爬取微博热搜榜 - 李白之死 - Python
最近有关中国传统文化的内容频频登上热搜,就比如最近的李白之死,今天换一种方式爬取,以前爬取微博评论是网址里一大串参数,今天把参数提出来做一个字典,然后请求的时候再构造url。
1 """ 2 就爬取李白之死的评论 3 """ 4 import requests 5 import re 6 import openpyxl as op 7 8 wb = op.Workbook() 9 ws = wb.create_sheet(index=0) 10 # 表头 11 ws.cell(row=1, column=1, value='评论者id') # 第一行第一列userId 12 ws.cell(row=1, column=2, value='评论者昵称') # 第一行第一列userId 13 ws.cell(row=1, column=3, value='获赞数') # 第一行第一列userId 14 ws.cell(row=1, column=4, value='创建时间') # 第一行第一列userId 15 ws.cell(row=1, column=5, value='评论内容') # 第一行第一列userId 16 17 headers = { 18 "cookie": "cookie", 19 "referer": "https://m.weibo.cn/status/L690FmKXW?jumpfrom=weibocom", 20 "user-agent": "Mozilla/5.0 (iPhone; CPU iPhone OS 13_2_3 like Mac OS X) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/13.0.3 Mobile/15E148 Safari/604.1", 21 } 22 page = 1 23 while page < 100 + 1: 24 url = 'https://m.weibo.cn/comments/hotflow' 25 if page == 1: 26 params = { 27 'id': '4714646055423756', 28 'mid': '4714646055423756', 29 'max_id_type':0, 30 } 31 else: 32 params = { 33 'id': '4714646055423756', 34 'mid': '4714646055423756', 35 'max_id': max_id, 36 'max_id_type':max_id_type, 37 } 38 response = requests.get(url=url, headers=headers, params=params) 39 max_id = response.json()['data']['max_id'] 40 max_id_type = response.json()['data']['max_id_type'] 41 results = response.json()['data']['data'] # 获取到评论列表 42 for item in results: 43 userId = item['user']['id'] 44 userName = item['user']['screen_name'] 45 likeCount = item['like_count'] 46 timeCreated = item['created_at'] # 创建时间 47 commentContent = item['text'] # 评论内容 48 print(userId, userName, likeCount, timeCreated, commentContent, response.url, sep=' | ') 49 ws.append([userId, userName, likeCount, timeCreated, commentContent]) 50 page += 1 51 52 wb.save('李白之死.xlsx') 53 wb.close()
保存方式有很多,前面也有过一篇关于python爬虫数据保存方式的。但是今天只要爬评论内容来做个词频。
1 """ 2 就爬取李白之死的评论 3 """ 4 import requests 5 import re 6 import openpyxl as op 7 8 # wb = op.Workbook() 9 # ws = wb.create_sheet(index=0) 10 # 表头 11 # ws.cell(row=1, column=1, value='评论者id') # 第一行第一列userId 12 # ws.cell(row=1, column=2, value='评论者昵称') # 第一行第一列userId 13 # ws.cell(row=1, column=3, value='获赞数') # 第一行第一列userId 14 # ws.cell(row=1, column=4, value='创建时间') # 第一行第一列userId 15 # ws.cell(row=1, column=5, value='评论内容') # 第一行第一列userId 16 17 headers = { 18 "cookie": "cookie", 19 "referer": "https://m.weibo.cn/status/L690FmKXW?jumpfrom=weibocom", 20 "user-agent": "Mozilla/5.0 (iPhone; CPU iPhone OS 13_2_3 like Mac OS X) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/13.0.3 Mobile/15E148 Safari/604.1", 21 } 22 page = 1 23 while page < 100 + 1: 24 url = 'https://m.weibo.cn/comments/hotflow' 25 if page == 1: 26 params = { 27 'id': '4714646055423756', 28 'mid': '4714646055423756', 29 'max_id_type':0, 30 } 31 else: 32 params = { 33 'id': '4714646055423756', 34 'mid': '4714646055423756', 35 'max_id': max_id, 36 'max_id_type':max_id_type, 37 } 38 response = requests.get(url=url, headers=headers, params=params) 39 max_id = response.json()['data']['max_id'] 40 max_id_type = response.json()['data']['max_id_type'] 41 results = response.json()['data']['data'] # 获取到评论列表 42 for item in results: 43 """ 44 这一次只爬评论内容 45 """ 46 commentContent = re.sub(r'<[^>]*>', '', item['text']) # 将评论内容里的特殊字符用正则替换掉 47 print(commentContent) 48 with open('libazhisi.txt', mode='a', encoding='utf-8') as f: 49 f.write(f'{commentContent}\n') # 换行写入 50 page += 1 51 52 # wb.save('李白之死.xlsx') 53 # wb.close()
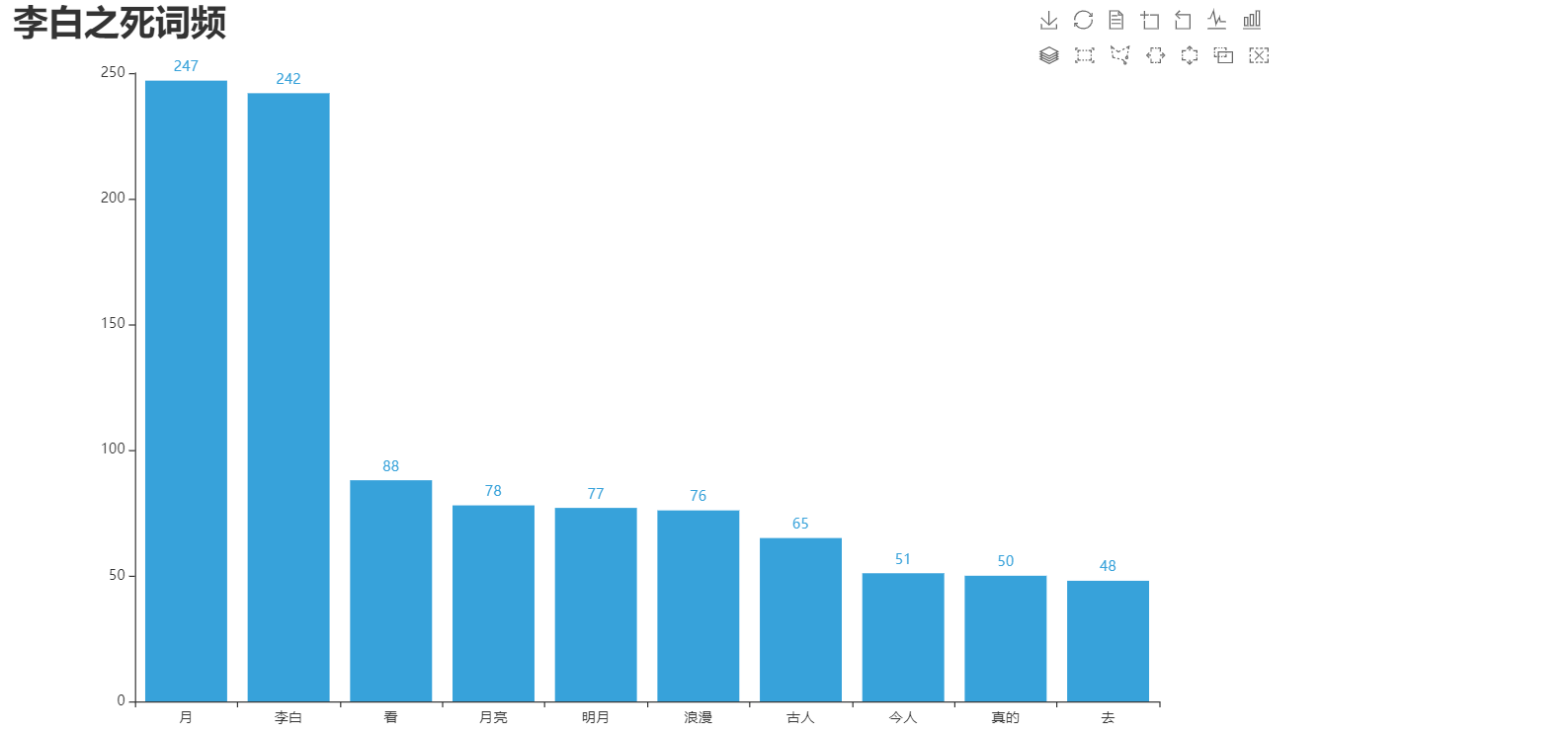
词频展示:
1 """ 2 做个词频 3 """ 4 # 打开文档 5 import re 6 from collections import Counter 7 import jieba 8 from pyecharts.charts import Bar 9 import pyecharts.options as opts 10 from pyecharts.globals import ThemeType 11 12 def replaceSth(sth): 13 pattern = re.compile(r'[a-zA-Z0-9…,\@”![\\]_]。') 14 new = re.sub(pattern, '', sth) 15 return new 16 17 with open('李白之死.txt', mode='r', encoding='utf-8') as f: 18 reader = f.read() 19 new_reader = re.sub('[”0-9a-zA-Z!🙊🌙?,\@\-\_/\[\]\\...\\#【】\*\…。\“]', '', reader) 20 # print(new_reader) 21 # 打开停用此表 22 with open('stopwords.txt', mode='r', encoding='utf-8') as f: 23 stopReader = f.read() 24 word = jieba.cut(new_reader) # 分词 25 words = [] # 空list 26 for item in list(word): # 遍历 27 if item not in stopReader: # 条件判断 28 words.append(item) # 追加列表 29 30 # print(dict(Counter(words))) # 打印分词 31 # 开始画图 32 label = [] # x轴标签 33 data = [] # y轴数据 34 for k, v in dict(Counter(words).most_common(10)).items(): # 取字典里常出现的十个 35 label.append(k) 36 data.append(v) 37 38 bar = ( 39 Bar(init_opts=opts.InitOpts(width='1080px', height='960px', theme=ThemeType.LIGHT)) 40 .add_xaxis(label) 41 .add_yaxis(series_name='', y_axis=data) 42 .set_global_opts( 43 title_opts=opts.TitleOpts( 44 title='李白之死词频', 45 title_textstyle_opts=opts.TextStyleOpts(font_size=30),), 46 toolbox_opts=opts.ToolboxOpts(), 47 tooltip_opts=opts.TooltipOpts( 48 is_show=True, 49 trigger='axis', 50 axis_pointer_type='cross', 51 ), 52 ) 53 ).render('词频.html')

 浙公网安备 33010602011771号
浙公网安备 33010602011771号