Python爬虫
- 运行环境: python3.7 win7x64
- 使用工具: VS Code
- python 第三方库: requests (自行安装 >>> cmd --->pip install requests, 具体不做介绍)
- requests 库简介
| 函数 | 说明 |
| get(url [, timeout=n]) | 对应HTTP的GET方式,设定请求超时时间为n秒 |
| post(url, data={'key':'value'}) | 对应HTTP的POST方式,字典用于传输客户数据 |
| delete(url) | 对应HTTP的DELETE方式 |
| head(url) | 对应HTTP的HEAD方式 |
| options(url) | 对应HTTP的OPTIONS方式 |
| put(url, data={'key':'value'}) | 对应HTTP的PUT方式,字典用于传输客户数据 |
其中,最常用的是get方法,它能够获得url的请求,并返回一个response对象作为响应。有了响应对象,就能为所欲为了,你觉得呢 ^x^
| 属性 | 说明 |
| status_code | HTTP请求的返回状态(???咨询一下) |
| encoding | HTTP响应内容的编码方式 |
| text | HTTP响应内容的字符串形式 |
| content | HTTP响应内容的二进制形式 |
| 方法 | 说明 |
| json() | 若http响应内容中包含json格式数据, 则解析json数据 |
| raise_for_status() | 若http返回的状态码不是200, 则产生异常 |
(一)先试一试爬一次的效果
# -*- coding: utf-8 -*- """ Created on Mon May 20 10:13:57 2019 @author: lzz """ import requests def getHTMLText(url): try: r=requests.get(url,timeout=30) #打开文件 r.raise_for_status() #返回状态 r.encoding='utf-8' #把文件编码默认为utf-8 return r.text #返回文本 #return r.content except: return "" url="http://www.baidu.cn" for i in range(1): print(getHTMLText(url)) print(len(getHTMLText(url)))
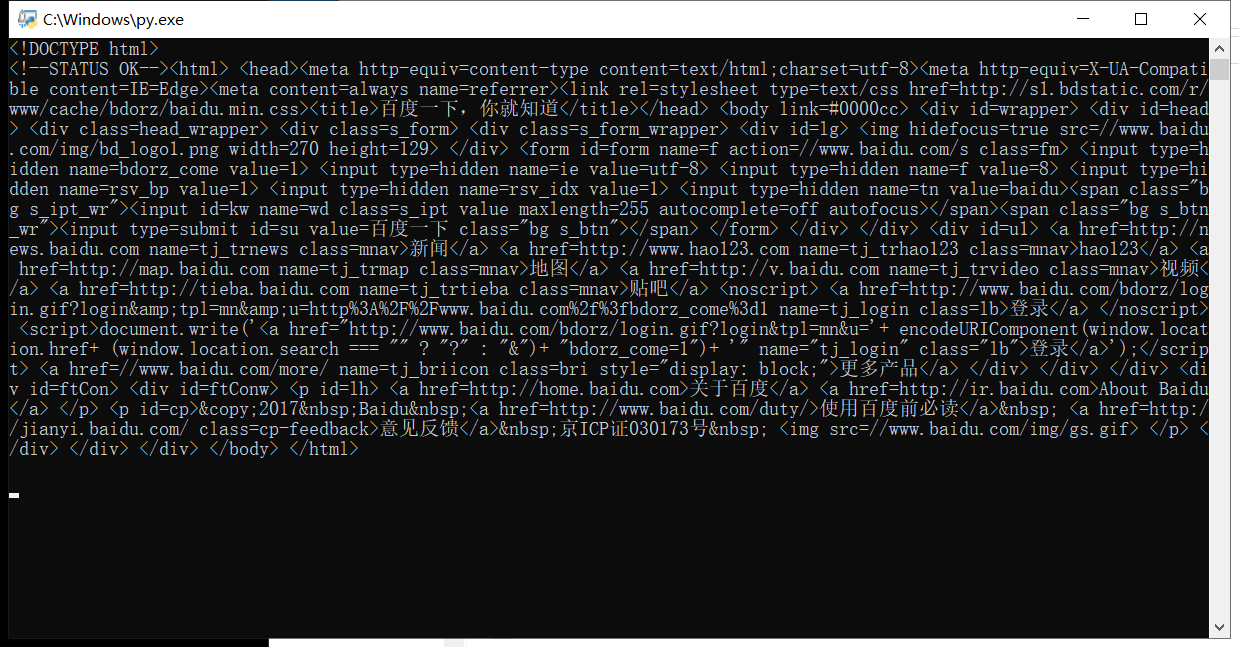
其中返回的text的属性长度为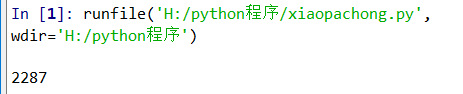
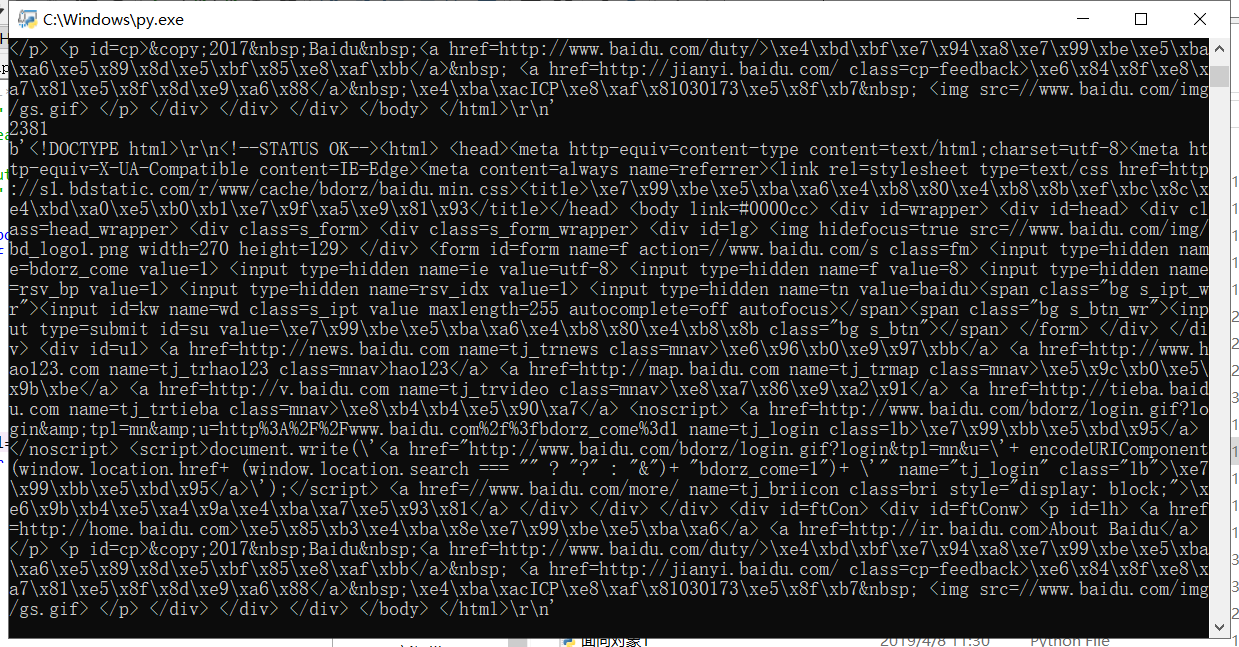
返回的content属性长度为
(二)爬20次的效果
# -*- coding: utf-8 -*- """ Created on Mon May 20 10:13:57 2019 @author: lzz """ import requests def getHTMLText(url): try: r=requests.get(url,timeout=30) #打开文件 r.raise_for_status() #返回状态 r.encoding='utf-8' #把文件编码默认为utf-8 #return r.text #返回文本 return r.content except: return "" url="http://www.baidu.cn" for i in range(20): print("Test %d:" % (i+1), end=" ") response = requests.get(url, timeout=30) # 判断连接状态 if response.status_code == 200: print("Conncect successful!") else: print("Conncect UNsuccessful!")

三.BeautifulSoup4库的运用
安装beautifulsoup4库
pip install beautifulsoup4
1.简介
beautifulsoup是一个非常强大的工具,爬虫利器。
beautifulSoup “美味的汤,绿色的浓汤”
一个灵活又方便的网页解析库,处理高效,支持多种解析器。
利用它就不用编写正则表达式也能方便的实现网页信息的抓取。
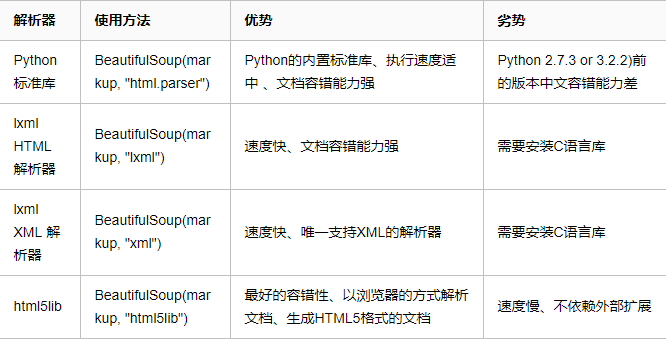
2.常用解析库
Beautiful Soup支持Python标准库中的HTML解析器,还支持一些第三方的解析器,
如果我们不安装它,则 Python 会使用 Python默认的解析器,lxml 解析器更加强大,速度更快,推荐安装。
3.基本使用
# BeautifulSoup入门 from bs4 import BeautifulSoup html = ''' <html><head><title>The Dormouse's story</title></head> <body> <p class="title"><b>The Dormouse's story</b></p> <p class="story">Once upon a time there were three little sisters; and their names were <a href="http://example.com/elsie" class="sister" id="link1">Elsie</a>, <a href="http://example.com/lacie" class="sister" id="link2">Lacie</a> and <a href="http://example.com/tillie" class="sister" id="link3">Tillie</a>; and they lived at the bottom of a well.</p> <p class="story">...</p> ''' soup = BeautifulSoup(html,'lxml') # 创建BeautifulSoup对象 print(soup.prettify()) # 格式化输出 print(soup.title) # 打印标签中的所有内容 print(soup.title.name) # 获取标签对象的名字 print(soup.title.string) # 获取标签中的文本内容 == soup.title.text print(soup.title.parent.name) # 获取父级标签的名字 print(soup.p) # 获取第一个p标签的内容 print(soup.p["class"]) # 获取第一个p标签的class属性 print(soup.a) # 获取第一个a标签 print(soup.find_all('a')) # 获取所有的a标签 print(soup.find(id='link3')) # 获取id为link3的标签 print(soup.p.attrs) # 获取第一个p标签的所有属性 print(soup.p.attrs['class']) # 获取第一个p标签的class属性 print(soup.find_all('p',class_='title')) # 查找属性为title的p # 通过下面代码可以分别获取所有的链接以及文字内容 for link in soup.find_all('a'): print(link.get('href')) # 获取链接 print(soup.get_text())获取文本
(1):标签选择器
在快速使用中我们添加如下代码:
print(soup.title)
print(type(soup.title))
print(soup.head)
print(soup.p)
通过这种soup.标签名 我们就可以获得这个标签的内容
这里有个问题需要注意,通过这种方式获取标签,如果文档中有多个这样的标签,返回的结果是第一个标签的内容,如我们通过soup.p获取p标签,而文档中有多个p标签,但是只返回了第一个p标签内容。
(2):获取名称
当我们通过soup.title.name的时候就可以获得该title标签的名称,即title。
(3):获取属性
print(soup.p.attrs['name'])
print(soup.p['name'])
上面两种方式都可以获取p标签的name属性值
(4):获取内容
print(soup.p.string)
结果就可以获取第一个p标签的内容。
(5):嵌套选择
我们直接可以通过下面嵌套的方式获取
print(soup.head.title.string)
(6):标准选择器
find_all
find_all(name,attrs,recursive,text,**kwargs)
可以根据标签名,属性,内容查找文档
实例
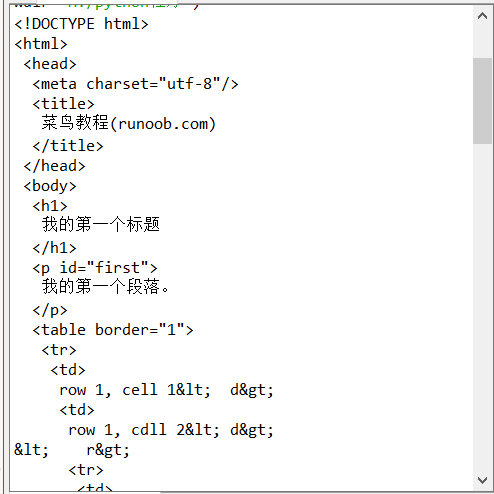
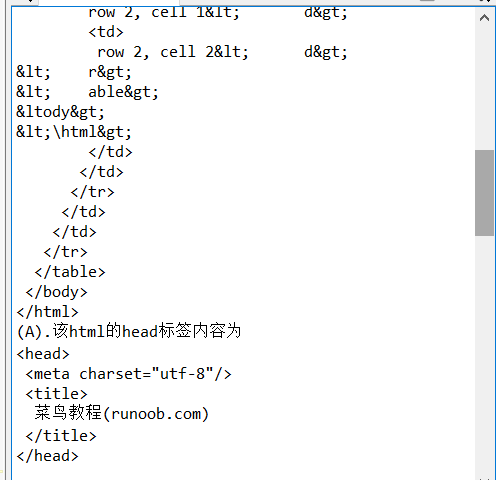
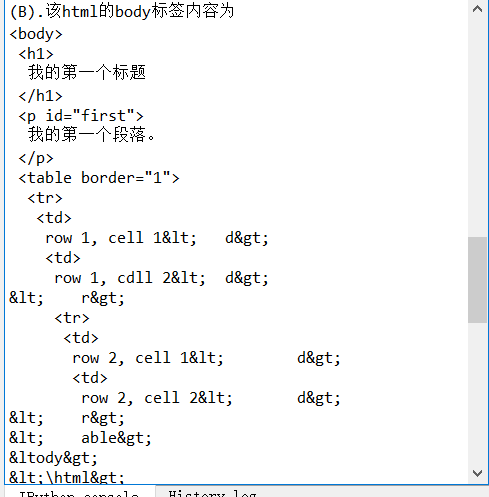
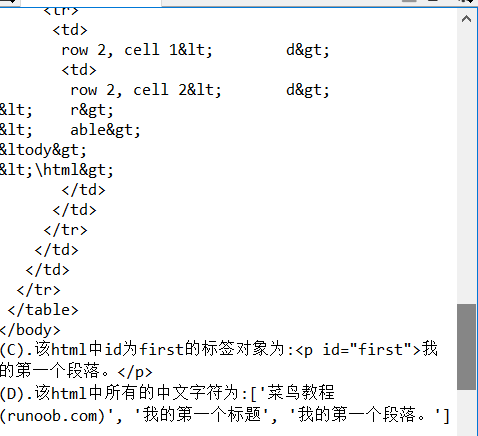
import re from bs4 import BeautifulSoup html = """ <!DOCTYPE html> <html> <head> <meta charset="utf-8"> <title>菜鸟教程(runoob.com)</title> </head> <body> <h1>我的第一个标题</h1> <p id="first">我的第一个段落。</p> <table border="1"> <tr> <td>row 1, cell 1<\td> <td>row 1, cdll 2<\td> <\tr> <tr> <td>row 2, cell 1<\td> <td>row 2, cell 2<\td> <\tr> <\table> <\body> <\html> """ soup = BeautifulSoup(html,"html.parser") print(soup.prettify()) print("(A).该html的head标签内容为\n{}\n03".format(soup.head.prettify())) print("\n") print("(B).该html的body标签内容为\n{}".format(soup.body.prettify())) print("(C).该html中id为first的标签对象为:{}".format(soup.find(id="first"))) print("(D).该html中所有的中文字符为:{}".format(soup.find_all(string = re.compile('[^\x00-\xff]'))))#这里用到正则表达式来找出中文字符串