
Django的View(视图)
原文链接:https://www.cnblogs.com/maple-shaw/articles/9285269.html
一个视图函数(类),简称视图,是一个简单的Python 函数(类),它接受Web请求并且返回Web响应。
响应可以是一张网页的HTML内容,一个重定向,一个404错误,一个XML文档,或者一张图片。
无论视图本身包含什么逻辑,都要返回响应。代码写在哪里也无所谓,只要它在你当前项目目录下面。除此之外没有更多的要求了——可以说“没有什么神奇的地方”。为了将代码放在某处,大家约定成俗将视图放置在项目(project)或应用程序(app)目录中的名为views.py的文件中。
一个简单的视图


from django.http import HttpResponse
import datetime
def current_datetime(request):
now = datetime.datetime.now()
html = "<html><body>It is now %s.</body></html>" % now
return HttpResponse(html)
让我们来逐行解释下上面的代码:
-
首先,我们从 django.http模块导入了HttpResponse类,以及Python的datetime库。
-
接着,我们定义了current_datetime函数。它就是视图函数。每个视图函数都使用HttpRequest对象作为第一个参数,并且通常称之为request。
注意,视图函数的名称并不重要;不需要用一个统一的命名方式来命名,以便让Django识别它。我们将其命名为current_datetime,是因为这个名称能够比较准确地反映出它实现的功能。
-
这个视图会返回一个HttpResponse对象,其中包含生成的响应。每个视图函数都负责返回一个HttpResponse对象。
Django使用请求和响应对象来通过系统传递状态。
当浏览器向服务端请求一个页面时,Django创建一个HttpRequest对象,该对象包含关于请求的元数据。然后,Django加载相应的视图,将这个HttpRequest对象作为第一个参数传递给视图函数。
每个视图负责返回一个HttpResponse对象。
CBV和FBV
CBV :class based views FBV :function based views
我们之前写过的都是基于函数的view,就叫FBV。还可以把view写成基于类的。
就拿我们之前写过的添加班级为例:
FBV版:
# FBV版添加班级
def add_class(request):
if request.method == "POST":
class_name = request.POST.get("class_name")
models.Classes.objects.create(name=class_name)
return redirect("/class_list/")
return render(request, "add_class.html")
CBV版:
# CBV版添加班级
from django.views import View
class AddClass(View):
def get(self, request):
return render(request, "add_class.html")
def post(self, request):
class_name = request.POST.get("class_name")
models.Classes.objects.create(name=class_name)
return redirect("/class_list/")
注意:
使用CBV时,urls.py中也做对应的修改:
# urls.py中 url(r'^add_class/$', views.AddClass.as_view()),
将函数改为类(FBV->CBV)案例,即定义CBV的写法:
新增出版社函数分get请求和post请求,各自返回不同的内容,逻辑代码如下


# 新增出版社 def add_publisher(request): error = '' # 对请求方式进行判断 if request.method == 'POST': # 处理POST请求 # 获取到出版社的名称 publisher_name = request.POST.get('publisher_name') # 判断出版社名称是否有重复的 if models.Publisher.objects.filter(name=publisher_name): error = '出版社名称已存在' # 判断输入的值是否为空 if not publisher_name: error = '不能输入为空' if not error: # 使用ORM将数据插入到数据库中 obj = models.Publisher.objects.create(name=publisher_name) # 跳转到展示出版社的页面 return redirect('/publisher_list/') # 返回一个包含form表单的页面 return render(request, 'add_publisher.html', {'error': error})
1)我们要将函数改成类,这个类不能直接只是我们自己写,因为需要很多功能,自己写的然后需要继承Django的View类。
2)定义的类中写get和post等方法,需要接收参数request。方法中是各自请求做的操作以及返回的一个响应
3)当请求到来时根据请求方法会执行对应的方法,然后返回响应的内容
4)这样执行的好处是把各个请求的代码分开了,是逻辑更清楚
5)如果还有其他的请求,那么继续写对应请求的方法。
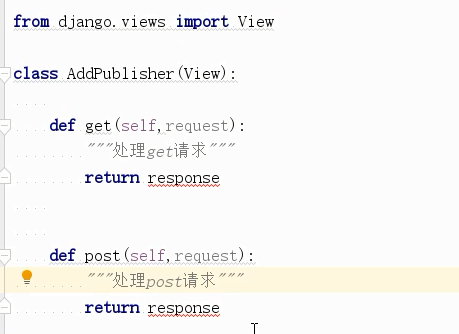
6)使用CBV:将之前对应的函数写成对应的类,并且模块.类.as_views() 执行,这样就实现了CBV写法,get请求就走get方法
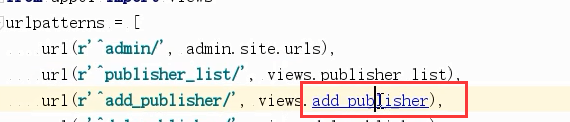
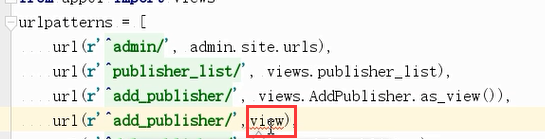
如果没有加as_views(),那么报错:

没有执行报错:

如此才是正确的
url(r'^add_publisher/', views.AddPblisher.as_view()),
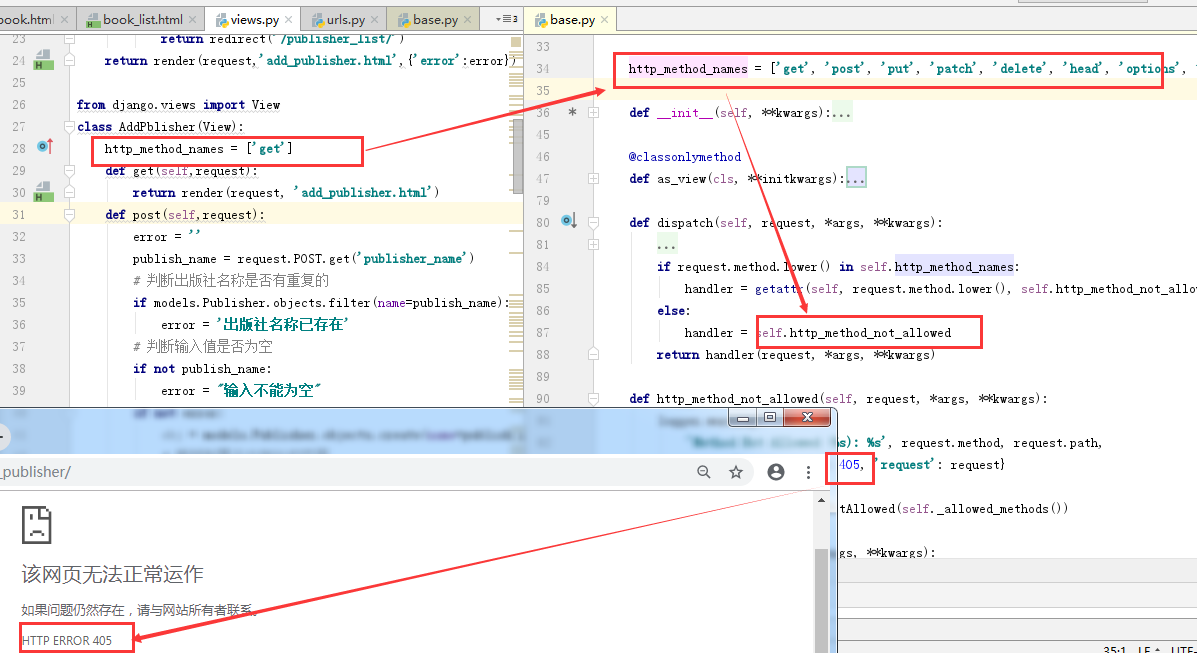
as_view的流程
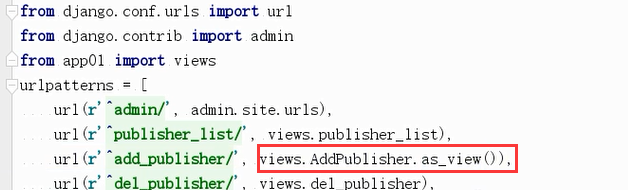
class View(object): """ Intentionally simple parent class for all views. Only implements dispatch-by-method and simple sanity checking. """ http_method_names = ['get', 'post', 'put', 'patch', 'delete', 'head', 'options', 'trace'] def __init__(self, **kwargs): """ Constructor. Called in the URLconf; can contain helpful extra keyword arguments, and other things. """ # Go through keyword arguments, and either save their values to our # instance, or raise an error. for key, value in six.iteritems(kwargs): setattr(self, key, value) @classonlymethod def as_view(cls, **initkwargs): """ Main entry point for a request-response process. """ for key in initkwargs: if key in cls.http_method_names: raise TypeError("You tried to pass in the %s method name as a " "keyword argument to %s(). Don't do that." % (key, cls.__name__)) if not hasattr(cls, key): raise TypeError("%s() received an invalid keyword %r. as_view " "only accepts arguments that are already " "attributes of the class." % (cls.__name__, key)) def view(request, *args, **kwargs): self = cls(**initkwargs) if hasattr(self, 'get') and not hasattr(self, 'head'): self.head = self.get self.request = request self.args = args self.kwargs = kwargs return self.dispatch(request, *args, **kwargs) view.view_class = cls view.view_initkwargs = initkwargs # take name and docstring from class update_wrapper(view, cls, updated=()) # and possible attributes set by decorators # like csrf_exempt from dispatch update_wrapper(view, cls.dispatch, assigned=()) return view
cls指的是当前的类,就是我们在views模块中定义的类,url中执行了as_view(),由下图可知它的返回值是view,也就是views.AddPblisher.as_view()执行就是定义了一个view方法并返回的就是这个view方法。
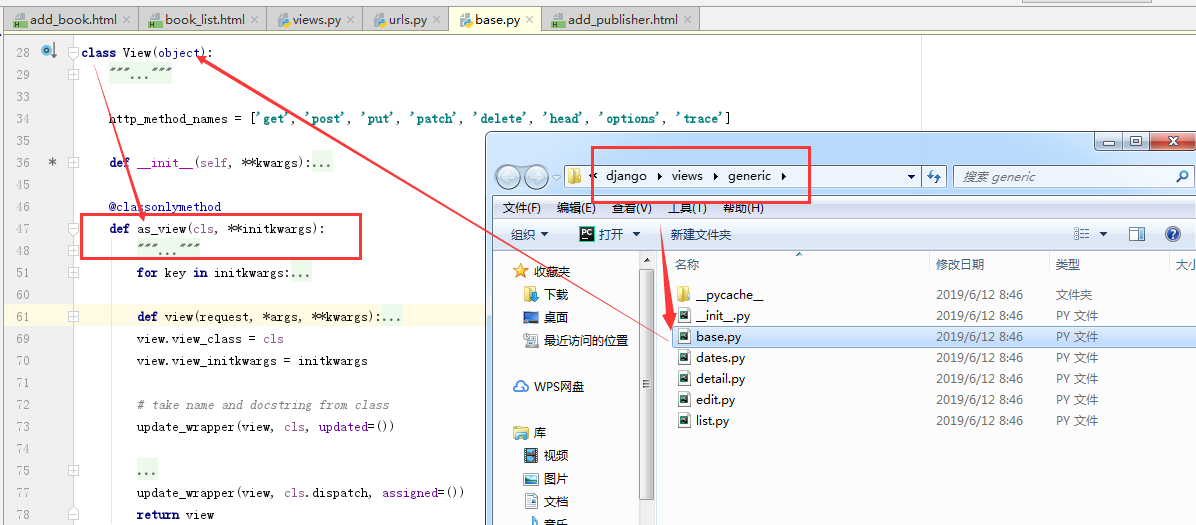
这就是相当于从上到下执行,然后到了这里就执行view函数
下面再看view函数做的
cls()将自己写的类AddPblisher实例化一个对象,并赋予self。然后这个子函数view中就能以self代替AddPblisher的对象做操作。
view函数中将request赋值给实例变量self.request,这样就能在CBV方式的类中get或其它方法里使用self.request,从而操作请求对象。而在FBV方式中直接使用request。

class View(object): """ Intentionally simple parent class for all views. Only implements dispatch-by-method and simple sanity checking. """ http_method_names = ['get', 'post', 'put', 'patch', 'delete', 'head', 'options', 'trace'] def __init__(self, **kwargs): """ Constructor. Called in the URLconf; can contain helpful extra keyword arguments, and other things. """ # Go through keyword arguments, and either save their values to our # instance, or raise an error. for key, value in six.iteritems(kwargs): setattr(self, key, value) @classonlymethod def as_view(cls, **initkwargs): #cls指的是当前的类,就是我们在views模块中定义的类 """ Main entry point for a request-response process. """ for key in initkwargs: if key in cls.http_method_names: raise TypeError("You tried to pass in the %s method name as a " "keyword argument to %s(). Don't do that." % (key, cls.__name__)) if not hasattr(cls, key): raise TypeError("%s() received an invalid keyword %r. as_view " "only accepts arguments that are already " "attributes of the class." % (cls.__name__, key)) def view(request, *args, **kwargs): self = cls(**initkwargs) # cls()将自己写的类AddPblisher实例化一个对象,并赋予self。然后在类AddPblisher中就能以self代替AddPblisher的对象做操作。 if hasattr(self, 'get') and not hasattr(self, 'head'): self.head = self.get self.request = request #在这里request和self.request是一样的,这样做是为了在自己创建的类中能用self.的方法 self.args = args self.kwargs = kwargs return self.dispatch(request, *args, **kwargs) #view返回的是dispatch方法的返回值。 view.view_class = cls view.view_initkwargs = initkwargs # take name and docstring from class update_wrapper(view, cls, updated=()) # and possible attributes set by decorators # like csrf_exempt from dispatch update_wrapper(view, cls.dispatch, assigned=()) return view def dispatch(self, request, *args, **kwargs): # Try to dispatch to the right method; if a method doesn't exist, # defer to the error handler. Also defer to the error handler if the # request method isn't on the approved list. #http_method_names = ['get', 'post', 'put', 'patch', 'delete', 'head', 'options', 'trace'] if request.method.lower() in self.http_method_names: #如果请求方式变小写后在上面的列表中,那么让handler通过反射获取到你的请求方法,否则让它 handler = getattr(self, request.method.lower(), self.http_method_not_allowed) #等于 self.http_method_not_allowed else: handler = self.http_method_not_allowed #否则handler等于 self.http_method_not_allowed 方法 return handler(request, *args, **kwargs) #返回handler的执行结果给as_view中的view,有人调用as_view方法是,那么返回的就是view的返回值,view方法的返回值是 #当url中执行了as_view方法时,返回的是view这个实现闭包并封装了数据的函数地址,url中相当于写的是view这个函数,那么url路由之后会执行view这个函数。 view执行的返回值就是dispatch执行的返回值。dispatch执行的返回值就是handler函数的返回值。[1]如果浏览器的请求方式在我的方式列表中(一般是8个)存在,那么handler就是self对象本身和请求方式通过反射获取到小写的请求方式的方法。[2]如果不是那么让它等于另一个方法。[3]如果handler是【1】,那么get方法首先从我写的类中找,我们在类中写了get请求方法,那么handler执行的返回值就是我们get的返回内容。也就是我们在自己创建的类中写了对应请求的方法,那么就会执行我们写的对应请求的方法。[4]如果handler是【2】,那么返回的self.http_method_not_allowed是不被允许访问的方法执行返回结果。即打印405错误码并返回执行不被允许的的返回方法。 def http_method_not_allowed(self, request, *args, **kwargs): logger.warning( 'Method Not Allowed (%s): %s', request.method, request.path, extra={'status_code': 405, 'request': request} ) return http.HttpResponseNotAllowed(self._allowed_methods())
#当url中执行了as_view方法时,返回的是view这个实现闭包并封装了数据的函数地址,url中相当于写的是view这个函数,那么url路由之后会执行view这个函数。
view执行的返回值就是dispatch执行的返回值。dispatch执行的返回值就是handler函数的返回值。[1]如果浏览器的请求方式在我的方式列表中(一般是8个)存在,那么handler就是self对象本身和请求方式通过反射获取到小写的请求方式的方法。[2]如果不是那么让它等于另一个方法。[3]如果handler是【1】,那么get方法首先从我写的类中找,我们在类中写了get请求方法,那么handler执行的返回值就是我们get的返回内容。也就是我们在自己创建的类中写了对应请求的方法,那么就会执行我们写的对应请求的方法。[4]如果handler是【2】,那么返回的self.http_method_not_allowed是不被允许访问的方法执行返回结果。即打印405错误码并返回执行不被允许的的返回方法。
如果get不到也是执行不被允许的方法
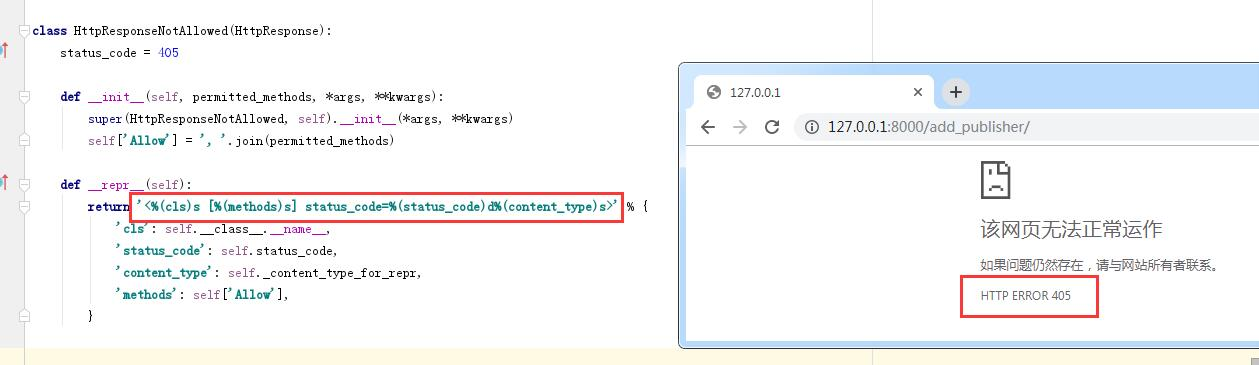
base.py class View(object): http_method_names = ['get', 'post', 'put', 'patch', 'delete', 'head', 'options', 'trace'] @classonlymethod def as_view(cls, **initkwargs): def view(request, *args, **kwargs): self = cls(**initkwargs) if hasattr(self, 'get') and not hasattr(self, 'head'): self.head = self.get self.request = request self.args = args self.kwargs = kwargs return self.dispatch(request, *args, **kwargs) view.view_class = cls ................. return view def dispatch(self, request, *args, **kwargs): if request.method.lower() in self.http_method_names: handler = getattr(self, request.method.lower(), self.http_method_not_allowed) else: handler = self.http_method_not_allowed return handler(request, *args, **kwargs) def http_method_not_allowed(self, request, *args, **kwargs): logger.warning( 'Method Not Allowed (%s): %s', request.method, request.path, extra={'status_code': 405, 'request': request} ) return http.HttpResponseNotAllowed(self._allowed_methods()) 另一个文件:response.py class HttpResponseNotAllowed(HttpResponse): status_code = 405 def __init__(self, permitted_methods, *args, **kwargs): super(HttpResponseNotAllowed, self).__init__(*args, **kwargs) self['Allow'] = ', '.join(permitted_methods) def __repr__(self): return '<%(cls)s [%(methods)s] status_code=%(status_code)d%(content_type)s>' % { 'cls': self.__class__.__name__, 'status_code': self.status_code, 'content_type': self._content_type_for_repr, 'methods': self['Allow'], }

如下,我要在子中重写源码中的dispatch()方法。因为dispatch执行的结果就是返回的页面的内容,2处找这个方法先在1处寻找,找到后给浏览器返回ok,那么此时无论什么请求都是返回的ok,不符合我们的需要
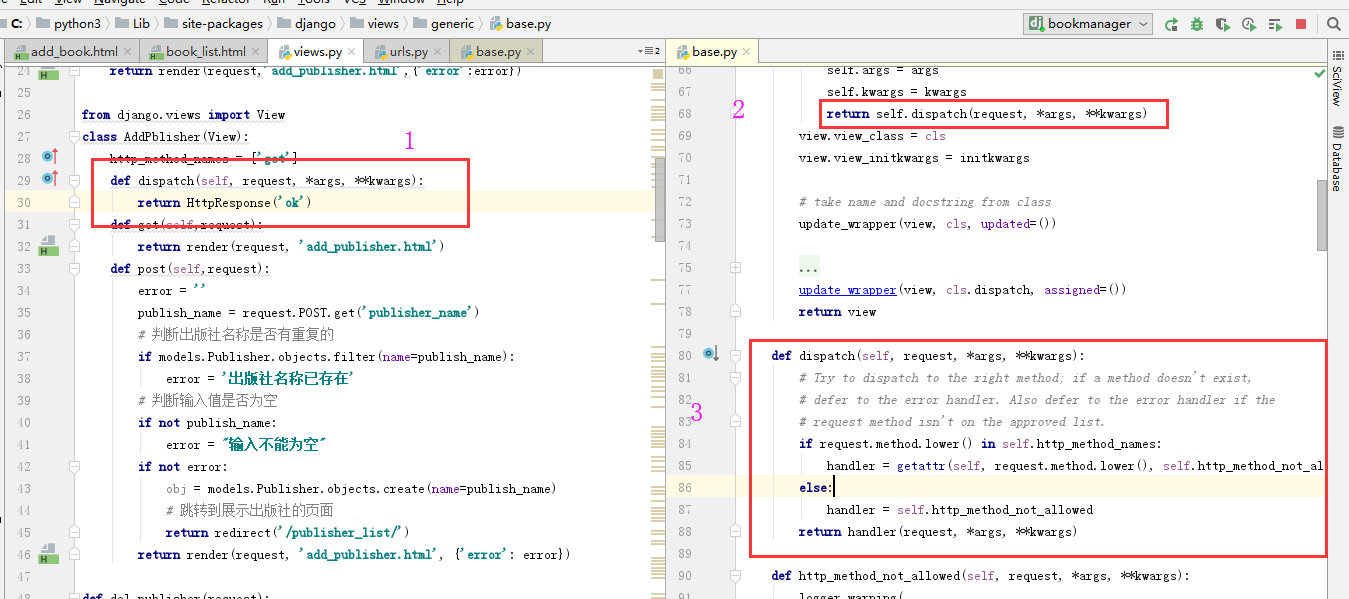
我们重写dispatch这个方法,那么就相当于是需要给这个方法添加功能。函数中装饰器可以给另外的函数添加功能,那么重写方法时我们可以super执行父类中的方法并接收返回值,在执行父类中方法的前后做些其它的操作给它添加功能。
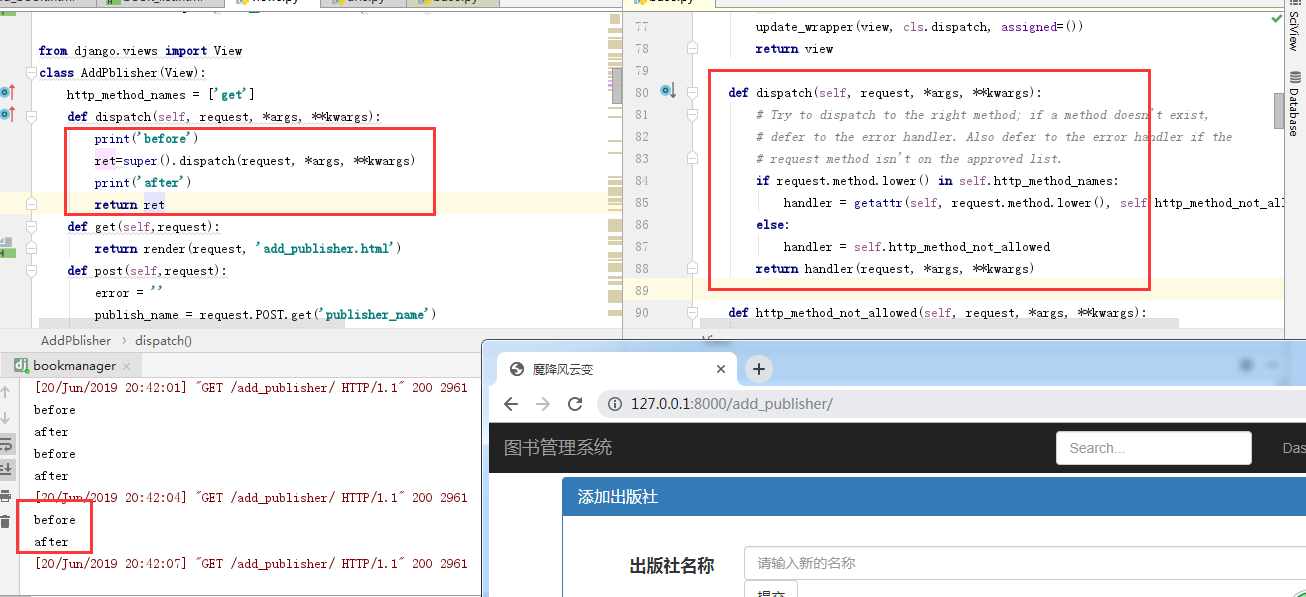
如果将super前后换成时间,那么就能计算dispatch执行时间
给视图加装饰器
使用装饰器装饰FBV
FBV本身就是一个函数,所以和给普通的函数加装饰器无差:
def wrapper(func): def inner(*args, **kwargs): start_time = time.time() ret = func(*args, **kwargs) end_time = time.time() print("used:", end_time-start_time) return ret return inner # FBV版添加班级 @wrapper def add_class(request): if request.method == "POST": class_name = request.POST.get("class_name") models.Classes.objects.create(name=class_name) return redirect("/class_list/") return render(request, "add_class.html")
使用装饰器装饰CBV
类中的方法与独立函数不完全相同,因此不能直接将函数装饰器应用于类中的方法 ,我们需要先将其转换为方法装饰器。
Django中提供了method_decorator装饰器用于将函数装饰器转换为方法装饰器。
# CBV版添加班级 from django.views import View from django.utils.decorators import method_decorator class AddClass(View): @method_decorator(wrapper) def get(self, request): return render(request, "add_class.html") def post(self, request): class_name = request.POST.get("class_name") models.Classes.objects.create(name=class_name) return redirect("/class_list/")
# 使用CBV时要注意,请求过来后会先执行dispatch()这个方法,如果需要批量对具体的请求处理方法,如get,post等做一些操作的时候,这里我们可以手动改写dispatch方法,这个dispatch方法就和在FBV上加装饰器的效果一样。 class Login(View): def dispatch(self, request, *args, **kwargs): print('before') obj = super(Login,self).dispatch(request, *args, **kwargs) print('after') return obj def get(self,request): return render(request,'login.html') def post(self,request): print(request.POST.get('user')) return HttpResponse('Login.post')
我们在视图函数中给类中方法加装饰器,先导入某个类。然后直接在get等方法前面@方式装饰器(装饰器函数名)。如果想要所有请求加上装饰器,那么重写dispatch方法并执行父的方法,然后给dispatch方法添加这个装饰器。
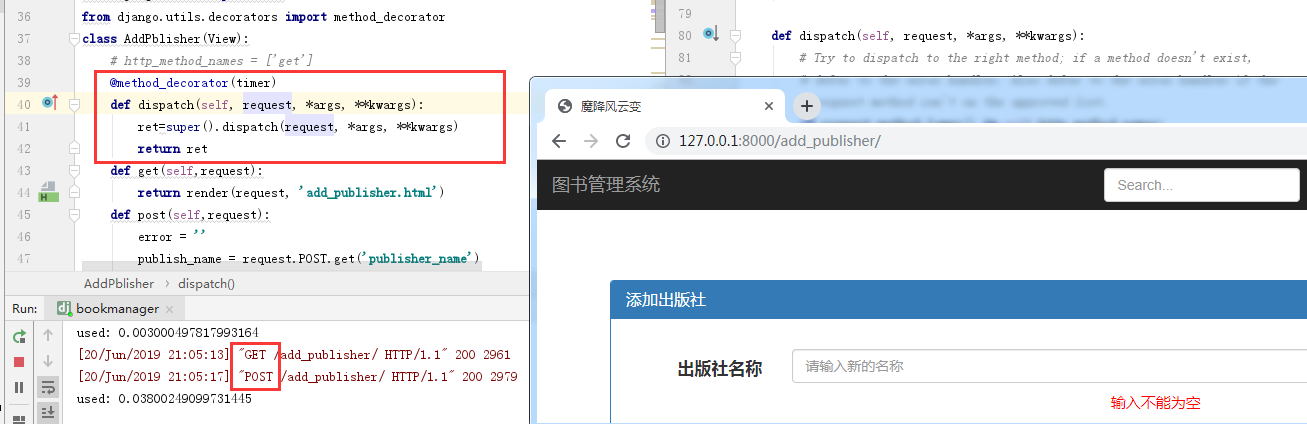
还可以加多个,指定方法名字:
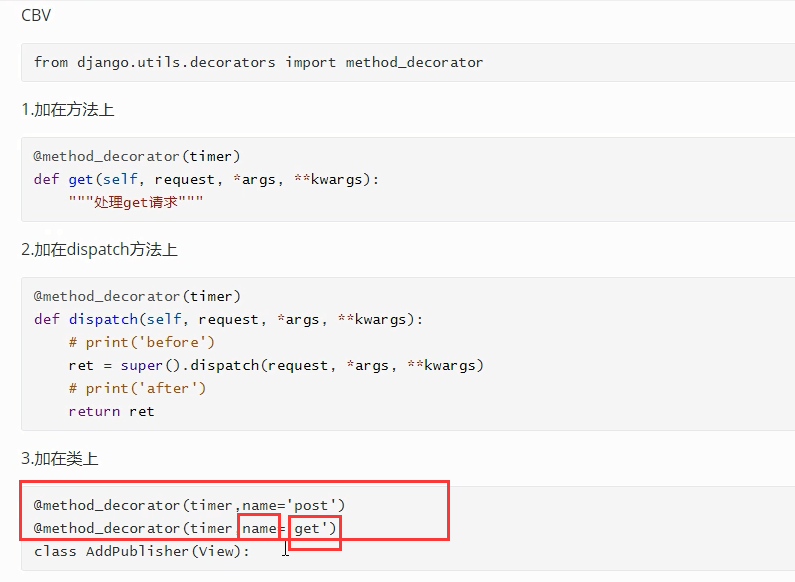
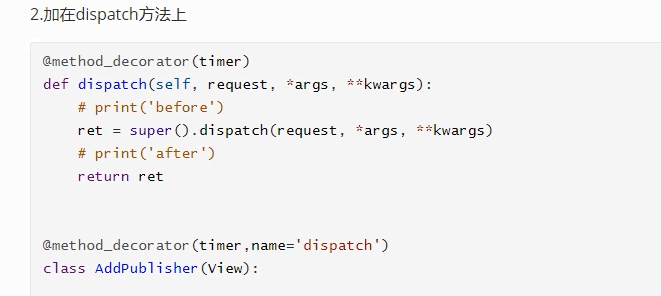
在类中方法添加装饰器,可以直接
@装饰器名
def 方法名字(self):
使用和不使用method_decorator的区别如下,主要是不使用时参数第一个是自己写的类对象,传到装饰器的第一个参数是方法中的self,第二个才是 我的request对象;使用时那么装饰器中第一个参数就是request

因此装饰器中要使用request对象,那么需要判断第几个形参是它:

Request对象和Response对象
当get访问一个网页的时候,GET和POST返回的都是这里类型的,
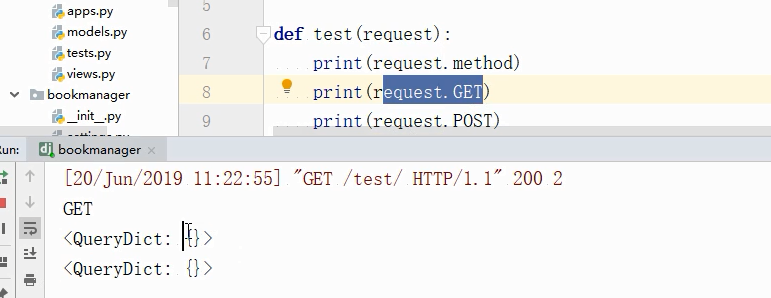
当get请求后面有拼接的内容的时候,

get就有值了
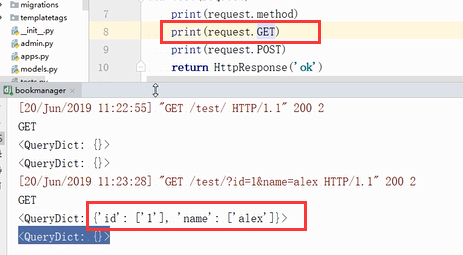
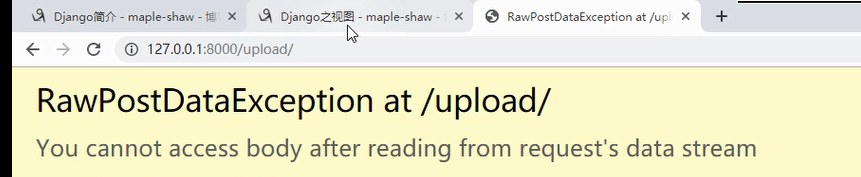
当访问是这个路径的时候,打印一下request.path_info 返回用户访问路径,不包括ip和端口

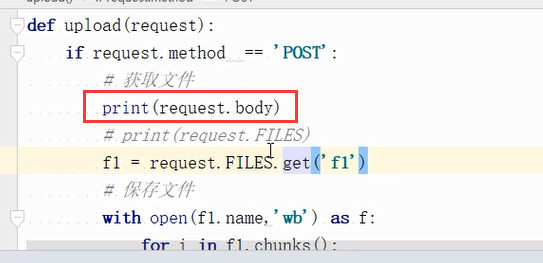
打印body,因为get没有请全体,是没有内容的bytes类型。请求行,请求头,请求体

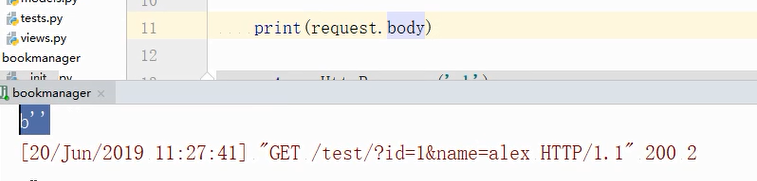
post请求中打印请求体:print('request.body'),数据会进行url编码,原始的数据编码了的


request对象
当一个页面被请求时,Django就会创建一个包含本次请求原信息的HttpRequest对象。
Django会将这个对象自动传递给响应的视图函数,一般视图函数约定俗成地使用 request 参数承接这个对象。
请求相关的常用值
- path_info 返回用户访问url,不包括域名
- method 请求中使用的HTTP方法的字符串表示,全大写表示。
- GET 包含所有HTTP GET参数的类字典对象
- POST 包含所有HTTP POST参数的类字典对象
- body 请求体,byte类型 request.POST的数据就是从body里面提取到的
属性
所有的属性应该被认为是只读的,除非另有说明。
0.HttpRequest.scheme
表示请求方案的字符串(通常为http或https),即浏览器请求协议http https
print(request,type(request)) # <WSGIRequest: GET '/test/'> <class 'django.core.handlers.wsgi.WSGIRequest'>
属性: django将请求报文中的请求行、头部信息、内容主体封装成 HttpRequest 类中的属性。 除了特殊说明的之外,其他均为只读的。 0.HttpRequest.scheme 表示请求方案的字符串(通常为http或https) 1.HttpRequest.body 一个字符串,代表请求报文的主体。在处理非 HTTP 形式的报文时非常有用,例如:二进制图片、XML,Json等。 但是,如果要处理表单数据的时候,推荐还是使用 HttpRequest.POST 。 另外,我们还可以用 python 的类文件方法去操作它,详情参考 HttpRequest.read() 。 2.HttpRequest.path 一个字符串,表示请求的路径组件(不含域名)。 例如:"/music/bands/the_beatles/" 3.HttpRequest.method 一个字符串,表示请求使用的HTTP 方法。必须使用大写。 例如:"GET"、"POST" 4.HttpRequest.encoding 一个字符串,表示提交的数据的编码方式(如果为 None 则表示使用 DEFAULT_CHARSET 的设置,默认为 'utf-8')。 这个属性是可写的,你可以修改它来修改访问表单数据使用的编码。 接下来对属性的任何访问(例如从 GET 或 POST 中读取数据)将使用新的 encoding 值。 如果你知道表单数据的编码不是 DEFAULT_CHARSET ,则使用它。 5.HttpRequest.GET 一个类似于字典的对象,包含 HTTP GET 的所有参数。详情请参考 QueryDict 对象。 6.HttpRequest.POST 一个类似于字典的对象,如果请求中包含表单数据,则将这些数据封装成 QueryDict 对象。 POST 请求可以带有空的 POST 字典 —— 如果通过 HTTP POST 方法发送一个表单,但是表单中没有任何的数据,QueryDict 对象依然会被创建。 因此,不应该使用 if request.POST 来检查使用的是否是POST 方法;应该使用 if request.method == "POST" 另外:如果使用 POST 上传文件的话,文件信息将包含在 FILES 属性中。 7.HttpRequest.COOKIES 一个标准的Python 字典,包含所有的cookie。键和值都为字符串。 8.HttpRequest.FILES 一个类似于字典的对象,包含所有的上传文件信息。 FILES 中的每个键为<input type="file" name="" /> 中的name,值则为对应的数据。 注意,FILES 只有在请求的方法为POST 且提交的<form> 带有enctype="multipart/form-data" 的情况下才会 包含数据。否则,FILES 将为一个空的类似于字典的对象。 9.HttpRequest.META 一个标准的Python 字典,包含所有的HTTP 首部。具体的头部信息取决于客户端和服务器,下面是一些示例: CONTENT_LENGTH —— 请求的正文的长度(是一个字符串)。 CONTENT_TYPE —— 请求的正文的MIME 类型。 HTTP_ACCEPT —— 响应可接收的Content-Type。 HTTP_ACCEPT_ENCODING —— 响应可接收的编码。 HTTP_ACCEPT_LANGUAGE —— 响应可接收的语言。 HTTP_HOST —— 客服端发送的HTTP Host 头部。 HTTP_REFERER —— Referring 页面。 HTTP_USER_AGENT —— 客户端的user-agent 字符串。 QUERY_STRING —— 单个字符串形式的查询字符串(未解析过的形式)。 REMOTE_ADDR —— 客户端的IP 地址。 REMOTE_HOST —— 客户端的主机名。 REMOTE_USER —— 服务器认证后的用户。 REQUEST_METHOD —— 一个字符串,例如"GET" 或"POST"。 SERVER_NAME —— 服务器的主机名。 SERVER_PORT —— 服务器的端口(是一个字符串)。 从上面可以看到,除 CONTENT_LENGTH 和 CONTENT_TYPE 之外,请求中的任何 HTTP 首部转换为 META 的键时, 都会将所有字母大写并将连接符替换为下划线最后加上 HTTP_ 前缀。 所以,一个叫做 X-Bender 的头部将转换成 META 中的 HTTP_X_BENDER 键。 10.HttpRequest.user 一个 AUTH_USER_MODEL 类型的对象,表示当前登录的用户。 如果用户当前没有登录,user 将设置为 django.contrib.auth.models.AnonymousUser 的一个实例。你可以通过 is_authenticated() 区分它们。 例如: if request.user.is_authenticated(): # Do something for logged-in users. else: # Do something for anonymous users. user 只有当Django 启用 AuthenticationMiddleware 中间件时才可用。 ------------------------------------------------------------------------------------- 匿名用户 class models.AnonymousUser django.contrib.auth.models.AnonymousUser 类实现了django.contrib.auth.models.User 接口,但具有下面几个不同点: id 永远为None。 username 永远为空字符串。 get_username() 永远返回空字符串。 is_staff 和 is_superuser 永远为False。 is_active 永远为 False。 groups 和 user_permissions 永远为空。 is_anonymous() 返回True 而不是False。 is_authenticated() 返回False 而不是True。 set_password()、check_password()、save() 和delete() 引发 NotImplementedError。 New in Django 1.8: 新增 AnonymousUser.get_username() 以更好地模拟 django.contrib.auth.models.User。 11.HttpRequest.session 一个既可读又可写的类似于字典的对象,表示当前的会话。只有当Django 启用会话的支持时才可用。 完整的细节参见会话的文档。
{ 'ALLUSERSPROFILE': 'C:\\ProgramData', 'APPDATA': 'C:\\Users\\Administrator\\AppData\\Roaming', 'COMMONPROGRAMFILES': 'C:\\Program Files (x86)\\Common Files', 'COMMONPROGRAMFILES(X86)': 'C:\\Program Files (x86)\\Common Files', 'COMMONPROGRAMW6432': 'C:\\Program Files\\Common Files', 'COMPUTERNAME': 'PC-20190328RVNA', 'COMSPEC': 'C:\\Windows\\system32\\cmd.exe', 'DJANGO_SETTINGS_MODULE': 'bookmanager.settings', 'FP_NO_HOST_CHECK': 'NO', 'HOMEDRIVE': 'C:', 'HOMEPATH': '\\Users\\Administrator', 'LOCALAPPDATA': 'C:\\Users\\Administrator\\AppData\\Local', 'LOGONSERVER': '\\\\PC-20190328RVNA', 'NUMBER_OF_PROCESSORS': '4', 'OS': 'Windows_NT', 'PATH': 'C:\\Windows\\system32;C:\\Windows;C:\\Windows\\System32\\Wbem;C:\\Windows\\System32\\WindowsPowerShell\\v1.0\\;C:\\软件安装\\Git\\cmd;C:\\mysql\\mysql-5.6.44-winx64\\bin;C:\\python3\\Scripts\\;C:\\python3\\', 'PATHEXT': '.COM;.EXE;.BAT;.CMD;.VBS;.VBE;.JS;.JSE;.WSF;.WSH;.MSC', 'PROCESSOR_ARCHITECTURE': 'x86', 'PROCESSOR_ARCHITEW6432': 'AMD64', 'PROCESSOR_IDENTIFIER': 'Intel64 Family 6 Model 58 Stepping 9, GenuineIntel', 'PROCESSOR_LEVEL': '6', 'PROCESSOR_REVISION': '3a09', 'PROGRAMDATA': 'C:\\ProgramData', 'PROGRAMFILES': 'C:\\Program Files (x86)', 'PROGRAMFILES(X86)': 'C:\\Program Files (x86)', 'PROGRAMW6432': 'C:\\Program Files', 'PSMODULEPATH': 'C:\\Windows\\system32\\WindowsPowerShell\\v1.0\\Modules\\', 'PUBLIC': 'C:\\Users\\Public', 'PYCHARM_HOSTED': '1', 'PYCHARM_MATPLOTLIB_PORT': '50724', 'PYTHONIOENCODING': 'UTF-8', 'PYTHONPATH': 'C:\\mcw\\bookmanager;C:\\软件安装\\PyCharm 2018.3.5\\helpers\\pycharm_matplotlib_backend', 'PYTHONUNBUFFERED': '1', 'SESSIONNAME': 'Console', 'SYSTEMDRIVE': 'C:', 'SYSTEMROOT': 'C:\\Windows', 'TEMP': 'C:\\Users\\ADMINI~1\\AppData\\Local\\Temp', 'TMP': 'C:\\Users\\ADMINI~1\\AppData\\Local\\Temp', 'USERDOMAIN': 'PC-20190328RVNA', 'USERNAME': 'Administrator', 'USERPROFILE': 'C:\\Users\\Administrator', 'WINDIR': 'C:\\Windows', 'WINDOWS_TRACING_FLAGS': '3', 'WINDOWS_TRACING_LOGFILE': 'C:\\BVTBin\\Tests\\installpackage\\csilogfile.log', 'RUN_MAIN': 'true', 'SERVER_NAME': 'PC-20190328RVNA', 'GATEWAY_INTERFACE': 'CGI/1.1', 'SERVER_PORT': '8000', 'REMOTE_HOST': '', 'CONTENT_LENGTH': '', 'SCRIPT_NAME': '', 'SERVER_PROTOCOL': 'HTTP/1.1', 'SERVER_SOFTWARE': 'WSGIServer/0.2', 'REQUEST_METHOD': 'GET', 'PATH_INFO': '/test/', 'QUERY_STRING': '', 'REMOTE_ADDR': '127.0.0.1', 'CONTENT_TYPE': 'text/plain', 'HTTP_HOST': '127.0.0.1:8000', 'HTTP_CONNECTION': 'keep-alive', 'HTTP_CACHE_CONTROL': 'max-age=0', 'HTTP_UPGRADE_INSECURE_REQUESTS': '1', 'HTTP_USER_AGENT': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.169 Safari/537.36', 'HTTP_ACCEPT': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3', 'HTTP_ACCEPT_ENCODING': 'gzip, deflate, br', 'HTTP_ACCEPT_LANGUAGE': 'zh-CN,zh;q=0.9', 'HTTP_COOKIE': 'csrftoken=e17Wb68amZdumsRa67LXuTzmdEjaA2lYLj0OkmjiiR2SKPRXBHoYcB3c929v8csg', 'wsgi.input': < _io.BufferedReader name = 776 > , 'wsgi.errors': < _io.TextIOWrapper name = '<stderr>' mode = 'w' encoding = 'UTF-8' > , 'wsgi.version': (1, 0), 'wsgi.run_once': False, 'wsgi.url_scheme': 'http', 'wsgi.multithread': True, 'wsgi.multiprocess': False, 'wsgi.file_wrapper': < class 'wsgiref.util.FileWrapper' > , 'CSRF_COOKIE': 'e17Wb68amZdumsRa67LXuTzmdEjaA2lYLj0OkmjiiR2SKPRXBHoYcB3c929v8csg' }
上传文件示例
def upload(request): """ 保存上传文件前,数据需要存放在某个位置。默认当上传文件小于2.5M时,django会将上传文件的全部内容读进内存。从内存读取一次,写磁盘一次。 但当上传文件很大时,django会把上传文件写到临时文件中,然后存放到系统临时文件夹中。 :param request: :return: """ if request.method == "POST": # 从请求的FILES中获取上传文件的文件名,file为页面上type=files类型input的name属性值 filename = request.FILES["file"].name # 在项目目录下新建一个文件 with open(filename, "wb") as f: # 从上传的文件对象中一点一点读 for chunk in request.FILES["file"].chunks(): # 写入本地文件 f.write(chunk) return HttpResponse("上传OK")
1)post表单中写一个类型是file的input标签,起个name,给个button。
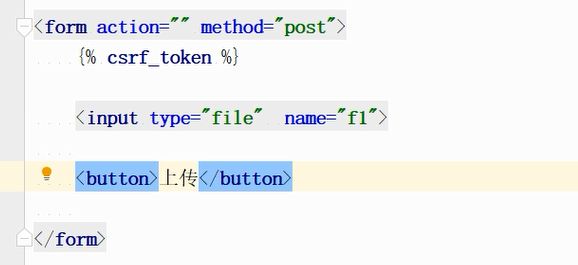

浏览器上传一张图片,查看文件是否获取到,结果为空
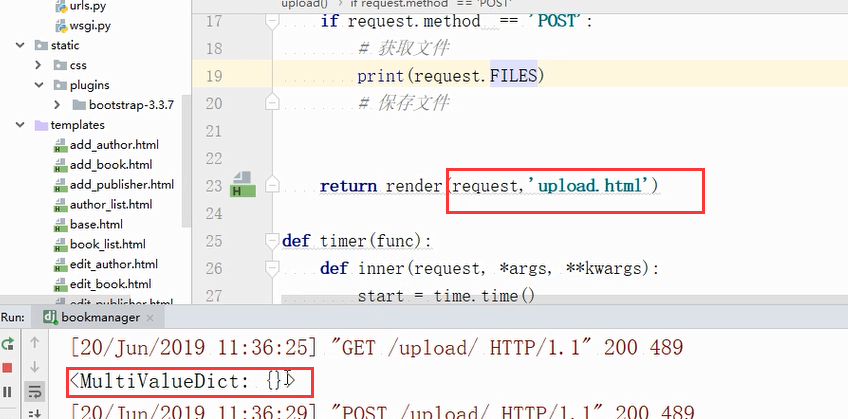
需要修改传输数据类型:
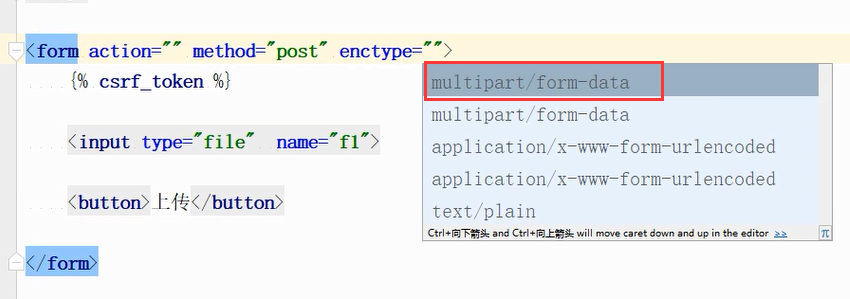
默认用的是下面这个:post请求中打印请求体:print('request.body'),数据会进行url编码,指的就是这个编码

然后上传文件:文件在request的FILES属性中
一个类似于字典的对象,包含所有的上传文件信息。 FILES 中的每个键为<input type="file" name="" /> 中的name,值则为对应的数据。 注意,FILES 只有在请求的方法为POST 且提交的<form> 带有enctype="multipart/form-data" 的情况下才会 包含数据。否则,FILES 将为一个空的类似于字典的对象。
get获取到这个文件对象。默认位置在项目根目录,获取到f1的值,值.name是文件名
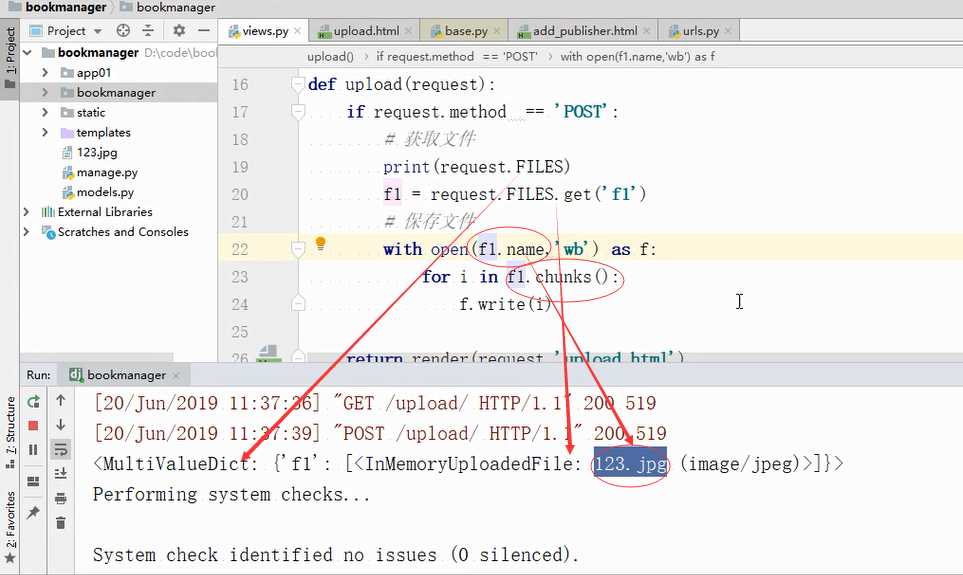
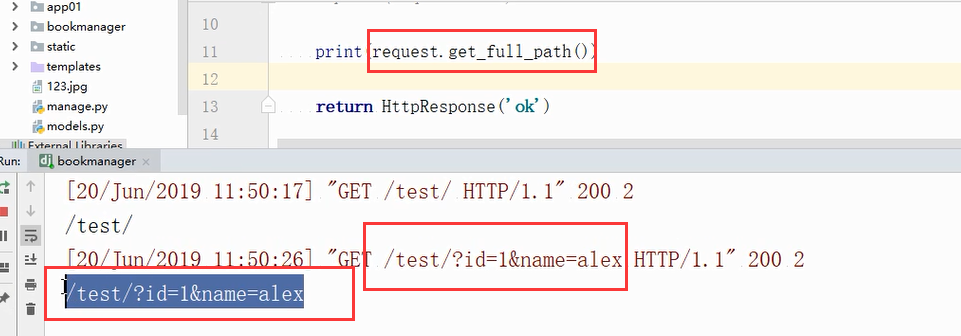
全路径:如果有拼接的内容也会获取到。不包含IP端口,但是包含参数
方法
1.HttpRequest.get_host() 根据从HTTP_X_FORWARDED_HOST(如果打开 USE_X_FORWARDED_HOST,默认为False)和 HTTP_HOST 头部信息返回请求的原始主机。 如果这两个头部没有提供相应的值,则使用SERVER_NAME 和SERVER_PORT,在PEP 3333 中有详细描述。 USE_X_FORWARDED_HOST:一个布尔值,用于指定是否优先使用 X-Forwarded-Host 首部,仅在代理设置了该首部的情况下,才可以被使用。 例如:"127.0.0.1:8000" 注意:当主机位于多个代理后面时,get_host() 方法将会失败。除非使用中间件重写代理的首部。 2.HttpRequest.get_full_path() 返回 path,如果可以将加上查询字符串。 例如:"/music/bands/the_beatles/?print=true" 3.HttpRequest.get_signed_cookie(key, default=RAISE_ERROR, salt='', max_age=None) 返回签名过的Cookie 对应的值,如果签名不再合法则返回django.core.signing.BadSignature。 如果提供 default 参数,将不会引发异常并返回 default 的值。 可选参数salt 可以用来对安全密钥强力攻击提供额外的保护。max_age 参数用于检查Cookie 对应的时间戳以确保Cookie 的时间不会超过max_age 秒。 复制代码 >>> request.get_signed_cookie('name') 'Tony' >>> request.get_signed_cookie('name', salt='name-salt') 'Tony' # 假设在设置cookie的时候使用的是相同的salt >>> request.get_signed_cookie('non-existing-cookie') ... KeyError: 'non-existing-cookie' # 没有相应的键时触发异常 >>> request.get_signed_cookie('non-existing-cookie', False) False >>> request.get_signed_cookie('cookie-that-was-tampered-with') ... BadSignature: ... >>> request.get_signed_cookie('name', max_age=60) ... SignatureExpired: Signature age 1677.3839159 > 60 seconds >>> request.get_signed_cookie('name', False, max_age=60) False 复制代码 4.HttpRequest.is_secure() 如果请求时是安全的,则返回True;即请求通是过 HTTPS 发起的。 5.HttpRequest.is_ajax() 如果请求是通过XMLHttpRequest 发起的,则返回True,方法是检查 HTTP_X_REQUESTED_WITH 相应的首部是否是字符串'XMLHttpRequest'。 大部分现代的 JavaScript 库都会发送这个头部。如果你编写自己的 XMLHttpRequest 调用(在浏览器端),你必须手工设置这个值来让 is_ajax() 可以工作。 如果一个响应需要根据请求是否是通过AJAX 发起的,并且你正在使用某种形式的缓存例如Django 的 cache middleware, 你应该使用 vary_on_headers('HTTP_X_REQUESTED_WITH') 装饰你的视图以让响应能够正确地缓存。
注意:键值对的值是多个的时候,比如checkbox类型的input标签,select标签,需要用:
request.POST.getlist("hobby")
Response对象
与由Django自动创建的HttpRequest对象相比,HttpResponse对象是我们的职责范围了。我们写的每个视图都需要实例化,填充和返回一个HttpResponse。
如果没有返回报错,需要返回一个HttpResponse对象
HttpResponse类位于django.http模块中。
render参数,有request 模板 上下文就是我们传的变量(字典)
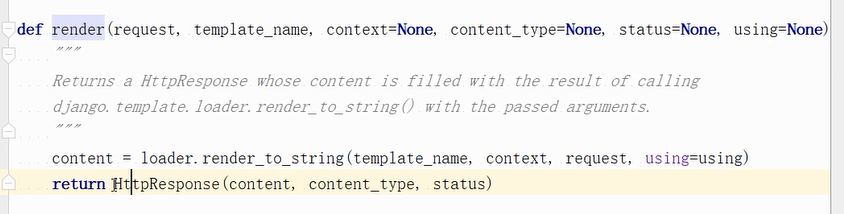
下面render_to_string方法会拿到模板和变量做字符串替换。返回的content就是渲染之后的html字符串。这个content内容又给了HttpResponse对象。也就是说render里面返回的还是HttpResponse对象,只是里面调用其它的方法把这个模板渲染好了。这里是Django的模板引擎,也可以换成jinja2的。
再看看redirect,拿到的是两个类:,返回的而是其中一个类的对象
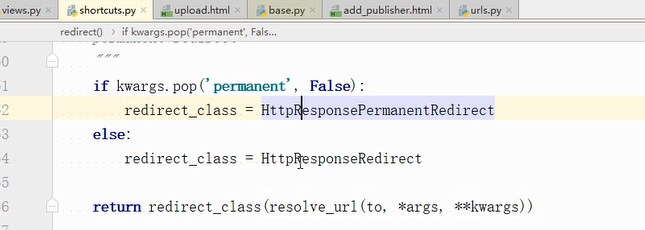
下面这个是永久跳转的类,

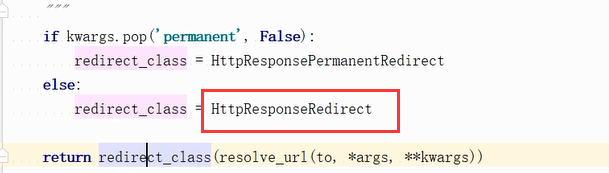
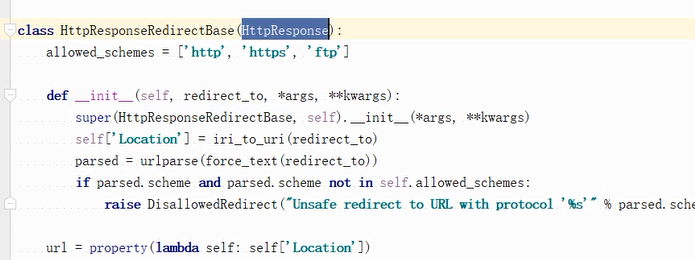
永久跳转的类继承的重定向基本的类,又是继承的HttpResponse这个类:location就是我们在开发这个工具中看到的重定向中的那个属性。所以重定向也是继承的HttpResponse。

它也是继承的这个对象:
使用
传递字符串
from django.http import HttpResponse
response = HttpResponse("Here's the text of the Web page.")
response = HttpResponse("Text only, please.", content_type="text/plain")
设置或删除响应头信息
response = HttpResponse() response['Content-Type'] = 'text/html; charset=UTF-8' del response['Content-Type']
属性
HttpResponse.content:响应内容
HttpResponse.charset:响应内容的编码
HttpResponse.status_code:响应的状态码
JsonResponse对象
JsonResponse是HttpResponse的子类,专门用来生成JSON编码的响应。
from django.http import JsonResponse
response = JsonResponse({'foo': 'bar'})
print(response.content)
b'{"foo": "bar"}'
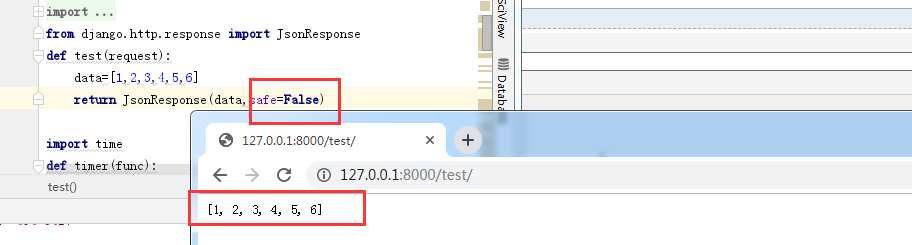
默认只能传递字典类型,如果要传递非字典类型需要设置一下safe关键字参数。
response = JsonResponse([1, 2, 3], safe=False)
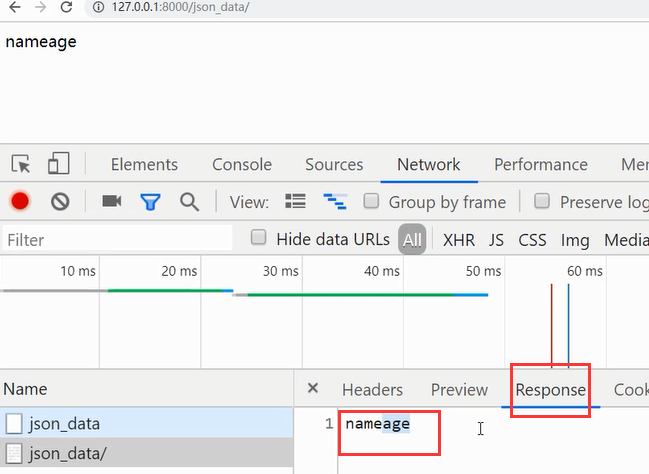
定义一个字典返回给浏览器

显示的是name和age连到一块的:将字典迭代拿的里面的key
但是我想要的是完整的字典,那么我就要自己做json序列化了:

显示的是完整的字典内容
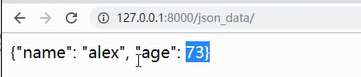
那么还可以使用另一个类做返回内容传递字典数据,直接将字典放到JsonResponse对象中

效果如下:跟自己做的json序列化比起来,小了点细了点。并且告诉浏览器当前发送数据内容的类型。如果是在使用ajax,那么它遇到这个内容它自己会做反序列化。前端发送一个请求,回来之后它看到这个类型自己会将这个数据反序列化,变成前端使用的对象,然后点的方法取里面的内容。
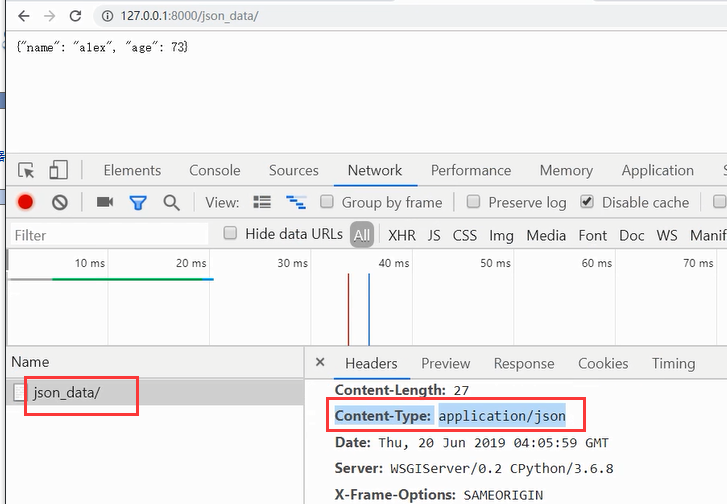
如果是自己做序列化的话那么响应头的内容类型如下。发送的是普通文本,它不会给你做任 何变化,你想用的话就需要自己做反序列化

我们也可以自己序列化发送,但是需要修改这个内容类型的属性,这样也可以达到一样的效果。用字典重新赋值的方式修改它的属性值

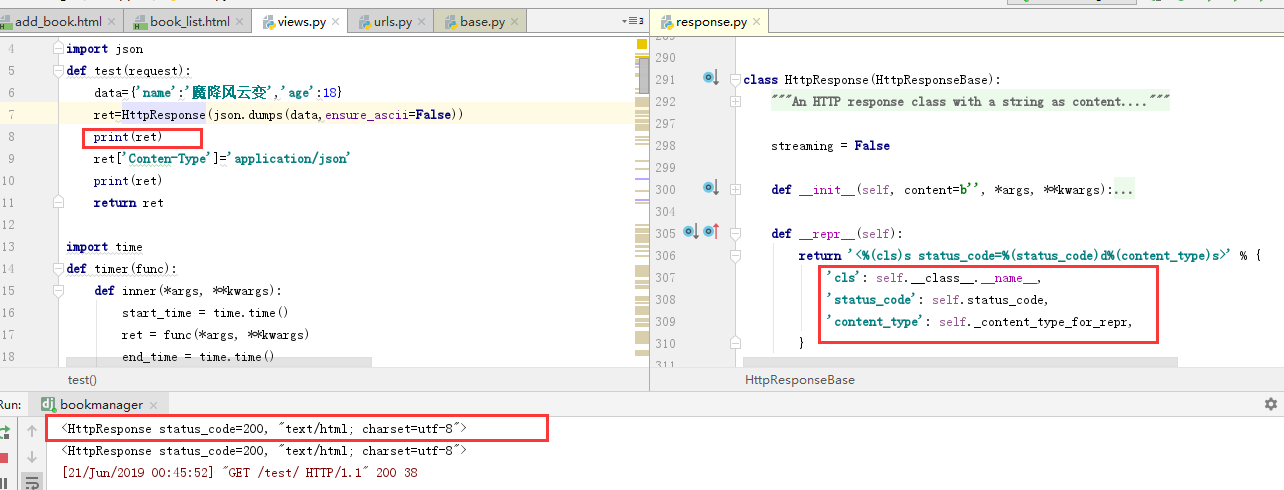
HttpResponse默认返回的是text/html charset utf-8 JsonResponse默认返回的是 application/json 。
下面可以找一下它的默认的:

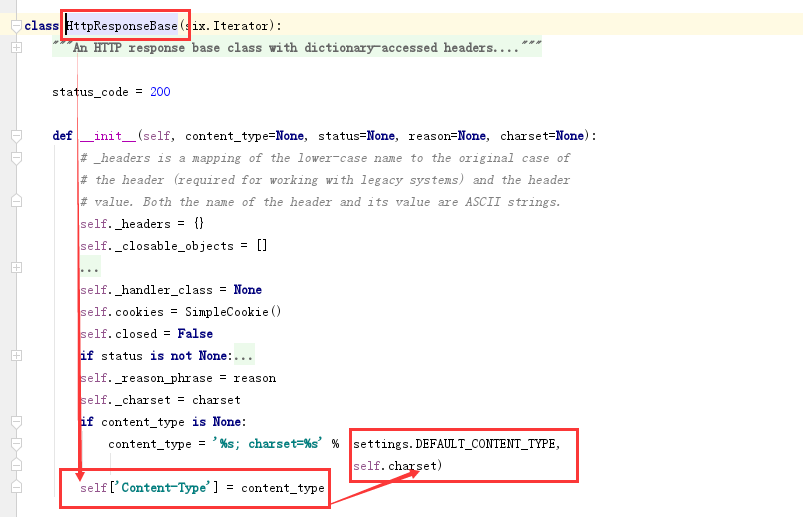
这个settings点不进去,它是全局配置文件里的:由下可以看到HttpResponse返回的是默认类型
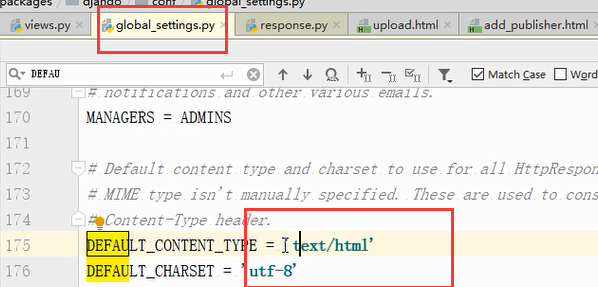
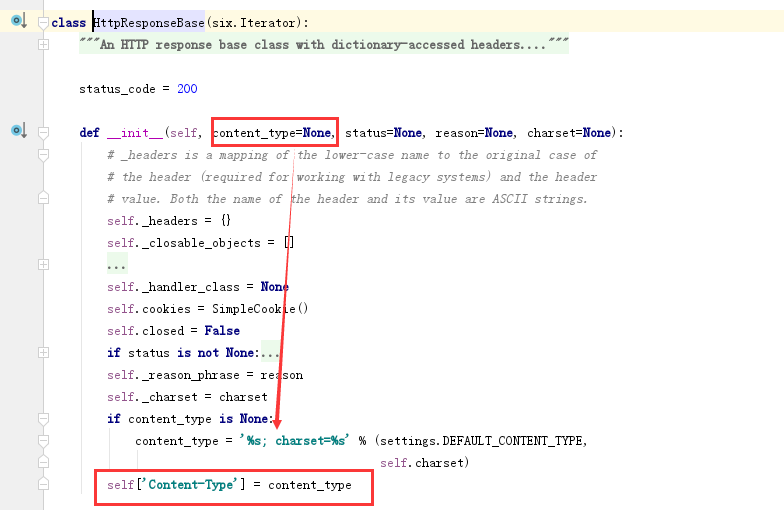
由下可以看出没有传默认参数那么使用的是text/html,
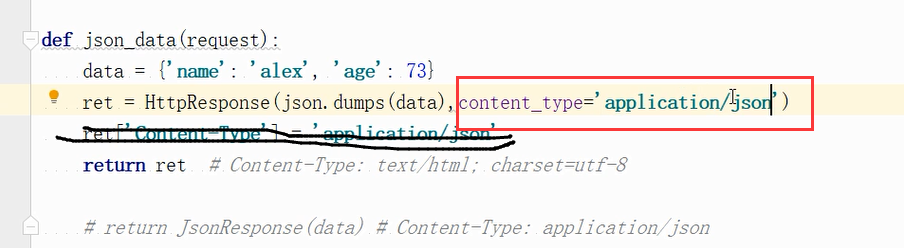
那么把内容类型传递一个参数修改成别的也可以改变它的类型:
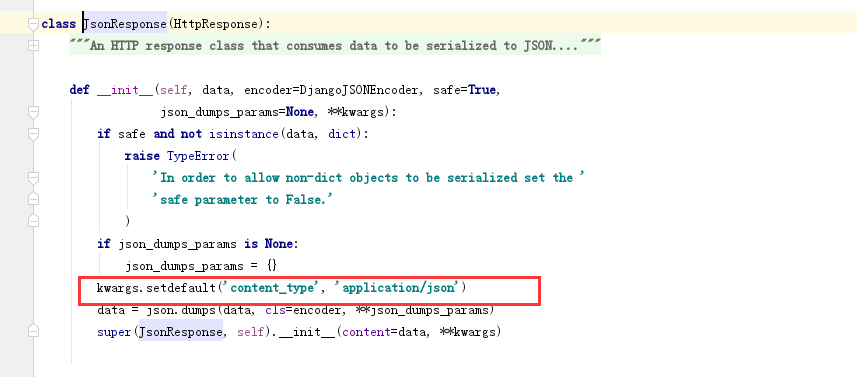
由下可以看到JsonResponse默认的就是 application/json 。JsonReponse会给你做序列化,并且响应头给你设置成application/json,有了这个之后,前端拿到数据就自动反序列化
那么其它类型的比如列表传输呢?报错: In order to allow non-dict objects to be serialized set the safe parameter to False.

那么根据提示设置safe为False前端就拿到数据了。这是因为JsonResponse默认只支持序列化字典类型的。如果是非字典类型的那么就要加上safe=False
Django shortcut functions
render()

结合一个给定的模板和一个给定的上下文字典,并返回一个渲染后的 HttpResponse 对象。
参数:
- request: 用于生成响应的请求对象。
- template_name:要使用的模板的完整名称,可选的参数
- context:添加到模板上下文的一个字典。默认是一个空字典。如果字典中的某个值是可调用的,视图将在渲染模板之前调用它。
- content_type:生成的文档要使用的MIME类型。默认为 DEFAULT_CONTENT_TYPE 设置的值。默认为'text/html'
- status:响应的状态码。默认为200。
- useing: 用于加载模板的模板引擎的名称。
一个简单的例子:
from django.shortcuts import render
def my_view(request):
# 视图的代码写在这里
return render(request, 'myapp/index.html', {'foo': 'bar'})
上面的代码等于:
from django.http import HttpResponse
from django.template import loader
def my_view(request):
# 视图代码写在这里
t = loader.get_template('myapp/index.html')
c = {'foo': 'bar'}
return HttpResponse(t.render(c, request))
redirect()
参数可以是:
- 一个模型:将调用模型的get_absolute_url() 函数
- 一个视图,可以带有参数:将使用urlresolvers.reverse 来反向解析名称
- 一个绝对的或相对的URL,将原封不动的作为重定向的位置。
默认返回一个临时的重定向;传递permanent=True 可以返回一个永久的重定向。
你可以用多种方式使用redirect() 函数。
传递一个具体的ORM对象(了解即可)
将调用具体ORM对象的get_absolute_url() 方法来获取重定向的URL:
from django.shortcuts import redirect
def my_view(request):
...
object = MyModel.objects.get(...)
return redirect(object)
传递一个视图的名称
def my_view(request):
...
return redirect('some-view-name', foo='bar')
传递要重定向到的一个具体的网址
def my_view(request):
...
return redirect('/some/url/')
当然也可以是一个完整的网址
def my_view(request):
...
return redirect('http://example.com/')
默认情况下,redirect() 返回一个临时重定向。以上所有的形式都接收一个permanent 参数;如果设置为True,将返回一个永久的重定向:
def my_view(request):
...
object = MyModel.objects.get(...)
return redirect(object, permanent=True)
扩展阅读:
临时重定向(响应状态码:302)和永久重定向(响应状态码:301)对普通用户来说是没什么区别的,它主要面向的是搜索引擎的机器人。
A页面临时重定向到B页面,那搜索引擎收录的就是A页面。
A页面永久重定向到B页面,那搜索引擎收录的就是B页面。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· Linux系列:如何用 C#调用 C方法造成内存泄露
· AI与.NET技术实操系列(二):开始使用ML.NET
· 无需6万激活码!GitHub神秘组织3小时极速复刻Manus,手把手教你使用OpenManus搭建本
· C#/.NET/.NET Core优秀项目和框架2025年2月简报
· 什么是nginx的强缓存和协商缓存
· 一文读懂知识蒸馏
· Manus爆火,是硬核还是营销?