mysql10-查询数据
1、基本查询语句
- 基本语法格式如下:
1 2 3 4 5 6 7 8 | SELECT {* | <字段列表>} [ FROM <表1> [,<表2>...] [WHERE <表达式>] [GROUP BY <字段名>] [HAVING <expression> [{<operator> <expression>}...]] [ORDER BY <字段名>] [LIMIT [<offset>,] <row count>]] |
-
- {* | <字段列表>}:
- 星号通配符表示查询所有的字段。
- 字段列表:表示查询的字段列表,字段列至少包含一个字段。如果要查询多个字段,多个字段之间用逗号隔开,最后一个字段后不要加逗号。
- FROM <表1> [,<表2>...]:表1和表2表示查询数据的来源,可以是单个或者多个表。
- [WHERE <表达式>]:可选项,查询的行必须满足的条件。
- [GROUP BY <字段>]:可选项,告诉MySQL如何显示查询出来的数据,并按照指定的字段分组。
- [ORDER BY <字段>]:可选项,告诉MySQL按什么样的顺序显示查询出来的数据,可以进行的排序有:升序(ASC)、降序(DESC).
- [LIMIT [<offset,] <row count]:告诉MySQL每次显示查询出来的数据条数。
- {* | <字段列表>}:
- 创建示例数据表
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 | --创建颜色表(主表)create table colour( id int primary key auto_increment, colour_str char(15));--创建水果表(从表)create table fruit( id int primary key auto_increment, fruit_str char(15), colourid int, constraint fruit_colour_dep foreign key(colourid) references colour(id));--插入颜色mysql> insert into colour(colour_str) values('red'),('cyan'),('yellow');--插入水果mysql> insert into fruit(fruit_str,colourid) values('apple',1),('mango',3),('pitaya',1),('banana',3),('grapes','2'),('orange',3);mysql> select * from colour;+----+------------+| id | colour_str |+----+------------+| 1 | red || 2 | cyan || 3 | yellow |+----+------------+mysql> select * from fruit;+----+-----------+----------+| id | fruit_str | colourid |+----+-----------+----------+| 1 | apple | 1 || 2 | mango | 3 || 3 | pitaya | 1 || 4 | banana | 3 || 5 | grapes | 2 || 6 | orange | 3 |+----+-----------+----------+ |
2、单表查询
1、查询所有行
- 基本语法格式如下:
1 2 | SELECT * FROM 表名; --在SELECT语句中使用星号(*)通配符查询所有字段SELECT 字段名1,字段名2,...,字段名n FROM 表名; --在SELECT语句中指定要查询的字段。 |
示例:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 | mysql> select * from fruit;+----+-----------+----------+| id | fruit_str | colourid |+----+-----------+----------+| 1 | apple | 1 || 2 | mango | 3 || 3 | pitaya | 1 || 4 | banana | 3 || 5 | grapes | 2 || 6 | orange | 3 |+----+-----------+----------+mysql> select id,fruit_str from fruit;+----+-----------+| id | fruit_str |+----+-----------+| 1 | apple || 2 | mango || 3 | pitaya || 4 | banana || 5 | grapes || 6 | orange |+----+-----------+ |
2、使用where子句查询符合条件的行
- 基本语法格式如下:
1 | SELECT 字段名1,字段名2,...,字段名n FROM 表名 WHERE 查询条件 |
示例:
1 2 3 4 5 6 7 8 | mysql> select id,fruit_str from fruit where id > 3;+----+-----------+| id | fruit_str |+----+-----------+| 4 | banana || 5 | grapes || 6 | orange |+----+-----------+ |
3、带IN关键字的查询
- IN操作符用来查询满足指定范围内的条件的记录。
- 使用IN操作符,将所有检索条件用括号括起来,检索条件之间用逗号分隔开,只要满足条件范围内的任意一个值即为匹配项。
- 可以使用关键字NOT IN来检索不在条件范围内的记录。
示例:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 | mysql> select * from fruit where colourid in (1,2);+----+-----------+----------+| id | fruit_str | colourid |+----+-----------+----------+| 1 | apple | 1 || 3 | pitaya | 1 || 5 | grapes | 2 |+----+-----------+----------+mysql> select * from fruit where colourid not in (1,2);+----+-----------+----------+| id | fruit_str | colourid |+----+-----------+----------+| 2 | mango | 3 || 4 | banana | 3 || 6 | orange | 3 |+----+-----------+----------+ |
4、带BETWEEN AND的范围查询
- BETWEEN AND用来查询某个范围内的值,该操作符需要两个参数,即范围的开始值和结束值,如果字段值在指定的范围内,则返回这些记录。
- NOT BETWEEN AND表示指定范围之外的值,如果字段值不在指定的范围内,则返回这些记录。
示例:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 | mysql> select * from fruit where id between 3 and 5;+----+-----------+----------+| id | fruit_str | colourid |+----+-----------+----------+| 3 | pitaya | 1 || 4 | banana | 3 || 5 | grapes | 2 |+----+-----------+----------+mysql> select * from fruit where id not between 3 and 5;+----+-----------+----------+| id | fruit_str | colourid |+----+-----------+----------+| 1 | apple | 1 || 2 | mango | 3 || 6 | orange | 3 |+----+-----------+----------+ |
5、带LIKE的字符匹配查询
- LIKE有两种通配符有'%'和'_'
- 百分号通配符'%',匹配任意长度的字符,甚至包括零字符
- 下划线通配符'_',一次只能匹配任意一个字符。
示例:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 | mysql> select * from fruit where fruit_str like 'p%';+----+-----------+----------+| id | fruit_str | colourid |+----+-----------+----------+| 3 | pitaya | 1 |+----+-----------+----------+mysql> select * from fruit where fruit_str like '%p%';+----+-----------+----------+| id | fruit_str | colourid |+----+-----------+----------+| 1 | apple | 1 || 3 | pitaya | 1 || 5 | grapes | 2 |+----+-----------+----------+mysql> select * from fruit where fruit_str like '%g_';+----+-----------+----------+| id | fruit_str | colourid |+----+-----------+----------+| 2 | mango | 3 || 6 | orange | 3 |+----+-----------+----------+ |
6、查询空值
- 空值不同于0,也不同于空字符串。空值一般表示数据未知、不适用或将在以后添加数据。
- 在SELECT语句中使用IS NULL子句,可以查询某字段内容为空的记录。
- 与IS NULL相反的是IS NOT NULL,该关键字查找字段不为空的记录。
示例:
1 2 3 4 5 6 7 8 9 10 11 12 13 | mysql> select * from fruit where id is null;mysql> select * from fruit where id is not null;+----+-----------+----------+| id | fruit_str | colourid |+----+-----------+----------+| 1 | apple | 1 || 2 | mango | 3 || 3 | pitaya | 1 || 4 | banana | 3 || 5 | grapes | 2 || 6 | orange | 3 |+----+-----------+----------+ |
7、多条件查询AND和OR
- 在WHERE子句中使用AND操作符,表示只有满足所有条件的记录才会被返回。
- 在WHERE子句中使用OR操作符,表示只要满足其中一个条件的记录即可返回。
- OR操作符和IN操作符可以实现相同的功能。但是使用IN操作符使得检索语句更加简洁明了,并且IN执行的速度要快于OR。更重要的是,使用IN操作符,可以执行更加复杂的嵌套查询。
- OR可以和AND一起使用,但是在使用时要注意两者的优先级,由于AND的优先级高于OR,因此先对AND两边的操作数进行操作,再与OR中的操作数结合。
示例1:and操作符
1 2 3 4 5 6 | mysql> select * from fruit where colourid = 3 and fruit_str like '%a';+----+-----------+----------+| id | fruit_str | colourid |+----+-----------+----------+| 4 | banana | 3 |+----+-----------+----------+ |
示例2:or操作符
1 2 3 4 5 6 7 8 | mysql> select * from fruit where colourid = 1 or colourid =2;+----+-----------+----------+| id | fruit_str | colourid |+----+-----------+----------+| 1 | apple | 1 || 3 | pitaya | 1 || 5 | grapes | 2 |+----+-----------+----------+ |
示例3:and和or
1 2 3 4 5 6 7 8 9 10 | mysql> select * from fruit where fruit_str like '%p%' or fruit_str like '%o%' and colourid = 3;+----+-----------+----------+| id | fruit_str | colourid |+----+-----------+----------+| 1 | apple | 1 || 2 | mango | 3 || 3 | pitaya | 1 || 5 | grapes | 2 || 6 | orange | 3 |+----+-----------+----------+ |
8、查询结果不重复
- DISTINCT关键字应用于所有列,而不仅是它后面的第一个指定列。
- 基本语法格式如下:
- 用DISTINCT关键字指示MysQL消除重复的记录值。
1 | SELECT DISTINCT 字段名 FROM 表名 |
示例:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 | mysql> SELECT colourid FROM fruit;+----------+| colourid |+----------+| 1 || 1 || 2 || 3 || 3 || 3 |+----------+mysql> SELECT DISTINCT colourid FROM fruit;+----------+| colourid |+----------+| 1 || 2 || 3 |+----------+ |
9、对查询结果排序
- MySQL可以通过在SELECT语句中使用ORDER BY子句,对查询的结果进行排序。
- ASC:升序排序,默认
- DESC:降序排序
- 对多列进行排序,须将需要排序的列之间用逗号隔开。
- 在对多列进行排序的时候,首先排序的第一列必须有相同的列值,才会对第二列进行排序如果第一列数据中所有值都是唯一的,将不再对第二列进行排序。
- LIMIT必须位于ORDER BY之后,ORDER BY必须位于FROM之后。
- 基本语法格式如下:
- ASC或DESC可以在每个字段名后面都使用,即可以多次使用,但每个都只作用于自己的字段。
1 | SELECT 字段名1,字段名2,...,字段名n FROM table_name ORDER BY 字段名1 [,字段名2 [,...字段名n]]; |
示例:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 | mysql> select * from fruit order by colourid DESC;+----+-----------+----------+| id | fruit_str | colourid |+----+-----------+----------+| 2 | mango | 3 || 4 | banana | 3 || 6 | orange | 3 || 5 | grapes | 2 || 1 | apple | 1 || 3 | pitaya | 1 |+----+-----------+----------+mysql> select * from fruit order by colourid DESC,fruit_str; --注意,DESC位于要排序的字段后面,而不是最后。表示colourid用降序,fruit_str用升序+----+-----------+----------+| id | fruit_str | colourid |+----+-----------+----------+| 4 | banana | 3 || 2 | mango | 3 || 6 | orange | 3 || 5 | grapes | 2 || 1 | apple | 1 || 3 | pitaya | 1 |+----+-----------+----------+ |
10、分组查询
- 分组查询是对数据按照某个或多个字段进行分组,MySQL中使用GROUP BY关键字对数据进行分组。
- 基本语法格式如下:
1 | [GROUP BY 字段名] [HAVING <条件表达式>] |
-
- 字段名:按照此列的值进行分组。字段值相同的就分成一组。
- "HAVING <条件表达式>":显示满足限定条件的结果。
1、创建分组
- GROUP BY关键字通常和集合函数一起使用,例如: MAX()、MIN()、COUNT()、SUM()、AVG()
- MySQL中可以在GROUP BY中使用GROUP_CONCAT()函数,将每个分组中各个字段值显示出来。
示例:
1 2 3 4 5 6 7 8 | mysql> select *,count(colourid),group_concat(fruit_str) from fruit group by colourid;+----+-----------+----------+-----------------+-------------------------+| id | fruit_str | colourid | count(colourid) | group_concat(fruit_str) |+----+-----------+----------+-----------------+-------------------------+| 1 | apple | 1 | 2 | apple,pitaya || 5 | grapes | 2 | 1 | grapes || 2 | mango | 3 | 3 | mango,banana,orange |+----+-----------+----------+-----------------+-------------------------+ |
2、使用HAVING过滤分组
- GROUP BY可以和HAVING一起限定显示记录所需满足的条件,只有满足条件的分组才会被显示。
- HAVING和WHERE的区别?
- HAVING和WHERE都是用来过滤数据。
- HAVING在分组之后进行过滤来选择分组。
- WHERE在分组之前用来选择记录,并且WHERE排除的记录不再包括在分组中。
示例:
1 2 3 4 5 6 7 | mysql> select *,count(colourid),group_concat(fruit_str) from fruit group by colourid having count(colourid) >= 2;+----+-----------+----------+-----------------+-------------------------+| id | fruit_str | colourid | count(colourid) | group_concat(fruit_str) |+----+-----------+----------+-----------------+-------------------------+| 1 | apple | 1 | 2 | apple,pitaya || 2 | mango | 3 | 3 | mango,banana,orange |+----+-----------+----------+-----------------+-------------------------+ |
3、在GROUP BY子句中用WITH ROLLUP
- 使用WITH ROLLUP关键字之后,在所有查询出的分组记录之后增加一条记录,该记录计算查询出的所有记录的总和,即统计记录数量。
- ORDER BY可以和GROUP BY一起使用
- 当使用ROLLUP时,不能同时使用ORDER BY子句进行结果排序。即ROLLUP和ORDERBY是互相排斥的目非斥的
示例:
1 2 3 4 5 6 7 8 9 | mysql> select *,count(colourid),group_concat(fruit_str) from fruit group by colourid with rollup;+----+-----------+----------+-----------------+-----------------------------------------+| id | fruit_str | colourid | count(colourid) | group_concat(fruit_str) |+----+-----------+----------+-----------------+-----------------------------------------+| 1 | apple | 1 | 2 | apple,pitaya || 5 | grapes | 2 | 1 | grapes || 2 | mango | 3 | 3 | mango,banana,orange || 2 | mango | NULL | 6 | apple,pitaya,grapes,mango,banana,orange |+----+-----------+----------+-----------------+-----------------------------------------+ |
4、多字段分组
- 使用GROUP BY可以对多个字段进行分组, GROUP BY关键字后面跟需要分组的多个字段,MySQL根据多字段的值来进行层次分组,分组层次从左到右,即先按第1个字段分组,然后,在第1个字段值相同的记录中,再根据第2个字段的值进行分组,依次类推。
示例:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 | mysql> insert into fruit(fruit_str,colourid) values('orange',3);mysql> select * from fruit;+----+-----------+----------+| id | fruit_str | colourid |+----+-----------+----------+| 1 | apple | 1 || 2 | mango | 3 || 3 | pitaya | 1 || 4 | banana | 3 || 5 | grapes | 2 || 6 | orange | 3 || 7 | orange | 3 |+----+-----------+----------+mysql> select *,count(colourid),group_concat(fruit_str) from fruit group by colourid,fruit_str;+----+-----------+----------+-----------------+-------------------------+| id | fruit_str | colourid | count(colourid) | group_concat(fruit_str) |+----+-----------+----------+-----------------+-------------------------+| 1 | apple | 1 | 1 | apple || 3 | pitaya | 1 | 1 | pitaya || 5 | grapes | 2 | 1 | grapes || 4 | banana | 3 | 1 | banana || 2 | mango | 3 | 1 | mango || 6 | orange | 3 | 2 | orange,orange |+----+-----------+----------+-----------------+-------------------------+ |
11、使用LIMIT限制查询结果的数量
- LIMIT必须位于ORDER BY之后,ORDER BY必须位于FROM之后。
- 基本语法格式如下:
1 | LIMIT [位置偏移量,] 行数 |
-
- 第一个“位置偏移量”参数:可选参数,表示从哪一行开始显示。不指定“位置偏移量”,将会从表中的第一条记录开始(第一条记录的位置偏移量是0,第二条记录的位置偏移量是1...依次类推)
- 第二个参数“行数”指示返回的记录条数。
- MySQL5.7中可以使用"LIMIT 4 OFFSET 3",意思是获取从第5条记录开始后面的3条记录,和"LIMIT 4,3;"返回的结果相同。
3、连接查询
- 连接是关系数据库模型的主要特点。
- 连接查询是关系数据库中最主要的查询,主要包括内连接、外连接和复合条件连接查询。
- 通过连接运算符可以实现多个表查询。
- 在关系数据库管理系统中,表建立时各数据之间的关系不必确定,常把一个实体的所有信息存放在一个表中。当查询数据时,通过连接操作查询出存放在多个表中的不同实体的信息。当两个或多个表中存在相同意义的字段时,便可以通过这些字段对不同的表进行连接查询。
1、where联合查询
- 基本语法格式如下:
1 | SELECT 字段名1,字段名2,...,字段名n FROM 表名1,表名2,...,表名n WHERE 查询条件; |
示例1:
1 2 3 4 5 6 7 8 9 10 11 12 | mysql> select fruit.id,fruit_str,colour_str from colour,fruit where colourid = colour.id;+----+-----------+------------+| id | fruit_str | colour_str |+----+-----------+------------+| 1 | apple | red || 2 | mango | yellow || 3 | pitaya | red || 4 | banana | yellow || 5 | grapes | cyan || 6 | orange | yellow || 7 | orange | yellow |+----+-----------+------------+ |
2、内连接查询
- 内连接(INNER JOIN)使用比较运算符进行表间某(些)列数据的比较操作,并列出这些表中与连接条件相匹配的数据行,组合成新记录。也就是说,在内连接查询中,只有满足条件的记录才能出现在结果关系中。
- INNER JOIN指定两个表之间的关系,使用ON子句给出连接条件,而不是WHERE。ON和WHERE后面指定的条件相同。
- 如果在一个连接查询中,涉及的两个表都是同一个表,这种查询称为自连接查询。自连接种特殊的内连接,它是指相互连接的表在物理上为同一张表,但可以在逻辑上分为两张表。
- 使用WHERE子句定义连接条件比较简单明了,而INNER JOIN语法是ANSI SQL的标准规范,使用INNER JOIN连接语法能够确保不会忘记连接条件,而且,WHERE子句在某些时候会影响查询的性能。
- INNER JOIN(内连接):只返回两个表中连接字段相等的行。
- 内连接查询,基本语法格式如下:
1 | SELECT 字段名1,字段名2,...,字段名n FROM 表名1 INNER JOIN 表名2 ON 查询条件; |
- INNER JOIN连接多个表,基本语法格式如下:
1 2 3 4 5 6 7 8 9 10 11 | --INNER JOIN 连接两个数据表的用法:SELECT * FROM 表1 INNER JOIN 表2 ON 表1.字段号=表2.字段号;--INNER JOIN 连接三个数据表的用法:SELECT * FROM (表1 INNER JOIN 表2 ON 表1.字段号=表2.字段号) INNER JOIN 表3 ON 表1.字段号=表3.字段号;--INNER JOIN 连接四个数据表的用法:SELECT * FROM ((表1 INNER JOIN 表2 ON 表1.字段号=表2.字段号) INNER JOIN 表3 ON 表1.字段号=表3.字段号) INNER JOIN 表4 ON Member.字段号=表4.字段号;--INNER JOIN 连接五个数据表的用法:SELECT * FROM (((表1 INNER JOIN 表2 ON 表1.字段号=表2.字段号) INNER JOIN 表3 ON 表1.字段号=表3.字段号) INNER JOIN 表4 ON Member.字段号=表4.字段号) INNER JOIN 表5 ON Member.字段号=表5.字段号; |
示例:内连接查询
1 2 3 4 5 6 7 8 9 10 11 12 | mysql> select fruit.id,fruit_str,colour_str from colour inner join fruit on colourid = colour.id;+----+-----------+------------+| id | fruit_str | colour_str |+----+-----------+------------+| 1 | apple | red || 2 | mango | yellow || 3 | pitaya | red || 4 | banana | yellow || 5 | grapes | cyan || 6 | orange | yellow || 7 | orange | yellow |+----+-----------+------------+ |
3、外连接查询
- 外连接有两种:左连接和右连接。
- LEFT JOIN(左连接): 返回包括左表中的所有记录和右表中连接字段相等的记录。如果左表的某行在右表中没有匹配行,右表将返回空值。
- RIGHT JOIN(右连接):返回包括右表中的所有记录和左表中连接字段相等的记录。如果右表的某行在左表中没有匹配行,左表将返回空值。
- 基本语法格式如下:
1 2 | SELECT 字段名1,字段名2,...,字段名n FROM 表名1 LEFT JOIN 表名2 ON 查询条件;SELECT 字段名1,字段名2,...,字段名n FROM 表名1 RIGHT JOIN 表名2 ON 查询条件; |
示例1:左连接
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 | mysql> select * from colour left join fruit on colourid = colour.id;+----+------------+------+-----------+----------+| id | colour_str | id | fruit_str | colourid |+----+------------+------+-----------+----------+| 1 | red | 1 | apple | 1 || 1 | red | 3 | pitaya | 1 || 2 | cyan | 5 | grapes | 2 || 3 | yellow | 2 | mango | 3 || 3 | yellow | 4 | banana | 3 || 3 | yellow | 6 | orange | 3 || 3 | yellow | 7 | orange | 3 || 4 | black | NULL | NULL | NULL |+----+------------+------+-----------+----------+mysql> select * from fruit left join colour on colourid = colour.id;+----+-----------+----------+------+------------+| id | fruit_str | colourid | id | colour_str |+----+-----------+----------+------+------------+| 1 | apple | 1 | 1 | red || 2 | mango | 3 | 3 | yellow || 3 | pitaya | 1 | 1 | red || 4 | banana | 3 | 3 | yellow || 5 | grapes | 2 | 2 | cyan || 6 | orange | 3 | 3 | yellow || 7 | orange | 3 | 3 | yellow |+----+-----------+----------+------+------------+ |
示例2:右链接
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 | mysql> select * from fruit right join colour on colourid = colour.id;+------+-----------+----------+----+------------+| id | fruit_str | colourid | id | colour_str |+------+-----------+----------+----+------------+| 1 | apple | 1 | 1 | red || 3 | pitaya | 1 | 1 | red || 5 | grapes | 2 | 2 | cyan || 2 | mango | 3 | 3 | yellow || 4 | banana | 3 | 3 | yellow || 6 | orange | 3 | 3 | yellow || 7 | orange | 3 | 3 | yellow || NULL | NULL | NULL | 4 | black |+------+-----------+----------+----+------------+mysql> select * from colour right join fruit on colourid = colour.id;+------+------------+----+-----------+----------+| id | colour_str | id | fruit_str | colourid |+------+------------+----+-----------+----------+| 1 | red | 1 | apple | 1 || 3 | yellow | 2 | mango | 3 || 1 | red | 3 | pitaya | 1 || 3 | yellow | 4 | banana | 3 || 2 | cyan | 5 | grapes | 2 || 3 | yellow | 6 | orange | 3 || 3 | yellow | 7 | orange | 3 |+------+------------+----+-----------+----------+ |
4、使用聚合函数查询
- MySQL聚合函数
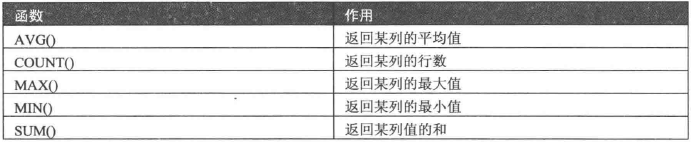
1、COUNT()函数
- COUNT()函数统计数据表中包含的记录行的总数,或者根据查询结果返回列中包含的数据行数。
- 有两种使用方法:
- COUNT(*)计算表中总的行数,不管某列有数值或者为空值。
- COUNT(字段名)计算指定列下总的行数,计算时将忽略空值的行。
- COUNT()函数与GROUP BY关键字一起使用,用来计算不同分组中的记录总数。
示例1:
1 2 3 4 5 6 7 8 9 10 11 12 13 | mysql> select count(*) from fruit ;+----------+| count(*) |+----------+| 7 |+----------+mysql> select count(id) from fruit ;+-----------+| count(id) |+-----------+| 7 |+-----------+ |
示例2:
1 2 3 4 5 6 7 8 | mysql> select colourid,count(id) from fruit group by colourid;+----------+-----------+| colourid | count(id) |+----------+-----------+| 1 | 2 || 2 | 1 || 3 | 4 |+----------+-----------+ |
2、SUM()函数
- SUM()是一个求总和的函数,返回指定列值的总和。
- SUM()函数在计算时,忽略列值为NULL的行。
- SUM()可以与GROUP BY一起使用,计算每个分组的总和。
示例1:
1 2 3 4 5 6 | mysql> select sum(id),sum(colourid) from fruit;+---------+---------------+| sum(id) | sum(colourid) |+---------+---------------+| 28 | 16 |+---------+---------------+ |
示例2:
1 2 3 4 5 6 7 8 | mysql> select sum(id),sum(colourid) from fruit group by colourid;+---------+---------------+| sum(id) | sum(colourid) |+---------+---------------+| 4 | 2 || 5 | 2 || 19 | 12 |+---------+---------------+ |
3、AVG()函数
- AVG()函数通过计算返回的行数和每一行数据的和,求得指定列数据的平均值。
- AVG()可以与GROUP BY一起使用,来计算每个分组的平均值。
示例1:
1 2 3 4 5 6 | mysql> select avg(id),count(colourid) from fruit;+---------+-----------------+| avg(id) | count(colourid) |+---------+-----------------+| 4.0000 | 7 |+---------+-----------------+ |
示例2:
1 2 3 4 5 6 7 8 | mysql> select avg(id),count(colourid) from fruit group by colourid;+---------+-----------------+| avg(id) | count(colourid) |+---------+-----------------+| 2.0000 | 2 || 5.0000 | 1 || 4.7500 | 4 |+---------+-----------------+ |
4、MAX()函数
- MAX()返回指定列中的最大值。
- MAX()函数不仅适用于查找数值类型,也可应用于字符类型。
- MAX()可以和GROUP BY关键字一起使用,求每个分组中的最大值。
- MAX()函数除了用来找出最大的列值或日期值之外,还可以返回任意列中的最大值,包括返回字符类型的最大值。在对字符类型数据进行比较时,按照字符的ASCII码值大小进行比较,在a-z中,a最小z最大。在比较时,先比较第一个字母,如果相等,继续比较下一个字符,一直到两个字符不相等或者字符结束为止。
示例1:
1 2 3 4 5 6 | mysql> select max(id),max(colourid),max(fruit_str) from fruit;+---------+---------------+----------------+| max(id) | max(colourid) | max(fruit_str) |+---------+---------------+----------------+| 7 | 3 | pitaya |+---------+---------------+----------------+ |
示例2:
1 2 3 4 5 6 7 8 | mysql> select max(id),max(colourid),max(fruit_str) from fruit group by colourid;+---------+---------------+----------------+| max(id) | max(colourid) | max(fruit_str) |+---------+---------------+----------------+| 3 | 1 | pitaya || 5 | 2 | grapes || 7 | 3 | orange |+---------+---------------+----------------+ |
5、MIN()函数
- MIN()返回查询列中的最小值
- MIN()函数与MAX()函数类似,不仅适用于查找数值类型,也可应用于字符类型。
- MIN()可以和GROUP BY关键字一起使用,求出每个分组中的最小值
示例1:
1 2 3 4 5 6 | mysql> select min(id),min(colourid),min(fruit_str) from fruit;+---------+---------------+----------------+| min(id) | min(colourid) | min(fruit_str) |+---------+---------------+----------------+| 1 | 1 | apple |+---------+---------------+----------------+ |
示例2:
1 2 3 4 5 6 7 8 | mysql> select min(id),min(colourid),min(fruit_str) from fruit group by colourid;+---------+---------------+----------------+| min(id) | min(colourid) | min(fruit_str) |+---------+---------------+----------------+| 1 | 1 | apple || 5 | 2 | grapes || 2 | 3 | banana |+---------+---------------+----------------+ |
5、子查询
- 子查询指一个查询语句嵌套在另一个查询语句内部的查询。在SELECT子句中先计算子查询,子查询结果作为外层另一个查询的过滤条件,查询可以基于一个表或者多个表。
- 子查询可以添加到SELECT,UPDATE和DELETE语句中,而且可以进行多层嵌套。
- 子查询中常用的操作符有ANY(SOME)、ALL、IN、EXISTS。
- 子查询中可以使用比较运算符,如"="、"<"、"<="、">"、">="和"!="等。
1、带ANY,SOME关键字的子查询
- ANY和SOME关键字是同义词,表示满足其中任一条件。创建一个表达式对子查询的返回值列表进行比较,只要内层子查询的返回值中的任意一个值满足条件,就返回一行记录作为外层查询的结果。
- ANY关键字接在一个比较操作符的后面,表示若与子查询返回的任意值比较为TRUE,则返回TRUE。
示例:
1 2 3 4 5 6 7 8 9 | mysql> select * from fruit where id > any(select id from colour where id > 2); --大于任意一个子查询结果的值即可+----+-----------+----------+| id | fruit_str | colourid |+----+-----------+----------+| 4 | banana | 3 || 5 | grapes | 2 || 6 | orange | 3 || 7 | orange | 3 |+----+-----------+----------+ |
2、带ALL关键字的子查询
- ALL关键字与ANY和SOME不同,使用ALL时需要同时满足所有内层查询的条件。
- ALL关键字接在一个比较操作符的后面,表示与子查询返回的所有值比较为TRUE,则返回TRUE。
示例:
1 2 3 4 5 6 7 8 | mysql> select * from fruit where id > all(select id from colour where id >2) ;+----+-----------+----------+| id | fruit_str | colourid |+----+-----------+----------+| 5 | grapes | 2 || 6 | orange | 3 || 7 | orange | 3 |+----+-----------+----------+ |
3、带EXISTS关键字的子查询
- EXISTS关键字后面的参数是一个任意的子查询,系统对子查询进行运算以判断它是否返回行。
- 如果至少返回一行,那么EXISTS的结果为true,此时外层查询语句将进行查询;
- 如果子查询没有返回任何行,那么EXISTS返回的结果是false,此时外层语句将不进行查询。
- NOT EXISTS与EXISTS使用方法相同,返回的结果相反。
- 如果子查询至少返回一行,那,么NOT EXISTS的结果为false,此时外层查询语句将不进行查询;
- 如果子查询没有返回任何行,那么NOT EXISTS返回的结果是true,此时外层语句将进行查询。
- EXISTS和NOT EXISTS的结果只取决于是否会返回行,而不取决于这些行的内容,所以这个子查询输入列表通常是无关紧要的。
示例1:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 | mysql> select * from fruit where exists (select id from colour where id >4) ;Empty set (0.00 sec)mysql> select * from fruit where exists (select id from colour where id >3) ;+----+-----------+----------+| id | fruit_str | colourid |+----+-----------+----------+| 1 | apple | 1 || 2 | mango | 3 || 3 | pitaya | 1 || 4 | banana | 3 || 5 | grapes | 2 || 6 | orange | 3 || 7 | orange | 3 |+----+-----------+----------+ |
- EXISTS关键字可以和条件表达式一起使用。
示例2:
1 2 3 4 5 6 7 8 9 10 11 | mysql> select * from fruit where fruit_str like '%p%' and exists (select id from colour where id >4) ;Empty set (0.00 sec)mysql> select * from fruit where fruit_str like '%p%' and exists (select id from colour where id >3) ;+----+-----------+----------+| id | fruit_str | colourid |+----+-----------+----------+| 1 | apple | 1 || 3 | pitaya | 1 || 5 | grapes | 2 |+----+-----------+----------+ |
4、带IN关键字的子查询
- IN关键字进行子查询时,内层查询语句仅仅返回一个数据列,这个数据列里的值将提供给外层查询语句进行比较操作。
- NOT IN关键字,其作用与IN正好相反。
示例:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 | mysql> select * from fruit where colourid in (select id from colour where id > 1);+----+-----------+----------+| id | fruit_str | colourid |+----+-----------+----------+| 2 | mango | 3 || 4 | banana | 3 || 5 | grapes | 2 || 6 | orange | 3 || 7 | orange | 3 |+----+-----------+----------+mysql> select * from fruit where colourid not in (select id from colour where id > 1);+----+-----------+----------+| id | fruit_str | colourid |+----+-----------+----------+| 1 | apple | 1 || 3 | pitaya | 1 |+----+-----------+----------+ |
5、带比较运算符的子查询
- 子查询时还可以使用其他的比较运算符,如"="、"<"、"<="、">"、">="和"!="等。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 | mysql> select * from fruit where colourid > (select id from colour where id < 2);+----+-----------+----------+| id | fruit_str | colourid |+----+-----------+----------+| 2 | mango | 3 || 4 | banana | 3 || 5 | grapes | 2 || 6 | orange | 3 || 7 | orange | 3 |+----+-----------+----------+mysql> select * from fruit where colourid = (select id from colour where id < 2);+----+-----------+----------+| id | fruit_str | colourid |+----+-----------+----------+| 1 | apple | 1 || 3 | pitaya | 1 |+----+-----------+----------+ |
6、使用正则表达式查询(REGEXP)
- 正则匹配时,只要能匹配到子串即可,不用匹配字符串的全部。
- 正则表达式常用字符匹配列表
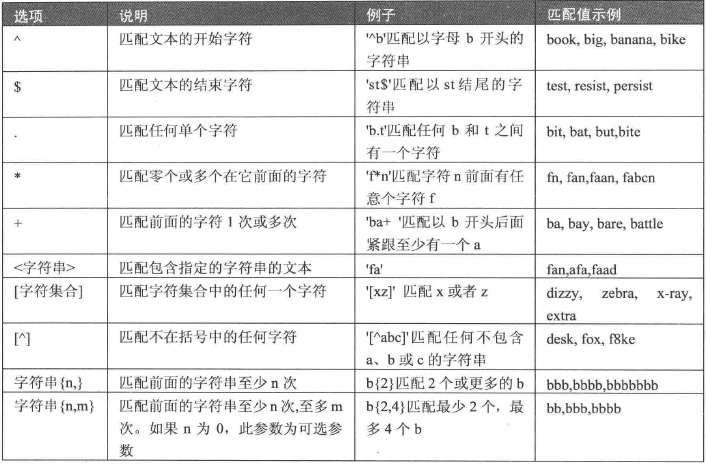
-
- ^:匹配以特定字符或者字符串开头的文本。
- $:匹配以特定字符或者字符串结尾的文本。
-
- .:匹配任意一个字符。除"\n"外,要匹配包括'\n'在内的任意字符,可以使用'[.\n]'。
- []:字符集合,匹配其中的任意一个字符。例如,'[abc]' 可以匹配 "plain" 中的 'a'。
- [^]:匹配不在指定集合中的任何字符。例如, '[^abc]' 可以匹配 "plain" 中的'p'。
- <字符串>:匹配包含指定的字符串的文本
- p1|p2|p3:匹配p1或p2或p3。
-
- +:前面的字符出现一次或多次。
- *:前面的字符出现零次或多次。
- {n}:前面的字符出现n次。
- {n,m}:前面的字符至少出现n次,最多出现m次。
示例:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 | mysql> select * from fruit where fruit_str regexp '^a';+----+-----------+----------+| id | fruit_str | colourid |+----+-----------+----------+| 1 | apple | 1 |+----+-----------+----------+mysql> select * from fruit where fruit_str regexp 'a$';+----+-----------+----------+| id | fruit_str | colourid |+----+-----------+----------+| 3 | pitaya | 1 || 4 | banana | 3 |+----+-----------+----------+mysql> select * from fruit where fruit_str regexp 'an';+----+-----------+----------+| id | fruit_str | colourid |+----+-----------+----------+| 2 | mango | 3 || 4 | banana | 3 || 6 | orange | 3 || 7 | orange | 3 |+----+-----------+----------+ |
7、合并查询结果
- UNION关键字,可以将多个SELECT语句的结果进行合并。
- 合并时,两个表对应的列数和数据类型必须相同。
- 各个SELECT语句之间使用UNION或UNION ALL关键字分隔。
- UNION:删除重复的记录,所有返回的行都是唯一的。
- UNION ALL:不删除重复行也不对结果进行自动排序。
- 基本语法格式如下:
1 2 3 | SELECT column,... FROM table1UNION [ALL]SELECT column,... FROM table2 |
示例:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 | mysql> SELECT id,colour_str FROM colour UNION ALL SELECT id,fruit_str FROM fruit;+----+------------+| id | colour_str |+----+------------+| 1 | red || 2 | cyan || 3 | yellow || 4 | black || 1 | apple || 2 | mango || 3 | pitaya || 4 | banana || 5 | grapes || 6 | orange || 7 | orange |+----+------------+ |
8、为表和字段取别名
- 表别名只在执行查询的时候使用,并不在返回结果中显示。列别名定义之后,将返回给客户端显示,显示的结果字段为字段列的别名。
1、为表取别名
- 当表名字很长或者执行一些特殊查询时,为了方便操作或者需要多次使用相同的表时,可以为表指定别名,用这个别名替代表原来的名称。
- 在为表取别名时,要保证不能与数据库中的其他表的名称冲突。
- 基本语法格式如下:
1 | 表名 [AS] 表别名 |
-
- “表名”为数据库中存储的数据表的名称,
- “表别名”为查询时指定的表的新名称,AS关键字为可选参数。
2、为字段取别名
- 在使用SELECT语句显示查询结果时,MysQL会显示每个SELECT后面指定的输出列,在有些情况下,显示的列的名称会很长或者名称不够直观,MySQL可以指定列别名,替换字段或表达式。
- 也可以为SELECT子句中的计算字段取别名。
- 基本语法格式如下:
1 | 列名 [AS] 列别名 |
-
- “列名”为表中字段定义的名称。
- “列别名”为字段新的名称,AS关键字为可选参数。
示例:
1 2 3 4 5 6 7 8 | mysql> select colourid,count(id) as cuont_id from fruit group by colourid;+----------+----------+| colourid | cuont_id |+----------+----------+| 1 | 2 || 2 | 1 || 3 | 4 |+----------+----------+ |
9、SQL语句执行顺序
1、sql语句定义的顺序
1 2 3 4 5 6 7 8 9 10 | (1)SELECT (2)DISTINCT <select_list>(3)FROM <left_table>(4)<join_type> JOIN <right_table>(5) ON <join_condition>(6)WHERE <where_condition>(7)GROUP BY <group_by_list>(8)WITH {CUBE | ROLLUP}(9)HAVING <having_condition>(10)ORDER BY <order_by_list>(11)LIMIT <limit_number> |
2、SQL语句执行顺序
1 2 3 4 5 6 7 8 9 10 | (8)SELECT (9)DISTINCT <select_list>(1)FROM <left_table>(2)<join_type> JOIN <right_table>(3) ON <join_condition>(4)WHERE <where_condition>(5)GROUP BY <group_by_list>(6)WITH {CUBE | ROLLUP}(7)HAVING <having_condition>(10)ORDER BY <order_by_list>(11)LIMIT <limit_number> |
- (1)FROM:对FROM子句中的左表<left_table>和右表<right_table>执行笛卡儿积,产生虚拟表VT1;
- (2)ON:对虚拟表VT1进行ON筛选,只有那些符合<join_condition>的行才被插入虚拟表VT2;
- (3)JOIN:如果指定了OUTER JOIN(如LEFT OUTER JOIN、RIGHT OUTER JOIN),那么保留表中未匹配的行作为外部行添加到虚拟表VT2,产生虚拟表VT3。如果FROM子句包含两个以上的表,则对上一个连接生成的结果表VT3和下一个表重复执行步骤1~步骤3,直到处理完所有的表;
- (4)WHERE:对虚拟表VT3应用WHERE过滤条件,只有符合<where_condition>的记录才会被插入虚拟表VT4;
- (5)GROUP By:根据GROUP BY子句中的列,对VT4中的记录进行分组操作,产生VT5;
- (6)with:对VT5进行CUBE或ROLLUP操作,产生表VT6;
- (7)HAVING:对虚拟表VT6应用HAVING过滤器,只有符合<having_condition>的记录才会被插入到VT7;
- (8)SELECT:第二次执行SELECT操作,选择指定的列,插入到虚拟表VT8中;
- (9)DISTINCT:去除重复,产生虚拟表VT9;
- (10)ORDER BY:将虚拟表VT9中的记录按照<order_by_list>进行排序操作,产生虚拟表VT10;
- (11)LIMIT:取出指定街行的记录,产生虚拟表VT11,并返回给查询用户
3、SQL语句执行顺序图解
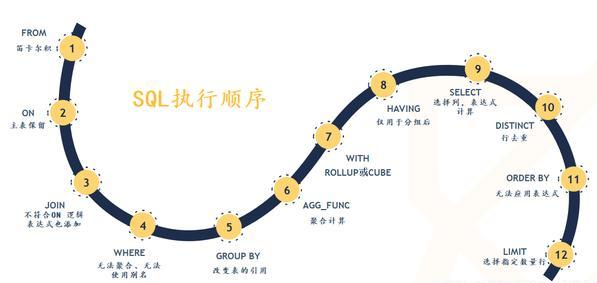
1 | # # |


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· .NET Core 中如何实现缓存的预热?
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· .NET Core 中如何实现缓存的预热?
· 阿里巴巴 QwQ-32B真的超越了 DeepSeek R-1吗?
· 如何调用 DeepSeek 的自然语言处理 API 接口并集成到在线客服系统
· 【译】Visual Studio 中新的强大生产力特性