
[转]数据中心网络虚拟化 隧道技术
http://www.sdnlab.com/12077.html SDNLAB
如何实现不同租户和应用间的地址空间和数据流量的隔离是实现数据中心网络虚拟化首先需要解决的几个问题之一。所谓地址空间的隔离是指不同租户和应用之间的网络(ip)地址之间不会产生相互干扰。换句话说,两个租户完全可以使用相同的网络地址。所谓数据流量的隔离是指任何一个租户和应用都不会感知或捕获到其他虚拟网络内部的流量。为了实现上述目的,我们可以在物理网络上面为租户构建各自的覆盖(overlay)网络,而隧道封装技术则是实现覆盖网络的关键。本节我们将针对目前较为流行的构建覆盖网络的隧道封装技术展开讨论,具体包括VXLAN,VXLAN-GPE,NVGRE和STT技术。
1.VXLAN
VXLAN(Virtual eXtensible Local Area Network)即虚拟可扩展局域网,是一种将二层报文用四层协议进行封装的Overlay技术。具体来说,VXLAN采用MAC-in-UDP的封装方式对二层网络进行扩展。目前在数据中心内应用VXLAN技术最广泛的场景即是实现虚拟机在三层网络范围内的自由迁移。使用VXLAN之后,原来局限于同数据中心、同物理二层网、同VLAN的虚拟机迁移可以不再受这些限制,可以按需扩展到虚拟二层网络上的任何地方。此外,VXLAN使用户可以创建多达16M相互隔离的虚拟网络,相对于VLAN所能支持的4096个虚拟网络而言具有质的提升。如图 1所示,VXLAN报文共有50字节(或54字节)的封装报文头,包括14字节(或18字节,含802.1 QTag)的外部以太网帧头(对应虚拟机所在物理机的MAC)、20字节的外部IP头(对应虚拟机所在物理机的IP)、8字节的外部UDP头、8字节的VXLAN头。
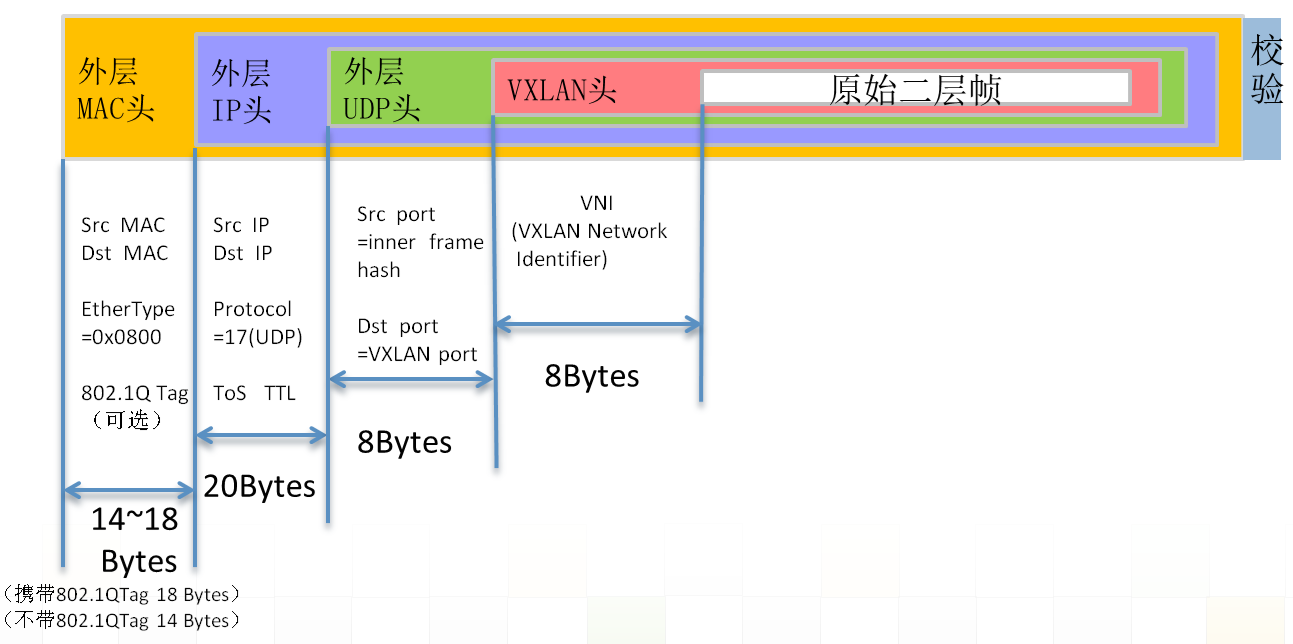
图 1. VXLAN封装格式
外层UDP头的目的端口缺省使用4798,也可以根据需要进行修改,源端口号是一个使用内层数据包计算出来的hash值,变动范围为49152-65535。外层IP头的源IP地址为源VTEP(VXLAN Tunnel End Point, VXLAN隧道端点)的地址,目的IP为目的VTEP地址(在内层数据包对应的目的VTEP未知时,此处为该内层数据包所属虚拟网络对应的IP多播组地址)。外层以太网头的MAC地址为VTEP的MAC 地址。由此可见对传输路径上的网络设备而言,虚拟机的信息完全被掩盖了。
如图 2所示,VXLAN头长8个字节,其中目前有效的字段包括一个字节的Flags标识位和3个字节的VNI(VXLAN Network Identifier,VXLAN网络标识符,用于标识一个虚拟网络)。其余4个字节作为保留域留作它用,但是目前在使用的时候必须将这些位置为0。对于Flags域而言,其中I 位(I代表Invalidation有效)必须被设为1,其余7位需要被设为0。VXLAN利用VNI进行网络隔离,同一个VNI中的虚拟机可以相互通讯。因VXLAN的网络标识VNI为24bit,故用户可以创建16M个相互隔离的虚拟网络。
![数据中心网络虚拟化 隧道技术 图 2. VXLAN头格式[1]](http://www.sdnlab.com/my_sdnlab/wp-content/uploads/2015/06/%E6%95%B0%E6%8D%AE%E4%B8%AD%E5%BF%83%E7%BD%91%E7%BB%9C%E8%99%9A%E6%8B%9F%E5%8C%96-%E9%9A%A7%E9%81%93%E6%8A%80%E6%9C%AF-%E5%9B%BE-2.-VXLAN%E5%A4%B4%E6%A0%BC%E5%BC%8F1.png)
图 2. VXLAN头格式[1]
VXLAN报文的封装/解封装是由位于隧道两端的VTEP负责完成。源端VTEP在对一段报文进行VXLAN封装之后,通过隧道向目的端VTEP发送封装报文。内层数据包对传输路径上的网络设备是不可见的,无需为内层数据包维护转发信息。当目的端VTEP接收到报文之后,首先对报文进行解封装,然后发给相应的虚拟机。VXLAN协议并没有对VTEP的实现形式进行规定,其可由支持VXLAN的硬件设备或软件来实现。
由于通信的VM对并不知道对端VM所对应VTEP的IP地址(即不知道该VM在哪个物理机上),因此VXLAN采取了数据平面学习机制:VXLAN的每个虚拟网络对应一个IP多播组(即VNI与IP多播地址为一一映射关系),并在VTEP本地维护这种对应关系。在进行数据包封装时,若本地没有目的VM对应的VTEP信息,则在该虚拟网络对应的IP多播组内进行多播,收到多播的VTEP检查目的VM是否在本地,做出响应,并将源VM和源VTEP的对应关系记录在本地。当源VTEP收到这一响应消息后即学得了目的VM和目的VTEP的对应关系。除此之外,VXLAN还可采用中央控制器的方式获取对端VTEP信息:各VTEP将本地VM MAC地址和VTEP IP的对应关系推送给控制器,当源VTEP不知道目的VM对应的VTEP IP时,直接向控制器请求该信息。
下面我们通过一个例子来介绍使用VXLAN构建虚拟网络的工作方式(根据[RFC7348],VTEP可实现在物理交换机或物理服务器上,下例以VTEP在VM所在物理服务器的hypervisor内来示例)。首先,假设当前虚拟网络(VNI=300)包含两台虚拟机:VM1和VM2。如图 3所示,为了实现虚拟网络内部虚拟机之间的相互通信,首先所有相关的VTEP需要通过IGMP协议加入多播组(239.0.0.1)。
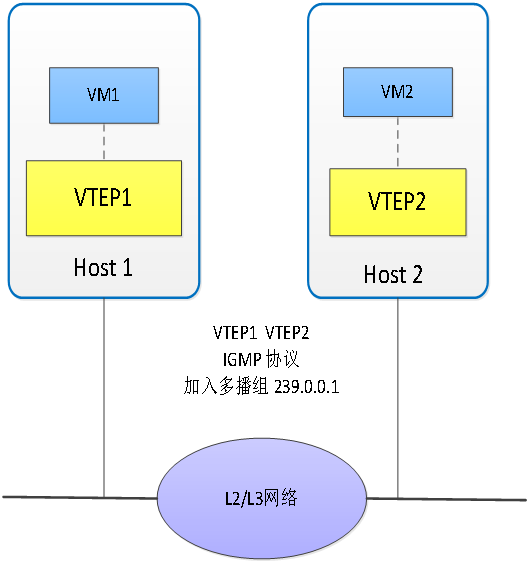
图 3. VXLAN虚拟网络的初始化/加入多播组
此时,假设VM1需要向VM2发送数据。由于是第一次通信,VM1并没有VM2的MAC地址。因此,如图 4所示,VM1首先发出ARP请求。VTEP1捕获该报文,对其进行封装,并将VXLAN头中VNI设置为300,用于说明该消息属于编号为300的虚拟网络。目标ip地址被设为组播地址239.0.0.1,而源ip地址则为VTEP1的ip地址。经过多播转发之后,目的端的VTEP2会收到数据包。其首先对其进行解封装,并且发现其还没有存储VM1的地址信息,所以VTEP2首先将VM1的虚拟网络编号(300)、MAC地址(MAC1)和VTEP1的ip地址之间的映射关系进行缓存。在完成VM1地址的学习之后,VTEP2将解封装后ARP数据包在与其相连的所有VNI=300的虚拟机内进行广播。

图 4. VXLAN中发送ARP请求过程
如图 5所示,当VM2接收到ARP请求之后,因为发现其自身为目标主机,因此按照标准流程向VM1发送ARP响应。显然,响应必然被VTEP2所截获,并进行封装。由于此时VTEP2已经学习到了VM1的地址信息,因此其可以使用VTEP1的ip地址,以及主机1的MAC地址进行单播传输。VTEP1接收到单播报文后,学习内层MAC到外层IP地址的映射,解封装并根据被封装内容的目的MAC地址转发给VM1。最后由VM1完成对ARP应答报文的处理。
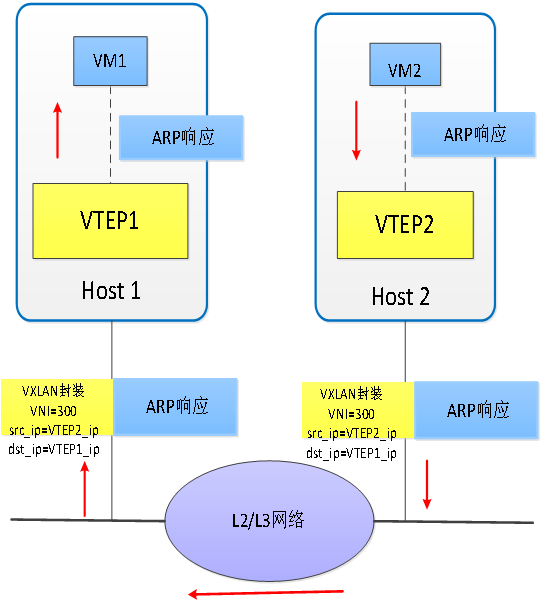
图 5. VXLAN中发送ARP响应过程
2.VXLAN-GPE
VXLAN定义了将以太网帧封装在外部UDP报文中的封装格式。VXLAN-GPE(Generic Protocol Extension VXLAN)则是对VXLAN的扩展,从而使得可以封装任意层次的数据包,另外还提供了对OAM(Operations ,Administration and Management)协议的支持。VXLAN-GPE扩展的方法是通过对外层VXLAN 头的一些保留位进行修改。如图 6所示,VXLAN-GPE对VXLAN头做了以下4方面的变动:
1)增加封装协议域(Next Protocol Field):该域用于指明被封装的数据报的协议类型,当前已定义的Next Protocol值包括:
- 0x1 : IPv4
- 0x2 : IPv6
- 0x3 : Ethernet
- 0x4 : Network Service Header(NSH)。上一节介绍Cisco的虚拟化平台时,我们提到了NSH的概念,在此我们再进行简单的回顾。NSH头包括两部分内容:1)服务路径相关信息(服务节点要利用它来选择服务路径上的下一个服务节点),2)为途径的网络设备和服务设备提供所需的元数据。NSH服务头是由具有服务分类功能的设备或应用添加,该设备或应用可以确定哪些数据包需要服务,需要哪些服务,相应地经过怎样的服务路径。
2)增加P bit域:Flag域中的第5位(从零开始编号)被定义为P bit,其中如果8比特的封装协议域(Next Protocol)存在,则P bit需要设置为1。如果P bit为0,则按照标准的VXLAN协议进行解析。
3)增加O bit域:Flag的第7位被定义为O(OAM)bit。当O bit被设置为1时,内层的被封装数据包为OAM包,从而触发OAM包的处理过程。
4)增加Ver域:Flag的第8和第9两位被定义为Ver(Version),用于指明VXLAN-GPE版本(当前VXLAN-GPE版本为0)。
![数据中心网络虚拟化 隧道技术 图 6. VXLAN-GPE头格式[2]](http://www.sdnlab.com/my_sdnlab/wp-content/uploads/2015/06/%E6%95%B0%E6%8D%AE%E4%B8%AD%E5%BF%83%E7%BD%91%E7%BB%9C%E8%99%9A%E6%8B%9F%E5%8C%96-%E9%9A%A7%E9%81%93%E6%8A%80%E6%9C%AF-%E5%9B%BE-6.-VXLAN-GPE%E5%A4%B4%E6%A0%BC%E5%BC%8F2.png)
图 6. VXLAN-GPE头格式[2]
3.NVGRE
在介绍NVGRE之前,我们首先介绍一下由Cisco公司提出的GRE(Generic Routing Encapsulation,通用路由封装协议)。GRE的提出主要为了解决在任意层次网络协议之间的封装问题。本小节的内容主要参考了RFC1701和RFC1702。首先,GRE将需要传输的真实数据包称为载荷包(payload packet)。为了在隧道内进行传输,我们首先需要使用GRE头对载荷包进行封装,并且称封装后的数据包为GRE包。最后,GRE头外部还需封装相应的包头从而实现在物理网络上的传输。为了方便,外层的协议被称为传送协议(deliver protocol)。如图 7所示为GRE包头,其中各域的定义如下:
1)Flag域:GRE头的前2个字节为Flag域,其中:
- C (bit 0):表示Checksum Present(检查和字段存在),如果设为1,说明Checksum字段存在。
- R(bit 0):表示Routing Present(路由字段存在),如果设置为1,则说明可选的Routing字段存在。
- K(bit 2):表示Key Present(Key字段存在),如果设为1,说明Key字段存在。
- S(bit 3):表示Sequence Number Present(序列号字段存在),如果设为1,说明Sequence Number字段存在。
- s(bit 4): 表示严格源端路由(Strict Source route)。所谓的严格源路由是指路径上的所有路由器都应该有源端指定,并且经过路由器的顺序是不允许发生改变的。一般来说,只有当所有的路由信息中都包含严格路由信息时,才将该位置1。
- Recur(bits 5-7);递归/嵌套控制(Recursion Control)域通过使用3位来表明允许的额外封装层数,一般默认设置为0。
- Flags(bits 8-12):传输时需要设置为0
- Ver (bits 13-15): 版本号。
2)Next Protocol(2个字节):指明内层被封装数据包的协议类型,如果内层数据包是IPv4类型,则应该被设置为 0x800。
3)Checksum(2字节):检验和
4)Offset(2字节):表明路由字段的起始地址到第一个有效的路由信息字段的偏移量,单位为字节。这个字段只有在C或者R位被置1时才存在,并且只有在R位有效时,其所包含的信息才有意义。
5)Key(4 字节):相同流中的数据包含有相同的Key值,解封装的隧道终端依据该值判断数据包是否属于相同的流。在NVGRE中,该字段被用来表示虚拟网络的标识。
6)Sequence Number (4 字节):用于标明数据包的传送顺序。
7)Routing(变长):源路由信息,当R位有效时,该域包含多个源路由条目(Source Routing Entry, SRE)。SRE的具体定义此处省略,有兴趣的读者可以参看RFC1701。

图 7. GRE包头的格式
GRE的封装和解封装过程与VXLAN的封装和解封装过程类似,此处就不再赘述。下面我们介绍一下NVGRE(Network Virtualization using Generic Routing Encapsulation)协议。NVGRE最初由微软公司提出,其目的是为了实现数据中心的多租户虚拟二层网络,其实现方式是将以太网帧封装在GRE头内并在三层网络上传输(MAC-in-IP)[3]。顾名思义,NVGRE的底层实现细节都可是复制GRE,因此我们将主要针对NVGRE与传统GRE的区别进行说明。如图 8所示,使用NVGRE封装的数据包包头格式与使用GRE封装是相同的。区别在于,在使用NVGRE时,GRE包头中的C和S位必须置0。换句话说,NVGRE的头中将没有检验和以及序列号。K位必须设置为1,从而使得Key域有效。但是NVGRE对Key域做了重新定义,其中前3个字节并定义为VSID(Virtual Subnet ID)、第四个字节被定义为FlowID。其中24位的VSID用于标示二层虚拟网络,因此NVGRE可以最多支持16M虚拟网。这个数量与VXLAN支持的虚拟网络数量是相同的。8位的FlowID使得管理程序可以在一个虚拟网络内部针对不同的数据流进行更加细粒度的操控。FlowID应该由NVGRE端点(NVE)来生成并添加,在网络传输过程中不允许网络设备修改。如果NVE没有生成FlowID,那么该域必须置零。另外,因为NVGRE内部封装的是以太网帧,所以GRE头中的protocol type域一定要设置为0x6558(transparent Ethernet bridging,透明以太网桥)。

图 8. 采用NVGRE封装的数据包头格式
4.STT
STT(Stateless Transport Tunneling),无状态传输隧道技术,是在数据中心2层/3层物理网络上创建2层虚拟网络的又一种Overlay技术。在进行数据封装时使用了无状态的类TCP头(TCP-like Header),因此可以认为其是一种MAC-in-TCP方式。使用类TCP头的好处在于可以利用网卡的一些硬件下放机制来提高系统性能,例如TSO(TCP Segmentation Offload)和 LRO(Large Receive Offload)。利用TSO技术,我们可以将TCP分片工作下放到网卡。由网卡来完成大包地分片,以及复制MAC、IP、TCP包头等工作。相反,所谓的LRO技术,即是接收端利用网卡将分片合并成一个大包之后再生成一个中断并发送给操作系统。TSO和LRO的好处是明显的。首先,通过传输大包的方式减少了系统中断的次数,从而减少中断开销。其次,封装的开销(封装头)可以均摊到多个MTU大小的数据包上,所以数据传输的有效性也可以大幅提升。为了利用网卡的这种加速特性,STT的封装头模拟了TCP的格式,但是STT并没有维护TCP的连接状态。例如,在使用STT发送数据之前不需要进行三次握手,并且TCP的拥塞控制机制等等也不会起作用。虽然STT可以利用网卡加速来提升系统性能,但是由于其没有维护TCP的状态信息,所以其也会遇到一些问题。例如,某些系统中可能会使用一些中间盒(middlebox),但是由于有些中间盒会检查数据流的四层会话状态,所以会导致无状态的STT流无法通过这些中间盒。当然这个问题,采用MAC-in-IP的NVGRE方案也同样存在。但是对于MAC-in-UDP的VXLAN方案则不是问题。
如图 9所示,数据包在通过STT发送之前首先需要封装STT帧头。STT帧头的格式如图 10所示,其中各域的含义如下。从这些域的定义我们可以发现,利用STT帧头可以大幅简化接收方的处理进程。例如,接收方可以很容易的通过IP Version域来判断封装内部的载荷数据是IPv4还是IPv6,或者通过TCP payload域来判断载荷数据是否是TCP包。
1)Version:版本,当前需要指定为0
2)Flags:8位,具体定义如下:
- 0位:checksum verified,如果设置为1,则表示被封装的载荷数据包的检验和已经被验证。
- 1位:checksum partial,如果检验和只针对TCP/IP头进行计算,那么此位必须置位。另外,需要说明的是,如果发送方使用TSO,那么此位必须置位。最后,从定义我们可以看出,0位和1位不可能同时为1。
- 2位:IP version,如果载荷数据包是IPv4包,那么该位置位;如果是IPv6包,那么则不置位。
- 3位:TCP payload,如果载荷包采用TCP,那么该位置位。
- 4-7:保留,发送方需要将其置0,接收方需要忽略这4位。
3)L4 Offset:STT帧头尾部距载荷数据包四层头(TCP/UDP)的偏移量。增加这个域的好处在于方便接收方的快速处理。
4)Reserved Filed:发送方需要将其置0,而接收方则会忽略这个字段。
5)Max Segment Size:隧道端点在网络上发送数据时需要采用的TCP MSS大小。
6)PCP:优先级
7)V:如果设置为1,则说明后续的VLAN ID和前述PCP域有效
8)VLAN ID:虚拟网络编号,12位
9)Context ID:64位上下文ID。上下文ID的作用是为了标识STT帧的所有者,所以可以将上下文ID理解为广义的虚拟网络标识符。STT使用64标识符的好处是显而易见的,这使得他可以比VXLAN和NVGRE支持更多的虚拟网络。另外,因为STT是为分片而生,所以可以通过分片将STT首部的开销进行分摊。
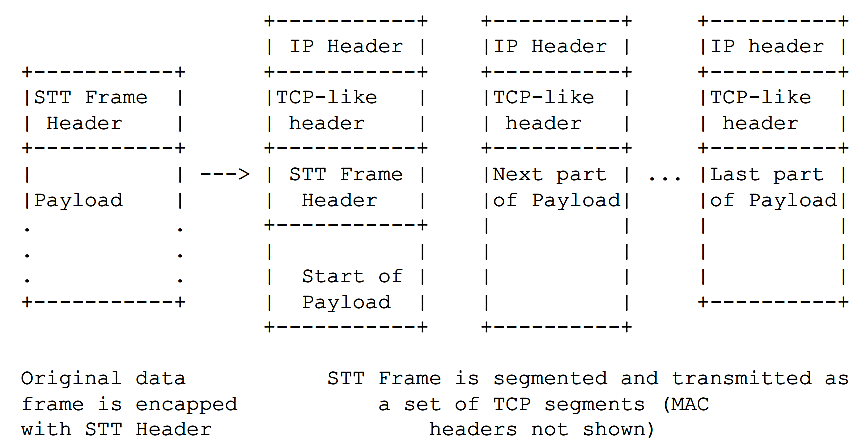
图 9. 使用STT封装的数据包分片后格式

图 10. 分片前的STT帧头格式
就像前面提到的,STT相比于其他封装协议的优势在于可以利用网卡的TCP offload功能来加速数据的传输。而STT实现这个功能的法宝就是在图 9中已经出现的TCP-like头。如图 11所示,STT中所采用的TCP-like头与[RFC0793]中定义的TCP首部是相同的。这里的区别体现在对图 11中用*号标识的两个字段的用法。首先,ACK域被用来标识分片,其在功能上与IPv4和IPv6首部分片中的ID域是一样。对于一个STT数据帧,分片的编号必须是固定的,并且在一定时间之内不同STT数据帧分片的编号不能重复。其次,32位的SEQ域被分为两部分:高16位用于标识整个STT帧的长度(单位字节),而低16位则用于标识当前分片的偏移量。我们可以发现,对于一个STT帧而言,SEQ的高16位是不变的,而低16位则逐渐增大。这使得修改后的SEQ与传统的SEQ的工作方式是一样的。为了保证数据分片的正确组合,一些注意事项必须重点强调。首先,对于一个STT帧,所有分片的源端口必须保持恒定。其次,为了方便实施ECMP等流量均衡策略,针对一个数据流的所有STT帧同样需要具有恒定的源端口号。

图 11. STT分片格式
5.总结
通过上面的介绍,我们可以发现为了构建覆盖网络,我们需要将虚拟网络的数据通过隧道传输。而为了构建隧道,我们需要对原有的载荷数据包进行封装。按照封装的层次不同,可以有MAC-in-UDP(VXLAN),MAC-in-IP(NVGRE),MAC-in-TCP(STT),ANY-in-UDP(VXLAN-GPE)和ANY-in-ANY(GRE)。由于不同协议选取的封装层次不同,所以将具有不同的特点。例如,VXLAN使用标准的UDP协议来进行封装,因此具有最好的通过性。STT虽然使用TCP来进行封装,但是它修改了TCP首部的定义,并且没有维护TCP的状态信息,所以对于某些中间盒而言,STT数据帧将无法通过。NVGRE因为使用的是IP封装,所以对于某些需要四层状态信息的中间盒而言,NVGRE数据包也将无法通过。本节介绍的是Overlay网络的一些封装技术,但我们在此处需声明,要做到网络虚拟化,并非一定要通过Overlay的方式。例如,上节提到的NEC VTN所采用的Hop-by-hop方式亦是一种选择。Overlay方式是在主机端实现虚拟化,Hop-by-hop方式是在控制器实现虚拟化。Overlay方式下中间网络设备看到的物理网络流量,隐藏了虚拟机流量,Hop-by-hop方式网络设备看到的是虚拟机流量(即虚拟机可见),从而网络设备可对虚拟机流量做一些QoS操作。但是同时,对Hop-by-hop方式而言,网络设备需维护虚拟机级别的网络状态信息。若网络中虚拟机非常多,则这个开销也是不容忽视的。
参考文献
[1]Virtual eXtensible Local Area Network (VXLAN): A Framework for Overlaying Virtualized Layer 2 Networks over Layer 3 Networks RFC7348 ,http://datatracker.ietf.org/doc/rfc7348/
[2]Generic Protocol Extension for VXLAN, http://tools.ietf.org/html/draft-quinn-vxlan-gpe-04
[3]M. Sridharan, et al., “NVGRE: Network Virtualization using Generic Routing Encapsulation-- draft-sridharan-virtualization-nvgre-08”, April, 2015.
[4]Brad McConnell, et al., “A Stateless Transport Tunneling Protocol for Network Virtualization-- draft-davie-stt-01”, March, 2012.
A Stateless Transport Tunneling Protocol for Network Virtualization (STT) ,http://datatracker.ietf.org/doc/draft-davie-stt/
作者简介:
付斌章(博士),男,中国科学院计算技术研究所副研究员,主要研究方向为大规模计算机系统高性能互连网络,包括数据中心网络和片上网络等。
吴洁,女,中国科学院计算技术研究所,硕士研究生,主要研究方向为数据中心网络虚拟化.
刘静一,女,华中科技大学,硕士研究生,主要研究方向为数据中心网络虚拟化.注: 该文为其在中科院计算所实习期间工作.

