
项目github地址:https://github.com/holidaysss/WC
|
PSP2.1 |
Personal Software Process Stages |
预估耗时(分钟) |
实际耗时(分钟) |
|
Planning |
计划 |
90 | 90 |
|
· Estimate |
· 估计这个任务需要多少时间 |
90 | 90 |
|
Development |
开发 |
365 | 385 |
|
· Analysis |
· 需求分析 (包括学习新技术) |
240 | 240 |
|
· Design Spec |
· 生成设计文档 |
20 | 20 |
|
· Design Review |
· 设计复审 (和同事审核设计文档) |
30 | 30 |
|
· Coding Standard |
· 代码规范 (为目前的开发制定合适的规范) |
15 | 15 |
|
· Design |
· 具体设计 |
180 | 180 |
|
· Coding |
· 具体编码 |
180 | 200 |
|
· Code Review |
· 代码复审 |
120 | 120 |
|
· Test |
· 测试(自我测试,修改代码,提交修改) |
180 | 180 |
|
Reporting |
报告 |
165 | 165 |
|
· Test Report |
· 测试报告 |
120 | 120 |
|
· Size Measurement |
· 计算工作量 |
15 | 15 |
|
· Postmortem & Process Improvement Plan |
· 事后总结, 并提出过程改进计划 |
30 | 30 |
|
合计 |
620 | 640 |
执行代码:
if __name__ == '__main__': opts, args = getopt.getopt(sys.argv[1:], "hc:w:l:s:a:") files_list = [] # 相应后缀文件列表 main(opts)
主要函数:
count_word : 统计文件的词数(单词) (基本功能 -w)
def count_word(file): list = open(file, 'r', encoding='utf-8').read() word_list = [] end = 0 for i in range(len(list)): # 遍历全文 if list[i].isalpha() and i >= end: # 词首(字母) for j in range(i, len(list)): if (list[j].isalpha() == 0) or (j == len(list)-1): # 词尾(非字母) word_list.append(list[i: j]) # 词 end = j break word_list.pop(-1) for k, v in Counter(word_list).items(): print('{}: {}'.format(k, v)) num = len(word_list) print('总词数: {}'.format(num))
count_char, count_line :统计字符数和行数 (基本功能 -c, -l)
def count_char(file): num = len(open(file, 'r', encoding='ISO-8859-1').read()) print("文件{}的字符数(包括换行符)为{}".format(file, num)) def count_line(file): print('文件{}的行数:'.format(file) + str(len(open(file, 'r', encoding='ISO-8859-1').readlines())))
down_find: 递归查询当前目录下相应后缀(hz)的文件, 返回文件列表files (拓展功能 -s)
recursion: 对文件列表进行第二选项串判断,执行相应处理
def down_find(dir, hz): dir_files = os.listdir(dir) # 路径下的文件列表 for i in dir_files: # 生成子目录 son_path = os.path.join(dir, i) if os.path.isdir(son_path): # 如果是目录,递归操作 down_find(son_path, hz) elif hz in son_path: files_list.append(son_path) return files_list def recursion(value): op2 = value[0: 2] # 第二选项串 hz = args[0] # 文件后缀参数 dir = os.getcwd() # 当前路径 files = down_find(dir, hz) # 返回相应后缀文件列表 print("当前目录下符合后缀{}的文件有: {}".format(hz, files)) for file in files: if op2 == "-c": # 返回字符数 count_char(file) elif op2 == "-w": # 返回词的数目 count_word(file) elif op2 == "-l": # 返回行数 count_line(file) elif op2 == '-a': more_data(file)
more_data: 返回文件空行,代码行,注释行数 (拓展功能 -a)
def more_data(value): code_line = blank_line = comment_line = 0 end = -1 lines = open(value, 'r', encoding='ISO-8859-1').readlines() for i in range(len(lines)): if '#' in lines[i] and (i > end): # 单行注释 comment_line += 1 elif len(lines[i].strip()) <= 1: # 空行 blank_line += 1 elif lines[i][0].isalpha() and (i > end) and ('#' not in lines[i]): # 代码行 code_line += 1 elif lines[i].startswith('"""') and (i > end): # 多行注释 for j in range(i + 1, len(lines)): if lines[j].startswith('"""'): comment_line += (j - i + 1) end = j elif lines[i].startswith("'''") and (i > end): for j in range(i + 1, len(lines)): if lines[j].startswith("'''"): comment_line += (j - i + 1) end = j print('文件:{}\n代码行:{}\n空行:{}\n注释行:{}\n'.format(value,code_line, blank_line, comment_line))
main():
def main(opts): for op, value in opts: # op为选项串,value为附加参数 try: if op == "-c": # 返回字符数 count_char(value) elif op == "-w": # 返回词的数目 count_word(value) elif op == "-l": # 返回行数 count_line(value) elif op == "-s": # 递归处理目录下符合条件的文件 recursion(value) elif op == "-a": # 返回代码行,空行,注释行数 more_data(value) elif op == "-h": print('-c file 返回文件 file 的字符数\n' '-w file 返回文件 file 的词的数目\n' '-l file 返回文件 file 的行数\n' '-a file 返回空行代码行注释行数\n' '-s -*[后缀] 递归相应后缀文件再执行基本指令') sys.exit() except FileNotFoundError as e: print("{}\n输入 -h 查看帮助".format(e))
运行结果:
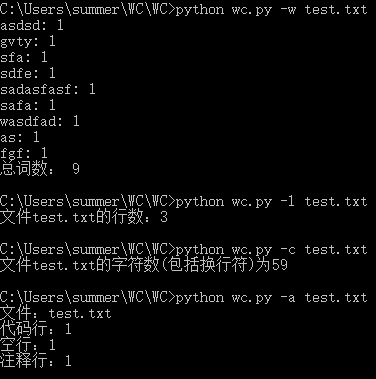
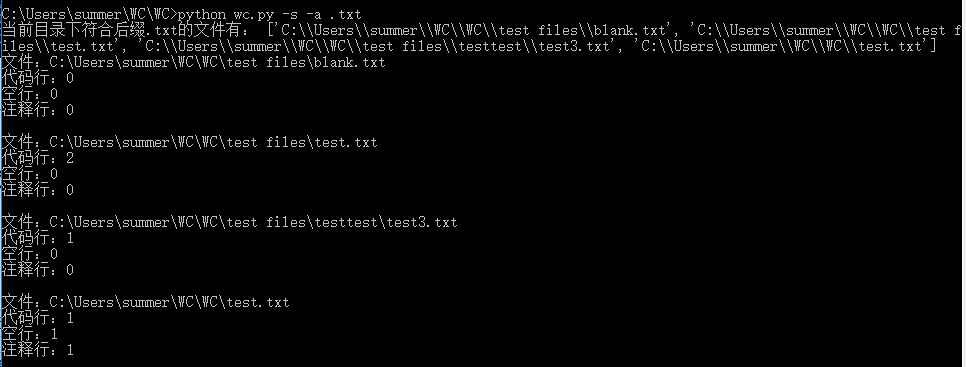
过程中遇到的问题:
1.打开文件的编码问题:刚开始默认gpk无法识别。后来换utf-8还不行,最后百度到转为
'ISO-8859-1',问题解决。
项目小结:
python 是当下比较流行的一种编译语言,学好python可以让一些让其他编译语言头疼的事变得轻松!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号