MySQL索引学习

MySQL官方对索引的定义为:索引是帮助MySQL高效获取数据的数据结构。
索引的本质:索引是数据结构,可以简单的理解为“排好序的快速查找B+树数据结构”
B+树:B代表平衡(balance)而不是二叉(binary)
检索原理:
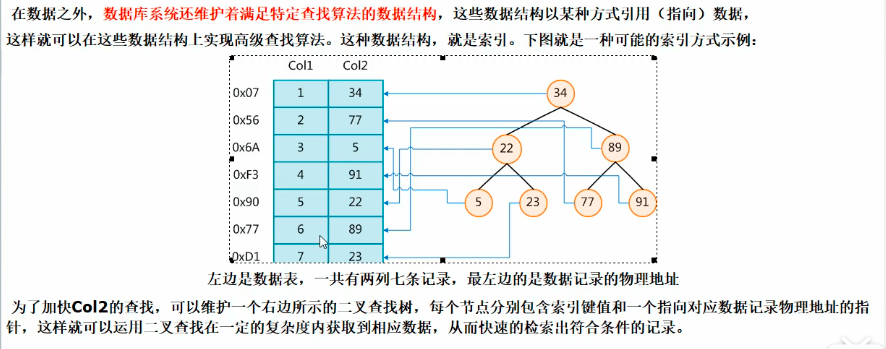
mysql索引结构:
BTREE:
B树(Balance Tree多路平衡查找树)
B+树(加强版多路平衡查找树)
为什么是B+树?
通过六步迭代演变:
1.全部遍历
2.Hash
找一次就能找到,而不是遍历,保证一次性。hash搞不定范围和排序查找。
加速查找速度的数据结构,常见的有两类:
(1)哈希,例如hashmap,查询/插入/修改/删除的平均时间复杂度都是O(1);
(2)树,例如平衡二叉搜索树,查询/插入/修改/删除的平均时间复杂度都是O(log2(n));
可以看到,不管是读请求,还是写请求,哈希类型的索引,都要比树型的索引更快一些,那为什么,索引结构要设计成树型呢?
想想范围/排序等其他sql条件:
哈希型的索引,时间复杂度会退化为O(n),而树型的“有序”特性,依然能保持O(log2(n))的高效率。
备注:InnoDB并不支持哈希索引。O(n)指查找n次。
3.二叉树
哈希比树快,索引结构为什么要设计成树型?

普通二叉树存在两种问题:
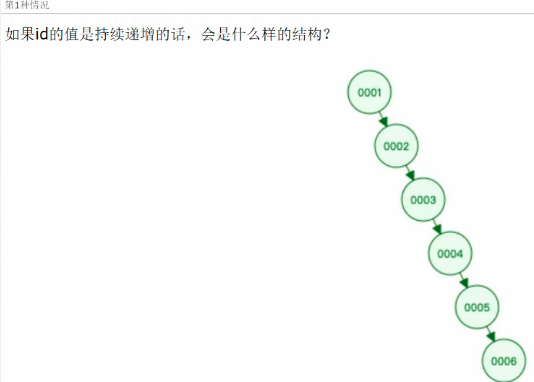
出现左倾或右倾问题

又是链表又是树
4.平衡二叉树(AVL)
从算法的数学逻辑来讲,二叉树的查找速度和比较次数都是最小的,那为什么选择BTREE?
只要是平衡二叉树,随着树的增加,根节点会变化,不会变左倾错误。
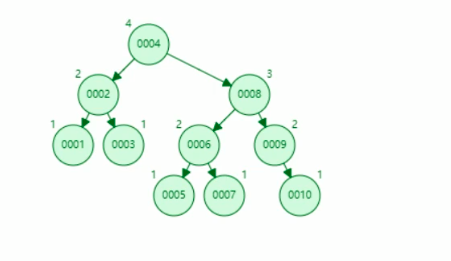
比如10,查找次数是4。如果数据量越多,树就会越高,查找次数就越多。数据量越多,树就会越高,遍历的次数就会越多,IO就会开销越大,导致系统性能下降。
遗留问题:树高问题导致磁盘IO过多。尽量从瘦高变矮胖。
5.B树
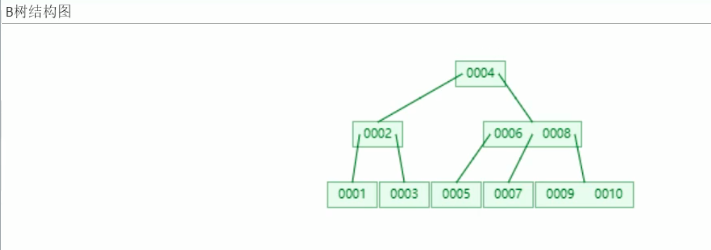
底层原理:
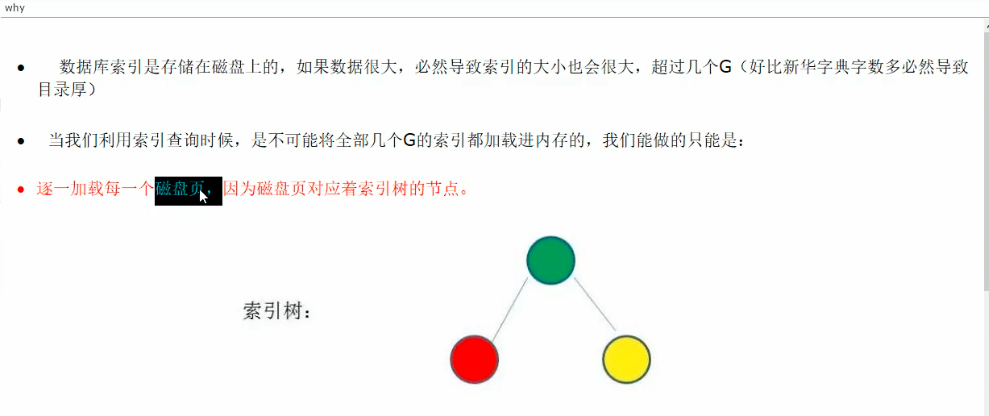
磁盘页/块:
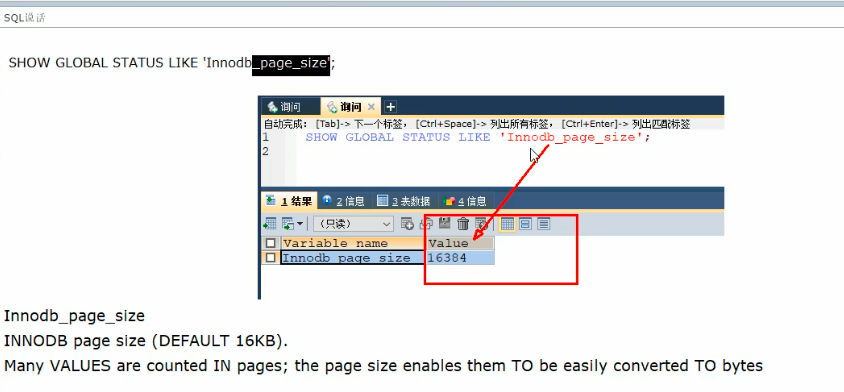
sql说话:
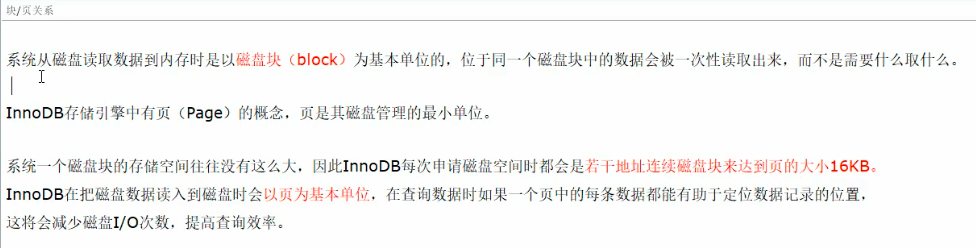
块/页关系:
B树检索原理:
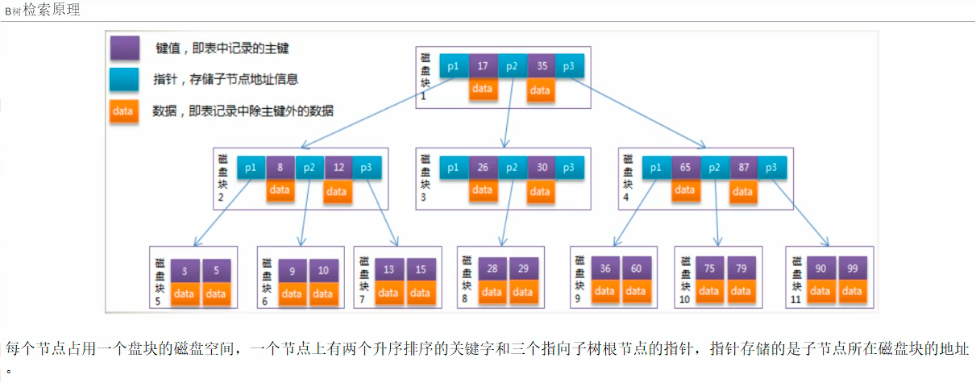

总结:B树比平衡二叉树少了一次IO操作
6.B+树:
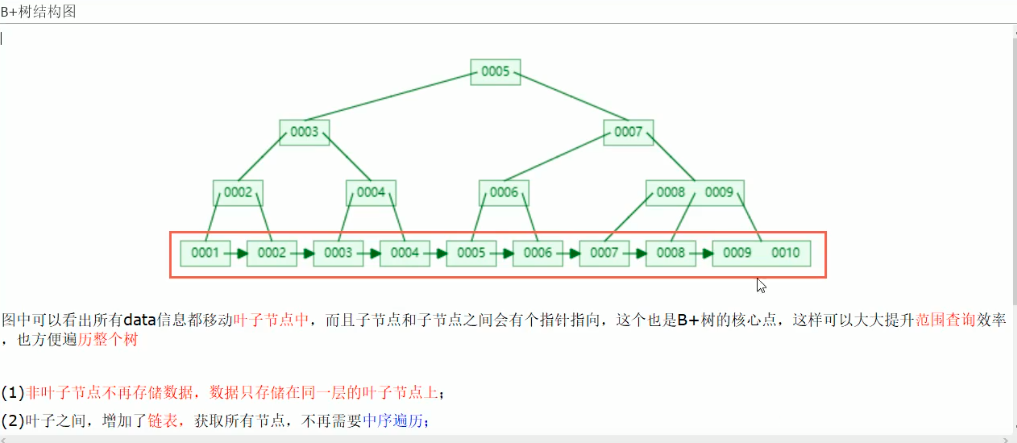

检索原理


B+树与B树的区别:
非叶子节点只存储键值信息
所有叶子节点之间都有一个链指针
数据记录都存放在叶子节点中
哪些情况下需要建立索引:
1.主键自动建立索引
2.频繁作为查询条件的字段应该创建索引
3.查询中与其他表关联的字段,外键关系建立索引
4.单键/组合索引的选择问题,组合索引性价比更高
5.查询中排序的字段,排序字段若通过索引去访问将大大提高排序速度
6.查询中统计或分组字段(分组包含排序,先排序后分组)
哪些情况不要创建索引:
1.表记录太少
2.经常增删改的表或字段
3.where条件里用不到的字段
4.过滤性不好的字段

 浙公网安备 33010602011771号
浙公网安备 33010602011771号