结合源码学习 TCP/IP 协议栈(1)
-
前言
课本上计网基本上是纯理论的东西 + 一坨考研真题,学完只能理解一个大致架构和少许的数学应用题解题能力。我还是认为作为一个网络安全专业的学生,在学习这些底层知识的时候,最好还是能从代码出发,一方面不看代码永远不会理解漏洞的本质,另一方面不会写代码的安全人员,他的成长也只能是从 jb 小子 -> jb 老子。
主要参考自 https://github.com/EmbedHacker/level-ip 这个项目,同类的还有很多,只是比较方便的找到了原作者的 blog 和国内的教程(参考文献第一个)。
-
整体架构
该项目模拟了一个 linux 内核的 tcp 协议栈
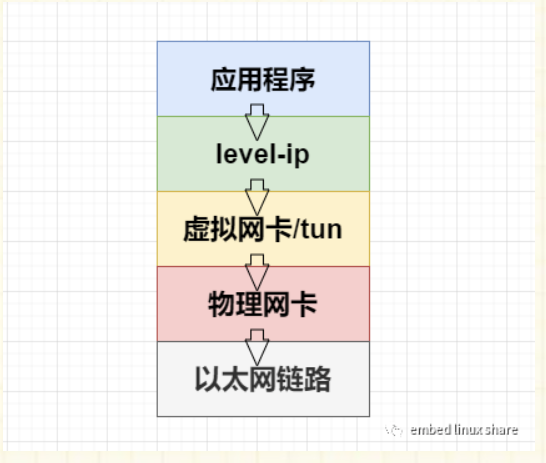
其中, level-ip 是运行在 linux 用户空间的协议栈,也是我们主要实现的部分,虚拟网卡/tun 则是用了 Linux 自带的 TUN/TAP。
tun是网络层的虚拟网络设备,可以收发第三层数据报文包,如IP封包,因此常用于一些点对点IP隧道,例如OpenVPN,IPSec等。 tap是链路层的虚拟网络设备,等同于一个以太网设备,它可以收发第二层数据报文包,如以太网数据帧。Tap最常见的用途就是做为虚拟机的网卡,因为它和普通的物理网卡更加相近,也经常用作普通机器的虚拟网卡。 -
环境搭建及测试
本地 WSL2 的 Ubuntu20.04 编译报错,换成 18.04
git clone https://github.com/EmbedHacker/level-ip sudo apt install libcab-dev make all-
以太网 -> 物理网卡
ping 一下百度确保能连网就行
-
物理网卡 -> 虚拟网卡
利用 iptables 设置 netfilter 过滤规则实现,首先设置 linux 的路由器功能
sudo sysctl -w net.ipv4.ip_forward=1设置防火墙,允许虚拟网卡的数据包通过
sudo iptables -I INPUT --source 10.0.0.0/24 -j ACCEPT配置 NAT,修改发送到互联网的数据包的源地址为 ens33(物理网卡)
sudo iptables -t nat -I POSTROUTING --out-interface enp0s3 -j MASQUERADE设置物理网卡和虚拟网卡的相互转发
#物理网卡转发虚拟网卡 sudo iptables -I FORWARD --in-interface enp0s3 --out-interface tap0 -j ACCEPT #虚拟网卡转发物理网卡 sudo iptables -I FORWARD --in-interface tap0 --out-interface enp0s3 -j ACCEPT -
虚拟网卡 -> level-ip
通过 tun/tap驱动实现,位于 /dev/net/tun,具体原理。。。和项目没什么关系,略了。
-
level-ip -> 应用程序
用我们自己写的 .so 文件(动态库)来接管应用程序中调用的在 linux 内核中的 Socket API,让数据走 level-ip。
运行协议栈:
./lvl-ip在另一个端口运行应用程序
cd tools ./level-ip ../apps/curl/curl www.baidu.com 80成功返回抓取结果。
-
-
向下封装虚拟网卡
TCP / IP 协议栈的实现过程可以看作层层加壳和层层脱壳,每向下一层就要加上下层对应的头部,每向上一层就会把下层的头部脱去。在这个项目中,首先写要实现的 level-ip 和下面的虚拟网卡这一层的交互。
首先看 src\tuntap_if.c 文件,找到初始化的 tun_init
void tun_init() { dev = calloc(10, 1); tun_fd = tun_alloc(dev); if (set_ip_up(dev) != 0) { print_err("ERROR when setting up if\n"); } if (set_if_route(dev, taproute) != 0) { print_err("ERROR when setting route for if\n"); } if (set_if_address(dev, tapaddr) != 0) { print_err("ERROR when setting addr for if\n"); } }给 dev 开辟了块内存,然后跟进一下 tun_alloc,首先要打开 tun 文件(linux 一切皆文件,拿到文件描述符才能操作),然后是设置了网卡的属性,其中:
IFF_TUN: 创建一个点对点设备 IFF_TAP: 创建一个以太网设备 IFF_NO_PI: 不包含包信息,默认的每个数据包当传到用户空间时,都将包含一个附加的包头来保存包信息这里选择创建了一个 TAP 设备用于和上层的 TCP/IP 协议通信,而设置 IFF_NO_PI 属性就不需要将数据包的信息提前预置到以太网帧中,而是我们手动加一个头用于上下层的识别。
static int tun_alloc(char *dev) { struct ipreq ifr; int fd, err; if( (fd = open("/dev/net/tun", O_RDWR)) < 0 ) { perror("Cannot open TUN/TAP dev\n" "Make sure one exists with " "'$ mknod /dev/net/tap c 10 200'"); exit(1); } CLEAR(ifr); /* Flags: IFF_TUN - TUN device (no Ethernet headers) * IFF_TAP - TAP device * * IFF_NO_PI - Do not provide packet information */ ifr.ifr_flags = IFF_TAP | IFF_NO_PI; if( *dev ) { strncpy(ifr.ifr_name, dev, IFNAMSIZ); } if ( (err = ioctl(fd, TUNSETIFF, (void *) &ifr)) < 0 ) { perror("ERR: Could not ioctl tun"); close(fd); return err; } // ioctl 是系统库函数,用于配置一些虚拟网卡属性 strcpy(dev, ifr.ifr_name); return fd; }除此意外这个文件中的 tun_read 和 tun_write 就是对 read 和 write 做了简单的封装,方便直接操作 tun。
int tun_read(char *buf, int len) { return read(tun_fd, buf, len); } int tun_write(char *buf, int len) { return write(tun_fd, buf, len); } -
向下封装以太网
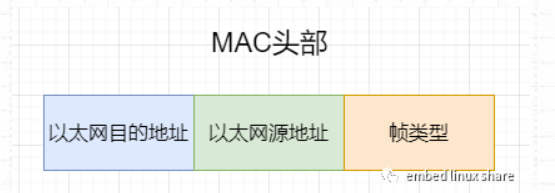
在上面那张结构图中,虚拟网卡的已经封装好了,物理网卡没法操作不用管,接着就是封装下面的数据链路层,也就是以太网头部(mac头部),结构:
看一下代码中的实现:
struct eth_hdr { uint8_t dmac[6]; // 目标主机物理地址 uint8_t smac[6]; // 源主机物理地址 uint16_t ethertype; // 判断标志,用于区分 ip 和 arp 包 uint8_t payload[]; // 变长数组 } __attribute__((packed)); // 设置结构体按照实际占用字节数进行对齐同时,一台主机可能有多块网卡,在收发数据流的过程中,还要根据包中的地址信息,确定当前的收到的数据流该由哪块网卡处理,网卡的具体信息在 level-ip 中的 include\netdev.h 中实现:
struct netdev { uint32_t addr; // 本地网卡的 ip 地址 uint8_t addr_len; // 地址长度 uint8_t hwaddr[6]; // 本地网卡的物理地址 uint32_t mtu; // 网卡的最大传输单元 };接着看一下这个网卡管理的初始化
void netdev_init(char *addr, char *hwaddr) { loop = netdev_alloc("127.0.0.1", "00:00:00:00:00:00", 1500); netdev = netdev_alloc("10.0.0.4", "00:0c:29:6d:50:25", 1500); }自定义了 ip 地址和 mac 地址,接着跟进 netdev_alloc,至此网卡初始化完成。
static struct netdev *netdev_alloc(char *addr, char *hwaddr, uint32_t mtu) { struct netdev *dev = malloc(sizeof(struct netdev)); dev->addr = ip_parse(addr); // ip 十进制->二进制格式 sscanf(hwaddr, "%hhx:%hhx:%hhx:%hhx:%hhx:%hhx", &dev->hwaddr[0], &dev->hwaddr[1], &dev->hwaddr[2], &dev->hwaddr[3], &dev->hwaddr[4], &dev->hwaddr[5]); // 把 mac 地址填充到 netdev 中 dev->addr_len = 6; dev->mtu = mtu; return dev; }接着就开始写收发数据的操作,首先是发送接口 netdev_transmit
int netdev_transmit(struct sk_buff *skb, uint8_t *dst_hw, uint16_t ethertype) { struct netdev *dev; struct eth_hdr *hdr; // 即将填充的头部 int ret = 0; dev = skb->dev; // sk_buff 结构体用于记录待发送的数据帧和网卡型号 skb_push(skb, ETH_HDR_LEN); // ETH_HDR_LEN是 eth_hdr 结构体大小,把 sk_buff 前移 ETH_HDR_LEN 个长度,空出位置添加 eth_hdr hdr = (struct eth_hdr *)skb->data; memcpy(hdr->dmac, dst_hw, dev->addr_len); memcpy(hdr->smac, dev->hwaddr, dev->dadr_len); hdr->ethertype = htons(ethertype); eth_dbg("out", hdr); // 将信息填充到数据帧头部 ret = tun_write((char *)skb->data, skb->len); // 调用 write 相当于发送数据了 return ret; }然后是数据流的接收 netdev_receive,
static int netdev_receive(struct sk_buff *skb) { struct eth_hdr *hdr = eth_hdr(skb); // 获取以太网头部数据 eth_dbg("in", hdr); switch (hdr->ethertype) { // 根据不同的头部进行不同的处理 case ETH_P_ARP: arp_rcv(skb); break; case ETH_P_IP: ip_rcv(skb); break; case ETH_P_IPV6: default: printf("Unsupported ethertype %x\n", hdr->ethertype); free_skb(skb); break; } return 0; }看一下整个接收数据的过程,其中在 netdev_rx_loop 中,首先实例化一个 skb 结构体,用 read 函数将接收的数据存到 skb 结构体中,然后调用 netdev_receive 解析。netdev_rx_loop 直接是在 main 函数中创建的线程。
void *netdev_rx_loop() { while (running) { struct sk_buff *skb = alloc_skb(BUFLEN); if (tun_read((char *)skb->data, BUFLEN) < 0) { perror("ERR: Read from tun_fd"); free_skb(skb); return NULL; } netdev_receive(skb); } return NULL; } -
ARP 相关实现
ARP协议是用来将目标主机的IP地址转换为对应的以太网(MAC)地址的,要实现通过发起 ARP 查询帧,在本地建立 IP 地址和 MAC 的映射关系,同样也要实现应答其他的 ARP 查询。ARP 数据帧位于以太网数据帧上一次,报文结构如下:

硬件协议:以太网 1 协议类型:mac -> ip 0x0800 硬件地址长度:mac 地址长度 6 协议地址长度:ip 地址长度 6 OP:1 为 ARP 请求,2 为 ARP 应答ARP 报文结构的实现,结构体中的变量和上面图中的每个字段一一对应:
struct arp_hdr { uint16_t hwtype; uint16_t protype; uint8_t hwsize; uint8_t prosize; uint16_t opcode; unsigned char data[]; } __attribute__((packed)); struct arp_ipv4 { unsigned char smac[6]; uint32_t sip; unsigned char dmac[6]; uint32_t dip; } __attribute__((packed));ARP 数据帧的发送接口由 arp_request 函数实现
int arp_request(uint32_t sip, uint32_t dip, struct netdev *netdev) { struct sk_buff *skb; struct arp_hdr *arp; struct arp_ipv4 *payload; int rc = 0; skb = arp_alloc_skb(); if (!skb) return -1; skb->dev = netdev; // 选择网卡 payload = (struct arp_ipv4 *) skb_push(skb, ARP_DATA_LEN); // 向前移动 arp_ipv4 大小的位置,也就是上图后四个字段,先解析这几个,现在 payload 相当于一个指向 arp_ipv4 的指针 memcpy(payload->smac, netdev->hwaddr, netdev->addr_len); payload->sip = sip; memcpy(payload->dmac, broadcast_hw, netdev->addr_len); payload->dip = dip; // 填充这 4 个字段 arp = (struct arp_hdr *) skb_push(skb, ARP_DATA_LEN); // 同样的道理,前移 arp_hdr 大小,现在的 arp 是指向 arp_hdr 的指针 arp_dbg("req", arp); arp->opcode = htons(ARP_REQUEST); arp->hwtype = htons(ARP_ETHERNET); arp->protype = htons(ETH_P_IP); arp->hwsize = netdev->addr_len; arp->prosize = 4; // 同样进行填充 arpdata_dbg("req", payload); payload->sip = htonl(payload->sip); payload->dip = htonl(payload->dip); // 做一下格式转换 rc = netdev_transmit(skb, broadcast_hw, ETH_P_ARP); // 进一步构建以太网数据帧进行发送 free_skb(skb); return rc; }上面是发送了 arp 请求,接着写一个接口来接收 arp 请求
void arp_reply(struct sk_buff *skb, struct netdev *netdev) { struct arp_hdr *arphdr; struct arp_ipv4 *arpdata; arphdr = arp_hdr(skb); // 获取报文数据 skb_reserve(skb, ETH_HDR_LEN + ARP_HDR_LEN + ARP_DATA_LEN); // 接收了请求头(并处理) skb_push(skb, ARP_HDR_LEN + ARP_DATA_LEN); // 已经接收完了,可以跳过去了 arpdata = (struct arp_ipv4 *) arphdr->data; memcpy(arpdata->dmac, arpdata->smac, 6); arpdata->dip = arpdata->sip; memcpy(arpdata->smac, netdev->hwaddr, 6); arpdata->sip = netdev->addr; arphdr->opcode = ARP_REPLY; arp_dbg("reply", arphdr); arphdr->opcode = htons(arphdr->opcode); arphdr->hwtype = htons(arphdr->hwtype); arphdr->protype = htons(arphdr->protype); arpdata_dbg("reply", arpdata); arpdata->sip = htonl(arpdata->sip); arpdata->dip = htonl(arpdata->dip); // 解析 arp 报文头,分别存放在 arphdr 和 arpdata 中 skb->dev = netdev; // 用指定的网卡发送 netdev_transmit(skb, arpdata->dmac, ETH_P_ARP); // 收到之后回复一个相应 free_skb(skb); } -
编写 Socket 结构
socket 被翻译为套接字,实际上是应用层和传输层的一个抽象层,具体表现为应用层用户进程需要通过 socket 和 协议栈中的下层进行通讯和交互。
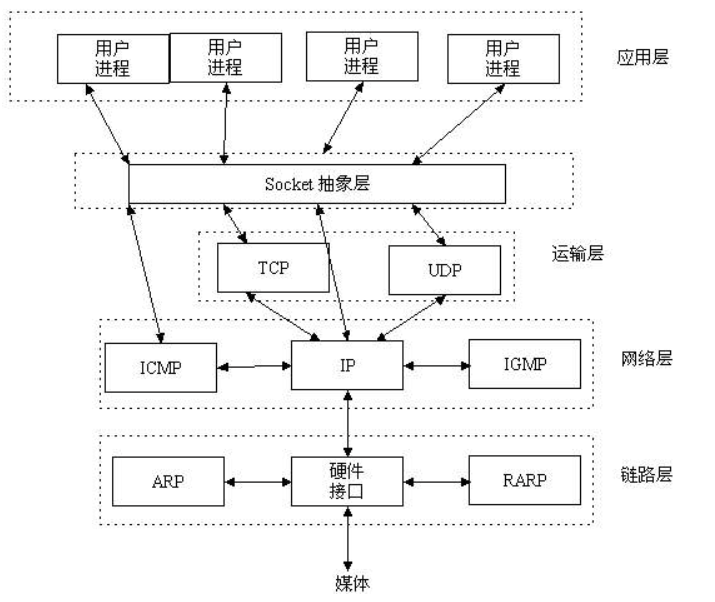
在 linux 下一切皆文件,对 socket 的操作也是通过文件读写实现的。
看一下套接字的格式(Linux 库中自带)
通用套接字:
struct sockaddr{ sa_family_t sa_family; /* 地址族. 16-bit*/ char sa_data[14]; /* 具体的地址值 112-bit */ };IPv4 套接字格式地址:
struct sockaddr_in { sa_family_t sin_family; /* 地址族. 16-bit*/ in_port_t sin_port; /* 端口 16-bit*/ struct in_addr sin_addr; /* 这里仅仅用作占位符,不做实际用处 */ unsigned char sin_zero[8]; };IPv6 套接字地址格式:
struct sockaddr_in6 { sa_family_t sin6_family; /* 地址族. 16-bit*/ in_port_t sin6_port; /* 传输端口号 # 16-bit */ uint32_t sin6_flowinfo; /* IPv6流控信息 32-bit*/ struct in6_addr sin6_addr; /* IPv6地址128-bit */ uint32_t sin6_scope_id; /* IPv6域ID 32-bit */ };关于地址族,也就是在 socket 编程中 socket 函数的第一个参数:
AF_LOCAL:本地通信 AF_INET:IPv4地址 AF_INET6:IPv6地址 -
IP 结构实现
报文结构如下:
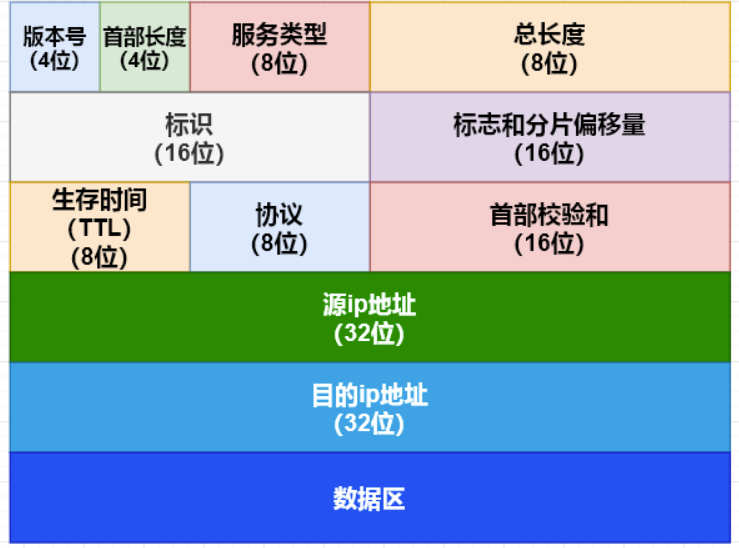
ip 数据首部结构在 include/ip.h 中
struct iphdr { uint8_t ihl : 4; // 首部长度(最小是5) uint8_t version : 4; // 版本号,分别对应 4 / 6 uint8_t tos; // 服务字段类型(最小延时、最大吞吐量、最高可靠性、最小费用) uint16_t len; // ip 数据包的总字节数(数据链路层通常限制为 1500,IP 分片技术) uint16_t id; // 发生分片时记录每个 ip 分片的序号 uint16_t frag_offset; //标志该 ip 数据报在转发过程是否允许分片以及是否是最后一个分片。分片偏移量记录该分片 ip 数据报在整个数据报中的相对位置 uint8_t ttl; // 最多能被转发的次数,每转发一次减 1 uint8_t proto; // 此 ip 数据报中的数据来自哪一个上层协议 uint16_t csum; // 首部校验和 uint32_t saddr; // 本地主机 ip uint32_t daddr; // 目标主机 up uint8_t data[]; // 非必须,共不同上层协议使用 } __attribute__((packed));ip 数据报的发送接口实现(ip_output函数)
int ip_output(struct sock *sk, struct sk_buff *skb) { struct rtentry *rt; struct iphdr *ihdr = ip_hdr(skb); rt = route_lookup(sk_daddr); // 搜索路由表,根据目标 ip 选择合适的网卡(同一网段) if (!rt) { // TODO: dest_unreachable print_err("IP output route lookup fail\n"); return -1; } skb->dev = rt->dev; skb->rt = rt; // 把选中的网卡和路由记录在 sk_buff 结构体 skb_push(skb, IP_HDR_LEN); // 预留 ip 数据包首部 ihdr->version = IPV4; ihdr->ihl = 0x05; ihdr->tos = 0; ihdr->len = skb->len; ihdr->id = ihdr->id; ihdr->frag_offset = 0x4000; ihdr->ttl = 64; ihdr->proto = skb->protocol; ihdr->saddr = skb->dev->addr; ihdr->daddr = sk->daddr; ihdr->csum = 0; // 填充首部信息 ip_dbg("out", ihdr); ihdr->len = htons(ihdr->len); ihdr->id = htons(ihdr->id); ihdr->daddr = htonl(ihdr->daddr); ihdr->saddr = htonl(ihdr->saddr); ihdr->csum = htons(ihdr->csum); ihdr->frag_offset = htons(ihdr->frag_offset); // 做一下格式转换 ip_send_check(ihdr); // 计算校验和 return dst_neigh_output(skb); // 发送! }发送的细节继续跟进 dst_neigh_output,这里参数只传了一个 skb,该结构体负责网络数据发送的全部过程。
int dst_neigh_output(struct sk_buff *skb) { struct iphdr *iphdr = ip_hdr(skb); struct netdev *netdev = skb->dev; struct rtentry *rt = skb->rt; uint32_t daar = ntohl(iphdr->daddr); uint32_t saddr = ntohl(iphdr->saddr); uint8_t *dmac; if (rt->flags & RT_GATEWAY) { daddr = rt->gateway; } dmac = arp_get_hwaddr(daddr); // 从 arp 缓存表中查询目标 ip 对应以太网地址 if (dmac) { return netdev_transmit(skb, dmac, ETH_P_IP); } else { arp_request(saddr, daddr, netdev); // 如果 arp 缓存表中有记录则直接发送,否则先发 arp 请求查询接口(广播) /* Inform upper layer that traffic was not sent, retry later */ return -1; } }然后是 ip 数据接收端口 ip_rcv,这个函数在前面的接收数据流函数 netdev_receive 中,经过判断协议类型是 ip 还是 arp 后调用。
int ip_rcv(struct sk_buff *skb) { struct iphdr *ih = iphdr(skb); // 读取 ip 首部信息 uint16_t csum = -1; if (ih->version != IPV4) { print_err("Datagram version was not IPv4\n"); goto drop_pkt; } if (ih->ihl < 5) { print_err("IPv4 header length must be at least 5\n"); goto drop_pkt; } if (ih->ttl == 0) { //TODO: Send ICMP error print_err("Time to live of datagram reached 0\n"); goto drop_pkt; } csum = checksum(ih, ih->ihl * 4, 0); if (csum != 0) { // Invalid checksum, drop packet handling goto drop_pkt; } // 一系列头部校验 // TODO: Check fragmentation, possibly reassemble ip_init_pkt(ih); // 字段进行小段转换 ip_dbg("in", ih); switch (ip->proto) { // 判断应用层协议类型,并转交数据包给对应处理逻辑 case ICMPV4: icmpv4_incoming(skb); return 0; case IP_TCP: tcp_in(skb); return 0; default: print_err("Unknown IP header proto\n"); goto drop_pkt; } drop_pkt: free_skb(skb); return 0; } -
ICMP 包相关实现
众所周知 ping 命令就是走的 icmp 协议(在基础的 icmp 格式后面增加了自己的格式),icmp 是和 tcp,udp 同一级的传输层协议,首先看一下报文结构,在 include/icmpv4.h 文件中
struct icmp_v4 { uint8_t type; uint8_t code; uint16_t csum; uint8_t data[]; } __attribute__((packed));ICMP 数据接收端口,是完成 ip_rcv 之后的可选分支之一:
void icmpv4_incoming(struct sk_buff *skb) { struct iphdr *iphdr = ip_hdr(skb); struct icmp_v4 *icmp = (struct icmp_v4 *) ip_hdr->data; // 获取 icmp 报文 //TODO: Check csum switch (icmp->type) { // 判断报文类型 case ICMP_V4_ECHO: icmpv4_reply(skb); // 回复 return; case ICMP_V4_DST_UNREACHABLE: // 不可达 print_err("ICMPv4 received 'dst unreachable' code %d, " "check your routes and firewall rules\n", icmp->code); goto drop_pkt; default: print_err("ICMPv4 did not match supported types\n"); goto drop_pkt; } drop_pkt: free_skb(skb); return; }接收到 icmp 查询报文后,如果类型正确,会调用 icmpv4_reply 进行回复:
void icmpv4_reply(struct sk_buff *skb) { struct iphdr *iphdr = ip_hdr(skb); // 获取数据包首部 struct icmp_v4 *icmp; struct sock sk; memset(&sk, 0, sizeof(struct sock)); uint16_t icmp_len = iphdr->len - (iphdr->ihl * 4); // ip 包总长度 - ip 首部长度 = icmp 包总长度 skb_reserve(skb, ETH_HDR_LEN + IP_HDR_LEN + icmp_len); // sk_buff 指针后移至有效数据结束 skb_push(skb, icmp_len); // sk_buff 前移 icmp_len 的长度,开始解析 icmp 包 icmp = (struct icmp_v4 *)skb->data; icmp->type = ICMP_V4_REPLY; // 应答类型 icmp->csum = 0; // ping 应答 icmp->csum = checksum(icmp, icmp_len, 0); // 修改校验数据 skb->protocol = ICMPv4; sk.daddr = iphdr->saddr; ip_output(&sk, skb); // 送到下一层的 ip 层进行发送 free_skb(skb); } -
TCP 包相关实现
TCP 协议有自己的数据包格式(报文段),TCP 报文段封装在 IP 数据包中发送(uint8_t data[]),所以 TCP 报文段由 TCP 首部和 TCP 数据区组成,首部包含了连接建立与断开,数据确认,窗口大小通告,数据发送的相关标志和控制信息。
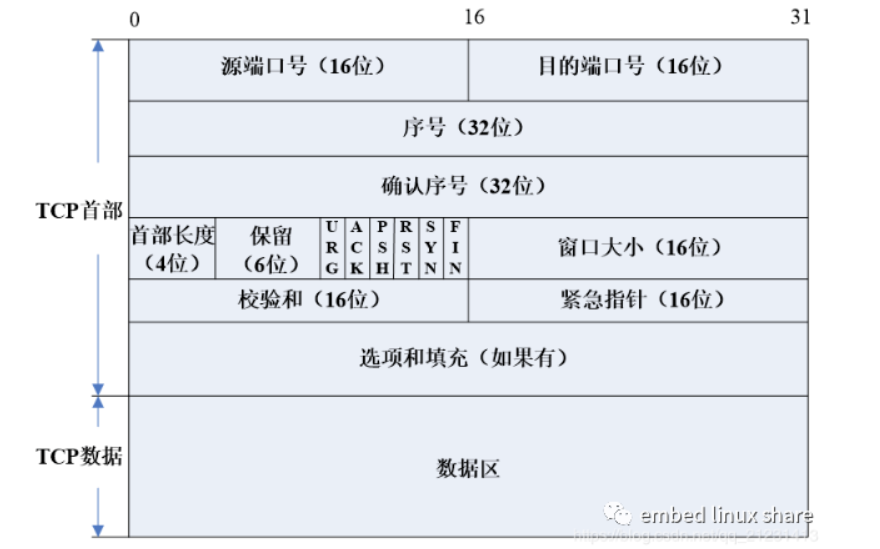
具体实现在 include/tcp.h 中
struct tcphdr { uint16_t sport; // 源端口号 uint16_t dport; // 目的端口号 uint32_t seq; // 是发送端到接收端的数据字节编号,值为当前报文段中第一个数据的字节序号,接收方先计算数据区长度,然后就能根据这个序号字段计算出最后一个数据的序号。 // 当建立一个新连接的时候,SYN 初始化为 1,此时的序号字段是发送方随机选择的初始序号(ISN:Initial Sequence Number),之后发送方每发送数据的第一个字节序号为 ISN + 1 uint32_t ack_seq; // 确认序号只有 ACK 标志为 1 的时候才有效,包含了本机所期望收到的下一个数据序号 uint8_t rsvd : 4; // 不使用 uint8_t hl : 4; // 首部长度、 uint8_t fin : 1, // 终止连接 syn : 1, // 发起连接,同步序号 rst : 1, // 连接复位 psh : 1, // 尽快交付(推送数据) ack : 1, // 首部中的确认序号字段有效 urg : 1, // 首部中的紧急指针字段有效 ece : 1, // 收到拥塞通知 cwr : 1; // 通知发送方降低发送速率 uint16_t win; // 窗口大小字段,通知对方自己可用单独缓冲区大小(字节为单位),为 0 的时候阻止发送方发送数据,流量控制和拥塞控制的本质在于对发送窗口的合理调节 uint16_t csum; uint16_t urp; // 紧急数据时钟放在报文段数据最开始的地方,紧急指针定义出了紧急数据在数据区的结束处 uint8_t data[]; } __attribute__((packed));接着是 tcp 报文的发送,这个函数会在 tcp 建立连接的时候被多次调用(三次握手,write,read),在 src\tcp_output.c 中实现
static int tcp_transmit_skb(struct sock *sk, struct sk_buff *skb, uint32_t seq) { struct tcp_sock *tsk = tcp_sk(sk); struct tcb *tcb = &tsk->tcb; struct tcphdr *thdr = tcp_hdr(skb); /* No options were previously set */ if (thdr->hl == 0) thdr->hl = TCP_DOFFSET; skb_push(skb, thdr->hl * 4); thdr->sport = sk->sport; // 源端口号 thdr->dport = sk->dport; // 目的端口号 thdr->seq = seq; // 起始序号 thdr->ack_seq = tcb->rcv_nxt; // 通知对方期望接受的下一字节的序号(见三次握手部分) thdr->rsvd = 0; // 保留位 thdr->win = tcb->rcv_wnd; // 滑动窗口大小 thdr->csum = 0; // 校验和设置为 0 thdr->urp = 0; // 紧急指针设置为 0 if (thdr->hl > 5) { tcp_write_options(tsk, thdr); } tcp_out_dbg(thdr, sk, skb); thdr->sport = htons(thdr->sport); thdr->dport = htons(thdr->dport); thdr->seq = htonl(thdr->seq); thdr->ack_seq = htonl(thdr->ack_seq); thdr->win = htons(thdr->win); thdr->csum = htons(thdr->csum); thdr->urp = htons(thdr->urp); // 格式转换 thdr->csum = tcp_v4_checksum(skb, htonl(sk->saddr), htonl(sk->daddr)); // 设置校验和 return ip_output(sk, skb); // 发给 ip 层处理 }tcp 接收端口 tcp_in函数(src\tcp.c),在 ip_rcv 中被调用,
void tcp_in(struct sk_buff *skb) { struct sock *sk; struct iphdr *iph; struct tcphdr *th; iph = ip_hdr(skb); // 读取 ip 首部信息 th = (struct tcphdr*) iph->data; // 从 ip 包的 data 区域读取 tcp 数据的信息 tcp_init_segment(th, iph, skb); // 大小端变换和计算应答序号(详见三次握手) sk = inet_lookup(skb, th->sport, th->dport); // 查找管理该 tcp 连接的 sock 结构体(根据两个端口号可确定唯一连接) if (sk == NULL) { print_err("No TCP socket for sport %d dport %d\n", th->sport, th->dport); free_skb(skb); return; } socket_wr_acquire(sk->sock); // 获取该结构体的读写锁 tcp_in_dbg(th, sk, skb); /* if (tcp_checksum(iph, th) != 0) { */ /* goto discard; */ /* } */ tcp_input_state(sk, th, skb); // 根据当前 tcp 通信状态的变化,把整理好的报文递交给应用程序 socket_release(sk->sock); } -
参考文献
- https://mp.weixin.qq.com/mp/appmsgalbum?__biz=MzI0NzA1NTQwOQ==&action=getalbum&album_id=1396822636906545152&scene=173&from_msgid=2247484352&from_itemidx=1&count=3&nolastread=1#wechat_redirect
- http://www.saminiir.com/lets-code-tcp-ip-stack-1-ethernet-arp/
- https://zhuanlan.zhihu.com/p/293658778
- https://www.cnblogs.com/dolphinx/p/3460545.html


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 别再用vector<bool>了!Google高级工程师:这可能是STL最大的设计失误
· 单元测试从入门到精通
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 上周热点回顾(3.3-3.9)