
Python基础知识-06-集合内存布尔False
1、判断一个字符串中是否有敏感字符?

#str: m_str="我叫魔降风云变" if "魔" in m_str: #判断指定字符是否在某个字符串中 print("含敏感字符") ---------结果: 含敏感字符 #list/tuple: 方法一:for循环 char_list=["mcw","xiaoma","xiaxiao"] content=input("请输入内容:") success=False #什么时候用success这种标志,前面还有个message的类似的 for i in char_list: #判断字符串是否在指定列表中 if i==content: success=True
break
if success: print("包含敏感字符") ------------结果: 请输入内容:mcw 存在敏感字符 方法二:in char_list=["mcw","xiaoma","xiaxiao"] content=input("请输入内容:") if content in char_list: print("存在敏感字符") -----------结果: 请输入内容:mcw 存在敏感字符
#dic
v = {'k1':'v1','k2':'v2','k3':'v3'}
# 默认按照键判断,即:判断x是否是字典的键。
if 'x' in v:
print(True)
# 请判断:k1 是否在其中?
if 'k1' in v: #判断是否是字典的键
print(True)
# 请判断:v2 是否在其中?
# 方式一:循环判断
flag = '不存在'
for i in v.values(): #判断是否是字典的值
if i == 'v2':
flag = '存在'
print(flag)
# 方式二:
if 'v2' in list(v.values()): # 强制转换成列表 ['v1','v2','v3']
print(True)
# 请判断:k2:v2 是否在其中?
value = v.get('k2') #判断键值对是否在字典。先确定键是否存在,再确定值是否相等
if value == 'v2':
print('存在')
else:
print('不存在')
2、集合
集合(set)是一个无序的不重复元素序列。
可以使用大括号 { } 或者 set() 函数创建集合,注意:创建一个空集合必须用 set() 而不是 { },因为 { } 是用来创建一个空字典。
2.1创建集合
创建格式:
parame = {value01,value02,...} 或者 set(value)
set={"mcw","xiaoma","xiaoma",1,True} print(set) ------------------结果: {'mcw', 'xiaoma', 1} #集合有去重功能,每次执行一次,元素排序发生改变,说明集合是无序的.集合里面元素 0 FALSE ; 1 Ture 算是重复值,也会去重
>>> set={"mcw","xiaoma","xiaoma",1,True}
>>> "mcw" in set #快速判断元素是否在集合内
True
>>> "xiao" in set
False
mcw=set() #定义空集合,空集合布尔值为False
print(mcw,bool(mcw))
-----------结果:
set() False
2.2集合独有功能 -添加
集合.add(集合元素)
>>> set={"mcw",1,True,(1,2)} >>> set.add("xiaoma") >>> print(set) {'mcw', 1, 'xiaoma', (1, 2)}
集合.update(集合,列表等等)
>>> set={"mcw",1,True,(1,2)} >>> set.update({"mcw","xiaoma"}) #update重复的不管,没有的添加进集合 >>> print(set) {'mcw', 1, (1, 2), 'xiaoma'}
>>> set={"mcw",1,(1,2)}
>>> set.update([3,4])
>>> print(set)
{(1, 2), 1, 3, 4, 'mcw'}
2.3删除(集合无序不重复,所以不能用索引删除)
集合.discard(集合元素)
>>> set={"mcw",1,(1,2)} >>> set={"mcw",1,True,(1,2),"xiaoma","ming"} >>> set.discard((1,2)) #似乎删除的是单个 >>> print(set) {'mcw', 1, 'xiaoma', 'ming'}
2.4修改,因为无法定位,无法修改,能重新定义
2.5集合交并差以及集合运算
集合2的位置都可以是列表、元组,交集并集等都是生成新的集合,结果都是赋给新的集合


交集 交集=集合1.intersection({集合2}) >>> set={1,2} >>> jiao=set.intersection({2,3,4}) >>> print(jiao) {2} 并集 并集=集合1.union({集合2}) >>> set={1,2} >>> bing=set.union({2,3,4}) >>> print(bing) set([1, 2, 3, 4]) 差集 差集=集合1.difference(集合2) #自我注解:集合1与2比较,1在2中1有什么不同的元素。所以1有,2没有 $1与2的差集,1-2,就是在1中减去与2相同的元素后1中剩下的元素 set1={1,2} set2={2,3,4} cha=set1.difference(set2) print(cha) --------------结果: {1} 对称差集 #二者元素和再去掉二者共有的。 对称差集=集合1.symmetric_difference(集合2) set1={1,2} set2={2,3,4} duichencha=set1.symmetric_difference(set2) print(duichencha) --------------结果: {1, 3, 4}
集合运算
图片修改部分内容(更精确的描述):a与b的交集取反,不同时在a和b的两个集合的元素
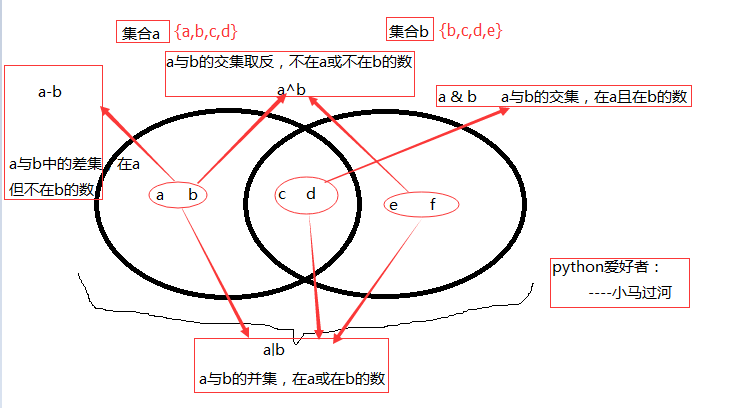
>>> a=set('abcd') >>> b=set('cdfe') >>> a {'d', 'b', 'c', 'a'} >>> a-b #集合a中包含而集合b中不包含的元素 $a与b中的差集,在a但不在b的元素 %%%a-b差集,就是在a中减去和b相同的元素剩下来的a的元素 {'a', 'b'} >>> a|b #集合a或b中包含的所有元素 $a与b的并集,在a或在b的元素 {'e', 'f', 'c', 'b', 'd', 'a'} >>> a & b # 集合a和b中都包含了的元素 $a与b的交集,在a且在b的元素 {'d', 'c'} >>> a^b # 不同时包含于a和b的元素 $a与b的交集取反,不同时在a和b的两个集合的元素 {'e', 'f', 'b', 'a'}
2.6#公共功能:只有len,for循环的公共功能
len
for循环
索引 无
步长 无
切片 无
删除 无
修改 无
set={1,2} print(len(set)) -------结果: 2 set={"mcw","xiaoma","ming"} for i in set: print(i) ----------结果: ming xiaoma mcw
2.7集合的嵌套
集合里面可以存放整型,布尔 字符串 None 等等


>>> print({1,"xiaoma",False,(1,2),None})
{False, 1, (1, 2), 'xiaoma', None}
不能放列表 报错 unhashable type 列表/集合/字典不能放入集合,也不能作为 字典的key(unhashable)
>>> set={{1,2},"xiaoma"} Traceback (most recent call last): File "<pyshell#34>", line 1, in <module> set={{1,2},"xiaoma"} TypeError: unhashable type: 'set' >>> set={[1,2],"xiaoma"} Traceback (most recent call last): File "<pyshell#35>", line 1, in <module> set={[1,2],"xiaoma"} TypeError: unhashable type: 'list' >>> set={{"name":"mcw"},"xiaoma"} Traceback (most recent call last): File "<pyshell#36>", line 1, in <module> set={{"name":"mcw"},"xiaoma"} TypeError: unhashable type: 'dict'
2.8hash
判断什么是否在列表里,for循环/in方法 遍历列表很慢
集合, 给元素计算hash值,并存放到hash表,hash值指向内存地址,效率比遍历列表快。
字典里面也会hash,hash键,并放在内存一个地址。根据key,直接定位找到value,速度快。在字典和集
合中查询是否存在某个元素,效率等价。
hash是怎么回事?
因为在内部会将值进行哈希算法并得到一个值(这个值映射到实际存储的内存地址),以后根据值作为索引,实现快速查找
2.9集合特殊情况(0 False ;1 Ture会去重)
集合里面元素 0 FALSE 1 Ture 是重复值,由于集合元素具有唯一性,所以会做去重的
字典里的键也具有唯一性,所以也会自动做去重操作
info ={1:2,True:3}
print(info)
---------结果:
{1: 3}
3、内存相关的东西 赋值和修改要区别开来,赋值(重新定义)是重新开辟内存,修改是原内存空间内的改变
3.1赋值(定义)和修改
定义两个列表,字符串,都是重新开辟内存地址。两块内存地址
>>> li1=["mcw","xiaoma"] >>> li2=["mcw","xiaoma"] >>> id(li1) 46000048 >>> id(li2) 45924224
定义一个变量,给变量重新赋值,重新开辟内存空间。原值内存地址如果没有指定它的那么就会成为垃圾,垃圾回收机制会回收内存地址
>>> li=["mcw","xiaoma"] >>> id(li) 45994232 >>> li=["ming","tian"] >>> id(li) 45924064
定义变量1,定义变量2=变量1,变量1有内存地址,变量2指向变量1的内存地址
>>> li=["mcw","xiaoma"] >>> li1=["mcw","xiaoma"] >>> li2=li1 >>> id(li1) 45999968 >>> id(li2) 45999968
v1=
v2=v1
v1=[原]
v2=v1
v1=[新]
print(v2) #[原]
思考,再对v2操作,结果?
-----------
v=[1,2,3]
valuse=[11,22,v]
v.append(9)
v发生变化,values发生变化,values里的v指向v的内存地址
v=999
values还是原来的地址,人眼看的v只是一个外部表现形式,其实内部执行时表现形式是内存地址
v只是内存地址指向吗?
什么时候成为垃圾,没有人指向它的时候(自我思考:那么有人指向的时候是不是有标记记录呢)
查看内存地址的函数:
id(变量)
3.2Python的内部缓冲机制实现性能优化
Python缓冲机制,为了提高性能的优化方案,常用的没有重新开辟内存空间,而是指向内存中已存在的
地址。Python数据的小数据池,常用字符串,浮点型等缓存
1、整型-5到256 缓存,不重新开辟
2、字符串: "f_*"*3 包含特殊字符串的会重新开辟内存。
列表,元组等就不是这样了。
--------
案例分析:
a=1
b=1 按理说应该重新开辟内存,但是Python为了提高性能,有缓存机制,-5到256,所以内存地址一样
a=1
b=a 内存地址一样
>>> a=-5 >>> b=-5 >>> id(a) 1357524016 >>> id(b) 1357524016 >>> a=-6 >>> b=-6 >>> id(a) 45638912 >>> id(b) 45639568 >>> a=256 >>> b=256 >>> id(a) 1357528192 >>> id(b) 1357528192 >>> a=257 >>> b=257 >>> id(a) 45639568 >>> id(b) 45638912
-------
3.3 问题:==和is的区别是什么
v1==v2 ==比较值是否相等 返回布尔值
v1 is v2 is比较的内存地址是否一致 返回布尔值
>>> v1=257 >>> v2=257 >>> bool(v1==v2) True >>> v1 is v2 False >>> id(v1) 45639136 >>> id(v2) 45639152
如果v1,v2的值符合Python缓冲机制里面的要求,那么v1==v2 ,v1 is v2 返回的是一样的
>>> v1=256 >>> v2=256 >>> bool(v1==v2) True >>> v1 is v2 True >>> id(v1) 1421687936 >>> id(v2) 1421687936
-----
4、布尔返回值是False的有哪些?
>>> print(bool(0)) #数字0 False >>> print(bool(())) #空元组 False >>> print(bool([])) #空列表 False >>> print(bool({})) #空字典 False >>> print(bool(None)) #None False >>> print(bool("")) #空字符串 False >>> print(bool(set())) #空集合 False
>>> bool(False) #False
False
#备注:3+5空
python 字节码和汇编语言是同级别的


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· Linux系列:如何用 C#调用 C方法造成内存泄露
· AI与.NET技术实操系列(二):开始使用ML.NET
· 无需6万激活码!GitHub神秘组织3小时极速复刻Manus,手把手教你使用OpenManus搭建本
· C#/.NET/.NET Core优秀项目和框架2025年2月简报
· 什么是nginx的强缓存和协商缓存
· 一文读懂知识蒸馏
· Manus爆火,是硬核还是营销?