[C语言]声明解析器cdecl修改版
一、写在前面
K&R曾经在书中承认,"C语言声明的语法有时会带来严重的问题。"。由于历史原因(BCPL语言只有唯一一个类型——二进制字),C语言声明的语法在各种合理的组合下会变得晦涩难懂。不过在15级的优先级规则加持下,C语言的声明仍然有迹可循。这篇文章讲解了一个通常取名为"cdecl"(不同于函数调用约定)的小型程序,该程序常用来解析C语言的声明。本程序的基始版本来源于《C专家编程》p75,约140行代码。
博主在这个程序的基础上,增加了两个模块的功能:
1、struct/enum/union关键字后标签与变量名的甄别
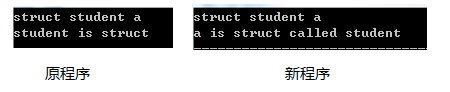
有如下声明:struct student a; 在这个声明中student是作为struct后可选的"结构标签"出现的,a才是变量名称。
2、函数参数的处理
源程序略过了函数参数处理的模块,在此,我们加入了此功能,尽管有些简化。

二、声明的组成部分
通常情况下来讲,一个C语言声明由三部分组成:类型说明符+声明名称(declarator)+分号,如int a;

三、优先级规则
1、声明从它的名字开始读取,随后按照优先级顺序依次读取。
2、优先级从高到低依次是:
2.1、声明中被括号括起来的那部分
2,2、后缀操作符:
符号 () 表示这是一个函数
符号 [] 表示这是一个数组
2.3、前缀操作符:*代表"指向...的指针"
3、如果const/volatile关键字后面紧跟类型说明符(如int),那么该关键字作用于类型说明符。在其他情况下,const/volatile关键字作用于它左边紧邻的指针星号。
因此运用该规则分析如下声明:char *(*c[10])();
第一步:找到变量名c
第二步:处理c后的[10],表示"c是一个有10个元素的数组"
第三步:处理c前的*,表示"数组元素为指针"
第四步:处理c所在括号后的括号,表示"数组的元素类型是函数指针"
第五步:处理(*c[10])前的星号,表示"数组元素指向的函数的返回值是一个指针"
第六步:处理char,表示"数组元素指向的函数的返回值是一个指向char的指针"
综上,该声明表示:C是一个有10个元素的数组,数组元素类型是函数指针,其所指向的函数的返回值是一个指向char的指针。
四、程序执行流程
由于C语言声明并不可以从左往右直接解析,所以我们需要一个栈结构来保存在读取到声明名称前的所有字段,以便在读取到id后再分析。
-
struct token{
-
char type;
-
char string[MAXTOKENLEN];
-
};
-
struct token stack[MAXTOKENS];
将所有字段分为三类:名称、类型以及限定词,使用枚举类型,使之与char type对应。
-
enum type_tag {
-
IDENTIFIER,QUALIFIER,TYPE
-
};
主函数有两大功能,一是找到identifier,二是处理剩下的声明。
-
int main (void)
-
{
-
read_to_first_identifier();
-
deal_with_declarator();
-
-
return 0;
-
}
第一个函数从左往右读入输入数据,一个读取一个字段(声明的基本单位),若字段不是id(标识符),则将其压入栈中,再读取下一个字段,直到读取到字段,该阶段任务结束。
第二个函数在得到id后开始工作。根据语法规则,先读取id后的字符,判断其为数组还是函数。在处理完id后的字段后,再依次出栈解析前面的声明。

五、各模块代码
5.1、读取标识符:read_to_first_identifier();
使用一个循环,每次读取一个字段,并判断其是否为标识符,是,则退出,并输出。对于正在读取的标识符,使用一个全局变量struct token thistoken存储,在处理完该字段后,若其不为标识符,则压入栈中。
-
void read_to_first_identifier()
-
{
-
gettoken();
-
while(thistoken.type != IDENTIFIER)
-
{
-
push(thistoken);
-
gettoken();
-
}
-
printf("%s is ",thistoken.string);
-
gettoken();
-
}
5.2、读取各字段:gettoken();
我们假设各个含有英文字母的字段(如类型说明符、标识符等)都以空格隔开,因此我们可以从我们读取到的第一个非空字符开始,判断它的类型。标识符前的符号有一下几种:说明符、指针(*)。所以我们将其单独处理。
-
void gettoken()
-
{
-
char *p = thistoken.string;
-
-
while((*p = getchar()) == ' ');
-
-
if(isalnum(*p))
-
{
-
while(isalnum(*++p = getchar()));
-
ungetc(*p,stdin);
-
*p = '\0';
-
thistoken.type = classify_string();
-
return ;
-
}
-
-
if(*p == '*')
-
{
-
strcpy(thistoken.string,"pointer to");
-
thistoken.type = '*';
-
return ;
-
}
-
thistoken.string[1] = '\0';
-
thistoken.type = *p;
-
return ;
-
}
对于标识符及声明符,我们在读取完一个字段后就判断其类型。对于'*'或其他符号('(''['等),则直接用符号本身作为其类型。
5.3、解析字段类型:classify_string ();
在我们提取到完整的英文/数字字段后,通过该函数来推断其类型。通过strcmp()函数,将其与各个类型说明符对比,如果一样,则返回类型说明符,如type/qualifier。与因为用strcmp()函数来比较字符串时,字符串相等,函数返回值为0。为了在相等时得到我们想要的真值,就需要对其进行取反。除了用"!"外,用宏来解决更方便。
-
#define STRCMP(a,R,b) (strcmp(a,b) R 0)
因此,字符串的比较就成了如下形式:
-
if(STRCMP(s,==,"void"))
-
return TYPE;
如果读取到的字段并非限定符或者说明符,则认为其为标识符。
-
enum type_tag classify_string()
-
{
-
char *s = thistoken.string;
-
if(STRCMP(s,==,"const"))
-
{
-
strcpy(s,"read-only");
-
return QUALIFIER;
-
}
-
if(STRCMP(s,==,"volatile"))
-
return QUALIFIER;
-
if(STRCMP(s,==,"void"))
-
return TYPE;
-
if(STRCMP(s,==,"char"))
-
return TYPE;
-
if(STRCMP(s,==,"singed"))
-
return TYPE;
-
if(STRCMP(s,==,"unsinged"))
-
return TYPE;
-
if(STRCMP(s,==,"short"))
-
return TYPE;
-
if(STRCMP(s,==,"int"))
-
return TYPE;
-
if(STRCMP(s,==,"long"))
-
return TYPE;
-
if(STRCMP(s,==,"float"))
-
return TYPE;
-
if(STRCMP(s,==,"double"))
-
return TYPE;
-
if(STRCMP(s,==,"struct"))
-
{
-
check_type_or_id(s);
-
return TYPE;
-
}
-
if(STRCMP(s,==,"union"))
-
{
-
check_type_or_id(s);
-
return TYPE;
-
}
-
if(STRCMP(s,==,"enum"))
-
{
-
check_type_or_id(s);
-
return TYPE;
-
}
-
return IDENTIFIER;
-
}
5.4、解析字段类型:check_type_or_id();
对于类型struct/type/enum,在声明该类型变量时,类型后的字段极有可能是该关键字后可选的"结构标签"。如声明struct student xxx;,student是作为一个结构标签存在。该声明与struct student {内容…}xxx;一致。所以在判断student时,需要看它后面字段的类型。如果struct后两个字段都为标识符,则最后一个标识符才是真的标识符,类型struct/type/enum后的字段则是该类型的另一个名字,如:xxx是一个叫student的结构体。
在该模块的实现上,则是在读取到结构struct/type/enum时,再读取其后的两个标签,再判断,并将真正的标识符及其后的内容返回到输入流中。
-
void check_type_or_id(char *s)
-
{
-
char temp[MAXTOKENLEN] = {'\0'};
-
-
struct token temp_struct_one = thistoken;
-
-
gettoken();
-
struct token temp_struct = thistoken;
-
-
gettoken();
-
struct token temp_struct3 = thistoken;
-
-
if(thistoken.type==IDENTIFIER)
-
{
-
strcat(temp,temp_struct_one.string);
-
strcat(temp," called ");
-
strcat(temp,temp_struct.string);
-
strcpy(s,temp);
-
thistoken = temp_struct3;
-
strcpy(temp_struct_one.string,temp);
-
}
-
else
-
{
-
thistoken = temp_struct;
-
for(int i = strlen(temp_struct3.string)-1;i>=0;i--)
-
{
-
ungetc(temp_struct3.string[i],stdin);
-
}
-
}
-
-
if(thistoken.type>=0 && thistoken.type<=2)
-
{
-
for(int i = strlen(thistoken.string)-1;i>=0;i--)
-
{
-
ungetc(thistoken.string[i],stdin);
-
}
-
}
-
thistoken = temp_struct_one;
-
}
5.5、声明的处理:deal_with_declarator();
在确定了标识符之后,我们就可以处理各种声明、修饰符了。依据优先级规则,我们先需要观察标识符后的符号,以确定其是否是数组/函数;其后还需要处理指针,最后再处理先前被压栈的符号。
在开始该阶段的处理之前,我们观察read_to_first_identifier()函数,在该函数的最后一行,我们确定了标识符后,有进行了一次gettoken(),这次调用即将标识符后的符号读入,因此现在在函数开头我们就可以使用switch()直接选择要处理的情况。
-
void deal_with_declarator()
-
{
-
switch(thistoken.type)
-
{
-
case '[':
-
deal_with_arrays();
-
break;
-
case '(':
-
deal_with_function_args();
-
break;
-
}
-
-
deal_with_pointers();
-
-
while(top >= 0)
-
{
-
if(stack[top].type == '(')
-
{
-
pop;
-
gettoken();
-
deal_with_declarator();
-
}
-
else
-
{
-
printf("%s ",pop.string);
-
}
-
}
-
}
5.6、函数参数的处理:deal_with_function_args();
在《C专家编程》中,没有对函数参数进行处理。在此,我加入了对参数的简单处理。简单处理也即,对于复杂声明的参数,并没有能正确的处理。在我写这个模块时,我有一种对整个程序重构的想法,即将声明的解析抽象成一个独立的函数,现在程序里全局变量对函数功能的拓展限制太大了。
该函数的流程则是,将括号内的字段全部读取并输出,遇到','重新读取输出。普通单一的类型说明符可直接输出(如 int a),而int *a;则无法如此简单处理。由于输出使用的是英语,所以该函数大部分的代码都是在处理不同参数时英语表述的语法问题,如但单参数的'parameter is'与多参数的'parameters are'等语法细节。处理粗糙,不看也罢。
-
void deal_with_function_args()
-
{
-
char str[MAXTOKENLEN] = {'\0'};
-
char para[MAXTOKENLEN] = {'\0'};
-
bool flag_no_para = true;
-
bool para_is_one = true;
-
-
strcat(str,"function");
-
-
gettoken();
-
-
if(thistoken.type != ')')
-
{
-
strcat(str," whose parameter");
-
flag_no_para = false;
-
}
-
while(thistoken.type != ')')
-
{
-
if(thistoken.string[0] == ',')
-
{
-
if(para_is_one == true)
-
{
-
strcat(str,"s are");
-
para_is_one = false;
-
}
-
-
strcat(para," and");
-
}
-
else
-
{
-
strcat(para," ");
-
strcat(para,thistoken.string);
-
}
-
gettoken();
-
}
-
if(para_is_one == true && flag_no_para== false)
-
{
-
strcat(str," is");
-
}
-
strcat(str,para);
-
gettoken();
-
if(flag_no_para == true)
-
{
-
strcat(str," returning ");
-
}
-
else
-
{
-
strcat(str,",it returns ");
-
}
-
printf("%s",str);
-
}
六、一些声明的解析结果



七、写在后面
新增的功能并不尽如人意,不过也将这次的修改探索总结出来,以供后来者学习,希望后来者少踩一些坑,老老实实重构去哈哈哈。
最后….预祝新年快乐~
源码地址:C语言声明解析器修改版源码


 浙公网安备 33010602011771号
浙公网安备 33010602011771号