B 树、B+ 树特点及使用场景
如果有海量的数据,要考虑的是,如何在磁盘中快速找到需要的数据。
今他们的使用场景是:查找磁盘中的大量数据。
B 树
B 树就是常说的“B 减树(B- 树)”,又名平衡多路(即不止两个子树)查找树,它和平衡二叉树的不同有这么几点:
- 平衡二叉树节点最多有两个子树,而 B 树每个节点可以有多个子树,M 阶 B 树表示该树每个节点最多有 M 个子树
- 平衡二叉树每个节点只有一个数据和两个指向孩子的指针,而 B 树每个中间节点有 k-1 个关键字(可以理解为数据)和 k 个子树( **k 介于阶数 M 和 M/2 之间,M/2 向上取整)
- B 树的所有叶子节点都在同一层,并且叶子节点只有关键字,指向孩子的指针为 null
和平衡二叉树相同的点在于:B 树的节点数据大小也是按照左小右大,子树与节点的大小比较决定了子树指针所处位置。
看着概念可能有点难理解,来看看图对比下平衡二叉树和 B 树。
对比平衡二叉树和 B 树
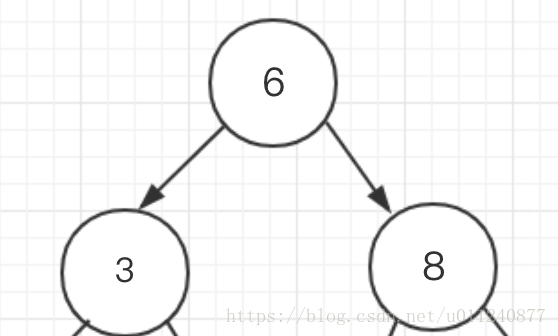
首先是节点, 平衡二叉树的节点如下图所示,每个节点有一个数据和最多两个子树:
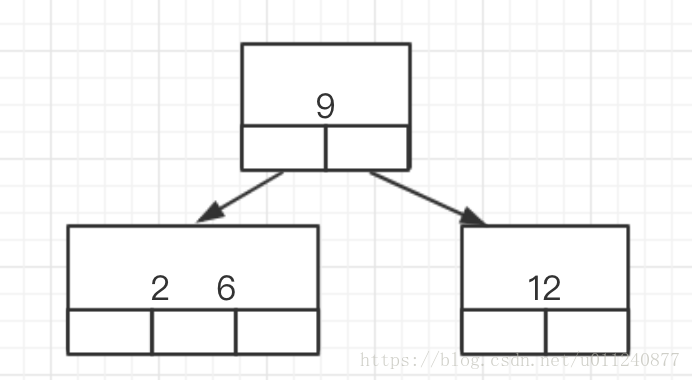
B 树中的每个节点由两部分组成:
- 关键字(可以理解为数据)
- 指向孩子节点的指针
B 树的节点如下图所示,每个节点可以有不只一个数据,同时拥有数据数加一个子树,同时每个节点左子树的数据比当前节点都小、右子树的数据都比当前节点的数据大:
上图是为了方便读者理解 B 树每个节点的内容,实际绘制图形还是以圆表示每个节点。
了解了节点的差异后,来看看 B 树的定义,一棵 B 树必须满足以下条件:
- 若根结点不是终端结点,则至少有2棵子树
- 除根节点以外的所有非叶结点至少有 M/2 棵子树,至多有 M 个子树(关键字数为子树减一)
- 所有的叶子结点都位于同一层
用一张图对比平衡二叉树和 B 树:
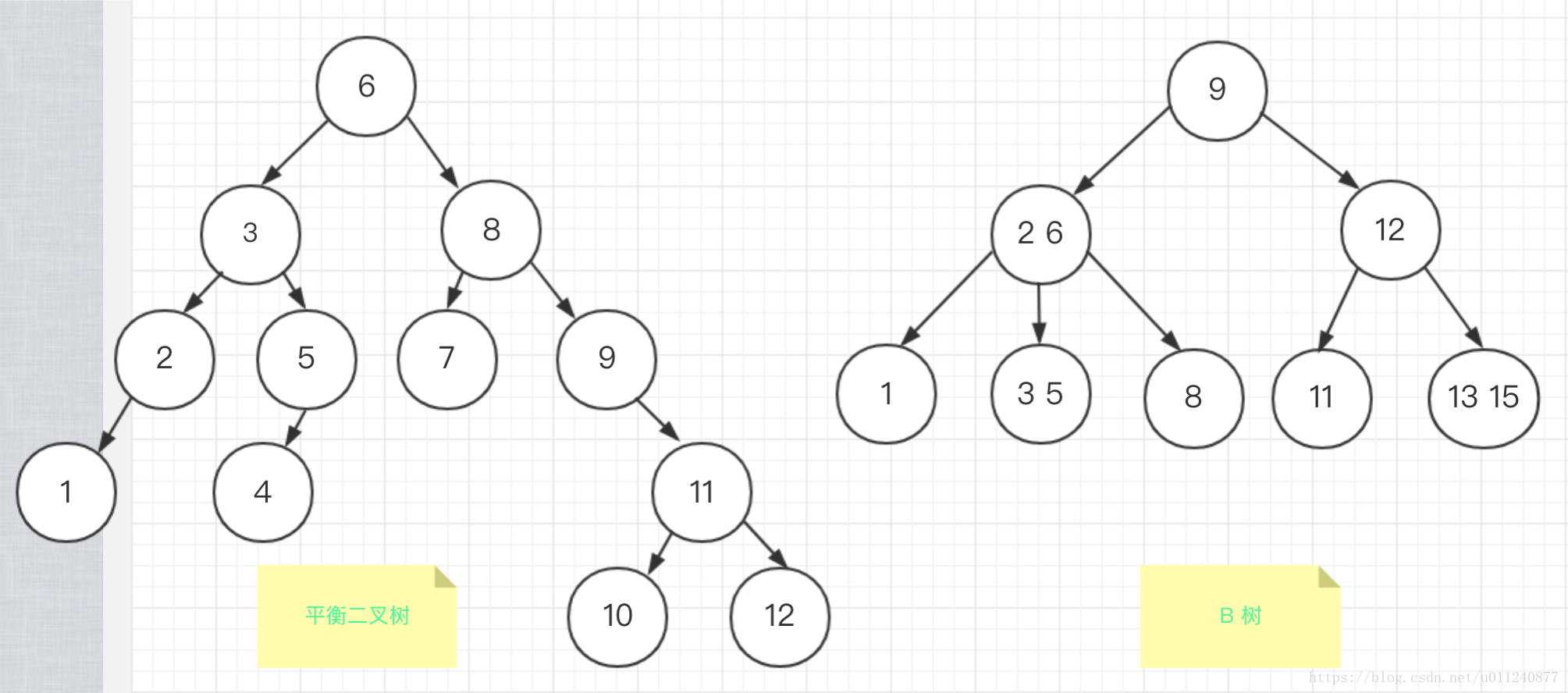
可以看到,B 树的每个节点可以表示的信息更多,因此整个树更加“矮胖”,这在从磁盘中查找数据(先读取到内存、后查找)的过程中,可以减少磁盘 IO 的次数,从而提升查找速度。
B 树中如何查找数据
因为 B 树的子树大小排序规则,因此在 B 树中查找数据时,一般需要这样:
- 从根节点开始,如果查找的数据比根节点小,就去左子树找,否则去右子树
- 和子树的多个关键字进行比较,找到它所处的范围,然后去范围对应的子树中继续查找
- 以此循环,直到找到或者到叶子节点还没找到为止
B 树如何保证平衡
我们知道,平衡的树之所以能够加快查找速度,是因为在添加、删除的时候做了某些操作以保证平衡。
平衡二叉树的平衡条件是:左右子树的高度差不大于 1;而 B 树的平衡条件则有三点:
- 叶子节点都在同一层
- 每个节点的关键字数为子树个数减一(子树个数 k 介于树的阶 M 和它的二分之一
- 子树的关键字保证左小右大的顺序
也就是说,一棵 3 阶的 B 树(即节点最多有三个子树),每个节点的关键字数最少为 1,最多为 2,如果要添加数据的子树的关键字数已经是最多,就需要拆分节点,调整树的结构。
网上找到一张很不错的动图,我们来根据它分析下 B 树添加元素时如何保证平衡。
这个图用以表示往 4 阶 B 树中依次插入下面这组数据的过程:
6 10 4 14 5 11 15 3 2 12 1 7 8 8 6 3 6 21 5 15 15 6 32 23 45 65 7 8 6 5 4
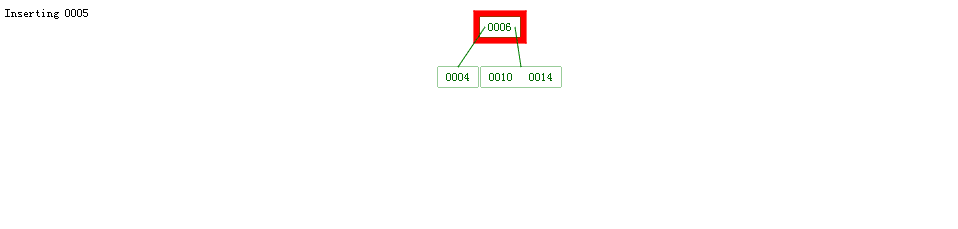
建议放大图查看。
由于我比较懒,我们来根据前几步分析下 B 树的添加流程:
- 首先明确:4 阶 B 树表示每个节点最多有 4 个子树、3 个关键字,最少有 2 个子树、一个关键字
- 添加 6,第一个节点,没什么好说的
- 添加 10,根节点最多能放三个关键字,按顺序添到根节点中
- 添加 4,还能放到根节点中
- 添加 14,这时超出了关键字最大限制,需要把 14 添加为子树,同时为了保证“所有叶子节点在同一层”,就需要拆几个关键字作为子树:
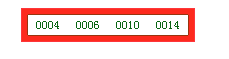 拆为:
拆为: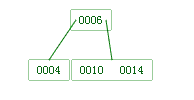
这个拆的过程比较复杂,首先要确定根节点保留几个关键字,由于“非叶子节点的根节点至少有 2 棵子树”的限制,那就至少需要两个关键字分出去,又因为“子树数是关键字数+1”,如果根节点有两个关键字,就得有三个子树,无法满足,所以只好把除 6 以外的三个关键字都拆为子树。
谁和谁在一个子树上呢,根据“左子树比关键字小、右子树比关键字大”的规律,4 在左子树,10 和 14 在右子树。
继续添加 :
- 添加 5,放到 4 所在的子树上
- 添加 11,放在 10 和 14 所在的右子树上
- 添加 15,按大小应该放到 10、11 和 14 所在的子树上,但因为超过了关键字数限制,又得拆分
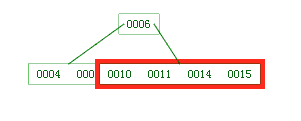
因为“根节点必须都在同一层”,因此我们不能给现有的左右子树添加子树,只能添加给 6 了;但是如果 6 有三个子树,就必须得有 2 个关键字,提升谁做关键字好呢,这得看谁做 6 中间的子树,因为右子树的所有关键字都得比父节点的关键字大,所以这个提升的关键字只能比未来右子树中的关键字都小,那就只有 10 和 11 可以考虑了。
提升 10 吧,没有比它小的做子树,那就只能提升 11 了:
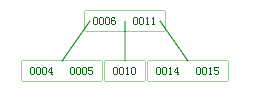
再添加元素也是类似的逻辑:
- 首先考虑要插入的子树是否已经超出了关键字数的限制
- 超出的话,如果要插入的位置是叶子节点,就只能拆一个关键字添加到要插入位置的父节点
- 如果非叶子节点,就得从其他子树拆子树给新插入的元素做孩子
删除也是一样的,要考虑删除孩子后,父节点是否还满足子树 k 介于 M/2 和 M 的条件,不满足就得从别的节点拆子树甚至修改相关子树结构来保持平衡。
总之添加、删除的过程很复杂,要考虑的条件很多,具体实现就不细追究了,这里我们有个基本认识即可。
正是这个复杂的保持平衡操作,使得平衡后的 B 树能够发挥出磁盘中快速查找的作用。
使用场景
这部分摘自:浅谈算法和数据结构:平衡查找树之B树
文件系统和数据库系统中常用的B/B+ 树,他通过对每个节点存储个数的扩展,使得对连续的数据能够进行较快的定位和访问,能够有效减少查找时间,提高存储的空间局部性从而减少IO操作。他广泛用于文件系统及数据库中,如:
-
Windows:HPFS 文件系统
-
Mac:HFS,HFS+ 文件系统
-
Linux:ResiserFS,XFS,Ext3FS,JFS 文件系统
-
数据库:ORACLE,MYSQL,SQLSERVER 等中
-
数据库:ORACLE,MYSQL,SQLSERVER 等中
B+ 树
这部分主要学习自“程序员小灰”的 漫画:什么是B+树?
了解了 B 树后再来了解下它的变形版:B+ 树,它比 B 树的查询性能更高。
一棵 B+ 树需要满足以下条件:
- 节点的子树数和关键字数相同(B 树是关键字数比子树数少一)
- 节点的关键字表示的是子树中的最大数,在子树中同样含有这个数据
- 叶子节点包含了全部数据,同时符合左小右大的顺序
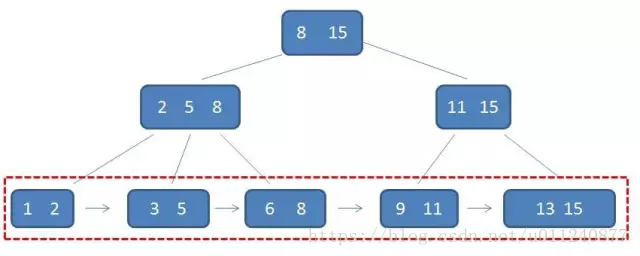
简单概括下 B+ 树的三个特点:
- 关键字数和子树相同
- 非叶子节点仅用作索引,它的关键字和子节点有重复元素
- 叶子节点用指针连在一起
首先第一点不用特别介绍了,在 B 树中,节点的关键字用于在查询时确定查询区间,因此关键字数比子树数少一;而在 B+ 树中,节点的关键字代表子树的最大值,因此关键字数等于子树数。
第二点,除叶子节点外的所有节点的关键字,都在它的下一级子树中同样存在,最后所有数据都存储在叶子节点中。
根节点的最大关键字其实就表示整个 B+ 树的最大元素。
第三点,叶子节点包含了全部的数据,并且按顺序排列,B+ 树使用一个链表将它们排列起来,这样在查询时效率更快。
由于 B+ 树的中间节点不含有实际数据,只有子树的最大数据和子树指针,因此磁盘页中可以容纳更多节点元素,也就是说同样数据情况下,B+ 树会 B 树更加“矮胖”,因此查询效率更快。
B+ 树的查找必会查到叶子节点,更加稳定。
有时候需要查询某个范围内的数据,由于 B+ 树的叶子节点是一个有序链表,只需在叶子节点上遍历即可,不用像 B 树那样挨个中序遍历比较大小。
B+ 树的三个优点:
- 层级更低,IO 次数更少
- 每次都需要查询到叶子节点,查询性能稳定
- 叶子节点形成有序链表,范围查询方便
添加过程就不深入研究了,后面用到再看吧,这里先贴一个 B+ 树动态添加元素图:


 浙公网安备 33010602011771号
浙公网安备 33010602011771号