind: Pod
metadata:
name: restart-test-busybox-pod
spec:
containers:
- name: dapi-test-busybox
image: busybox:1.28
imagePullPolicy: IfNotPresent
command: ["/bin/sh", "-c", "sleep 3600"]
restartPolicy: Never
8、Pod健康检查和服务可用性检查
- Kubernetes对Pod的健康状态可以通过三类探针来检查:LivenessProbe和ReadinessProbe,kubelet定期执行这两类探针来诊断容器的健康状况。
- LivenessProbe探针:存活性探针,用于判断容器是否存活(Running状态)。
- LivenessProbe按照配置去探测容器(进程、或者端口、或者命令执行后是否成功等等),并判断容器是不是正常。如果探测失败,代表容器不健康(可以配置连续多少次失败才记为不健康),kubelet会杀掉该容器,并根据容器的重启策略做相应的处理。
- 如果没有配置LivenessProbe,则默认容器启动为通过(Success)状态,即探针返回值永远是Success,即Success后pod状态是RUNING。
- ReadinessProbe探针:就绪性探针,用于判断容器内的进程是否存活(或者说是否健康),只有进程(服务)正常,容器才能对外提供网络访问(启动完成并就绪)。
- 容器启动后会按照readinessProbe配置去探测容器中的进程,并判断容器中的进程是不是正常。如果成功,pod的Ready状态为true(Success),从0/1变为1/1。如果失败,pod的Ready状态为false,继续为0/1。
- 如果没有配置readinessProbe,则容器启动后状态默认为Success。
- 对于此pod、此pod关联的Service、EndPoint资源也将基于Pod的Ready状态进行设置,如果Pod运行过程中Ready状态变为false,系统将自动从Service资源关联的EndPoint列表中去除此pod。届时service资源接收到GET请求后,kube-proxy将一定不会把流量引入此pod中,通过这种机制就能防止将流量转发到不可用的Pod上。如果Pod恢复为Ready状态。将再会被加回Endpoint列表。kube-proxy也将有概率通过负载机制会引入流量到此pod中。
- startupProbe探针:启动性探针,判断容器中的进程是否已经启动、是否存活。在1.16版本增加startupProbe探针。
- 如果三种探针同时存在,会先执行startupProbe探针,如果探测失败,kubelet会杀掉该容器,并根据容器的重启策略做相应的处理。如果探测成功,才会执行另外两种探针。
- 引入startupProbe探针是为了服务readinessProbe、livenessProbe探针。initialDelaySeconds的时间并不好判断,因为容器中的进程启动的时间没有办法评估。
- readinessProbe、livenessProbe两种探针在容器启动后,会按照配置一直对容器进行探测,直到容器终止。startupProbe探针仅在容器启动时按照配置进行探测,只要探测成功一次,就会结束探测。
- 注意,在readinessProbe中可以不用配置initialDelaySeconds,不配置默认pod刚启动,就开始进行readinessProbe探测。因为readinessProbe失败并不会重启pod,只有startupProbe、livenessProbe失败才会重启pod。
- 注意,在startupProbe执行完之后,另外两种探针才会被执行。相当于容器刚启动的时候,另外2种探针如果配置了initialDelaySeconds,建议不要给太长。
- LivenessProbe探针:存活性探针,用于判断容器是否存活(Running状态)。
- LivenessProbe、ReadinessProbey和startupProbe都有以下三种实现方式:
- ExecAction:在容器内部执行一个命令,如果该命令的返回码为0,则表明容器健康。
- TCPSocketAction:通过容器的IP地址和端口号执行TCP检查,如果能够建立TCP连接,则表明容器健康。
- HTTPGetAction:通过容器的IP地址、端口号及路径调用HTTP Get方法,如果响应的状态码大于等于200且小于400,则认为容器健康。
- 每种探测方式,都需要设置initialDelaySeconds和timeoutSeconds两个参数:
- initialDelaySeconds:启动容器后进行首次健康检查的等待时间,单位为s。
- timeoutSeconds:健康检查发送请求后等待响应的超时时间,单位为s。当超时发生时,kubelet会认为容器已经无法提供服务,将会重启该容器。
8.1、实现LivenessProbe探针
8.1.1、以ExecAction方式实现LivenessProbe探针
- 通过执行“cat /tmp/health”命令来判断一个容器运行是否正常。在该Pod运行后,将在创建/tmp/health文件10s后删除该文件,而LivenessProbe健康检查的初始探测时间(initialDelaySeconds)为15s,探测结果是Fail,将导致kubelet杀掉该容器并重启它。
apiVersion: v1
kind: Pod
metadata:
name: probe-test-busybox-pod1
spec:
containers:
- name: probe-test-busybox
image: busybox:1.28
imagePullPolicy: IfNotPresent
args: ["/bin/sh", "-c", "echo ok > /tmp/health;sleep 10;rm -rf /tmp/health;sleep 600"]
livenessProbe:
exec:
command: ["cat", "/tmp/health"]
initialDelaySeconds: 15
timeoutSeconds: 1
8.1.2、以TCPSocketAction方式实现LivenessProbe探针
- 通过与容器内的localhost:80建立TCP连接进行健康检查
apiVersion: v1
kind: Pod
metadata:
name: probe-test-nginx-pod2
spec:
containers:
- name: probe-test-nginx
image: nginx:latest
imagePullPolicy: Never
ports:
- containerPort: 80
livenessProbe:
tcpSocket:
port: 80
initialDelaySeconds: 30
timeoutSeconds: 1
8.1.3、以HTTPGetAction方式实现LivenessProbe探针
- kubelet定时发送HTTP请求到localhost:80/_status/healthz来进行容器应用的健康检查。
apiVersion: v1
kind: Pod
metadata:
name: probe-test-nginx-pod3
spec:
containers:
- name: probe-test-nginx
image: nginx:latest
imagePullPolicy: Never
ports:
- containerPort: 80
livenessProbe:
httpGet:
path: /_status/healthz
port: 80
initialDelaySeconds: 30
timeoutSeconds: 1
8.2、Pod Readiness Gates
- Kubernetes的ReadinessProbe机制可能无法满足某些复杂应用对容器内服务可用状态的判断,所以Kubernetes从1.11版本开始,引入Pod Ready++特性对Readiness探测机制进行扩展,在1.14版本时达到GA稳定版,称其为Pod Readiness Gates。
- 通过Pod Readiness Gates机制,用户可以将自定义的ReadinessProbe探测方式设置在Pod上,辅助Kubernetes设置Pod何时达到服务可用状态(Ready)。为了使自定义的ReadinessProbe生效,用户需要提供一个外部的控制器(Controller)来设置相应的Condition状态。
- Pod的Readiness Gates在Pod定义中的ReadinessGate字段进行设置。
- 设置了一个类型为www.example.com/feature-1的新ReadinessGate:
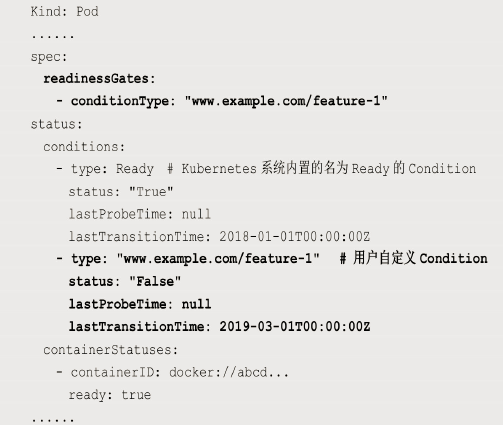
- 新增的自定义Condition的状态(status)将由用户自定义的外部控制器设置,默认值为False。Kubernetes将在判断全部readinessGates条件都为True时,才设置Pod为服务可用状态(Ready为True)。
9、玩转Pod调度
- 在Kubernetes平台上,很少会直接创建一个Pod,在大多数情况下会通过RC、Deployment、DaemonSet、Job等控制器完成一组Pod副本的创建、调度及全生命周期的自动控制任务。
- 最早的Kubernetes只有一个Pod副本控制器RC(Replication Controller)。
- RC控制器是这样设计实现的:RC独立于所控制的Pod,并通过Label标签这个松耦合关联关系控制目标Pod实例的创建和销毁。
- Deployment控制器(RC的继任者),用于更加自动地完成Pod副本的部署、版本更新、回滚等功能。
- Deployment通过ReplicaSet来实现Pod副本自动控制功能的。
- ReplicaSet控制器(RC的真正继任者),进一步增强了RC标签选择器的灵活性。
- RC的标签选择器只能选择一个标签。
- ReplicaSet拥有集合式的标签选择器,可以选择多个Pod标签,使用方式如下:
- Kubernetes的滚动升级就是利用ReplicaSet的这个特性来实现的。
selector:
matchLabels:
tier: frontend
matchExpressions:
- {key: tier, operator: In, values: [frontend]}
- 与RC不同,ReplicaSet被设计成能控制多个不同标签的Pod副本。
- 一种常见的应用场景是,应用MyApp目前发布了v1与v2两个版本,用户希望MyApp的Pod副本数保持为3个,可以同时包含v1和v2版本的Pod,就可以用ReplicaSet来实现这种控制,写法如下:
selector:
matchLabels:
version: v2
matchExpressions:
- {key: version, operator: In, values: [v1,v2]}
- 官方的建议:我们不应该直接使用底层的ReplicaSet来控制Pod副本,而应该使用管理ReplicaSet的Deployment对象来控制副本。
- Pod模板中的NodeSelector属性可以使某种Pod的所有副本在指定的一个或者一些节点上运行。比如希望将MySQL数据库调度到一个具有SSD磁盘的目标节点上,实现方式可分为以下两步:
- (1)把具有SSD磁盘的Node都打上自定义标签“disk=ssd”。
- (2)在Pod模板中设定NodeSelector的值为“disk: ssd”。
- 如此一来,Kubernetes在调度Pod副本的时候,就会先按照Node的标签过滤出合适的目标节点,然后选择一个最佳节点进行调度。看起来既简单又完美,但在真实的生产环境中可能面临以下令人尴尬的问题:
- (1)如果NodeSelector选择的Label不存在或者不符合条件,比如这些目标节点此时宕机或者资源不足,该怎么办?
- (2)如果要选择多种合适的目标节点,比如SSD磁盘的节点或者超高速硬盘的节点,该怎么办?Kubernates引入了NodeAffinity(节点亲和性设置)来解决该需求。
- 在真实的生产环境中还存在如下所述的特殊需求。
- 不同Pod之间的亲和性(Affinity)。比如MySQL数据库与Redis中间件不能被调度到同一个目标节点上,或者两种不同的Pod必须被调度到同一个Node上,以实现本地文件共享或本地网络通信等特殊需求,这就是PodAffinity要解决的问题。
- 有状态集群的调度。对于ZooKeeper、Elasticsearch、MongoDB、Kafka等有状态集群,虽然集群中的每个节点看起来都是相同的,但每个节点都必须有明确的、不变的唯一ID(主机名或IP地址),这些节点的启动和停止次序通常有严格的顺序。此外,由于集群需要持久化保存状态数据,所以集群中Pod不管在哪个Node上恢复,都需要挂载原来的Volume,因此这些Pod还需要捆绑具体的PV。针对这种复杂的需求,Kubernetes提供了StatefulSet副本控制器来解决问题,在Kubernetes 1.9版本发布后,StatefulSet才可用于正式生产环境中。
- 在每个Node上调度并且仅仅创建一个Pod副本。这种调度通常用于系统监控相关的Pod,比如主机上的日志采集、主机性能采集等进程需要被部署到集群中的每个节点,并且只能部署一个副本,这就是DaemonSet副本控制器所解决的问题。
- 对于批处理作业,需要创建多个Pod副本来协同工作,当这些Pod副本都完成自己的任务时,整个批处理作业就结束了。这种Pod运行且仅运行一次的特殊调度,Kubernates引入了新的Pod调度控制器Job来解决问题,并继续延伸了定时作业的调度控制器CronJob。
- 与单独的Pod实例不同,由RC、ReplicaSet、Deployment、DaemonSet等控制器创建的Pod副本实例都是归属于这些控制器的,这就产生了一个问题:控制器被删除后,归属于控制器的Pod副本该何去何从?
- 在Kubernates 1.9之前,在RC等对象被删除后,它们所创建的Pod副本都不会被删除;
- 在Kubernates 1.9以后,在RC等对象被删除后,它们所创建的Pod副本会被一并删除。如果不希望这样做,则可以通过kubectl命令的--cascade=false参数来取消这一默认特性:
kubectl delete replicaset my-repset --cascade=false
9.1、Deployment或RC:全自动调度
- Deployment或RC的主要功能之一就是自动部署一个容器应用的多份副本,以及持续监控副本的数量,在集群内始终维持用户指定的副本数量。
apiVersion: apps/v1
kind: Deployment
metadata:
name: test-nginx-deployment1
namespace: default
spec:
selector:
matchLabels:
app: test-nginx-pod
replicas: 2
template:
metadata:
labels:
app: test-nginx-pod
spec:
containers:
- name: test-nginx-container
image: nginx:latest
imagePullPolicy: Never
command: ["/usr/sbin/nginx", "-g", "daemon off;"]
ports:
- containerPort: 80
- 运行kubectl create命令创建这个Deployment:
//创建Deployment ]# kubectl apply -f test-nginx-deployment1.yaml //查看Deployment ]# kubectl get deployments NAME READY UP-TO-DATE AVAILABLE AGE test-nginx-deployment1 2/2 2 2 20s //查看Replicaset ]# kubectl get replicasets NAME DESIRED CURRENT READY AGE test-nginx-deployment1-6ddfc8bf69 2 2 2 32s //查看Pod ]# kubectl get pods -A -o wide NAMESPACE NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES default test-nginx-deployment1-6ddfc8bf69-8whws 1/1 Running 0 39s 10.10.36.73 k8s-node1 <none> <none> default test-nginx-deployment1-6ddfc8bf69-k9576 1/1 Running 0 39s 10.10.169.147 k8s-node2 <none> <none>
- 从调度策略上来说,这2个Nginx Pod由系统全自动完成调度。它们各自最终运行在哪个节点上,完全由Master的Scheduler经过一系列算法计算得出,用户无法干预调度过程和结果。
- 除了使用系统自动调度算法完成一组Pod的部署,Kubernetes也提供了多种丰富的调度策略,用户只需在Pod的定义中使用NodeSelector、NodeAffinity、PodAffinity、Pod驱逐等更加细粒度的调度策略设置,就能完成对Pod的精准调度。
9.2、NodeSelector:定向调度
- Kubernetes Master上的Scheduler服务(kube-scheduler进程)负责实现Pod的调度,整个调度过程通过执行一系列复杂的算法,最终为每个Pod都计算出一个最佳的目标节点,这一过程是自动完成的,通常我们无法知道Pod最终会被调度到哪个节点上。
- 在实际情况下,也可能需要将Pod调度到指定的一些Node上,可以通过Node的标签(Label)和Pod的nodeSelector属性相匹配,来达到上述目的。
- 实现NodeSelector(定向调度)需要两步:
- (1)通过kubectl label命令给目标Node打上一些标签。
- kubectl label nodes <node-name> <label-key>=<label-value>
- (2)在Pod的定义中加上nodeSelector的设置。
- (1)通过kubectl label命令给目标Node打上一些标签。
- 如果给多个Node都定义了相同的标签,则scheduler会根据调度算法从这组Node中挑选一个可用的Node进行Pod调度。
- 通过基于Node标签的调度方式,可以把集群中具有不同特点的Node都贴上不同的标签,例如“role=frontend”“role=backend”“role=database”等标签,在部署应用时就可以根据应用的需求设置NodeSelector来进行指定Node范围的调度。
- 注意,如果指定了Pod的nodeSelector条件,且在集群中不存在包含相应标签的Node,则即使在集群中还有其他可供使用的Node,这个Pod也无法被成功调度。
- 除了用户可以自行给Node添加标签,Kubernetes也给Node预定义一些标签:
- kubernetes.io/hostname
- beta.kubernetes.io/os(从1.14版本开始更新为稳定版,到1.18版本删除)
- beta.kubernetes.io/arch(从1.14版本开始更新为稳定版,到1.18版本删除)
- kubernetes.io/os(从1.14版本开始启用)
- kubernetes.io/arch(从1.14版本开始启用)
- NodeSelector通过标签的方式,简单实现了限制Pod所在节点的方法。亲和性调度机制则极大扩展了Pod的调度能力,主要的增强功能如下:
- 更具表达力(不仅仅是“符合全部”的简单情况)。
- 可以使用软限制、优先采用等限制方式,代替之前的硬限制,这样调度器在无法满足优先需求的情况下,会退而求其次,继续运行该Pod。
- 可以依据节点上正在运行的其他Pod的标签来进行限制,而非节点本身的标签。这样就可以定义一种规则来描述Pod之间的亲和或互斥关系。
- 亲和性调度功能包括节点亲和性(NodeAffinity)和Pod亲和性(PodAffinity)两个维度的设置。
- 节点亲和性与NodeSelector类似,增强了上述前两点优势;
- Pod的亲和与互斥限制则通过Pod标签而不是节点标签来实现,也就是上面第3点内容所陈述的方式,同时具有前两点提到的优点。
- NodeSelector将会继续使用,随着节点亲和性越来越能够表达nodeSelector的功能,最终NodeSelector会被废弃。
示例:
- 查看node的标签
]# kubectl get nodes --show-labels
- 为k8s-node1节点打上一个node-name=node1标签。
]# kubectl label nodes k8s-node1 node-name=node1
- 在Pod的定义中加上nodeSelector的设置,并创建pod。
]# vim test-nginx-deployment2.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: test-nginx-deployment2
namespace: default
spec:
selector:
matchLabels:
app: test-nginx-pod
replicas: 2
template:
metadata:
labels:
app: test-nginx-pod
spec:
containers:
- name: test-nginx-container
image: nginx:latest
imagePullPolicy: Never
command: ["/usr/sbin/nginx", "-g", "daemon off;"]
ports:
- containerPort: 80
nodeSelector:
node-name: node1
//创建Deployment
]# kubectl apply -f test-nginx-deployment2.yaml
//查看Pod所在的Node
]# kubectl get pods -A -o wide
NAMESPACE NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
default test-nginx-deployment2-86dd78fb7-5wvnf 1/1 Running 0 37s 10.10.36.74 k8s-node1 <none> <none>
default test-nginx-deployment2-86dd78fb7-pvl2w 1/1 Running 0 37s 10.10.36.75 k8s-node1 <none> <none>
9.3、NodeAffinity:Node亲和性调度
- NodeAffinity意为Node亲和性的调度策略,是用于替换NodeSelector的全新调度策略。目前有两种节点亲和性表达:
- requiredDuringSchedulingIgnoredDuringExecution(硬):必须满足指定的规则才可以调度Pod到Node上(功能与nodeSelector很像,但是使用的是不同的语法),相当于硬限制。
- preferredDuringSchedulingIgnoredDuringExecution(软):强调优先满足指定规则,调度器会尝试调度Pod到Node上,但并不强求,相当于软限制。多个优先级规则还可以设置权重(weight)值,以定义执行的先后顺序。
- IgnoredDuringExecution的意思是:如果一个Pod所在的节点在Pod运行期间标签发生了变更,不再符合该Pod的节点亲和性需求,则系统将忽略Node上Label的变化,该Pod能继续在该节点运行。
- 实现NodeAffinity(Node亲和性调度)需要两步:
- (1)通过kubectl label命令给目标Node打上一些标签。
- kubectl label nodes <node-name> <label-key>=<label-value>
- (2)在Pod的定义中加上nodeAffinity的设置。
- (1)通过kubectl label命令给目标Node打上一些标签。
- NodeAffinity规则设置的注意事项如下:
- 如果同时定义了nodeSelector和nodeAffinity,那么必须两个条件都得到满足,Pod才能最终运行在指定的Node上。
- 如果nodeAffinity指定了多个nodeSelectorTerms,那么其中一个能够匹配成功即可。
- 指的是nodeSelectorTerms下面有多个matchExpressions。
- 如果在nodeSelectorTerms中有多个matchExpressions,则一个节点必须满足所有matchExpressions才能运行该Pod。
- 指的是一个matchExpressions下面有多个key=value。
- 一些字段的解释是:
- key:选择器应用于的标签键。
- operator:表示一个键与一组值的关系。有效的操作符有In、NotIn、Exists、DoesNotExist、Gt和Lt。
- values:
- 如果操作符是In或NotIn,值数组必须是非空的。
- 如果操作符是Exists或DoesNotExist,则值数组必须为空。
- 如果运算符是Gt或Lt,则值数组必须有一个元素,该元素将被解释为整数。
- 虽然没有节点排斥功能,但是用NotIn和DoesNotExist就可以实现排斥的功能了。
- weight:与对应的nodeSelectorTerm相匹配的权重,范围为1-100。
示例1:
- 下面三个示例都只有一个label满足其要求:
]# kubectl label nodes k8s-node1 node-name=node1
- 设置NodeAffinity调度规则如下:
- requiredDuringSchedulingIgnoredDuringExecution要求只运行在有label是node-name=node1的节点上。
- preferredDuringSchedulingIgnoredDuringExecution的要求是尽量运行在label是disk=ssd的节点上。
apiVersion: apps/v1
kind: Deployment
metadata:
name: test-nginx-deployment3
namespace: default
spec:
selector:
matchLabels:
app: test-nginx-pod
replicas: 2
template:
metadata:
labels:
app: test-nginx-pod
spec:
containers:
- name: test-nginx-container
image: nginx:latest
imagePullPolicy: Never
command: ["/usr/sbin/nginx", "-g", "daemon off;"]
ports:
- containerPort: 80
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: node-name
operator: In
values:
- node1
preferredDuringSchedulingIgnoredDuringExecution:
- weight: 1
preference:
matchExpressions:
- key: disk
operator: In
values:
- ssd
- 创建并查看pod
//创建pod ]# kubectl apply -f test-nginx-deployment3.yaml //查看Pod ]# kubectl get pods -A -o wide NAMESPACE NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES default test-nginx-deployment3-69c747d667-t5gbd 1/1 Running 0 7s 10.10.36.77 k8s-node1 <none> <none> default test-nginx-deployment3-69c747d667-znfzv 1/1 Running 0 7s 10.10.36.76 k8s-node1 <none> <none>
示例2:
- 指定多个nodeSelectorTerms。调度成功
apiVersion: apps/v1 kind: Deployment metadata: name: test-nginx-deployment4 namespace: default spec: selector: matchLabels: app: test-nginx-pod replicas: 2 template: metadata: labels: app: test-nginx-pod spec: containers: - name: test-nginx-container image: nginx:latest imagePullPolicy: Never command: ["/usr/sbin/nginx", "-g", "daemon off;"] ports: - containerPort: 80 affinity: nodeAffinity: requiredDuringSchedulingIgnoredDuringExecution: nodeSelectorTerms: - matchExpressions: - key: node-name operator: In values: - node1 - matchExpressions: - key: node-ip operator: In values: - 10.1.1.333
示例3:
- 指定多个matchExpressions。调度不成功,因为缺少一个label。
apiVersion: apps/v1 kind: Deployment metadata: name: test-nginx-deployment5 namespace: default spec: selector: matchLabels: app: test-nginx-pod replicas: 2 template: metadata: labels: app: test-nginx-pod spec: containers: - name: test-nginx-container image: nginx:latest imagePullPolicy: Never command: ["/usr/sbin/nginx", "-g", "daemon off;"] ports: - containerPort: 80 affinity: nodeAffinity: requiredDuringSchedulingIgnoredDuringExecution: nodeSelectorTerms: - matchExpressions: - key: node-name operator: In values: - node1 - key: node-ip operator: In values: - 10.1.1.333
- 执行下面命令后调度成功:
kubectl label nodes k8s-node1 node-ip=10.1.1.333
9.4、PodAffinity:Pod亲和与互斥调度策略
- Pod间的亲和与互斥从Kubernetes 1.4版本开始引入。
- 从另一个角度来限制Pod所能运行的节点:
- 根据在节点上正在运行的Pod的标签而不是节点的标签进行判断和调度,要求对节点和Pod两个条件进行匹配。
- 这种规则可以描述为:如果在具有标签X的Node上运行了一个或者多个符合条件Y的Pod,那么Pod应该(如果是互斥的情况,那么就变成拒绝)运行在这个Node上。
- 这里X指的是一个集群中的节点、机架、区域等概念,通过Kubernetes内置节点标签中的key来进行声明。这个key的名字为topologyKey,意为表达节点所属的topology范围。
- kubernetes.io/hostname
- failure-domain.beta.kubernetes.io/zone
- failure-domain.beta.kubernetes.io/region
- 与节点不同的是,Pod是属于某个命名空间的,所以条件Y指的是一个或者全部命名空间中的一个Label Selector。
- Pod亲和与互斥的条件设置(和节点亲和相同):
- requiredDuringSchedulingIgnoredDuringExecution(硬):必须满足指定的规则才可以调度Pod到Node上,相当于硬限制。
- preferredDuringSchedulingIgnoredDuringExecution(软):强调优先满足指定规则,调度器会尝试调度Pod到Node上,但并不强求,相当于软限制。多个优先级规则还可以设置权重(weight)值,以定义执行的先后顺序。
- 实现PodAffinity(Pod亲和与互斥调度)需要两步:
- (1)选定要亲和或互斥的pod的标签(该标签只能存在该pod中)。
- (2)在Pod的定义中加上podAffinity或podAntiAffinity的设置。
- 原则上,topologyKey可以使用任何合法的标签Key赋值,但是出于性能和安全方面的考虑,对topologyKey有如下限制:
- 在Pod亲和性和RequiredDuringScheduling的Pod互斥性的定义中,不允许使用空的topologyKey。
- 如果Admission controller包含了LimitPodHardAntiAffinityTopology,那么针对RequiredDuringScheduling的Pod互斥性定义就被限制为kubernetes.io/hostname,要使用自定义的topologyKey,就要改写或禁用该控制器。
- 在PreferredDuringScheduling类型的Pod互斥性定义中,空的topologyKey会被解释为kubernetes.io/hostname、failuredomain.beta.kubernetes.io/zone及failuredomain.beta.kubernetes.io/region的组合。
- 如果不是上述情况,就可以采用任意合法的topologyKey了。
- PodAffinity规则设置的注意事项如下:
- 除了设置Label Selector和topologyKey,用户还可以指定Namespace列表来进行限制,同样,使用Label Selector对Namespace进行选择。Namespace的定义和Label Selector及topologyKey同级。省略Namespace的设置,表示使用定义了affinity/anti-affinity的Pod所在的Namespace。如果Namespace被设置为空值(""),则表示所有Namespace。
- 在所有关联requiredDuringSchedulingIgnoredDuringExecution的matchExpressions全都满足之后,系统才能将Pod调度到某个Node上。
- 与节点亲和性类似,Pod亲和性的操作符也包括In、NotIn、Exists、DoesNotExist、Gt、Lt。
9.4.1、参照Pod
- 首先,创建一个名为flag-nginx-pod的Pod,带有标签security=S1和app=nginx。
- 后面的例子将使用该控制器生成的pod作为其他Pod亲和与互斥的目标Pod。
apiVersion: apps/v1
kind: Deployment
metadata:
name: flag-nginx-pod-deployment
namespace: default
spec:
selector:
matchLabels:
podname: flag-nginx-pod
replicas: 1
template:
metadata:
labels:
podname: flag-nginx-pod
security: S1
app: nginx
spec:
containers:
- name: test-nginx-container
image: nginx:latest
imagePullPolicy: Never
command: ["/usr/sbin/nginx", "-g", "daemon off;"]
ports:
- containerPort: 80
9.4.2、Pod的亲和性调度
- 创建第2个Pod,我们希望它与参照Pod运行在同一个Node上。这里使用的亲和标签是security=S1,对应参照Pod中的标签“security: S1”,topologyKey的值被设置为“kubernetes.io/hostname”。
apiVersion: apps/v1
kind: Deployment
metadata:
name: podaffinitynginx-pod-deployment1
namespace: default
spec:
selector:
matchLabels:
podname: podaffinitynginx-pod
replicas: 1
template:
metadata:
labels:
podname: podaffinitynginx-pod
spec:
containers:
- name: podaffinitynginx-nginx-container
image: nginx:latest
imagePullPolicy: Never
command: ["/usr/sbin/nginx", "-g", "daemon off;"]
ports:
- containerPort: 80
affinity:
podAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchExpressions:
- key: security
operator: In
values:
- S1
topologyKey: kubernetes.io/hostname
9.4.3、Pod的互斥性调度
- 创建第3个Pod,我们希望它不与参照Pod运行在同一个Node上。这里使用的互斥标签是security=S1,对应参照Pod中的标签“security: S1”,topologyKey的值被设置为“kubernetes.io/hostname”。
apiVersion: apps/v1
kind: Deployment
metadata:
name: podaffinitynginx-pod-deployment2
namespace: default
spec:
selector:
matchLabels:
podname: podaffinitynginx-pod
replicas: 1
template:
metadata:
labels:
podname: podaffinitynginx-pod
spec:
containers:
- name: podaffinitynginx-nginx-container
image: nginx:latest
imagePullPolicy: Never
command: ["/usr/sbin/nginx", "-g", "daemon off;"]
ports:
- containerPort: 80
affinity:
podAntiAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchExpressions:
- key: security
operator: In
values:
- S1
topologyKey: kubernetes.io/hostname
9.5、Taints和Tolerations(污点和容忍)
- NodeAffinity(节点亲和性)是在Pod上定义的一种属性,使得Pod能够被调度到某些Node上运行(优先选择或强制要求)。
- Taint正好与NodeAffinity相反,它让Node拒绝Pod的在其上运行。
- Taint需要和Toleration配合使用,让Pod避开那些不合适的Node。
- 在Node上设置一个或多个Taint之后,除非Pod明确声明能够容忍这些污点,否则pod无法在这些Node上运行。
- Toleration是Pod的属性,让Pod能够(注意,只是能够,而非必须)运行在标注了Taint的Node上。
- 实现pod要容忍Taints(污点)需要两步:
- (1)选定node,查看其上的Taints(污点)。
- (2)在Pod的定义中加tolerations,容忍node上的Taints。
9.5.1、Tolerations的定义语法
- Toleration声明中的指令(kubectl explain pods.spec.tolerations):
- key:key是污点的键(taint key)(需要与Taint的设置保持一致)。
- 空的key配合Exists操作符能够匹配所有的键和值。
- effect:表示要匹配的污点效果(需要与Taint的设置保持一致)。
- 当指定时,允许的值是NoSchedule、PreferNoSchedule和NoExecute。
- 空的effect匹配所有的effect。
- operator:如果不指定operator,则默认值为Equal。
- operator的值是Equal,并且value的值需要与Taint设置的值相等。
- operator的值是Exists(无须指定value)。
- value:Value是污点的值(taint value)。
- tolerationSeconds:表示容忍(必须是NoExecute才生效,否则将忽略此字段)污点的时间段。
- 默认情况下,即没有设置,这意味着永远容忍污点(不要驱逐)。
- 0和负值将被系统视为0(立即驱逐)
- key:key是污点的键(taint key)(需要与Taint的设置保持一致)。
- 效果是NoExecute的Taint(污点),对节点上正在运行的Pod有以下影响:
- 没有设置对应Toleration的Pod会被立刻驱逐。
- 配置了对应Toleration的Pod,如果没有为tolerationSeconds赋值,则会一直留在这一节点上。
- 配置了对应Toleration的Pod,且指定了tolerationSeconds值,则会在指定时间后驱逐。
//Equal方式如下 tolerations: - key: key1 operator: Equal value: value1 effect: Noexecute tolerationSeconds: 3600 //Exists方式如下 tolerations: - key: key1 operator: Exists effect: NoExecute tolerationSeconds: 3600
9.5.2、Taints和Tolerations的使用
示例1:一个Taints和Tolerations的使用
- (1)为k8s-node1加上了一个Taint。该Taint的键为disk,值为ssd,Taint的效果是NoSchedule。这意味着除非Pod明确声明可以容忍这个Taint,否则就不会被调度到k8s-node1上。
]# kubectl taint nodes k8s-node1 disk=ssd:NoSchedule
- (2)然后,需要在Pod上声明Toleration。下面的两个Toleration都被设置为可以容忍(Tolerate)具有该Taint的Node,使得Pod能够被调度到k8s-node1上:
tolerations: - key: disk operator: Equal value: ssd effect: NoSchedule //或者 tolerations: - key: disk operator: Exists effect: NoSchedule
示例2:多个Taints和Tolerations的使用
- 在同一个Node上可以设置多个Taint,也可以在Pod上设置多个Toleration。Kubernetes调度器处理多个Taint和Toleration的逻辑顺序为:
- 首先列出节点中所有的Taint,然后忽略Pod的Toleration能够匹配的部分,剩下的没有忽略的Taint就是对Pod的效果了。
- 下面是几种特殊情况。
- 如果在剩余的Taint中存在effect=NoSchedule,则调度器不会把该Pod调度到这一节点上。
- 如果在剩余的Taint中没有NoSchedule效果,但是有PreferNoSchedule效果,则调度器会尝试不把这个Pod指派给这个节点。
- 如果在剩余的Taint中有NoExecute效果,并且这个Pod已经在该节点上运行,则会被驱逐;如果没有在该节点上运行,则也不会再被调度到该节点上。
- (1)如果对一个节点进行这样的Taint设置:
]# kubectl taint nodes k8s-node2 keyl=valuel:NoSchedule ]# kubectl taint nodes k8s-node2 keyl=valuel:NoExecute ]# kubectl taint nodes k8s-node2 key2=value2:NoSchedule
- (2)然后在Pod上设置两个Toleration:
- 结果是该Pod无法被调度到k8s-node2上,这是因为第3个Taint没有匹配的Toleration。但是如果该Pod已经在k8s-node2上运行了,那么在运行时设置第3个Taint,它还能继续在k8s-node2上运行,这是因为Pod可以容忍前两个Taint。
tolerations: - key: keyl operator: Equal value: value1 effect NoSchedule - key: keyl operator: Equal value: value1 effect NoExecute
9.5.3、独占节点
- 如果想要拿出一部分节点专门给一些特定应用使用,则可以为节点添加这样的Taint:
kubectl taint nodes node_name dedicated=groupName:NoSchedule
- 然后给这些应用的Pod加入对应的Toleration。这样,带有合适Toleration的Pod就会被允许同使用其他节点一样使用有Taint的节点。
- 通过自定义Admission Controller也可以实现这一目标。如果希望让这些应用独占一批节点,并且确保它们只能使用这些节点,则还可以给这些Taint节点加入类似的标签dedicated=groupName,然后Admission Controller需要加入节点亲和性设置,要求Pod只会被调度到具有这一标签的节点上。
9.5.4、具有特殊硬件设备的节点
- 在集群里可能有一小部分节点安装了特殊的硬件设备(如GPU芯片),用户自然会希望把不需要占用这类硬件的Pod排除在外,以确保对这类硬件有需求的Pod能够被顺利调度到这些节点。
- 可以用下面的命令为节点设置Taint:
kubectl taint nodes node_name special=true:NoSchedule kubectl taint nodes node_name special=true:PreferNoSchedule
- 然后在Pod中利用对应的Toleration来保障特定的Pod能够使用特定的硬件。
- 和上面的独占节点的示例类似,使用Admission Controller来完成这一任务会更方便。例如,Admission Controller使用Pod的一些特征来判断这些Pod,如果可以使用这些硬件,就添加Toleration来完成这一工作。要保障需要使用特殊硬件的Pod只被调度到安装这些硬件的节点上,则还需要一些额外的工作,比如将这些特殊资源使用opaque-int-resource的方式对自定义资源进行量化,然后在PodSpec中进行请求;也可以使用标签的方式来标注这些安装有特别硬件的节点,然后在Pod中定义节点亲和性来实现这个目标。
9.6、DaemonSet:为每个Node都调度一个Pod
- DaemonSet是Kubernetes 1.2版本新增的一种资源对象,为集群中每个Node都运行一个Pod的副本实例。
- DaemonSet控制器可以用于一下场景:
- 在每个Node上都运行一个GlusterFS存储或者Ceph存储的Daemon进程。
- 在每个Node上都运行一个日志采集程序,例如Fluentd或者Logstach。
- 在每个Node上都运行一个性能监控程序,采集该Node的运行性能数据,例如Prometheus Node Exporter、collectd、New Relic agent或者Ganglia gmond等。
- DaemonSet的Pod调度策略与RC类似,除了使用系统内置的算法在每个Node上进行调度,也可以在Pod的定义中使用NodeSelector或NodeAffinity来指定满足条件的Node范围进行调度。
- 在Kubernetes 1.6以后,设置更新策略(updateStrategy)DaemonSet可以进行滚动升级:
- 当更新策略(updateStrategy)为RollingUpdate时,DaemonSet可以进行滚动升级。即在更新一个DaemonSet模板的时候,旧的Pod副本会被自动删除,同时新的Pod副本会被自动创建。
- 当更新策略(updateStrategy)为OnDelete时,即只有手工删除了DaemonSet创建的Pod副本,新的Pod副本才会被创建出来。
- 如果不设置updateStrategy的值,默认为RollingUpdate。
- 创建一个DaemonSet控制器,为每个Node上都启动一个busybox容器
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: daemonset-busybox-deployment
namespace: default
spec: #不用定义控制的pod数量
updateStrategy: #进行滚动升级
type: RollingUpdate
selector:
matchLabels:
app: busybox-pod
template:
metadata:
labels:
app: busybox-pod
spec:
volumes:
- name: html
hostPath:
path: /apps/html
containers:
- name: test-busybox-container
image: busybox:1.28
imagePullPolicy: IfNotPresent
command: ["/bin/sleep", "10000000000"]
volumeMounts:
- mountPath: /usr/share/
name: html
- 应用该daemonset的yaml文件
//创建该DaemonSet ]# kubectl apply -f daemonsetbusybox-deployment.yaml //查看DaemonSet ]# kubectl get daemonset NAME DESIRED CURRENT READY UP-TO-DATE AVAILABLE NODE SELECTOR AGE daemonsetbusybox-deployment 2 2 2 2 2 <none> 5m9s //查看Pod ]# kubectl get pods -A -o wide NAMESPACE NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES default daemonsetbusybox-deployment-44ttk 1/1 Running 0 5m12s 10.10.36.73 k8s-node1 <none> <none> default daemonsetbusybox-deployment-7jtbc 1/1 Running 0 5m12s 10.10.169.138 k8s-node2 <none> <none>
9.7、Job:批处理调度
- Kubernetes从1.2版本开始支持批处理类型的应用,我们可以通过Job控制器来定义并启动一个批处理任务。批处理任务通常并行(或者串行)启动多个计算进程去处理一批工作项(work item),处理完成后,整个批处理任务结束。
- 按照批处理任务实现方式的不同,批处理任务可以分为如图所示的几种模式:
- Job Template Expansion模式:一个Job对象对应一个待处理的Work item,有几个Work item就产生几个独立的Job。通常适用Work item数量少、每个Work item要处理的数据量比较大的场景,比如有一个100GB的文件作为一个Work item,总共有10个文件需要处理。
- Queue with Pod Per Work Item模式:采用一个任务队列存放Work item,一个Job对象作为消费者去完成这些Work item,在这种模式下,Job会启动N个Pod,每个Pod都对应一个Work item。
- Queue with Variable Pod Count模式:也是采用一个任务队列存放Work item,一个Job对象作为消费者去完成这些Work item,但与上面的模式不同,Job启动的Pod数量是可变的。
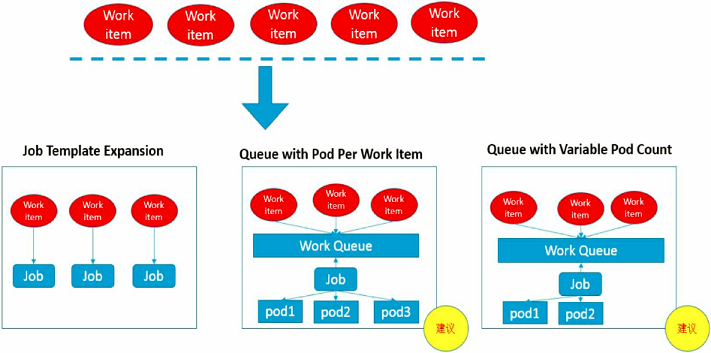
- 还有一种被称为Single Job with Static Work Assignment的模式,也是一个Job产生多个Pod,但它采用程序静态方式分配任务项,而不是采用队列模式进行动态分配。
- 这几种模式的一个对比:

- 按照并行运行批处理任务, Kubemetes将Job分以下三种类型。
- (1)Non-parallel Jobs
- 通常一个Job只启动一个Pod,则除非Pod异常,才会重启该Pod,一旦此Pod正常结束,Job将结束。
- (2)Parallel Jobs with a fixed completion count
- 并行Job会启动多个Pod,此时需要设定Job的.spec.completions参数为一个正数,当正常结束的Pod数量达至此参数设定的值后,Job结束。此外,Job的.spec.parallelism参数用来控制并行度,即同时启动几个Job 来处理Work Item 。
- (3)Parallel Jobs with a work queue
- 任务队列方式的并行Job需要一个独立的Queue, Work item都在一个Queue中存放,不能设置Job的.spec.completions参数,此时Job有以下特性。
- 每个Pod能独立判断和决定是否还有任务项需要处理。
- 如果某个Pod正常结束,则Job不会再启动新的Pod 。
- 如果一个Pod成功结束,则此时应该不存在其他Pod还在干活的情况,它们应该都处于即将结束、退出的状态。
- 如果所有Pod都结束了,且至少有一个Pod成功结束,则整个Job算是成功结束。
- 任务队列方式的并行Job需要一个独立的Queue, Work item都在一个Queue中存放,不能设置Job的.spec.completions参数,此时Job有以下特性。
9.7.1、Job Template Expansion模式
- 由于在这种模式下每个Work item对应一个Job实例,所以这种模式首先定义一个Job模板,模板里的主要参数是Work item的标识,因为每个Job都处理不同的Work item。
1、定义一个Job模板(文件名为job.yaml.txt),模板中的ITEM作为任务项的标识
cat > job.yaml.txt << EOF
apiVersion: batch/v1
kind: Job
metadata:
name: process-item-ITEM
labels:
jobgroup: jobexample
spec:
template:
metadata:
name: jobexample
labels:
jobgroup: jobexample
spec:
containers:
- name: c
image: busybox:1.28
imagePullPolicy: Never
command: ["sh", "-c", "echo 'Processing item ITEM' && sleep 5"]
restartPolicy: Never
EOF
2、生成3个对应的Job定义文件,并创建Job
//生成3个对应的Job定义文件 ]# mkdir ./jobs ]# for i in apple banana cherry;do cat job.yaml.txt | sed "s#ITEM#$i#" > ./jobs/job-$i.yaml;done //创建Job ]# kubectl apply -f jobs
3、查看Job的运行情况
]# kubectl get jobs -l jobgroup=jobexample NAME COMPLETIONS DURATION AGE process-item-apple 1/1 7s 8s process-item-banana 1/1 7s 8s process-item-cherry 1/1 7s 8s
9.7.2、Queue with Pod Per Work Item模式
- 在这种模式下需要一个任务队列存放Work item,比如RabbitMQ,客户端程序先把要处理的任务变成Work item放入任务队列,然后编写Worker程序、打包镜像并定义成为Job中的Work Pod。Worker程序的实现逻辑是从任务队列中拉取一个Work item并处理,在处理完成后即结束进程。
- 并行度为2的Demo示意图如图所示。
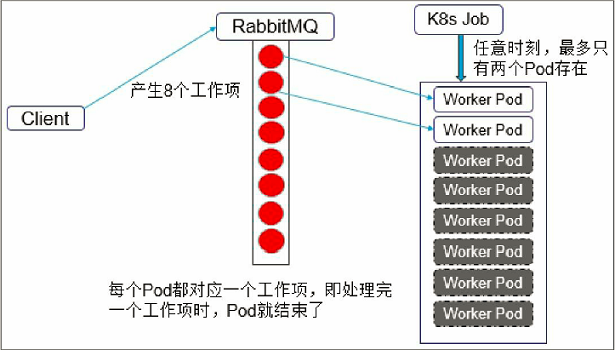
9.7.3、Queue with Variable Pod Count模式
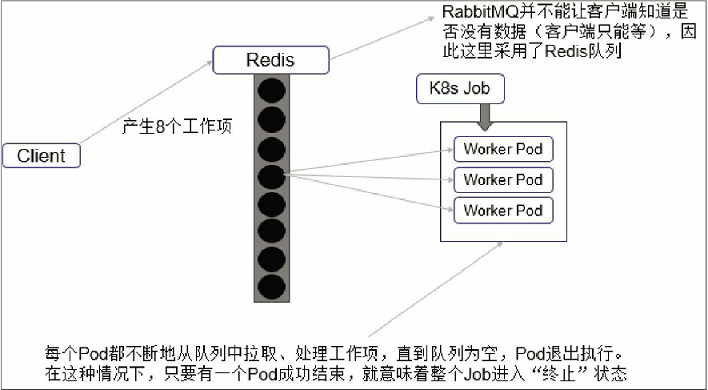
- 由于这种模式下,Worker程序需要知道队列中是否还有等待处理的Work item,如果有就取出来处理,否则就认为所有工作完成并结束进程,所以任务队列通常要采用Redis或者数据库来实现,如图所示。
9.8、Cronjob:定时任务
- Kubernetes从1.5版本开始增加了一种新类型的Job,即类似Linux Cron的定时任务Cron Job。
- 如何定义和使用Cronjob:
- 首先,确保Kubernetes的版本为1.8及以上。
- 其次,需要掌握Cron Job的定时表达式,它基本上照搬了Linux Cron的表达式。
Minutes Hours DayofMonth Month DayofWeek Year
- 其中每个域都可出现的字符如下。
- Minutes:可出现","、"-"、"*"、"/"这4个字符,有效范围为0~59的整数。
- Hours:可出现","、"-"、"*"、"/"这4个字符,有效范围为0~23的整数。
- DayofMonth:可出现","、"-"、"*"、"/"、"?"、"L"、"W"、"C"这8个字符,有效范围为0~31的整数。
- Month:可出现","、"-"、"*"、"/"这4个字符,有效范围为1~12的整数或JAN~DEC。
- DayofWeek:可出现","、"-"、"*"、"/"、"?"、"L"、"C"、"#"这8个字符,有效范围为1~7的整数或SUN~SAT。1表示星期天,2表示星期一,以此类推。
- 表达式中的特殊字符"*"与"/"的含义如下。
- *:表示匹配该域的任意值,假如在Minutes域使用"*",则表示每分钟都会触发事件。
- /:表示从起始时间开始触发,然后每隔固定时间触发一次,例如在Minutes域设置为5/20,则意味着第1次触发在第5min时,接下来每20min触发一次,将在第25min、第45min等时刻分别触发。
示例:
1、创建cronjob的yaml文件
- Job,任务每隔1min执行一次,运行的镜像是busybox,执行的命令是Shell脚本,脚本执行时会在控制台输出当前时间。
cat > cronjob.yaml << EOF
apiVersion: batch/v1beta1
kind: CronJob
metadata:
name: cronjob-date
labels:
cronjob: cronjob-date
spec:
schedule: "*/1 * * * *"
jobTemplate:
metadata:
name: cronjob-job
labels:
cronjobjob: cronjob-job
spec:
template:
metadata:
name: cronjob-pod
labels:
cronjobpod: cronjob-pod
spec:
containers:
- name: cj
image: busybox:1.28
imagePullPolicy: Never
command: ["sh", "-c", "date '+%x %T'"]
restartPolicy: OnFailure
EOF
2、创建cronjob
]# kubectl apply -f cronjob.yaml
3、然后每隔1min执行kubectl get cronjob cronjob-date查看任务状态,发现的确每分钟调度了一次
]# kubectl get cronjob cronjob-date NAME SCHEDULE SUSPEND ACTIVE LAST SCHEDULE AGE cronjob-date */1 * * * * False 1 10s 2m39s
4、查看pod和任意一个容器的日志
]# kubectl get pods NAME READY STATUS RESTARTS AGE cronjob-date-1648785660-rqg9v 0/1 Completed 0 2m43s cronjob-date-1648785720-4f6zw 0/1 Completed 0 103s cronjob-date-1648785780-gpnxm 0/1 Completed 0 43s ]# kubectl logs cronjob-date-1648785660-rqg9v 04/01/22 04:01:09
5、当不需要某个Cron Job时,可以通过下面的命令删除它
]# kubectl delete -f cronjob.yaml //或者 ]# kubectl delete cronjob cronjob-date
10、Init Container(初始化容器)
- 在很多应用场景中,应用在启动之前都需要进行如下初始化操作:
- 等待其他关联组件正确运行(例如数据库或某个后台服务)。
- 基于环境变量或配置模板生成配置文件。
- 从远程数据库获取本地所需配置,或者将自身注册到某个中央数据库中。
- 下载相关依赖包,或者对系统进行一些预配置操作。
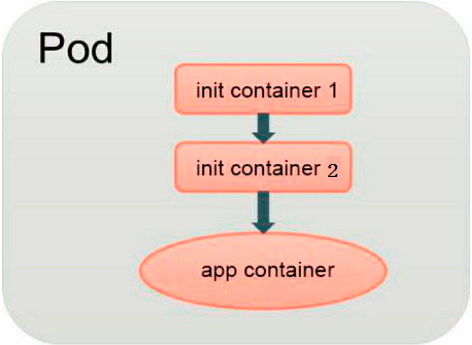
- Kubernetes 1.3引入了一个Alpha版本的新特性init container(初始化容器,在Kubernetes 1.5时被更新为Beta版本),用于在启动应用容器(app container)之前启动一个或多个初始化容器,完成应用容器所需的预置条件,如图所示:
- init container与应用容器在本质上是一样的,但它们是仅运行一次就结束的任务,并且必须在成功执行完成后,系统才能继续执行下一个容器。根据Pod的重启策略(RestartPolicy),当init container执行失败,且设置RestartPolicy=Never时,Pod将会启动失败;而设置RestartPolicy=Always时,Pod将会被系统自动重启。
- init container与应用容器的区别如下:
- (1)init container的运行方式与应用容器不同,它们必须先于应用容器执行完成,当设置了多个init container时,将按顺序逐个运行,并且只有前一个init container运行成功后才能运行后一个init container。当所有init container都成功运行后,Kubernetes才会初始化Pod的各种信息,并开始创建和运行应用容器。
- (2)在init container的定义中也可以设置资源限制、Volume的使用和安全策略,等等。但资源限制的设置与应用容器略有不同。
- 如果多个init container都定义了资源请求/资源限制,则取最大的值作为所有init container的资源请求值/资源限制值。
- Pod的有效(effective)资源请求值/资源限制值取以下二者中的较大值。
- 所有应用容器的资源请求值/资源限制值之和。
- init container的有效资源请求值/资源限制值。
- 调度算法将基于Pod的有效资源请求值/资源限制值进行计算,也就是说init container可以为初始化操作预留系统资源,即使后续应用容器无须使用这些资源。
- Pod的有效QoS等级适用于init container和应用容器。
- 资源配额和限制将根据Pod的有效资源请求值/资源限制值计算生效。
- Pod级别的cgroup将基于Pod的有效资源请求/限制,与调度机制一致。
- (3)init container不能设置readinessProbe探针,因为必须在它们成功运行后才能继续运行在Pod中定义的普通容器。
- 在Pod重新启动时,init container将会重新运行,常见的Pod重启场景如下:
- init container的镜像被更新时,init container将会重新运行,导致Pod重启。仅更新应用容器的镜像只会使得应用容器被重启。
- Pod的infrastructure容器更新时,Pod将会重启。
- 若Pod中的所有应用容器都终止了,并且RestartPolicy=Always,则Pod会重启。
示例:
1、创建deployment控制器的yaml文件
- 以Nginx应用为例,在启动Nginx之前,通过初始化容器busybox为Nginx创建一个index.html主页文件。这里为init container和Nginx设置了一个共享的Volume,以供Nginx访问init container设置的index.html文件:
apiVersion: apps/v1
kind: Deployment
metadata:
name: init-busybox-nginx-deployment
namespace: default
spec:
selector:
matchLabels:
app: init-busybox-nginx-pod
replicas: 2
template:
metadata:
labels:
app: init-busybox-nginx-pod
spec:
volumes:
- name: html
hostPath:
path: /apps/html
initContainers:
- name: init-busybox-container
image: busybox:1.28
imagePullPolicy: Never
command: ["/bin/wget", "-O", "/html/index.html", "http://www.baidu.com/"]
volumeMounts:
- mountPath: /html
name: html
containers:
- name: init-nginx-container
image: nginx:latest
imagePullPolicy: Never
command: ["/usr/sbin/nginx", "-g", "daemon off;"]
ports:
- containerPort: 80
volumeMounts:
- mountPath: /usr/share/nginx/html
name: html
2、创建pod
]# kubectl apply -f init-busybox-nginx-deployment.yaml
3、查看pod
//在运行init container的过程中查看Pod的状态,可见init过程还未完成 ]# kubectl get pods -A NAMESPACE NAME READY STATUS RESTARTS AGE default init-busybox-nginx-deployment-678584495c-6x4c6 0/1 Init:0/1 0 13s default init-busybox-nginx-deployment-678584495c-phcqm 0/1 Init:0/1 0 13s //在init container成功执行完成后,系统继续启动Nginx容器,再次查看Pod的状态 ]# kubectl get pod -A NAMESPACE NAME READY STATUS RESTARTS AGE default init-busybox-nginx-deployment-678584495c-6x4c6 1/1 Running 0 5m40s default init-busybox-nginx-deployment-678584495c-phcqm 1/1 Running 0 5m40s
4、登录进Nginx容器,可以看到/usr/share/nginx/html目录下init container生成的index.html文件
]# kubectl exec -it init-busybox-nginx-deployment-678584495c-6x4c6 -c init-nginx-container -- /bin/sh # ls /usr/share/nginx/html index.html
11、Pod的升级和回滚
- 如果Pod是通过Deployment创建的,可以实现pod的自动更新和回滚:
- 用户可以在运行时修改Deployment的Pod定义(spec.template)或镜像名称,并应用到Deployment对象上,Kubernetes就可以自动完成pod的自动更新操作。
- 如果在更新过程中发生了错误,则还可以通过回滚操作恢复Pod的版本。
- 在整个升级的过程中,Kubernetes会保证有一定数量的Pod是可用的,这是Deployment通过复杂的算法完成的。
- Deployment需要确保在整个更新过程中只有一定数量的Pod可能处于不可用状态。
- 在默认情况下,最多有1个pod不可用(maxUnavailable=1)。
- Deployment还需要确保在整个更新过程中Pod的总数量不会超过所需的副本数量太多。
- 在默认情况下,Pod的总数最多比Pod的期望副本数多1个(maxSurge=1)。
- Kubernetes从1.6版本开始,maxUnavailable和maxSurge的默认值将从1、1更新为期望副本数量的25%、25%。
- Deployment需要确保在整个更新过程中只有一定数量的Pod可能处于不可用状态。
- 这样,在升级过程中,Deployment就能够保证服务不中断,并且副本数量始终维持为用户指定的数量(DESIRED)。
11.1、Deployment的升级
示例:
1、创建deployment的yaml文件
apiVersion: apps/v1
kind: Deployment
metadata:
name: busybox-deployment
namespace: default
spec:
replicas: 2
selector:
matchLabels:
app: busybox-pod
strategy: #!
type: RollingUpdate
rollingUpdate: #先减一个pod,再加一个pod
maxSurge: 0
maxUnavailable: 1
template:
metadata:
labels:
app: busybox-pod
spec:
containers:
- name: busybox-container
image: busybox:1.28
imagePullPolicy: IfNotPresent
command: ["/bin/sh", "-c", "sleep 3600"]
2、创建并查看pod
- 注意,在创建Deployment时使用--record参数,就可以在部署历史记录的CHANGECAUSE列看到部署该版本时使用的命令。
]# kubectl apply -f busybox-deployment.yaml --record ]# kubectl get pods -o wide NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES busybox-deployment-5d65fbc75b-89tjm 1/1 Running 0 6s 10.10.36.79 k8s-node1 <none> <none> busybox-deployment-5d65fbc75b-c44pr 1/1 Running 0 6s 10.10.169.142 k8s-node2 <none> <none>
3、Deployment的升级
- 将Pod的镜像更新为busybox:latest。
]# kubectl set image deployment/busybox-deployment busybox-container=busybox:latest --record //或者 ]# kubectl edit deployment/busybox-deployment
4、使用kubectl rollout status命令查看Deployment的更新过程
]# kubectl rollout status deployment/busybox-deployment
5、查看pod(pod的名称变了),并获取其使用的image
]# kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
busybox-deployment-7649565bcd-gngqw 1/1 Running 0 93s 10.10.36.80 k8s-node1 <none> <none>
busybox-deployment-7649565bcd-vrtcr 1/1 Running 0 95s 10.10.169.143 k8s-node2 <none> <none>
]# kubectl describe pods busybox-deployment-7649565bcd-gngqw | grep 'Image:'
Image: busybox:latest
6、查看Deployment的更新的详细过程
]# kubectl describe deployment/busybox-deployment ...... Events: Type Reason Age From Message ---- ------ ---- ---- ------- Normal ScalingReplicaSet 2m52s deployment-controller Scaled up replica set busybox-deployment-5d65fbc75b to 2 Normal ScalingReplicaSet 2m35s deployment-controller Scaled down replica set busybox-deployment-5d65fbc75b to 1 Normal ScalingReplicaSet 2m35s deployment-controller Scaled up replica set busybox-deployment-7649565bcd to 1 Normal ScalingReplicaSet 2m33s deployment-controller Scaled down replica set busybox-deployment-5d65fbc75b to 0 Normal ScalingReplicaSet 2m33s deployment-controller Scaled up replica set busybox-deployment-7649565bcd to 2
- Deployment是如何完成Pod更新的?
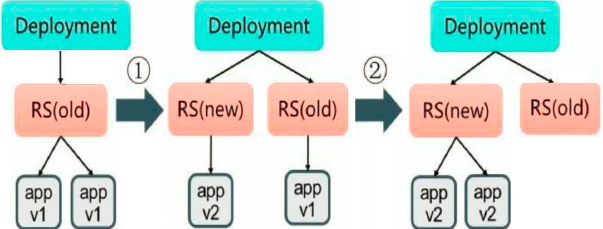
- 初始创建Deployment时,Kubernetes创建了一个ReplicaSet(busybox-deployment-5d65fbc75b),并按用户的需求创建了2个Pod副本。当更新Deployment时,系统创建了一个新的ReplicaSet(busybox-deployment-7649565bcd),并将其副本数量扩展到1,然后将旧的ReplicaSet缩减为1。之后,Kubernetes继续按照相同的更新策略对新旧两个ReplicaSet进行逐个调整。最后,新的ReplicaSet运行了2个新版本Pod副本,旧的ReplicaSet副本数量则缩减为0,过程如图所示。
7、查看两个ReplicaSet的最终状态
]# kubectl get rs NAME DESIRED CURRENT READY AGE busybox-deployment-5d65fbc75b 0 0 0 3m35s busybox-deployment-7649565bcd 2 2 2 3m18s
11.1.1、Deployment的两种更新策略
- Deployment的两种更新策略:Recreate(重建)和RollingUpdate(滚动更新),默认是RollingUpdate。
- Recreate:设置spec.strategy.type=Recreate,表示Deployment在更新Pod时,会先杀掉所有正在运行的Pod,然后创建新的Pod。
- RollingUpdate:设置spec.strategy.type=RollingUpdate,表示Deployment会以滚动更新的方式来逐个更新Pod。同时,可以通过设置spec.strategy.rollingUpdate下的两个参数(maxUnavailable和maxSurge)来控制滚动更新的过程。
]# kubectl explain Deployment.spec.strategy
- type:配置更新策略,其值可以是Recreate或RollingUpdate,默认是RollingUpdate。
- rollingUpdate:当type=RollingUpdate时,该配置才有效。
11.1.2、滚动更新(RollingUpdate)的两个参数
]# kubectl explain Deployment.spec.strategy.rollingUpdate
- maxSurge:用于指定在Deployment更新Pod的过程中Pod总数超过Pod期望副本数的最大数量。(从Kubernetes 1.6开始,maxSurge的默认值从1改为25%。)
- maxSurge的值可以是一个整整(例如5)或Pod期望副本数的百分比(例如10%)。如果是百分比,Kubernetes会先计算出一个数值,并向上取整。
- 如果MaxUnavailable为0,其值必须大于0。
- 例如,当maxSurge的值被设置为30%时,新的ReplicaSet可以在滚动更新开始时立即进行副本数扩容,只需要保证新旧ReplicaSet的Pod副本数之和不超过期望副本数的130%即可。一旦旧的Pod被杀掉,新的ReplicaSet就会进一步扩容。在整个过程中系统在任意时刻都能确保新旧ReplicaSet的Pod副本总数之和不超过所需副本数的130%。
- maxUnavailable:用于指定Deployment在更新过程中不可用状态的Pod数量的上限(从Kubernetes 1.6开始,maxUnavailable的默认值从1改为25%)。
- maxUnavailable的值可以是一个整整(例如5)或Pod期望副本数的百分比(例如10%)。如果是百分比,Kubernetes会先计算出一个数值,并向下取整。
- 如果maxSurge为0,其值必须大于0。
- 例如,当maxUnavailable被设置为30%时,旧的ReplicaSet可以在滚动更新开始时立即将副本数缩小到所需副本总数的70%。一旦新的Pod创建并准备好,旧的ReplicaSet会进一步缩容,新的ReplicaSet又继续扩容,整个过程中系统在任意时刻都可以确保可用状态的Pod总数至少占Pod期望副本总数的70%。
- 注意:
- 如果Deployment的上一次更新正在进行,此时用户再次发起Deployment的更新操作,那么Deployment会为每一次更新都创建一个ReplicaSet,而每次在新的ReplicaSet创建成功后,会逐个增加Pod副本数,同时将之前正在扩容的ReplicaSet停止扩容(更新),并将其加入旧版本ReplicaSet列表中,然后开始缩容至0的操作。
- 例如,假设我们创建一个Deployment,这个Deployment开始创建5个busybox:1.7.9的Pod副本,在这个创建Pod动作尚未完成时,我们又将Deployment进行更新,在副本数不变的情况下将Pod模板中的镜像修改为busybox:1.9.1,又假设此时Deployment已经创建了3个busybox:1.7.9的Pod副本,则Deployment会立即杀掉已创建的3个busybox:1.7.9 Pod,并开始创建busybox:1.9.1 Pod。Deployment不会在等待busybox:1.7.9的Pod创建到5个之后再进行更新操作。
11.1.3、更新Deployment的标签选择器(Label Selector)
- 通常来说,不鼓励更新Deployment的标签选择器,因为这样会导致Deployment选择的Pod列表发生变化,也可能与其他控制器产生冲突。如果一定要更新标签选择器,那么请务必谨慎,确保不会出现其他问题。
- 更新Deployment标签选择器的注意事项:
- (1)添加选择器标签时,必须同步修改Deployment配置的Pod的标签,为Pod添加新的标签,否则Deployment的更新会报验证错误而失败。
- 添加标签选择器是无法向后兼容的,这意味着新的标签选择器不会匹配和使用旧选择器创建的ReplicaSets和Pod,因此添加选择器将会导致所有旧版本的ReplicaSets和由旧ReplicaSets创建的Pod处于孤立状态(不会被系统自动删除,也不受新的ReplicaSet控制)。
- (2)更新标签选择器,即更改选择器中标签的键或者值,也会产生与添加选择器标签类似的效果。
- (3)删除标签选择器,即从Deployment的标签选择器中删除一个或者多个标签,该Deployment的ReplicaSet和Pod不会受到任何影响。但需要注意的是,被删除的标签仍会存在于现有的Pod和ReplicaSets上。
- (1)添加选择器标签时,必须同步修改Deployment配置的Pod的标签,为Pod添加新的标签,否则Deployment的更新会报验证错误而失败。
11.2、Deployment的回滚
- 在默认情况下,所有Deployment的发布历史记录都被保留在系统中(可以配置历史记录数量)。
示例:(接着11.1进行操作)
1、更新Deployment
- 在更新Deployment镜像时,将容器镜像名误设置成busybox:1.99(一个不存在的镜像)。
]# kubectl set image deployment/busybox-deployment busybox-container=busybox:1.99 --record
2、此时使用kubectl rollout status命令查看Deployment的更新过程会被卡住
]# kubectl rollout status deployment/busybox-deployment
3、查看rs和pod
//查看ReplicaSet,可以看到新建的ReplicaSet(busybox-deployment-6466786f44 ) ]# kubectl get rs NAME DESIRED CURRENT READY AGE busybox-deployment-5d65fbc75b 0 0 0 6m4s busybox-deployment-6466786f44 1 1 0 109s busybox-deployment-7649565bcd 1 1 1 5m47s //查看创建的Pod,会发现新的ReplicaSet创建的1个Pod被卡在镜像拉取过程中 ]# kubectl get pods NAME READY STATUS RESTARTS AGE busybox-deployment-6466786f44-878jx 0/1 ImagePullBackOff 0 117s busybox-deployment-7649565bcd-vrtcr 1/1 Running 0 5m55s
4、Deployment的回滚
- 查看Deployment的部署历史记录
- 在创建Deployment时使用--record参数,就可以在部署历史记录的CHANGECAUSE列看到部署该版本时使用的命令。
- Deployment的更新操作是在Deployment进行部署(Rollout)时被触发的,这意味着当且仅当Deployment的Pod模板(即spec.template)被更改时才会创建新的修订版本,例如更新模板标签或容器镜像。其他更新操作(如扩展副本数)将不会触发Deployment的更新操作,这也意味着我们将Deployment回滚到之前的版本时,只有Deployment的Pod模板部分会被修改。
]# kubectl rollout history deployment/busybox-deployment //查看某个历史记录的详细信息,加上--revision=<N>参数 ]# kubectl rollout history deployment/busybox-deployment --revision=2
- Deployment的回滚
//回滚到上一个部署版本 ]# kubectl rollout undo deployment/busybox-deployment //回滚到指定的部署版本,加上--to-revision参数 ]# kubectl rollout undo deployment/busybox-deployment --to-revision=2
5、查看pod,并获取其使用的image
]# kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
busybox-deployment-7649565bcd-r9xrg 1/1 Running 0 7s 10.10.36.81 k8s-node1 <none> <none>
busybox-deployment-7649565bcd-vrtcr 1/1 Running 0 7m36s 10.10.169.143 k8s-node2 <none> <none>
]# kubectl describe pods busybox-deployment-7649565bcd-r9xrg | grep 'Image:'
Image: busybox:latest
11.3、暂停和恢复Deployment的自动更新
- 对于一次复杂的Deployment配置修改,为了避免频繁触发Deployment的更新操作,可以先暂停Deployment的自动更新,然后进行配置修改,最后再恢复Deployment的自动更新,一次性触发完整的更新操作,这样就可以避免不必要的Deployment更新操作了。
示例:(接着11.2进行操作)
1、查看控制器
]# kubectl get deployments NAME READY UP-TO-DATE AVAILABLE AGE busybox-deployment 2/2 2 2 9m8 ]# kubectl get rs NAME DESIRED CURRENT READY AGE busybox-deployment-5d65fbc75b 0 0 0 9m18s busybox-deployment-6466786f44 0 0 0 5m3s busybox-deployment-7649565bcd 2 2 2 9m1s
2、暂停Deployment的自动更新
]# kubectl rollout pause deployment/busybox-deployment
3、修改Deployment的镜像信息
- 在暂停Deployment部署之后,可以根据需要进行任意次数的配置更新。
//修改Deployment的镜像信息 ]# kubectl set image deployment/busybox-deployment busybox-container=busybox:1.28 --record=true //更新容器的资源限制 ]# kubectl set resources deployment/busybox-deployment -c=busybox-container --limits=cpu=200m,memory=512Mi --record=true
4、查看Deployment的部署历史记录,上面两个变更操作并没有触发新的Deployment部署操作
]# kubectl rollout history deployment/busybox-deployment
5、恢复Deployment的自动更新
]# kubectl rollout resume deployment/busybox-deployment
11.4、RC的滚动升级(有问题?)
- 问题:没有kubectl rolling-update命令
- 对于RC的滚动升级,Kubernetes还提供了kubectl rolling-update命令进行实现。
- 该命令创建了一个新的RC,然后自动控制旧的RC中的Pod副本数量逐渐减少到0,同时新的RC中的Pod副本数量从0逐步增加到目标值,来完成Pod的升级。
- 需要注意的是,Kubernetes要求新的RC与旧的RC都在相同的命名空间内。
示例:
1、创建RC的yaml文件
apiVersion: v1
kind: ReplicationController
metadata:
name: busybox-rc
namespace: default
spec:
replicas: 2
selector:
app: busybox-pod
template:
metadata:
labels:
app: busybox-pod
spec:
containers:
- name: busybox-container
image: busybox:1.28
imagePullPolicy: IfNotPresent
command: ["/bin/sh", "-c", "sleep 3600"]
2、创建并查看pod
]# kubectl apply -f busybox-rc.yaml ]# kubectl get pods -o wide NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES busybox-rc-hg4fp 1/1 Running 0 26s 10.10.36.89 k8s-node1 <none> <none> busybox-rc-n8bz8 1/1 Running 0 26s 10.10.169.152 k8s-node2 <none> <none>
11.5、DaemonSet和StatefulSet的更新策略
- Kubernetes从1.6版本开始,对DaemonSet和StatefulSet的更新策略也引入类似于Deployment的滚动升级,通过不同的策略自动完成应用的版本升级。
11.5.1、DaemonSet的更新策略
- DaemonSet的两种更新策略:OnDelete和RollingUpdate。
- OnDelete:DaemonSet的默认更新策略,与1.5及以前版本的Kubernetes保持一致。当使用OnDelete作为更新策略时,在创建好新的DaemonSet配置之后,新的Pod并不会被自动创建,直到用户手动删除旧版本的Pod,才触发新建操作。
- RollingUpdate:从Kubernetes 1.6版本开始引入。当使用RollingUpdate作为更新策略对DaemonSet进行更新时,旧版本的Pod将被自动杀掉,然后自动创建新版本的DaemonSet Pod。整个过程与普通Deployment的滚动升级一样是可控的。不过有两点不同于普通Pod的滚动升级:一是目前Kubernetes还不支持查看和管理DaemonSet的更新历史记录;二是DaemonSet的回滚(Rollback)并不能如同Deployment一样直接通过kubectl rollback命令来实现,必须通过再次提交旧版本配置的方式实现。
11.5.2、StatefulSet的更新策略
- Kubernetes从1.6版本开始,针对StatefulSet的更新策略逐渐向Deployment和DaemonSet的更新策略看齐,也将实现RollingUpdate、Paritioned和OnDelete这几种策略,以保证StatefulSet中各Pod有序地、逐个地更新,并且能够保留更新历史,也能回滚到某个历史版本。
12、Pod的扩缩容
- 在实际生产系统中,我们经常会遇到某个服务需要扩容的场景,也可能会遇到由于资源紧张或者工作负载降低而需要减少服务实例数量的场景。此时可以利用Deployment/RC的Scale机制来完成这些工作。
- Kubernetes对Pod的扩缩容操作提供了手动和自动两种模式:
- 手动模式通过执行kubectl scale命令或通过RESTful API对一个Deployment/RC进行Pod副本数量的设置,即可一键完成。
- 自动模式则需要用户根据某个性能指标或者自定义业务指标,并指定Pod副本数量的范围,系统将自动在这个范围内根据性能指标的变化进行调整。
12.1、手动扩缩容机制
示例:
1、创建deployment的yaml文件
apiVersion: apps/v1
kind: Deployment
metadata:
name: scale-busybox-deployment
namespace: default
spec:
replicas: 1
selector:
matchLabels:
app: scale-busybox-pod
template:
metadata:
labels:
app: scale-busybox-pod
spec:
containers:
- name: scale-busybox-container
image: busybox:1.28
imagePullPolicy: IfNotPresent
command: ["/bin/sh", "-c", "sleep 3600"]
2、创建并查看pod
- 可以看到有一个pod副本。
]# kubectl apply -f scale-busybox-deployment.yaml ]# kubectl get pods -o wide NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES scale-busybox-deployment-99688954b-k9576 1/1 Running 0 5m21s 10.10.169.132 k8s-node2 <none> <none>
3、手动扩容
- 将pod副本的数量从一个扩容到两个。
]# kubectl scale deployment/scale-busybox-deployment --replicas 2 ]# kubectl get pods -o wide NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES scale-busybox-deployment-99688954b-8whws 1/1 Running 0 9s 10.10.36.68 k8s-node1 <none> <none> scale-busybox-deployment-99688954b-k9576 1/1 Running 0 8m24s 10.10.169.132 k8s-node2 <none> <none>
4、手动缩容
- 将--replicas的值设置为比当前Pod副本数小,Kubernetes将会“杀掉”一些运行中的Pod,以实现应用的缩容。
]# kubectl scale deployment/scale-busybox-deployment --replicas 1 ]# kubectl get pods -o wide NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES scale-busybox-deployment-99688954b-k9576 1/1 Running 0 12m 10.10.169.132 k8s-node2 <none> <none>
12.2、自动扩缩容机制
- Kubernetes从1.1版本开始,新增了一个名为Horizontal Pod Autoscaler(HPA)的控制器,用于实现基于CPU使用率进行自动Pod扩缩容的功能。HPA控制器基于Master的kube-controller-manager服务启动参数--horizontal-pod-autoscaler-sync-period定义的探测周期(默认值为15s),周期性地监测目标Pod的资源性能指标,并与HPA资源对象中的扩缩容条件进行对比,在满足条件时对Pod副本数量进行调整。
- Kubernetes在早期版本中,只能基于Pod的CPU使用率进行自动扩缩容操作,关于CPU使用率的数据来源于Heapster组件。
- Kubernetes从1.6版本开始,引入了基于应用自定义性能指标的HPA机制,并在1.9版本之后逐步成熟。
- Kubernetes从1.11版本开始,弃用基于Heapster组件完成Pod的CPU使用率采集的机制,全面转向基于Metrics Server完成数据采集。Metrics Server将采集到的Pod性能指标数据通过聚合API(Aggregated API)如metrics.k8s.io、custom.metrics.k8s.io和external.metrics.k8s.io提供给HPA控制器。
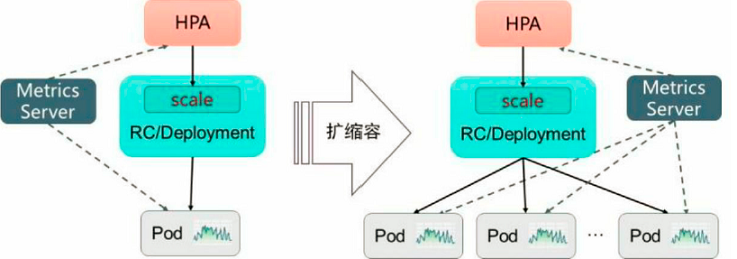
12.2.1、HPA的工作原理
- Kubernetes中的某个Metrics Server(Heapster或自定义Metrics Server)持续采集所有Pod副本的指标数据。
- (1)HPA控制器通过Metrics Server的API(Heapster的API或聚合API)获取这些数据,基于用户定义的扩缩容规则进行计算,得到目标Pod副本数量。
- (2)当目标Pod副本数量与当前副本数量不同时,HPA控制器就向Pod的副本控制器(Deployment、RC或ReplicaSet)发起scale操作,调整Pod的副本数量,完成扩缩容操作。
- HPA体系中的关键组件和工作流程
12.2.2、指标的类型
- Master的kube-controller-manager服务持续监测目标Pod的某种性能指标,以计算是否需要调整副本数量。
- 目前Kubernetes支持的指标类型如下:
- Pod资源使用率:Pod级别的性能指标,通常是一个比率值,例如CPU使用率。
- Pod自定义指标:Pod级别的性能指标,通常是一个数值,例如接收的请求数量。
- Object自定义指标或外部自定义指标:通常是一个数值,需要容器应用以某种方式提供,例如通过HTTP URL“/metrics”提供,或者使用外部服务提供的指标采集URL。
12.2.3、扩缩容算法详解
- HPA控制器从聚合API获取到Pod性能指标数据之后,基于下面的算法计算出目标Pod副本数量,与当前运行的Pod副本数量进行对比,决定是否需要进行扩缩容操作:
//当前副本数 ×(当前指标值/期望的指标值),并将结果向上取整 desiredReplicas = ceil[currentReplicas * (currentMetricvalue / desiredMetricValue)]
- 例如,如果用户设置的CPU期望指标值为100m,当前CPU实际使用的指标值为200m,则计算得到期望的Pod副本数量应为当前pod副本数量的两倍(200/100=2)。如果当前CPU实际使用的指标值为50m,则计算得到期望的Pod副本数量应为当前pod副本数量的一半(50/100=0.5)。
- 可以设置一个容忍度,当“当前指标值/期望的指标值”的结果与1非常接近时,可以让Kubernetes不做扩缩容操作。容忍度通过kube-controller-manager服务的启动参数--horizontalpod-autoscaler-tolerance进行设置,默认值为0.1(即10%),表示当“当前指标值/期望的指标值”结果在[0.9-1.1]范围之内,控制器就不会进行扩缩容操作。
- 也可以将期望指标值(desiredMetricValue)设置为指标的平均值类型,例如targetAverageValue或targetAverageUtilization,此时当前指标值(currentMetricValue)的算法为所有Pod副本当前指标值的总和除以Pod副本数量得到的平均值。
- 在计算“当前指标值/期望的指标值”(currentMetricValue / desiredMetricValue)时将不会包括这些异常Pod:
- 如果一个Pod正在被删除(设置了删除时间戳),这个pod就不会计入期望Pod副本数量。
- 如果一个Pod的当前指标值无法获得,本次探测就不会将这个Pod计入期望Pod副本数量,后续的探测会被重新纳入计算范围。
- 如果指标类型是CPU使用率,则对于正在启动但是还未达到Ready状态的Pod,也不会计入期望Pod副本数量。
- 可以通过kubecontroller-manager服务的启动参数--horizontal-pod-autoscaler-initialreadiness-delay设置首次探测Pod是否Ready的延时时间,默认值为30s。
- 另一个启动参数--horizontal-pod-autoscaler-cpuinitialization-period设置首次采集Pod的CPU使用率的延时时间。
- 当存在缺失指标的Pod时,系统将更保守地重新计算平均值。系统会假设这些Pod在需要缩容(Scale Down)时消耗了期望指标值的100%,在需要扩容(Scale Up)时消耗了期望指标值的0%,这样可以抑制潜在的扩缩容操作。
- 此外,如果存在未达到Ready状态的Pod,并且系统原本会在不考虑缺失指标或NotReady的Pod情况下进行扩展,则系统仍然会保守地假设这些Pod消耗期望指标值的0%,从而进一步抑制扩容操作。
- 如果在HorizontalPodAutoscaler中设置了多个指标,系统就会对每个指标都执行上面的算法,在全部结果中以期望副本数的最大值为最终结果。如果这些指标中的任意一个无法转换为期望的副本数(例如无法获取指标的值),系统就会跳过扩缩容操作。
- 最后,在HPA控制器执行扩缩容操作之前,系统会记录扩缩容建议信息(Scale Recommendation)。控制器会在操作时间窗口(时间范围可以配置)中考虑所有的建议信息,并从中选择得分最高的建议。这个值可通过kube-controller-manager服务的启动参数--horizontal-podautoscaler-downscale-stabilization-window进行配置,默认值为5min。这个配置可以让系统更为平滑地进行缩容操作,从而消除短时间内指标值快速波动产生的影响。
12.2.4、HorizontalPodAutoscaler配置详解
- Kubernetes将HorizontalPodAutoscaler资源对象提供给用户来定义扩缩容的规则。
- HorizontalPodAutoscaler资源对象处于Kubernetes的API组“autoscaling”中,目前包括v1和v2两个版本。
- autoscaling/v1仅支持基于CPU使用率的自动扩缩容,
- autoscaling/v2则用于支持基于任意指标的自动扩缩容配置,包括基于资源使用率、Pod指标、其他指标等类型的指标数据,当前版本为autoscaling/v2beta2。
1、autoscaling/v1版本的HorizontalPodAutoscaler的使用
- 为了使用autoscaling/v1版本的HorizontalPodAutoscaler,需要先安装Heapster组件或Metrics Server,用于采集Pod的CPU使用率。Heapster从Kubernetes 1.11版本开始进入弃用阶段,就不再对Heapster进行详细说明。
- autoscaling/v1仅支持基于CPU使用率的自动扩缩容。
apiVersion: autoscaling/vl
kind: HorizontalPodAutoscaler
metadata:
name: hpa-scale-busybox-deployment1
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: scale-busybox-deployment
minReplicas: 1
maxReplicas: 10
targetCPUUtilizationPercentage: 50
- scaleTargetRef:作用的目标对象,可以是Deployment、ReplicationController或ReplicaSet。
- minReplicas和maxReplicas:Pod副本数量的最小值和最大值,系统将在这个范围内进行自动扩缩容操作。
- targetCPUUtilizationPercentage:期望每个Pod的CPU使用率都为50%,该使用率基于Pod设置的CPU Request值进行计算,例如该值为200m,那么系统将维持Pod的实际CPU使用值为100m。
2、autoscaling/v2beta2的HorizontalPodAutoscaler的使用
- autoscaling/v2beta2可以用于支持基于任意指标的自动扩缩容配置,包括基于资源使用率、Pod指标、其他指标等类型的指标数据。
- 为了使用autoscaling/v2beta2版本的HorizontalPodAutoscaler,需要先安装Metrics Server,用于采集Pod的CPU使用率。
- kubectl explain HorizontalPodAutoscaler.spec --api-version=autoscaling/v2beta2
- scaleTargetRef:指定HorizontalPodAutoscaler要作用于的目标对象,可以是Deployment、ReplicationController或ReplicaSet。
- minReplicas和maxReplicas:Pod副本数量的最小值和最大值,系统将在这个范围内进行自动扩缩容操作。minReplicas的默认值是1。
- metrics:目标指标值。
- 通过参数type指定指标的类型;
- 通过参数target定义相应的指标目标值,系统将在指标数据达到目标值时(考虑容忍度的区间,见前面算法部分的说明)触发扩缩容操作。
- 如果没有设置,默认的指标将被设置为80%的平均CPU利用率。
- behavior:在向上和向下两个方向配置目标的伸缩行为(分别为scaleUp和scaleDown字段)。如果没有设置,默认使用hpascalinrules。
- kubectl explain HorizontalPodAutoscaler.spec.metrics --api-version=autoscaling/v2beta2(autoscaling/v2beta2的5种用法)
- resource:基于Kubernetes已知的资源指标(例如,在请求和限制中指定的),可以设置的资源为CPU和内存。
- pods:基于Pod的指标(例如,每秒处理的事务数),Kubernetes将对全部Pod副本的指标值进行平均值计算。
- object:基于kubernetes某种资源对象(如Ingress)的指标或应用系统的任意自定义指标(例如,Ingress对象上的每秒命中次数)。
- containerResource:
- external:
- type:其值是ContainerResource、External、Object、Pods或Resource中的一个。
- pods类型和object类型都属于自定义指标类型,指标的数据通常需要搭建自定义Metrics Server和监控工具进行采集和处理。指标数据可以通过API“custom.metrics.k8s.io”进行查询,要求预先启动自定义Metrics Server服务。
示例:
apiVersion: autoscaling/v2beta2
kind: HorizontalPodAutoscaler
metadata:
name: hpa-scale-busybox-deployment1
spec:
scaleTargetRef:
apiVersion: apps/vl
kind: Deployment
name: scale-busybox-deployment
minReplicas: 1
maxReplicas: 10
metrics:
- type: Resource #其值是ContainerResource、External、Object、Pods或Resource中的一个
resource:
name: cpu
target:
type: Utilization #其值可以是Utilization、Value、AverageValue中的一个
averageUtilization: 50
12.3、实现自动扩缩容(autoscaling/v2beta2)
1、安装metrics-server
- 将yaml文件下载到metrics-server目录中
- https://github.com/kubernetes/kubernetes/tree/master/cluster/addons/metrics-server
- 修改metrics-server-deployment.yaml文件
- 修改前的metrics-server-deployment.yaml文件
apiVersion: v1 kind: ServiceAccount metadata: name: metrics-server namespace: kube-system labels: kubernetes.io/cluster-service: "true" addonmanager.kubernetes.io/mode: Reconcile --- apiVersion: v1 kind: ConfigMap metadata: name: metrics-server-config namespace: kube-system labels: kubernetes.io/cluster-service: "true" addonmanager.kubernetes.io/mode: EnsureExists data: NannyConfiguration: |- apiVersion: nannyconfig/v1alpha1 kind: NannyConfiguration --- apiVersion: apps/v1 kind: Deployment metadata: name: metrics-server-v0.5.2 namespace: kube-system labels: k8s-app: metrics-server addonmanager.kubernetes.io/mode: Reconcile version: v0.5.2 spec: selector: matchLabels: k8s-app: metrics-server version: v0.5.2 template: metadata: name: metrics-server labels: k8s-app: metrics-server version: v0.5.2 spec: securityContext: seccompProfile: type: RuntimeDefault priorityClassName: system-cluster-critical serviceAccountName: metrics-server nodeSelector: kubernetes.io/os: linux containers: - name: metrics-server image: k8s.gcr.io/metrics-server/metrics-server:v0.5.2 command: - /metrics-server - --metric-resolution=30s - --kubelet-use-node-status-port - --kubelet-insecure-tls - --kubelet-preferred-address-types=InternalIP,Hostname,InternalDNS,ExternalDNS,ExternalIP - --cert-dir=/tmp - --secure-port=10250 ports: - containerPort: 10250 name: https protocol: TCP readinessProbe: httpGet: path: /readyz port: https scheme: HTTPS periodSeconds: 10 failureThreshold: 3 livenessProbe: httpGet: path: /livez port: https scheme: HTTPS periodSeconds: 10 failureThreshold: 3 volumeMounts: - mountPath: /tmp name: tmp-dir - name: metrics-server-nanny image: k8s.gcr.io/autoscaling/addon-resizer:1.8.14 resources: limits: cpu: 100m memory: 300Mi requests: cpu: 5m memory: 50Mi env: - name: MY_POD_NAME valueFrom: fieldRef: fieldPath: metadata.name - name: MY_POD_NAMESPACE valueFrom: fieldRef: fieldPath: metadata.namespace volumeMounts: - name: metrics-server-config-volume mountPath: /etc/config command: - /pod_nanny - --config-dir=/etc/config - --cpu={{ base_metrics_server_cpu }} - --extra-cpu=0.5m - --memory={{ base_metrics_server_memory }} - --extra-memory={{ metrics_server_memory_per_node }}Mi - --threshold=5 - --deployment=metrics-server-v0.5.2 - --container=metrics-server - --poll-period=30000 - --estimator=exponential # Specifies the smallest cluster (defined in number of nodes) # resources will be scaled to. - --minClusterSize={{ metrics_server_min_cluster_size }} # Use kube-apiserver metrics to avoid periodically listing nodes. - --use-metrics=true volumes: - name: metrics-server-config-volume configMap: name: metrics-server-config - emptyDir: {} name: tmp-dir tolerations: - key: "CriticalAddonsOnly" operator: "Exists"
-
- 修改后的metrics-server-deployment.yaml文件
apiVersion: v1 kind: ServiceAccount metadata: name: metrics-server namespace: kube-system labels: kubernetes.io/cluster-service: "true" addonmanager.kubernetes.io/mode: Reconcile --- apiVersion: v1 kind: ConfigMap metadata: name: metrics-server-config namespace: kube-system labels: kubernetes.io/cluster-service: "true" addonmanager.kubernetes.io/mode: EnsureExists data: NannyConfiguration: |- apiVersion: nannyconfig/v1alpha1 kind: NannyConfiguration --- apiVersion: apps/v1 kind: Deployment metadata: name: metrics-server-v0.5.2 namespace: kube-system labels: k8s-app: metrics-server addonmanager.kubernetes.io/mode: Reconcile version: v0.5.2 spec: selector: matchLabels: k8s-app: metrics-server version: v0.5.2 template: metadata: name: metrics-server labels: k8s-app: metrics-server version: v0.5.2 spec: securityContext: seccompProfile: type: RuntimeDefault priorityClassName: system-cluster-critical serviceAccountName: metrics-server nodeSelector: kubernetes.io/os: linux containers: - name: metrics-server image: registry.cn-hangzhou.aliyuncs.com/google_containers/metrics-server:v0.5.2 imagePullPolicy: Never command: - /metrics-server - --metric-resolution=30s - --kubelet-use-node-status-port - --kubelet-insecure-tls - --kubelet-preferred-address-types=InternalIP,Hostname,InternalDNS,ExternalDNS,ExternalIP - --cert-dir=/tmp - --secure-port=10250 ports: - containerPort: 10250 name: https protocol: TCP readinessProbe: httpGet: path: /readyz port: 10250 scheme: HTTPS periodSeconds: 10 failureThreshold: 3 initialDelaySeconds: 30 timeoutSeconds: 5 livenessProbe: httpGet: path: /livez port: 10250 scheme: HTTPS periodSeconds: 10 failureThreshold: 3 initialDelaySeconds: 30 timeoutSeconds: 5 volumeMounts: - mountPath: /tmp name: tmp-dir - name: metrics-server-nanny image: registry.cn-hangzhou.aliyuncs.com/google_containers/addon-resizer:1.8.11 imagePullPolicy: Never resources: limits: cpu: 100m memory: 300Mi requests: cpu: 5m memory: 50Mi env: - name: MY_POD_NAME valueFrom: fieldRef: fieldPath: metadata.name - name: MY_POD_NAMESPACE valueFrom: fieldRef: fieldPath: metadata.namespace volumeMounts: - name: metrics-server-config-volume mountPath: /etc/config command: - /pod_nanny - --config-dir=/etc/config - --cpu=80m - --extra-cpu=0.5m - --memory=80Mi - --extra-memory=10Mi - --threshold=5 - --deployment=metrics-server-v0.5.2 - --container=metrics-server - --poll-period=30000 - --estimator=exponential # Specifies the smallest cluster (defined in number of nodes) # resources will be scaled to. #- --minClusterSize={{ metrics_server_min_cluster_size }} # Use kube-apiserver metrics to avoid periodically listing nodes. - --use-metrics=true volumes: - name: metrics-server-config-volume configMap: name: metrics-server-config - emptyDir: {} name: tmp-dir tolerations: - key: "CriticalAddonsOnly" operator: "Exists"
- 部署metrics-server
]# kubectl apply -f ./metrics-server/
- 查看pod和service
]# kubectl get pods -A -o wide NAMESPACE NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES kube-system metrics-server-v0.5.2-69fd75fb88-vrtcr 2/2 Running 0 63s 10.10.169.141 k8s-node2 <none> <none> ]# kubectl get svc -A -o wide NAMESPACE NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE SELECTOR kube-system metrics-server ClusterIP 10.20.81.50 <none> 443/TCP 28m k8s-app=metrics-server
- 测试部署metrics-server是否成功
//使用kubectl top测试 ]# kubectl top node NAME CPU(cores) CPU% MEMORY(bytes) MEMORY% k8s-master1 275m 13% 1125Mi 65% k8s-node1 142m 7% 831Mi 48% k8s-node2 160m 8% 895Mi 52% ]# kubectl top pods //使用kubectl get测试 ]# kubectl get --raw "/apis/metrics.k8s.io/v1beta1/nodes" ]# kubectl get --raw "/apis/metrics.k8s.io/v1beta1/pods" //使用curl测试 ]# kubectl proxy --port=8001 ]# curl http://localhost:8001/apis/metrics.k8s.io/v1beta1/pods ]# curl http://localhost:8001/apis/metrics.k8s.io/v1beta1/nodes
2、创建hpa的pod和service
- 创建deployment的yaml文件
apiVersion: v1
kind: Service
metadata:
name: svc-hpa
namespace: default
labels:
app: hpa-nginx-pod
spec:
type: NodePort
ports:
- port: 8888
nodePort: 8880
targetPort: 80
protocol: TCP
name: http
selector:
app: hpa-nginx-pod
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: hpa-nginx-deployment
namespace: default
spec:
selector:
matchLabels:
app: hpa-nginx-pod
replicas: 1
template:
metadata:
labels:
app: hpa-nginx-pod
spec:
volumes:
- name: html
hostPath:
path: /apps/html
containers:
- name: hpa-nginx-container
image: nginx:latest
imagePullPolicy: Never
command: ["/usr/sbin/nginx", "-g", "daemon off;"]
ports:
- containerPort: 80
volumeMounts:
- mountPath: /usr/share/nginx/html
name: html
resources:
requests:
memory: "32Mi"
cpu: "100m"
limits:
memory: "64Mi"
cpu: "200m"
- 在node上创建/apps/html/index.html
]# mkidr -p /apps/html/ ]# echo 'autoscaling/v2beta2' > /apps/html/index.html
- 创建pod和service
]# kubectl apply -f hpa-nginx-deployment.yaml
- 查看pod和service
]# kubectl get pods -o wide NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES hpa-nginx-deployment-856757b6bf-cmvb7 1/1 Running 0 11s 10.10.36.81 k8s-node1 <none> <none> ]# kubectl get svc -o wide NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE SELECTOR svc-hpa NodePort 10.20.230.249 <none> 8888:8880/TCP 19s app=hpa-nginx-pod
- 测试pod和service是否正常
//访问NodeIP:NodePort ]# curl http://10.1.1.11:8880/index.html
12.3.1、基于资源指标(resource类型)
- Resource类型的指标可以设置CPU和内存。
- 对于CPU使用率,在target参数中设置averageUtilization定义目标平均CPU使用率。
- 对于内存资源,在target参数中设置AverageValue定义目标平均内存使用值。
- 指标数据可以通过API “metrics.k8s.io”进行查询,要求预先启动Metrics Server服务。
- kubectl explain HorizontalPodAutoscaler.spec.metrics.resource --api-version=autoscaling/v2beta2
- name:是所涉及资源的名称。
- target:指定给定指标的目标值。
- type:表示度量类型,其值可能是Utilization、Value或AverageValue。
- averageUtilization:表示所有相关pod的平均资源指标的目标值,表示为pod的资源请求值的百分比。目前仅对资源度量源类型有效。
- averageValue:表示所有相关pod中度量的平均值的目标值(作为一个数量)。
- value:是度量的目标值(作为一个量)。
示例:
1、创建HorizontalPodAutoscaler的yaml文件
apiVersion: autoscaling/v2beta2
kind: HorizontalPodAutoscaler
metadata:
name: hpa-nginx
spec:
scaleTargetRef:
apiVersion: apps/vl
kind: Deployment
name: hpa-nginx-deployment
minReplicas: 1
maxReplicas: 10
metrics:
- type: Resource
resource:
name: cpu
target:
type: Utilization #其值可以是Utilization、Value、AverageValue中的一个
averageUtilization: 50
2、创建并查看HorizontalPodAutoscaler
]# kubectl apply -f hpa-nginx.yaml ]# kubectl get hpa NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE hpa-nginx Deployment/hpa-nginx-deployment 0%/50% 1 10 1 6s ]# kubectl describe hpa/hpa-nginx
3、测试HorizontalPodAutoscaler
//在一个窗口请求hpa-nginx-deployment的pod
]# for i in {1..100000}; do wget -q -O- http://10.1.1.11:8880/index.html > /dev/null; done
//在另个窗口查看pod的数量及其cpu、内存的使用情况
]# watch -n0.1 'kubectl top pod | grep hpa-nginx-deployment'
12.3.2、基于Pods指标数据(pods类型)
- Pods的指标数据来源于Pod对象本身,其target指标类型只能使用AverageValue。
- kubectl explain HorizontalPodAutoscaler.spec.metrics.pods --api-version=autoscaling/v2beta2
- metric:通过name和selector标识目标度量
- name:是给定度量的名称。
- selector:选择给定的度量。当未设置时,只使用metricName来收集指标。
- target:指定给定指标的目标值。
- type:表示度量类型,其值只能是AverageValue。
- averageValue:表示所有相关pod中度量的平均值的目标值(作为一个数量)。
- metric:通过name和selector标识目标度量
示例:
- 设置Pod的指标名为packets-per-second,在目标指标平均值为1000时触发扩缩容操作。
metrics:
- type: Pods
pods:
metric:
name: packets-per-second
target:
type: AverageValue #只能使用AverageValue
averageValue: 1k
12.3.3、基于object类型
- Object的指标数据来源于其他资源对象或任意自定义指标,其target指标类型可以使用Value或AverageValue(根据Pod副本数计算平均值)进行设置。
- Kubernetes推荐尽量使用type为Object的HPA配置方式,这可以通过使用Operator模式,将外部指标通过CRD(自定义资源)定义为API资源对象来实现。
- kubectl explain HorizontalPodAutoscaler.spec.metrics.object --api-version=autoscaling/v2beta2
- describedObject:
- apiVersion:引用的API版本。
- kind:是指涉物。
- name:引用对象的名称。
- metric:通过name和selector标识目标度量
- name:是给定度量的名称。
- selector:选择给定的度量。当未设置时,只使用metricName来收集指标。
- target:指定给定指标的目标值
- type:表示度量类型,其值可能是Value或AverageValue。
- averageValue:表示所有相关pod中度量的平均值的目标值(作为一个数量)。
- value:是度量的目标值(作为一个量)。
- describedObject:
示例1:
- 设置指标的名称为requests-per-second,其值来源于Ingress “main-route”,将目标值(value)设置为2000,即在Ingress的每秒请求数量达到2000个时触发扩缩容操作。
metrics:
- type: Object
object:
metric:
name: requests-per-second
describedObject:
apiversion: extensions/v1beta1
kind: Ingress
name: main-route
target:
type: Value #可以使用Value或AverageValue
Value: 2k
示例2:
- 设置指标的名称为http_requests,并且该资源对象具有标签“verb=GET”,在指标平均值达到500时触发扩缩容操作。
metrics:
- type: Object
object:
metric:
name: http_requests
selector: 'verb=GET'
target:
type: AverageValue #可以使用Value或AverageValue
averageValue: 500
12.3.4、基于外部服务的指标(external类型)
- 从1.10版本开始,Kubernetes引入了对外部系统指标的支持。例如,用户使用了公有云服务商提供的消息服务或外部负载均衡器,希望基于这些外部服务的性能指标(如消息服务的队列长度、负载均衡器的QPS)对自己部署在Kubernetes中的服务进行自动扩缩容操作。这时,就可以在metrics参数部分设置type为External来设置自定义指标,然后就可以通过API“external.metrics.k8s.io”查询指标数据了。当然,这同样要求自定义Metrics Server服务已正常工作。
- 在使用外部服务的指标时,要安装、部署能够对接到Kubernetes HPA模型的监控系统,并且完全了解监控系统采集这些指标的机制,后续的自动扩缩容操作才能完成。
- kubectl explain HorizontalPodAutoscaler.spec.metrics.external --api-version=autoscaling/v2beta2
- metric:通过name和selector标识目标度量
- name:是给定度量的名称。
- selector:选择给定的度量。当未设置时,只使用metricName来收集指标。
- target:指定给定指标的目标值
- type:表示度量类型,其值可能是Value或AverageValue。
- averageValue:表示所有相关pod中度量的平均值的目标值(作为一个数量)。
- metric:通过name和selector标识目标度量
示例:
metrics:
- type: External
external:
metric:
name: queue_messages_ready
selector: "queue=worker_tasks"
target:
type: AverageValue
averageValue: 30
12.3.5、基于容器资源指标(containerResource类型)
- HPA可以跨一组Pod跟踪单个容器的资源使用情况,以扩展目标资源。这可以为特定Pod中最重要的容器配置扩展阈值。例如,如果有一个Web应用程序和一个日志记录Sidecar,可以根据Web应用程序的资源使用情况进行扩展,而忽略Sidecar容器及其资源使用情况。
- kubectl explain HorizontalPodAutoscaler.spec.metrics.containerResource --api-version=autoscaling/v2beta2
- container:是伸缩目标中容器的名称。
- name:是所涉及资源的名称。
- target:指定给定指标的目标值。
metrics:
- type: ContainerResource
containerResource:
name: cpu
container: application
target:
type: Utilization
averageUtilization: 60
12.3.6、多个类型的指标
- 可以在同一个HorizontalPodAutoscaler资源对象中定义多个类型的指标,系统将针对每种类型的指标都计算Pod副本的目标数量,以最大值为准进行扩缩容操作。
示例:
metrics:
- type: Resource
resource:
name: cpu
target:
type: Utilization
averageUtilization: 50
- type: Pods
pods:
metric:
name: packets-per-second
target:
type: AverageValue
averageValue: 1k
- type: Object
object:
metric:
name: requests-per-second
describedObject:
apiversion: extensions/v1beta1
kind: Ingress
name: main-route
target:
type: Value
Value: 2k
13、StatefulSet:调度有状态的pod
- 在创建StatefulSet之前,需要确保在Kubernetes集群中管理员已经创建好共享存储。建议使用StorageClass,以实现动态创建PV。
- 共享存储查看:https://www.cnblogs.com/maiblogs/p/16392831.html,这里使用“6.2、动态存储卷”。
1、创建service的yaml文件
apiVersion: v1
kind: Service
metadata:
name: busybox-headless-service
namespace: default
labels:
app: busybox-headless-service
spec:
spec:
selector:
app: busybox-pod
ports:
- port: 8080
targetPort: 80
protocol: TCP
2、创建statefulset的yaml文件
- 注意,StorageClass的名字是nfs-client。
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: busybox-statefulset
namespace: default
spec:
serviceName: busybox-headless-service #(必须的)serviceName是管理此StatefulSet的服务的名称。此服务必须在StatefulSet之前存在,并负责该集合的网络标识。Pods获得遵循以下模式的DNS/主机名:pod-specific-string. servicename .default.svc.cluster.local,其中“pod-specific-string”由StatefulSet控制器管理。
podManagementPolicy: Parallel #创建pod的方式,可用值有:OrderedReady(递增创建,即一个一个的创建)、Parallel(并行创建)
replicas: 1 #pod的数量
revisionHistoryLimit: 10 #记录滚动更新的最大历史次数
selector: #(必须的)标签选择器
matchLabels:
app: busybox-pod
template: #(必须的)pod模板
metadata:
labels:
app: busybox-pod
spec:
containers:
- name: busybox-container
image: busybox:1.28
imagePullPolicy: IfNotPresent
command: ["/bin/sh", "-c", "while true; do echo $(date) >> /log/time.log; sleep 3; done"]
volumeMounts:
- mountPath: /log/
name: busybox-log-pvc
updateStrategy: #updateStrategy表示当对Template进行修订时,将用于更新StatefulSet中的Pods的statfulsetupdatestrategy。
rollingUpdate:
partition: 0
type: RollingUpdate
volumeClaimTemplates: #存储卷,优先于模板(template)中具有相同名称的任何卷。
- apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: busybox-log-pvc
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 8Gi
storageClassName: nfs-client
volumeMode: Filesystem
3、查看
//查看service ]# kubectl get svc NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE busybox-headless-service ClusterIP 10.20.207.210 <none> 8080/TCP 38s //查看pod ]# kubectl get pods NAME READY STATUS RESTARTS AGE busybox-statefulset-0 1/1 Running 0 42s test-busybox-deployment-5dd4f8dc7f-jc9vf 1/1 Running 0 10h test-busybox-deployment-5dd4f8dc7f-w4c8d 1/1 Running 0 10h //查看pvc ]# kubectl get pvc NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE busybox-log-pvc-busybox-statefulset-0 Bound pvc-b4e071d0-c2f7-43aa-b7ae-b7fa051f731f 8Gi RWO nfs-client 52s //查看pv ]# kubectl get pv NAME CAPACITY ACCESS MODES RECLAIM POLICY STATUS CLAIM STORAGECLASS REASON AGE pvc-b4e071d0-c2f7-43aa-b7ae-b7fa051f731f 8Gi RWO Delete Bound default/busybox-log-pvc-busybox-statefulset-0 nfs-client 56s //查看存储 ]# tail -f /data1/default-busybox-log-pvc-busybox-statefulset-0-pvc-b4e071d0-c2f7-43aa-b7ae-b7fa051f731f/time.log Mon Oct 10 21:28:18 UTC 2022 Mon Oct 10 21:28:21 UTC 2022 Mon Oct 10 21:28:24 UTC 2022 ...

 浙公网安备 33010602011771号
浙公网安备 33010602011771号