

可扩展的Zabbix – 9400NVPS经验分享
The Future of Monitoring
可扩展的Zabbix – 9400NVPS经验分享
对于我们这些大规模使用Zabbix的用户来说,最关心的问题之一就是:Zabbix能承受多大规模的数据写入量?我最近的一些工作正好以此为中心,远期来看,我可能会有一个超大量级的环境(大约32000+台设备)需要通过Zabbix实现完全监控。在Zabbix论坛里有一个模块讨论大型环境的监控,但是不走运的是,我并没有找到一个完善的系列解决方案来实现大型环境的监控。
在此,我想为大家展示一下我是如何配置来处理大规模环境监控的。下图是我当前环境的一些统计数据:
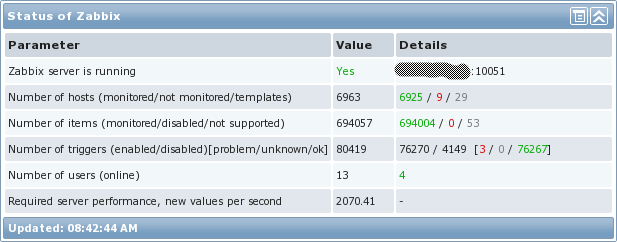 大型Zabbix环境的统计信息
大型Zabbix环境的统计信息
需要指出的一点是“ Required server performance”参数这一栏的实际意思,并不代表有多少数据实际上进入了Zabbix。它只是计算Zabbix通过查找每个项监控采集时间间隔估算每秒值个数。由于Zabbix采集器监控项没有指定采集间隔,他们不被包含在计算中。在我自有的环境中,我很大程度上地使用了Zabbix采集器监控项,所以这就是我的环境实际上处理了多少NVPS(每秒新值)。
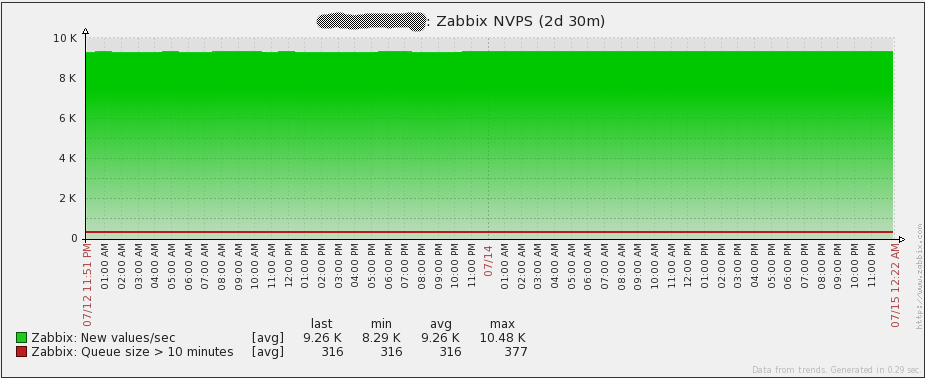
正如报表所示,在2天时间内,Zabbix Sever平均处理大约9.26k的NVPS。实际上我有短暂的峰值一直到大约15k,sever照样处理的很好。总之非常好!
架构
首要问题之一是考虑所使用的架构类型。Zabbix server需要高可用吗?一两个小时的宕机时间有关系吗?如果Zabbix数据库down了,会导致什么后果呢?Zabbix的数据库需要怎样的磁盘类型和raid模式呢?Zabbix server和Proxies之间是哪种网络类型呢?是否有大量的潜在因素。数据怎么进入Zabbix-数据是被动采集或者主动采集。
我将详细介绍我如何解决这些问题。当我开始学习搭建我的Zabbix环境时,我并没有关于网络和延迟的认识。但是正如你现在所见,忽视这些问题将导致一些很难弄明白的问题。下面是我使用的架构图解:
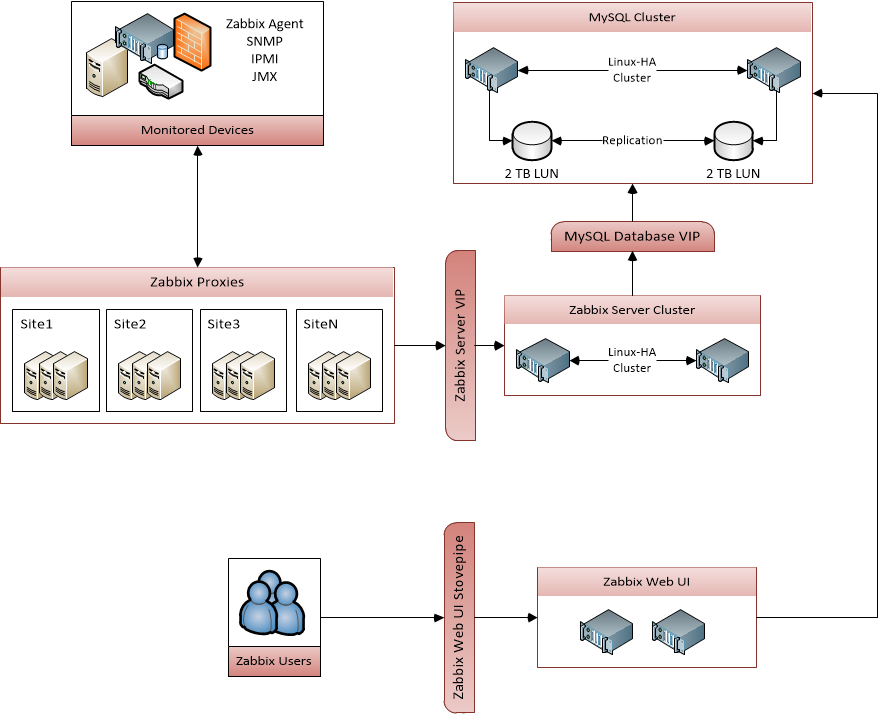
硬件
甄别合适的硬件资源并不简单。在该小节的底部,我列出了我使用的硬件信息,仅供参考。Zabbix数据库需要大量的I/O处理能力,所以我给我的数据库选择了高性能的SAN空间。理论上,数据库磁盘处理越快,Zabbix可以处理越多的数据。并且cpu和内存对于一个mysql数据库而言是很重要的。较大的内存允许Zabbix在内存中迅速的访问数据从而提升性能。起初我想要给我的数据库server分配64G的内存,但是到目前为止,32G的内存看上去工作的也不错。
在这个性能相当强的Zabbix server背后,我认为有必要评估成千上万的触发器。这将占用一些cpu性能,所以充足的cpu资源有益无害。由于我的Zabbix server上没有跑很多进程(自监控消耗很小),我也可以把内存降低到12G。
Zabbix proxies不需要大量硬件资源,所以我选择了VM虚拟机。我主要使用主动类型监控项,我的Proxies大多情况作为收集点使用,其自身不用去收集大量的数据。
| Zabbix server | Zabbix database |
|---|---|
| HP ProLiant BL460c Gen8 12x Intel Xeon E5-2630 16GB memory 128GB disk CentOS 6.2 x64 Zabbix 2.0.6 |
HP ProLiant BL460c Gen8 12x Intel Xeon E5-2630 32GB memory 2TB SAN-backed storage (4Gbps FC) CentOS 6.2 x64 MySQL 5.6.12 |
| Zabbix proxies | SAN |
|---|---|
| VMware Virtual Machine 4x vCPU 8GB memory 50GB disk CentOS 6.2 x64 Zabbix 2.0.6 MySQL 5.5.18 |
Hitachi Unified Storage VM 2x 2TB LUN Tiered storage (with 2TB SSD) |
服务器高可用
现在让我们来考虑下Zabbix server的架构。通常在一个大型的环境中,我们无法忍受监控服务器长时间的宕机(超过几分钟)。由于Zabbix server进程的运行方式,不能同时运行多个Zabbix server实例。围绕着该问题,我使用Pacemaker和CMAN组件实现Linux高可用。作为安装时的基础,你需要了解RedHat 6.4的快速指南(←点击查看详情),不巧的是,我上次使用之后,这个指南就已经更改了,但是我可以将我最后一次配置的客户端结果分享给你们。以下是配置高可用需要的四个服务:
- 共享的IP地址
- 在发生故障时,IP将与之前的server失去关联同时在新活动的server使用
- 这个IP地址总是与活动的服务器关联。有以下三点好处。
- 更便于发现哪台server是活动的
- 来自活动的Zabbix server的所有连接都来自相同的IP(通过在zabbix_server.conf中设置“SourceIP”配置)
- 可以将所有的proxies/agents配置为简单地就能共享IP地址以访问活动的Zabbix server
- Zabbix server 进程
- 在发生故障时,在之前的sever上的zabbix_server进程将会停止,并在新的活动的server上启动
- 一个符号链接的crons
- 这指向一个目录,该目录包含的只在活动的server上运行的crons。每个server上的crontab应该通过此符号链接访问所有的crons。
- 在发生故障时。符号链接将先在之前的server上删除,并且在新的活动的server上创建。
- Cron进程(crond)
- 在发生故障时,crond守护程序将在之前的server上停止,并在新的活动的server上启动。
可以在此处下载(←点击下载)所有这些样本配置文件和LSB兼容的Zabbix server init脚本。在样本配置文件中需要修改一些参数(包含在“<>”标签内)。此外,编写init脚本的想法是所有的Zabbix文件都放在一个公共的区域(对我来说,所有的文件都在“/usr/local/zabbix”)。如果不是这种情况,你需要自行修改一下init脚本。
数据库高可用
如果数据库很容易就出现故障,那么高可用的Zabbix sever进程就没有多大用处。高可用MySQL有很多种方法——这里只介绍我采用的方法。
我也使用Pacemaker和CMAN的Linux高可用方式实现数据库高可用。我发现它有一些非常好的功能来管理MySQL复制。我使用(请参阅本文的“待解决的问题”部分)复制来维护我的主动和被动MySQL server之间的同步。有关于执行Linux高可用基本安装的文档链接,请参考上文关于Zabbix server高可用的部分。这是我关于我的数据库高可用的一些想法:
- 共享的IP地址
- 在发生故障时,IP将与之前的sever失去关联同时在新活动的server使用
- 这个IP地址总是与活动的服务器关联。有以下两点好处。
- 更便于发现哪台server是活动的
- 在故障发生时,Zabbix服务器不需要做出改变去表明新活动的数据库。
- 备份IP地址
- 当Zabbix数据库只可以通过只读方式访问,必须使用这个IP。这样点对点的类型事件使用备份的IP地址(如果他是up的)代替了主up
- 这个IP地址并不是在主server或者备server上。它完全是由以下信息决定的:
- 如果备份server在线并且其MySQL比起主服务器没有超过60s的延时,IP将在备份server上。
- 如果备份server离线或者比起主服务器有超过60s的延时,IP将在主server上。
- MySQL进程(mysqld)
- 故障发生时,最新活动的MySQL实例成为主MySQL,一旦最新的备份server变成可用了,MySQL将变成新主机的备份。
可以在此处下载(←点击下载)所有这些样本配置文件和LSB兼容的Zabbix server init脚本。在样本配置文件中需要修改一些参数(包含在“<>”标签内)。此外,为了使其正常工作,你可能需要下载不同的MySQL 资源agent以与pacemaker一起使用。在Percona github存储库(←点击查看详情)中使用pacemaker设置MySQL主/从集群的一些很不错的文档中可以找到它的链接。如果文档的链接由于一些原因失效了,可以在此处(←点击下载)获取副本。
Zabbix Proxies
对于之前没有接触过Proxy的读者,我强烈建议您去手册里学习了解,Proxy真的很棒!Zabbix server在众多的机器中分出来一部分来给Proxies监控。Proxies之后将所有收集到的数据发送给Zabbix server。关于Zabbix proxies,你还应该知道的有很多:
- 搭建好Proxies后,他们可以处理海量的录入数据。在测试期间,我有一个服务器(proxy A)处理了大约1500-1750 NVPS,没有发现异常。它是一个用SQLite3的数据库,2vCPU和4GB内存。“proxy A”和Zabbix server在同一数据中心因而不存在潜在的延迟。“proxy A”忙于处理这些指标信息,但是proxies和被监控对象之间有很少量的网络问题,Zabbix server可以处理大量的数据,注意“proxy A”是一个活动的proxy,它所监控的大部分监控项来自于活动的Zabbix agent监控项。
- 还记住早些时候我怎么告诉你们proxies和Zabbix server之间的网络延迟的吗?我保证没有开玩笑。我发现Zabbix proxy处理的数据量与发送到Zabbix server的数据量近乎相等,这是一个网络延迟的函数。我有一个监控项跟踪proxy发送到Zabbix server的值。如果忽略网络延迟,可能会发生以下情况:
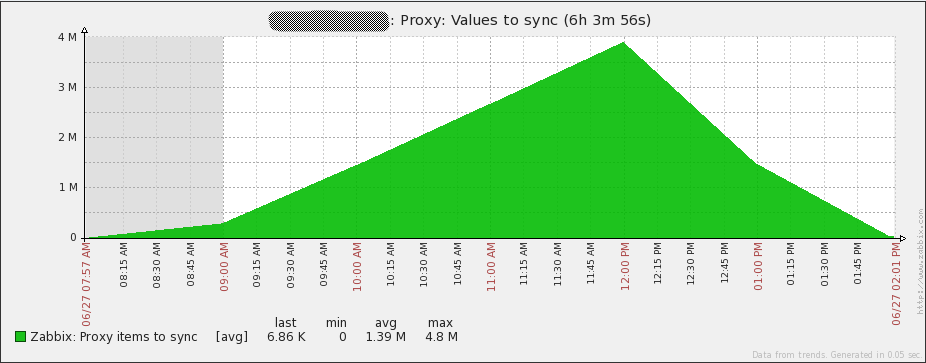 A proxy that cannot keep up
A proxy that cannot keep up
显而易见地,一个proxy需要传递给持续运行的server无数的值。“proxy b”采集大约500nvps的数据。还记得之前和Zabbix server处在同一数据中心的Proxy,它可以处理3-3.5倍的数据量吗?Proxy到Server之间不大可能有严重的延迟的。“proxy B”在新加坡,而Zabbix server在南美。两个server之间的网络延迟大约在230ms。考虑到proxy发送数据到server的处理方式,网络延迟会有很大的影响。在这种情况下,“proxy b”每2-3秒钟能仅仅发送1000收集的值到Zabbix server上。下面我将要告诉你的是在尝试发送数据到server上所发生的事情:
- proxy与server之间建立连接
- proxy最多发送1000个值
- proxy关闭连接
所有这些步骤都根据需要执行多次.由于存在两个主要问题,因此延迟时间很长:
- 初始连接慢,在这个情况下,建立初始连接发费至少0.25s,天啊!
- 在发送1000个值后连接会关闭,因此TCP连接不会存在这么长时间的连接去加速链路上可用的带宽。
这个真的是很慢了,对比之下,Proxy A在相同的虚拟硬件下,2-3秒内发送40000个值,表现更佳!
数据库性能
由于Zabbix使用数据库存储所有数据,因此数据库性能对于可扩展的解决办法绝对至关重要。显然由于大量数据写入到数据库server里,I/O性能是最容易受到影响的瓶颈之一。我非常幸运地有固态硬盘的SAN,但仅仅因为我有快速的I/O并不意味着我的环境不受数据库问题的影响!例子如下:
当我开始在我的大型环境中研究Zabbix的用处的时候,我跑的是MYSQL5.5.18,数据库跑了一段时间后,一旦我运行了大约700-750的NVPS时,我server上的MySQL进程就将占用100%的CPU,数据库性能停滞不前。我尝试在数据库中配置设置,启用large pages(←点击查看详情),分区表,调整不同的Zabbix设置。比我聪明的多的妻子建议将MySQL升级到5.6看看会发生什么。令人惊讶的是,升级之后的数据库性能太完美了。我从来没有使用5.5.18工作过,但5.6.12在我目前的环境中运行良好。作为参考,这是my.cnf 文件(←点击查看详情)的副本。
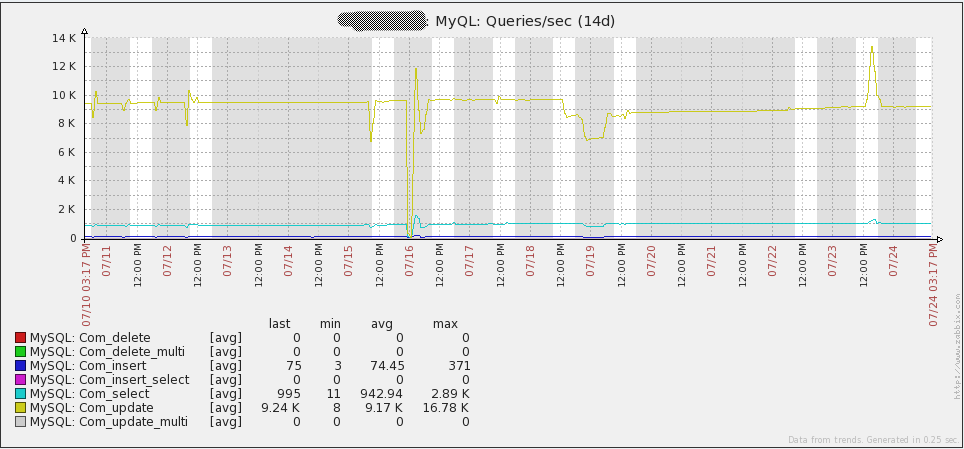
下图显示了我的环境中每秒运行的查询数:
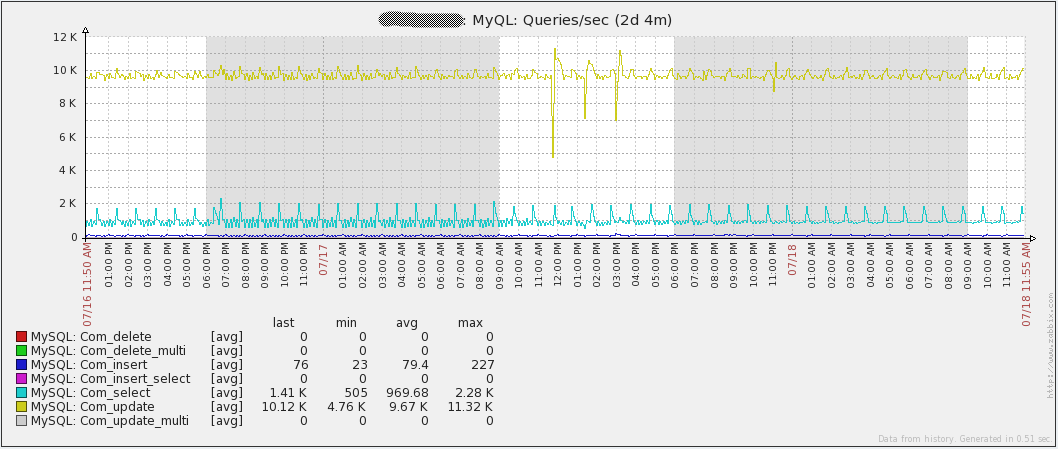 Large environment Queries/sec
Large environment Queries/sec
注意,“Com_update”每秒的查询数最多。原因在于Zabbix检索的每个值都会导致数据库中“items”表的更新。另外要指出的是数据库写入占比很大。这意味着MySQL的查询缓存对于性能提升没有帮助。实际上,由于修改的数据在查询时标记为无效,因此可能会导致性能的下降。
另一个在大型环境中可能摧毁数据库性能的是Zabbix Housekeeper。强烈建议在大型环境中关闭Zabbix Housekeeper。可以将“Zabbix_server.conf”(←点击查看详情)中的“DisableHousekeeping”设置为“l”来实现。当然,如果没有Zabbix Housekeeper,则不会删除任何历史/事件/动作数据。解决此限制的方法之一是在数据库上启用分区。对于我来说,这就是我的MySQL。MySQL 5.6.12的一个限制是分区不能用于具有外键的表。不幸的是,外键在Zabbix2.0.x使用的很多,但历史数据表中没有。对历史数据表进行分区有2个好处:
- 在其自己的分区中自包含表中特定日/周/月的任何历史数据。这样以后可以轻松删除旧数据,几乎不会对数据库server产生任何影响,并且无论你的分区时间范围是多少,都可以查看到该环境下提取了多少数据量。
- 使用MySQL InnoDB表,删除数据不会释放磁盘空间。 它只是在InnoDB命名空间中创建区域,以后可以保存新数据。 缩小InnoDB命名空间是不可能的,但是可以随意删除分区。 删除分区将会释放磁盘空间。
学习怎么分区可能很烦,但是在Zabbixzone.com(←点击查看详情)上有一篇很好的关于分区表的文章。可以通过修改历史记录和趋势表的指令来应用到2.0x。其他用户对该文章的很多评论都很有用,并且修改了帖子中出现的原始程序的版本。此处(←点击查看详情)提供了用于添加/删除分区的存储过程的副本。这些过程创建每日的趋势/历史记录分区,并且是Zabbixzone.com上的文章中的过程修改后的版本。请注意在你使用存储过程之前,必须先在历史数据表中创建分区。此外,我的程序版本永远不会删除“trend”或者“trend_unit”分区,我的趋势数据理论上永远存在。
轮询或者
Zabbix提供两种不同的获取数据的方法:主动或被动(←点击查看详情)。如果你不清楚区别是什么,请认为就像Zabbix server/proxies从Zabbix agents中获取被动类型监控项的数据,Zabbixagents中Zabbix agent(active)类型监控项的数据推送给Zabbix server/proxies。根据定义,Zabbix采集器(←点击查看详情)类型的监控项是主动式的,因为他们需要将数据发送到Zabbix server/proxies(使用“Zabbix_sender”或其他一些方法)。
我之所以提到这一点,是因为所使用的监控类型会对Zabbix成功获取的数据量产生巨大的影响。被动检测需要Zabbix server/proxies上的一个轮询进程向代理发出请求,然后等待响应。根据你的网络和正在检测的server的性能,轮询器可能需要几秒钟才能获得响应。即便只访问一千台servers,也可以将轮询转换为一个非常缓慢的过程。
现在让我们来谈谈主动监控。通过主动监控,Zabbix server/proxies只需等待来自Zabbix agent的连接。每个单独的代理将定期连接到Zabbix server/proxies来获取需要检测的项目列表。之后proxies将根据其监控项采集间隔发送数据。只有当agent实际上有数据需要发送的时候,和server/proxies之间的连接才会建立起来。这种监测方法可以防止ZABBIX server/proxies在获取数据之前需要等待检测完成。这样可以提高获取数据的速度。在我的环境中我是这样使用的。
server/proxy监测
我直截了当地说–如果你认为在不监测内部服务器进程的情况下可以适当地进行Zabbix安装,你就错了。你必须监测这些进程以了解任何瓶颈的位置,缩减规模以节省资源。有关这些监控项的文档在这里(←点击查看详情)可以找到。关于这些监控项的好blogpost也在Zabbix的博客(←点击查看详情)上。Zabbix 2.0.x附带的默认Zabbix server模板已经配置了这些项。确保将这些项添加到Zabbix server上!
可以表明数据库问题的统计信息之一是历史写入缓存(server配置文件中的“HistoryCacheSize)变量。此条目的值应始终接近100%,如果此缓存持续变满,这意味着Zabbix无法足够快地将传入数据写入数据库。
不幸的是,proxies不支持这些监控项,这使得识别问题的位置变得有点困难。proxies的另一个问题是Zabbix中没有内置键值追踪proxy还有多少数据没有同步到server。值得庆幸的是,有一种方法可以监控代理的落后程度。很有必要对数据库执行一条查询语句:
SELECT ((SELECT MAX(proxy_history.id) FROM proxy_history)-nextid) FROM ids WHERE field_name='history_lastid'
查询将返回proxy仍需要发送到Zabbix server的值的数量。如果您碰巧使用SQLite3作为proxy的数据库,只需将此命令作为UserParameter添加到proxy上的agent配置文件中:
UserParameter=zabbix.proxy.items.sync.remaining,/usr/bin/sqlite3 /path/to/the/sqlite/database "SELECT ((SELECT MAX(proxy_history.id) FROM proxy_history)-nextid) FROM ids WHERE field_name='history_lastid'" 2>&1
设置一个触发器,当你的proxy开始备份时进行检测,并且你可以捕获慢速proxies。这里是一个例子:
{Hostname:zabbix.proxy.items.sync.remaining.min(10m)}>100000
整体性能结果
以下是我的server的一些性能图表。7月16日你会注意到一些峰值/波动,我不确定那个事件里发生了什么。我不得不在我的proxies上重新初始化数据库来解决事件(我当时使用的sqlite3)。自从将数据库换成MySQL后,我的proxies没有再发现这个问题。图中的其它峰值来自负载测试。通过查看这些图表,很容易看出我使用的硬件在未来一段时间后可能会过度。
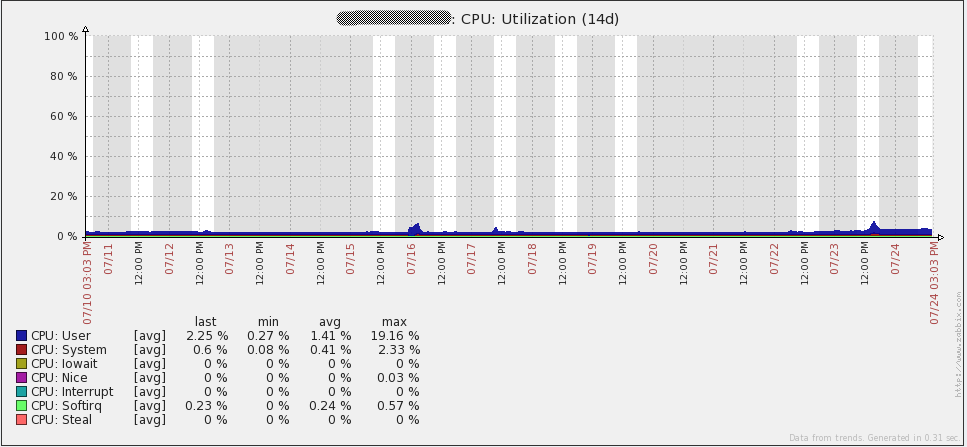
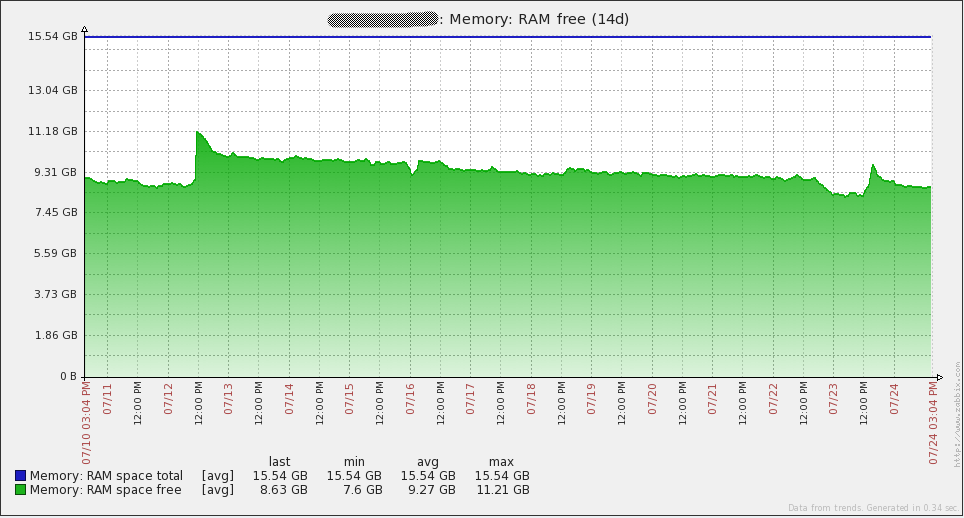
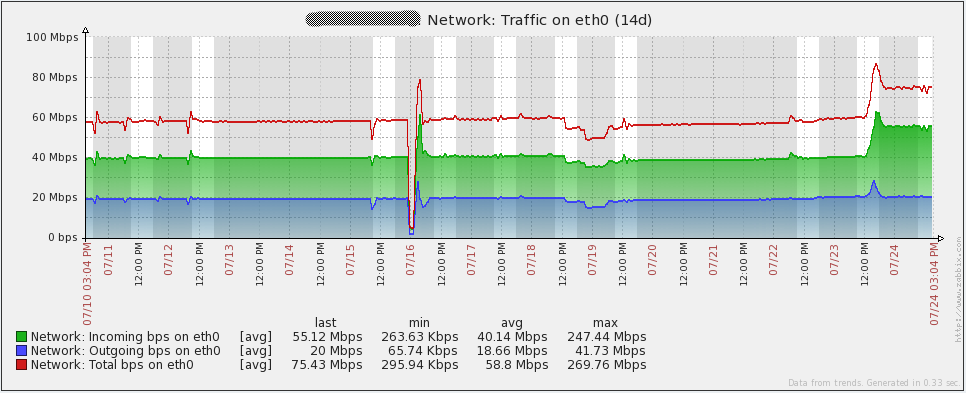
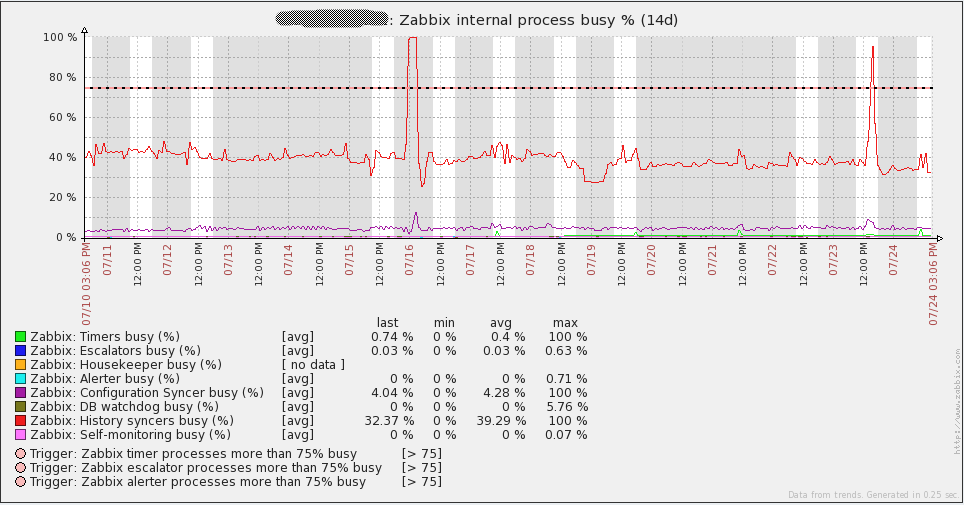

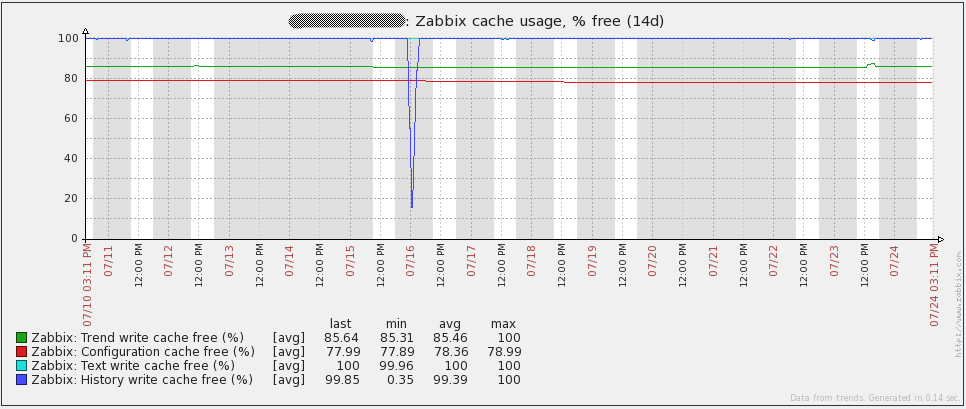
以下是我的数据库server的性能图表。你将注意到每1到2天在网络流量上的大幅增长。那些是我的数据库备份运行时发生的(mysqldump)。由于我上面提到的问题,你还会在16日的每秒查询图表中看到大幅下降。
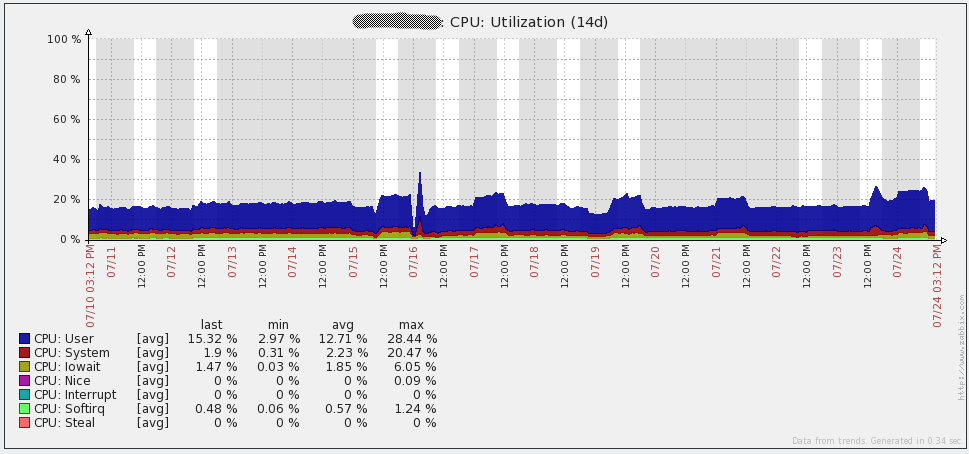
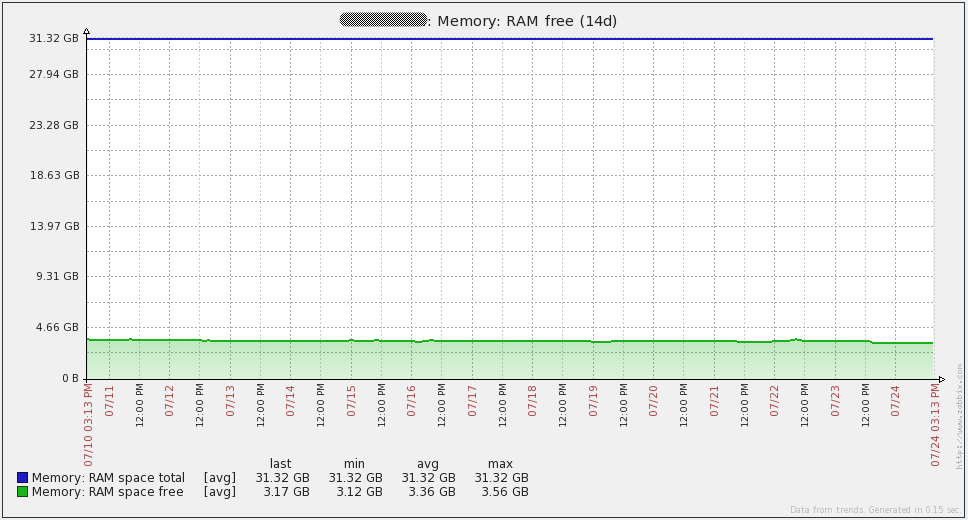
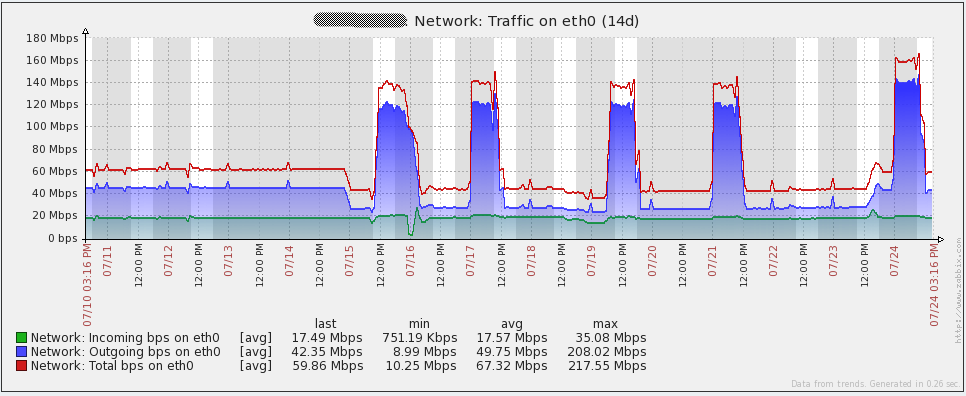
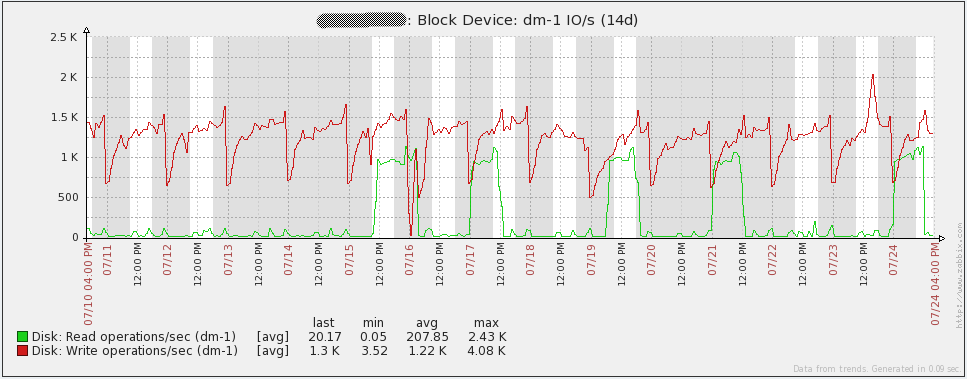
配置管理
我当前的环境总共有2台Zabbix server,2台MySQL servers,16台Zabbix proxies和数千个Zabbix agents。有这么多的server需要管理,手动更改配置文件并不是一个真正的选择。我公司目前使用Puppet来部署应用程序,但目前尚未设置配置管理。因此我必须以自己的方法来管理开发,分期和生产环境中的配置文件。
值得庆幸的是,我可以访问git来存储所有配置文件。我的所有servers都可以访问该git,因此我利用它来存储任何脚本,配置文件或者我希望在servers之间同步的任何其它内容。我写了一个脚本可以通过所有agents上可用的自定义参数调用。当我调用自定义脚本时,它会自动转到git,拉取所有最新文件,修改配置文件后重启agent/proxy/server。通过这种方式,对我的整个环境进行更改就像使用“Zabbix_get”命令一样简单。
除了管理配置文件外,在Zabbix中手动创建数千个主机不可行。我公司有一个CMDB来存储有关我们所有服务器及其上面运行的服务器信息。我有另一个脚本每小时从CMDB中拉取信息,然后再与Zabbix中的内容进行比较。然后它将根据需要增加/删除/启动/禁用主机,创建主机组,移动主机到主机组,给主机分配模板。通过这种方式,添加我需要关注的主机的唯一部分就在于是否需要实现新的监控项/触发器。
然而,由于们与我们的系统紧密集成,我不能在这里发布脚本。
需要解决的问题
即使我们已经完成了所有工作,仍然有一个重要问题需要解决。
一旦我达到了8000-9000 NVPS,我的数据库复制将不能与主机同步。实际上,这使得高可用在我的数据中不存在。关于高可用的这一点,我有一些想法,但没有实际测试/实现他们中的任何一个,以下是我的一些想法。
- 将Linux高可用与DRBD一起用于我的数据库分区
- 在SAN上设置LUN复制,以将所有更改复制到另一个LUN上
- 采用Percona XtraDB集群。 5.6版本还没有发布,所以我不得不等待尝试这个选项(因为我的MySQL 5.5存在性能问题)
参考文献
以下是在这篇文章中全部引用的下载/URL列表
- Zip file with all downloads from the article (also includes my Zabbix configuration files)
- Large environment forum thread
- Zabbix server configuration documentation
- Zabbix proxy distributed monitoring documentation
- Zabbix active/passive item documentation
- Zabbix internal item documentation
- Zabbix blogpost on internal items
- Pacemaker/CMAN quickstart guide
- MySQL Pacemaker configuration guide
- MySQL Large Pages
- Partitioning the Zabbix database

