1.逻辑回归是怎么防止过拟合的?为什么正则化可以防止过拟合?(大家用自己的话介绍下)
答:算法上可以使用正则化;数据上可以加大样本量和通过特征选择减少特征量。
正则化是通过约束参数的范数使其不要太大,所以可以在一定程度上减少过拟合情况。
2.用logiftic回归来进行实践操作,数据不限。
实验代码:
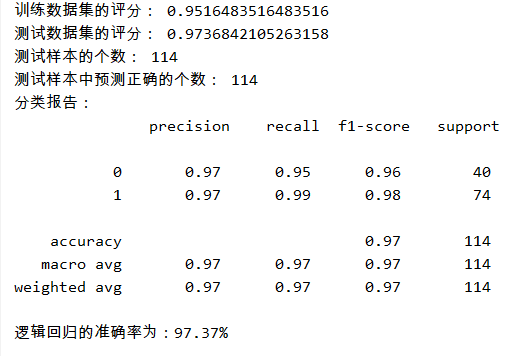
1 from sklearn.datasets import load_breast_cancer 2 from sklearn.model_selection import train_test_split 3 from sklearn.linear_model import LogisticRegression 4 from sklearn.metrics import classification_report 5 import numpy as np 6 7 cancer = load_breast_cancer() # 载入数据 8 X = cancer.data # 数据 9 y = cancer.target # 是否患病 10 X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2) # 划分训练集和测试集 11 12 model = LogisticRegression() # 模型的构建 13 model.fit(X_train, y_train) # 模型的训练 14 print('训练数据集的评分:', model.score(X_train, y_train)) 15 print('测试数据集的评分:', model.score(X_test, y_test)) 16 # 样本预测 17 y_pre = model.predict(X_test) 18 print('测试样本的个数:', y_test.shape[0]) 19 print('测试样本中预测正确的个数:', np.equal(y_pre, y_test).shape[0]) 20 # classification_report标签: 21 # 精确度:precision,正确预测为正的,占全部预测为正的比例,TP / (TP+FP) 22 # 召回率:recall,正确预测为正的,占全部实际为正的比例,TP / (TP+FN) 23 # F1-score:精确率和召回率的调和平均数,2 * precision*recall / (precision+recall) 24 # 同时还会给出总体的微平均值,宏平均值和加权平均值。 25 # 26 # 微平均值:micro average,所有数据结果的平均值 27 # 宏平均值:macro average,所有标签结果的平均值 28 # 加权平均值:weighted average,所有标签结果的加权平均值 29 print('分类报告:\n', classification_report(y_test, y_pre)) 30 print('逻辑回归的准确率为:{0:.2f}%'.format(model.score(X_test, y_test)*100))
实验结果: