吴恩达深度学习与神经网络课程小记
时间:2021/01/08
好不容易完成了考研初试,又来了论文。。。。呜呜,我选的题目是基于深度学习的图像语义分割,是神经网络在图像语义分割方面的一个应用。由于之前完全没接触过深度学习,所以刚看老师发的论文时一脸懵逼,就去b站搜了吴恩达大神早期录的神经网络的课程,课程链接如下:https://www.bilibili.com/video/BV164411m79z。果然,人活着就要学习。
先夸一下吴恩达老师的课,通俗易懂,有点太详细了,很适合刚入门的小白。下面就是本篇的正题了,关于自己看了视频后对于一些概念的理解,由于刚入门,可能理解的不够深入,有问题欢迎在评论区指正。
先上一个深度学习方面经典的图片:
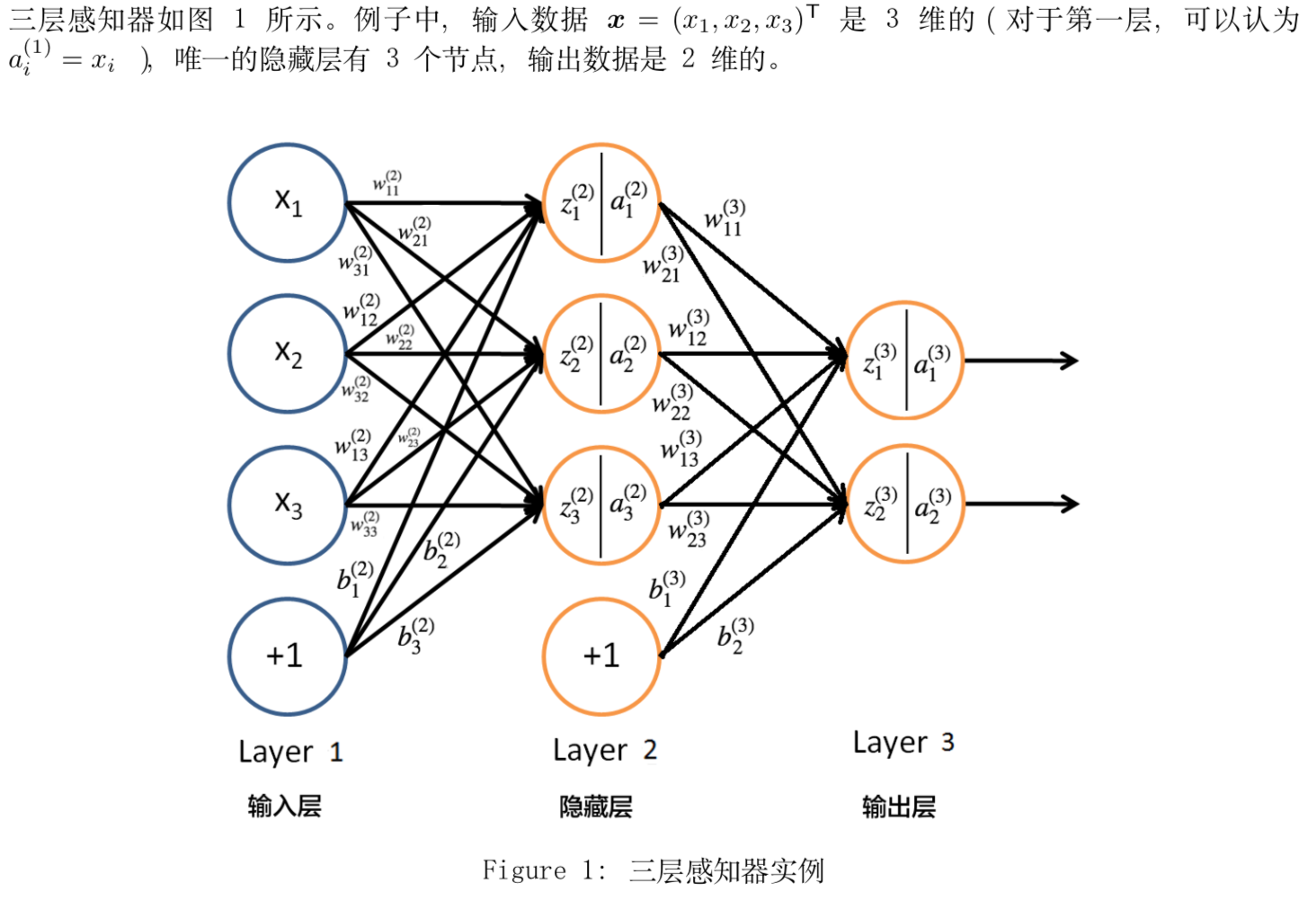
上面是一个最简单的神经网络模型,一共有三层(有时也可以说两层,因为输入层一般被称为第0层,可以不计入其中)。对于一个神经网络而言,可以分为两个过程,第一个是训练,第二个是预测。
这里先说一下两者之间的区别:首先是训练,从上图中可以看出,该神经网络中每一条线都有一个参数,如w[i]和b[i],在神经网络中,我们开始并不知道每个参数应该是什么值最为合适,所以需要通过训练数据来进行学习,进而得到参数合适的值。这里提到的训练数据是人工处理过的数据,与预测数据相比,它不仅含有输入变量x的值,而且还有输出变量y的真值。在进行训练时,先通过输入输入变量x进行正向传播,得到输出变量y的预测值。然后通过定义一个损失函数来计算输出变量y的预测值和真值之间差距,对于不同的神经网络而言,采取的损失函数也是不同的。进行完正向传播后,接下来是反向传播过程,反向传播中一般使用的是梯度下降法,当然不同的模型也可以不同,这里以吴恩达老师课上所讲的为例。梯度下降法从weizhi损失函数开始,及从最后开始,求损失函数对前面变量的导数,进而对参数进行不断地调整,直到达到指定的迭代次数或者达到指定误差范围为止。这样得到的参数即为最终的参数,也就完成了模型的训练。在我目前的理解中,训练模型就是对神经网络中的参数进行优化的过程。
之后是预测,预测时使用的是预测数据,与训练数据不同,预测数据中只有输入变量x的值,而输出变量的值则是需要通过神经网络进行求解的。预测过程也就是一个正向传播的过程。
大家可以能还对隐藏层和输出层中分为两个部分有疑惑,这是因为由于现实中的问题大多都是非线性的,以中间的隐藏层为例,如果该神经节点只包含前半部分z,这只是一个线性变换,很难解决实际问题中的非线性问题,所以在进行线性变换求出z后还要使用一个非线性的激活函数(在某些特殊的情况下可能也会使用线性的激活函数,这是少数情况,这里不进行讨论),常见的激活函数大家可以自行百度,对于复杂的神经网络而言,它可能含有多层神经节点,每层神经节点使用的激活函数可以不同。
对于代码实践,这里推荐一个大佬的博文,他实现的是吴恩达老师课程的课后作业,讲解的很详细:https://blog.csdn.net/u013733326/article/details/79639509
补一张图:

上面这幅图比较好的展示了正向传播和反向传播的过程。
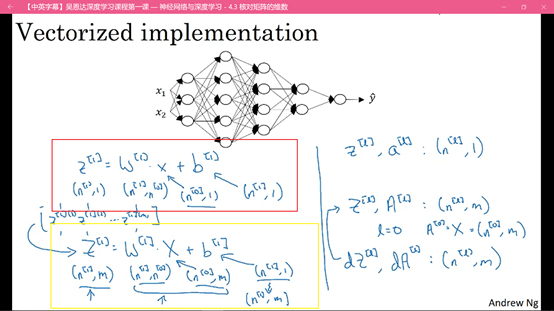
在实际操作中,很多bug是由于矩阵维数不一致造成的,上图红框中是一个样本在正向传播过程中的维度公式,黄框中是对于m个样本在正向传播过程中的维度公式。
这里放一些自己认为有助于理解神经网络的好的文章:
1.https://zhuanlan.zhihu.com/p/65472471 这篇文章通俗易懂的讲解了神经网络的基本过程,适合不理解神经网络的基本过程的小白
2021应该是元气满满的一年,希望不负努力。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号