Netty:Netty中的零拷贝(Zero Copy)
零复制概念:
“ 零复制”描述了计算机操作,其中CPU 不执行将数据从一个存储区复制到另一个存储区的任务。通过网络传输文件时,通常用于节省CPU周期和内存带宽。
WIKI的定义中,我们看到 “零复制” 是指计算机操作的过程,不需要消耗CPU资源来在内存之间进行数据复制。它通常是指计算机在网络上发送文件时,不需要将文件的内容复制到用户空间并将其直接传输到内核空间中的网络的方式。
① 非零副本(传统的数据复制方法):
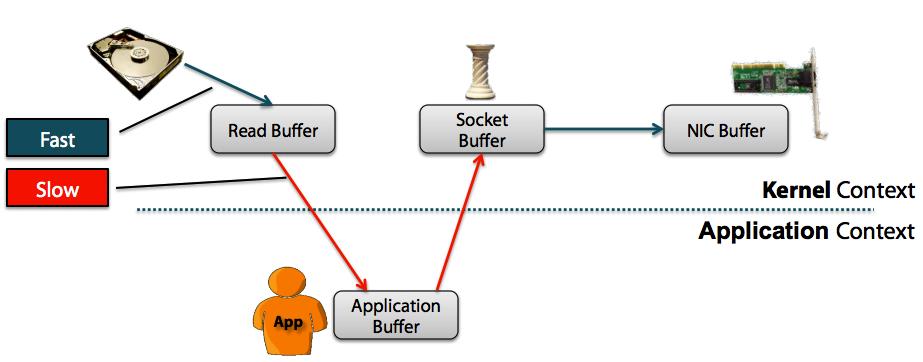
→ :CPU Copy(慢)
→ :DMA(直接内存访问) Copy(快)
下面看传统数据的复制方法以及其上下文的切换
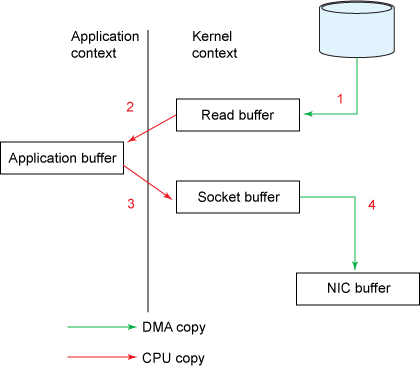
图1. 传统的数据复制方法
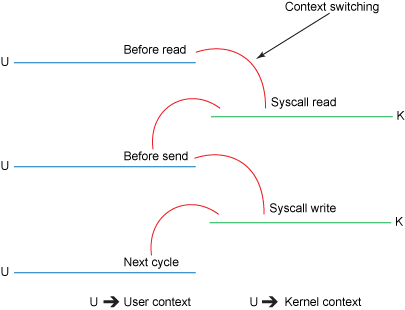
图2. 传统的上下文切换
-
-
请求的数据量从读取缓冲区复制到用户缓冲区,然后 read() 调用返回。调用返回导致另一个上下文从内核切换回用户模式。现在,数据存储在用户地址空间缓冲区中。
-
该 send() 插座调用导致从用户模式到内核模式的上下文切换。执行第三次复制以再次将数据放入内核地址空间缓冲区。但是,这次,数据被放到了另一个缓冲区中,该缓冲区与目标套接字相关联。
-
该 send() 系统调用返回,创造了第四上下文切换。独立且异步地,当 DMA 引擎将数据从内核缓冲区传递到协议引擎时,发生第四次复制。
使用中间内核缓冲区(而不是将数据直接传输到用户缓冲区中)似乎无效。但是,将中间内核缓冲区引入了该过程以提高性能。在读取侧使用中间缓冲区可以使内核缓冲区充当“预读缓存”,而应用程序所需要的数据却不如内核缓冲区所需的那么多。当请求的数据量小于内核缓冲区大小时,这将显着提高性能。写侧的中间缓冲区允许写异步完成。
不幸的是,如果请求的数据大小比内核缓冲区的大小大得多,则此方法本身可能会成为性能瓶颈。数据在最终交付给应用程序之前,已在磁盘,内核缓冲区和用户缓冲区之间多次复制。
零复制通过消除这些冗余数据副本来提高性能。
② 零复制方法:
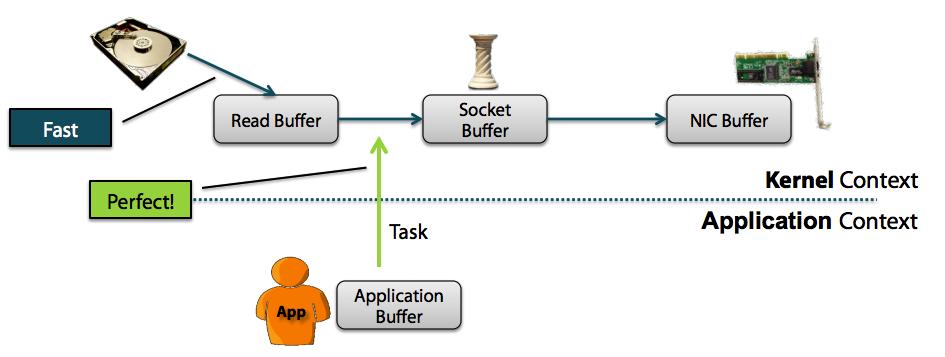
从上图可以清楚地看到,在零复制模式下,避免了用户空间和内存空间之间的数据复制,从而提高了系统的整体性能。
程序访问方式
-
Linux内核通过各种系统调用(例如 sys/socket.h 的 sendfile,sendfile64 和 splice)支持零复制。其中一些是在 POSIX 中指定的,因此也存在于 BSD 内核或 IBM AIX 中,其中一些是 Linux 内核 API 特有的。
-
Microsoft Windows 通过 TransmitFile API 支持零复制。
-
如果基础操作系统也支持零拷贝,则Java输入流可以通过 java.nio.channels.FileChannel 的 transferTo() 方法支持零拷贝。
1 public abstract long transferTo(long position, long count, WritableByteChannel target) throws IOException;
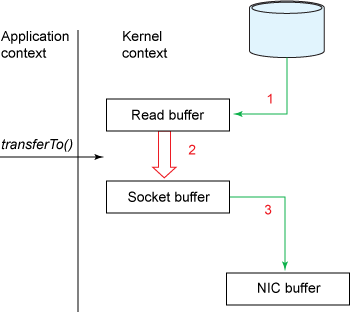
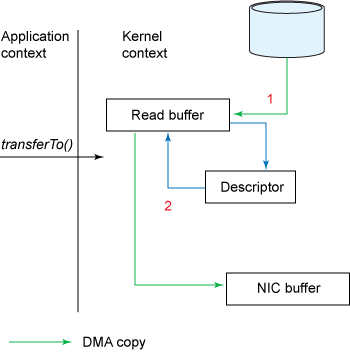
图3. 用transferTo()复制数据
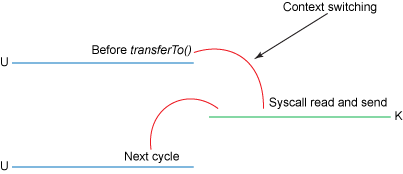
图4. 使用transferTo() 进行上下文切换
-
-
第三份副本发生在DMA引擎将数据从内核套接字缓冲区传递到协议引擎时。
这是一个改进:我们将上下文切换的数量从四个减少到了两个,并将数据副本的数量从四个减少到了三个(其中只有一个涉及 CPU)。但这还不能使我们达到零拷贝的目标。如果基础网络接口卡支持收集操作,则可以进一步减少内核完成的数据重复。在 Linux 内核2.4及更高版本中,已修改套接字缓冲区描述符以适应此要求。这种方法不仅减少了多个上下文切换,而且消除了需要CPU参与的重复数据副本。用户端的用法仍然保持不变,但内在函数已更改:
-
该 transferTo() 方法使文件内容被 DMA 引擎复制到内核缓冲区中。
-
没有数据复制到套接字缓冲区。而是仅将具有有关数据的位置和长度的信息的描述符附加到套接字缓冲区。DMA 引擎将数据直接从内核缓冲区传递到协议引擎,从而消除了剩余的最终 CPU 复制。
transferTo()与 gather 操作一起使用的数据副本。在linux 2.4及以上版本的内核中(如linux 6或centos 6以上的版本),开发者修改了socket buffer descriptor,使网卡支持 gather operation,通过 kernel 进一步减少数据的拷贝操作。
transferTo()
在默认情况下,Linux 内核的映射/内存分配工具将创建虚拟连续但物理上不相交的内存区域。这意味着从文件系统读取的内容 sendfile() 会在内部进入内核虚拟内存中 的缓冲区,该缓冲区必须由DMA代码迁移到网卡的DMA引擎可以读取的内容。
由于DMA(通常但并非总是)使用物理地址,这意味着您可以将数据缓冲区(复制到内存中专门分配的物理上相邻的区域,即上面的套接字缓冲区)中,或者以一个one-physical-page-at-a-time 的方式传输。
另一方面,如果你的DMA引擎能够将多个物理上不相交的内存区域聚合到单个数据传输中(称为“scatter-gather”),则无需复制缓冲区,只需传递物理地址列表即可(指向内核缓冲区的物理连续子段,即上面的聚合描述符),您不再需要为每个物理页启动单独的DMA传输。这通常更快,但是是否可以完成取决于DMA引擎的功能。
Netty支持两种零拷贝类型:
1)包装 FileChannel.tranferTo 方法以实现零复制
FileChannel是一个连接到文件的通道,可以通过文件通道读写文件。FileChannel无法设置为非阻塞模式,它总是运行在阻塞模式下。
Netty通过将NIO的FileChannel.transferTo()方法包装在FileRegion中来实现零拷贝(直接拷贝到另一个Channel中,中间不经过应用程序)。
FileRegion是一个接口,默认实现类是:DefaultFileRegion
2)内置到复合缓冲区类型中的透明零复制实现
① 透明零拷贝透明零拷贝
为了使Web应用程序达到最佳性能,你需要减少内存复制操作的数量。你可能有一组可以组合形成完整消息的缓冲区。网络提供了一个复合缓冲区,使你可以从任何现有数量的缓冲区中创建一个新的缓冲区,而无需复制内存。例如,一条消息可以包含两个部分:标头和正文。在模块化应用程序中,当发送消息时,两个部分可以由不同的模块生产和组装。
+--------+----------+ | header | body | +--------+----------+
如果使用的是 ByteBuffer(JDK的),则必须创建一个新的大缓冲区,以将两个部分复制到该新缓冲区中。另外,你可以在Nio上执行收集写操作,但限制将复合缓冲区类型用作ByteBuffers 数组而不是单个缓冲区,从而破坏了抽象并引入了复杂的状态管理。另外,如果您不从NIO通道进行读取或写入,那将毫无用处。
1 // 复合类型与组件类型不兼容。 2 ByteBuffer [] message = new ByteBuffer [] {header,body};
相比之下,ByteBuf(Netty的)不会发出警告,因为它是完全可扩展的并且具有内置的复合缓冲区。
1 // 复合类型与组件类型兼容。 2 ByteBuf message = Unpooled.wrappedBuffer(header,body); 3 4 // 因此,你甚至可以通过将复合类型与常规缓冲区混合来创建复合类型。 5 ByteBuf messageWithFooter = Unpooled.wrappedBuffer(message,footer); 6 7 // 由于复合类型仍然是ByteBuf,因此访问其内容很容易。 8 // 访问方法的行为就像访问一个单独的缓冲区一样。 9 // 即使你要访问的区域跨越多个组件。 10 // 此处读取的无符号整数位于正文和页脚中 11 messageWithFooter.getUnsignedInt( 12 messageWithFooter.visibleBytes() - footer.izableBytes() - 1);
② 自动扩容自动扩容
许多协议定义了可变长度的消息,这意味着在构建消息之前,无法确定消息的长度。或者,计算长度的精确值既困难又不便。这就像在构建字符串时一样。您通常会估计结果字符串的长度,从而允许 StringBuffer 扩展其自身的要求。
1 // 创建一个新的动态缓冲区。在内部,实际缓冲区是“惰性”创建的,以避免潜在地浪费内存空间。 2 ByteBuf b = Unpooled.buffer(4); 3 4 // 首次尝试写入时,将创建内部初始容量为4的缓冲区。 5 b.writeByte('1'); 6 7 b.writeByte('2'); 8 b.writeByte('3'); 9 b.writeByte('4'); 10 11 // 当写入的字节数超过初始容量4时, 12 // 内部缓冲区自动分配有更大的容量 13 b.writeByte('5');
③ 更好的表现
最常用的缓冲区 ByteBuf 的实现是一个非常薄的字节数组包装器(例如,一个字节)。与 ByteBuffer 不同,它没有复杂的边界和索引检查补偿,因此访问 JVM 优化的缓冲区要简单得多。与 ByteBuffer 相比,更复杂的缓冲区实现用于拆分或合并缓存,并具有更好的性能。
ByteBuf 具有丰富的操作集,可实现快速的协议优化。例如,ByteBuf 提供了各种操作来访问无符号值和字符串,以及在缓冲区中搜索某个字节序列。你还可以扩展或包装现有的缓冲区类型以提供方便的访问。仍然从ByteBuf接口实现自定义缓冲区,而不是引入不兼容的类型
与 ByteBuffer 相比,不再需要 flip() 方法,它在正常情况下更加高效且响应迅速。
参考: Efficient data transfer through zero copy,Understand Zero-copy in Netty,zero-copy-with-and-without-scatter-gather-operations,JAVA Zero Copy的相关知识,FileChannel的基本操作

 浙公网安备 33010602011771号
浙公网安备 33010602011771号