
采集一个国外产品站数据 - Python
前面朋友喊采一个国外的产品站。而且要根据他的格式给他返回数据。做过zen-cart的朋友应该知道,zen-cart是可以批量上传数据的,有一个叫批量表的东西,他就是要我给他把数据按照要求填到数据表里,数据表的样板如下:
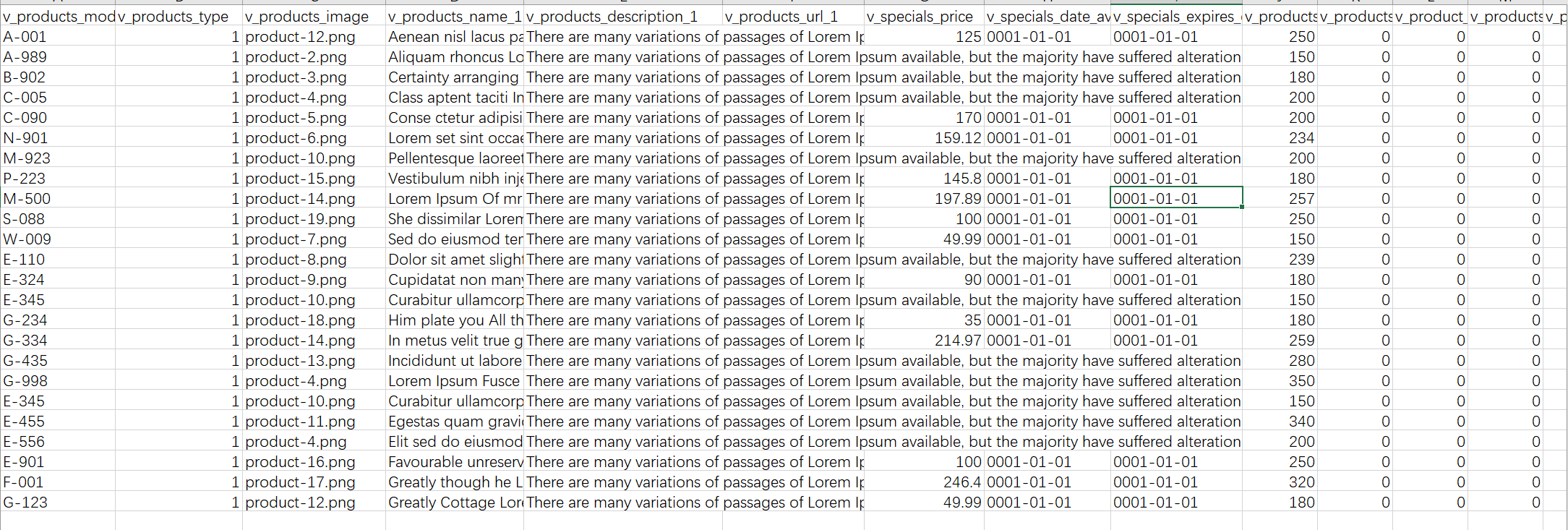
其中有些参数是必须的:
- 第一列的v_products_model是产品的model号,也就是常说的sku,这个东西是唯一的,在数据库里;
- 第三列的v_products_image是图片在服务器的路径;
- 第四列的v_products_name_1是产品的名称;
- 第五列的v_products_description_1是产品的描述;
- 第七列的v_specials_price是产品的打折价格,网站为了吸引顾客总有打折的商品;
- 与上面v_speicials_price对应的是v_products_price,也就是产品的本来价格;
- 还有一列重要的就是v_categories_name_1,就是产品的目录;这也设计产品在网站的分目录问题;
上面的参数都是重要的,其他的参数可以照sample表填写。昨天采集好的,今天正好有时间,整理成文。目标站为:https://www.shopdisney.com/,ping了下,服务器在阿三所住的国家,速度不是很快。说实话,站还是做得蛮不错的。清朗简洁,不像某宝某东,那界面恶心死人,浓墨重彩。观察一下网站,要采集全部产品,刚一看还是有点摸不着头脑的。
经过观察,发现每个导航目录下面都有个SHOP ALL [导航名],点开发现当前导航的产品都在此。而且左上角还有该导航栏下产品的总数统计。有个问题就是SHOP ALL [导航名]下面的产品是懒加载的,要手工滑动滚动条数据才会加载,python中可替代的selenium,可以渲染js进行模拟滑动。(当然,懒加载一般是异步加载的,也就是肯定有数据接口,待会再说。)
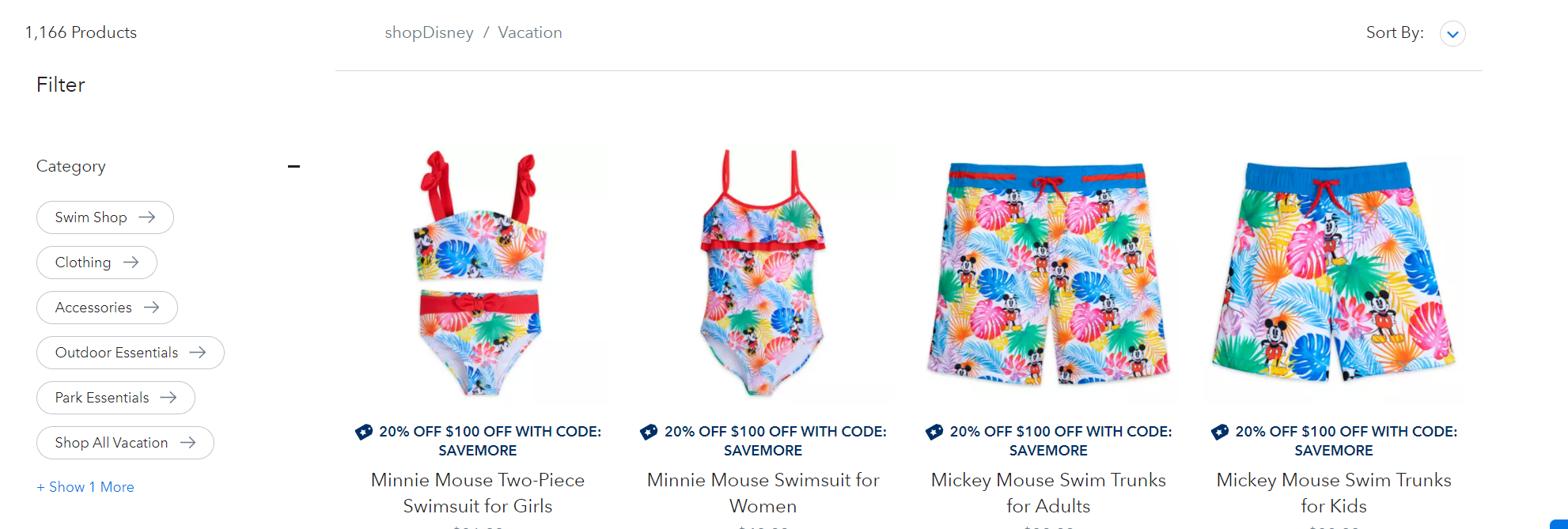
思路:
- 通过selenium模拟浏览器,请求导航下的SHOP ALL [导航名];
- 通过selenium滑动滚动条实现懒加载,直至加载完成;
- 提取通过加载完的html页面,也就是driver.page_source;
- 用parsel对上一步的html页面进行Selector;
- 用Selector提取产品的链接地址;
- 在产品的链接地址里对所需数据进行提取;
感觉上,如果产品列表够长,懒加载时间过长,我的小破电脑是扛不住的。内存会被吃光。不过还是试试,不试试怎么知道。

第一种方式开始,上代码:

1 import pprint 2 import re 3 import os 4 from selenium import webdriver 5 from selenium.webdriver.common.by import By 6 from selenium.webdriver.support import expected_conditions as EC 7 from selenium.webdriver.support.wait import WebDriverWait, TimeoutException 8 import csv 9 import random 10 import time 11 import parsel 12 import requests 13 14 # 导航栏列表 15 category_lists = ['vacation', 'clothing', 'accessories', 'toys', 'home', 'shop-by-category'] 16 17 # 第一个函数,应对懒加载 18 def scroll_until_loaded(): 19 # 针对懒加载 20 wait = WebDriverWait(driver, 30) 21 check_height = driver.execute_script('return document.body.scrollHeight;') 22 while True: 23 driver.execute_script('window.scrollTo(0, document.body.scrollHeight);') 24 try: 25 wait.until(lambda h: driver.execute_script("return document.body.scrollHeight;") > check_height) 26 check_height = driver.execute_script("return document.body.scrollHeight;") 27 except TimeoutException: 28 break 29 # 另外有固定写法固定了每次滚动操作后等待页面加载的时间 30 def scroll_until_loaded_sticky(): 31 all_window_height = [] # 创建一个列表,用于记录每一次拖动滚动条后页面的最大高度 32 all_window_height.append(driver.execute_script("return document.body.scrollHeight;"))#当前页面的最大高度加入列表 33 while True: 34 driver.execute_script("scroll(0,100000)") # 执行拖动滚动条操作,这里的100000数值根据页面高度进行调整 35 time.sleep(3) 36 check_height = driver.execute_script("return document.body.scrollHeight;") 37 if check_height == all_window_height[-1]: # 判断拖动滚动条后的最大高度与上一次的最大高度的大小,相等表明到了最底部 38 break 39 else: 40 all_window_height.append(check_height) # 如果不相等,将当前页面最大高度加入列表。 41 # 开始保存图片 42 def save_images(imageLists, productModel): 43 # 传入图片链接列表以及产品model号进行处理 44 filePath = f'./images/{productModel}/' # 图片路径是images下的,一定要有后面这个反斜杠,不然存不到指定目录 45 if not os.path.exists(filePath): 46 os.makedirs(filePath) 47 for index, imagelink in enumerate(imageLists): 48 if index == 0: 49 productImageMain = productModel 50 mainContent = requests.get(url=imagelink).content 51 try: 52 with open(filePath + productModel + '.jpg', mode='wb') as f: 53 f.write(mainContent) 54 print(f'-正在保存{productModel}的主图{productImageMain},请稍等!') 55 except: 56 print(f'--主图{productModel}保存有错误,请检查!') 57 else: 58 productImageDetail = productModel + '_' + str(index) 59 # print(productImageDetail) 60 detailContent = requests.get(url=imagelink).content 61 try: 62 with open(filePath + productImageDetail + '.jpg', mode='wb') as f: 63 f.write(detailContent) 64 print(f'----正在保存{productModel}的细节图{productImageDetail},请稍等!') 65 except: 66 print(f'-----{productModel}细节图{productImageDetail}保存有错误,请检查!') 67 68 headers = { 69 'user-agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/99.0.4844.82 Safari/537.36', 70 } 71 72 # 开始加载浏览器 73 for category in category_lists: 74 driver = webdriver.Chrome() 75 url = 'https://www.shopdisney.com/vacation/' 76 driver.maximize_window() 77 driver.implicitly_wait(5) # 隐式等待 78 driver.get(url=url) # 开始请求网页 79 # 滑动页面至底部 80 scroll_until_loaded_sticky() 81 time.sleep(random.uniform(8, 15)) # 随机休眠 82 # 开始提取产品列表 83 htmlText = driver.page_source 84 selector = parsel.Selector(htmlText) 85 # 解析产品列表 86 productLists = selector.xpath('//div[@class="products__grid"]/div[contains(@class, "product")]') 87 # 打开csv文档,属性批量表和产品批量表 88 attributeFile = open(f'shopdisneyAttribute-{category}.csv', mode='a', encoding='utf-8', newline='') # 属性 89 attributeCsvWriter = csv.writer(attributeFile) #写入器 90 productFile = open(f'shopDisneyProduct-{category}.csv', mode='a', encoding='utf-8', newline='') # 产品 91 productCsvWriter = csv.writer(productFile) # 写入器 92 # 从productLists中提取标题和链接并写入到csv 93 for productlist in productLists: 94 # 提取产品链接 95 productLink = "https://www.shopdisney.com" + productlist.xpath('.//div[@class="product__tile_name"]/a/@href').get().strip() 96 # 提取产品标题 97 productTitle = productlist.xpath('.//div[@class="product__tile_name"]/a/text()').get().strip() 98 # 开始请求产品详情页数据 99 response = requests.get(url=productLink, headers=headers) 100 # 选择器 101 productDetailPageSelector = parsel.Selector(response.text) 102 # 开始定位产品 103 detailInfos = productDetailPageSelector.xpath('//main[@class="main-content"]') 104 # 产品目录 105 categoryList = detailInfos.xpath('.//ol[@class="breadcrumb"]/li/a/span/text()').getall() 106 categoryStr = '^'.join(categoryList[1:]) # 目录,取列表的第一项到最后一项,去除面包屑(breadcrumb)里的home 107 # 提取价格 108 price = detailInfos.xpath('.//div[@class="prices"]/div/span/span/span[@class="value"]/@content').get() # 价格 109 discountPrice = round(float(price) * 0.85, 2) 110 # 尝试提取尺码,因为不一定有 111 try: 112 sizeList = detailInfos.xpath('.//div[@class="product__variation-attributes"]/div/ul/li/@data-attr-value').getall() 113 sizeStr = ','.join(sizeList) # 尺码表的字符串 114 except: 115 sizeList = '' # 没有尺码 116 117 # 尝试提取model,也就是sku,也是不一定会有 118 try: 119 productModelList = detailInfos.xpath('.//p[@class="prod-partnumber"]/*/text()').getall() 120 productModelStr = detailInfos.xpath('.//p[@class="prod-partnumber"]/span[2]/text()').get() 121 # productModelStr = productModelList[-1] # 取列表的最后一项 122 except: 123 productModelList = None 124 productModelStr = '' 125 # 提取产品描述 126 productDescription = detailInfos.xpath('//div[@id="descriptionAndDetailContainer"]/div[contains(@class, "tab-content-1")]').get().strip() 127 # 图片和细节图列表 128 imageLists = re.findall('data-image-base="(.*?)"', response.text) # 129 imageLists = imageLists[0:int(len(imageLists)/2)] # 因为会有重复的,处理一下列表,截取列表的一半 130 imagePath = f'images/{productModelStr}' # 设定图片路径,好写入批量表 131 # print(categoryStr, imagePath, price, productTitle, discountPrice, productModelStr, sizeStr, imageLists, productDescription,sep=' | ') 132 # 属性批量表的值 133 attributeData = [productModelStr, 0, 'Sizes', sizeStr] 134 # 产品批量表的值 135 productData = [productModelStr, '1', imagePath, productTitle, productDescription, '', discountPrice, '2014/10/31 0:00:00', 136 '0001-01-01', price, 0, 0, 0, 1, 1, 0, 0, '2014/10/31 0:00:00', '2021/11/11 20:05:05', 1000, 137 'Disney', categoryStr, '--none--', 1, 0, 0, 0, 0, 0, '', '', ''] 138 attributeCsvWriter.writerow(attributeData) # 写入属性 139 productCsvWriter.writerow(productData) # 写入产品 140 save_images(imageLists=imageLists, productModel=productModelStr) # 调用函数保存图片 141 time.sleep(random.uniform(2,5)) # 随机休眠 142 143 attributeFile.close() # 关闭属性文档 144 productFile.close() # 关闭产品文档
代码可以运行,也可以采集到数据,会出现几个问题:
- 人服务器在国外,懒加载的时候会掉包,很容易就获取不到全部数据;
- 抓取的selector可能过长,处理数据的时候,程序会出现假死;
- 产品页面问题,这个站的产品页面模板有两个,一个通过程序能抓取到数据,另外一个是从第三方加载产品的,只能获取到标题;
- 图片下载的时候请求过多会被远程服务器关闭连接;个人理解不算反爬,只是请求的数据过多,因为图片数据还是蛮大的。
第二种方式,就是懒加载,异步加载的话,肯定会有数据接口,通过F12查找数据接口。
通过开发者工具,拉动鼠标下滑加载:
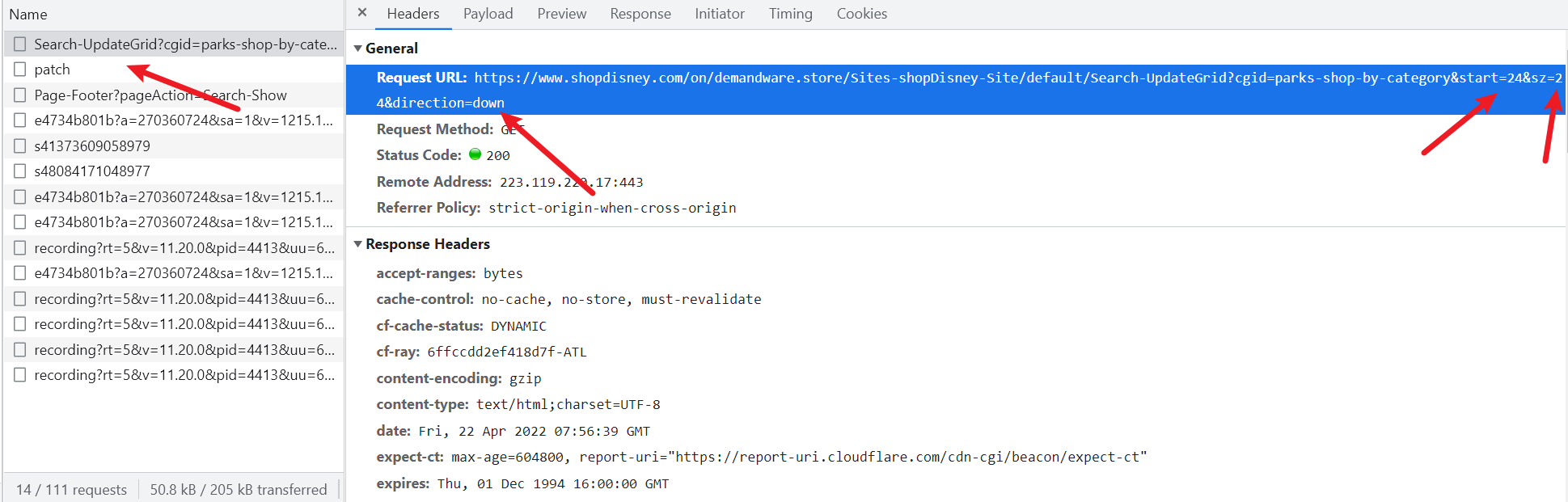
多滑动几页,发现只有只有start=[24]这个24会变动,而且都是24的倍数,url规则如下:
https://www.shopdisney.com/on/demandware.store/Sites-shopDisney-Site/default/Search-UpdateGrid?cgid=parks-shop-by-category&start=0&sz=24&direction=down https://www.shopdisney.com/on/demandware.store/Sites-shopDisney-Site/default/Search-UpdateGrid?cgid=parks-shop-by-category&start=24&sz=24&direction=down https://www.shopdisney.com/on/demandware.store/Sites-shopDisney-Site/default/Search-UpdateGrid?cgid=parks-shop-by-category&start=48&sz=24&direction=down
那就请求接口吧,上代码:
1 import os 2 import re 3 import time 4 import random 5 import parsel 6 import requests 7 import csv 8 import concurrent.futures 9 10 def get_response(page_url): 11 # 一个解析html页面的函数 12 headers = { 13 'user-agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/99.0.4844.82 Safari/537.36', 14 } 15 response = requests.get(url=page_url) 16 response.encoding = response.apparent_encoding 17 response.encoding = 'utf-8' 18 return response 19 20 def save_image(imageLists, productModelStr): 21 # 创建文件夹 22 filePath = f'./images/{productModelStr}/' 23 if not os.path.exists(filePath): 24 os.makedirs(filePath) 25 26 # 开始处理图片列表 27 # imageLists = imageLists[0:int(len(imageLists)/2)] # 截取列表的一半,取出另外一半重复的 28 # 开始解析图片网址并保存 29 for index, imagelink in enumerate(imageLists): 30 # 如果是第一个链接,那么以model号进行保存,其他的图片以model号加下划线加格式保存,如20200_1.jpg 31 if index == 0: 32 productImageMain = productModelStr 33 mainContent = get_response(page_url=imagelink).content 34 try: 35 with open(filePath + productImageMain + '.jpg', mode='wb') as f: 36 f.write(mainContent) 37 print(f'-正在保存{productModelStr}的主图{productImageMain},请稍等!') 38 except: 39 pass 40 else: 41 # 处理细节图 42 productImageDetail = productModelStr + '_' + str(index) 43 detailContent = get_response(page_url=imagelink).content 44 time.sleep(random.uniform(2, 15)) 45 try: 46 with open(filePath + productImageDetail + '.jpg', mode='wb') as f: 47 f.write(detailContent) 48 print(f'-----正在保存{productModelStr}的细节图{productImageDetail},请稍等!') 49 except: 50 pass 51 # 解析函数 52 def main(url): 53 NORMALDATA = [] # 正常数据统计,用于统计采集了多少有用数据 54 ABANDONDATA = [] # 丢弃的数据,用于统计丢弃了多少数据 55 USER_AGENT_LIST = [ 56 'Mozilla/5.0 (Windows NT 10.0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/99.0.7113.93 Safari/537.36', 57 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4495.0 Safari/537.36', 58 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4476.0 Safari/537.36', 59 'Mozilla/5.0 (Windows NT 6.1; Win64; x64; rv:90.0) Gecko/20100101 Firefox/90.0', 60 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:90.0) Gecko/20100101 Firefox/90.0', 61 'Mozilla/5.0 (Windows NT 6.3; Win64; x64; rv:90.0) Gecko/20100101 Firefox/90.0', 62 'Mozilla/5.0 (Windows NT 6.2; Win64; x64; rv:89.0) Gecko/20100101 Firefox/89.0', 63 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:89.0) Gecko/20100101 Firefox/89.0', 64 'Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.85 Safari/537.36 OPR/76.0.4017.94', 65 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.85 Safari/537.36 OPR/76.0.4017.94 (Edition utorrent)', 66 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.85 Safari/537.36 OPR/76.0.4017.94', 67 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.128 Safari/537.36 OPR/75.0.3969.259 (Edition Yx GX 03)', 68 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4482.0 Safari/537.36 Edg/92.0.874.0', 69 'Mozilla/5.0 (Windows NT 6.3; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.19 Safari/537.36 Edg/91.0.864.11', 70 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4471.0 Safari/537.36 Edg/91.0.864.1', 71 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.93 Safari/537.36 Vivaldi/3.7', 72 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.93 Safari/537.36 Vivaldi/3.7', 73 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.38 Safari/537.36 Brave/75', 74 'Mozilla/5.0 (Windows NT 6.3; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.38 Safari/537.36 Brave/75', 75 ] 76 random_user_agent = random.choice(USER_AGENT_LIST) 77 headers = { 78 'user-agent': random_user_agent, 79 } 80 params = { 81 "cgid": f"{cgid}", 82 "start": f"{page}", 83 "sz": "24", 84 "direction": "down", 85 } 86 # 打开csv文档 87 attributeFile = open('shopDisneyProductAttribute.csv', mode='a', encoding='utf-8', newline='') # 属性 88 attributeCsvWriter = csv.writer(attributeFile) # 写入器 89 productFile = open('shopDisneyProduct.csv', mode='a', encoding='utf-8', newline='') # 产品 90 productCsvWriter = csv.writer(productFile) # 写入器 91 # 解析页面,首先获取返回的html 92 firstHtmlData = requests.get(url=url, headers=headers,params=params) 93 time.sleep(random.uniform(5, 15)) 94 print(f'--请求的网址为:{firstHtmlData.url}') 95 # print(firstHtmlData.url) 96 selector = parsel.Selector(firstHtmlData.text) # 从这里获取model,因为衣服的产品的model存在这里 97 productLists = selector.xpath('//div[@class="product hidden"]') 98 # print(len(productLists)) 99 for product in productLists: 100 productTitle = product.xpath('.//a[@class="product__tile_link"]/text()').get().strip() 101 productLink = 'https://www.shopdisney.com' + product.xpath('.//a/@href').get().strip() 102 productModel = product.xpath('.//div[@itemprop="sku"]/text()').get().strip() # 从接口出获得的model号 103 # 开始请求详情页获取数据 104 productDetailPageData = get_response(page_url=productLink).text 105 detailSelector = parsel.Selector(productDetailPageData) 106 detailInfos = detailSelector.xpath('//main[@class="main-content"]') 107 # 如果请求到有iframe的直接跳过 108 eventsiframe = re.findall('<iframe id="eventsiframe" src="https:', productDetailPageData) # 如果发现有,则为True 109 time.sleep(random.uniform(2, 10)) 110 categoryList = detailInfos.xpath('.//ol[@class="breadcrumb"]/li/a/span/text()').getall() 111 categoryStr = '^'.join(categoryList[1:]) # 目录,取列表的第一项到最后一项 112 # print(categoryStr) 113 # print(categoryList) 114 try: 115 price = detailInfos.xpath('.//div[@class="prices"]/div/span/span/span[@class="value"]/@content').get() # 价格 116 except: 117 price = None 118 if price: 119 discountPrice = round(float(price) * 0.85, 2) 120 else: 121 discountPrice = None 122 # print(discountPrice) 123 # exit() 124 try: 125 sizeList = detailInfos.xpath( 126 './/div[@class="product__variation-attributes"]/div/ul/li/@data-attr-value').getall() 127 sizeStr = ','.join(sizeList) # 尺码表的字符串 128 except: 129 sizeList = '' # 没有尺码 130 131 # 提取model 132 try: 133 productModelList = detailInfos.xpath('.//p[@class="prod-partnumber"]/*/text()').getall() 134 productModelStr = detailInfos.xpath('.//p[@class="prod-partnumber"]/span[2]/text()').get() 135 # productModelStr = productModelList[-1] # 取列表的最后一项 136 except: 137 productModelList = None 138 productModelStr = '' 139 try: 140 productDescription = detailInfos.xpath( 141 '//div[@id="descriptionAndDetailContainer"]/div[@class="tab-content-1 show"]').get().strip() 142 except: 143 productDescription = None 144 # 图片和细节图列表 145 imageLists = re.findall('data-image-base="(.*?)"', productDetailPageData) # 146 # 判定imageLists的长度 147 # 如果等于1说明只有一张图 148 if imageLists and len(imageLists) == 1: 149 imageLists = imageLists 150 else: 151 imageLists = imageLists[0:int(len(imageLists) / 2)] # 如果大于2,就有四张图片,就切片 152 # imageLists = imageLists[0:int(len(imageLists) / 2)] # 因为会有重复的,处理一下列表,截取列表的一半 153 imagePath = f'images/{productModelStr}' 154 if (not eventsiframe) and (productModelList): 155 # 如果发现有,则为True,那没有的话就是我们需要的数据 156 # 同时满足上述条件我们才执行下面代码 157 print(f'*****{productModel}是正常数据,开始采集并保存!*****') 158 NORMALDATA.append(productModel) 159 # print(productModelStr, productTitle, price, discountPrice, categoryStr, sizeStr, productDescription, sep=' | ') 160 attributeData = [productModelStr, 0, 'Sizes', sizeStr] 161 productData = [productModelStr, '1', imagePath, productTitle, productDescription, '', discountPrice, 162 '2014/10/31 0:00:00', 163 '0001-01-01', price, 0, 0, 0, 1, 1, 0, 0, '2014/10/31 0:00:00', '2021/11/11 20:05:05', 1000, 164 'Disney', categoryStr, '--none--', 1, 0, 0, 0, 0, 0, '', '', ''] 165 print(productData) 166 attributeCsvWriter.writerow(attributeData) # 写入 167 productCsvWriter.writerow(productData) 168 save_image(imageLists=imageLists, productModelStr=productModelStr) 169 else: 170 # 其他直接跳过 171 ABANDONDATA.append(productModel) # 要丢弃数据的model列表 172 print(f'*********发现了eventsiframe标识,{productModel}是从第三方调用的数据,将其丢弃!*********') 173 continue # 跳过本次循环直接到下一次循环 174 attributeFile.close() 175 productFile.close() 176 print(f'采集数据统计:\n\t合法数据{str(len(NORMALDATA))}条!\n\t丢弃数据{str(len(ABANDONDATA))}条!') 177 # 要采集的目录页 178 cgids = ['vacation', 'clothing', 'accessories', 'toys', 'home', 'parks-shop-by-category'] 179 180 if __name__ == "__main__": 181 startTime = time.time() 182 app = concurrent.futures.ThreadPoolExecutor(max_workers=15) 183 for page in range(0, 3085 + 1, 24): 184 time.sleep(random.uniform(2, 15)) # 每请求一页进行休眠 185 cgid = 'vacation' 186 # print(f'----------正在采集*{cgid}*第{int(page/24) + 1}页的数据,一页24条.----------') 187 url = f'https://www.shopdisney.com/on/demandware.store/Sites-shopDisney-Site/default/Search-UpdateGrid?' 188 app.submit(main, url) 189 # main(url) 190 app.shutdown() 191 endTime = time.time() 192 print(f'----采集完成!总共耗时{int(endTime) - int(startTime)}----')
代码其实差不多,不同的地方在于:
- 导入了个线程函数
- 对产品页进行了筛选,从第三方网站例如amazon引入的产品舍弃;
- user-agent随机化了;
采集好后整理的数据截图,可以发现,打包后的数据都将近1G。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 别再用vector<bool>了!Google高级工程师:这可能是STL最大的设计失误
· 单元测试从入门到精通
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 上周热点回顾(3.3-3.9)