kafka05-主题与分区
- 主题作为消息的归类,可以再细分为一个或多个分区,分区也可以看作对消息的二次归类。分区的划分不仅为Kafka提供了可伸缩性、水平扩展的功能,还通过多副本机制来为Kafka提供数据冗余以提高数据可靠性。
- 从Kafka的底层实现来说,主题和分区都是逻辑上的概念:
- 分区可以有一至多个副本。
- 每个副本对应一个日志文件。
- 每个日志文件对应一至多个日志分段(LogSegment)。
- 每个日志分段还可以细分为索引文件、日志存储文件和快照文件等。
1、主题的管理(kafka-topics.sh)
- 主题的管理包括创建主题、查看主题信息、修改主题和删除主题等操作。可以通过Kafka提供的kafka-topics.sh脚本来执行这些操作,这个脚本位于$KAFKA_HOME/bin/目录下,其核心代码仅有一行,具体如下:
exec $(dirname $0)/kafka-run-class.sh kafka.admin.TopicCommand "$@" #实质上就是调用kafka.admin.TopicCommand类执行主题管理的操作
- 主题的管理并非只有使用kafka-topics.sh脚本这一种方式。
- 还可以通过KafkaAdminClient的方式实现(这种方式实质上是通过发送CreateTopicsRequestDelete、TopicsRequest等请求来实现的。
- 还可以通过直接操纵日志文件和ZooKeeper节点来实现。
1、创建主题
- 推荐使用kafka-topics.sh脚本来创建主题。
1、生产者和消费者创建主题
- 如果broker端配置参数auto.create.topics.enable设置为true(默认值就是true)。
- 当生产者向一个尚未创建的主题发送消息时,会自动创建一个分区数为num.partitions(默认值为1)、副本因子为default.replication.factor(默认值为1)的主题。
- 当一个消费者开始从未知主题中读取消息时,或者当任意一个客户端向未知主题发送元数据请求时,都会按照配置参数num.partitions和default.replication.factor的值来创建一个相应的主题。
- 很多时候,这种自动创建主题的行为都是非预期的。除非有特殊应用需求,否则不建议将auto.create.topics.enable参数设置为true,这会增加主题的管理与维护的难度。
2、使用kafka-topics.sh脚本创建主题
- 使用kafka-topics.sh脚本创建主题的两种方式:
- 使用--partitions和--replication-factor参数
- 使用--replica-assignment参数
1、创建主题的常用方式
示例1:创建主题
- 创建一个分区数为4、副本因子为2的主题topic-create。
- 可以看到128节点中创建了2个文件夹topic-create-0和topic-create-2,对应主题topic-create的2个分区编号为0和2的分区。128上只有2个分区,而我们创建的是4个分区,另外两个分区被分配到了130和131节点上。
128 ~]# kafka-topics.sh --zookeeper localhost:2181 --create --topic topic-create --partitions 4 --replication-factor 2 128 ~]# ll /tmp/kafka/log/ drwxr-xr-x. 2 root root 167 11月 11 15:29 topic-create-0 drwxr-xr-x. 2 root root 167 11月 11 15:29 topic-create-2 130 ~]# ll /tmp/kafka/log/ drwxr-xr-x. 2 root root 167 11月 11 15:29 topic-create-0 drwxr-xr-x. 2 root root 167 11月 11 15:29 topic-create-1 drwxr-xr-x. 2 root root 167 11月 11 15:29 topic-create-3 131 ~]# ll /tmp/kafka/log/ drwxr-xr-x. 2 root root 167 11月 11 15:29 topic-create-1 drwxr-xr-x. 2 root root 167 11月 11 15:34 topic-create-2 drwxr-xr-x. 2 root root 167 11月 11 15:29 topic-create-3
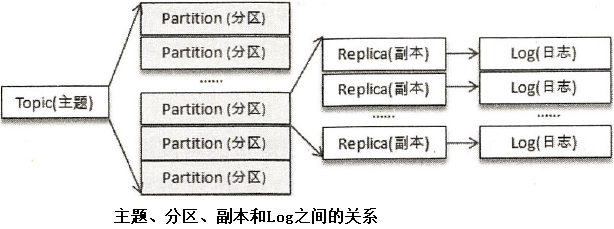
- 文件夹的命名方式为<topic>-<partition>。严谨地说,<topic>-<parition>这类文件夹对应的不是分区,分区同主题一样是一个逻辑的概念而没有物理上的存在。
- 三个broker节点一共创建了8个文件夹,这个数字8实质上是分区数4与副本因子2的乘积。每个副本(或者更确切地说应该是日志,副本与日志一一对应)才真正对应了一个命名形式如<topic>-<partition>的文件夹。
- 主题、分区、副本和Log(日志)的关系如图所示,主题和分区都是提供给上层用户的抽象,而在副本层面或更加确切地说是Log层面才有实际物理上的存在。同一个分区中的多个副本必须分布在不同的broker中,这样才能提供有效的数据冗余。
示例2:查看主题
- Partitioncount表示主题中分区的个数。
- ReplicationFactor表示副本因子。
- configs表示创建或修改主题时指定的参数配置。
- Topic表示主题名称。
- Partition表示分区号。
- Leader表示分区的leader副本所对应的brokerID。
- Replicas表示分区的所有的副本分配情况,即AR集合(数字是brokerID)。
- Isr表示分区的ISR集合(数字是brokerID)。
128 ~]# kafka-topics.sh --zookeeper localhost:2181 --describe --topic topic-create Topic: topic-create TopicId: 10GvLH1_QXSm-BV8wehrEA PartitionCount: 4 ReplicationFactor: 2 Configs: Topic: topic-create Partition: 0 Leader: 1 Replicas: 1,2 Isr: 1,2 Topic: topic-create Partition: 1 Leader: 2 Replicas: 2,3 Isr: 2,3 Topic: topic-create Partition: 2 Leader: 3 Replicas: 3,1 Isr: 1,3 Topic: topic-create Partition: 3 Leader: 1 Replicas: 1,3 Isr: 1,3
2、创建主题时指定分区副本的分配方案
- kafka-topics.sh脚本中还提供了一个replica-assignment参数来手动指定分区副本的分配方案。
--replica-assignment <string: broker_id_for_partl_replical:broker_id_for_partl_replica2, #broker_id_for_partl_replical:第一个分区的第一个副本分配到的broker_id。 broker_id_for_part2_replical:broker_id_for_part2_replica2, #broker_id_for_part2_replica2:第二个分区的第二个副本分配到的broker_id。 ... >
- 这种方式根据分区号的数值大小按照从小到大的顺序进行排列,分区与分区之间用逗号","隔开,分区内多个副本用冒号“:”隔开。并且在使用replica-assignment参数创建主题时不需要原本必备的partitions和replication-factor这两个参数。
示例1:
128 ~]# kafka-topics.sh --zookeeper localhost:2181 --create --topic topic-create-same --replica-assignment 1:2,2:3,3:1,1:3 128 ~]# kafka-topics.sh --zookeeper localhost:2181 --describe --topic topic-create-same Topic: topic-create-same TopicId: FCcHO_BcS76jFb_Vp7D4Vw PartitionCount: 4 ReplicationFactor: 2 Configs: Topic: topic-create-same Partition: 0 Leader: 1 Replicas: 1,2 Isr: 1,2 Topic: topic-create-same Partition: 1 Leader: 2 Replicas: 2,3 Isr: 2,3 Topic: topic-create-same Partition: 2 Leader: 3 Replicas: 3,1 Isr: 3,1 Topic: topic-create-same Partition: 3 Leader: 1 Replicas: 1,3 Isr: 1,3
- 同一个分区内的副本不能在同一台broker上。比如指定了0:0,1:1这种,就会报出AdminCommandFailedException异常。
- 同一个主题的所有分区的副本数量的应该相同。比如指定了0:1,0,1:0这种,就会报出AdminOperationException异常。
- 必须指定所有的分区,不允许跳过某个分区。比如指定了0:1,,0:1,1:0这种,就会报出.NumberFormatException异常。
示例2:
128 ~]# kafka-topics.sh --zookeeper localhost:2181 --create --topic topic-create-same3 --replica-assignment 1:1,2:3,3:1,1:3 128 ~]# kafka-topics.sh --zookeeper localhost:2181 --create --topic topic-create-same3 --replica-assignment 1,2:3,3:1,1:3 128 ~]# kafka-topics.sh --zookeeper localhost:2181 --create --topic topic-create-same3 --replica-assignment 1:2,,3:1,1:3
3、config参数
- 在创建主题时可以通过config参数来设置所要创建主题的相关参数,通过这个参数可以覆盖原本的默认配置。在创建主题时可以同时设置多个参数。
--config <String:namel=valuel> --config <String:name2=value2> ...
示例:
- cleanup.policy和max.message.bytes参数都是主题端的配置。
128 ~]# kafka-topics.sh --zookeeper localhost:2181 --create --topic topic-create3 --partitions 4 --replication-factor 2 --config cleanup.policy=compact --config max.message.bytes=10000 128 ~]# kafka-topics.sh --zookeeper localhost:2181 --describe --topic topic-create3 Topic: topic-create3 TopicId: MxkBPkPqQt-czQyzJhTujw PartitionCount: 4 ReplicationFactor: 2 Configs: cleanup.policy=compact,max.message.bytes=10000 Topic: topic-create3 Partition: 0 Leader: 1 Replicas: 1,2 Isr: 1,2 Topic: topic-create3 Partition: 1 Leader: 2 Replicas: 2,3 Isr: 2,3 Topic: topic-create3 Partition: 2 Leader: 3 Replicas: 3,1 Isr: 3,1 Topic: topic-create3 Partition: 3 Leader: 1 Replicas: 1,3 Isr: 1,3
4、主题名称的注意事项
- 不能与已经存在的主题同名,如果创建了同名的主题就会报错(抛出TopicExistsException异常)。
- 在katka-topics.sh脚本中还提供了一个if-not-exists参数,如果在创建主题时带上了这个参数,那么在发生命名冲突时将不做任何处理(既不创建主题,也不报错)。如果没有发生命名冲突,那么和不带if-not-exists参数的行为一样正常创建主题。
- kafka-topics.sh脚本在创建主题时会检测是否包含“.”或“_”字符。
- 为什么要检测这两个字符呢?因为在Kafka的内部做埋点时会根据主题的名称来命名metrics的名称,并且会将点号“.”改成下画线“_”。
- 假设遇到一个名称为"topic.1_2"的主题,还有一个名称为"topic_1.2"的主题,那么最后的metrics的名称都会为"topic_1_2",这样就发生了名称冲突。
-
主题的命名同样不推荐(虽然可以这样做)使用双下画线“__”开头,因为以双下画线开头的主题一般看作Kafka的内部主题,比如__consumer_offsts和__transaction_state。
主题的名称必须由大小写字母、数字、点号"."、连接线“-"、下画线“-”组成,不能为空,不能只有点号".",也不能只有双点号"..",且长度不能超过249
示例:
128 ~]# kafka-topics.sh --zookeeper localhost:2181 --create --topic topic-create3 --partitions 3 --replication-factor 2 --if-not-exists #首先创建一个以"topic.1_2"为名称的主题,提示WARNING警告,之后再创建"topic_1.2"时发生InvalidTopicException异常 128 ~]# kafka-topics.sh --zookeeper localhost:2181 --create --topic topic.1_2 --partitions 3 --replication-factor 2 128 ~]# kafka-topics.sh --zookeeper localhost:2181 --create --topic topic_1.2 --partitions 3 --replication-factor 2
2、分区副本的分配
- 生产者的分区分配是指为每条消息指定其所要发往的分区。
- 消费者的分区分配是指为消费者指定其可以消费消息的分区。
- 而这里的分区分配是指为集群制定创建主题时的分区副本分配方案,即在哪个broker中创建哪些分区的副本。
1、replica-assignment参数对副本分配的影响
- 在创建主题时,如果使用了replica-assignment参数,那么就按照指定的方案来进行分区副本的创建。
- 在创建主题时,如果没有使用replica-assignment参数,那么就需要按照内部的逻辑来计算分配方案了。
- 使用kafka-topics.sh脚本创建主题时的内部分配逻辑按照机架信息划分成两种策略:未指定机架信息和指定机架信息。
- 如果集群中所有的broker节点都没有配置broker.rack参数,或者使用disable-rck-aware参数来创建主题,那么采用的就是未指定机架信息的分配策略。
- 否则采用的就是指定机架信息的分配策略。
- 使用kafka-topics.sh脚本创建主题时的内部分配逻辑按照机架信息划分成两种策略:未指定机架信息和指定机架信息。
示例:
- 机架就是可以放置多台服务器的架子。
- 假设目前有3个机架rackl、rack2和rack3,Kafka集群中的9个broker点都部署在这3个机架之上,机架与broker节点的对照关系如下:
- rack1: 0, 1, 2
- rack2: 3, 4, 5
- rack3: 6, 7, 8
2、机架信息对副本分配的影响
- Kafka从0.10.x版本开始支持指定broker的机架信息(机架的名称)。
- 如果指定了机架信息,则在分区副本分配时会尽可能地让分区副本分配到不同的机架上。
- 指定机架信息是通过broker端参数broker.rack来配置的,比如配置当前broker所在的机架为"RACK1"。
- 如果一个集群中有部分broker指定了机架信息,并且其余的broker没有指定机架信息,那么在使用katka-topics.sh脚本创建主题时会报出的AdminOperationException的异常。
- 此时若要成功创建主题,要么将集群中的所有broker都加上机架信息或都去掉机架信息,要么使用disable-rack-aware参数来忽略机架信息。
- 如果集群中的所有broker都有机架信息,也可以使用disable-rack-aware参数来忽略机架信息对分区副本的分配影响。
示例:
- 忽略机架信息对分区副本的分配影响
128 ~]# kafka-topics.sh --zookeeper localhost:2181 --create --topic topic-create4 --partitions 4 --replication-factor 2 --disable-rack-aware
3、查看主题
- kafka-topics.sh脚本有5种指令类型:dreate、list、describe、alter和delete。其中list和describe指令可以用来查看主题的信息。
1、list指令
- list指令可以查看当前所有可用的主题。
128 ~]# kafka-topics.sh --zookeeper localhost:2181 --list
2、describe指令
- describe指令可以查看主题的详细信息。
kafka-topics.sh --zookeeper localhost:2181 --describe [--topic [topic_name1, topic_name2, ...]]
示例:
#查看所有主题的详细信息 128 ~]# kafka-topics.sh --zookeeper localhost:2181 --describe #查看单个主题的详细信息 128 ~]# kafka-topics.sh --zookeeper localhost:2181 --describe --topic topic-name1 #查看多个主题的详细信息 128 ~]# kafka-topics.sh --zookeeper localhost:2181 --describe --topic topic-name1,topic-name2
- 通过topics-with-overrides参数可以找出所有包含覆盖配置的主题,它只会列出与集群不一样配置的主题。注意使用topics-with-overrides参数时只显示原本只使用describe指令的第一行信息。
128 ~]# kafka-topics.sh --zookeeper localhost:2181 --describe --topics-with-overrides
- 通过under-replicated-partitions参数可以找出所有包含失效副本的分区。
- 包含失效副本的分区可能正在进行同步操作,也有可能同步发生异常,此时分区的ISR集合小于AR集合。
- 对于通过该参数查询到的分区要重点监控,因为这很可能意味着集群中的某个broker已经失效或同步效率降低等。
128 ~]# kafka-topics.sh --zookeeper localhost:2181 --describe --under-replicated-partitions
- 通过unavailable-partitions参数可以查看主题中没有leader副本的分区,这些分区已经处于离线状态,对于外界的生产者和消费者来说处于不可用的状态。
128 ~]# kafka-topics.sh --zookeeper localhost:2181 --describe --unavailable-partitions
4、修改主题
- 当一个主题被创建之后,可以对其做一定的修改,比如修改分区个数、修改配置等,修改功能就是由katka-topics.sh脚本中的alter指令提供的。
1、修改分区个数
- 目前Kafka的分区数只能增加,不能减少。
- 在增加分区数时一定要三思而后行。对于基于key计算的主题而言,建议在一开始就设置好分区数量,避免以后对其进行调整。
- 减少分区数时,会抛出InvalidPartitionsException异常
示例1:
- 注意警告信息:当主题中的消息包含key时(即key不为nu11),根据key计算分区的行为就会受到影响。
128 ~]# kafka-topics.sh --zookeeper localhost:2181 --alter --topic topic-create1 --partitions 5 #原本只有4个分区 WARNING: If partitions are increased for a topic that has a key, the partition logic or ordering of the messages will be affected Adding partitions succeeded!
- 如果所要修改的主题不存在,就会抛出异常,可以通过if-exists参数来忽略异常。
示例:
- 修改一个不存在的主题topic-unknown的分区,会报出错误信息"Topic topic-unknown does not exist"
128 ~]# kafka-topics.sh --zookeeper localhost:2181 --alter --topic topic-unknown --partitions 3 Error while executing topic command : Topic 'topic-unknown' does not exist as expected [2021-11-12 17:07:47,136] ERROR java.lang.IllegalArgumentException: Topic 'topic-unknown' does not exist as expected at kafka.admin.TopicCommand$.kafka$admin$TopicCommand$$ensureTopicExists(TopicCommand.scala:542) at kafka.admin.TopicCommand$ZookeeperTopicService.alterTopic(TopicCommand.scala:410) at kafka.admin.TopicCommand$.main(TopicCommand.scala:65) at kafka.admin.TopicCommand.main(TopicCommand.scala) (kafka.admin.TopicCommand$) 128 ~]# kafka-topics.sh --zookeeper localhost:2181 --alter --topic topic-unknown --partitions 3 --if-exists
2、修改主题的配置
- 使用kafka-topics.sh脚本的alter指令来变更(增、删、改)主题配置的方式已经过时,并且在未来的版本中会被删除。
- 推荐使用kafka-configs.sh脚本来变更主题配置。(见本页的“6、主题配置管理(kafka-configs.sh)”)
- 使用kafka-topics.sh脚本的alter指令来变更主题的配置。
- 在创建主题的时候可以通过config参数来设置所要创建主题的相关参数,通过这个参数可以覆盖原本的默认配置。
- 在创建完主题之后,还可以通过alter指令配合config参数增加或修改一些配置以覆盖它们配置原有的值。
- 在创建完主题之后,还可以通过alter指令配合delete-config参数来删除之前覆盖的配置,使其恢复原有的默认值。
示例:
#查看topic-create3主题信息 128 ~]# kafka-topics.sh --zookeeper localhost:2181 --describe --topic topic-create3 ... Configs: cleanup.policy=compact,max.message.bytes=10000 ... #修改配置 128 ~]# kafka-topics.sh --zookeeper localhost:2181 --alter --topic topic-create3 --config max.message.bytes=20000 #增加配置 128 ~]# kafka-topics.sh --zookeeper localhost:2181 --alter --topic topic-create3 --config segment.bytes=1048577 #查看topic-create3主题信息 128 ~]# kafka-topics.sh --zookeeper localhost:2181 --describe --topic topic-create3 ... Configs: cleanup.policy=compact,max.message.bytes=20000,segment.bytes=1048577 ... #删除配置 128 ~]# kafka-topics.sh --zookeeper localhost:2181 --alter --topic topic-create3 --delete-config max.message.bytes --delete-config max.message.bytes --delete-config cleanup.policy #查看topic-create3主题信息 128 ~]# kafka-topics.sh --zookeeper localhost:2181 --describe --topic topic-create3 ... Configs: segment.bytes=1048577 ...
5、删除主题
- 如果确定不再使用一个主题,那么最好的方式是将其删除,这样可以释放一些资源,比如磁盘、文件句柄等。
- kafka-opics.sh脚本中的delete指令就可以用来删除主题。
128 ~]# kafka-topics.sh --zookeeper localhost:2181 --delete --topic topic-create3 Topic topic-create3 is marked for deletion. Note: This will have no impact if delete.topic.enable is not set to true.
- 在执行完删除命令之后会有相关的提示信息,这个提示信息和broker端配置参数delete.topic.enable有关。
- 必须将delete.topic.enable参数配置为true才能够删除主题,这个参数的默认值就是true,如果配置为false,那么删除主题的操作将会被忽略。
- 在实际生产环境中,建议将这个参数的值设置为true。
- 如果要删除的主题是Kafka的内部主题,那么删除时就会报错。截至Kafka2.0.0,Katka的内部一共包含2个主题,分别为__consumer_offsets和__transaction_state。
- 如果要删除一个不存在的主题也会报错,可以通过if-exists参数来忽略异常
#删除内部主题 128 ~]# kafka-topics.sh --zookeeper localhost:2181 --delete --topic __consumer_offsets ... ERROR kafka.admin.AdminOperationException: Topic __consumer_offsets is a kafka internal topic and is not allowed to be marked for deletion. #删除一个不存在的主题 128 ~]# kafka-topics.sh --zookeeper localhost:2181 --delete --topic topic-create5 ... ERROR java.lang.IllegalArgumentException: Topic 'topic-create5' does not exist as expected ... 128 ~]# kafka-topics.sh --zookeeper localhost:2181 --delete --topic topic-create5 --if-exists
- 使用kafka-topics.sh脚本删除主题的行为本质上只是在ZooKeeper中的/admin/delete_topics路径下创建一个与待删除主题同名的节点,以此标记该主题为待删除的状态。与创建主题相同的是,真正删除主题的动作也是由Katka的控制器负责完成的。
- 注意,删除主题是一个不可逆的操作。一旦删除之后,与其相关的所有消息数据会被全部删除,所以在执行这一操作的时候也要三思而后行。
6、主题配置管理(kafka-configs.sh)
- kafka-configs.sh脚本是专门用来对配置进行操作的,这里的操作是指在运行状态下修改原有的配置,如此可以达到动态变更的目的。
- kafka-configs.sh脚本可以操作主题相关的配置、broker、用户和客户端这4个类型的配置。
- kafka-configs.sh脚本包含变更配置alter(增、删、改)和查看配置describe这两种指令类型。
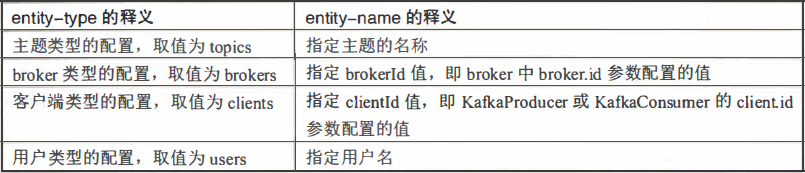
- kafka-configs.sh脚本使用entity-type参数来指定操作配置的类型,并且使用entity-name参数来指定操作配置的名称。
- entity-type只可以配置4个值:topics、brokers、clients和users。
1、查看主题配置(describe指令)
- --describe指定了查看配置的指令动作,--entity-type指定了查看配置的实体类型,--entity-name指定了查看配置的实体名称。
#会有告警信息,--zookeeper已弃用 128 ~]# kafka-configs.sh --zookeeper localhost:2181 --describe --entity-type topics --entity-name topic-create3 128 ~]# kafka-configs.sh --bootstrap-server localhost:9092 --describe --entity-type topics --entity-name topic-create3
- 如果使用kafka-configs.sh脚本查看配置信息时没有指定entity-name参数的值,则会查看entity-type所对应的所有配置信息。
128 ~]# kafka-configs.sh --bootstrap-server localhost:9092 --describe --entity-type topic 128 ~]# kafka-configs.sh --bootstrap-server localhost:9092 --describe --entity-type brokers 128 ~]# kafka-configs.sh --bootstrap-server localhost:9092 --describe --entity-type clients 128 ~]# kafka-configs.sh --bootstrap-server localhost:9092 --describe --entity-type users
2、修改主题配置(alter指令)
- 使用alter指令变更配置时,需要配合add-config和delete-config这两个参数起使用。
- add-config参数用来实现配置的增、改,即覆盖原有的配置。
- delete-config参数用来实现配置的删,即删除被覆盖的配置以恢复默认值。
示例1:add-config参数
- 注意两种查看主题配置信息方式区别。
#查看主题的配置
128 ~]# kafka-configs.sh --bootstrap-server localhost:9092 --describe --entity-type topics --entity-name topic-create3
Dynamic configs for topic topic-create3 are:
segment.bytes=1048577 sensitive=false synonyms={DYNAMIC_TOPIC_CONFIG:segment.bytes=1048577, STATIC_BROKER_CONFIG:log.segment.bytes=1073741824, DEFAULT_CONFIG:log.segment.bytes=1073741824}
#修改主题配置
128 ~]# kafka-configs.sh --bootstrap-server localhost:9092 --alter --entity-type topics --entity-name topic-create3 --add-config cleanup.policy=compact,max.message.bytes=20000
#查看主题的配置
128 ~]# kafka-configs.sh --bootstrap-server localhost:9092 --describe --entity-type topics --entity-name topic-create3
Dynamic configs for topic topic-create3 are:
cleanup.policy=compact sensitive=false synonyms={DYNAMIC_TOPIC_CONFIG:cleanup.policy=compact, DEFAULT_CONFIG:log.cleanup.policy=delete}
segment.bytes=1048577 sensitive=false synonyms={DYNAMIC_TOPIC_CONFIG:segment.bytes=1048577, STATIC_BROKER_CONFIG:log.segment.bytes=1073741824, DEFAULT_CONFIG:log.segment.bytes=1073741824}
max.message.bytes=20000 sensitive=false synonyms={DYNAMIC_TOPIC_CONFIG:max.message.bytes=20000, DEFAULT_CONFIG:message.max.bytes=1048588}
#查看主题的配置
128 ~]# kafka-topics.sh --zookeeper localhost:2181 --describe --topic topic-create3 --topics-with-overrides
Topic: topic-create3 TopicId: MxkBPkPqQt-czQyzJhTujw PartitionCount: 4 ReplicationFactor: 2 Configs: cleanup.policy=compact,max.message.bytes=20000,segment.bytes=1048577
示例2:delete-config参数
#修改主题配置
128 ~]# kafka-configs.sh --bootstrap-server localhost:9092 --alter --entity-type topics --entity-name topic-create3 --delete-config cleanup.policy,segment.bytes
#查看主题的配置
128 ~]# kafka-configs.sh --bootstrap-server localhost:9092 --describe --entity-type topics --entity-name topic-create3
Dynamic configs for topic topic-create3 are:
max.message.bytes=20000 sensitive=false synonyms={DYNAMIC_TOPIC_CONFIG:max.message.bytes=20000, DEFAULT_CONFIG:message.max.bytes=1048588}
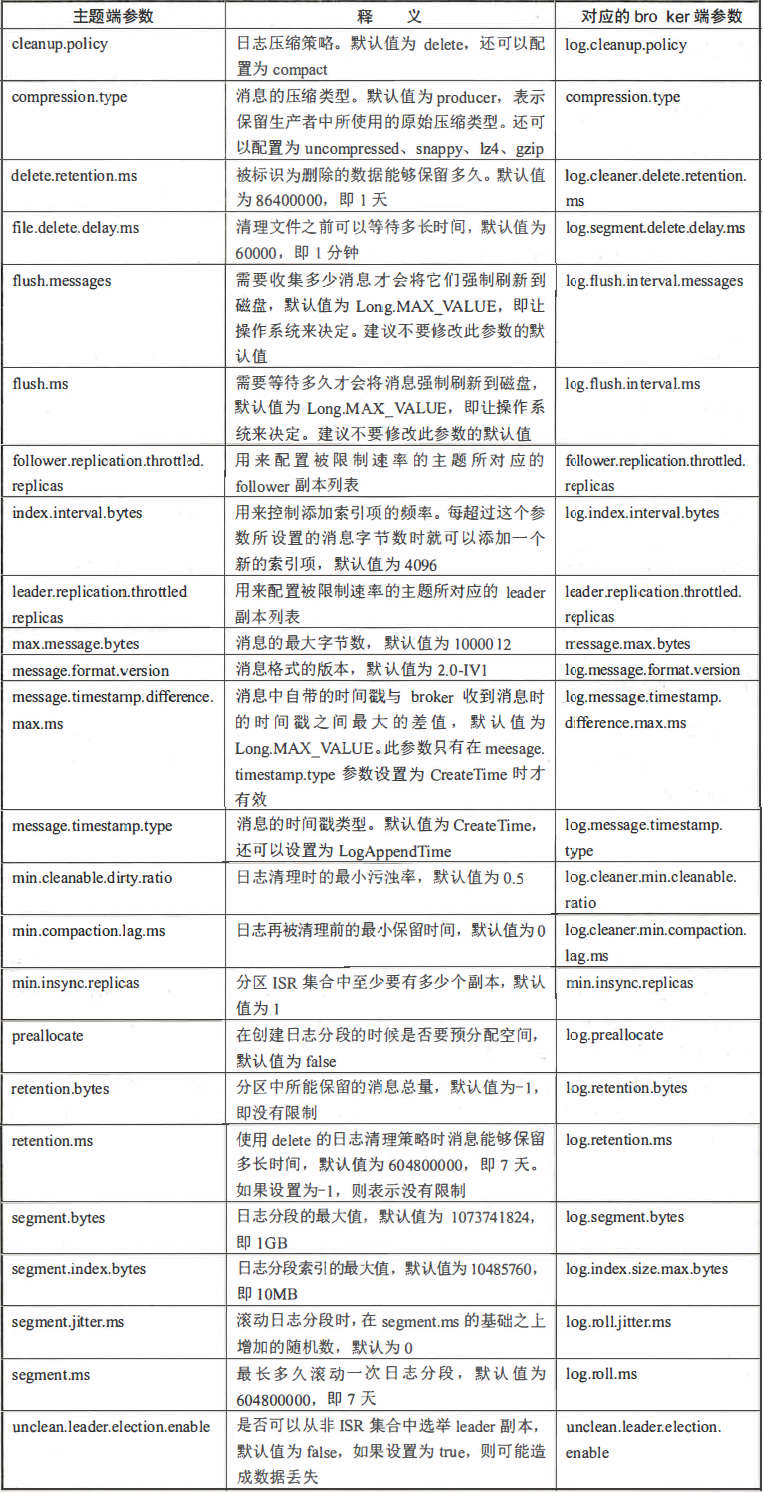
7、主题端参数
- 与主题相关的所有配置参数在broker层面都有对应参数。
- 如果没有修改过主题的任何配置参数,那么就会使用broker端的对应参数作为其默认值。
- 可以在创建主题时覆盖相应参数的默认值,也可以在创建完主题之后变更相应参数的默认值。
- 比如在创建主题的时候没有指定cleanup.policy参数的值,那么就使用1og.cleanup.policy参数所配置的值作为cleanup.polisy的值。
- 主题端参数与broker端参数的对照关系
2、分区的管理
- 分区的管理包括优先副本的选举、分区重分配、复制限流、修改副本因子等内容。
1、优先副本的选举(kafka-leader-election.sh)
- 分区使用多副本机制来提升可靠性,但只有leader副本对外提供读写服务,而follower副本只负责在内部进行消息的同步。如果一个分区的leader副本不可用,那么就意味着整个分区变得不可用,此时就需要Kafka从剩余的follower副本中挑选一个新的leader副本来继续对外提供服务。
- 从某种程度上说,broker节点中leader副本个数的多少决定了这个节点负载的高低(虽然不够严谨)。
- 在创建主题的时候,该主题的分区及副本会尽可能均匀地分布到Kafka集群的各个broker节点上,对应的leader副本的分配也比较均匀。
- 比如使用kafka-topics.sh脚本创建一个分区数为3、副本因子为3的主题topic-create,创建之后的分布信息如下:
128 ~]# kafka-topics.sh --zookeeper localhost:2181 --describe --topic topic-create Topic: topic-create TopicId: txUzBH0fRt6G02MiHwjOkg PartitionCount: 3 ReplicationFactor: 3 Configs: Topic: topic-create Partition: 0 Leader: 2 Replicas: 2,3,1 Isr: 2,3,1 Topic: topic-create Partition: 1 Leader: 3 Replicas: 3,1,2 Isr: 3,1,2 Topic: topic-create Partition: 2 Leader: 1 Replicas: 1,2,3 Isr: 1,2,3
- 针对同一个分区而言,同一个broker节点中不可能出现它的多个副本,即Katka集群的一个broker中最多只能有它的一个副本,因此可以将leader副本所在的broker节点叫作分区的leader节点,follower副本所在的broker节点叫作分区的follower节点。
- 优先副本(preferred replica)是指在AR集合列表中的第一个副本。比如上面主题topic-create中分区0的AR集合列表(Replicas)为[2,3,1],那么分区0的优先副本即为2。
- 理想情况下,优先副本就是该分区的leader副本,所以也可以称之为preferred leader。
- Katka要确保所有主题的优先副本在Kafka集群中均匀分布,这样就保证了所有分区的leader均衡分布。如果leader分布过于集中,就会造成集群负载不均衡。
- 优先副本有效地治理负载失衡。
- 优先副本的选举是指通过一定的方式促使优先副本选举为leader副本,以此来促进集群的负载均衡,这一行为也可以称为“分区平衡”。
- 自动优先副本选举:
- broker端参数auto.leader.rebalance.enable默认值为true,即默认情况下开启分区自动平衡功能(自动进行优先副本的选举)。
- 如果开启分区自动平衡的功能,则Kafka的控制器会启动一个定时任务,这个定时任务会轮询所有的broker节点,计算每个broker节点的分区不平衡率(broker中的不平衡率=非优先副本的leader个数/分区总数)是否超过leader.imbalance.per.broker.percentage参数配置的比值,默认值为10%,如果超过设定的比值则会自动执行优先副本的选举动作以求分区平衡。定时任务会轮询周期由参数leader.imbalance.check.interval.seconds控制,默认值为300秒,即5分钟。
- 生产环境中不建议将auto.leader.rebalance.enable设置为默认的true。(生产环境不建议开启分区自动平衡功能)
- 手动优先副本选举:
- Kafka中kafka-preferred-replica-election.sh脚本提供了优先副本选举的功能。
- 优先副本的选举过程是一个安全的过程,Kafka客户端可以自动感知分区leader副本的变更。
#获取kafka的版本号
128 ~]# kafka-leader-election.sh --version
#对所有被选中的分区进行分区均衡
128 ~]# kafka-leader-election.sh --bootstrap-server localhost:9092 --election-type preferred --all-topic-partitions
#对指定的主题分区进行分区均衡
128 ~]# kafka-leader-election.sh --bootstrap-server localhost:9092 --election-type preferred --topic topic-create --partition 0
必选项:
--election-type <[PREFERRED,UNCLEAN]: election type>
preferred:只有当前leader不是主题分区的首选leader时,才会执行选举。
unclean:只有当主题分区没有leader时,才会执行选举。
必选项,三选一:
--all-topic-partitions:根据选择的类型(election-type)在所有符合条件的主题分区上执行选择
--topic <String: topic name>:指定要进行选举的主题名称。
--path-to-json-file <String: Path to JSON file>:JSON文件,包含要为其执行leader选举的分区列表。示例
{"partitions":
[{"topic": "foo", "partition": 1},
{"topic": "foobar", "partition": 2}]
}
--partition <Integer: partition id>:如果有--topic,必须指定--partition
#老版本kafka,进行分区均衡
128 ~]# kafka-preferred-replica-election.sh --zookeeper localhost:2181
- 负载均衡:
- 随着时间的更替,Katka集群的broker节点不可避免地会遇到宕机或崩溃的问题,当分区的leader节点发生故障时,其中一个follower节点就会成为新的leader节点,这样就会导致集群的负载不均衡,从而影响整体的健壮性和稳定性。当原来的leader节点恢复之后重新加入集群时,它只能成为一个新的follower节点而不再对外提供服务。此时可以进行优先副本的选举,从而使得分区平衡(leader分配均衡)。
- 需要注意的是,分区平衡并不意味着Katka集群的负载均衡,因为还要考虑集群中的分区分配是否均衡。
- 更进一步,每个分区的leader副本的负载也是各不相同的,有些leader副本的负载很高,比如需要承载TPS为30000的负荷,而有些leader副本只需承载个位数的负荷。也就是说,就算集群中的分区分配均衡、leader分配均衡,也并不能确保整个集群的负载就是均衡的,还需要其他一些硬性的指标来做进一步的衡量。
2、分区重分配(kafka-reassign-partitions.sh)
- 当集群中的一个节点突然宕机下线时,如果节点上的分区是单副本的,那么这些分区就变得不可用了,在节点恢复前,相应的数据也就处于丢失状态;如果节点上的分区是多副本的,那么位于这个节点上的leader副本的角色会转交到集群的其他follower副本中。总而言之,这个节点上的分区副本都已经处于功能失效的状态,Kafka并不会将这些失效的分区副本自动地迁移到集群中剩余的可用broker节点上,如果放任不管,则不仅会影响整个集群的均衡负载,还会影响整体服务的可用性和可靠性。
- 当要对集群中的一个节点进行有计划的下线操作时,为了保证分区及副本的合理分配,我们希望通过某种方式能够将该节点上的分区副本迁移到其他的可用节点上。
- 如果要将某个broker下线,那么在执行分区重分配动作之前最好先关闭或重启broker。这样这个broker就不再是任何分区的leader节点了,它的分区就可以被分配给集群中的其他broker。这样可以减少broker间的流量复制,以此提升重分配的性能,以及减少对集群的影响。
- 当集群中新增broker节点时,只有新创建的主题分区才有可能被分配到这个节点上,而之前的主题分区并不会自动分配到新加入的节点中,因为在它们被创建时还没有这个新节点,这样新节点的负载和原先节点的负载之间严重不均衡。
- 为了解决上述问题,需要让分区副本再次进行合理的分配,也就是所谓的分区重分配。
- Kafka提供了kafka-reassign-partitions.sh脚本来执行分区分配的工作,它可以在集群扩容、broker节点失效时下对分区进行迁移。
- kafka-reassign-partitions.sh脚本的使用分为3个步骤:
- (1)创建需要一个包含主题清单的JSON文件。
- (2)根据主题清单和broker节点清单生成一份重分配方案。
- (3)根据重分配方案执行具体的重分配动作。
- ((4)验证查看分区重分配的进度(可以不操作))
- 分区重分配的基本原理是先通过控制器为每个分区添加新副本(增加副本因子),新的副本将从分区的leader副本那里复制所有的数据。在复制完成之后,控制器将旧副本从副本清单里移除(恢复为原先的副本因子数) 。注意在重分配的过程中要确保有足够的空间。
- 分区重分配对集群的性能有很大的影响,需要占用额外的资源,比如网络和磁盘。在实际操作中,我们将降低重分配的粒度,分成多个小批次来执行,以此来将负面的影响降到最低,这一点和优先副本的选举有异曲同工之妙。
- 在一个由3个节点(broker1、broker2、broker3)组成的集群中创建一个主题topic-reassign,主题中包含4个分区和2个副本。
#创建主题 128 ~]# kafka-topics.sh --zookeeper localhost:2181 --create --topic topic-reassign --partitions 4 --replication-factor 2 #查看主题详细信息 128 ~]# kafka-topics.sh --zookeeper localhost:2181 --describe --topic topic-reassign Topic: topic-reassign TopicId: MX505IXuQkuFZX6W0sxKMA PartitionCount: 4 ReplicationFactor: 2 Configs: Topic: topic-reassign Partition: 0 Leader: 3 Replicas: 3,2 Isr: 3,2 Topic: topic-reassign Partition: 1 Leader: 1 Replicas: 1,3 Isr: 1,3 Topic: topic-reassign Partition: 2 Leader: 2 Replicas: 2,1 Isr: 2,1 Topic: topic-reassign Partition: 3 Leader: 3 Replicas: 3,1 Isr: 3,1
1、减少broker节点
- 我们可以观察到主题topic-reassign在3个节点中都有相应的分区副本分布。由于某种原因,我们想要下线brokerID为2的broker节点,在此之前,我们要做的就是将其上的分区副本迁移出去。
(1)、创建json文件
128 ~]# vim reassign.json
{
"topics":[
{
"topic":"topic-reassign"
}
],
"version":1
}
(2)、生成一份重分配方案
- zookeeper用来指定ZooKeeper的地址。
- generate是kafka-reassign-partitions.sh脚本中指令类型的参数,生成一个重分配的候选方案。
- topic-to-move-json用来指定分区重分配对应的主题清单文件的路径,该清单文件的具体的格式可以归纳为{"topis":[{"topic":"foo"},{"topic:"fool"}],"version": 1}。
- broker-list用来指定所要分配的broker节点列表,比如示例中的"1,3"
128 ~]# kafka-reassign-partitions.sh --bootstrap-server localhost:9092 --generate --topics-to-move-json-file reassign.json --broker-list 1,3
Current partition replica assignment
{"version":1,"partitions":[{"topic":"topic-reassign","partition":0,"replicas":[3,2],"log_dirs":["any","any"]},{"topic":"topic-reassign","partition":1,"replicas":[1,3],"log_dirs":["any","any"]},{"topic":"topic-reassign","partition":2,"replicas":[2,1],"log_dirs":["any","any"]},{"topic":"topic-reassign","partition":3,"replicas":[3,1],"log_dirs":["any","any"]}]}
Proposed partition reassignment configuration
{"version":1,"partitions":[{"topic":"topic-reassign","partition":0,"replicas":[1,3],"log_dirs":["any","any"]},{"topic":"topic-reassign","partition":1,"replicas":[3,1],"log_dirs":["any","any"]},{"topic":"topic-reassign","partition":2,"replicas":[1,3],"log_dirs":["any","any"]},{"topic":"topic-reassign","partition":3,"replicas":[3,1],"log_dirs":["any","any"]}]}
- 第一个"Current partition replica assignment"所对应的JSON内容为当前的分区副本分配情况,在执行分区重分配的时候最好将这个内容保存起来,以备后续的回滚操作。
- 第二个"Proposed partition reassignment configuration"所对应的JSON内容为重分配的候选方案,注意这里只是生成一份可行性的方案,并没有真正执行重分配的动作。生成的可行性方案的具体算法和创建主题时的一样,这里也包含了机架信息。
(3)重分配分区
- 第二个JSON内容保存在一个JSON文件中,假定这个文件的名称为project.json。
128 ~]# vim project.json
{"version":1,"partitions":[{"topic":"topic-reassign","partition":0,"replicas":[1,3],"log_dirs":["any","any"]},{"topic":"topic-reassign","partition":1,"replicas":[3,1],"log_dirs":["any","any"]},{"topic":"topic-reassign","partition":2,"replicas":[1,3],"log_dirs":["any","any"]},{"topic":"topic-reassign","partition":3,"replicas":[3,1],"log_dirs":["any","any"]}]}
- 执行具体的重分配分区动作
- execute是指令类型的参数,用来指定执行重分配的动作。
- reassignment-json-file指定分区重分配方案的文件路径,对应于示例中的project.json文件。
- throttle <Long: throttle>:分区在broker之间复制时进行限流(B/s)。这个选项可以与execute一起包含在重新分配开始时,并且可以通过连同additional标志一起重新提交当前的重新分配来改变它。节流速率至少为1kb /s。(默认值:1)
128 ~]# kafka-reassign-partitions.sh --bootstrap-server localhost:9092 --execute --reassignment-json-file project.json
Current partition replica assignment
{"version":1,"partitions":[{"topic":"topic-reassign","partition":0,"replicas":[3,2],"log_dirs":["any","any"]},{"topic":"topic-reassign","partition":1,"replicas":[1,3],"log_dirs":["any","any"]},{"topic":"topic-reassign","partition":2,"replicas":[2,1],"log_dirs":["any","any"]},{"topic":"topic-reassign","partition":3,"replicas":[3,1],"log_dirs":["any","any"]}]}
Save this to use as the --reassignment-json-file option during rollback
Successfully started partition reassignments for topic-reassign-0,topic-reassign-1,topic-reassign-2,topic-reassign-3
- 查看主题详细信息
128 ~]# kafka-topics.sh --zookeeper localhost:2181 --describe --topic topic-reassign Topic: topic-reassign TopicId: MX505IXuQkuFZX6W0sxKMA PartitionCount: 4 ReplicationFactor: 2 Configs: Topic: topic-reassign Partition: 0 Leader: 3 Replicas: 1,3 Isr: 3,1 Topic: topic-reassign Partition: 1 Leader: 1 Replicas: 3,1 Isr: 3,1 Topic: topic-reassign Partition: 2 Leader: 1 Replicas: 1,3 Isr: 1,3 Topic: topic-reassign Partition: 3 Leader: 3 Replicas: 3,1 Isr: 3,1
(4)验证查看分区重分配的进度
- 只需将上面的execute替换为verify即可
128 ~]# kafka-reassign-partitions.sh --bootstrap-server localhost:9092 --verify --reassignment-json-file project.json
(5)优先副本选举
#对0分区进行优先副本选举 128 ~]# kafka-leader-election.sh --bootstrap-server localhost:9092 --election-type preferred --topic topic-reassign --partition 0 128 ~]# kafka-topics.sh --zookeeper localhost:2181 --describe --topic topic-reassign Topic: topic-reassign TopicId: MX505IXuQkuFZX6W0sxKMA PartitionCount: 4 ReplicationFactor: 2 Configs: Topic: topic-reassign Partition: 0 Leader: 1 Replicas: 1,3 Isr: 3,1 Topic: topic-reassign Partition: 1 Leader: 1 Replicas: 3,1 Isr: 3,1 Topic: topic-reassign Partition: 2 Leader: 1 Replicas: 1,3 Isr: 1,3 Topic: topic-reassign Partition: 3 Leader: 3 Replicas: 3,1 Isr: 3,1
2、增加、迁移broker节点
- 增加、迁移broker节点和减少broker节点的操作一样。
- 查看主题(只有broke1和3节点)
128 ~]# kafka-topics.sh --zookeeper localhost:2181 --describe --topic topic-reassign Topic: topic-reassign TopicId: MX505IXuQkuFZX6W0sxKMA PartitionCount: 4 ReplicationFactor: 2 Configs: Topic: topic-reassign Partition: 0 Leader: 1 Replicas: 1,3 Isr: 3,1 Topic: topic-reassign Partition: 1 Leader: 1 Replicas: 3,1 Isr: 3,1 Topic: topic-reassign Partition: 2 Leader: 1 Replicas: 1,3 Isr: 1,3 Topic: topic-reassign Partition: 3 Leader: 3 Replicas: 3,1 Isr: 3,1
- 生成一份重分配方案
#相当于将该主题从broker 1迁移到broker 2上,broker 3不变 128 ~]# kafka-reassign-partitions.sh --bootstrap-server localhost:9092 --generate --topics-to-move-json-file reassign.json --broker-list 2,3 #增加broker 2节点 128 ~]# kafka-reassign-partitions.sh --bootstrap-server localhost:9092 --generate --topics-to-move-json-file reassign.json --broker-list 1,2,3
3、复制限流
- 分区重分配本质在于数据复制,先增加新的副本,然后进行数据同步,最后删除旧的副本来达到最终的目的。数据复制会占用额外的资源,如果重分配的量太大必然会严重影响整体的性能,尤其是处于业务高峰期的时候。减小重分配的粒度,以小批次的方式来操作是一种可行的解决思路。如果集群中某个主题或某个分区的流量在某段时间内特别大,那么只靠减小粒度是不足以应对的,这时就需要有一个限流的机制,可以对副本间的复制流量加以限制来保证重分配期间整体服务不会受太大的影响。
- 副本间的复制限流有两种实现方式:kafka-config.sh脚本和kafka-reassign-partitions.sh脚本。
- kafka-reassign-partitions.sh脚本提供的限流功能背后的实现原理就是配置与kafka-config.sh没有什么太大的差别。
- kafka-config.sh脚本实现复制限流的功能比较烦琐,并且在手动配置限流副本列表时也比较容易出错。
- 推荐使用kafka-reassign-partitions.sh配合throttle参数的方式,方便快捷且不容易出错。
1、kafka-configsh脚本实现限流
- kafka-config.sh脚本主要以动态配置的方式来达到限流的目的。
1、broker级别的设置
- 在broker级别有两个与复制限流相关的配置参数:
- follower.replication.throttled.rate用于设置follower副本复制的速度(B/s)。
- leader.replication.throttled.rate用于设置leader副本传输的速度(B/s)。
- 通常情况下,两者的配置值是相同的。
- 查看broker的配置
128 ~]# kafka-configs.sh --bootstrap-server localhost:9092 --describe --entity-type brokers 128 ~]# kafka-configs.sh --bootstrap-server localhost:9092 --describe --entity-type brokers --entity-name 1
- 修改broker的配置
128 ~]# kafka-configs.sh --bootstrap-server localhost:9092 --alter --entity-type brokers --entity-name 1 --add-config follower.replication.throttled.rate=1024,leader.replication.throttled.rate=1024
- 删除broker的配置
128 ~]# kafka-configs.sh --bootstrap-server localhost:9092 --alter --entity-type brokers --entity-name 1 --delete-config follower.replication.throttled.rate,leader.replication.throttled.rate
2、主题级别的设置
- 在主题级别也有两个相关的参数来限制复制的速度:follower.replication.throttled.replicas和leader.replication.throttled.replicas分别用来配置被限制速度的主题所对应的leader副本列表和follower副本列表。
128 ~]# kafka-topics.sh --zookeeper localhost:2181 --describe --topic topic-reassign Topic: topic-reassign TopicId: MX505IXuQkuFZX6W0sxKMA PartitionCount: 4 ReplicationFactor: 2 Configs: Topic: topic-reassign Partition: 0 Leader: 2 Replicas: 2,3 Isr: 3,2 Topic: topic-reassign Partition: 1 Leader: 3 Replicas: 3,2 Isr: 3,2 Topic: topic-reassign Partition: 2 Leader: 2 Replicas: 2,3 Isr: 3,2 Topic: topic-reassign Partition: 3 Leader: 3 Replicas: 3,2 Isr: 3,2
- 在上面示例中,主题topic-reassign的4个分区所对应的leader节点分别为2、3、2、3,即分区与代理的映射关系为0:2、1:3、2:2、3:3。而对应的follower节点分别为3、2、3、2,分区与代理的映射关系为0:3、1:2、2:3、3:2,那么此主题的限流副本列表及具体的操作细如下:
#查看topic-reassign的主题配置 128 ~]# kafka-configs.sh --bootstrap-server localhost:9092 --describe --entity-type topics --entity-name topic-reassign #修改主题配置,复制限流 128 ~]# kafka-configs.sh --bootstrap-server localhost:9092 --alter --entity-type topics --entity-name topic-reassign --add-config leader.replication.throttled.replicas=[0:2,1:3,2:2,3:3],follower.replication.throttled.replicas=[0:3,1:2,2:3,3:2]
3、带有主题限流的分区重分配
- 比较复杂,亦不常用,就不介绍了,
2、kafka-reassign-partitions.s脚本实现限流
- 分区重分配脚本kafka-reassign-partitions.sh也提供了限流的功能,只需在执行分区分配时加一个throttle参数即可(单位B/s)。
128 ~]# kafka-reassign-partitions.sh --bootstrap-server localhost:9092 --execute --reassignment-json-file project.json --throttle 10
Current partition replica assignment
{"version":1,"partitions":[{"topic":"topic-reassign","partition":0,"replicas":[1,3],"log_dirs":["any","any"]},{"topic":"topic-reassign","partition":1,"replicas":[3,1],"log_dirs":["any","any"]},{"topic":"topic-reassign","partition":2,"replicas":[1,3],"log_dirs":["any","any"]},{"topic":"topic-reassign","partition":3,"replicas":[3,1],"log_dirs":["any","any"]}]}
Save this to use as the --reassignment-json-file option during rollback
Warning: You must run --verify periodically, until the reassignment completes, to ensure the throttle is removed.
The inter-broker throttle limit was set to 10 B/s
Successfully started partition reassignments for topic-reassign-0,topic-reassign-1,topic-reassign-2,topic-reassign-3
- 告警信息:需要周期性地执行查看进度的命令直到重分配完成,这样可以确保限流设置被移除。也就是说,使用这种方式的限流同样需要显式地执行某些操作以使在重分配完成之后可以删除限流的设置。
128 ~]# kafka-reassign-partitions.sh --bootstrap-server localhost:9092 --verify --reassignment-json-file project.json
- 如果想在重分配期间修改限制来增加吞吐量,以便完成得更快,则可以重新运行kafkareassign-partitions.sh脚本的execute命令,使用相同的reassignment-json-file。
128 ~]# kafka-reassign-partitions.sh --bootstrap-server localhost:9092 --execute --reassignment-json-file project.json --throttle 1024
4、修改副本因子
- 修改副本因子的场景有很多,比如在创建主题时填写了错误的副本因子数而需要修改,再比如运行一段时间之后想要通过增加副本因子数来提高容错性和可靠性。
- 副本数可以增加,也可以减少。(分区数只能加,不能减)
- 修改副本因子也是通过分区分红分配脚本kafka-reassign-partitions.sh实现的
1、增加副本数
- 只需稍加修改之前使用的project.json文件即可添加副本。
#修改前
{
"version":1,
"partitions":[
{"topic":"topic-reassign","partition":0,"replicas":[1,3],"log_dirs":["any","any"]},
{"topic":"topic-reassign","partition":1,"replicas":[3,1],"log_dirs":["any","any"]},
{"topic":"topic-reassign","partition":2,"replicas":[1,3],"log_dirs":["any","any"]},
{"topic":"topic-reassign","partition":3,"replicas":[3,1],"log_dirs":["any","any"]}
]
}
#修改后。(replicas中添加要加副本的brokerID,log_dirs中对应添加日志标志)
{
"version":1,
"partitions":[
{"topic":"topic-reassign","partition":0,"replicas":[1,3,2],"log_dirs":["any","any","any"]},
{"topic":"topic-reassign","partition":1,"replicas":[3,1,2],"log_dirs":["any","any","any"]},
{"topic":"topic-reassign","partition":2,"replicas":[1,3,2],"log_dirs":["any","any","any"]},
{"topic":"topic-reassign","partition":3,"replicas":[3,1,2],"log_dirs":["any","any","any"]}
]
}
- 执行分区重分配
128 ~]# kafka-topics.sh --zookeeper localhost:2181 --describe --topic topic-reassign Topic: topic-reassign TopicId: MX505IXuQkuFZX6W0sxKMA PartitionCount: 4 ReplicationFactor: 2 Configs: Topic: topic-reassign Partition: 0 Leader: 1 Replicas: 1,3 Isr: 3,1 Topic: topic-reassign Partition: 1 Leader: 3 Replicas: 3,1 Isr: 3,1 Topic: topic-reassign Partition: 2 Leader: 1 Replicas: 1,3 Isr: 3,1 Topic: topic-reassign Partition: 3 Leader: 3 Replicas: 3,1 Isr: 3,1 128 ~]# kafka-reassign-partitions.sh --bootstrap-server localhost:9092 --execute --reassignment-json-file project.json 128 ~]# kafka-topics.sh --zookeeper localhost:2181 --describe --topic topic-reassign Topic: topic-reassign TopicId: MX505IXuQkuFZX6W0sxKMA PartitionCount: 4 ReplicationFactor: 3 Configs: Topic: topic-reassign Partition: 0 Leader: 1 Replicas: 1,3,2 Isr: 3,1,2 Topic: topic-reassign Partition: 1 Leader: 3 Replicas: 3,1,2 Isr: 3,1,2 Topic: topic-reassign Partition: 2 Leader: 1 Replicas: 1,3,2 Isr: 3,1,2 Topic: topic-reassign Partition: 3 Leader: 3 Replicas: 3,1,2 Isr: 3,1,2
2、减少副本数
- 减少副本数,最直接的方式是关闭一些broker,不过这种手法不太正规。
- 同样可以通过kafka-reassign-partition.sh脚本来减少副本数。
- 和增加副本数的方法一样
3、如何选择合适的分区数
- 这个问题没有固定的答案,也没有非常权威的答案。只能从某些角度来做具体的分析,最终还是要根据实际的业务场景、软件条件、硬件条件、负载情况等来做具体的考量。
- 本节主要介绍与本问题相关的一些重要的决策因素。
1、性能测试工具
- Kafka本身提供的性能测试工具:
- 生产者性能测试工具kafka-producer-perf-test.sh。
- 消费者性能测试工具kafka-consumer-perf-test.sh。
- 创建一个只有1个分区和1个副本的主题topic-1。
128 ~]# kafka-topics.sh --zookeeper localhost:2181 --create --topic topic-1 --partitions 1 --replication-factor 1
1、生产者性能测试工具
- 我们向主题topic-1中发送100万条消息,并且每条消息大小为1024B,生产者对应的acks参数为1。
- topic指定生产者发送消息的目标主题。
- num-records指定发送消息的总条数。
- record-size设置每条消息的字节数。
- throughput用来进行限流控制,当设定的值小于0时不限流,当设定的值大于0时,当发送的吞吐量大于该值时就会被阻塞一段时间。
- producer-props指定生产者的配置,可同时指定多组配置,各组配置之间以空格分隔,与producer-props参数对应的还有一个producer.config参数,它用来指定生产者的配置文件。
- print-metrics参数会在测试完成之后打印很多指标信息
128 ~]# kafka-producer-perf-test.sh --topic topic-1 --num-records 1000000 --record-size 1024 --throughput -1 --producer-props bootstrap.servers=localhost:9092 acks=1
- kafka-producer-perf-test.sh脚本的输出信息
- records sent表示测试时发送的消息总数。
- records/sec表示以每秒发送的消息数来统计吞吐量,括号中的MB/sec表示以每秒发送的消息大小来统计吞吐量,注意这两者的维度。
- avg latency表示消息处理的平均耗时。
- max latency表示消息处理的最大耗时。
- 50th、95th、99th和99.9th分别表示50%、95%、99%和99.9%的消息处理耗时。
1000000 records sent, 18173.887758 records/sec (17.75 MB/sec), 1626.65 ms avg latency, 4394.00 ms max latency, 1260 ms 50th, 3429 ms 95th, 4081 ms 99th, 4366 ms 99.9th.
2、消费者性能测试工具
- 简单地消费主题topic-1中的100万条消息。
128 ~]# kafka-consumer-perf-test.sh --topic topic-1 --messages 1000000 --broker-list localhost:9092
- kafka-consumer-perf-test.sh脚本的输出信息
- 起始运行时间(start.time)。
- 结束运行时间(end.time)。
- 消费的消息总量(data.consumed.in.MB,单位为MB) 。
- 按字节大小计算的消费吞吐量(MB.sec,单位为MB/s)。
- 消费的消息总数(data.consumed.in.nMsg)。
- 按消息个数计算的吞吐量(nMsg.sec)。
- 再平衡的时间(rebalance.time.ms,单位为ms) 。
- 拉取消息的持续时间(fetch.time.ms,单位为ms)。
- 每秒拉取消息的字节大小(fetch.MB.sec,单位为MB/s) 。
- 每秒拉取消息的个数(fetch.nMsg.sec) 。
- 其中fetch.time.ms = end.time-start.time-rebalance.time.ms。
start.time, end.time, data.consumed.in.MB, MB.sec, data.consumed.in.nMsg, nMsg.sec, rebalance.time.ms, fetch.time.ms, fetch.MB.sec, fetch.nMsg.sec 2021-11-17 15:28:20:411, 2021-11-17 15:28:34:491, 977.0264, 69.3911, 1000475, 71056.4631, 1711, 12369, 78.9899, 80885.6819
2、分区数越多吞吐量就越高吗
- 分区是Kaika中最小的并行操作单元。
- 对生产者而言,每一个分区的数据写入是完全可以并行化的。
- 对消费者而言,Kafka只允许单个分区中的消息被一个消费者线程消费,一个消费组的消费并行度完全依赖于所消费的分区数。
- 消息中间件的性能一般是指吞吐量(广义来说还包括延迟)。
- 抛开硬件资源的影响,消息写入的吞吐量还会受到消息大小、消息压缩方式、消息发送方式(同步/异步)、消息确认类型(acks)、副本因子等参数的影响,消息消费的吞吐量还会受到应用逻辑处理速度的影响。
- 分区数越多吞吐量也就越高?
- 网络上很多资料都认可这一观点,但实际上很多事情都会有一个临界值,当超过这个临界值之后,很多原本符合既定逻辑的走向又会变得不同。读者需要对此有清晰的认知,懂得去伪求真,实地测试验证不失为一座通向真知的桥梁。
- 不过本节并没有指明分区数越多吞吐量就越低这个观点,并且具体吞吐量的数值和走势还会和磁盘、文件系统、IO调度策略相关。
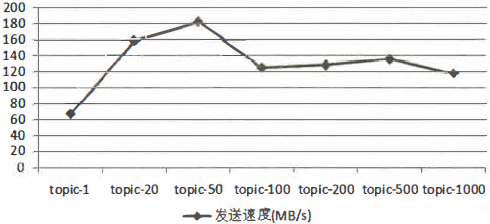
- 性能测试工具来实际测试一下。首先分别创建分区数为1、20、50、100、200、500、1000的主题,对应的主题名称分别为topic-1、topic-20、topic-50、topic-100、topic-200、topic-500、topic-1000,所有主题的副本因子都设置为1。
1、生产者性能测试结果
- 使用kafka-producer-perf-test.sh脚本分别向这些主题中发送100万条消息体大小为1KB的消息。
128 ~]# kafka-producer-perf-test.sh --topic topic-xxx --num-records 1000000 --record-size 1024 --throughput -1 --producer-props bootstrap.servers=localhost:9092 acks=1
-
- 在图中,我们可以看到分区数为1时吞吐量最低,随着分区数的增长,相应的吞吐量也跟着上涨。一旦分区数超过了某个阈值之后,整体的吞吐量是不升反降的。也就是说,并不是分区数越多吞吐量也越大。这里的分区数临界阈值针对不同的测试环境也会表现出不同的结果,实际应用中可以通过类似的测试案例(比如复制生产流量以便进行测试回放)来找到一个合理的临界值区间。
- 在同一套环境下,我们还可以测试一下同时往两个分区数为200的主题中发送消息的性能,假设测试结果中两个主题所对应的吞吐量分别为A和B,再测试一下只往一个分区数为200的主题中发送消息的性能,假设此次测试结果中得到的吞吐量为c,会发现A<C、B<C且A+B>C。可以发现由于共享系统资源的因素,A和B之间会彼此影响。通过A+B>C的结果,可知topic-200的那个点位也并没有触及系统资源的瓶颈,发生吞吐量有所下降的结果也并非是系统资源瓶颈造成的。
2、消费者性能测试结果
- 使用kafka-consumer-perf-test.sh脚本分别消费这些主题中的100万条消息。
128 ~]# kafka-consumer-perf-test.sh --topic topic-xxx --messages 1000000 --broker-list localhost:9092
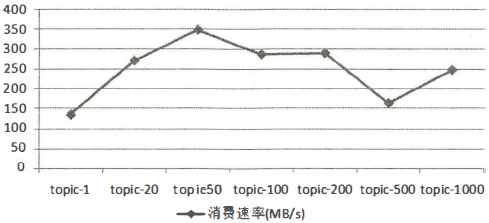
- 在图中,随着分区数的增加,相应的吞吐量也会有所增长。一旦分区数超过了某个阈,值之后,整体的吞吐量也是不升反降的,同样说明了分区数越多并不会使吞吐量一直增长。
3、分区数的上限
- kafka的分区总数与文件描述符的数量有关,因为分区的每个副本都会消耗其所在主机的一个文件描述符。(一个进程)
- 每个kafka机器上的副本数量不能大于“ulimit -Hn”的结果。
1、硬限制和软限制
- ulimit是在系统允许的情况下,提供对特定shell可利用的资源的控制。-H和-s选项指定资源的硬限制和软限制。
- 硬限制设定之后不能再添加,而软限制则可以增加到硬限制规定的值。
- 限制值可以是指定资源的数值或har d、soft、unlimited 这些特殊值。
- har d代表当前硬限制。
- soft代表当前软件限制。
- unlimited代表不限制。
- 硬限制可以在任何时候、任何进程中设置,但硬限制只能由超级用户设置。软限制是内核实际执行的限制,任何进程都可以将软限制设置为任意小于等于硬限制的值。
- 设定ulimit的值:如果-H和-S选项都没有指定,则同时设定软限制和硬限制。
- 查看ulimit的值:如果不指定限制值,则打印指定资源的软限制值,除非指定了-H选项。
- 修改ulimit的值
#ulimit永久全局有效的两种方法:
修改/etc/security/limits.conf文件,重启后生效。
root soft nofile 65535
root hard nofile 65535
在/et/profile文件中添加ulimit,并source使其生效。
#ulimit临时当前shell有效:
ulimit -n 65535
- 查看ulimit的值
128 ~]# ulimit -n 1024 #软限制 128 ~]# ulimit -Sn 1024 #硬限制 128 ~]# ulimit -Hn 4096
2、分区与文件描述符
- 分区的每个副本都会消耗其所在主机的一个文件描述符。
- 一个进程(kafka进程)所能支配的文件描述符是有限的。
128 ~]# ls /proc/2089/fd | wc -l 164 128 ~]# ls /proc/11922/fd | wc -l 196 128 ~]# kafka-topics.sh --zookeeper localhost:2181 --create --topic topic-fd-2 --partitions 1 --replication-factor 1 128 ~]# kafka-topics.sh --zookeeper localhost:2181 --describe --topic topic-fd-2 Topic: topic-fd-2 TopicId: GCWSR-6lQS20CUj81KCaVQ PartitionCount: 1 ReplicationFactor: 1 Configs: Topic: topic-fd-2 Partition: 0 Leader: 1 Replicas: 1 Isr: 1 128 ~]# ls /proc/11922/fd | wc -l 197
4、考量因素
- 从吞吐量方面考虑,增加合适的分区数可以在一定程度上提升整体吞吐量,但超过对应的阈值之后吞吐量不升反降。如果应用对吞吐量有一定程度上的要求,则建议在投入生产环境之前对同款硬件资源做一个完备的吞吐量相关的测试,以找到合适的分区数阅值区间。
- 在创建主题时,最好能确定好分区数,这样也可以省去后期增加分区所带来的多余操作。
- 如果应用与key高关联,在创建主题时可以适当地多创建一些分区,以满足未来的需求。通常情况下,可以根据未来2年内的目标吞吐量来设定分区数。
- 如果应用与key弱关联,并且具备便捷的增加分区数的操作接口,那么也可以不用考虑那么长远的目标。
- 当然分区数也不能一味地增加,分区数会占用文件描述符,而一个进程所能支配的文件描述符是有限的,这也是通常所说的文件句柄的开销。虽然我们可以通过修改配置来增加可用文件描述符的个数,但凡事总有一个上限,在选择合适的分区数之前,最好再考量一下当前Kafka进程中已经使用的文件描述符的个数。
- 分区数的多少还会影响系统的可用性。
- Kafka通过多副本机制来实现集群的高可用和高可靠,每个分区都会有一至多个副本,每个副本分别存在于不同的broker节点上,并且只有leader副本对外提供服务。
- 在Kafka集群的内部,所有的副本都采用自动化的方式进行管理,并确保所有副本中的数据都能保持一定程度上的同步。当broker发生故障时,leader副本所属宿主的broker节点上的所有分区将暂时处于不可用的状态,此时Kafka会自动在其他的follower副本中选举出新的leader用于接收外部客户端的请求,整个过程由Kafka控制器负责完成。
- 分区在进行leader角色切换的过程中会变得不可用,不过对于单个分区来说这个过程非常短暂,对用户而言可以忽略不计。如果集群中的某个broker节点宕机,那么就会有大量的分区需要同时进行leader角色切换,这个切换的过程会耗费一笔可观的时间,并且在这个时间窗口内这些分区也会变得不可用。
- 分区数越多也会让Kafka的正常启动和关闭的耗时变得越长,与此同时,主题的分区数越多不仅会增加日志清理的耗时,而且在被删除时也会耗费更多的时间。对旧版的生产者和消费者客户端而言,分区数越多,也会增加它们的开销,不过这一点在新版的生产者和消费者客户端中有效地得到了抑制。
- 如何选择合适的分区数?
- 从某种意思来说,考验的是决策者的实战经验,更透彻地说,是对Kafka本身、业务应用、硬件资源、环境配置等多方面的考量而做出的选择。
- 在设定完分区数,或者更确切地说是创建主题之后,还要对其追踪、监控、调优以求更好地利用它。
- 一般情况下,根据预估的吞吐量及是否与key相关的规则来设定分区数即可,后期可以通过增加分区数、增加broker或分区重分配等手段来进行改进。
- 如果一定要给一个准则,则建议将分区数设定为集群中broker的倍数,即假定集群中有3个broker节点,可以设定分区数为3、6、9等,至于倍数的选定可以参考预估的吞吐量。不过,如果集群中的broker节点数有很多,比如大几十或上百、上干,那么这种准则也不太适用,在选定分区数时进一步可以引入基架等参考因素。
