Java基础教程(21)--泛型
一.为什么使用泛型
泛型意味着编写的代码可以被很多不同类型的对象所重用。例如,我们不希望为存放String和Integer对象的集合设计不同的类。现在的ArrayList类可以存放任何类型的对象,但是在Java中增加泛型之前已经有了一个ArrayList类,它是使用继承来实现泛型的。这个ArrayList类只维护一个Object数组:
public class ArrayList {
private Object [] elementData ;
public Object get (int i) {...}
public void add (Object o) {...}
}
这样存在两个问题。第一是可以向集合中添加任何对象:
ArrayList collection = new ArrayList();
collection.add(new Integer(0));
collection.add("string");
第二是在获取值时必须进行强制类型转换:
Integer i0 = (Integer)collection.get(0);
如果我们默认这个集合是用来存放Integer对象的,那么下面的类型转换可以通过编译,但是在运行时会产生错误:
Integer i1 = (Integer)collection.get(1);
泛型提供了一个更好的解决方案:类型参数。现在的ArrayList类有一个类型参数用来指示元素的类型:
ArrayList<Integer> collection = new ArrayList<Integer>();
这使得代码具有更好的可读性,一看就知道这个集合中存放的是Integer对象。
注:在Java SE 7及以后的版本中,构造函数中可以省略泛型类型。也就是说,上面的语句实际上可以这么写:
ArrayList<Integer> collection = new ArrayList<>();
编译器也可以很好地利用这个信息。当调用get的时候,不需要进行强制类型转换,编译器就知道返回值类型是Integer,而不是Object:
Integer i0 = collection.get(0);
而且,在插入元素时编译器会进行检査,避免插人错误类型的对象。例如:
collection.add("string");
这句代码是无法通过编译的。出现编译错误比运行时出现类的强制类型转换异常要好得多。类型参数的魅力在于可以使程序具有更好的可读性和安全性。
二.泛型类型
泛型类型就是将参数类型化的类或接口。就是具有一个或多个类型参数的类。我们先定义一个简单的Box类,然后使用泛型对它进行改造。
1.一个简单的Box类
我们可以将Box类看作是一个盒子,它可以用来存放一个对象。这里我们使用一个Object类型的成员变量来存放对象,并且需要提供两个方法:一个是将对象放入盒子的set方法,另一个是获取盒子中的对象的get方法。
public class Box {
private Object object;
public void set(Object object) { this.object = object; }
public Object get() { return object; }
}
由于它内部维护的是一个Object对象的引用,因此你可以放入任何类型的对象。但是当你取出对象时,你必须进行强制类型转换。这样就会存在一个问题,如果你存入的对象类型与你转换的类型不一致,将会在运行时出现异常,但是编译器却无法在编译时期发现这个问题。例如:
Box b = new Box();
b.set("box");
Integer i = (Integer) b.get();
上面的代码可以通过编译,但是会在运行的时候抛出一个ClassCastException。
2.使用泛型的Box类
泛型类使用如下的语法定义:
class ClassName<T1, T2, ..., Tn> {...}
类名后面是类型参数(也称类型变量),使用一对尖括号<>括起来,一个类中可以有多个类型参数。
下面是使用泛型改造后的Box类:
public class Box<T> {
private T t;
public void set(T t) { this.t = t; }
public T get() { return t; }
}
所有的Object都被替换成了类型变量T。在使用时,类型变量可以是任何非基本数据类型。
泛型接口的语法与泛型类类似:
interface InterfaceName<T1, T2, ..., Tn> {...}
3.类型参数的命名惯例
按照惯例,类型参数名称是单个大写字母。这与我们已经了解的变量命名规范有很大的出入,但是这有充分的理由:如果没有这种约定,就很难区分类型变量和类或接口的名称。
下面是最常用的类型参数的名称:
- E - 元素(广泛应用于集合中)
- K - 键
- V - 值
- N - 数字
- T - 类型
- S,U,V等 - 第二、第三、第四类型
4.调用和实例化泛型类型
要在代码中使用Box类,必须执行泛型类型调用,也就是将T替换为具体的类型,比如Integer:
Box<Integer> integerBox;
你可以把泛型类型调用看作是普通的方法调用,但是不同于将参数传递给方法,泛型类型调用将类型参数(在这个例子中是Integer)传递给泛型类。
正如其他的变量声明一样,上面的代码并没有创建Box对象,它只是声明了一个可以引用装有Integer对象的Box对象的引用。
泛型类型调用也被称作是类型参数化。
要实例化这个类,可以像实例化其他类一样使用new关键字,但是要在类名和小括号之间加上<Integer>:
Box<Integer> integerBox = new Box<Integer>();
5.钻石运算符
在Java SE 7及以后的版本中,在调用泛型类的构造方法时可以省略尖括号中的类型参数,这对尖括号被称为钻石运算符。例如,你可以使用下面的语句来实例化Box<Integer>:
Box<Integer> integerBox = new Box<>();
6.原始类型
原始类型是指没有类型参数的泛型类或接口。例如下面的泛型类Box:
public class Box<T> {
public void set(T t) { /* ... */ }
// ...
}
要创建一个类型参数化的Box<T>,需要为类型参数T提供一个实际的类型:
Box<Integer> intBox = new Box<>();
如果没有提供实际的类型,将会创建一个Box<T>的原始类型:
Box rawBox = new Box();
因此,Box就是Box<T>的原始类型。但是,非泛型类或接口不是原始类型。
原始类型多出现在遗留代码中,这是因为很多类或接口(例如集合类)在JDK 5.0之前不是泛型的。在使用原始类型时,你实际上已经获得了预泛型行为。为了向后兼容,允许将一个参数化的类型赋值给原始类型:
Box<String> stringBox = new Box<>();
Box rawBox = stringBox; // OK
但是如果你把原始类型赋值给参数化的类型,就会产生警告:
Box rawBox = new Box(); // rawBox is a raw type of Box<T>
Box<Integer> intBox = rawBox; // warning: unchecked conversion
如果使用原始类型调用泛型类型中定义的使用了泛型的方法,也会产生警告:
Box<String> stringBox = new Box<>();
Box rawBox = stringBox;
rawBox.set(8); // warning: unchecked invocation to set(T)
警告显示原始类型将会绕过泛型类型检查,将不安全代码的捕获推迟到运行时。因此,应该避免使用原始类型。
三.泛型方法
泛型方法是指引入了自己独有的类型参数的方法。这类似于声明泛型类型,但类型参数的使用范围仅限于声明它的方法。允许使用静态和非静态泛型方法,以及泛型构造方法。
定义泛型方法时,要将使用尖括号包围的类型参数列表放在修饰符之后,返回值之前。
下面的Util类中定义了一个泛型方法compare,这个方法可以用来比较两个Pair对象:
public class Util {
public static <K, V> boolean compare(Pair<K, V> p1, Pair<K, V> p2) {
return p1.getKey().equals(p2.getKey()) && p1.getValue().equals(p2.getValue());
}
}
class Pair<K, V> {
private K key;
private V value;
public Pair(K key, V value) {
this.key = key;
this.value = value;
}
public void setKey(K key) { this.key = key; }
public void setValue(V value) { this.value = value; }
public K getKey() { return key; }
public V getValue() { return value; }
}
调用该方法的语法如下:
Pair<Integer, String> p1 = new Pair<>(1, "apple");
Pair<Integer, String> p2 = new Pair<>(2, "pear");
boolean same = Util.<Integer, String>compare(p1, p2);
上面的代码中显式提供了类型参数。一般来说,可以省略类型参数,编译器将会自动推断出需要的类型。
Pair<Integer, String> p1 = new Pair<>(1, "apple");
Pair<Integer, String> p2 = new Pair<>(2, "pear");
boolean same = Util.compare(p1, p2);
这个特性被称为类型推断,允许将泛型方法作为普通方法调用,而无需在尖括号之间指定类型。我们稍后将会进一步讨论有关类型推断的内容。
构造方法也可以是泛型方法,并且非泛型类也可以拥有泛型构造方法,例如:
class MyClass {
<T> MyClass(T t) {
...
}
}
四.有界类型参数
有时你可能希望限制类型参数的类型。例如,对数字进行操作的方法可能只想接受Number及其子类的实例。这正是有界类型参数的用途。
要声明有界类型参数,需要在类型参数后面使用extends关键字,然后跟上这个类型参数的上界。需要注意的是,在这种情况下,extends既可以用于表示继承(对于类而言),又可以用于表示实现(对于接口而言)。
public class Box<T> {
private T t;
public void set(T t) {
this.t = t;
}
public T get() {
return t;
}
public <U extends Number> void inspect(U u){
System.out.println("T: " + t.getClass().getName());
System.out.println("U: " + u.getClass().getName());
}
public static void main(String[] args) {
Box<Integer> integerBox = new Box<Integer>();
integerBox.set(new Integer(10));
integerBox.inspect("some text"); // error: argument must be Number or its subclass
}
}
上面的程序将会编译失败,因为inspect方法只接受Number类及它的子类的实例作为参数。
一个类型参数可以有多个上界:
<T extends B1 & B2 & B3>
如果一个类型参数有多个上界,那么这些上界中最多只能有一个类,并且这个类必须是列表中的第一个:
Class A { /* ... */ }
interface B { /* ... */ }
interface C { /* ... */ }
class D <T extends A & B & C> { /* ... */ }
如果A没有放在第一个,将会产生一个编译错误。
五.泛型,继承和子类型
正如我们所知,可以将子类的实例赋值给父类类型的变量。例如,可以将Integer类的实例赋值给Number类型的变量,因为Integer是Number的子类。
Number someNumber = new Integer(10);
在泛型中也是如此,例如:
Box<Number> box = new Box<Number>();
box.set(new Integer(10));
现在考虑以下方法:
public void boxTest(Box<Number> n) { /* ... */ }
这个方法接受一个Box<Number>类型的参数。我们是否可以传递Box<Integer>或Box<Double>类型的参数呢?答案是否定的。因为Box<Integer>和Box<Double>不是Box<Number>的子类。在使用泛型编程时,这是一个常见的误解,但这是一个需要学习的重要概念。
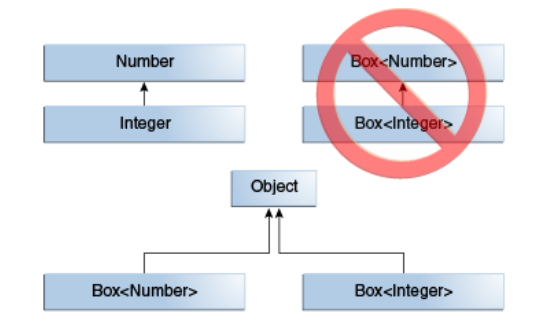
给定两个具体类型A和B(例如,Number和Integer),MyClass<A>与MyClass<B>无关,无论A和B是否相关。MyClass<A>和MyClass<B>的公共父类是Object。
两个泛型类型的关系是通过它们之间的继承(或实现)语句确定的,而不是通过类型参数之间的关系确定的。只要两个泛型类型之间存在继承(或实现)关系,并且不改变类型参数,就会在类型之间保留子类型关系。
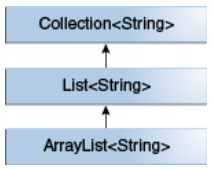
使用ArrayList类作为示例。ArrayList<E>实现了List<E>接口,而List<E>接口又继承了Collection<E>接口。所以ArrayList<E>是List<E>和Collection<E>的子类型,List<E>是Collection<E>的子类型。只要不改变参数类型,他们之间就存在子类型关系:
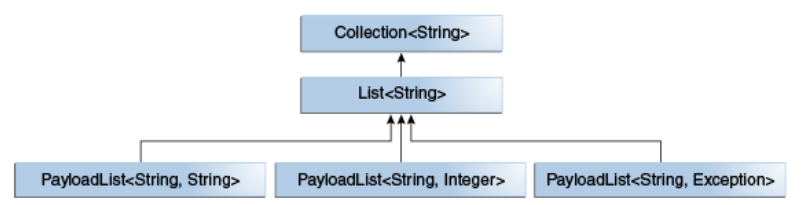
现在假设我们要定义一个自己的接口PayLoadList,它继承自List接口,同时引入了新的类型参数P:
interface PayloadList<E,P> extends List<E> {
void setPayload(int index, P val);
...
}
只要我们保证传递给类型参数E的类型和List一致,无论传递给P的类型是什么,这个接口都是List的子类型,例如:
- PayloadList<String,String>
- PayloadList<String,Integer>
- PayloadList<String,Exception>
六.类型推断
类型推断是Java编译器的一种根据方法调用和对应的声明来推断类型参数的具体类型的能力。类型推断试图找到适用于所有参数的最贴切的类型。例如:
static <T> T pick(T a1, T a2) { return a2; }
Serializable s = pick("d", new ArrayList<String>());
在上面的例子中,T将会被推断为Serializable类型。因为a1是String类型,a2是ArrayList<String>类型,因此编译器将会寻找它们的共同超类型,也就是Serializable类型。
1.类型推断和泛型方法
在泛型方法中我们已经提到了类型推断,它使我们能够像调用普通方法一样调用泛型方法,而无需在尖括号之间指定类型。考虑下面的例子:
public class BoxDemo {
public static <U> void addBox(U u, List<Box<U>> boxes) {
Box<U> box = new Box<>();
box.set(u);
boxes.add(box);
}
public static <U> void outputBoxes(List<Box<U>> boxes) {
int counter = 0;
for (Box<U> box: boxes) {
U boxContents = box.get();
System.out.println("Box #" + counter + " contains [" + boxContents.toString() + "]");
counter++;
}
}
public static void main(String[] args) {
ArrayList<Box<Integer>> listOfIntegerBoxes = new ArrayList<>();
BoxDemo.<Integer>addBox(Integer.valueOf(10), listOfIntegerBoxes); // statement 1
BoxDemo.addBox(Integer.valueOf(20), listOfIntegerBoxes); // statement 2
BoxDemo.outputBoxes(listOfIntegerBoxes);
}
}
上面的例子输出如下:
Box #0 contains [10]
Box #1 contains [20]
泛型方法addBox定义了一个类型参数U。当调用addBox时,在方法前面的尖括号中放入具体的类型,正如上面的statement 1:
BoxDemo.<Integer>addBox(Integer.valueOf(10), listOfIntegerBoxes);
不过,大多数情况下,编译器可以根据方法调用来推断出类型参数的具体类型,因此可以省略方法名后面的尖括号和类型,正如上面的statement 2:
BoxDemo.addBox(Integer.valueOf(20), listOfIntegerBoxes);
2.类型推断和构造方法
在泛型类和非泛型类中,都可以包含泛型构造方法(换句话说就是可以引入它们自己的类型参数)。首先我们看一个泛型类的例子:
class MyClass<X> {
<T> MyClass(T t) {
...
}
}
首先需要明确一点的是,在实例化一个泛型类时,构造方法后面的尖括号里的参数列表与声明泛型类时类名后的尖括号里的参数列表是一一对应的,也就是说,无论构造方法是不是泛型方法,它都是提供给泛型类引入的类型参数使用的。这与普通的泛型方法不一样,普通的泛型方法在调用时尖括号中的参数是提供给该方法使用的。这就意味着,如果一个泛型类包含泛型构造方法,那么在实例化该泛型类时,无论构造方法后的尖括号中是否省略了类型参数列表,该构造方法始终需要推断出自己引入的类型参数的具体类型。因此,可以像下面这样实例化上面的泛型类:
MyClass<Integer> myObject1 = new MyClass<Integer>("obj1"); // statement 1
MyClass<Integer> myObject2 = new MyClass<>("obj2"); // statement 2
上面的statement 1中,构造方法后面提供了X的类型,因此无需推断,但由于无法提供T的类型,因此编译器需要从构造方法的参数中推断出其类型String;在statement 2中,X和T的类型都没有提供,因此均需要推断。
下面再来看一个非泛型类的例子:
class MyClass {
<T> MyClass(T t) {
...
}
}
因为这是一个非泛型类,在实例化时构造方法后面不能使用尖括号,因此仍然无法提供该泛型构造方法需要的类型信息,那么T的类型必须通过推断得出:
MyClass myObject = new MyClass("obj");
经过类型推断可以得出T的类型是String。
七.通配符
在泛型程序设计中,问号(?)被称为通配符,它表示未知的类型。通配符可以被用在很多场景中:参数、域或局部变量的类型,有时候也用在返回值类型中(不过更好的编程实践是使用具体的返回值类型)。下面将更详细地讨论通配符。
1.上界通配符
可以使用上界通配符来放宽对变量的限制。例如,如果你的方法接受的参数是一个List,它里面的元素可以是Number以及它的子类的实例,你可以使用上界通配符来实现这一点。
要声明一个上界通配符,在尖括号中使用?,后面跟上extends关键字和它的上界。在这种情况下,extends既可以用于表示继承(对于类而言),又可以用于表示实现(对于接口而言)。
要编写适用于Number及其子类类型的集合的方法,你可以指明List<? extends Number>。List<Number>比List<? extends Number>更严格,因为前者只接受Number类型的集合,而后者可以接受Number及其子类类型的集合。
下面的sumOfList方法返回一个集合中的数字的总和:
public static double sumOfList(List<? extends Number> list) {
double s = 0.0;
for (Number n : list)
s += n.doubleValue();
return s;
}
以下的代码使用了一个Integer集合,将会输出sum = 6.0:
List<Integer> li = Arrays.asList(1, 2, 3);
System.out.println("sum = " + sumOfList(li));
下面的代码使用了Double集合,将会输出sum = 7.0:
List<Double> ld = Arrays.asList(1.2, 2.3, 3.5);
System.out.println("sum = " + sumOfList(ld));
2.无界通配符
无界通配符只用到了问号(?),例如List<?>。在以下两种场景中无界通配符很有用:
- 对于通配符表示的类型,你编写的方法只用到了来自Object类的方法。
- 你的代码只使用到了泛型类中不依赖于类型参数的方法,例如List的size()和clear()方法。
考虑以下方法:
public static void printList(List<Object> list) {
for (Object elem : list)
System.out.println(elem + " ");
System.out.println();
}
printList的目标是打印任何类型的集合,但它无法实现该目标,因为它只能打印Object类型的集合。它不能打印List<Integer>,List<String>,List<Double>等,因为它们不是List<Object>的子类型。要编写通用的printList方法,需要使用List<?>:
public static void printList(List<?> list) {
for (Object elem: list)
System.out.print(elem + " ");
System.out.println();
}
对于任意的具体类型A,List<A>是List<?>的子类型,可以使用printList打印任何类型的集合:
List<Integer> li = Arrays.asList(1, 2, 3);
List<String> ls = Arrays.asList("one", "two", "three");
printList(li);
printList(ls);
要注意的是,List<Object>和List<?>并不一样。List<Object>中可以插入任意类型的对象,而List<?>中只能插入null。
3.下界通配符
与上界通配符类似,下界通配符将类型参数限制为某个特定类型及它的超类型。不过需要注意的是,不能同时指定通配符的上界和下界。要声明一个下界通配符,在尖括号中使用?,后面跟上super关键字和它的下界。
假设我们要编写一个将Integer对象放入集合的方法。为了最大限度地提高灵活性,我们希望该方法可以处理List<Integer>,List<Number>和List<Object>,也就是任何可以保存Integer值的集合。
要编写适用于Integer及其超类型的集合的方法,你可以指明List<? super Integer>。List<Integer>比List<? super Integer>更严格,因为前者只接受Integer类型的集合,而后者可以接受Integer及其超类型的集合。
下面的代码将数字1~10添加到指定的集合中:
public static void addNumbers(List<? super Integer> list) {
for (int i = 1; i <= 10; i++) {
list.add(i);
}
}
4.通配符和子类型
正如第五小节《泛型,继承和子类型》中描述的那样,泛型类或接口之间的关系与类型参数并没有直接联系。然而,可以使用通配符在泛型类或接口之间创建关系。
观察以下代码:
Integer i = new Integer(1);
Number n = i;
上面的代码是合理的。这个例子展示了常规类的继承规则:如果类B继承了类A,则类B是类A的子类型。但是这条规则在泛型类型中并不成立:
List<Integer> li = new ArrayList<>();
List<Number> ln = li; // compile-time error
Integer是Number的子类型,那么List<Integer>和List<Number>之间到底是什么关系?
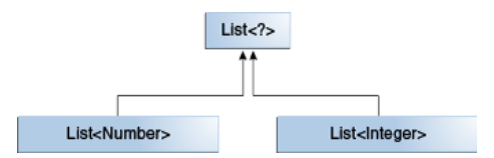
尽管Integer是Number的子类型,但List<Integer>不是List<Number>的子类型。List<Integer>和List<Number>的公共超类型是List<?>。
如果不好理解,可以回想一下面向对象程序设计中对于继承的定义。在面向对象程序设计中,继承是通过is-a来体现的。可以这么说,如果B is a A,那么A就是B的超类型。例如,任何对象都是一个Object,因此Object是所有类的超类型。
现在我们回过头来看List<Integer>和List<Number>,List<Integer>表示一个Integer类型的集合,List<Number>是一个Number类型的集合,这两个集合中的元素不是同一种类型。因此,尽管Number是Integer的超类型,但却不能说一个Integer类型的集合是一个Number类型的集合,也就是说List<Number>不是List<Integer>的超类型。
再来说说这两个集合和List<?>。List<?>表示一个任何类型元素的集合,既然可以表示任何元素的集合,自然也就可以表示Integer类型的集合和Number类型的集合。下面的代码是合理的:
List<Integer> li = new ArrayList<>();
List<Number> ln = new ArrayList<>();
List<?> l1 = li;
List<?> l2 = ln;
在理解了这个概念之后,我们就可以判断使用通配符的泛型类型之间的关系了。下面的图片展示了几个使用通配符的List之间的关系,大家可以试着自己理解:
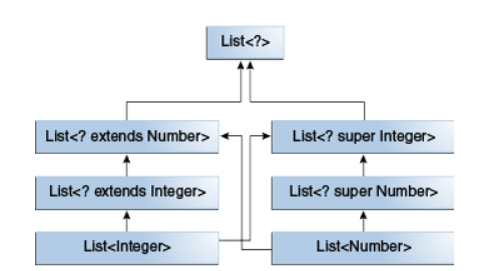
5.通配符捕获
下面的rebox方法将元素从Box中取出并重新放回:
public class Box<T> {
private T value;
public T get() {
return value;
}
public void set(T value) {
this.value = value;
}
public static void rebox(Box<?> box) {
box.set(box.get());
}
}
这段代码看上去应该可以运行,因为取出的值和放回的值是相同类型的。但是,在编译时却会产生以下错误信息:
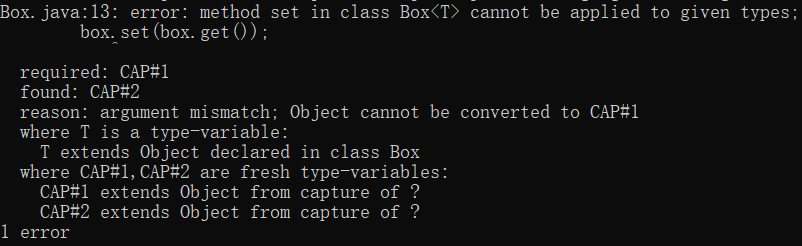
在我们讨论这个错误之前,我们首先来区分一下通配符(?)和类型参数(以下使用T来说明)的区别。虽然它们都用来表示未知的类型,但是类型参数T会在第一次用到它的时候就确定下来,之后程序中的所有类型参数T都代表这个类型;而通配符?则不同,程序中出现的每个通配符都会获得不同的捕获,编译器会为每个通配符的捕获分配不同的名称,因为任意未知的类型参数之间并没有关系。
现在上面出现的错误提示就很容易理解了。rebox方法的box参数是Box<?>类型的,那么编译器会将它的set方法的参数标记为CAP#1,将它的get方法的返回值标记为CAP#2,由于编译器并不知道CAP#1与CAP#2是否相同(虽然在这里它们就是相同的),因此就会出现上面的错误信息。
那么是不是rebox方法的功能就无法实现了呢?实际上,这里我们可以借助一个辅助方法:
public static void rebox(Box<?> box) {
reboxHelper(box);
}
private static <T> void reboxHelper(Box<T> box) {
box.set(box.get());
}
现在rebox方法什么也没做,只是将box参数原封不动地传递给reboxHelper方法。当reboxHelper方法接收到这个参数的时候,类型参数T就会捕获通配符所代表的类型,之后的所有T都代表了这个类型,也就不会出现类型转换所带来的问题。
当然这里的例子只是为了演示通配符捕获这个概念,并没有什么意义。实际上可以直接将rebox定义为泛型方法:
public static <T> void rebox(Box<T> box) {
box.set(box.get());
}
6.通配符使用指南
在使用泛型进行编程时,令人困惑的一个方面是确定何时使用通配符以及使用哪种类型的通配符。下面提供了几条编码时要遵循的一些指导原则。
首先我们应该考虑该使用泛型的变量属于哪种类型:
- in变量:“in”变量将数据提供给代码。假设有一个带两个参数的的复制方法copy(src,dest),src参数提供需要被复制的数据,因此它是“in”变量。
- out变量:“out”变量用于保存其他地方的数据。在复制方法copy(src,dest)中,dest参数接受数据,所以它是“out”变量。
当然,一些变量既属于“in”变量也属于“out”变量,这种情况在下面的准则中也有说明。
下面是几条选择通配符类型时的准则:
- “in”变量使用上界通配符
- “out”变量使用下界通配符
- 在只需要使用Object类中定义的方法访问“in”变量的情况下,使用无界通配符
- 若该变量既属于“in”变量,又属于“out”变量,不使用通配符
不过,这些准则并不适用于方法的返回类型。应避免使用通配符作为返回类型,因为它强制程序员使用代码来处理通配符。
八.类型擦除
Java中引入泛型的目的是提供更严格的编译时类型检查,以及更好地支持泛型程序设计。但是对于虚拟机而言,并不存在泛型,所有的类都是普通类。在编译时,编译器会将类型参数擦除,并替换为它的限定类型或Object。类型擦除确保不为参数化类型创建新的类,因此泛型并不会产生运行时开销。
1.泛型类型的擦除
考虑下面单链表中的节点类:
public class Node<T> {
private T data;
private Node<T> next;
public Node(T data, Node<T> next) {
this.data = data;
this.next = next;
}
public T getData() { return data; }
// ...
}
因为类型参数T没有限制,所以Java编译器会将其替换为Object。也就是说,编译后的Node类应该是下面这样的:
public class Node {
private Object data;
private Node next;
public Node(Object data, Node next) {
this.data = data;
this.next = next;
}
public Object getData() { return data; }
// ...
}
在下面的例子中,Node类使用了有界类型参数:
public class Node<T extends Comparable<T>> {
private T data;
private Node<T> next;
public Node(T data, Node<T> next) {
this.data = data;
this.next = next;
}
public T getData() { return data; }
// ...
}
Java编译器会将有界类型参数T替换为它的限定类型Comparable:
public class Node {
private Comparable data;
private Node next;
public Node(Comparable data, Node next) {
this.data = data;
this.next = next;
}
public Comparable getData() { return data; }
// ...
}
2.泛型方法的擦除
Java编译器也会擦除泛型方法中的类型参数。考虑以下的泛型方法,这个方法用来统计一个元素在数组中的出现次数:
public static <T> int count(T[] anArray, T elem) {
int cnt = 0;
for (T e : anArray) {
if (e.equals(elem)) {
++cnt;
}
}
return cnt;
}
因为类型参数T没有限制,所以Java编译器会将其替换为Object:
public static int count(Object[] anArray, Object elem) {
int cnt = 0;
for (Object e : anArray) {
if (e.equals(elem)) {
++cnt;
}
}
return cnt;
}
假设有以下的几个类:
class Shape { /* ... */ }
class Circle extends Shape { /* ... */ }
class Rectangle extends Shape { /* ... */ }
你可以编写一个泛型方法来绘制不同的图形:
public static <T extends Shape> void draw(T shape) { /* ... */ }
这个方法将会被编译为:
public static void draw(Shape shape) { /* ... */ }
3.桥接方法
考虑下面的Node类和MyNode类:
public class Node<T> {
public T data;
public Node(T data) { this.data = data; }
public void setData(T data) {
System.out.println("Node.setData");
this.data = data;
}
}
public class MyNode extends Node<Integer> {
public MyNode(Integer data) { super(data); }
public void setData(Integer data) {
System.out.println("MyNode.setData");
super.setData(data);
}
}
MyNode类继承了参数化的Node类,也就是Node<Integer>。那么,擦除类型之后的Node类和MyNode类应该是:
public class Node {
public Object data;
public Node(Object data) { this.data = data; }
public void setData(Object data) {
System.out.println("Node.setData");
this.data = data;
}
}
public class MyNode extends Node {
public MyNode(Integer data) { super(data); }
public void setData(Integer data) {
System.out.println("MyNode.setData");
super.setData(data);
}
}
MyNode类重写了Node<Integer>的setData方法,但经过编译器的类型擦除后,Node<Integer>类并不存在,MyNode继承的类也变成了Node类。此时,MyNode类的setData方法和Node类的setData方法的参数列表并不相同,并不符合重写的定义。也就是说,我们在编写代码时设计的重写经过编译器的类型擦除后就消失了。为了保持重写的语义和保留多态性,编译器会自动生成一个桥接方法。对于MyNode类来说,编译器将会为setData生成下面的桥接方法:
public class MyNode extends Node {
public MyNode(Integer data) { super(data); }
// Bridge method generated by the compiler
public void setData(Object data) {
setData((Integer) data);
}
public void setData(Integer data) {
System.out.println("MyNode.setData");
super.setData(data);
}
}
泛型接口也是如此。考虑下面的泛型接口和实现类:
public interface DemoInterface<T> {
void foo(T t);
}
public class DemoInterfaceImpl implements DemoInterface<String> {
void foo(String s) {
// ...
}
}
经过类型擦除后,DemoInterface和DemoInterfaceImpl将会变成:
public interface DemoInterface {
void foo(Object t);
}
public class DemoInterfaceImpl implements DemoInterface {
void foo(String s) {
// ...
}
}
我们知道,实现类必须重写接口中所有的抽象方法。但是DemoInterfaceImpl中的foo(String s)方法并没有重写DemoInterface中的foo(Object t)方法,这显然违背了继承的原则。此时,编译器也会在编译时自动生成桥接方法:
public class DemoInterfaceImpl implements DemoInterface {
public void foo(Object t) {
foo((String) t);
}
public void foo(String s) {
// ...
}
}
4.不可具体化类型
可具体化类型是指类型信息在运行时完全可用的类型。这包括基本类型,非泛型类型,原始类型和使用了无界通配符的类型。
不可具体化类型是指那些类型信息在编译期被擦除的类型,也就是没有使用无界通配符定义的泛型类型。我们无法在运行时获取一个不可具体化类型的所有信息。例如List<Number>和List<String>,JVM在运行时无法区分它们。
(1)堆污染
当一个参数化类型的变量引用了一个对象,而这个对象的类型并不是该参数化类型时,就会产生堆污染。如果一个程序执行了一些在编译时会出现非受检警告的操作时,就会出现这种情况。非受检警告既有可能出现在编译时(在编译时类型检查规则的限制下),也有可能出现在运行时无法保证涉及参数化类型操作(例如类型转换或方法调用)的正确性。例如,将原始类型和参数化类型混合使用时,或者执行了一个未受检的类型转换时,堆污染就会发生。
在正常情况下,当所有代码同时被编译后,编译器就会对潜在的堆污染发出一个警告以引起你的关注。如果你分模块对代码进行编译,那就很难检测出潜在的堆污染。如果你确定代码编译后没有产生警告,那么堆污染就不会发生。
(2)具有不可具体化形参的可变参数方法的潜在隐患
具有可变参数的泛型方法可以引起堆污染。考虑下面的ArrayBuilder类:
public class ArrayBuilder {
public static <T> void addToList (List<T> listArg, T... elements) {
for (T x : elements) {
listArg.add(x);
}
}
public static void faultyMethod(List<String>... l) {
Object[] objectArray = l;
objectArray[0] = Arrays.asList(42);
String s = l[0].get(0);
}
}
下面的HeapPollutionExample使用了ArrayBuiler类:
public class HeapPollutionExample {
public static void main(String[] args) {
List<String> stringListA = new ArrayList<String>();
List<String> stringListB = new ArrayList<String>();
ArrayBuilder.addToList(stringListA, "Seven", "Eight", "Nine");
ArrayBuilder.addToList(stringListB, "Ten", "Eleven", "Twelve");
List<List<String>> listOfStringLists = new ArrayList<List<String>>();
ArrayBuilder.addToList(listOfStringLists, stringListA, stringListB);
ArrayBuilder.faultyMethod(Arrays.asList("Hello!"), Arrays.asList("World!"));
}
}
编译时,ArrayBuilder.addToList方法会产生这样的警告:
warning: [varargs] Possible heap pollution from parameterized vararg type T
当编译遇到可变参数方法时,它会将可变参数翻译成一个数组。在方法ArrayBuilder.addList中,编译器将可变形参T... elements翻译成T[] elements。然而,由于类型擦除,编译器又将T[] elements转化为Object[] elements。这样就存在堆污染的可能性。
下面的语句把可变形参l赋值给Object数组objectArgs:
Object[] objectArray = l;
这个语句也会潜在地引起堆污染。一个不匹配可变形参l的参数化类型的值可以被赋值给变量l,也就可以赋值给objectArray。然而,编译器并不会在这一句上生成未受检警告。在将可变形参List<String> l翻译成形参List[] l时,编译就已经生成了一个警告。这一句是有效的,因为变量l是List[]类型,它同时也是Object[]的子类。
因此,如果你像如下语句那样,把一个任何类型的List对象赋值给objectArray数组的任何一个元素时,编译器也不会报任何警告或错误。
objectArray[0] = Arrays.asList(42);
这个语句将objectArray的第一个元素赋值为一个List对象,这个List持有一个Integer元素。
当你通过下面的语句去调用ArrayBuilder.faultyMetho方法时,就会抛出一个ClassCastException异常:
String s = l[0].get(0);
l数组中的第一个元素存储了一个List<Integer>类型的对象,但是这一句期望的类型却是List<String>。
(3)避免来自不可具体化形参的可变参数方法的警告
如果你定义了一个具有参数化类型参数的可变参数方法,并且确保你的方法不会抛出一个ClassCastException异常或其他因对可变形参处理不当而引起的相似异常时,你就可以通过在静态或非构造方法上使用@SafeVarargs注解来人为地屏蔽编译器生成的这些警告。这个注释断言此方法的实现会合理地处理可变形参。
如果你还想同时屏蔽非受检警告,可以像下面这样:
@SuppressWarnings({"unchecked", "varargs"})
九.泛型的限制
为了更有效地使用泛型,你必须了解下面这些限制:
1.不能使用基本类型实例化泛型类型
考虑下面的参数化类型:
class Pair<K, V> {
private K key;
private V value;
public Pair(K key, V value) {
this.key = key;
this.value = value;
}
// ...
}
在创建Pair对象的时候,不能使用基本类型来替换K或V:
Pair<int, char> p = new Pair<>(8, 'a'); // compile-time error
不过可以使用它们的包装类来代替,编译器会对它们进行自动装箱:
Pair<Integer, Character> p = new Pair<>(8, 'a');
2.不能创建类型参数的实例
不能创建类型参数的实例。例如,下面的代码将会导致一个编译错误:
public static <E> void append(List<E> list) {
E elem = new E(); // compile-time error
list.add(elem);
}
3.不能使用类型参数声明静态域
因为静态域在类加载时就已经创建,而类型参数在实例化类时才会指定。因此不能使用类型参数声明静态域。下面的代码也会导致编译错误:
public class MobileDevice<T> {
private static T os;
// ...
}
4.不能对类型参数使用类型转换或instanceof
因为编译器擦除了所有的类型参数,因此你不能在运行时判断泛型类型使用的是什么类型参数:
public static <E> void rtti(List<E> list) {
if (list instanceof ArrayList<Integer>) { // compile-time error
// ...
}
}
运行时并不能区分ArrayList<Integer>和ArrayList<String>。你能做的就是使用无界通配符来判断list是不是一个ArrayList:
public static void rtti(List<?> list) {
if (list instanceof ArrayList<?>) { // OK; instanceof requires a reifiable type
// ...
}
}
不能对类型参数进行类型转换,除非这个类型参数是无界通配符。例如:
List<Integer> li = new ArrayList<>();
List<Number> ln = (List<Number>) li; // compile-time error
5.不能创建类型参数的数组
不能实例化参数化类型的数组,例如:
Pair<String>[] table = new Pair<String>[10]; // Error
这又什么问题呢?擦除之后,table的类型是Pair[]。可以把它转换成Object[]:
Object[] objarray = table;
数组会记住它的元素类型,如果试图存储其他类型的元素,就会抛出一个ArrayStoreException异常:
objarray[0] = "Hello"; // Error--component type is Pair
不过对于泛型类型,擦除会使这种机制失效。以下赋值:
objarray[0] = new Pair<Integer>();
能够通过数组存储检查,但仍然会导致一个错误。出于这个原因,不允许创建参数化类型的数组。
需要说明的是,只是不允许创建这些数组,而声明类型为Pair<String>[]的变量仍是合法的。不过不能用new Pair<String>[10]初始化这个变量。
6.不能抛出或捕获泛型类的实例
既不能抛出也不能捕获泛型类对象。实际上,甚至泛型类扩展Throwable都是不合法的。例如,以下定义就不能正常编译:
public class Problem<T>extends Exception { ... } // Error--can't extend Throwable
不过,在异常规范中使用类型变量是允许的。以下方法是合法的:
public static <T extends Throwable> void doWork(T t) throws T { // OK
try {
// ...
} cathe (Throwable realCause) {
t.initCause(realCause);
throw t;
}
}
7.不能重载擦除类型后参数列表相同的方法
一个类不能有两个在类型擦除后具有相同签名的方法:
public class Example {
public void print(Set<String> strSet) { }
public void print(Set<Integer> intSet) { }
}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号