

C#爬虫系列(一)——国家标准全文公开系统
网上有很多Python爬虫的帖子,不排除很多培训班借着AI的概念教Python,然后爬网页自然是其中的一个大章节,毕竟做算法分析没有大量的数据怎么成。
C#相比Python可能笨重了些,但实现简单爬虫也很便捷。网上有不少爬虫工具,通过配置即可实现对某站点内容的抓取,出于定制化的需求以及程序员重复造轮子的习性,我也做了几个标准公开网站的爬虫。
在学习的过程中,爬网页的难度越来越大,但随着问题的一一攻克,学习到的东西也越来越多,从最初简单的GET,到POST,再到模拟浏览器填写表单、提交表单,数据解析也从最初的字符串处理、正则表达式处理,到HTML解析。一个NB的爬虫需要掌握的知识不少,HTTP请求、响应,HTML DOM解析,正则表达式匹配内容,多线程、数据库存储,甚至有些高级验证码的处理都得AI。
当然,爬爬公开标准不是那么难,比如国家标准全文公开系统。
整个过程需要爬以下页面:
- 列表页
- 详细信息页
- 文件下载页
需要处理的技术问题有:
- HTTP请求
- 正则表达式
- HTML解析
- SqlLite数据库存储
一、列表页
首先查看到标准分GB和GB/T两类,地址分别为:
http://www.gb688.cn/bzgk/gb/std_list_type?p.p1=1&p.p90=circulation_date&p.p91=desc
和
http://www.gb688.cn/bzgk/gb/std_list_type?p.p1=2&p.p90=circulation_date&p.p91=desc。
从中可以看出,GET请求的查询字符串参数p1值为1和2分别查询到GB和GB/T。因此,要获取到标准列表,向以上地址发送GET请求即可。

HttpWebRequest httprequst = (HttpWebRequest)WebRequest.Create(Url); HttpWebResponse webRes = (HttpWebResponse)httprequst.GetResponse(); using (System.IO.Stream stream = webRes.GetResponseStream()) { using (System.IO.StreamReader reader = new StreamReader(stream, System.Text.Encoding.GetEncoding("utf-8"))) { content = reader.ReadToEnd(); } }
标准共N多页,查看第二页标准列表,地址更改为:
http://www.gb688.cn/bzgk/gb/std_list_type?r=0.7783908698326173&page=2&pageSize=10&p.p1=1&p.p90=circulation_date&p.p91=desc。
由此可见page参数指定了分页列表的当前页数,据此,循环请求即可获取到所有的标准列表信息。
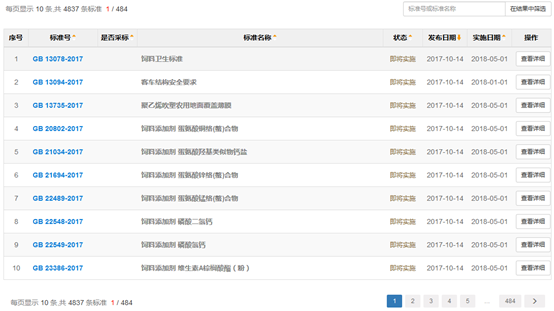
二、详细信息页
获取到标准列表后,下一步我需要获取到标准的详细信息页,从详细信息页中抓取更多的标准说明信息,例如标准的发布单位、归口单位等。
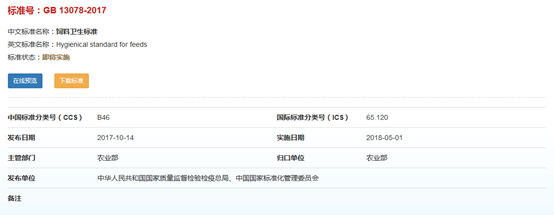
查看标准详细页URL,其值为:
http://www.gb688.cn/bzgk/gb/newGbInfo?hcno=9E5467EA1922E8342AF5F180319F34A0。
可以看出每个标准有个GUID值,在列表页面中点击按钮“查看详细”,转到详细页。实现这个跳转的方式,最简单的是HTML超链接,此外还可以是JS脚本,甚至是POST数据到服务器。不同的链接方式,自然需要不同的抓取方式,因此需要查看列表页源码来分析该站点的实现方式并找到对应的处理方法。

通过分析源码,可以看到在点击标准号时,通过JS的showInfo函数打开详细页面,由于JS方法传递的ID即为详细页面的参数ID,因此没必要去模拟onclick执行JS函数,直接解析到该GUID,GET请求详细页面即可。解析该GUID值,可以通过正则表达式方便的抓取到。
获取到详细信息页面后,要解析其中的内容,此时使用正则表达式解析就比较费劲了,可以采用HTML解析。C#解析HTML的第三方类库有不少,选择其中一款即可,HtmlAgilityPack或Winista.HtmlParser都是比较好用的。
三、文件下载页
解析到标准详细信息后,还需要进一步获取到标准PDF文件,分析详细页面可以看到标准文件下载页面路径为:
http://c.gb688.cn/bzgk/gb/showGb?type=download&hcno=9E5467EA1922E8342AF5F180319F34A0

进一步分析PDF文件的URL为:
http://c.gb688.cn/bzgk/gb/viewGb?hcno=9E5467EA1922E8342AF5F180319F34A0。
仍然是那个GUID值,因此可以直接GET请求该地址即可下载标准PDF文件。
至此标准的属性信息和标准PDF文件都可以下载到了,然后需要将这些信息存储起来。存储为SQL Server、Oracle自然比较笨重,即使Excel和Access也不大友好,推荐此类临时存储可以使用SqlLite。


string connectionString = @"Data Source=" + dbBasePath + "StandardDB.db;Version=3;"; m_dbConnection = new SQLiteConnection(connectionString); m_dbConnection.Open(); SQLiteCommand command = new SQLiteCommand(sql, m_dbConnection); command.ExecuteNonQuery(); m_dbConnection.Close();
作者:马洪彪
出处:http://www.cnblogs.com/mahongbiao/
本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接,否则保留追究法律责任的权利。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· winform 绘制太阳,地球,月球 运作规律
· AI与.NET技术实操系列(五):向量存储与相似性搜索在 .NET 中的实现
· 超详细:普通电脑也行Windows部署deepseek R1训练数据并当服务器共享给他人
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 上周热点回顾(3.3-3.9)