kafka03-生产者
参考文档:https://kafka-python.readthedocs.io/en/master/index.html
1、python中KafkaProducer类
1、KafkaProducer类
class kafka.KafkaProducer(**configs)
- 将记录发布到Kafka集群的Kafka客户端。
- 生产者是线程安全的,跨线程共享一个生产者实例通常比拥有多个实例要快。
- 生产者由一个缓冲空间池和一个后台I/O线程组成,前者保存尚未传输到服务器的记录,后者负责将这些记录转换为请求并将它们传输到集群。
- send()是异步的。当调用它时,它将记录添加到待发送记录的缓冲区中并立即返回。这允许生产者将单个记录批处理在一起以提高效率。
- “acks”配置控制着请求被认为是完整的标准。“all”设置将导致阻塞记录的全部提交,这是最慢但最持久的设置。
- 如果请求失败,生产者可以自动重试,除非' retries '配置为0。启用重试还可能出现重复(有关消息传递语义的详细信息,请参阅文档:https://kafka.apache.org/documentation.html#semantics)。
- 生产者为每个分区维护未发送记录的缓冲区。这些缓冲区的大小由'batch_size'配置指定。使这个值变大会导致更多的批处理,但需要更多的内存(因为我们通常会为每个活动分区使用一个这样的缓冲区)。
- 默认情况下,即使缓冲区中有额外的未使用空间,也可以立即发送缓冲区。
- 如果你想减少请求的数量,你可以将'linger_ms'设置为大于0的值。这将指示生产者在发送请求之前等待该毫秒数,希望有更多的记录到达以填充为同一批。这类似于TCP中的Nagle算法。
- 请注意,即使linger_ms=0,到达时间相近的记录通常也会一起批处理,所以在高负载下,无论linger配置如何,都会发生批处理;然而,如果将这个值设置为大于0的值,那么在没有达到最大负载的情况下,以少量延迟为代价,请求会更少、更高效。
- buffer_memory控制生成器可用于缓冲的内存总量。如果记录发送的速度比传输到服务器的速度快,那么这个缓冲区空间就会被耗尽。当缓冲区空间耗尽时,额外的发送调用将会阻塞。
- key_serializer和value_serializer指示如何将用户提供的键和值对象转换为字节。
下面介绍KafkaProducer类的关键字参数:
1、bootstrap_servers
- 'host[:port]'字符串(或'host[:port]'字符串列表),例如bootstrap_servers='host[:port]'(或['host[:port]','host[:port]','host[:port]'])
- 生产者应该联系它来获取集群的元数据。这并不一定是完整的节点列表(即只需要kefka集群中部分kafka服务器的即可)。它只需要至少有一个响应元数据API请求的代理。默认端口为9092。
- 如果没有指定服务器,则默认为localhost:9092。
- 设置两个以上的broker地址信息,当其中任意一个宕机时,消费者仍然可以连接到Kafka集群上。
2、acks(0, 1, 'all')
- 用来指定分区中必须要有多少个副本收到这条消息,之后生产者才会认为这条消息是成功写入的。acks是生产者客户端中一个非常重要的参数,它涉及消息的可靠性和吞吐量之间的权衡。
- acks参数有3种类型的值:
- 0:生产者发送消息之后不需要等待任何服务端的响应。
- 该消息将立即添加到套接字缓冲区并视为已发送。在这种情况下,不能保证服务器已经收到记录,重试配置不会生效(因为客户端通常不会知道任何失败)。每个记录返回的偏移量将始终设置为 -1。
- 在其他配置环境相同的情况下,acks设置为0可以达到最大的吞吐量。
- 1:生产者发送消息之后,只要分区的leader副本成功写入消息,那么它就会收到来自服务端的成功响应。
- 如果消息无法写入leader副本,比如在leader副本崩溃、重新选举新的leader副本的过程中,那么生产者就会收到一个错误的响应,为了避免消息丢失,生产者可以选择重发消息。
- 如果消息写入leader副本并返回成功响应给生产者,且在被其他follower副本拉取之前leader副本崩溃,那么此时消息还是会丢失,因为新选举的leader副本中并没有这条对应的消息。
- acks设置为1,是消息可靠性和吞吐量之间的折中方案。
- all:生产者在消息发送之后,需要等待ISR中的所有副本都成功写入消息之后才能够收到来自服务端的成功响应。
- 在其他配置环境相同的情况下,acks设置为all可以达到最强的可靠性。但这并不意味着消息就一定可靠,因为ISR中可能只有leader副本,这样就退化成了acks=1的情况。
- 如果未设置,则默认为acks=1。
- 0:生产者发送消息之后不需要等待任何服务端的响应。
3、client_id(str)
- 此客户端的名称。该字符串在每个请求中传递给服务器,并可用于识别与此客户端对应的特定服务器端日志条目。
- 默认值: ‘kafka-python-producer-#’(每个实例附加一个唯一的数字)
4、key_serializer(callable)
- 用于将用户提供的key转换为bytes。如果不是None,称为f(key),应该返回字节。默认值:None。
5、value_serializer(callable)
- 用于将用户提供的消息value转换为bytes。如果不是None,则称为f(value),应该返回字节数。默认值:None。
6、compression_type(str)
- 这个参数用来指定消息的压缩方式。有效值为‘gzip’、‘snappy’、‘lz4’或者None。压缩是对整批数据进行的,所以batching的效果也会影响压缩率(batching越多,压缩效果越好)。
- 默认值:None,即消息不会被压缩。
- 对消息进行压缩可以极大地减少网络传输量、降低网络I/O,从而提高整体的性能。消息压缩是一种使用时间换空间的优化方式,如果对时延有一定的要求,则不推荐对消息进行压缩。
7、retries(int)
- retries参数用来配置生产者重试的次数。(retry_backoff_ms设定两次重试之间的时间间隔)
- 默认值为0,即在发生异常的时候不进行任何重试动作。
- 消息在从生产者发出到成功写入服务器之前可能发生一些临时性的异常,比如网络抖动、leader副本的选举等,这种异常往往是可以自行恢复的,生产者可以通过配置retries大于0的值,以此通过内部重试来恢复而不是一昧地将异常抛给生产者的应用程序。如果重试达到设定的次数,那么生产者就会放弃重试并返回异常。
- 不过,并不是所有的异常都是可以通过重试来解决的,比如消息太大,超过max_request_size参数配置的值。
- Kafka可以保证同一个分区中的消息是有序的。如果生产者按照一定的顺序发送消息,那么这些消息也会顺序地写入分区,进而消费者也可以按照同样的顺序消费它们。对于某些应用来说,顺序性非常重要,比如MySQL的binlog传输,如果出现错误就会造成非常严重的后果。
- 如果将acks参数配置为非零值,并且max_in_flight_requests_per_connection参数配置为大于l的值,那么就会出现错序的现象:如果第一批次消息写入失败,而第二批次消息写入成功,那么生产者会重试发送第一批次的消息,此时如果第一批次的消息写入成功,那么这两个批次的消息就出现了错序。
- 一般而言,在需要保证消息顺序的场合建议把参数max_in_flight_requests_per_connection配置为1,而不是把acks配置为0,不过这样也会影响整体的吞吐。
8、batch_size(int)
- 用于指定ProducerBatch(消息批次)可以复用内存区域的大小。
- 默认值:16384
9、linger_ms(int)
- 发送请求的延迟时间,以便多个消息组成一个消息批次,减少请求数量。
- 生产者将在请求传输之前到达的任何消息组合成消息批次。通常情况下,只有当消息到达的速度比发送的速度快时,才会发生这种情况。然而,在某些情况下,即使在中等负载下,客户端也可能希望减少请求的数量。
- 通过添加少量的人为延迟来实现这一点;也就是说,不是立即发送一条消息,生产者将等待到给定的延迟,以便等待其他消息,可以发送一个消息批次。这可以被认为类似于TCP中的Nagle算法。
- 此参数给出了消息延迟的上限:一旦消息批次的大小到达batch_size值,不管linger_ms怎么设置都将会立即发送,否则将延迟指定的时间以便等待更多的记录。例如,设置linger_ms=5可以减少发送的请求数量,但是在没有负载的情况下,发送记录的延迟会增加5毫秒。
- 默认值:0(即没有延迟,单位毫秒)。
10、partitioner(callable)
- Callable用于确定每个消息被分配到哪个分区。调用(在键序列化之后):partitioner(key_bytes, all_partitions, available_partitions)。
- 默认的分区器实现使用与java客户端相同的murmur2算法,散列每个非None键,以便将具有相同键的消息分配给相同的分区。当键为None时,消息将传递到随机分区(如果可能的话,过滤到只有可用前导符的分区)。
11、buffer_memory(int)
- 生产者客户端中用于缓存消息的缓冲区大小(内存)。
- 如果记录的发送速度比它们可以传递到服务器的速度快,生产者将阻塞最多 max_block_ms,在超时时引发异常。
- 在当前的实现中,这个设置是一个近似值。
- 默认值:33554432(32MB)
12、max_block_ms(int)
- 用来控制KafkaProducer中send()和partitions_for()方法的阻塞毫秒数。这些方法可能因为缓冲区已满或元数据不可用而被阻塞。在用户提供的序列化器或分区器中的阻塞不会被计算到此超时。
- 默认值:60000。
13、max_request_size(int)
- 这个参数用来限制生产者客户端能发送的请求的最大值。这实际上也是对最大消息大小的限制。这个设置将限制生产者在单个请求中发送的消息的数量,以避免发送巨大的请求。
- 默认值为1048576B,即1MB。
- 一般情况下,这个默认值就可以满足大多数的应用场景了。不建议读者盲目地增大这个参数的配置值,尤其是在对Kafka整体脉络没有足够把控的时候。因为这个参数还涉及一些其他参数的联动,比如broker端的message.max.bytes参数,如果配置错误可能会引起一些不必要的异常。
- 比如将broker端的message.max.bytes参数配置为10,而max.request.size参数配置为20,那么当我们发送一条大小为15B的消息时,生产者客户端就抛出异常。
14、metadata_max_age_ms(int)
- 在这段时间(以毫秒为单位)之后,即使任何leader分区都没有发生变化,也会强制刷新元数据,以主动发现任何新的代理(broker)或分区。
- 默认值:300000
15、retry_backoff_ms(int)
- 用来设定两次重试之间的时间间隔,避免无效的频繁重试。
- 默认值:100。
- 在配置retries和retry_backoff_ms之前,最好先估算一下可能的异常恢复时间,这样可以设定总的重试时间大于这个异常恢复时间,以此来避免生产者过早地放弃重试。
16、request_timeout_ms(int)
- 这个参数用来配置Producer等待请求响应的最长时间,以毫秒为单位。
- 默认值:30000。
- 请求超时之后可以选择进行重试。注意这个参数需要比broker端参数replica.lag.time.max.ms的值要大,这样可以减少因客户端重试而引起的消息重复的概率。
17、receive_buffer_bytes(int)
- 这个参数用来设置Socket接收消息缓冲区(SO_RCVBUF)的大小。默认值:None(依赖于系统默认值)。Java客户机默认为32768。
- 如果Producer与Kafka处于不同的机房,则可以适地调大这个参数值。
18、send_buffer_bytes(int)
- 这个参数用来设置Socket发送消息缓冲区(SO_SNDBUF)的大小。默认值:None(依赖于系统默认值)。Java客户机默认为131072。
19、socket_options(list)
- socket.setsockopt的元组参数列表,适用于代理连接套接字。默认值:[(socket.IPPROTO_TCP, socket.TCP_NODELAY, 1)]
20、reconnect_backoff_ms(int)
- 在尝试重新连接到给定主机之前等待的时间量(以毫秒为单位)。
- 默认值:50。
21、reconnect_backoff_max_ms(int)
- 当重新连接到重复连接失败的代理(broker)时,后退/等待的最大时间(以毫秒为单位)。
- 如果提供,每个主机的回退将在每次连续连接失败时呈指数级增加,直到这个最大值。一旦达到最大值,重新连接尝试将以这个固定速率周期性地继续。
- 为了避免连接风暴,将对回退应用0.2的随机因素,从而产生一个介于计算值以下20%和以上20%之间的随机范围。
- 默认值:1000。
22、max_in_flight_requests_per_connection(int)
- 请求通过管道传输到kafka代理(broker),最多达到每个代理连接的最大请求数。请注意,如果此设置设置为大于1,并且发送失败,则存在由于重试(即,如果启用重试)而导致消息重新排序的风险。
- 默认值:5。
23、security_protocol(str)
- 用于与代理(broker)通信的协议。有效值为:PLAINTEXT、SSL、SASL_PLAINTEXT、SASL_SSL。
- 默认值:PLAINTEXT。
24、ssl_context(ssl.SSLContext)
- 用于包装套接字连接的预配置SSLContext。如果提供,所有其他 ssl_* 配置将被忽略。
- 默认值:None。
25、ssl_check_hostname(bool)
- 配置ssl握手是否应验证证书是否与代理(broker)主机名匹配的标志。
- 默认值:true。
26、ssl_cafile(str)
- 可选文件名,在证书验证中使用的ca文件。
- 默认值:None。
27、ssl_certfile(str)
- 可选文件名,包含客户端证书的pem格式文件,以及建立证书真实性所需的任何ca证书。
- 默认值:None。
28、ssl_keyfile(str)
- 可选文件名,包含客户端私钥的文件。
- 默认值:None。
29、ssl_password(str)
- 可选密码,加载证书链时使用的。
- 默认值:None。
30、ssl_crlfile(str)
- 可选文件名,包含用于检查证书过期的CRL。缺省情况下,不进行CRL检查。在提供文件时,仅根据这个CRL检查叶证书。只能使用Python 3.4+或2.7.9+检查CRL。
- 默认值:None。
31、ssl_ciphers(str)
- 可以选择为SSL连接设置可用的密码。它应该是OpenSSL密码列表格式的字符串。如果不能选择密码(因为编译时选项或其他配置禁止使用所有指定的密码),则会引发ssl.SSLError。见ssl.SSLContext.set_ciphers
32、api_version(tuple)
- 指定要使用的Kafka API版本。如果设置为None,客户端将尝试通过探测各种api来推断代理版本。例如(0,10,2)。
- 默认值:None。
33、api_version_auto_timeout_ms(int)
- 在检查代理(broker)API版本时从构造函数抛出超时异常的毫秒数。仅当api_version设置为None时才适用。
34、metric_reporters(list)
- 用作指标报告者的类列表。实现AbstractMetricsReporter接口允许插入将被通知新指标创建的类。
- 默认:[]
35、metrics_num_samples(int)
- 为计算指标而维护的样本数。
- 默认值:2
36、metrics_sample_window_ms(int)
- 用于计算指标的样本的最大时间(以毫秒为单位)。
- 默认值:30000
37、selector(selectors.BaseSelector)
- 提供用于I/O多路复用的特定选择器实现。
- 默认值: selectors.DefaultSelector
38、sasl_mechanism(str)
- 为SASL_PLAINTEXT或SASL_SSL配置security_protocol时的身份验证机制。有效值为:PLAIN、GSSAPI、OAUTHBEARER、SCRAM-SHA-256、SCRAM-SHA-512。
39、sasl_plain_username(str)
- sasl PLAIN和SCRAM身份验证的用户名。如果sasl_mechanism是PLAIN或SCRAM机制之一,则为必需。
40、sasl_plain_password (str)
- sasl PLAIN和SCRAM身份验证的密码。如果sasl_mechanism是PLAIN或SCRAM机制之一,则为必需。
41、sasl_kerberos_service_name(str)
- 要包含在GSSAPI sasl机制握手中的服务名称。
- 默认值:‘kafka’
42、sasl_kerberos_domain_name(str)
- 在GSSAPI sasl机制握手中使用的kerberos域名。
- 默认值:引导服务器之一
42、sasl_oauth_token_provider(AbstractTokenProvider)
- OAuthBearer令牌提供程序实例。(参见 kafka.oauth.abstract)。
- 默认值:None
2、KafkaProducer类的方法
1、bootstrap_connected()
- 如果引导程序已连接,则返回True。
2、close(timeout=None)
- 关闭这个生产者
- timeout(可选,浮点数)等待完成的超时时间,以秒为单位。
3、flush(timeout=None)
- 调用此方法使所有缓冲的记录立即被发送(即使linger_ms大于0)并在与这些记录关联的请求完成时阻塞。flush()的后置条件是任何先前发送的记录都将完成(例如 Future.is_done() == True)。当根据生产者的“acks”配置成功确认请求或导致错误时,请求被认为已完成。
- 当一个线程被阻塞等待刷新调用完成时,其他线程可以继续发送消息;但是,不能保证在flush调用开始后发送的消息是否完成。
- timeout(可选,浮点数)等待完成的超时时间,以秒为单位。
4、metrics(raw=False)
- 获取有关生产者绩效的指标
- 注意:这是一个不稳定的方法。在未来的版本中,它可能会在没有任何警告的情况下发生变化。
- 这是从Java Producer中移植的,详细信息请参见:https://kafka.apache.org/documentation/#producer_monitoring
5、partitions_for(topic)
- 返回主题的所有已知分区的集合。
6、send(topic, value=None, key=None, headers=None, partition=None, timestamp_ms=None)
- 将消息发布到主题。
- topic(str):将发布消息的主题
- value(optional):消息值。必须是bytes类型,或者可以通过配置的value_serializer序列化为bytes。如果value为 None,则需要键并且消息充当“删除”。有关更多详细信息,请参阅 kafka 压缩文档:https://kafka.apache.org/documentation.html#compaction (kafka >= 0.8.1)
- key(optional):与消息关联的键。必须是bytes类型,或者可以通过配置的key_serializer序列化为bytes。可用于确定将消息发送到哪个分区。如果partition为None(并且生产者的partitioner配置保留为默认值),则具有相同key的消息将被传递到相同的partition(但如果key为None,则partition是随机选择的)。
- headers(optional):标题键值对的列表。列表项是str键和bytes值的元组。
- partition(int,optional):可以选择指定一个分区。如果没有设置,将使用配置的“partitioner”选择分区。
- timestamp_ms(int,optional):用作消息时间戳的纪元毫秒(从UTC 1970年1月1日开始)。默认为当前时间。
2、生产者客户端开发
- 一个正常的生产逻辑需要具备以下几个步骤:
- (1)配置生产者客户端参数及创建相应的生产者实例。
- (2)构建待发送的消息。
- (3)发送消息。
- (4)关闭生产者实例。
1、KafkaProducer的简单使用
- bootstrap_servers参数只需要配置部分broker节点的地址即可,不需要配置所有broker节点的地址,因为客户端可以自己发现其他broker节点的地址,具体的参看元数据更新。
示例1:生产者
from kafka import KafkaProducer
producer = KafkaProducer(bootstrap_servers=['192.168.248.128:9092', '192.168.248.131:9092']) #创建一个生产者对象
print(producer.bootstrap_connected()) #判断是否成功连接到了kafka
print(producer.metrics(raw=False)) #获取生产者的绩效
print(producer.partitions_for('topic-name1')) #获取主题所有的分区的集合
producer.send('topic-name1', b'raw_bytes1') #发送消息到主题 #注意,如果后端没有目标这个topic,send会创建该topic
producer.flush() #立即发送缓存区中的所有消息
producer.close() #关闭生产者对象
示例2:消费者
from kafka import KafkaConsumer
consumer = KafkaConsumer('topic-name1', bootstrap_servers=['192.168.248.128:9092', '192.168.248.131:9092'])
for message in consumer:
print("%s:%d:%d: key=%s value=%s" % (message.topic, message.partition, message.offset, message.key, message.value))
2、消息的发送
- 创建生产者实例和构建消息之后,就可以开始发送消息了。发送消息主要有三种模式:发后即忘(fire-and-forget)、同步(sync)及异步(async)。
send(topic, value=None, key=None, headers=None, partition=None, timestamp_ms=None)
- topic(str):将发布消息的主题
- value(optional):消息值。必须是bytes类型,或者可以通过配置的value_serializer序列化为bytes。一般不为空,如果为空则表示特定的消息--墓碑消息。
- key(optional):与消息关联的键。必须是字节类型,或者可以通过配置的key_serializer序列化为字节。可用于确定将消息发送到哪个分区。
- headers(optional):标题键值对的列表。列表项是str键和bytes值的元组。
- partition(int,optional):可以选择指定一个分区。如果没有设置,将使用配置的“partitioner”选择分区。
- timestamp_ms(int,optional):用作消息时间戳的纪元毫秒(从UTC 1970年1月1日开始)。默认为当前时间。
1、发后即忘(fire-and-forget)
- 这种发送方式就是发后即忘,它只管往Kafka中发送消息而并不关心消息是否正确到达。在大多数情况下,这种发送方式没有什么问题,不过在某些时候(比如发生不可重试异常时)会造成消息的丢失。
- 这种发送方式的性能最高, 可靠性也最差。
示例:
from kafka import KafkaProducer
producer = KafkaProducer(bootstrap_servers=['192.168.248.128:9092', '192.168.248.130:9092', '192.168.248.131:9092'])
producer.send('topic-name1', b'raw_bytes1')
producer.send('topic-name2', value=b'topic-name2-value2', key=b'topic-name2-key2')
producer.send('topic-name3', value=b'topic-name3-value2', key=b'topic-name3-key2')
producer.close()
2、同步(sync)
- 要实现同步的发送方式,可以利用返回的Future对象实现
- KafkaProducer.send()方法的返回值是一个Future类型的对象。
- Future表示一个任务的生命周期,并提供了相应的方法来判断任务是否已经完成或取消,以及获取任务的结果和取消任务等。
- send()方法本身就是异步的,send()方法返回的Future对象可以使用get()方法获得发送的结果。
- KafkaProducer中一般会发生两种类型的异常:可重试的异常和不可重试的异常。
- 常见的可重试异常有:NetworkException、LeaderNotAvailableException、UnknownTopicOrParttionException、NotEnoughReplicasException、NotCoordinatorException等。
- NetworkException表示网络异常,这个有可能是由于网络瞬时故障而导致的异常,可以通过重试解决;
- LeaderNotAvailableException表示分区的leader副本不可用,这个异常通常发生在leader副本下线而新的leader副本选举完成之前,重试之后可以重新恢复。
- 不可重试的异常,比如RecordTooLargeException异常,暗示了所发送的消息太大,KafkaProducer对此不会进行任何重试,直接抛出异常。
- 常见的可重试异常有:NetworkException、LeaderNotAvailableException、UnknownTopicOrParttionException、NotEnoughReplicasException、NotCoordinatorException等。
- 对于可重试的异常,如果配置了retries参数,那么只要在规定的重试次数内自行恢复了,就不会抛出异常。否则仍会抛出异常,进而发送的外层逻辑就要处理这些异常了。
- 示例中配置了3次重试。如果重试了3次之后还没有恢复,那么仍会抛出异常,进而发送的外层逻辑就要处理这些异常了。
producer = KafkaProducer(retries=3,bootstrap_servers=['192.168.248.128:9092'])
- 同步发送的方式可靠性高,要么消息被发送成功,要么发生异常。
- 如果发生异常,则可以捕获并进行相应的处理,而不会像“发后即忘”的方式直接造成消息的丢失。
- 不过同步发送的方式的性能会差很多, 需要阻塞等待一条消息发送完之后才能发送下一条。
示例1:
- 在执行send()方法之后直接链式调用了get()方法来阻塞等待Kafka的响应,直到消息发送成功,或者发生异常。如果发生异常,那么就需要捕获异常并交由外层逻辑处理。
from kafka import KafkaProducer
from kafka.errors import KafkaError
producer = KafkaProducer(bootstrap_servers=['192.168.248.128:9092', '192.168.248.130:9092', '192.168.248.131:9092'])
try:
producer.send('topic-name3', b'raw_bytes').get(timeout=10)
except KafkaError:
# log.exception() #将报错信息写入日志
pass
示例2:
- 也可以在执行完send()方法之后不直接调用get()方法。
- 这样可以获取一个RecordMetadata对象(即get()方法返回RecordMetadata对象),在RecordMetadata对象里包含了消息的一些元数据信息,比如当前消息的主题、分区号、分区中的偏移量(offset)、时间戳等。如果在应用代码中需要这些信息,则可以使用这个方式。如果不需要,则直接采用producer.send(record).get()的方式更省事。
from kafka import KafkaProducer
from kafka.errors import KafkaError
producer = KafkaProducer(bootstrap_servers=['192.168.248.128:9092', '192.168.248.130:9092', '192.168.248.131:9092'])
try:
future = producer.send('topic-name3', b'raw_bytes')
record_metadata = future.get(timeout=10)
except KafkaError:
# log.exception()
pass
print(record_metadata)
print('topic:{},partition:{},offset:{}'.format(record_metadata.topic, record_metadata.partition, record_metadata.offset))
<<<
RecordMetadata(topic='topic-name3', partition=0, topic_partition=TopicPartition(topic='topic-name3', partition=0), offset=14, timestamp=1633956120256, log_start_offset=0, checksum=None, serialized_key_size=-1, serialized_value_size=9, serialized_header_size=-1)
topic:topic-name3,partition:0,offset:14
3、异步(async)
- 一般是在send()方法里指定一个Callback的回调函数,Kafka在返回响应时调用该函数来实现异步的发送确认。
- 有读者或许会有疑问,send()方法的返回值类型就是Future,而Future本身就可以用作异步的逻辑处理。这样做不是不行,只不过Future里的get()方法在何时调用,以及怎么调用都是需要面对的问题,消息不停地发送,那么诸多消息对应的Future对象的处理难免会引起代码处理逻辑的混乱。
- 但使用Callback的方式非常简洁明了,Kafka有响应时就会回调,要么发送成功,要么抛出异常。
示例1:send()本身就是异步的
for _ in range(100):
producer.send('my-topic', b'msg')
示例2:使用回调
def on_send_success(record_metadata):
print(record_metadata.topic)
print(record_metadata.partition)
print(record_metadata.offset)
def on_send_error(excp):
log.error('I am an errback', exc_info=excp)
# handle exception
producer.send('my-topic', b'raw_bytes').add_callback(on_send_success).add_errback(on_send_error)
4、close()方法
- 通常,一个KafkaProducer不会只负责发送单条消息,更多的是发送多条消息,在发送完这些消息之后,需要调用KafkaProducer的close()方法来回收资源。
- 无参close()方法会阻塞等待之前所有的发送请求完成后再关闭KafkaProducer。
- 带超时时间timeout的close()方法,只会在等待timeout时间内来完成所有尚未完成的请求处理,然后强行退出。
- 在实际应用中,一般使用的都是无参的close()方法。
示例:
- 发送100条消息后就调用了close()方法来回收所占用的资源。
from kafka import KafkaProducer
producer = KafkaProducer(bootstrap_servers=['192.168.248.128:9092', '192.168.248.130:9092', '192.168.248.131:9092'])
for i in range(100):
str123 = 'raw_bytes' + str(i)
producer.send('topic-name3', str123.encode('utf8'))
producer.close()
2、序列化(serializer)
- 生产者需要用序列化器(Serializer)把对象转换成字节数组才能通过网络发送给Kaflca。
- 消费者需要用反序列化器(Deserializer)把从Kaflca中收到的字节数组转换成相应的对象。
- 生产者使用的序列化器和消费者使用的反序列化器是需要一一对应的。
1、直接序列化
from kafka import KafkaProducer
producer = KafkaProducer(bootstrap_servers=['192.168.248.128:9092', '192.168.248.130:9092', '192.168.248.131:9092'])
producer.send('topic-name3', 'value_serializer'.encode('utf8'), 'key_serializer'.encode('utf8'))
producer.close()
2、使用序列化器
示例1:序列化字符串
from kafka import KafkaProducer
producer = KafkaProducer(value_serializer=lambda m: m.encode('utf8'), key_serializer=lambda m: m.encode('utf8'), bootstrap_servers=['192.168.248.128:9092', '192.168.248.130:9092', '192.168.248.131:9092'])
producer.send('topic-name3', 'value_serializer', 'key_serializer')
producer.close()
示例2:序列化json文本
from kafka import KafkaProducer
import json
producer = KafkaProducer(value_serializer=lambda m: json.dumps(m).encode('utf8'), bootstrap_servers=['192.168.248.128:9092', '192.168.248.130:9092', '192.168.248.131:9092'])
producer.send('topic-name3', {'key': 'value'})
producer.close()
3、分区器(partition)
- 分区器的作用就是为消息分配分区。
- 如果send()中指定了partition字段,就将消息发送到partition所指定的分区。不需要分区器。
- 如果send()中没有指定partition字段,就需要分区器根据key这个字段来计算partition的值。
- 如果key不为null,那么默认的分区器会对key进行哈希(采用MurmurHash2算法,具备高运算性能及低碰撞率),最终根据得到的哈希值来计算分区号,拥有相同key的消息会被写入同一个分区。
- 如果key为null,那么消息将会以轮询的方式发往主题内的各个可用分区。
- 注意:如果key不为null,那么计算得到的分区号会是所有分区中的任意一个;如果key为null,那么计算得到的分区号仅为可用分区中的任意一个,注意两者之间的差别。
- 在不改变主题分区数量的情况下,key与分区之间的映射可以保持不变。不过,一旦主题中增加了分区,那么就难以保证key与分区之间的映射关系了。
1、不使用分区器
- send()中指定partition字段
from kafka import KafkaProducer
producer = KafkaProducer(bootstrap_servers=['192.168.248.128:9092', '192.168.248.130:9092', '192.168.248.131:9092'])
partition1 = producer.send('topic-name1', value=b'topic-name1-value1', key=b'topic-name1-key1', partition=1).get()
partition2 = producer.send('topic-name1', value=b'topic-name1-value2', key=b'topic-name1-key2', partition=2).get()
partition3 = producer.send('topic-name1', value=b'topic-name1-value3', key=b'topic-name1-key3', partition=3).get()
partition4 = producer.send('topic-name1', value=b'topic-name1-value4', key=b'topic-name1-key4', partition=0).get()
print('topic:{},partition:{},offset:{}'.format(partition1.topic, partition1.partition, partition1.offset))
print('topic:{},partition:{},offset:{}'.format(partition2.topic, partition2.partition, partition2.offset))
print('topic:{},partition:{},offset:{}'.format(partition3.topic, partition3.partition, partition3.offset))
print('topic:{},partition:{},offset:{}'.format(partition4.topic, partition4.partition, partition4.offset))
producer.close()
<<<
topic:topic-name1,partition:1,offset:10
topic:topic-name1,partition:2,offset:21
topic:topic-name1,partition:3,offset:13
topic:topic-name1,partition:0,offset:13
2、使用默认分区器
- send()中没有指定partition字段,且在KafkaProducer()中没有指定partitioner
from kafka import KafkaProducer
producer = KafkaProducer(bootstrap_servers=['192.168.248.128:9092', '192.168.248.130:9092', '192.168.248.131:9092'])
partition1 = producer.send('topic-name1', value=b'topic-name1-value1', key=b'topic-name1-key1').get()
partition2 = producer.send('topic-name1', value=b'topic-name1-value2', key=b'topic-name1-key2').get()
partition3 = producer.send('topic-name1', value=b'topic-name1-value3', key=b'topic-name1-key3').get()
partition4 = producer.send('topic-name1', value=b'topic-name1-value4', key=b'topic-name1-key4').get()
print('topic:{},partition:{},offset:{}'.format(partition1.topic, partition1.partition, partition1.offset))
print('topic:{},partition:{},offset:{}'.format(partition2.topic, partition2.partition, partition2.offset))
print('topic:{},partition:{},offset:{}'.format(partition3.topic, partition3.partition, partition3.offset))
print('topic:{},partition:{},offset:{}'.format(partition4.topic, partition4.partition, partition4.offset))
producer.close()
<<<
topic:topic-name1,partition:0,offset:12
topic:topic-name1,partition:2,offset:19
topic:topic-name1,partition:2,offset:20
topic:topic-name1,partition:3,offset:12
3、自定义分区器
- 除了使用Kafka提供的默认分区器进行分区分配,还可以使用自定义的分区器,只需同DefaultPartitioner一样实现Partitioner接口即可。默认的分区器在key为null时不会选择非可用的分区,可以通过自定义的分区器DemoPartitioner来打破这一限制。
- 在KafkaProducer()中指定partitioner参数。
4、拦截器(interceptor)
- 拦截器(Interceptor)是早在Kafka0.10.0.0中就已经引入的一个功能,Kafka一共有两种拦截器:生产者拦截器和消费者拦截器
- 拦截器的作用:
- 生产者拦截器可以在消息发送前做一些准备工作,比如按照某个规则过滤不符合要求的消息、修改消息的内容等。
- 也可以用来在发送回调逻辑前做一些定制化的需求,比如统计类工作。
- 暂时没有找到python中有关于拦截器的内容
3、生产者客户端原理分析
- 本节是按照Java生产者客户端进行描述的。
1、整体架构
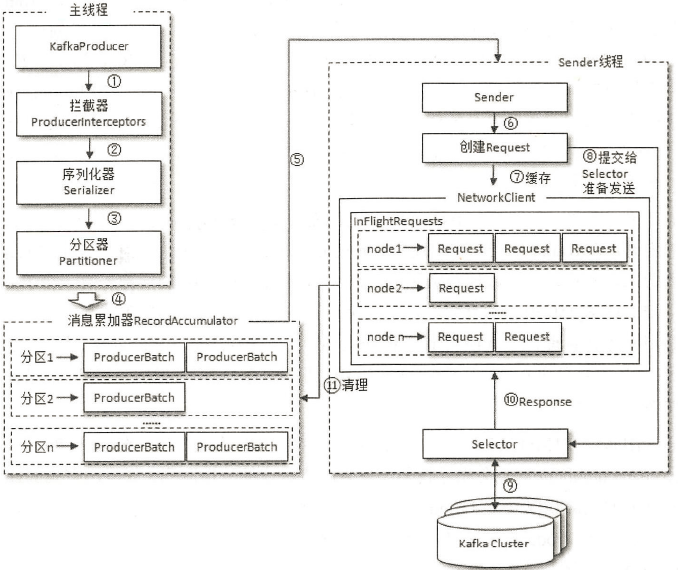
- 整个生产者客户端由两个线程协调运行,这两个线程分别为主线程和Sender线程(发送线程)。
- 在主线程中由KafkaProducer创建消息,然后可能通过拦截器、序列化器和分区器的作用之后缓存到消息累加器(RecordAccumulator,也称为消息收集器)中。
- Sender线程负责从RecordAccumulator中获取消息并将其发送到Kafka中。
1、主线程
- 消息累加器(RecordAccumulator)
- RecordAccumulator主要用来缓存消息以便Sender线程可以批量发送,进而减少网络传输的资源消耗以提升性能。
- RecordAccumulator缓存的大小可以通过生产者客户端参数buffer.memory(python中对应的参数是buffer_memory)配置,默认值为33554432B,即32MB。
- 如果生产者发送消息的速度超过发送到服务器的速度,则会导致生产者RecordAccumulator缓存空间不足,这个时候KafkaProducer的send()方法调用要么被阻塞,要么抛出异常,这个取决于参数max.block.ms(max_block_ms)的配置,此参数的默认值为60000,即60秒。
- 如果生产者客户端需要向很多分区发送消息,可以将buffer.memory(buffer_memory)参数适当调大增加RecordAccumulator的缓存空间,以增大整体的吞吐量。
- 主线程中发送的消息都会追加到RecordAccumulator的某个双端队列(Deque)中,在RecordAccumulator的内部为每个分区都维护了一个双端队列,队列中的内容就是ProducerBatch,即Deque<ProducerBatch>。
- 消息写入缓存时,追加到双端队列的尾部。
- Sender读取消息时,从双端队列的头部读取。
- ProducerBatch和ProducerRecord
- ProducerRecord是生产者中创建的消息。
- ProducerBatch是指一个消息批次。
-
- ProducerBatch可以包含一个或多个ProducerRecord,这样可以使字节的使用更加紧凑。
- 将较小的ProducerRecord拼凑成一个较大的ProducerBatch,也可以减少网络请求的次数以提升整体的吞吐量。
- ProducerBatch和消息的具体格式有关。
- 消息在网络上都是以字节(Byte)的形式传输的,在发送之前需要创建一块内存区域来保存对应的消息。
- 在Kafka生产者客户端中,通过java.io.ByteBuffer实现消息内存的创建和释放。不过频繁的创建和释放是比较耗费资源的,在RecordAccumulator的内部还有一个BufferPool,它主要用来实现ByteBuffer的复用,以实现缓存的高效利用。
- 不过BufferPool只针对特定大小的ByteBuffer进行管理,而其他大小的ByteBuffer不会缓存进BufferPool中,这个特定的大小由batch.size参数来指定,默认值为16384B,即16KB。可以适当地调大batch.size(batch_size)参数以便多缓存一些消息。
- ProducerBatch的大小和batch.size参数也有着密切的关系。
- 当一条消息(ProducerRecord)流入RecordAccumulator时,会先寻找与消息分区所对应的双端队列(如果没有则新建),再从这个双端队列的尾部获取一个ProducerBatch(如果没有则新建),查看ProducerBatch中是否还可以写入这个ProducerRecord,如果可以则写入,如果不可以则需要创建一个新的ProducerBatch。
- 在新建ProducerBatch时评估这条消息的大小是否超过batch.size参数的大小,如果不超过,那么就以batch.size参数的大小来创建ProducerBatch,这样在使用完这段内存区域之后,可以通过BufferPool的管理来进行复用。如果超过,那么就以评估的大小来创建ProducerBatch,这段内存区域不会被复用。
2、Sender线程
- Sender从RecordAccumulator中获取缓存的消息之后,会将原本<分区, Deque<ProducerBatch>>的形式转变成<Node, List<ProducerBatch>的形式,其中Node表示Kafka集群的broker节点。
- 对于网络连接来说,生产者客户端是与具体的broker节点建立的连接,也就是向具体的broker节点发送消息,而并不关心消息属于哪一个分区。
- 而对于KafkaProducer的应用逻辑而言,只关注向哪个分区中发送哪些消息,所以在这里需要做一个应用逻辑层面到网络I/O层面的转换。
- 在转换成<Node, List<ProducerBatch>>的形式之后,Sender还会进一步封装成<Node, Request>的形式,这样就可以将Request请求发往各个Node了,这里的Request是指Kafka的各种协议请求,对于消息发送而言就是指具体的ProduceRequest。
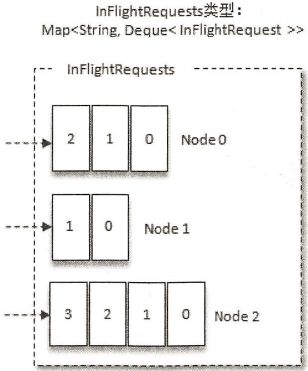
- 请求在从Sender线程发往Kafka之前还会保存到InFlightRequests中,InFlightRequests保存对象的具体形式为Map<NodeId,Deque<Request>>,它的主要作用是缓存已经发出但还没有收到响应的请求(NodeId是一个String类型,表示节点的id编号)。
- 通过配置max.in.flight.requests.per.connection(max_in_flight_requests_per_connection)参数还可以限制每个连接(也就是客户端与Node之间的连接)最多缓存的请求数,默认值为5,即每个连接最多只能缓存5个未响应的请求,超过该数值之后就不能再向这个连接发送更多的请求了,除非有缓存的请求收到了响应(Response)。通过比较Deque<Request>的size与这个参数的大小来判断对应的Node中是否己经堆积了很多未响应的消息,如果真是如此,那么说明这个Node节点负载较大或网络连接有问题,再继续向其发送请求会增大请求超时的可能。
2、元数据的更新
1、LeastLoadedNode
- InFlightRequests还可以获得leastLoadedNode,即所有Node中负载最小的那一个。这里的负载最小是通过每个Node在InFlightRequests中还未确认的请求决定的,未确认的请求越多则认为负载越大。
- 三个节点Node0、Nodel和Node2,很明显Nodel的负载最小。也就是说,Nodel为当前的leastLoadedNode。
- 选择leastLoadedNode发送请求可以使它能够尽快发出,避免因网络拥塞等异常而影响整体的进度。leastLoadedNode的概念可以用于多个应用场合,比如元数据请求、消费者组播协议的交互。
2、元数据
- 元数据是指Kafka集群的元数据,这些元数据具体记录了集群中有哪些主题,这些主题有哪些分区,每个分区的leader副本分配在哪个节点上,follower副本分配在哪些节点上,哪些副本在AR、ISR等集合中,集群中有哪些节点,控制器节点又是哪一个等信息。
- KafkaProducer要将消息追加到指定主题的某个分区所对应的leader副本之前,首先需要知道主题的分区数量,然后经过计算得出(或者直接指定〉目标分区,之后KafkaProducer需要知道目标分区的leader副本所在的broker节点的地址、端口等信息才能建立连接,最终才能将消息发送到Kafka,在这一过程中所需要的信息都属于元数据信息。
- 当要使用的元数据信息在客户端中没有时,比如没有指定的主题信息,或者超过metadata.max.age.ms时间没有更新元数据都会引起元数据的更新操作。客户端参数metadata.max.age.ms的默认值为300000,即5分钟。
- 元数据的更新操作是在客户端内部进行的,对客户端的外部使用者不可见。
- 当需要更新元数据时,会先挑选出leastLoadedNode,然后向这个Node发送MetadataRequest请求来获取具体的元数据信息。
- 这个更新操作是由Sender线程发起的,在创建完MetadataRequest之后同样会存入InFlightRequests,之后的步骤就和发送消息时的类似。
- 元数据虽然由Sender线程负责更新,但是主线程也需要读取这些信息,这里的数据同步通过synchronized和final关键字来保障。
问题
1、下载kafka-python报错
1、问题
D:\test\kafka>pip install kafka-python WARNING: Retrying (Retry(total=4, connect=None, read=None, redirect=None, status=None)) after connection broken by 'ConnectTimeoutEr ror(<pip._vendor.urllib3.connection.HTTPSConnection object at 0x000002D550294130>, 'Connection to pypi.org timed out. (connect timeo ut=15)')': /simple/kafka-python/
2、解决问题
- 这是因为使用默认的pip源速度太慢超时了,可以使用国内的pip源
- 阿里云:http://mirrors.aliyun.com/pypi/simple/
- 中国科技大学:https://pypi.mirrors.ustc.edu.cn/simple/
- 清华大学:https://pypi.tuna.tsinghua.edu.cn/simple/
D:\test\kafka>pip install kafka-python -i https://pypi.tuna.tsinghua.edu.cn/simple/

 浙公网安备 33010602011771号
浙公网安备 33010602011771号