15 python 字符编码
1、字符编码发展史

2、python默认编码
- python2.x默认的字符编码是ASCII,默认的文件编码是ASCII。(这里的字符是python中的字符串,文件是.py文件)
- python3.x默认的字符编码是unicode,默认的文件编码是utf-8。
1、Python2 默认的字符编码是ASCII(不支持中文)
- #-*-coding:utf-8-*-,告知python解释器,这个.py文件里的文本是用utf-8编码的。这样,python就会依照utf-8的编码形式解读其中的字符,然后转换成unicode编码内部处理使用。
- .py文件存储在磁盘上是什么编码方式,就要告知python解释器用的是什么编码方式。(#-*-coding:XXX-*-声明的编码方式要与.py文件的编码方式一致)
#!/usr/bin/env python # -*- coding: utf-8 -*- # print "你好,世界"
2、Python2 默认的文件编码是ASCII
C:\Windows\system32>python2 D:\test\python\test\test2.py #coding:utf8 import sys print(sys.getdefaultencoding()) #结果是:ascii
3、Python3 默认的字符编码是Unicode(支持中文)
#!/usr/bin/env python3 print "你好,世界"
4、Python3 默认的文件编码是utf-8
C:\Windows\system32>python3 D:\test\python\test\test3.py import sys print(sys.getdefaultencoding()) #结果是:utf-8
3、python中字符串的两种数据类型

- python2不区分str和unicode,但在拼接str和unicode时,str将自动转换成unicode。
###python2.7
# coding:utf8
a = 'hello'
b = '中国'
print(a, type(a)) #结果是:('hello', <type 'str'>)
print(b, type(b)) #结果是:('\xe4\xb8\xad\xe5\x9b\xbd', <type 'str'>) #前面输出的是字符的编码,这是print函数的原因。这问题只在python2中出现
print(b) #结果是:中国
c = 'hello' + u'中国' #字符串前加u是将此字符串转换为unicode
print(c, type(c)) #结果是:(u'hello\u4e2d\u56fd', <type 'unicode'>) #后面输出的是字符的编码,这是print函数的原因。
print(c) #结果是:hello中国
- python3严格区分了bytes和str,二者不能进行拼接。文本总是unicode,有str表示;二进制数据则由bytes表示。
a = b'hello' #字符串前加b是将此字符串转换为bytes b = '中国' print(a, type(a)) #结果是:b'hello' <class 'bytes'> print(b, type(b)) #结果是:中国 <class 'str'> # c = b'hello' + '中国' #异常,TypeError: can't concat str to bytes # print(c, type(c))
示例1:
- python2.7,在windows的cmd中执行
# coding:utf8 #告知python解释器,这个.py文件里的文本是用utf-8编码的,这样解释器就会依照utf-8的编码形式解读其中的字符。
str1 = 'hengha'
print(str1, type(str1)) #结果是:('hengha', <type 'str'>) #python2.x将字符串处理为str类型,即字节型。
str2 = '哼哈'
print(str2, type(str2)) #结果是:('\xe5\x93\xbc\xe5\x93\x88', <type 'str'>) #前面输出的是字符的编码,这是print函数的原因。
print(str2) #结果是:鍝煎搱 #这里python解释器用的编码是utf8,但cmd用的是gbk。按utf8输出,用gbk解释。
uutf = str2.decode('utf8') #str2本来就是字节型的,因此只能进行decode解码。
print(uutf, type(uutf)) #结果是:(u'\u54fc\u54c8', <type 'unicode'>) #前面输出的是字符的编码,这是print函数的原因。
print(uutf) #结果是:哼哈
x = 1
print(x, type(x)) #结果是:(1, <type 'int'>)
y = 1.1
print(y, type(y)) #结果是:(1.1, <type 'float'>)
示例2:
- python3.8,在windows的cmd中执行
str1 = 'hengha'
print(str1, type(str1)) #结果是:hengha <class 'str'> #python3.x将字符串处理为str类型,即字符串型。
str2 = '哼哈'
print(str2, type(str2)) #结果是:哼哈 <class 'str'> #python3.x将字符串处理为str类型,即字符串型(unicode编码)。
print(str2) #结果是:哼哈
uutf=str2.encode('utf8') #str2本来就是字符串型的,因此只能进行encode编码。
print(uutf,type(uutf)) #结果是:b'\xe5\x93\xbc\xe5\x93\x88' <class 'bytes'>
print(uutf) #结果是:b'\xe5\x93\xbc\xe5\x93\x88'
x = 1
print(x,type(x)) #结果是:1 <class 'int'>
y=1.1
print(y,type(y)) #结果是:1.1 <class 'float'>
4、python中编码和解码
- python3中字符串本身就是unicode,即字符串型。要转换成字节型,就要编码encode。
- python2中字符串本身就是bytes,即字节型。要转换成字符串型,就要解码decode,文件.py使用的是什么方式编码,就要用什么方式解码。
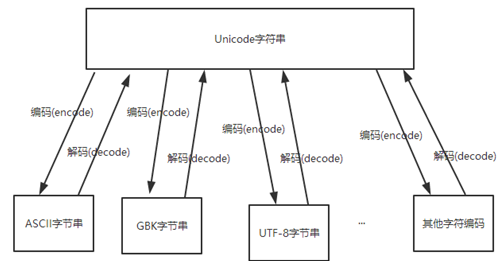
1、使用encode和decode进行编码解码
- python2和python3都支持。
>>> hh = 'hello 中国'
>>> hh.encode('utf-8') #将'hello 中国'从unicode编码成utf-8
b'hello \xe4\xb8\xad\xe5\x9b\xbd'
>>> hh.encode('gbk') #将'hello 中国'从unicode编码成gbk
b'hello \xd6\xd0\xb9\xfa'
>>> hh.encode('ascii') #将'hello 中国'从unicode编码成ascii,但ascii不支持中文,因此出现异常
Traceback (most recent call last):
File "<pyshell#54>", line 1, in <module>
hh.encode('ascii')
UnicodeEncodeError: 'ascii' codec can't encode characters in position 6-7: ordinal not in range(128)
>>> b'hello \xe4\xb8\xad\xe5\x9b\xbd'.decode('utf-8') #将其解码成Unicode,解码时告诉解码器自身是utf-8
'hello 中国'
>>> b'hello \xe4\xb8\xad\xe5\x9b\xbd'.decode('gbk') #将其解码成Unicode,解码时告诉解码器自身是gbk,但其并不是gbk而是utf-8,因此出现异常
Traceback (most recent call last):
File "<pyshell#58>", line 1, in <module>
b'hello \xe4\xb8\xad\xe5\x9b\xbd'.decode('gbk')
UnicodeDecodeError: 'gbk' codec can't decode byte 0xad in position 8: illegal multibyte sequence
2、使用bytes和str进行编码解码
- 仅python3支持,python2不支持。
- 在python3中,bytes和encode的作用都是编码,str和decode的作用都是解码。
###python3
hh = 'hello 中国'
print(hh)
d=hh.encode('utf-8')
print(d)
e=d.decode('utf-8')
print(e)
d2=bytes(hh,'utf-8')
print(d2)
e2=str(d2,'utf-8')
print(e2)
5、python的乱码问题
1、编码出现问题,可能的原因
- python解释器的默认编码
- Terminal使用的编码
- python源文件文件编码
- 操作系统的语言设置
2、Python支持中文的编码
- unicode、utf-8、gbk和gb2312。
- uft-8为国际通用,常用有数据库、编写代码。
- gbk如windows的cmd使用。
3、python使用编码的流程
- 保存.py文件时的编码
- python解释器使用的编码(默认或在.py文件中声明),要和.py的保持一致
- 加载到内存中,python字符串的编码是unicode(python3),其他的是解释器用的编码
- 解释器输出时用的还是解释器使用的编码
- 显示终端的编码

 浙公网安备 33010602011771号
浙公网安备 33010602011771号