xmind文件数据解析重构成mindmap可识别数据
【需求背景】
- 测试平台开发中,需要引入前端mindmap模块,进行在线xmind实时解析并前端展示
【卡点难点】
- 选取什么库进行xmind解析
- 如何转换成mindmap可以识别的数据
【xmind解析】
- 直接选用官方xmind-sdk-python,发现已经2018后停止维护了,解析最新版本报无法识别错误,弃用
- 直接去github上查最新维护的库,发现xmindparser库还可以使用,且方法简便易于上手,以下是内置api
is_xmind_zen #是否为xmind文件
xmind_to_dict #解析xmind成为字典
xmind_to_json #解析xmind成为json
xmind_to_xml #解析xmind成为xml
xmind_to_file #解析xmind成为json或xml,其余报错
点击查看代码
import xmindparser
path = r"xxx.xmind"
print(xmindparser.is_xmind_zen(path)) #判断是否xmind文件
print(xmindparser.xmind_to_dict(path)) #解析成字典
print(xmindparser.xmind_to_json(path)) #解析成json
print(xmindparser.xmind_to_xml(path)) #解析成xml
print(xmindparser.xmind_to_file(path,'json')) #解析成json
【转换mindmap数据】
- 通过查询mindmap的文档,数据与xmind文档解析出来的不一致
xmind解析数据结构如下:
点击查看代码
[
{
"title": "画布 1",
"topic": {
"title": "主题",
"topics": [
{
"title": "子题主",
"topics": [
{
"title": "孙主题",
"topics": [
{
"title": "孙孙主题",
"topics": [
{
"title": "叶子节点"
}
]
}
]
}
]
}
]
},
"structure": "org.xmind.ui.logic.right"
}
]
点击查看代码
[
{
"name": "主题",
"children": [
{
"name": "子题主",
"children": [
{
"name": "孙主题",
"children": [
{
"name": "孙孙主题",
"children": [
{
"name": "叶子节点",
}
],
}
],
}
],
}
],
}
]
【算法思路】
- 通过观察可知,两者只是key不同,需要title换成name,topics换成children即可
【方案一】
直接暴力replace替换
点击查看代码
data = xmindparser.xmind_to_dict(file)
res = [eval(str(data).replace('title','name').replace('topics','children'))[0]['topic']]
print(res)
【方案二】
由于层级不确定,使用递归更加优雅高级
点击查看代码
data = xmindparser.xmind_to_dict(path)
def recursion(data):
# 不存在topics则是叶子节点直接返回
if not data.get('topics',None):
return {'name':data['title']}
return {'name':data['title'],'children':[recursion(topic) for topic in data['topics']]}
res = [{'name':i['title'],'children':[recursion(i['topic'])]} for i in data]
print(res)
【总结】
这里利用递归方法解决了一个数据结构重构的算法,最终效果如图。
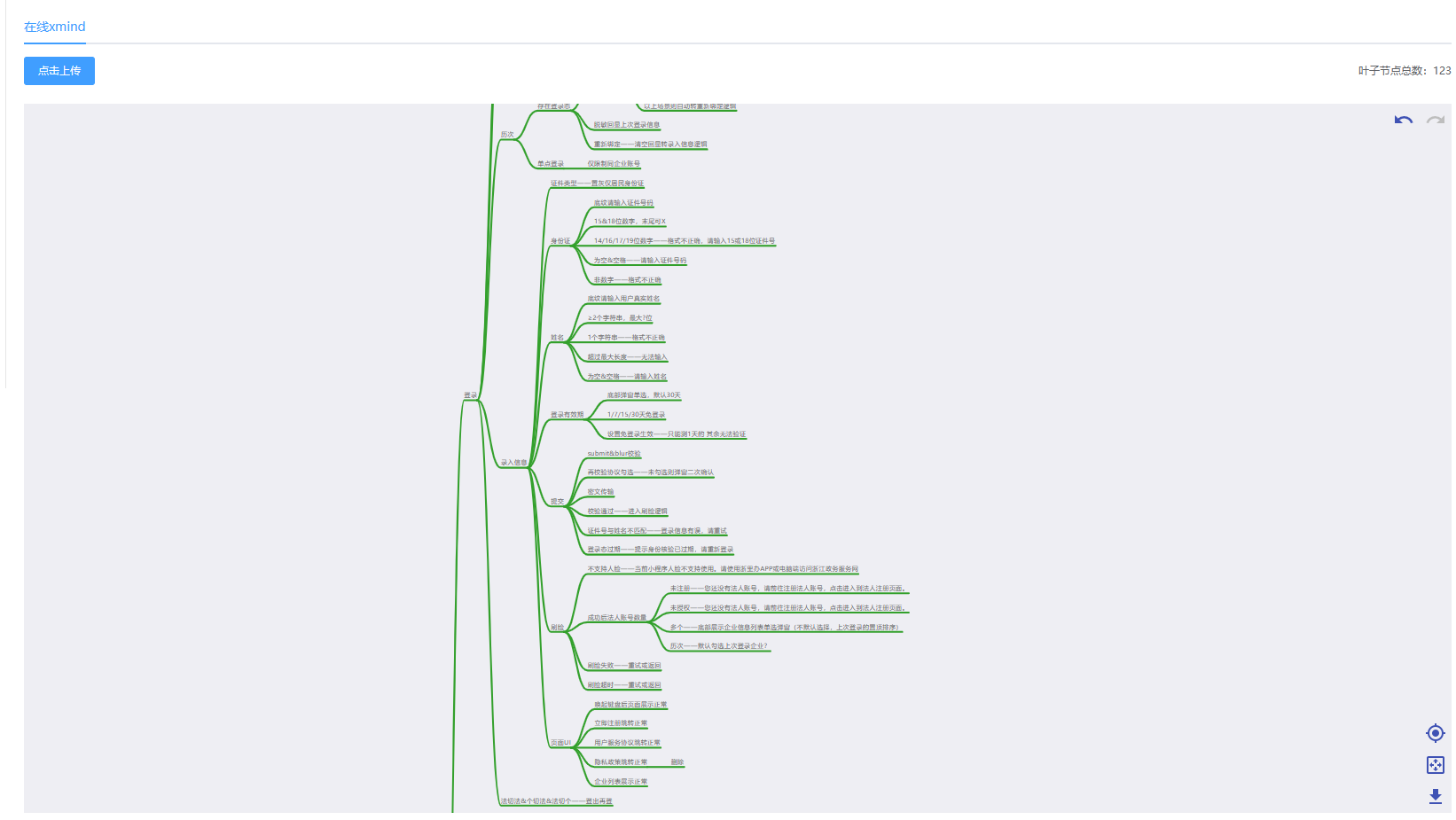
——每日进步亿点点,每年钱包鼓点点

 浙公网安备 33010602011771号
浙公网安备 33010602011771号