雪中悍刀行热播,来做一篇关于python的作业 - 爬虫与数据分析
雪中悍刀行在腾讯热播,做篇关于python的作业。--Python爬虫与数据分析。
分为三个部分:
第一:爬虫部分;爬虫爬评论内容和评论时间;
第二:数据处理部分;将爬下来的数据进行整理清洗以便可视化;
第三:可视化分析;对清洗好的数据进行可视化分析,对爬取的内容做一个整体的分析;
项目结构分为三个文件夹:Spiders,dataProcess和echarts。如图:

因为爬取的是腾讯视频,腾讯视频的评论内容都封装在json数据里,只要找到相应的视频id即可。前面有一片关于各大视频网站的文章 - 爬取某些网站的弹幕和评论数据 - Python。其实也就是找到视频播放地址,然后F12,然后搜索部分评论内容,找到response,就能看到targetid,在response里的callback参数也有视频id。雪中悍刀行的视频播放地址和id如下:
- 视频网址:https://v.qq.com/x/cover/mzc0020020cyvqh.html;
- 评论json数据网址:https://video.coral.qq.com/varticle/7579013546/comment/v2;
- 注:只要替换视频数字id的值,即可爬取其他视频的评论 ;
第一部分,爬虫
1,爬取评论内容,spiders/contentSpider.py。
1 """ 2 评论内容爬虫,爬取评论内容并保存到txt文件 3 """ 4 import json 5 import pprint 6 import re 7 import requests 8 9 class contentSpider(): 10 headers = { 11 "cookie": "",13 "referer": "https://v.qq.com/x/search/?q=%E9%9B%AA%E4%B8%AD%E6%82%8D%E5%88%80%E8%A1%8C&stag=101&smartbox_ab=", 14 "user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.110 Safari/537.36", 15 } 16 17 def __init__(self, url, params, headers=headers): 18 self.url = url 19 self.params = params 20 self.headers = headers 21 22 def get_html_content(self): 23 """ 24 获取网页内容 25 """ 26 response = requests.get(url=self.url, params=self.params, headers=self.headers) 27 response.raise_for_status() # 异常捕获 28 response.encoding = response.apparent_encoding # 自动识别编码 29 response.encoding = 'utf-8' # 将编码设置成utf-8 30 return response.text # 返回值 31 32 def parse_html_content(self): 33 """ 34 解析数据 35 """ 36 htmlText = self.get_html_content() 37 comment_content = re.findall('"content":"(.*?)"', htmlText, re.S) # 在网页文本中查找评论内容,忽略换行符,也就是匹配包括换行符在内的内容 38 # for comment in comment_content: 39 # print(comment) 40 return comment_content 41 42 def get_next_page_cursor(self): 43 htmlText = self.get_html_content() 44 nextPageCursor = re.findall('"last":"(.*?)"', htmlText, re.S) # 在文本中查找用于下一页的cursor,也就是产生的last参数 45 return nextPageCursor 46 47 def savetoTxt(self): 48 comments = self.parse_html_content() 49 fw = open('雪中悍刀行评论内容.txt', mode='a+', encoding='utf-8') 50 for comment in comments: 51 print(comment) 52 fw.write(comment + '\n') 53 fw.close() 54 if __name__ == "__main__": 55 for page in range(1, 100+1): 56 if page == 1: 57 params = { 58 "callback": "_varticle7579013546commentv2", 59 "orinum": "10", 60 "oriorder": "o", 61 "pageflag": "1", 62 "cursor": "0", 63 "scorecursor": "0", 64 "orirepnum": "2", 65 "reporder": "o", 66 "reppageflag": "1", 67 "source": "132", 68 "_": "1640918319760", 69 } 70 else: 71 params = { 72 "callback": "_varticle7579013546commentv2", 73 "orinum": "10", 74 "oriorder": "o", 75 "pageflag": "1", 76 "cursor": app.get_next_page_cursor(), 77 "scorecursor": "0", 78 "orirepnum": "2", 79 "reporder": "o", 80 "reppageflag": "1", 81 "source": "132", 82 "_": "1640918319760", 83 } 84 url = 'https://video.coral.qq.com/varticle/7579013546/comment/v2' 85 app = contentSpider(url=url, params=params) 86 app.savetoTxt()
2,评论时间爬取spiders/timeSpider,我自己为了练手,把上面的代码重写写了一遍,其实上面的代码只需要加个类属性保存时间txt就好了,然后多运行一次app。
1 """ 2 评论时间爬虫 3 """ 4 import os.path 5 6 import requests 7 import re 8 9 class timeSpider(): 10 headers = {13 "referer": "https://v.qq.com/x/search/?q=%E9%9B%AA%E4%B8%AD%E6%82%8D%E5%88%80%E8%A1%8C&stag=101&smartbox_ab=", 14 "user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.110 Safari/537.36", 15 } 16 def __init__(self, url, params, headers=headers): 17 self.url = url 18 self.params = params 19 self.headers = headers 20 21 def get_html_content(self): 22 response = requests.get(url=self.url, params=self.params, headers=self.headers) 23 response.raise_for_status() 24 response.encoding = response.apparent_encoding 25 response.encoding = 'utf-8' 26 return response.text 27 28 def parse_html_content(self): 29 htmlText = self.get_html_content() 30 timedata = re.findall('"time":"(\d+)",', htmlText) 31 return timedata 32 33 def get_next_page_cursor(self): 34 htmlText = self.get_html_content() 35 nextPageCursor = re.findall('"last":"(.*?)"', htmlText, re.S) # 在文本中查找用于下一页的cursor,也就是产生的last参数 36 return nextPageCursor 37 38 def savetoTxt(self): 39 times = self.parse_html_content() # 获取所有时间 40 for time in times: 41 with open('雪中悍刀行评论时间.txt', mode='a+', encoding='utf-8') as f: 42 f.write(time + '\n') 43 44 if __name__ == "__main__": 45 for page in range(1, 100+1): 46 if page == 1: 47 params = { 48 "callback": "_varticle7579013546commentv2", 49 "orinum": "10", 50 "oriorder": "o", 51 "pageflag": "1", 52 "cursor": "0", 53 "scorecursor": "0", 54 "orirepnum": "2", 55 "reporder": "o", 56 "reppageflag": "1", 57 "source": "132", 58 "_": "1640918319760", 59 } 60 else: 61 params = { 62 "callback": "_varticle7579013546commentv2", 63 "orinum": "10", 64 "oriorder": "o", 65 "pageflag": "1", 66 "cursor": app.get_next_page_cursor(), 67 "scorecursor": "0", 68 "orirepnum": "2", 69 "reporder": "o", 70 "reppageflag": "1", 71 "source": "132", 72 "_": "1640918319760", 73 } 74 url = 'https://video.coral.qq.com/varticle/7579013546/comment/v2' 75 app = timeSpider(url=url, params=params) 76 app.savetoTxt()
3,还有一份代码spiders/infoSpider.py,一次性爬取所需信息。
1 """ 2 爬取一些信息 3 """ 4 import json 5 import pprint 6 import random 7 import re 8 import csv 9 import time 10 import requests 11 12 13 class commentSpider(): 14 headers = { 15 "cookie": "", 16 "referer": "https://v.qq.com/", 17 "user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.110 Safari/537.36", 18 } 19 def __init__(self, url, params, headers=headers): 20 self.url = url 21 self.params = params 22 self.headers = headers 23 24 def requestsPage(self): 25 response = requests.get(url=self.url, params=self.params, headers=self.headers) 26 response.raise_for_status() 27 response.encoding = response.apparent_encoding 28 response.encoding = 'utf-8' 29 return response.text 30 31 def responseToJson(self): 32 htmlText = self.requestsPage() 33 # print(htmlText) 34 """ 35 处理字符串, 36 # 第一种,算出_varticle7579013546commentv2(的长度,然后切片 37 # 第二种,用正则表达式提取_varticle7579013546commentv2((*.?)) 38 # 第三种,用字符串方法lstrip('_varticle7579013546commentv2(')和rstrip(')')去除左右两边多余的东西 39 三种方法提取出来的字符串是一样的 40 """ 41 # htmlString1 = htmlText[29:-1] # 第一种切片 42 # print(htmlString1) 43 # htmlString2 = re.findall('_varticle7579013546commentv2\((.*?)\)', htmlText)[0] # 正则提取 44 # print(htmlString2) 45 # htmlString3 = htmlText.replace('_varticle7579013546commentv2(', '').rstrip(')') # 替换 46 # print(htmlString3) 47 # print(htmlString1==htmlString2==htmlString3) # True 48 htmlString = htmlText[29:-1] 49 json_data = json.loads(htmlString) # 转换成json 50 return json_data 51 52 def parse_json_data(self): 53 userIds = [] 54 contents = [] 55 pictureNums = [] 56 commentTimes = [] 57 likeCounts = [] 58 replyNums = [] 59 indexScores = [] 60 json_data = self.responseToJson() 61 results = json_data['data']['oriCommList'] # 要的评论结果 62 # 63 for item in results: 64 userId = item['userid'] # 评论者id 65 userIds.append(userId) 66 67 # 尝试获取一下是否有图片,以及评论的时候带了几张图片 68 try: 69 pictureNum = len(item['picture']) # 评论图片 70 except: 71 pictureNum = None 72 pictureNums.append(pictureNum) 73 commentTime = item['time'] # 十位时间戳,秒级,毫秒级是13位 74 commentTimes.append(commentTime) 75 likeCount = item['up'] # 评论获赞数 76 likeCounts.append(likeCount) 77 replyNum = item['orireplynum'] # 评论被回复的数量 78 replyNums.append(replyNum) 79 indexScore = item['indexscore'] # 排名评分 80 indexScores.append(indexScore) 81 content = item['content'] # 评论内容 82 contents.append(content) 83 # print(userId, pictureNum, commentTime, likeCount, replyNum, indexScore, content, sep = ' | ') 84 zipdata = zip(userIds, pictureNums, commentTimes, likeCounts, replyNums, indexScores, contents) 85 86 return zipdata 87 88 def get_next_cursor_id(self): 89 """ 90 获取到请求下一页的cursor参数,也就是json文件里的last 91 """ 92 json_data = self.responseToJson() 93 last = json_data['data']['last'] # 获取参数 94 cursor = last 95 return cursor 96 97 def saveToCsv(self, csvfile): 98 csvWriter = csv.writer(csvfile) 99 csvWriter.writerow(['评论者Id', '评论内容图片数', '评论时间', '评论获赞数', '评论被回复数', '评论rank值', '评论内容', ]) 100 results = self.parse_json_data() 101 for userId, pictureNum, commentTime, likeCount, replyNum, indexScore, content in results: 102 csvWriter.writerow([userId, pictureNum, commentTime, likeCount, replyNum, indexScore, content]) 103 104 def run(self): 105 self.saveToCsv(csvfile) 106 if __name__ == "__main__": 107 csvfile = open('雪中悍刀行评论信息.csv', mode='a', encoding='utf-8-sig', newline='') 108 page = 1 109 while page < 1000+1: 110 if page == 1: 111 params = { 112 "callback": "_varticle7579013546commentv2", 113 "orinum": "10", 114 "oriorder": "o", 115 "pageflag": "1", 116 "cursor": "0", 117 "scorecursor": "0", 118 "orirepnum": "2", 119 "reporder": "o", 120 "reppageflag": "1", 121 "source": "132", 122 "_": "1641368986144", 123 } 124 else: 125 params = { 126 "callback": "_varticle7579013546commentv2", 127 "orinum": "10", 128 "oriorder": "o", 129 "pageflag": "1", 130 "cursor": app.get_next_cursor_id(), 131 "scorecursor": "0", 132 "orirepnum": "2", 133 "reporder": "o", 134 "reppageflag": "1", 135 "source": "132", 136 "_": "1641368986144", 137 } 138 print(f'===================开始采集第{page}页数据。==================') 139 print() # 打印个空格 140 time.sleep(random.uniform(2, 5)) 141 url = 'https://video.coral.qq.com/varticle/7579013546/comment/v2' 142 app = commentSpider(url=url, params=params) 143 cursor = app.get_next_cursor_id() 144 print(f'**********第{page}页产生的cursor为{cursor},供第{page + 1}页使用!**********') 145 app.saveToCsv(csvfile=csvfile) 146 page += 1 147 csvfile.close()
至此,爬虫部分完成。
第二部分,数据处理
数据处理部分主要分为时间处理和内容处理。时间处理要处理出日期和时段,内容处理的话就一个演员提及占比。所以先将txt转换成csv(早知道直接用csv保存了)。
1,评论时间戳转成正常的时间。我喜欢叫格式化时间。
1 """ 2 爬取到的评论时间是时间戳,现在将它转换成正常的时间 3 这里把转换后的时间写入到csv文档,比较好读取 4 """ 5 import csv 6 import time 7 8 csvFile = open('timedata.csv', mode='a', encoding='utf-8-sig', newline='') # csv文档用来存储正常时间的 9 csvWriter = csv.writer(csvFile) 10 11 with open('spider/雪中悍刀行评论时间.txt', mode='r', encoding='utf-8') as f: 12 for line in f: 13 line = line.strip() # 行去空格 14 line = int(line) # 强制转换成整数 15 timedata = time.localtime(line) # 转换成本地时间 16 localtime = time.strftime("%Y-%m-%d %H:%M:%S", timedata) # 格式化本地时间 17 # print(type(localtime)) 18 localtime = localtime.split() # 以空格分割字符串 19 csvWriter.writerow(localtime) 20 csvFile.close()
2,评论内容写入csv文档。
1 """ 2 将评论内容读入csv 3 """ 4 import csv 5 6 csvFile = open('content.csv', mode='a', encoding='utf-8-sig', newline='') 7 csvWriter = csv.writer(csvFile) 8 9 with open(r'../spider/雪中悍刀行评论内容.txt', mode='r', encoding='utf-8') as f: 10 for line in f: 11 csvWriter.writerow(line.split()) # 写入行的时候一定是个字典 12 13 csvFile.close()
3,全局数据,按小时统计评论并写入csv。也就是全局数据内,0点有几条评论,1点有几条评论,以此类推,直到23点。
1 """ 2 评论时间是每次评论产生的时间,所以将时间csv所有条目提取出来,用来统计24个小时,每小时产生的评论数 3 """ 4 5 import csv 6 def getHourAndHourCount(): 7 """ 8 在总评论中获取每个点出现的次数 9 """ 10 with open(r'timedata.csv', mode='r', encoding='utf-8') as f: 11 reader = csv.reader(f) 12 # for row in reader: # 读取行,每一行都是一个list 13 # print(row) 14 hourTime = [str(row[1])[0:2] for row in reader] # 读取时间列并提取小时 15 # print(hourTime) 16 # print(type(hourTime)) # <class 'list'> 17 18 # 建立集合 19 timeSet = set(hourTime) 20 hourCount = [] 21 # 遍历集合 22 for item in timeSet: 23 hourCount.append((item, hourTime.count(item))) # 添加元素及出现的次数 24 # 排序 25 hourCount.sort() 26 # print(hourCount) 27 return hourCount 28 29 hourCounts = getHourAndHourCount() 30 print(hourCounts) 31 # 将函数得到的值存储到另外一个csv文档 32 with open('timedataprocessed.csv', mode='w+', encoding='utf-8-sig', newline='') as f: 33 csvWriter = csv.writer(f) 34 for hour in hourCounts: 35 csvWriter.writerow(hour) # hour是个元组,也就是在csv里写入两列 36 37 38 def setXandYdata(): 39 # 开始提取x轴和y轴需要的数据 40 # 首先是x轴 41 with open('timedataprocessed.csv', mode='r', encoding='utf-8-sig') as f: 42 reader = csv.reader(f) # 读取csv文档 43 hour = [str(row[0]) for row in reader] # 将每个时间的数字提取出来用来做x轴数据和标签 44 print(hour) 45 46 #其次是y轴 47 with open('timedataprocessed.csv', mode='r', encoding='utf-8-sig') as f: 48 reader = csv.reader(f) 49 count = [float(row[1]) for row in reader] 50 print(count)
4,全局数据,按天统计评论条数。比如全局数据采集到的时间是2021-12-24到2022-01-01,期间每一天产生的评论数量。
1 """ 2 统计评论时间中每天出现的评论数量 3 如果不用utf-8-sig进行编码会出现\ufeff 4 """ 5 6 import csv 7 def getLatestContent(): 8 """ 9 读取时间文档并按天提取参数 10 """ 11 with open(r'timedata.csv', mode='r', encoding='utf-8-sig') as f: 12 reader = csv.reader(f) 13 dateTime = [str(row[0]) for row in reader] 14 print(dateTime) 15 # print(type(dateTime)) 16 # 转换成集合 17 dateSet = set(dateTime) 18 # print(dateSet) 19 dateCount = [] 20 # 开始统计出现的次数 21 for item in dateSet: 22 dateCount.append((item, dateTime.count(item))) 23 dateCount.sort() 24 return dateCount 25 # 写入到另外一个csv文档里 26 dateCounts = getLatestContent() 27 with open('dateprocessed.csv', mode='w+', encoding='utf-8-sig', newline='') as f: 28 csvWriter = csv.writer(f) 29 for date in dateCounts: 30 csvWriter.writerow(date) # date是元组类型 31 32 def setXandYdata(): 33 """ 34 利用新csv获取x轴和y轴数据 35 """ 36 with open('dateprocessed.csv', mode='r', encoding='utf-8-sig') as f: 37 reader = csv.reader(f) 38 date = [str(row[0]) for row in reader] 39 print(date) 40 41 # 提取数量 42 with open('dateprocessed.csv', mode='r', encoding='utf-8') as f: 43 reader = csv.reader(f) 44 count = [float(row[1]) for row in reader] 45 print(count)
数据处理完毕,接下来就是数据可视化以及简单的数据分析。
第三部分,数据可视化和简单的数据分析
1,词云展示
1 """ 2 词云制作 3 """ 4 import jieba 5 import numpy as np 6 import re 7 from PIL import Image 8 from wordcloud import WordCloud 9 from matplotlib import pyplot as plt 10 11 # f = open('../spider/雪中悍刀行评论内容.txt', mode='r', encoding='utf-8-sig') # 打开文档,原始评论数据,是词的来源 12 # txt = f.read() # 读取打开的文档 13 # print(txt) 14 # f.close() # 关闭文档 15 16 with open('../spider/雪中悍刀行评论内容.txt', mode='r', encoding='utf-8') as f: 17 txt = f.read() # 读取文档 18 19 newTxt = re.sub(r"[A-Za-z0-9\!\%\[\]\,\。#😁🦵☁?😂⛽🌚👍🏻💩😄💕😊✨\\n]", "", txt) # 将txt中的特殊字符替换一下 20 print(newTxt) 21 22 # 分词 23 words = jieba.lcut(newTxt) # 利用jieba进行分词 24 # 背景图 25 bgimg = Image.open('../wc.jpg') 26 img_array = np.array(bgimg) # 二值化 27 28 wordcloud = WordCloud( 29 background_color='Yellow', 30 width=1080, 31 height=960, 32 font_path="../文悦新青年体.otf", 33 max_words=150, # 最大词数 34 scale=10, #清晰度 35 max_font_size=100, 36 mask=img_array, 37 collocations=False).generate(newTxt) 38 39 plt.imshow(wordcloud) 40 plt.axis('off') 41 plt.show() 42 wordcloud.to_file('wc.png')
2,全局数据,各个小时产生的评论条形图。
1 """ 2 每小时评论总数的条形图统计 3 """ 4 from pyecharts.charts import Bar 5 from pyecharts.globals import ThemeType 6 import pyecharts.options as opts 7 import csv 8 9 class drawBar(): 10 """ 11 绘制每个小时所产生评论的条形图 12 """ 13 def __init__(self): 14 self.bar = Bar(init_opts=opts.InitOpts(width='1200px', height='700px', theme=ThemeType.LIGHT)) 15 16 def add_x(self): 17 with open('../dataProcess/timedataprocessed.csv', mode='r', encoding='utf-8-sig') as f: 18 reader = csv.reader(f) 19 x = [str(row[0]) for row in reader] 20 print(x) 21 22 # 添加x轴数据 23 self.bar.add_xaxis( 24 xaxis_data=x, 25 ) 26 27 def add_y(self): 28 with open('../dataProcess/timedataprocessed.csv', mode='r', encoding='utf-8-sig') as f: 29 reader = csv.reader(f) 30 y = [float(row[1]) for row in reader] 31 print(y) 32 33 self.bar.add_yaxis( 34 series_name='每小时评论数', # 第一个系列 35 y_axis = y, # 第一个系列数据 36 label_opts=opts.LabelOpts(is_show=True, color='Black'), # y轴标签属性 37 bar_max_width='100px', # 柱子最大宽度 38 ) 39 40 # 为了区分y轴上数据的系列,这里再加一个空系列 41 self.bar.add_yaxis( 42 series_name='这是第二个系列', 43 y_axis=None, 44 ) 45 46 def set_gloabl(self): 47 self.bar.set_global_opts( 48 title_opts=opts.TitleOpts( 49 title='雪中悍刀行每小时产生的评论总数', 50 title_textstyle_opts=opts.TextStyleOpts(font_size=35), 51 ), 52 # 提示框配置,鼠标移动到上面所提示的东西 53 tooltip_opts=opts.TooltipOpts( 54 is_show=True, 55 trigger='axis', # 触发类型,axis坐标轴触发,鼠标移动到的时候会有一个x轴的实线跟随鼠标移动,并显示提示信息。 56 axis_pointer_type='cross', # 指示器类型(cross将会生成两条分别垂直于X轴和Y轴的虚线,不启用trigger才会显示完全) 57 ), 58 toolbox_opts=opts.ToolboxOpts(), # 工具栏选项,什么都不填会显示所有工具 59 legend_opts=opts.LegendOpts( # 调整图例的位置,也就是y轴seriesname的位置 60 pos_left='30%', 61 pos_top='110px', 62 ), # 63 ) 64 65 def draw(self): 66 # 开始绘制 67 self.add_x() 68 self.add_y() 69 self.set_gloabl() 70 self.bar.render('雪中悍刀行每个小时点产生的评论汇总.html') 71 72 def run(self): 73 # 一个运行函数 74 self.draw() 75 76 if __name__ == "__main__": 77 app = drawBar() 78 app.run()
3,全局数据内,各天产生数据的条形图。
1 """ 2 统计评论时间内,每天所产生的的评论数 3 """ 4 from pyecharts.charts import Bar 5 from pyecharts.globals import ThemeType 6 import pyecharts.options as opts 7 import csv 8 9 class drawBar(): 10 """ 11 一个统计评论时间内,每天产生评论总数的条形图的类 12 """ 13 def __init__(self): 14 self.bar = Bar(init_opts=opts.InitOpts(width='1280px', height='960px', theme=ThemeType.VINTAGE)) 15 16 def add_x(self): 17 """ 18 x轴数据 19 """ 20 # 先打开csv文档读取数据 21 with open('../dataProcess/dateprocessed.csv', mode='r', encoding='utf-8-sig') as f: 22 reader = csv.reader(f) # csv阅读对象 23 x = [str(row[0]) for row in reader] # 提取csv的第一列 24 print(x) # 是个列表 25 26 # 将数据添加到x轴 27 self.bar.add_xaxis( 28 xaxis_data=x, 29 ) 30 31 def add_y(self): 32 # 先读出数据 33 with open('../dataProcess/dateprocessed.csv', mode='r', encoding='utf-8-sig') as f: 34 reader = csv.reader(f) 35 y = [float(row[1]) for row in reader] 36 print(y) # 列表 37 38 # 添加到y轴 39 self.bar.add_yaxis( 40 series_name='每天产生的评论数', 41 y_axis=y, 42 label_opts=opts.LabelOpts(is_show=True, color='Red'), # y轴标签设置 43 bar_width='20px', # 设置柱子宽度 44 ) 45 46 def set_global(self): 47 """ 48 设置全局属性 49 """ 50 self.bar.set_global_opts( 51 xaxis_opts=opts.AxisOpts( 52 axislabel_opts=opts.LabelOpts(rotate=45), # 让x轴呈45度倾斜 53 ), # 设置x轴坐标 54 # datazoom_opts=opts.DataZoomOpts(), # 水平方向有拖块儿 55 title_opts=opts.TitleOpts( 56 title='雪中悍刀行评论内容每天产生的评论数', 57 title_textstyle_opts=opts.TextStyleOpts(font_size=28) 58 ), 59 # 提示设置 60 tooltip_opts=opts.TooltipOpts( 61 is_show=True, # 是否出现 62 trigger='axis', # 触发类型,(axis表示坐标轴触发,鼠标移动上去的时候会有一条垂直于x轴的实线跟随鼠标移动,并且提示信息) 63 axis_pointer_type='cross', # 指示器类型,(Cross表示生成两条分别垂直于x轴和y轴的虚线,不启用trigger才会显示完全) 64 ), 65 toolbox_opts=opts.ToolboxOpts(), # 工具箱配置,不填参数默认表示所有都开启 66 legend_opts=opts.LegendOpts( 67 pos_left='10%', 68 pos_top='110px', 69 ), 70 ) 71 72 def draw(self): 73 # 开始绘制 74 self.add_x() 75 self.add_y() 76 self.set_global() 77 self.bar.render('每天评论总数统计.html') 78 79 def run(self): 80 self.draw() 81 82 if __name__ == "__main__": 83 app = drawBar() 84 app.run()
4,全局数据,每小时产生评论的饼图。
1 """ 2 评论时间内,每个小时产生的评论的饼图 3 """ 4 from pyecharts.charts import Pie 5 from pyecharts.globals import ThemeType 6 import pyecharts.options as opts 7 import csv 8 9 class drawPie(): 10 """ 11 评论时间内,每个小时产生的评论数量饼图 12 """ 13 def __init__(self): 14 self.pie = Pie(init_opts=opts.InitOpts(width='1700px', height='500px', theme=ThemeType.VINTAGE)) 15 16 def set_global(self): 17 # 设置全局属性 18 self.pie.set_global_opts( 19 # 标题属性 20 title_opts=opts.TitleOpts( 21 title='每小时产生的评论饼图', 22 title_textstyle_opts=opts.TextStyleOpts(font_size=28), 23 ), 24 # 图例位置 25 legend_opts=opts.LegendOpts( 26 pos_left='20%', 27 pos_top='10%', 28 ), 29 ) 30 self.pie.set_series_opts( 31 label_opts=opts.LabelOpts(formatter="{b}:{c}"), 32 ) 33 def get_data_and_add(self): 34 # 首先读取的是小时 35 with open('../dataProcess/timedataprocessed.csv', mode='r', encoding='utf-8-sig') as f: 36 reader = csv.reader(f) 37 hour = [str(row[0]) for row in reader] # 读取到的是小时 38 print(hour) 39 # 其次读取的是次数 40 with open('../dataProcess/timedataprocessed.csv', mode='r', encoding='utf-8-sig') as f: 41 reader = csv.reader(f) 42 count = [float(row[1]) for row in reader] # 读取到的是统计的次数 43 print(count) 44 45 # 将他们添加到饼图里 46 self.pie.add('饼图', center=[280, 270], data_pair=[(i, j) for i, j in zip(hour, count)]) # 饼图 47 self.pie.add('环图', center=[845, 270], data_pair=[(i, j) for i, j in zip(hour, count)], radius=['40%', '75%']) 48 self.pie.add('南丁格尔图', center=[1350, 260], data_pair=[(i, j) for i, j in zip(hour, count)], rosetype='radius') 49 50 def draw(self): 51 self.set_global() 52 self.get_data_and_add() 53 self.pie.render('每小时产生评论饼图.html') 54 55 def run(self): 56 self.draw() 57 58 if __name__ == "__main__": 59 app = drawPie() 60 app.run()
5,全局数据内,各天产生评论的饼图。
1 """ 2 评论时间内,每天产生的评论统计饼图 3 """ 4 from pyecharts.charts import Pie 5 from pyecharts.globals import ThemeType 6 import pyecharts.options as opts 7 import csv 8 9 class drawPie(): 10 """ 11 每天评论总数饼图 12 """ 13 def __init__(self): 14 self.pie = Pie(init_opts=opts.InitOpts(width='1700px', height='750px', theme=ThemeType.VINTAGE)) 15 16 def set_global(self): 17 # 设置全局属性 18 self.pie.set_global_opts( 19 title_opts=opts.TitleOpts( 20 title='每天的评论数量统计', 21 title_textstyle_opts=opts.TextStyleOpts(font_size=18), 22 ), 23 legend_opts=opts.LegendOpts( 24 pos_left='20%', 25 pos_top='100px', 26 ), 27 ) 28 # 设置标签属性 29 self.pie.set_series_opts(label_opts=opts.LabelOpts(formatter="{b}:{c}")) 30 31 def get_data_and_add(self): 32 # 提取出标签 33 with open('../dataProcess/dateprocessed.csv', mode='r', encoding='utf-8-sig') as f: 34 reader = csv.reader(f) 35 lab = [str(row[0]) for row in reader] 36 print(lab) 37 38 # 提取数据 39 with open('../dataProcess/dateprocessed.csv', mode='r', encoding='utf-8-sig') as f: 40 reader = csv.reader(f) 41 num = [float(row[1]) for row in reader] 42 print(num) 43 44 # 添加数据 45 self.pie.add(series_name='饼图', center=[280, 370], data_pair=[list(z) for z in zip(lab, num)]) # 饼图 46 self.pie.add(series_name='环图', center=[845, 380], data_pair=[list(z) for z in zip(lab, num)], radius=['40%', '75%']) # 环图 47 self.pie.add(series_name='南丁格尔图', center=[1350, 380], data_pair=[list(z) for z in zip(lab, num)], rosetype='radius') # 南丁格尔图 48 49 def draw(self): 50 self.set_global() # 设置全局属性 51 self.get_data_and_add() # 添加 52 self.pie.render('每天评论数量饼图.html') 53 54 def run(self): 55 self.draw() 56 57 if __name__ == "__main__": 58 app = drawPie() 59 app.run()
6,全局数据内,观看时间区间,即凌晨,上午,下午,晚上产生评论的饼图。这样也可以分析出,哪个时间段人数评论最活跃。
1 """ 2 制作观看时间区间评论统计饼图,也就是上午看的还是下午看的之类的 3 """ 4 import csv 5 from pyecharts.charts import Pie 6 from pyecharts.globals import ThemeType 7 import pyecharts.options as opts 8 9 # 先把时间读出来 10 with open('../dataProcess/timedata.csv', mode='r', encoding='utf-8-sig') as f: 11 reader = csv.reader(f) 12 timeInt = [int(row[1].strip('')[0:2]) for row in reader] 13 print(timeInt) 14 15 # 建立集合,取出唯一的 16 timeSet = set(timeInt) 17 timeList = [] # 18 for item in timeSet: 19 timeList.append((item, timeInt.count(item))) 20 timeList.sort() 21 print(timeList) 22 23 # 将timeList写入到新文档 24 with open('time2.csv', mode='w+', encoding='utf-8-sig', newline='') as f: 25 csvWriter = csv.writer(f, delimiter=',') 26 for item in timeList: 27 csvWriter.writerow(item) 28 29 # 开始分组 30 n = 4 # 分成四组 31 m = int(len(timeList)/n) # 就是6 32 timeList2 = [] # 建立空分组 33 for item in range(0, len(timeList), m): # 34 timeList2.append(item) 35 print(timeList2) # [0, 6, 12, 18] 36 print('凌晨:', timeList2[0]) 37 print('上午:', timeList2[1]) 38 print('下午:', timeList2[2]) 39 print('晚上:', timeList2[3]) 40 41 # 读取刚刚建的csv文档 42 with open('time2.csv', mode='r', encoding='utf-8-sig') as f: 43 reader = csv.reader(f) 44 y1 = [int(row[1]) for row in reader] 45 # print(y1) 46 47 n = 6 48 groups = [y1[i:i+n] for i in range(0, len(y1), n)] 49 print(groups) 50 51 x = ['凌晨', '上午', '下午', '晚上'] 52 y1 = [] 53 for y1 in groups: 54 numSum = 0 55 for groups in y1: 56 numSum += groups 57 58 strName = '点' 59 num = y1 60 lab = x 61 62 ( 63 Pie(init_opts=opts.InitOpts(width='1500px', height='450px', theme=ThemeType.LIGHT)) 64 .set_global_opts( 65 title_opts=opts.TitleOpts( 66 title='雪中悍刀行观看时间区间评论统计', 67 title_textstyle_opts=opts.TextStyleOpts(font_size=28), 68 ), 69 legend_opts=opts.LegendOpts( 70 pos_left='10%', 71 pos_top='8%', 72 ) 73 ) 74 .add(series_name='', center=[260, 270], data_pair=[(j, i) for i, j in zip(num, lab)]) # 饼图 75 .add(series_name='', center=[1230, 270], data_pair=[(j, i) for i, j in zip(num, lab)], radius=['40%', '75%']) 76 .add(series_name='', center=[750, 270], data_pair=[(j, i) for i, j in zip(num, lab)], rosetype='radius') 77 ).render('观看时间评论统计.html')
7,演员提及占比饼图。
1 """ 2 主演提及饼图 3 """ 4 from pyecharts.charts import Pie 5 from pyecharts.globals import ThemeType 6 import pyecharts.options as opts 7 import csv 8 9 # f = open('../spider/雪中悍刀行评论内容.txt', 'r', encoding='utf-8') # 这是数据源,也就是想生成词云的数据 10 # words = f.read() # 读取文件 11 # f.close() # 关闭文件,其实用with就好,但是懒得改了 12 with open('../spider/雪中悍刀行评论内容.txt', mode='r', encoding='utf-8-sig') as f: 13 words = f.read() 14 print(words) 15 16 actors = ["张若昀","李庚希","胡军"] 17 counts = [ 18 float(words.count('张若昀')), 19 float(words.count('李庚希')), 20 float(words.count('胡军')), 21 ] 22 print(counts) 23 num = counts 24 lab = actors 25 26 ( 27 Pie(init_opts=opts.InitOpts(width='1650px', height='550px', theme=ThemeType.LIGHT)) 28 .set_global_opts( 29 title_opts=opts.TitleOpts( 30 title='雪中悍刀行演员提及占比', 31 title_textstyle_opts=opts.TextStyleOpts(font_size=28), 32 ), 33 legend_opts=opts.LegendOpts( 34 pos_left='8%', 35 pos_top='8%', 36 ) 37 ) 38 .add(series_name='', center=[280, 270], data_pair=[(i, j) for i, j in zip(lab, num)]) # 第一个参数是标签,第二个是值 39 .add(series_name='', center=[800, 270], data_pair=[list(z) for z in zip(lab, num)], radius=['40%', '70%']) 40 .add(series_name='', center=[1300, 270], data_pair=[list(z) for z in zip(lab, num)], rosetype='radius') 41 ).render('演员提及饼图.html')
8,评论内容情感分析。分值在0,1之间,越接近1表示越评论内容越积极,反之则越消极。
1 """ 2 评论内容情感分析 3 """ 4 5 import numpy as np 6 from snownlp import SnowNLP 7 import matplotlib.pyplot as plt 8 9 with open('../spider/雪中悍刀行评论内容.txt', mode='r', encoding='utf-8') as f: 10 lis = f.readlines() 11 12 sentimentlist = [] 13 14 for i in lis: 15 s = SnowNLP(i) 16 print(s.sentiments) 17 sentimentlist.append(s.sentiments) 18 19 plt.hist(sentimentlist, bins=np.arange(0, 1, 0.01), facecolor='g') 20 plt.xlabel('Sentiments Probability') 21 plt.ylabel('Quantity') 22 plt.title('Analysis of Sentiments') 23 plt.show()
好像都忘记放效果图了,最后放一个评论内容情感分析的效果图。
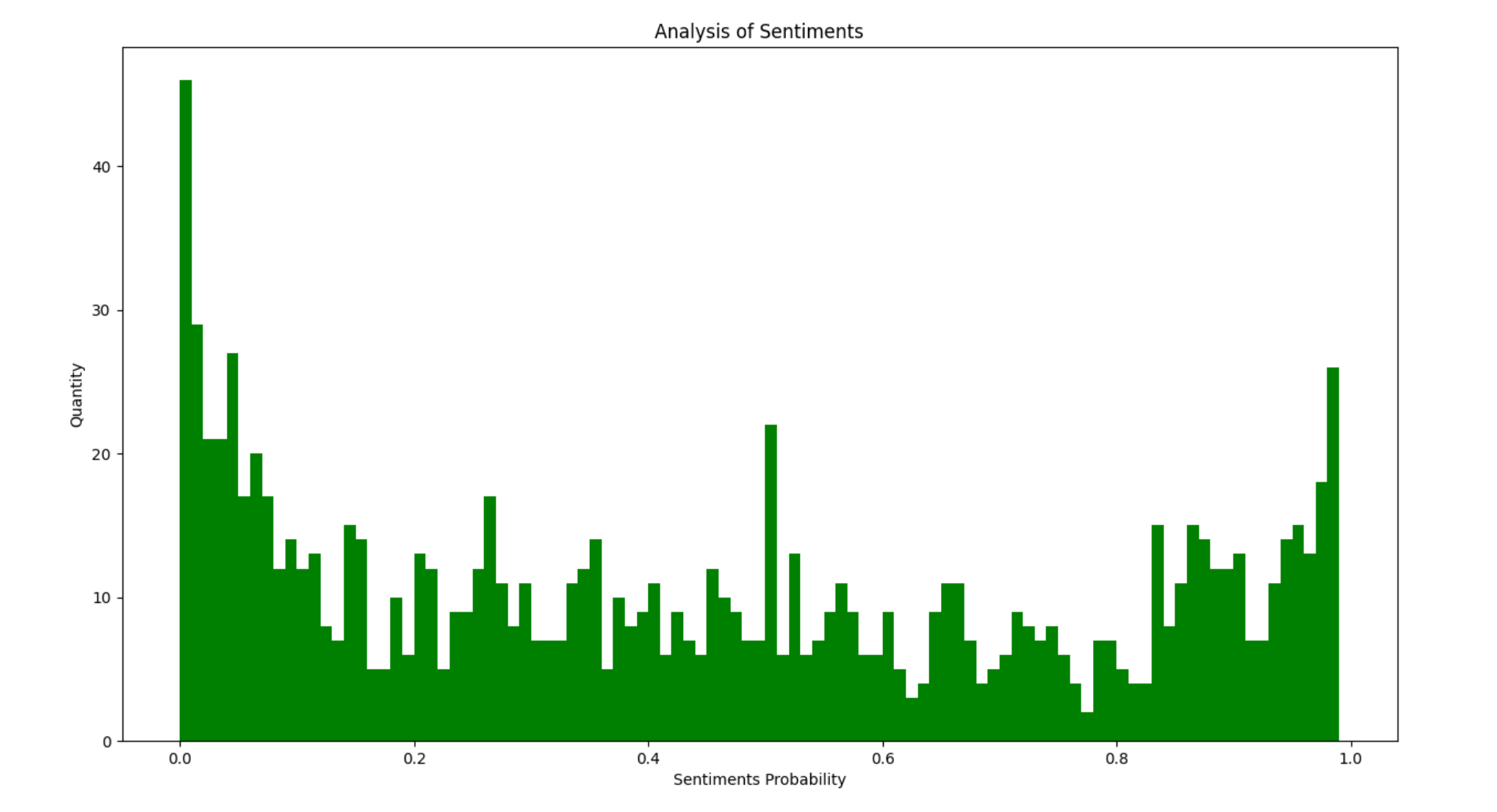
从图中大致看出,消极评论的人还是占多数,因为咱天朝大多键盘侠,有些人根本就是一点都不尊重社会化生产劳动下产生的成果。也可以利用上面的数据,做一个线性回归。做完之后就可以做一个可视化大屏。 - Pyecharts绘制精美图标并做成可视化大屏 - Python。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号