20172318 2017-2018-2 《程序设计与数据结构》实验2报告
20172318 2017-2018-2 《程序设计与数据结构》实验2报告
课程:《程序设计与数据结构》
班级: 1723
姓名: 陆大岳
学号:20172318
实验教师:王志强
实验日期:2018年11月11日
必修/选修: 必修
1.实验内容
-
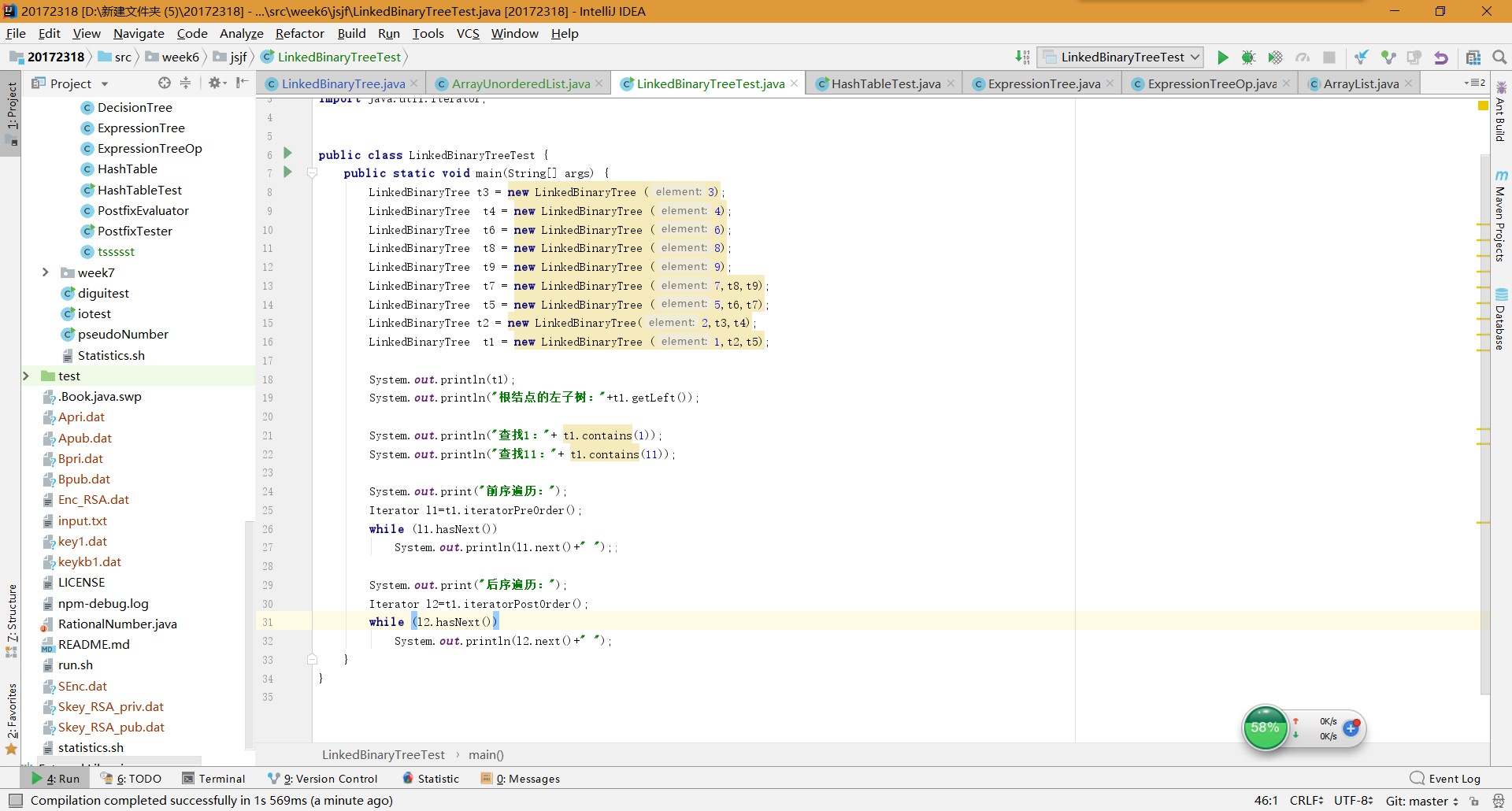
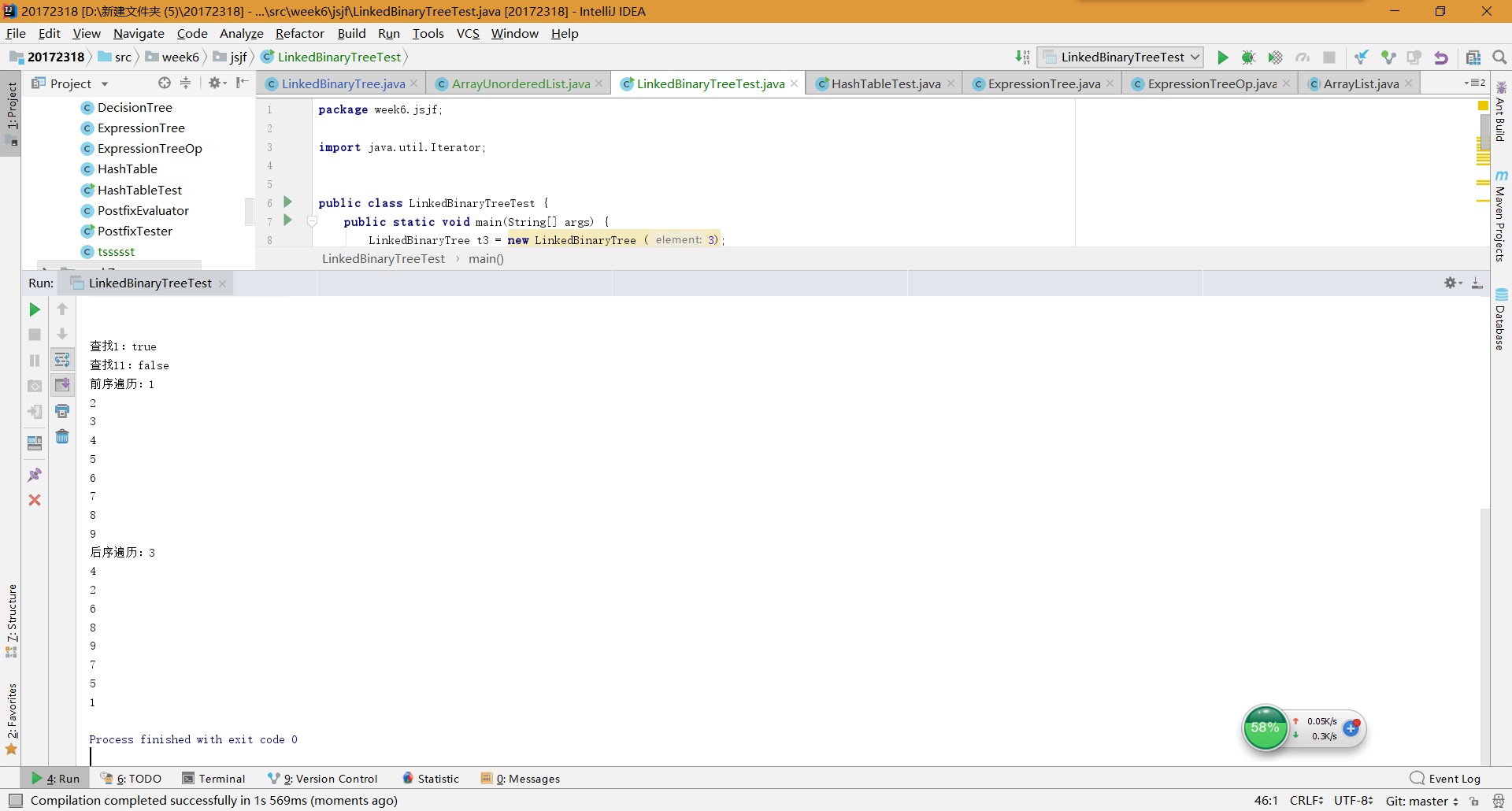
实验一:实现二叉树
参考教材p212,完成链树LinkedBinaryTree的实现(getRight,contains,toString,preorder,postorder)
用JUnit或自己编写驱动类对自己实现的LinkedBinaryTree进行测试 -
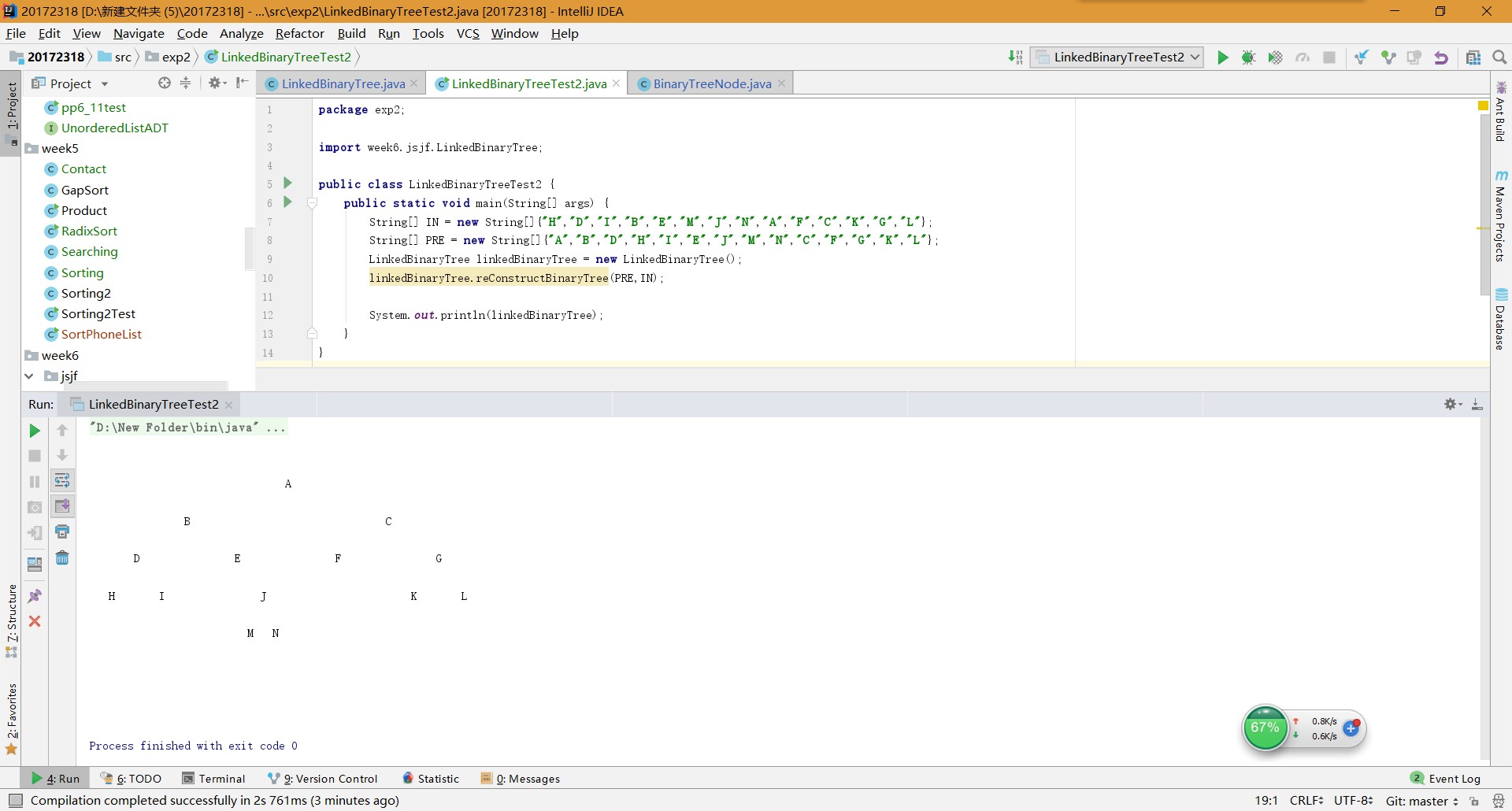
实验二:中序先序序列构造二叉树
基于LinkedBinaryTree,实现基于(中序,先序)序列构造唯一一棵二㕚树的功能,比如给出中序HDIBEMJNAFCKGL和后序ABDHIEJMNCFGKL,构造出附图中的树
用JUnit或自己编写驱动类对自己实现的功能进行测试 -
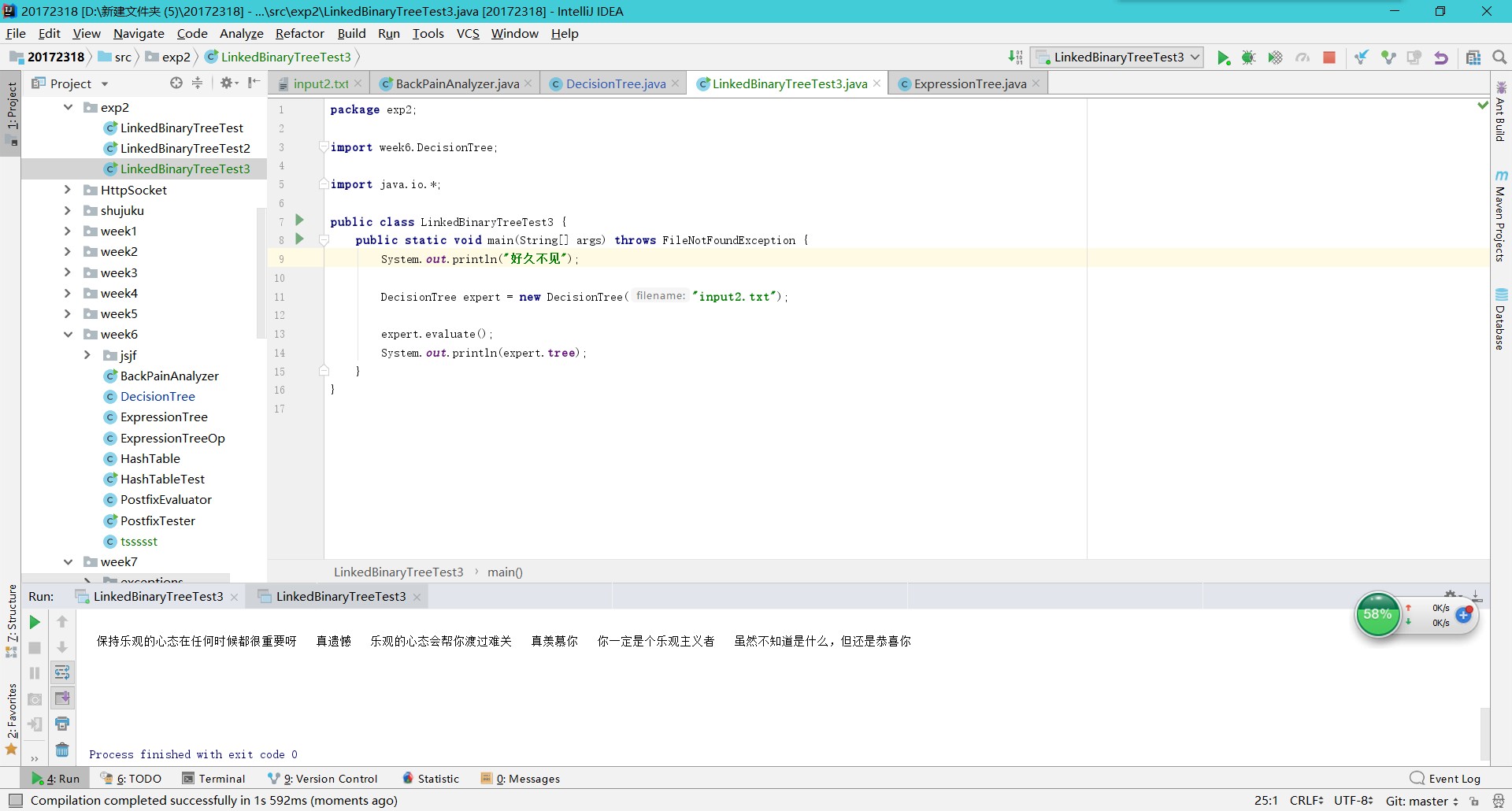
实验三:决策树
自己设计并实现一颗决策树 -
实验四:表达式树
输入中缀表达式,使用树将中缀表达式转换为后缀表达式,并输出后缀表达式和计算结果(如果没有用树,则为0分) -
实验五:二叉查找树
完成PP11.3 -
实验六:红黑树分析
参考http://www.cnblogs.com/rocedu/p/7483915.html对Java中的红黑树(TreeMap,HashMap)进行源码分析,并在实验报告中体现分析结果。
(C:\Program Files\Java\jdk-11.0.1\lib\src\java.base\java\util)
2. 实验过程及结果
第一部分 实现二叉树

第二部分 中序先序序列构造二叉树

第三部分 决策树


第四部分 表达式树



第五部分 二叉查找树

第六部分 红黑树分析
TreeMap 简介
TreeMap 是一个有序的key-value集合,它是通过红黑树实现的。
TreeMap 继承于AbstractMap,所以它是一个Map,即一个key-value集合。
TreeMap 实现了NavigableMap接口,意味着它支持一系列的导航方法。比如返回有序的key集合。
TreeMap 实现了Cloneable接口,意味着它能被克隆。
TreeMap 实现了java.io.Serializable接口,意味着它支持序列化。
TreeMap基于红黑树(Red-Black tree)实现。该映射根据其键的自然顺序进行排序,或者根据创建映射时提供的 Comparator 进行排序,具体取决于使用的构造方法。
TreeMap的基本操作 containsKey、get、put 和 remove 的时间复杂度是 log(n) 。
另外,TreeMap是非同步的。 它的iterator 方法返回的迭代器是fail-fastl的。
- TreeMap源码剖析
存储结构
TreeMap的排序是基于对key的排序实现的,它的每一个Entry代表红黑树的一个节点,Entry的数据结构如下:
static final class Entry<K,V> implements Map.Entry<K,V> {
// 键
K key;
// 值
V value;
// 左孩子
Entry<K,V> left = null;
// 右孩子
Entry<K,V> right = null;
// 父节点
Entry<K,V> parent;
// 当前节点颜色
boolean color = BLACK;
// 构造函数
Entry(K key, V value, Entry<K,V> parent) {
this.key = key;
this.value = value;
this.parent = parent;
}
。。。。。
}
构造方法
先来看下TreeMap的构造方法。TreeMap一共有4个构造方法。
1、无参构造方法
public TreeMap() {
comparator = null;
}
采用无参构造方法,不指定比较器,这时候,排序的实现要依赖key.compareTo()方法,因此key必须实现Comparable接口,并覆写其中的compareTo方法。
2、带有比较器的构造方法
public TreeMap(Comparator<? super K> comparator) {
this.comparator = comparator;
}
采用带比较器的构造方法,这时候,排序依赖该比较器,key可以不用实现Comparable接口。
3、带Map的构造方法
public TreeMap(Map<? extends K, ? extends V> m) {
comparator = null;
putAll(m);
}
该构造方法同样不指定比较器,调用putAll方法将Map中的所有元素加入到TreeMap中。putAll的源码如下:
// 将map中的全部节点添加到TreeMap中
public void putAll(Map<? extends K, ? extends V> map) {
// 获取map的大小
int mapSize = map.size();
// 如果TreeMap的大小是0,且map的大小不是0,且map是已排序的“key-value对”
if (size==0 && mapSize!=0 && map instanceof SortedMap) {
Comparator c = ((SortedMap)map).comparator();
// 如果TreeMap和map的比较器相等;
// 则将map的元素全部拷贝到TreeMap中,然后返回!
if (c == comparator || (c != null && c.equals(comparator))) {
++modCount;
try {
buildFromSorted(mapSize, map.entrySet().iterator(),
null, null);
} catch (java.io.IOException cannotHappen) {
} catch (ClassNotFoundException cannotHappen) {
}
return;
}
}
// 调用AbstractMap中的putAll();
// AbstractMap中的putAll()又会调用到TreeMap的put()
super.putAll(map);
}
显然,如果Map里的元素是排好序的,就调用buildFromSorted方法来拷贝Map中的元素,这在下一个构造方法中会重点提及,而如果Map中的元素不是排好序的,就调用AbstractMap的putAll(map)方法,该方法源码如下:
[java] view plain copy
public void putAll(Map<? extends K, ? extends V> m) {
for (Map.Entry<? extends K, ? extends V> e : m.entrySet())
put(e.getKey(), e.getValue());
}
很明显它是将Map中的元素一个个put(插入)到TreeMap中的,主要因为Map中的元素是无序存放的,因此要一个个插入到红黑树中,使其有序存放,并满足红黑树的性质。
4、带有SortedMap的构造方法
[java] view plain copy
public TreeMap(SortedMap<K, ? extends V> m) {
comparator = m.comparator();
try {
buildFromSorted(m.size(), m.entrySet().iterator(), null, null);
} catch (java.io.IOException cannotHappen) {
} catch (ClassNotFoundException cannotHappen) {
}
}
首先将比较器指定为m的比较器,这取决于生成m时调用构造方法是否传入了指定的构造器,而后调用buildFromSorted方法,将SortedMap中的元素插入到TreeMap中,由于SortedMap中的元素师有序的,实际上它是根据SortedMap创建的TreeMap,将SortedMap中对应的元素添加到TreeMap中。
插入删除
插入操作即对应TreeMap的put方法,put操作实际上只需按照二叉排序树的插入步骤来操作即可,插入到指定位置后,再做调整,使其保持红黑树的特性。put源码的实现:
public V put(K key, V value) {
Entry<K,V> t = root;
// 若红黑树为空,则插入根节点
if (t == null) {
// TBD:
// 5045147: (coll) Adding null to an empty TreeSet should
// throw NullPointerException
//
// compare(key, key); // type check
root = new Entry<K,V>(key, value, null);
size = 1;
modCount++;
return null;
}
int cmp;
Entry<K,V> parent;
// split comparator and comparable paths
Comparator<? super K> cpr = comparator;
// 找出(key, value)在二叉排序树中的插入位置。
// 红黑树是以key来进行排序的,所以这里以key来进行查找。
if (cpr != null) {
do {
parent = t;
cmp = cpr.compare(key, t.key);
if (cmp < 0)
t = t.left;
else if (cmp > 0)
t = t.right;
else
return t.setValue(value);
} while (t != null);
}
else {
if (key == null)
throw new NullPointerException();
Comparable<? super K> k = (Comparable<? super K>) key;
do {
parent = t;
cmp = k.compareTo(t.key);
if (cmp < 0)
t = t.left;
else if (cmp > 0)
t = t.right;
else
return t.setValue(value);
} while (t != null);
}
// 为(key-value)新建节点
Entry<K,V> e = new Entry<K,V>(key, value, parent);
if (cmp < 0)
parent.left = e;
else
parent.right = e;
// 插入新的节点后,调用fixAfterInsertion调整红黑树。
fixAfterInsertion(e);
size++;
modCount++;
return null;
}
这里的fixAfterInsertion便是节点插入后对树进行调整的方法
删除操作及对应TreeMap的deleteEntry方法,deleteEntry方法同样也只需按照二叉排序树的操作步骤实现即可,删除指定节点后,再对树进行调整即可。deleteEntry方法的实现源码如下:
// 删除“红黑树的节点p”
private void deleteEntry(Entry<K,V> p) {
modCount++;
size--;
if (p.left != null && p.right != null) {
Entry<K,V> s = successor (p);
p.key = s.key;
p.value = s.value;
p = s;
}
Entry<K,V> replacement = (p.left != null ? p.left : p.right);
if (replacement != null) {
replacement.parent = p.parent;
if (p.parent == null)
root = replacement;
else if (p == p.parent.left)
p.parent.left = replacement;
else
p.parent.right = replacement;
p.left = p.right = p.parent = null;
if (p.color == BLACK)
fixAfterDeletion(replacement);
} else if (p.parent == null) {
root = null;
} else {
if (p.color == BLACK)
fixAfterDeletion(p);
if (p.parent != null) {
if (p == p.parent.left)
p.parent.left = null;
else if (p == p.parent.right)
p.parent.right = null;
p.parent = null;
}
}
}
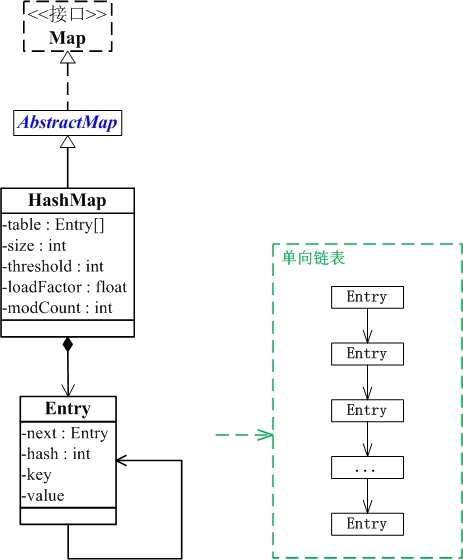
HashMap简介
HashMap 是一个散列表,它存储的内容是键值对(key-value)映射。
HashMap 继承于AbstractMap,实现了Map、Cloneable、java.io.Serializable接口。
HashMap 的实现不是同步的,这意味着它不是线程安全的。它的key、value都可以为null。此外,HashMap中的映射不是有序的。
HashMap 的实例有两个参数影响其性能:“初始容量” 和 “加载因子”。容量 是哈希表中桶的数量,初始容量 只是哈希表在创建时的容量。加载因子 是哈希表在其容量自动增加之前可以达到多满的一种尺度。当哈希表中的条目数超出了加载因子与当前容量的乘积时,则要对该哈希表进行 rehash 操作(即重建内部数据结构),从而哈希表将具有大约两倍的桶数。
通常,默认加载因子是 0.75, 这是在时间和空间成本上寻求一种折衷。加载因子过高虽然减少了空间开销,但同时也增加了查询成本(在大多数 HashMap 类的操作中,包括 get 和 put 操作,都反映了这一点)。在设置初始容量时应该考虑到映射中所需的条目数及其加载因子,以便最大限度地减少 rehash 操作次数。如果初始容量大于最大条目数除以加载因子,则不会发生 rehash 操作。
- HashMap实现原理
HashMap的主干是一个Entry数组。Entry是HashMap的基本组成单元,每一个Entry包含一个key-value键值对。
transient Entry<K,V>[] table = (Entry<K,V>[]) EMPTY_TABLE;
Entry是HashMap中的一个静态内部类。代码如下
static class Entry<K,V> implements Map.Entry<K,V> {
final K key;
V value;
Entry<K,V> next;//存储指向下一个Entry的引用,单链表结构
int hash;//对key的hashcode值进行hash运算后得到的值,存储在Entry,避免重复计算
/**
* Creates new entry.
*/
Entry(int h, K k, V v, Entry<K,V> n) {
value = v;
next = n;
key = k;
hash = h;
}
其他几个重要字段
//实际存储的key-value键值对的个数
transient int size;
//阈值,当table == {}时,该值为初始容量(初始容量默认为16);当table被填充了,也就是为table分配内存空间后,threshold一般为 capacity*loadFactory。HashMap在进行扩容时需要参考threshold,后面会详细谈到
int threshold;
//负载因子,代表了table的填充度有多少,默认是0.75
final float loadFactor;
//用于快速失败,由于HashMap非线程安全,在对HashMap进行迭代时,如果期间其他线程的参与导致HashMap的结构发生变化了(比如put,remove等操作),需要抛出异常ConcurrentModificationException
transient int modCount;
put操作的实现
public V put(K key, V value) {
//如果table数组为空数组{},进行数组填充(为table分配实际内存空间),入参为threshold,此时threshold为initialCapacity 默认是1<<4(24=16)
if (table == EMPTY_TABLE) {
inflateTable(threshold);
}
//如果key为null,存储位置为table[0]或table[0]的冲突链上
if (key == null)
return putForNullKey(value);
int hash = hash(key);//对key的hashcode进一步计算,确保散列均匀
int i = indexFor(hash, table.length);//获取在table中的实际位置
for (Entry<K,V> e = table[i]; e != null; e = e.next) {
//如果该对应数据已存在,执行覆盖操作。用新value替换旧value,并返回旧value
Object k;
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}
modCount++;//保证并发访问时,若HashMap内部结构发生变化,快速响应失败
addEntry(hash, key, value, i);//新增一个entry
return null;
}
inflateTable方法
private void inflateTable(int toSize) {
int capacity = roundUpToPowerOf2(toSize);//capacity一定是2的次幂
threshold = (int) Math.min(capacity * loadFactor, MAXIMUM_CAPACITY + 1);//此处为threshold赋值,取capacity*loadFactor和MAXIMUM_CAPACITY+1的最小值,capaticy一定不会超过MAXIMUM_CAPACITY,除非loadFactor大于1
table = new Entry[capacity];
initHashSeedAsNeeded(capacity);
}
inflateTable这个方法用于为主干数组table在内存中分配存储空间,通过roundUpToPowerOf2(toSize)可以确保capacity为大于或等于toSize的最接近toSize的二次幂,比如toSize=13,则capacity=16;to_size=16,capacity=16;to_size=17,capacity=32.
private static int roundUpToPowerOf2(int number) {
// assert number >= 0 : "number must be non-negative";
return number >= MAXIMUM_CAPACITY
? MAXIMUM_CAPACITY
: (number > 1) ? Integer.highestOneBit((number - 1) << 1) : 1;
}
roundUpToPowerOf2中的这段处理使得数组长度一定为2的次幂,Integer.highestOneBit是用来获取最左边的bit(其他bit位为0)所代表的数值.
hash函数
//这是一个神奇的函数,用了很多的异或,移位等运算,对key的hashcode进一步进行计算以及二进制位的调整等来保证最终获取的存储位置尽量分布均匀
final int hash(Object k) {
int h = hashSeed;
if (0 != h && k instanceof String) {
return sun.misc.Hashing.stringHash32((String) k);
}
h ^= k.hashCode();
h ^= (h >>> 20) ^ (h >>> 12);
return h ^ (h >>> 7) ^ (h >>> 4);
}
以上hash函数计算出的值,通过indexFor进一步处理来获取实际的存储位置
/**
* 返回数组下标
*/
static int indexFor(int h, int length) {
return h & (length-1);
}
h&(length-1)保证获取的index一定在数组范围内,
HashMap和TreeMap比较
(1)HashMap:适用于在Map中插入、删除和定位元素。
(2)Treemap:适用于按自然顺序或自定义顺序遍历键(key)。
(3)HashMap通常比TreeMap快一点(树和哈希表的数据结构使然),建议多使用HashMap,在需要排序的Map时候才用TreeMap.
(4)HashMap 非线程安全 TreeMap 非线程安全
(5)HashMap的结果是没有排序的,而TreeMap输出的结果是排好序的。
3. 实验过程中遇到的问题和解决过程
问题1:
问题1解决方案:将树的实现顺序更改一下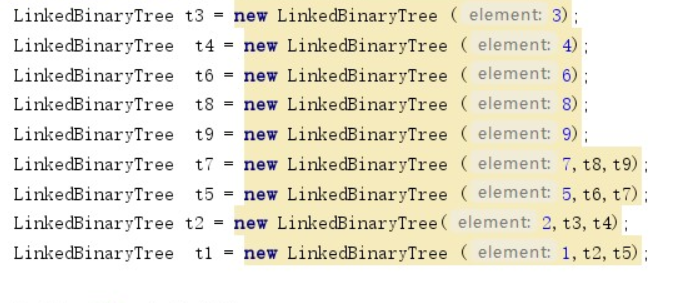

 浙公网安备 33010602011771号
浙公网安备 33010602011771号