哈希表的一些知识点
抛砖引玉,大家有没有想过Object-C中,NSDictionary是如何实现根据key快速查值的?
前言
在编程的世界中,比较重要的数据结构有以下3个:
- struct 结构体
- array 数组
- link list 链表
我们都知道,数组是存储数据的天然载体,在内存中是一段连续的地址,正是由于这个特性,我们能够通过数组的下标快速的获取与之对应的value。本质上是通过下标来计算出value的内存地址。
NSDictionary本身是一种key-value的结构关系。其内部也是用数组来存储value。那么就产生了一个最核心的问题,如何根据key来获取value的内存地址?这个过程既简单又不简单,由此我们引出哈希表的知识点。
哈希表
哈希表是一种数据结构,实现key-value的快速存取。之前说过数组可以实现快速存取,所以哈希表肯定会使用到数组。在这里,我们把每一个数组的单元叫做一个bucket(桶)。
CoreFoundation中的桶:
typedef struct {
CFIndex idx;
uintptr_t weak_key;
uintptr_t weak_value;
uintptr_t count;
} CFBasicHashBucket;
PHP中的桶:
typedef struct bucket {
ulong h; /* Used for numeric indexing */
uint nKeyLength;
void *pData;
void *pDataPtr;
struct bucket *pListNext;
struct bucket *pListLast;
struct bucket *pNext;
struct bucket *pLast;
char arKey[1]; /* Must be last element */
} Bucket;
通过上边的结构体,我们知道了,在数组中存放的是一个一个的桶,那么应该如何通过key来获取到指定的桶呢?
这时候就需要一个函数来实现这样一个功能,通过key计算出桶的内存地址。这个函数就叫做哈希函数F(x)。在现实中,考虑到性能的原因,这个哈希函数不会被设计成完美函数,即一个key只生成一个结果。有可能两个不同的key1,key2通过哈希函数得到了同一个值,这时候我们就称key1,key2为同义词,因此就产生了冲突,这个冲突往往发生在插值的过程中。
既然产生了冲突,就要想办法解决冲突。解决冲突的方式主要分两类 开放定址法(Open addressing)这种方法就是在计算一个key的哈希的时候,发现目标地址已经有值了,即发生冲突了,这个时候通过相应的函数在此地址后面的地址去找,直到没有冲突为止。这个方法常用的有线性探测,二次探测,再哈希。 这种解决方法有个不好的地方就是,当发生冲突之后,会在之后的地址空间中找一个放进去,这样就有可能后来出现一个key哈希出来的结果也正好是它放进去的这个地址空间,这样就会出现非同义词的两个key发生冲突。
链接法(Separate chaining)链接法是通过数组和链表组合而成的。当发生冲突的时候只要将其加到对应的链表中即可。
与开放定址法相比,链接法有如下几个优点:
- 链接法处理冲突简单,且无堆积现象,即非同义词决不会发生冲突,因此平均查找长度较短;
- 由于链接法中各链表上的结点空间是动态申请的,故它更适合于造表前无法确定表长的情况;
- 开放定址法为减少冲突,要求装填因子α较小,故当结点规模较大时会浪费很多空间。而链接法中可取α≥1,且结点较大时,拉链法中增加的指针域可忽略不计,因此节省空间;
- 在用链接法构造的散列表中,删除结点的操作易于实现。只要简单地删去链表上相应的结点即可。而对开放地址法构造的散列表,删除结点不能简单地将被删结点的空间置为空,否则将截断在它之后填人散列表的同义词结点的查找路径。这是因为各种开放地址法中,空地址单元(即开放地址)都是查找失败的条件。因此在 用开放地址法处理冲突的散列表上执行删除操作,只能在被删结点上做删除标记,而不能真正删除结点。
当然链接法也有其缺点,拉链法的缺点是:指针需要额外的空间,故当结点规模较小时,开放定址法较为节省空间,而若将节省的指针空间用来扩大散列表的规模,可使装填因子变小,这又减少了开放定址法中的冲突,从而提高平均查找速度。
负载因子 Load factor a=哈希表的实际元素数目(n)/ 哈希表的容量(m) a越大,哈希表冲突的概率越大,但是a越接近0,那么哈希表的空间就越浪费。 一般情况下建议Load factor的值为0-0.7,Java实现的HashMap默认的Load factor的值为0.75,当装载因子大于这个值的时候,HashMap会对数组进行扩张至原来两倍大。
不论使用了哪种碰撞解决策略,都导致插入和查找操作的时间复杂度不再是O(1)。以查找为例,不能通过key定位到桶就结束,必须还要比较原始key(即未做哈希之前的key)是否相等,如果不相等,则要使用与插入相同的算法继续查找,直到找到匹配的值或确认数据不在哈希表中。
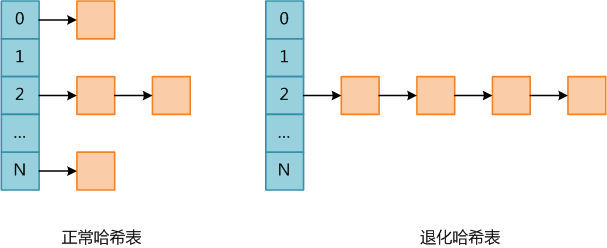
PHP是使用单链表存储碰撞的数据,因此实际上PHP哈希表的平均查找复杂度为O(L),其中L为桶链表的平均长度;而最坏复杂度为O(N),此时所有数据全部碰撞,哈希表退化成单链表。下图PHP中正常哈希表和退化哈希表的示意图。
总结
哈希和哈希表的概念是这篇文章的重点,即使开发中用到的概率不高。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号