
CMS系统模版引擎设计(2):页面生产流程
我画了一张图,先看一下生产流程。
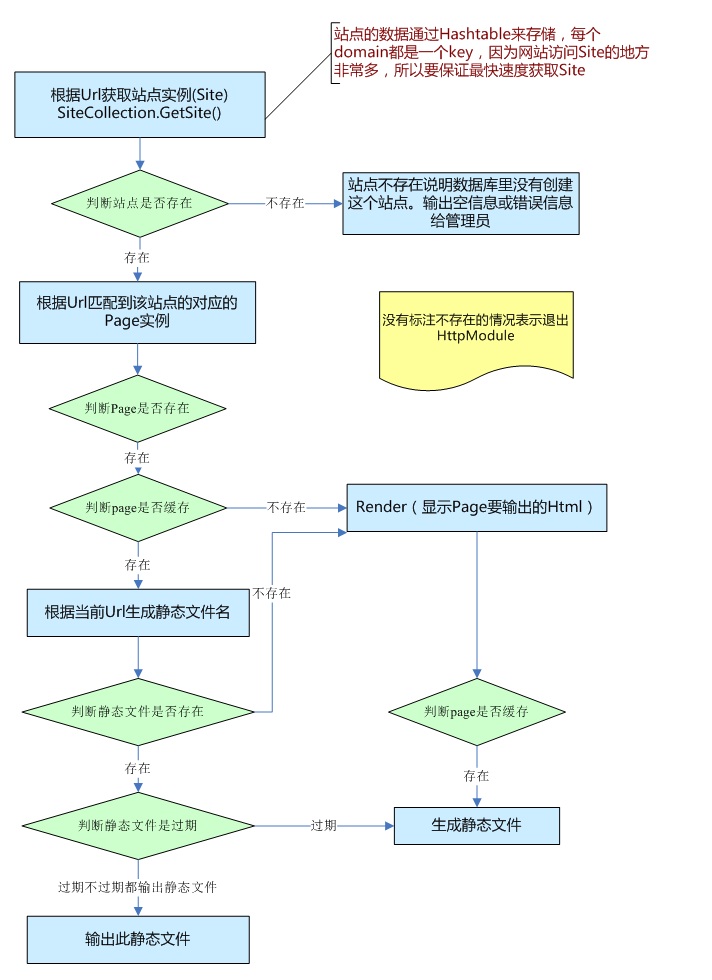
步骤如下:
获取匹配当前domain的Site,如果匹配不到,说明数据库中不存在这个Site。那就只能输出空信息了。
【注意】如果你想让你的URL访问没有后缀,那必须添加“通配符映射”,并且不能“检查文件是否存在”,什么是通配符?即使所有的URL格式,不管是什么后最,有没有后缀,都会走ASP.NET的 ISAPI筛选器。也就是都会走我们定义的HttpModule,包括页面内的图片、js等静态资源。所以我们必须过滤掉不想处理的后缀,这些后缀可以是针对每个Site配置,也可以针对全局配置,所以我们还需要给Site类增加一个Config属性,并且定义一个Config类。
 代码
代码

{
private IDictionary<string, string> _configs;
public string this[string key]
{
get
{
return _configs != null && _configs.ContainsKey(key) ? _configs[key] : string.Empty;
}
set
{
if (_configs == null)
{
_configs = new Dictionary<string, string>();
}
if (_configs.ContainsKey(key))
_configs[key] = value;
else
_configs.Add(key, value);
}
}
}
Site获取ConfigValue的逻辑是先从自己的Config获取,如果没有再去Global的config获取。为什么需要Config呢?因为不同的站点可能需要自定义一些变量到前台使用。
好了,过滤说完了,就该获取Page了。
根据URL拿Page实例,Page也需要用hashtable来缓存,因为这个获取实例的请求实在是太大了,复杂度也要降到O(1)。
如果page是null,说明数据库不存在这个Page,所以要跳出HttpModule,让IIS接手继续处理。
如果存在,则需要判断Page是否缓存,我们这里缓存其实就是生成静态页,如果缓存了,则根据URL生成静态页文件名,再去查找是否存在这个文件,如果存在还要判断文件的创建时间是否过期。如果过期了,我们就得重新写入一个新文件,通过返回旧文件,等新文件创建成功后覆盖掉旧文件(读写分离)。
如果不是缓存,则获取Page.Template.Content,然后循环Labels,对Content进行替换。
foreach (var label in page.Labels)
{
html = html.Replace(label.Template, label.GetHtml());
}
最后输出被替换掉标签的html,则页面生产完成。
我讲的都是粗略的框架,开发过程中会出现很多细节性的东西,我就不提了,只提一些比较重要的。下节我们该讲如何设计Label了!


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 如何编写易于单元测试的代码
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 周边上新:园子的第一款马克杯温暖上架
· Open-Sora 2.0 重磅开源!
· 分享 3 个 .NET 开源的文件压缩处理库,助力快速实现文件压缩解压功能!
· Ollama——大语言模型本地部署的极速利器
· DeepSeek如何颠覆传统软件测试?测试工程师会被淘汰吗?