11 python模块
1、什么是模块
- 在prthon中,模块是代码组织的一种方式,把功能相近的函数或者类放到一个文件中,一个文件(.py)就是一个模块(modue),模块名就是文件名去掉后缀.py。
2、模块的作用
- 提高代码的复用性和维护性。一个模块可以很方便的在其他项目中导入。
- 解决命名冲突,不同模块中相同的命名不会冲突。
1、自定义模块
- 模块就是程序。
- 模块用于定义函数和类等。
- 在主程序中,变量__name__的值是'__main__',而在导入的模块中,这个变量被设置为该模块的名称。
###自定义模块
__all__ = ['name', 'func', 'Ha']
name = 'heng99' #在模块中定义变量
age = 99
def func(name, age): #在模块中定义函数
print('他的名字是{},他{}岁了'.format(name, age))
class Ha: #在模块中定义类
def __init__(self, name, age):
self.name = name
self.age = age
def show(self):
print('他的名字是{},他{}岁了'.format(self.name, self.age))
print('modue模块中__name__的值:',__name__) #直接运行此模块。 #结果是:modue模块中__name__的值: __main__
if __name__ =='__main__': #测试代码
func('heng0', 0) #直接运行此模块。 #结果是:他的名字是heng0,他0岁了
2、导入模块
- 任何Python程序都可作为模块导入。文件的名称(不包括扩展名.py)将成为模块的名称。
- 导入模块时,将执行其中的代码。
- 导入模块多次和导入一次的效果相同。
- 模块有自己的作用域。这意味着在模块中定义的类和函数以及对其进行赋值的变量都将成为模块的属性。
- 当导入模块时,其所在目录中除源代码文件外,还将新建一个名为__pycache__的子目录(在较旧的Python版本中,是扩展名为.pyc的文件)。当再次导入这个模块时,如果.py文件未发生变化,Python将导入处理后的文件(即__pycache__目录中的文件),否则将重新生成处理后的文件。
1、让模块可用
- 有两种办法让解释器找到模块:将模块放在正确的位置;告诉解释器到哪里去查找。
1、将模块放在正确的位置
- sys.path包含一个目录(每个元素都是字符串)列表,解释器将在这些目录中查找模块。
- 目录列表中的每个元素都表示一个位置,如果要让解释器能够找到模块,可将其放在其中任何一个位置中。但目录site-packages是最佳的选择,因为它就是用来放置模块的。
2、告诉解释器到哪里去查找
- 将模块放在正确的位置可能不是合适的解决方案,其中的原因很多:
- 不希望Python解释器的目录中充斥着你编写的模块。
- 没有必要的权限,无法将文件保存到Python解释器的目录中。
- 想将模块放在其他地方。
- 解释器到哪里去查找模块
- 直接修改sys.path,这种做法不常见。
- 标准做法是将模块所在的目录包含在环境变量PYTHONPATH中。环境变量不是Python解释器的一部分,而是操作系统的一部分。
2、模块的三种导入方式
- import 模块名
- form 模块名 import 类名|函数名|变量名
- form 模块名 import *
1、第一种方式
- 第一种方式在调用模块中的变量、函数、类时,必须加模块的名称
import modue #导入模块,会执行模块中的代码。 #结果是:modue模块中__name__的值: modue
print(modue.name) #调用模块中的变量。 #结果是:heng99
print(modue.age) #结果是:99
modue.func('heng88', 88) #调用模块中的函数。 #结果是:他的名字是heng88,他88岁了
hh= modue.Ha('heng77',77) #调用模块中的类。
hh.show() #结果是:他的名字是heng77,他77岁了
2、第二种方式
- 第二种方式在调用模块中的变量、函数、类时,其名称可以直接使用。
from modue import name, age, func, Ha
print(name)
print(age)
func('heng88', 88)
hh = Ha('heng77', 77)
hh.show()
3、第三种方式
- 第三种方式在调用模块中的变量、函数、类时,其名称可以直接使用。
- 编写模块时,设置__all__很有用。因为模块可能包含大量其他程序不需要的变量、函数和类,比较周全的做法是将它们过滤掉。如果不设置__all__,则会在以import *方式导入时,导入所有不以下划线打头的全局名称。
- 不在__all__中的全局名称,必须显式地导入(import 模块名)并使用“模块名.全局名称”;或者使用“from 模块名 import 全局名称”。
from modue import *
print(name)
#print(age) #发生异常,因为模块中的列表__all__中没有age。
func('heng88', 88)
hh = Ha('heng77', 77)
hh.show()
3、包
- 为组织模块,可将其编组为包(package)。包其实就是另一种模块,它们可包含其他模块。
- 模块存储在扩展名为.py的文件中,而包则是一个必须包含__init__.py文件的目录。如果像普通模块一样导入包,文件__init__.py的内容就将是包的内容,即在导入包时__init__.py中的代码会被执行。
- 要将模块加入一个包,只需将模块文件放在包目录中。
- 还可以在包中嵌套其他包。
- 项目 > 包 > 模块 > 类、函数、变量(前面的大于后面的)
1、创建包
1、创建目录结构
./python/ #PYTHONPATH中的目录 ./python/packagehh #包目录(包名是packagehh) ./python/packagehh/__init__.py #包代码,也是一个模块,模块名是packagehh ./python/packagehh/module1.py #包中的模块,模块名是module1 ./python/packagehh/module2.py #包中的模块,模块名是module2 ./python/test.py #测试包的调用
2、包中的各文件
###./python/packagehh/__init__.py文件
__all__ = ['module2']
print('我在包的__init__中')
var01 = 'hh01'
def func():
print('我是包中的__init__中的func.')
class Ha:
def __init__(self):
print('我是包中的__init__中的Ha.')
###./python/packagehh/module1.py文件
var11 = 'hh11'
def func():
print('我是module1中的func.')
class Ha:
def __init__(self):
print('我是module1中的Ha.')
###./python/packagehh/module2.py文件
var21 = 'hh21'
def func():
print('我是module2中的func.')
class Ha:
def __init__(self):
print('我是module2中的Ha.')
2、导入包的五种方式
- import 包名 #导入包,仅可用__init__.py中的内容。
- import 包名.模块名 #导入模块
- from 包名 import 模块名 #导入模块
- from 包名.模块名 import 模块中全局名称 #导入模块中的全局名称
- from 包名 import * #导入包中的所有东西
1、第一种方式
- 只能使用packagehh目录中的__init__.py文件的内容,不能使用包中的模块。
###./python/test.py文件 import packagehh #导入包时会执行__init__.py文件 #结果是:我在包的__init__中 #导入package包 packagehh.func() #调用__init__.py中的内容 #结果是:我是包中的__init__中的func. # packagehh.module1.func() #调用module1.py中的内容 #异常,AttributeError: module 'packagehh' has no attribute 'module1' # packagehh.module2.func() #调用module2.py中的内容 #异常,AttributeError: module 'packagehh' has no attribute 'module2' print(packagehh.__all__) #查看__all__的值 #结果是:['module2']
2、第二种方式
- 可以使用模块module1的内容,只能通过全限定名“包名.模块名.全局名称”来使用。
- 也可以调用__init__.py的内容
###./python/test.py文件 import packagehh.module1 #导入包时会执行__init__.py文件 #结果是:我在包的__init__中 packagehh.func() #调用__init__.py中的内容 #结果是:我是包中的__init__中的func. packagehh.module1.func() #调用module1.py中的内容 #结果是:我是module1中的func. # packagehh.module2.func() #调用module2.py中的内容 #异常,AttributeError: module 'packagehh' has no attribute 'module2' print(packagehh.__all__) #查看__all__的值 #结果是:['module2']
3、第三种方式
- 只能使用module1模块,可直接通过“模块名.全局名称”来使用。
###./python/test.py文件 from packagehh import module1 #导入包时会执行__init__.py文件 #结果是:我在包的__init__中 # packagehh.func() #调用__init__.py中的内容 #异常,NameError: name 'packagehh' is not defined module1.func() #调用module1.py中的内容 #结果是:我是module1中的func. # packagehh.module2.func() #调用module2.py中的内容 #异常,NameError: name 'packagehh' is not defined # print(packagehh.__all__) #查看__all__的值 #异常,NameError: name 'packagehh' is not defined
4、第四种方式
- 只能使用module1模块中的func,可直接通过“全局名称”来使用。
###./python/test.py文件 from packagehh.module1 import func #导入包时会执行__init__.py文件 #结果是:我在包的__init__中 # packagehh.func() #调用__init__.py中的内容 #异常NameError: name 'packagehh' is not defined func() #调用module1.py中的func #结果是:我是module1中的func. # module2.func() #调用module2.py中的内容 #异常,NameError: name 'module2' is not defined # print(packagehh.__all__) #查看__all__的值 #异常,NameError: name 'packagehh' is not defined
5、第五种方式
- 因为__init__.py中的“__all__ = ['module2']”,因此仅导入了module2模块。
- 这方式导入方式默认是不能使用包中的模块的,要想使用包中的模块必须在__init__.py文件中用变量__all__ = ['模块名1','模块名2',...]显示指明。
- 不在__all__中的模块,可以显示的导入,即“from packagehh import 模块名”
- __all__仅对该方式生效。
###./python/test.py文件 from packagehh import * #导入包时会执行__init__.py文件 #结果是:我在包的__init__中 # packagehh.func() #调用__init__.py中的内容 #异常,NameError: name 'packagehh' is not defined # module1.func() #调用module1.py中的内容 #异常,NameError: name 'module1' is not defined module2.func() #调用module2.py中的func #结果是:我是module2中的func. # print(packagehh.__all__) #查看__all__的值 #异常,NameError: name 'packagehh' is not defined
4、循环导入
- 循环导入:大型的python项目中,需要很多python文件,由于架构不当,可能会出现模块之间的相互导入。
- 解决循环导入:
- 重新架构
- 将导入语句放到函数里面
- 把导入语句放到模块的最后(又时也可能与包中的__init__.py文件中的__all__里面的顺序有关)
##./python/packagehh/__init__.py文件
__all__ = ['module2', 'module1']
def func0():
print('我是包中的__init__中的func0.')
###./python/packagehh/module1.py文件
from packagehh.module2 import func2
def func1():
print('我是module1中的func1.')
###./python/packagehh/module2.py文件
def func2():
print('我是module2中的func2.')
from packagehh.module1 import func1
func1()
###./python/test.py文件
from packagehh import *
module1.func2()
module2.func2()
5、探索模块
1、模块包含什么
1、使用dir
- 要查明模块包含哪些东西,可使用函数dir,它列出对象的所有属性(对于模块,它列出所有的函数、类、变量等)。
###返回不以下划线打头的名称
import copy
list1 = [n for n in dir(copy) if not n.startswith('_')]
print(list1)
<<<
['Error', 'copy', 'deepcopy', 'dispatch_table', 'error']
2、变量__all__
- 告诉解释器从模块导入所有的名称(from 模块名 import *)意味着什么。
- from copy import *,将只能变量__all__中列出的3个函数导入。
- 要导入dispatch_table,必须显式地:导入copy并使用copy.dispatch_table;或者使用from copy import dispatch_table。
import copy print(copy.__all__) <<< ['Error', 'copy', 'deepcopy']
2、使用help获取帮助
- 有一个标准函数可提供你通常需要的所有信息,它就是help。
- 文档字符串就是在函数开头编写的字符串,用于对函数进行说明,而函数的属性__doc__可能包含这个字符串。
import copy help(copy.copy) print(copy.copy.__doc__)
3、文档
- “Python库参考手册”(https://docs.python.org/library),它描述了标准库中的所有模块。
- 所有的文档都可在Python网站(https://docs.python.org)上找到。
4、使用源代码
- 事实上,要学习Python,阅读源代码是除动手编写代码外的最佳方式。
- 源代码在哪里呢?一种办法是像解释器那样通过sys.path来查找,但更快捷的方式是查看模块的特性__file__。
- 如果列出的文件名以.pyc结尾,可打开以.py结尾的相应文件。
import copy print(copy.__file__) <<< C:\Program Files\Python\Python38\lib\copy.py
6、标准库(系统模块)
1、sys模块
- 模块sys能够访问与Python解释器紧密相关的变量和函数。
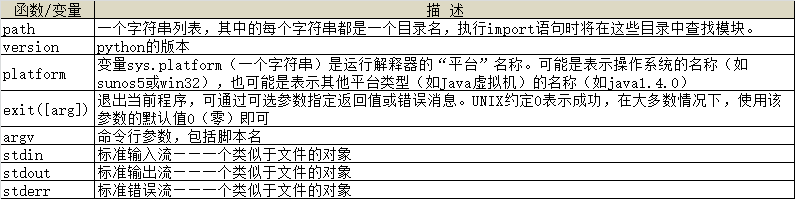
1、path、version、platform、exit
###在linux中执行
#!/usr/bin/python3
import sys
print(sys.path)
print('----------------')
print(sys.version)
print('----------------')
print(sys.platform)
exit(199)
~]# ./hh.py
['/root', '/usr/lib64/python36.zip', '/usr/lib64/python3.6', '/usr/lib64/python3.6/lib-dynload', '/usr/lib64/python3.6/site-packages', '/usr/lib/python3.6/site-packages']
----------------
3.6.8 (default, Nov 16 2020, 16:55:22)
[GCC 4.8.5 20150623 (Red Hat 4.8.5-44)]
----------------
linux
~]# echo $?
199
2、argv
###在Linux上执行 #!/usr/bin/python3 import sys var = sys.argv print(var[0],var[1],var[2]) ~]# ./hh.py 猪 不 戒 ./hh.py 猪 不
2、time模块
- 模块time包含用于获取当前时间、操作时间和日期、从字符串中读取日期、将日期格式化为字符串的函数。日期可表示为实数(从“新纪元”1月1日0时起过去的秒数。“新纪元”是一个随平台而异的年份,在UNIX中为1970年),也可表示为包含9个整数的元组。
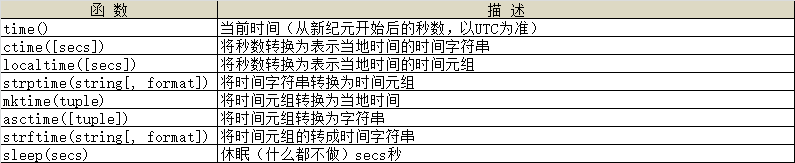
1、获取时间
import time tt = time.time() #获取时间戳 print(tt) #结果是:1615297664.540136 tc = time.ctime() #获取时间字符串 print(tc) #结果是:Tue Mar 9 21:47:44 2021 tl = time.localtime() #获取时间元组 print(tl) #结果是:time.struct_time(tm_year=2021, tm_mon=3, tm_mday=9, tm_hour=21, tm_min=47, tm_sec=44, tm_wday=1, tm_yday=68, tm_isdst=0)
2、时间类型的转换
import time
tt = 1615297664.540136
tc = time.ctime(tt) #将时间戳转成时间字符串
print(tc) #结果是:Tue Mar 9 21:47:44 2021
tl = time.localtime(tt) #将时间戳转成时间元组
print(tl) #结果是:time.struct_time(tm_year=2021, tm_mon=3, tm_mday=9, tm_hour=21, tm_min=47, tm_sec=44, tm_wday=1, tm_yday=68, tm_isdst=0)
tp = time.strptime('2021-03-09', '%Y-%m-%d') #将时间字符串转成时间元组
print(tp) #结果是:time.struct_time(tm_year=2021, tm_mon=3, tm_mday=9, tm_hour=0, tm_min=0, tm_sec=0, tm_wday=1, tm_yday=68, tm_isdst=-1)
tm = time.mktime(tl) #将元组转成时间戳
print(tm) #结果是:1615297664.0
ta = time.asctime(tl) #将时间元组的转成时间字符串
print(ta) #结果是:Tue Mar 9 21:47:44 2021
tf = time.strftime('%Y-%m-%d %H:%M:%S', tl) #将元组的转成字符串
print(tf) #结果是:2021-03-09 22:12:31
3、Python日期元组中的字段
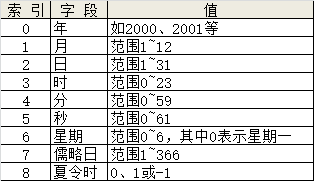
3、datetime模块
import datetime now = datetime.datetime.now() #获取当前时间 print(now) #结果是:2021-03-09 22:54:21.086363 ###时间差 print(now + datetime.timedelta(3)) #3天后的时间 #结果是:2021-03-12 22:54:21.086363 print(now + datetime.timedelta(days=3)) #3天后的时间 #结果是:2021-03-12 22:54:21.086363 print(now - datetime.timedelta(3)) #3天前的时间 #结果是:2021-03-06 22:54:21.086363 print(now + datetime.timedelta(-3)) #3天前的时间 #结果是:2021-03-06 22:54:21.086363 print(now + datetime.timedelta(seconds=3)) #3秒后的时间 #结果是:2021-03-09 22:54:24.086363 print(now + datetime.timedelta(minutes=3)) #3分钟后的时间 #结果是:2021-03-09 22:54:24.086363 print(now - datetime.timedelta(hours=3)) #3天后的时间 #结果是:2021-03-09 19:54:21.086363 print(now - datetime.timedelta(weeks=3)) #3周后的时间 #结果是:2021-02-16 22:54:21.086363
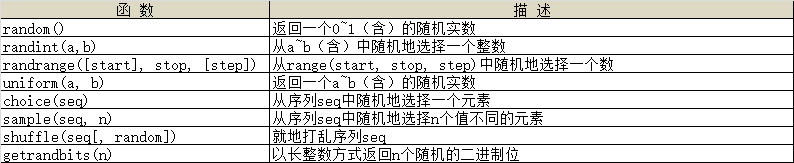
4、random模块
5、hashlib模块
import hashlib
strr = '我和你说啊,八戒在和嫦娥聊天呐!'
md5 =hashlib.md5(strr.encode('utf-8')) #md5加密,单向加密
print(md5.hexdigest()) #结果是:d5927df78917c83b98c74cab534f298a
sha1 = hashlib.sha1(strr.encode('utf-8')) #sha1加密,单向加密
print(sha1.hexdigest()) #结果是:8140bf68925bbce7dea371b17ccde78c4c2435a8
sha256 = hashlib.sha256(strr.encode('utf-8')) #sha256加密,单向加密
print(sha256.hexdigest()) #结果是:52455c80d37ff66d089f1ca5a9bfe97735590a80a5079ba77cf70098d400e75d
6、re模块
- 正则表达式是可匹配文本片段的模式。
- 正则表达式的作用在文本中查找模式,将特定的模式替换为计算得到的值,以及将文本分割成片段。
- 参考文档:https://docs.python.org/3/howto/regex.html
1、正则表达式的元字符
- 大多数字母和字符将简单地匹配它们自己。
- 特殊元字符不匹配他们自己。它们表明应该匹配一些不寻常的东西,或者通过重复它们或改变它们的含义来影响RE的其他部分。
- 元字符:“.”、“^”、“$”、“*”、“+”、“?”、“{”、“}”、“[”、“]”、“\”、“|”、“(”、“)”
(1)字符匹配:
- 通配符:
- .:句点,匹配除换行符“\n”外的任意单个字符,称为通配符(wildcard)。
- 字符集:[]
- []:匹配字符集中的任意单个字符
- [^]:匹配字符集外的任意单个字符
- 注意:
- 句点、星号和问号等特殊字符,要在模式中将其用作字面字符而不是正则表达式运算符,必须使用反斜杠对其进行转义。在字符集中,通常无需对这些字符进行转义,但进行转义也是完全合法的。
- 脱字符(^)位于字符集开头时,除非要将其用作排除运算符,否则必须对其进行转义。换而言之,除非有意为之,否则不要将其放在字符集开头。
- 右方括号(])和连字符(-),要么将其放在字符集开头,要么使用反斜杠对其进行转义(连字符也可以放在字符集末尾)。
(2)次数匹配:
- 可选模式
- (pattern)?:pattern可重复0或1次。 #可有可无
- 重复模式
- (pattern)*:pattern可重复0、1或多次。 #任意次
- (pattern)+:pattern可重复1或多次。 #至少一次
- (pattern){m}:pattern可重复m次。
- (pattern){m,n}:pattern可重复至少m次,至多n次。
- (pattern){m,}:pattern可重复至少m次。
(3)位置锚定:
- ^:锚定字符串的开头,即锚定行首。
- $:锚定字符串的尾部,即锚定行尾
(4)转义:\
- 要让特殊字符的行为与普通字符一样,可对其进行转义
- python使用模块re时,将对反斜杠“\”进行两次转义,python解释器执行的转义和模块re执行的转义。
- 使用原始字符串,如r'python\.org',可以禁止python解释器对反斜杠“\”进行转义,仅让模块re对其转义。
- 正则表达式只要有转义,就尽可能的使用原始字符串。
- python中特殊含义的字符
- \A:表示从字符串的开始处匹配。
- \Z:表示从字符串的结束处匹配,如果存在换行,只匹配到换行前的结束字符。
- \b:匹配一个单词边界,也就是指单词和空格间的位置。例如, "py\b'。 可以匹配"python"中的,py',但不能匹配"genpxxl"中的'py'。
- \B:匹配非单词边界. 'py\b'可以匹配"gsgpxl"中的'py',但不能匹配"python"中的'py'。
- \d:匹配任意数字,等价于[0-9]。
- \D:匹配任意非数字字符,等价于[^\d]。
- \s:匹配任意空白字符,等价于[\t\n\r\f]。
- \S:匹配任意非空白字符,等价于[^\s]。
- \w:匹配任意字母数字及下划线,等价于[a-zA-Z0-9]。
- \W:匹配任意非字母数字及下划线,等价于[^\w]。
- \\:匹配原义的反斜杠\。
(5)或:|
- 子模式:正则表达式的一部分,子模式可以放在圆括号中。
- 单个字符也可称为子模式。
# 位置锚定
str1 = 'root1wajroot2173root3 root4 root5hjhairoot6'
result = re.findall('root.', str1)
print(result) #结果是:['root1', 'root2', 'root3', 'root4', 'root5', 'root6']
result = re.findall('^root.', str1)
print(result) #结果是:['root1']
result = re.findall('root.$', str1)
print(result) #结果是:['root6']
result = re.findall(r'\broot.', str1)
print(result) #结果是:['root1', 'root4', 'root5']
result = re.findall(r'root.\b', str1)
print(result) #结果是:['root3', 'root4', 'root6']
result = re.findall(r'\broot.\b', str1)
print(result) #结果是:['root4']
# 验证QQ号,长度5-11位,不能以零开头
qq = '123456789'
result = re.search('^[1-9][0-9]{4,10}$', qq)
print(result) #结果是:<re.Match object; span=(0, 9), match='123456789'>
# 验证用户名,用户名可以由字母和数字组成,但不能以数字开头,6位以上。
usrname = 'admin123'
result = re.search('^[a-zA-Z][a-zA-Z0-9]{5,}$', usrname)
print(result) #结果是:<re.Match object; span=(0, 8), match='admin123'>
# 验证邮箱163、126、qq
email = 'hu627sj@126.cn'
result = re.search(r'^\w+@(163|126|qq)\.(com|cn)$', email)
print(result) #结果是:<re.Match object; span=(0, 14), match='hu627sj@126.cn'>
2、编组
- 在模块re中,查找与模式匹配的子串的函数都在找到时返回MatchObject对象。
(1)编组
- 编组就是放在圆括号内的子模式,它们是根据左边的括号数编号的,其中编组0指的是整个模式。
- 除整个模式(编组0)外,最多还可以有99个编组,编号为1~99。
编组示例: 'There (was a (wee) (cooper)) who (lived in Fyfe)' 包含如下编组: 0 There was a wee cooper who lived in Fyfe 1 was a wee cooper 2 wee 3 cooper 4 lived in Fyfe
import re
###分组
phone = 'hh010-123456hh'
result = re.search(r'(\d{3}|\d{4})-(\d{6})', phone)
print(result.group())
print(result.group(0))
print(result.group(1))
print(result.group(2))
###分组引用
#使用r'\n'的方式引用分组n
str1 = '<html><h1>hello world!</h1></html>'
result = re.search(r'<([0-9a-zA-Z]+)><([0-9a-zA-Z]+)>(.*)</\2></\1>', str1)
print(result)
print(result.group(0))
print(result.group(1))
print(result.group(2))
print(result.group(3))
#为分组命名。 命名分组:(?P<分组名>正则) 调用分组:(?P=分组名)
result = re.search(r'<(?P<name1>[0-9a-zA-Z]+)><(?P<name2>[0-9a-zA-Z]+)>(.*)</(?P=name2)></(?P=name1)>', str1)
print(result)
print(result.group(0))
print(result.group(1))
print(result.group(2))
print(result.group(3))
(2)编组和sub函数
- 为利用re.sub的强大功能,最简单的方式是在替代字符串中使用组号。在替换字符串中,任何类似于'\\n'的转义序列都将被替换为与模式中编组n匹配的字符串
import re emphasis_pattern = r'\*([^\*]+)\*' result = re.sub(emphasis_pattern, r'<em>\1</em>', 'Hello, *world*!') print(result) #结果是:Hello, <em>world</em>!
3、贪婪和非贪婪模式
- 重复运算符默认是贪婪的,这意味着它们将匹配尽可能多的内容。
- 对于所有的重复运算符,都可以在其后面加上问号“?”来将其指定为非贪婪的。尽可能少的匹配内容。
- 重复运算符:?、*、+、{m,n}
import re
str1 = 'centoshh:x:1000:1000:centoshh:/home/centoshh:/bin/bash'
result = re.findall('cen.?os', str1)
print(result) #结果是:['centos', 'centos', 'centos']
result = re.findall('cen.??os', str1)
print(result) #结果是:['centos', 'centos', 'centos']
result = re.findall('ce.*os', str1)
print(result) #结果是:['centoshh:x:1000:1000:centoshh:/home/centos']
result = re.findall('ce.*?os', str1)
print(result) #结果是:['centos', 'centos', 'centos']
result = re.findall('ce.+os', str1)
print(result) #结果是:['centoshh:x:1000:1000:centoshh:/home/centos']
result = re.findall('ce.+?os', str1)
print(result) #结果是:['centos', 'centos', 'centos']
result = re.findall('ce.{1,}os', str1)
print(result) #结果是:['centoshh:x:1000:1000:centoshh:/home/centos']
result = re.findall('ce.{1,}?os', str1)
print(result) #结果是:['centos', 'centos', 'centos']
4、函数和方法
(1)模块re中重要的函数

import re
str1 = 'centoshh:x:1000:1000:centoshh:/home/centoshh:/bin/bash'
# match函数 #判断字符串是否以此模式开头,如果不是返回None
result = re.match('centos', str1)
print(result) #结果是:<re.Match object; span=(0, 6), match='centos'>
# seach函数 #查找字符串,匹配到第一个就会结束匹配。没有找到就返回None
result = re.search('centos', str1)
print(result) #结果是:<re.Match object; span=(0, 6), match='centos'>
# findall函数 #查找字符串,以列表的方式返回所有与模式匹配的子串。没有找到就返回空列表
result = re.findall('centos', str1)
print(result) #结果是:['centos', 'centos', 'centos']
# sub函数 #替换。有与模式匹配的就进行替换,然后返回替换后的字符串;没有与模式匹配的,返回原字符串
result = re.sub('centos', 'root', str1)
print(result) #roothh:x:1000:1000:roothh:/home/roothh:/bin/bash
# split函数 #分割。返回一个列表
result = re.split(r'[:/]', str1)
print(result) #['centoshh', 'x', '1000', '1000', 'centoshh', '', 'home', 'centoshh', '', 'bin', 'bash']
(2)re匹配对象的重要方法

import re
str1 = '<html><h1>hello world!</h1></html>'
result = re.search(r'<([0-9a-zA-Z]+)><([0-9a-zA-Z]+)>(.*)</\2></\1>', str1)
print(result) #结果是:<re.Match object; span=(0, 34), match='<html><h1>hello world!</h1></html>'>
print(result.group()) #结果是:<html><h1>hello world!</h1></html>
print(result.group(1, 2, 3)) #结果是:('html', 'h1', 'hello world!')
print(result.group(1)) #结果是:html
print(result.start(1)) #结果是:1
print(result.end(1)) #结果是:5
print(result.span(1)) #结果是:(1, 5)
5、补充
import re
def func(temp):
num = temp.group()
num1 = int(num) + 1
return str(num1)
result = re.sub(r'\d+', '90', 'java:99,python95')
print(result) #结果是:java:90,python90
result = re.sub(r'\d+', func, 'java:99,python95') #使用了函数
print(result) #结果是:java:100,python96
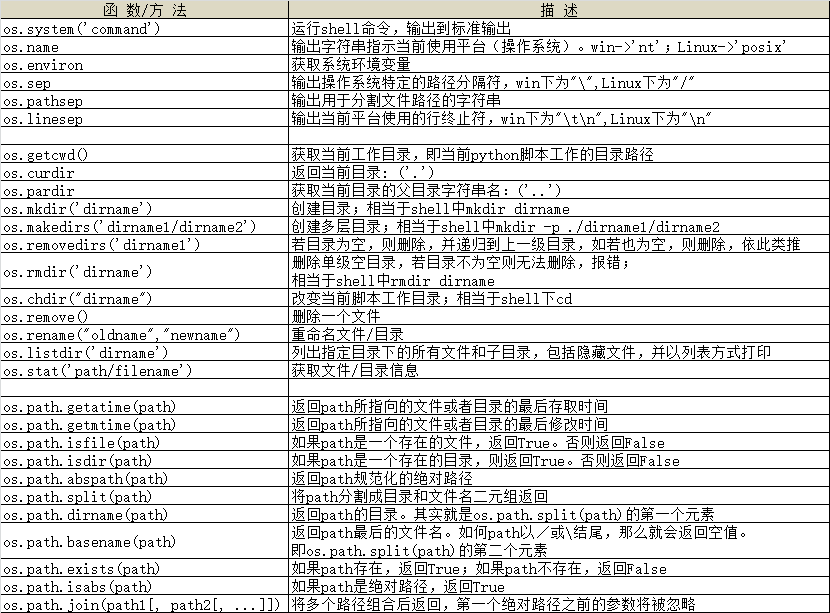
7、os模块
- 请注意,在Windows中,使用os.system或os.startfile启动外部程序后,当前Python程序将继续运行;而在UNIX中,当前Python程序将等待命令os.system结束。
8、fileinput模块
- 模块fileinput能够迭代一系列文本文件中的所有行。
1、fileinput模块的函数

- 函数fileinput.input返回一个可在for循环中进行迭代的对象。如果参数inplace设置为True(inplace=True),将就地进行处理。就地进行处理时,可选参数backup用于给从原始文件创建的备份文件指定扩展名。
- 函数fileinput.filename返回当前文件(即当前处理的行所属文件)的文件名。
- 函数fileinput.lineno返回当前行的编号。这个值是累计的,因此处理完一个文件并接着处理下一个文件时,不会重置行号,而是从前一个文件最后一行的行号加1开始。
- 函数fileinput.filelineno返回当前行在当前文件中的行号。每次处理完一个文件并接着处理下一个文件时,将重置这个行号并从1重新开始。
- 函数fileinput.isfirstline在当前行为当前文件中的第一行时返回True,否则返回False。
- 函数fileinput.isstdin在当前文件为sys.stdin时返回True,否则返回False。
- 函数fileinput.nextfile关闭当前文件并跳到下一个文件,且计数时忽略跳过的行。
- 函数fileinput.close关闭整个文件链并结束迭代。
2、如何使用fileinput模块
- 如果在UNIX命令行中这样调用脚本,就能够依次迭代文件file1.txt到file3.txt中的所有行。
- $ python some_script.py file1.txt file2.txt file3.txt
- 还可在UNIX管道中对使用UNIX标准命令cat提供给标准输入(sys.stdin)的行进行迭代。
- $ cat file.txt | python some_script.py
- 如果使用模块fileinput,上面两种方式的效果相同。
3、示例
###在Linux中执行 #修改selinux并备份
#!/usr/bin/python3
import fileinput
import re
for line in fileinput.input('python.txt', inplace=True, backup='.bak'):
print(re.sub('^SELINUX=(.*)', r'SELINUX=permissive', line), end='')
~]# ./hh.py /etc/selinux/config
8、集合、堆和双端队列

 浙公网安备 33010602011771号
浙公网安备 33010602011771号